ĄūDLÝÕiŧáĄŋLlama 2: Open Foundation and Fine-Tuned Chat Models
Download as pptx, pdf1 like2,406 views

2023/7/20 Deep Learning JP http://deeplearning.jp/seminar-2/
![DEEP LEARNING JP
[DL Papers]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Keno Harada, D1, the University of Tokyo
http://deeplearning.jp/](https://image.slidesharecdn.com/llama220230720-230720010354-617059c0/85/DL-Llama-2-Open-Foundation-and-Fine-Tuned-Chat-Models-1-320.jpg)
![Topic
? 2Trillion tokenĪĮÓūĪ·Īŋ7B, 13B, 70BĨâĨĮĨëĪōđŦé_
- ÔÓÃĪÎLLAMA2-CHATĪâđŦé_
- 34BĪâĪĪĪšĪėđŦé_ÓčķĻ
- 4096 context length(2x), grouped-query attention
? žČīæĪÎOpen Source ModelĪōÉÏŧØĪë
? °ēČŦÐÔĪÎŋž]
- Safety-specific data annotation and tuning
- Red-teaming
- Iterative evaluations
- ĀûÓÃÕßÏōĪąĪÎĨŽĨĪĨÉĪâÕûä
? FinetuningĪÎĘÖíĪōÔžĪËÓĘö
- PretrainingĪËĪÄĪĪĪÆĪÏĪÁĪįĪģĪÃĪČĪĀĪą
? ÐÂĪŋĪĘ°kŌ
- Emergence of tool usage
- Temporal organization of knowledge
ĖØeĪĘŅÔž°ĪŽĪĘĪĪöšÏĄĒíĪäąíĪÏLLaMA2ÔŠÕÎÄĪŦĪéĪÎŌýÓÃĪËĪĘĪęĪÞĪđ
3](https://image.slidesharecdn.com/llama220230720-230720010354-617059c0/85/DL-Llama-2-Open-Foundation-and-Fine-Tuned-Chat-Models-3-320.jpg)





















ĄūDLÝÕiŧáĄŋLlama 2: Open Foundation and Fine-Tuned Chat Models
- 1. DEEP LEARNING JP [DL Papers] Llama 2: Open Foundation and Fine-Tuned Chat Models Keno Harada, D1, the University of Tokyo http://deeplearning.jp/
- 3. Topic ? 2Trillion tokenĪĮÓūĪ·Īŋ7B, 13B, 70BĨâĨĮĨëĪōđŦé_ - ÔÓÃĪÎLLAMA2-CHATĪâđŦé_ - 34BĪâĪĪĪšĪėđŦé_ÓčķĻ - 4096 context length(2x), grouped-query attention ? žČīæĪÎOpen Source ModelĪōÉÏŧØĪë ? °ēČŦÐÔĪÎŋž] - Safety-specific data annotation and tuning - Red-teaming - Iterative evaluations - ĀûÓÃÕßÏōĪąĪÎĨŽĨĪĨÉĪâÕûä ? FinetuningĪÎĘÖíĪōÔžĪËÓĘö - PretrainingĪËĪÄĪĪĪÆĪÏĪÁĪįĪģĪÃĪČĪĀĪą ? ÐÂĪŋĪĘ°kŌ - Emergence of tool usage - Temporal organization of knowledge ĖØeĪĘŅÔž°ĪŽĪĘĪĪöšÏĄĒíĪäąíĪÏLLaMA2ÔŠÕÎÄĪŦĪéĪÎŌýÓÃĪËĪĘĪęĪÞĪđ 3
- 5. ÄŋīÎ ? Pretraining ? Fine-tuning ? Model safety ? Key observations and insights 5
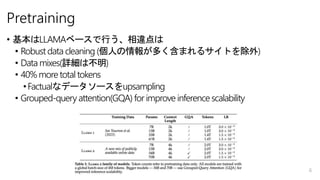
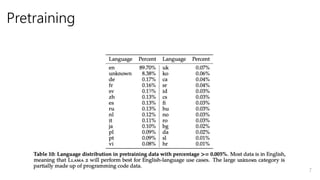
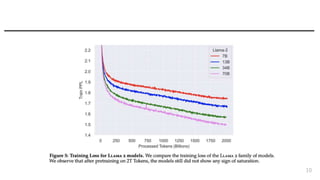
- 6. Pretraining ? ŧųąūĪÏLLAMAĨŲĐ`ĨđĪĮÐÐĪĶĄĒÏāß`ĩãĪÏ ? Robust data cleaning (ČËĪÎĮéóĪŽķāĪŊšŽĪÞĪėĪëĨĩĨĪĨČĪōģýÍâ) ? Data mixes(ÔžĪÏēŧÃũ) ? 40% more total tokens ?FactualĪĘĨĮĐ`ĨŋĨ―Đ`ĨđĪōupsampling ? Grouped-query attention(GQA) for improve inference scalability 6
- 8. ĨâĨĮĨëÔėĪĘĪÉ ? Standard transformer architecture ? Pre-normalization using RMSNorm ? SwiGLU activation ? Rotary positional embeddings ? (for 34B and 70B) GQA ? AdamW, cosine learning rate schedule, warmup ? Bytepair encoding(BPE) using SentencePiece - ĘýŨÖĪÏļũčėĮÐĪę·ÖĪą, unknown UTF-8ĪÏbytesĪĮdecompose 8
- 9. GQA(2023/05) by Google 9 From GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- 10. 10
- 11. Hardware ? A100(80G)ĪĮģÉĪĩĪėĪŋcluster - RSC: 400W, NVIDIA Quantum InifiniBand(ļßĪĪ) - Internal production cluster: 350W, RoCE(RDMA over converged Ethernet) - 200GpbsĪÎÄÚēŋÍĻÐÅ - ABCIQËã(A100 40G): 1720320(hour) / 8(GPUs/node) * 3(point/hour) * 2(80G/40G) * 220(point/yen) = žs2.8|Ō? 11
- 12. 12
- 13. Ôuý ? Code - HumanEvalĪČMBPPĪÎpass@1 scoresĪÎÆ―ūų ? Commonsense Reasoning - PIQA, SIQA, HellaSwag, WinoGrande, ARC OpenBookQA, CommonSenseQAĪÎÆ―ūųĨđĨģĨĒ ? CommonSenseQAĪÎĪß7-shot, ËûĪÏ0-shot ? World Knowledge - NaturalQuestions, TriviaQAĪÎ5-shotĪÎÆ―ūųĨđĨģĨĒ ? Reading Comprehension - SQuAD, QuAC, BoolQĪÎ0-shotĪÎÆ―ūųĨđĨģĨĒ ? MATH - GSM8K(8-shot), MATH(4-shot)ĪÎÆ―ūųĨđĨģĨĒ ? Popular Aggregated Benchmarks - MMLU(5-shot), Big Bench Hard(3-shot), AGI Eval(ÓĒÕZĪÎĪß)(3-5 shot)ĪÎÆ―ūųĨđĨģĨĒ 13
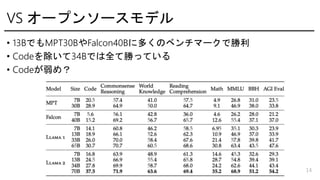
- 14. VS ĨŠĐ`ĨŨĨóĨ―Đ`ĨđĨâĨĮĨë ? 13BĪĮĪâMPT30BĪäFalcon40BĪËķāĪŊĪÎĨŲĨóĨÁĨÞĐ`ĨŊĪĮŲĀû ? CodeĪōģýĪĪĪÆ34BĪĮĪÏČŦĪÆŲĪÃĪÆĪĪĪë ? CodeĪŽČõĪáĢŋ 14
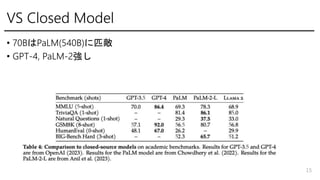
- 15. VS Closed Model ? 70BĪÏPaLM(540B)ĪËÆĨģ ? GPT-4, PaLM-2Ī· 15
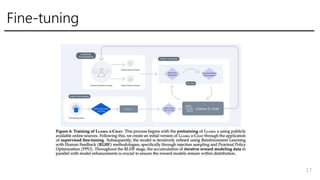
- 16. Fine-tuning ? Supervised fine-tuning ? Iterative reward modeling ? RLHF - Rejection sampling - PPO ? Ghost Attention(GAtt) - Ņ}ĘýŧØĪÎĪäĪęČĄĪęĪōĪĶĪÞĪŊQĪĶĪŋĪáĪÎđĪ·ō 16
- 17. Fine-tuning 17
- 18. Supervised fine-tuning ? FlanĪÎĨĮĐ`Ĩŋ + ķĀŨÔĪĮŨũģÉĪ·Īŋ(ĨŲĨóĨĀĐ`ĪËŌĀîm)ĨĮĐ`Ĩŋ - 10,000ĪŊĪéĪĪĪĒĪėĪÐĪĪĪĪ―YđûĪŽģöĪëĪéĪ·ĪĪ - gëHĪËĨĒĨÎĨÆĐ`Ĩ·ĨįĨóĪ·ĪŋĪÎĪÏ27,540 ?ŌĀîmĪ·ĪŋĨŲĨóĨĀĐ`ĪÎĨĮĐ`ĨŋĪīĪČĪĮŅ§ÁĪ·ĪÆĨŅĨÕĨĐĐ`ĨÞĨóĨđŌĪŋĪé―Y ß`ĪĪĪŽĪĒĪÃĪŋĪČĪÎĪģĪČ - ČËégĪÎģöÁĶĪČĨâĨĮĨëĪÎģöÁĶĪŽËÆĪŋĪčĪĶĪĘĨėĨŲĨëĪË ? Prompt + special token + answerĪÎÎÄŨÖÁÐĪōŨÔžšŧØĒĩÄĪĘÄŋĩÄévĘýĪĮŅ§ ÁĄĒanswerēŋ·ÖĪÎlossĪÎĪßĪĮŅ§Á, 2epoch - lr: 2 * 10 **-5, cosine lr schedule 18
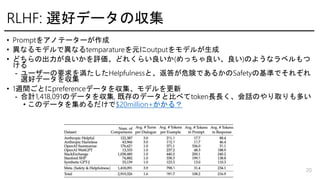
- 20. RLHF: ßxšÃĨĮĐ`ĨŋĪÎ §žŊ ? PromptĪōĨĒĨÎĨÆĐ`ĨŋĐ`ĪŽŨũģÉ ? ŪĪĘĪëĨâĨĮĨëĪĮŪĪĘĪëtemparatureĪōÔŠĪËoutputĪōĨâĨĮĨëĪŽÉúģÉ ? ĪÉĪÁĪéĪÎģöÁĶĪŽÁžĪĪĪŦĪōÔuýĄĒĪÉĪėĪŊĪéĪĪÁžĪĪĪŦ(ĪáĪÃĪÁĪãÁžĪĪĄĒÁžĪĪ)ĪÎĪčĪĶĪĘĨéĨŲĨëĪâĪÄ ĪąĪë - ĨæĐ`ĨķĐ`ĪÎŌŠĮóĪōšĪŋĪ·ĪŋHelpfulnessĪČĄĒ·ĩīðĪŽÎĢęĪĮĪĒĪëĪŦĪÎSafetyĪÎŧųĘĪĮĪ―ĪėĪūĪė ßxšÃĨĮĐ`ĨŋĪō §žŊ ? 1ßLégĪīĪČĪËpreferenceĨĮĐ`ĨŋĪō §žŊĄĒĨâĨĮĨëĪōļüР- šÏÓ1,418,091ĪÎĨĮĐ`ĨŋĪō §žŊ, žČīæĪÎĨĮĐ`ĨŋĪČąČĪŲĪÆtokenéLéLĪŊĄĒŧáÔĪÎĪäĪęČĄĪęĪâķāĪĪ ? ĪģĪÎĨĮĐ`ĨŋĪōžŊĪáĪëĪĀĪąĪĮ$20million+ĪŦĪŦĪëĢŋ 20
- 21. 21 From Surge AI ĄÁ Meta: The 1M+ RLHF Annotations Powering Llama 2
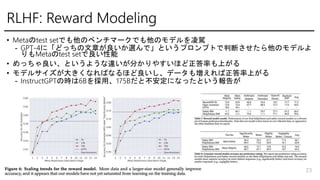
- 22. RLHF: Reward Modeling ? HelpfulnessĪČSafetyĪÎĨđĨģĨĒĪōģöĪđĨâĨĮĨëĪōĪ―ĪėĪūĪėÓū - ĨŠĐ`ĨŨĨóĨ―Đ`ĨđĪÎĨĮĐ`ĨŋĪČ―MĪßšÏĪïĪŧÓūĪ·ĪÆĪâî}ĪĘĪŦĪÃĪŋĪÎĪĮŌŧ ūwĪËĘđĪÃĪŋ - Helpfulness: MetaķĀŨÔĪÎHelpfulnessĨĮĐ`ĨŋĪČ, SafetyĨĮĐ`Ĩŋ?ĨŠĐ`ĨŨĨó Ĩ―Đ`ĨđĪÎĨĮĐ`ĨŋĪĮÓū - Safety: MetaķĀŨÔĪÎSafetyĨĮĐ`Ĩŋ + Anthropic:Helpfullness(MetaķĀŨÔ+ ĨŠĐ`ĨŨĨóĨ―Đ`Ĩđ)Īō9:1ĪÎļîšÏĪĮÓū ?10%HelpfullnessŧėĪžĪëĪČĪÉĪÁĪéĪâsafeĪĘrĪÎÅÐķĻĪËŌÛÁĒĪÄ - ĪáĪÃĪÁĪãÁžĪĪĄĒÁžĪĪĨéĨŲĨëĪōŧîÓÃĪ·ĪŋĨÞĐ`ĨļĨóĪâlossĪË―MĪßÞzĪā ? 1epoch(ß^Ņ§ÁĪōÓQyĪ·ĪŋĪŋĪá), lr: 5 * 10 ** -6(70B) ËûĪÏ1 * 10 ** -5, consine lr, warmup 22
- 23. RLHF: Reward Modeling ? MetaĪÎtest setĪĮĪâËûĪÎĨŲĨóĨÁĨÞĐ`ĨŊĪĮĪâËûĪÎĨâĨĮĨëĪōÁčņ{ - GPT-4ĪËĄļĪÉĪÃĪÁĪÎÎÄÕÂĪŽÁžĪĪĪŦßxĪóĪĮĄđĪČĪĪĪĶĨŨĨíĨóĨŨĨČĪĮÅÐķÏĪĩĪŧĪŋĪéËûĪÎĨâĨĮĨëĪč ĪęĪâMetaĪÎtest setĪĮÁžĪĪÐÔÄÜ ? ĪáĪÃĪÁĪãÁžĪĪĄĒĪČĪĪĪĶĪčĪĶĪĘß`ĪĪĪŽ·ÖĪŦĪęĪäĪđĪĪĪÛĪÉÕýīðÂĘĪâÉÏĪŽĪë ? ĨâĨĮĨëĨĩĨĪĨšĪŽīóĪĪŊĪĘĪėĪÐĪĘĪëĪÛĪÉÁžĪĪĪ·ĄĒĨĮĐ`ĨŋĪâĪĻĪėĪÐÕýīðÂĘÉÏĪŽĪë - InstructGPTĪÎrĪÏ6BĪōņÓÃĄĒ175BĪĀĪČēŧ°ēķĻĪËĪĘĪÃĪŋĪČĪĪĪĶóļæĪŽ 23
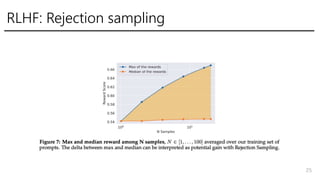
- 24. RLHF: iterative fine-tuning ? Rejection Sampling fine-tuning - KĨâĨĮĨëĪËģöÁĶĪĩĪŧĪÆĄĒReward ModelĪĮŌŧ·ŽļßĪĪĨđĨģĨĒĪōģöĪ·Īŋģö ÁĶĪōßxĪÓfine-tuneĪđĪë ? PPO ? RLHF modelĪÏV1ĪŦĪéV5ĪÞĪĮŨũĪęĄĒV4ĪÞĪĮĪÏRejection Sampling fine- tuning, V5ĪĮĪÏRejection Sampling fine-tuningááĪËPPO(70B) - 70BŌÔÍâĪĮĪÏ70BĪÎRejectionĪĮĪÎßxĪÐĪėĪŋģöÁĶĪōÔŠĪËfine-tune - V1, V2ĪËĪŠĪĪĪÆĪÎÁžĪĪģöÁĶĪōV3ĪÎÓūĪËĘđÓà ?šŽĪáĪĘĪĪĪČÐÔÄÜŧŊ(forgettingĪČĪŦĪČévßB?) 24
- 26. Ghost Attention ? RLHFV3ĪŦĪéßmÓÃĄĒĄļĐĐĪßĪŋĪĪĪËÕņĪëÎčĪÃĪÆĄđĪōŧáÔĪÎĪäĪęČĄĪęĪŽĪĻĪÆĪâ ūAĪąĪĩĪŧĪëĪčĪĶĪĘžžÐg ? ĄļĐĐĪßĪŋĪĪĪËÕņĪëÎčĪÃĪÆĄđĪōuser messageĪËĪŊĪÃĪÄĪąĪÆĄĒĨâĨĮĨëĪÎģöÁĶĪō ĩÃĪëĄĒŅ§ÁrĪËĪÏĮ°ŧØĪÞĪĮĪÎturnĪÎŧáÔĪÎtoken lossĪō0ĪËĪđĪë - ĄļĐĐĪßĪŋĪĪĪËÕņĪëÎčĪÃĪÆĄđĪÎĀýŨÔĖåĪâÉúģÉ ? 20ŌÔÉÏĪÎturnĪĮĪÎŌŧØÐÔĪōī_ÕJ 26
- 27. Ôuý ? GPT-4ĪōĘđÓÃĪ·ĪŋÔuýĪĮChatGPTĪËŲĀû ? ČËégĪËĪčĪëÔuýĪĮĨŠĐ`ĨŨĨóĨ―Đ`ĨđĨâĨĮĨëĪËŲĀû - Academic/ResearchžÄĪęĪÎpromptĪÎĪŋĪágęÓÃĪËŅØĪÃĪŋĪâĪÎĪĮĪĘĪĪ - Coding, reasoningĪËévĪđĪëpromptĪÏšŽĪÞĪėĪÆĪĪĪĘĪĪ - Ņ}ĘýĪäĪęČĄĪęĪÎŧáÔĪÏŨîááĪÎŧáÔĪÎŲ|ĪĮÔuý ? ŧáÔČŦĖåĪÎĖåōYĪĮÔuýĪ·ĪŋĪéäĪïĪëŋÉÄÜÐÔ 27
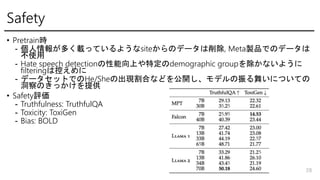
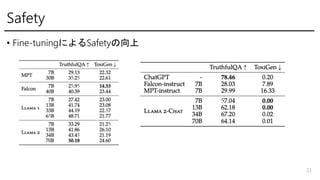
- 28. Safety ? Pretrainr - ČËĮéóĪŽķāĪŊÝdĪÃĪÆĪĪĪëĪčĪĶĪĘsiteĪŦĪéĪÎĨĮĐ`ĨŋĪÏÏũģý, MetaŅuÆ·ĪĮĪÎĨĮĐ`ĨŋĪÏ ēŧĘđÓà - Hate speech detectionĪÎÐÔÄÜÏōÉÏĪäĖØķĻĪÎdemographic groupĪōģýĪŦĪĘĪĪĪčĪĶĪË filteringĪÏŋØĪĻĪáĪË - ĨĮĐ`ĨŋĨŧĨÃĨČĪĮĪÎHe/SheĪÎģöŽFļîšÏĪĘĪÉĪōđŦé_Ī·ĄĒĨâĨĮĨëĪÎÕņĪëÎčĪĪĪËĪÄĪĪĪÆĪÎ ķīēėĪÎĪĪÃĪŦĪąĪōĖáđĐ ? SafetyÔuý - Truthfulness: TruthfulQA - Toxicity: ToxiGen - Bias: BOLD 28
- 29. Safety ? Fine-tuning - Supervised safety fine-tuning ?Adversarial promptsĪČĪ―ĪėĪËĪđĪësafe demonstrationĪōĪÏĪļĪáĪËĘ ä, RLHFĮ°ĪŦĪésafetyÐÔĪōļßĪáĪë - Safety RLHF ?Safety-specificĪĘReward ModelĪČĄĒĪčĪęŅ}ëjĪĘadversarial promptsĪō Ęä - Safety Context Distillation ?Ą°ĪĒĪĘĪŋĪÏsafeĪĮØČÎļÐĪÎĪĒĪëĨĒĨ·ĨđĨŋĨóĨČĪĮĪđĄąĪČĪĪĪĶpre-ĨŨĨíĨóĨŨ ĨČĪōŨãĪ·ĪÆģöÁĶĪĩĪŧĪŋĨĩĨóĨŨĨëĪōĄĒpre-ĨŨĨíĨóĨŨĨČĪōiĪĪĪÆfine- tune 29
- 30. Safety ? Red Teaming - MLŌÔÍâĪËĪâĄĐĪĘéTžŌšŽĪá350ČËĪÛĪÉĪŽēÎžÓ 30
- 32. RLHFĪÎÍÆĪ·ĨÝĨĪĨóĨČ ? SFTĪÏĨ·Ĩ°ĨĘĨëķāĪĪĪŦĪéŅ§ÁÉÏÁžĪĪĪŦĪĘĪÃĪÆËžĪÃĪÆĪŋĪąĪÉĄĒpoorĪĘ demonstrationĪËŌýĪÃĪéĪėĪëĄĒÉÏÏÞĪâĨĒĨÎĨÆĐ`ĨŋĐ`ĪÎĨđĨĨëĪËĪčĪÃĪÆķĻĪÞĪà ĪÁĪãĪĶ ? ĪÉĪÃĪÁĪÎģöÁĶĪŽÁžĪĪĪŦĪÎßxšÃĪōĪđĪëĨĒĨÎĨÆĐ`Ĩ·ĨįĨóĪÏĪäĪęĪäĪđĪĪĪ·ĨÖĨėĪâÉŲ ĪĘĪĪ - Reward ModelĪÎŅ§ÁĪŽßMĪāĪČĩÍĪĪĨđĨģĨĒĪŽļķĪąĪéĪėĪëĪŲĪÎÄÕÂĪōš gĪËŌ ·ÖĪąĪéĪėĪë ? Ą°the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHFĄą 32
- 34. In-context temperature rescaling ? RLHFĪËĪčĪęĄĒPromptĪËĪčĪÃĪÆtemperatureĪÎÓ°íķČšÏĪĪĪŽŪĪĘĪë - Ą°ÔĪōøĪĪĪÆĄąĪÎĪčĪĶĪĘpromptĪĀĪČtemperatureĪōÉÏĪēĪëĪČdiversityÉÏ ĪŽĪÃĪÆĪĪĪŊ - Ą°hogeĪÎĘŨķžĪÏĪÉĪģĢŋĄąĪÎĪčĪĶĪĘfactualĪĘpromptĪĀĪČtemperatureĪōÉÏ ĪēĪÆĪâdiversityĪÎÏōÉÏĪÏūĪäĪŦ - íĪÎĮāūĪÎAĪĪËŨĒÄŋ 34
- 36. Tool Use Emergence ? Tool-use usageĪËĪÄĪĪĪÆÃũĘūĩÄĪË―ĖĪĻĪÆĪĪĪĘĪĪĪÎĪËalignmentĪÎß^ģĖĪĮ tool-useĪÎÄÜÁĶĪŽģöŽFĪ·Īŋ 36
- 37. ĪÞĪČĪá 37
Editor's Notes
- #38: ĪÞĪČĪáĪĮĪđ ąūŅÐūŋĪĮĪÏķāĪĘhūģ?ĨŋĨđĨŊĪËęĪđĪëĪŋĪáĪËĪÏŅ§ÁĪËĪčĪëÐÐÓÏĩÁÐĪÎŦ@ĩÃĪŽÓÐŋĪĮĪĒĪëĪČŋžĪĻĪéĪėĪÞĪđĪŽĄĒŽFŨīĪÎĘÖ·ĻĪÏÐÐÓĪËévĪ·ĪÆĪÎąíŽFŅ§ÁĪŽĪĘĪĩĪėĪÆĪŠĪéĪšĄĒÐÐÓŦ@ĩÃĪËßmĪ·ĪŋÔėĪÎąØŌŠÐÔĪōÖļÕŠĪ·ĪÞĪ·Īŋ ąūŅÐūŋĪÏĨÕĨĢĐ`ĨÉĨÐĨÃĨŊÖÆÓųĪŽÐÐÓĪÎŅ§Á?Ŧ@ĩÃĪËĪČĪÃĪÆÓÐÓÃĪĘÔėĪĀĪČĒķĻĪ·ĄĒŅ§ÁĪËĪčĪëŦ@ĩÃĪōÄŋÖļĪ·ĪÞĪ·Īŋ ĮąÔÚŋÕégĪËĪŠĪąĪëēî·ÖĪōĪâĪČĪËÐÐÓßxkĪōÐÐĪĶĪģĪČĪĮžČīæĘÖ·ĻĪčĪę°ēķĻĪ·ĪÆÄŋËŨīBĪË §ĘøĪđĪëĪģĪČĪōī_ÕJĪ·ĪÞĪ·Īŋ ĪčĪęëAÓĩÄĪĮŅ}ëjĪĘĨŋĨđĨŊĪËIĪđĪëĪŋĪáĪËĮąÔÚŋÕégĪÎŅ§ÁĪÎđĪ·ōĪäÐÐÓĪÎļüÐÂĘ―ĪËévĪđĪëĪĩĪéĪĘĪëđĪ·ōĪŽąØŌŠĪĮĪĒĪëĪģĪČĪō―ņááĪÎÕnî}ĪČĪ·ĪÆÕûĀíĪ·ĪÞĪ·Īŋ ĪĘĪŠąūŅÐūŋĪËĪÄĪĪĪÆĪÏČËđĪÖŠÄÜŅ§ŧá2022ĪËĪŠĪĪĪÆņk?°kąígĪßĪĮĪđ °kąíĪÏŌÔÉÏĪËĪĘĪęĪÞĪđĄĒĪīĮåÂĪĒĪęĪŽĪČĪĶĪīĪķĪĪĪÞĪ·Īŋ