







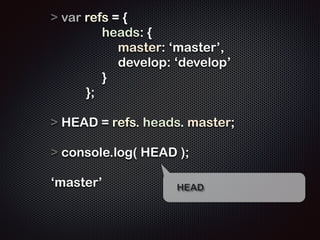










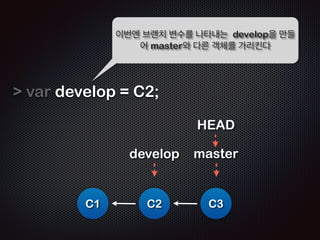
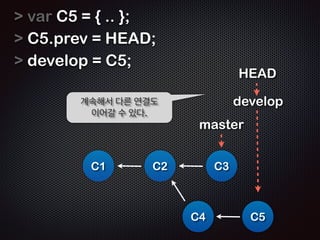








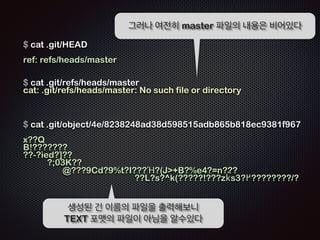


![$ cat .git/HEAD
!
ref: refs/heads/master
!!
ĻĘĖļ¤¼ļéś ņŚ¼ņĀäĒ׳ master ĒīīņØ╝ņØś ļé┤ņÜ®ņØĆ ļ╣äņ¢┤ņ׳ļŗż
$ cat .git/refs/heads/master
cat: .git/refs/heads/master: No such file or directory
!!!
$ cat .git/object/4e/8238248ad38d598515adb865b818ec9381f967
!
x??Q
B!???????
??-?ied?]??
?;03K??
@???9Cd?9%t?I???╬ē?(J+B?%e4?=n???
??L?s?^k(?????!???zk═żs3?▀é????????/?
ņāØņä▒ļÉ£ ĻĖ┤ ņØ┤ļ”äņØś ĒīīņØ╝ņØä ņČ£ļĀźĒĢ┤ļ│┤ļŗł
TEXT Ēżļ¦ĘņØś ĒīīņØ╝ņØ┤ ņĢäļŗśņØä ņĢīņłśņ׳ļŗż](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-58-320.jpg)






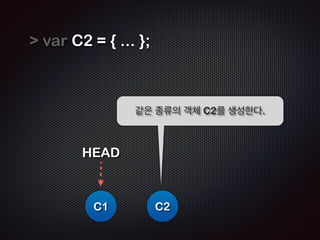
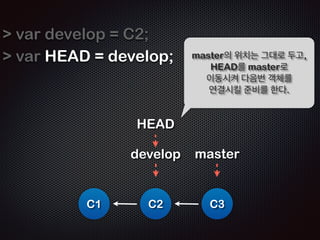
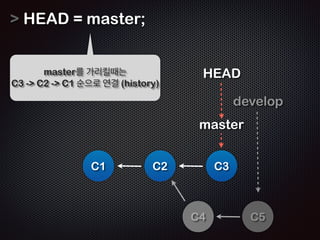
![var blob = ŌĆ£ĒŚżļŹö+ļé┤ņÜ®ņØ┤ zlib ļĪ£ ņĢĢņČĢļÉ£ ļ¼Ėņ×ÉņŚ┤ŌĆØ;
!
var Tree = [
blob,
Tree,
];
!
var Commit = {
JavascriptļĪ£ Ēæ£Ēśä ...
parent: { },
tree: [ ],
author: ŌĆ£stringŌĆØ,
date: ŌĆ£2011/11/30ŌĆØ
};
!
var Tag = ŌĆ£ņ╗żļ░ŗņØä Ļ░Ćļ”¼ĒéżļŖö ļ¼Ėņ×ÉņŚ┤ŌĆØ](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-68-320.jpg)











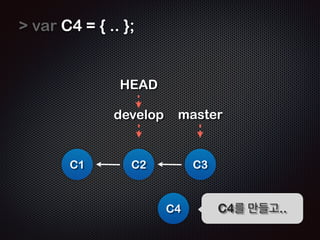
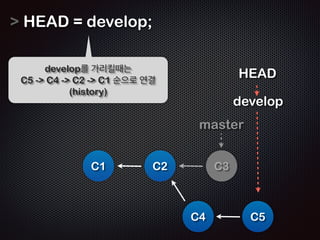
![!
!
Repo
!R
Working
EADME
!R
Staging
EADME
$ git commit -m ŌĆśfirst commitŌĆÖ
[master (root-commit) b3d38eb] first commit
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 README
!R
C1: b3d38eb
EADME
!
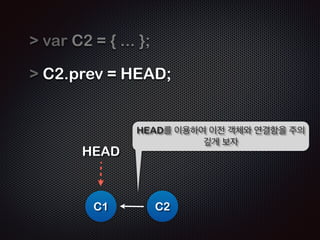
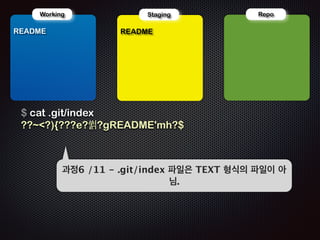
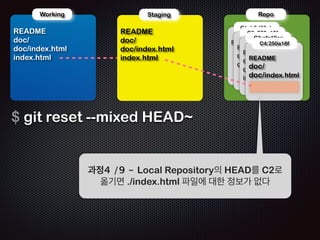
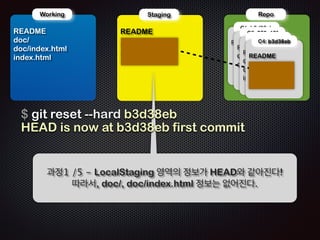
Ļ│╝ņĀĢ7 /11 - ņØ┤ļ»Ė README ņĀĆņןļÉśņ¢┤ ņ׳ņ£╝ļ»ĆļĪ£
ŌĆścommitŌĆÖ ļŗ©Ļ│äņŚÉņäĀ ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁņØś ļ”¼ņŖżĒŖĖļź╝ ņ░ĖņĪ░
ĒĢśņŚ¼ commit objectļź╝ ļ¦īļōĀļŗż](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-85-320.jpg)
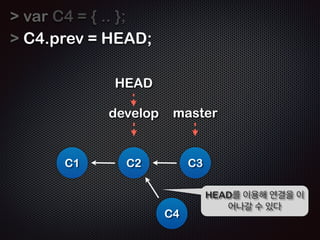
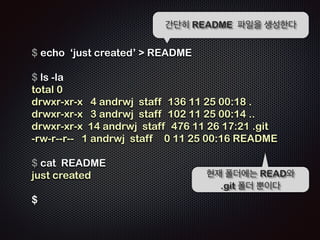
![!
!
Repo
!R
Working
EADME
!R
Staging
EADME
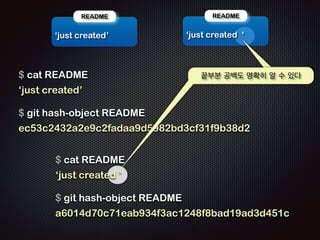
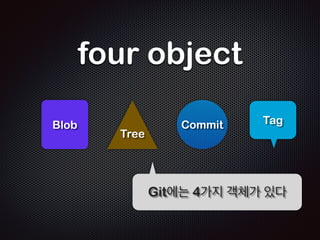
$ git commit -m ŌĆśfirst commitŌĆÖ
[master (root-commit) b3d38eb] first commit
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 README
!R
C1: b3d38eb
EADME
!
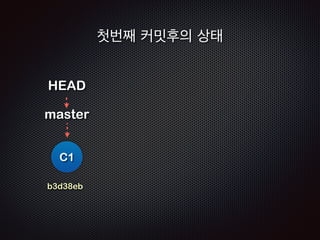
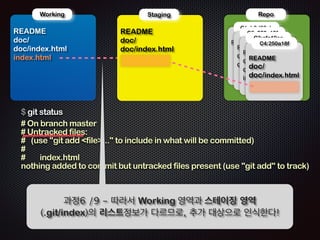
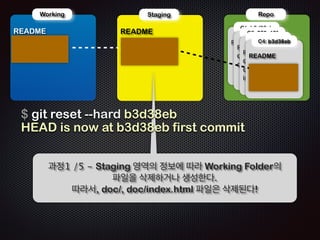
Ļ│╝ņĀĢ8 /11 - ņŖżĒģīņØ┤ņ¦Ģ (.git/index) ņśüņŚŁņØś ņĀĢļ│┤ļÅä
ĻĘĖļīĆļĪ£ ļé©ņĢäņ׳ļŗż!!](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-86-320.jpg)






![!
!
Repo
!R
Working
EADME
doc/
doc/index.html
!R
Staging
EADME
doc/
doc/index.html
!R
C2: 250a18f
EADME
!
$ git commit -m ŌĆśsecond commitŌĆÖ
[master 250a18f] second commit
1 files changed, 1 insertions(+), 0 deletions(-)
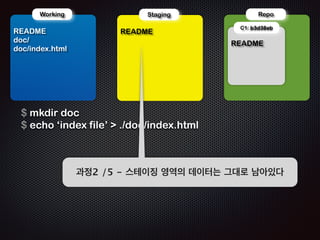
create mode 100644 doc/index.html
!
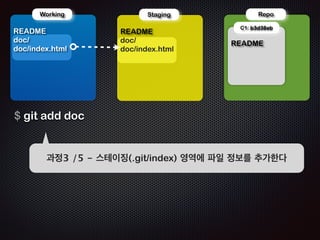
C1: b3d38eb
!R
EADME
doc/
doc/index.html
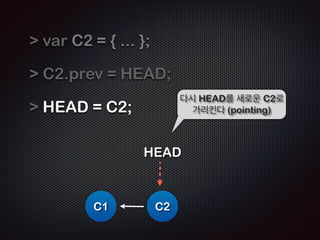
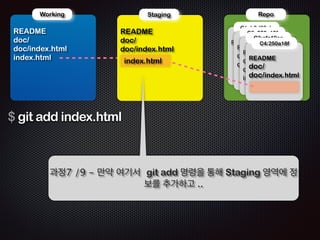
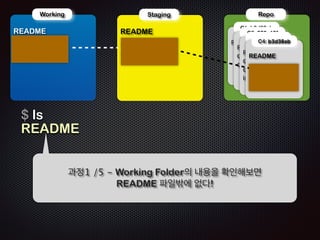
Ļ│╝ņĀĢ5 /5 - ņāłļĪ£ņÜ┤ ņ╗żļ░ŗ(ļ”¼ņŖżĒŖĖ)ĒīīņØ╝ņØ┤ ļ¦īļōżņ¢┤ņ¦ĆĻ│Ā
HEADļŖö ņØ┤ ņ╗żļ░ŗ(C2)ņØä Ļ░Ćļ”¼Ēé©ļŗż](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-97-320.jpg)


![!
!
Repo
!R
Working
EADME
doc/
doc/index.html
index.html
!R
Staging
EADME
doc/
doc/index.html
index.html
$ git commit -m ŌĆśthird commitŌĆÖ
[master cfc19ca] third commit
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 index.html
!R
C1: b3d38eb
C2: 250a18f
EADME
!
!R
!R
C3:cfc19ca
EADME
doc/
doc/index.html
EADME
doc/
doc/index.html
index.html
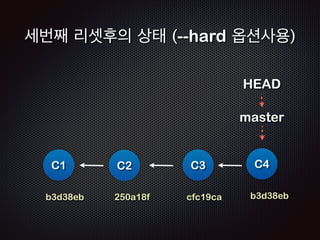
Ļ│╝ņĀĢ4 /4 - ņāłļĪ£ņÜ┤ ņ╗żļ░ŗ(ļ”¼ņŖżĒŖĖ)ĒīīņØ╝ņØ┤ ļ¦īļōżņ¢┤ņ¦ĆĻ│Ā
HEADļŖö ņØ┤ ņ╗żļ░ŗ(C3)ņØä Ļ░Ćļ”¼Ēé©ļŗż](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-103-320.jpg)












![!
!
Repo
!R
Working
EADME
doc/
doc/index.html
index.html
!R
Staging
EADME
doc/
doc/index.html
!R
C1: b3d38eb
!R
C2: 250a18f
C3:cfc19ca
C4:250a18f
EADME
!
!R
EADME
doc/
doc/index.html
!R
C5:0815eb5
EADME
doc/
doc/index.html
index.html
EADME
doc/
doc/index.html
index.html
$ git commit -m ŌĆś4th commitŌĆÖ
[master 0815eb5] 4th commit
1 files changed, 1 insertions(+), 0 deletions(-)
create mode 100644 index.html
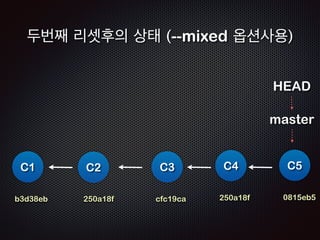
Ļ│╝ņĀĢ8 /9 - ŌĆścommitŌĆÖņØä ĒĢśļ®┤
ņāłļĪ£ņÜ┤ ņ╗żļ░ŗĻ░Øņ▓┤(C5)Ļ░Ć ļ¦īļōżņ¢┤ņ¦äļŗż!
!R
EADME
doc/
doc/index.html
!
index.html](https://image.slidesharecdn.com/track2-4-advancedgitpublic-111201004531-phpapp02/85/2011-KTH-H3-Track-B-4-Advanced-Git-by-A-J-124-320.jpg)







2011ļģä KTH H3 ņ╗©ĒŹ╝ļ¤░ņŖż Track B, ņäĖņģś4 "Advanced Git" by A.J
- 1. Advanced
- 2. ╠²Git A.J
- 4. ╠² ! @andrwj
- 5. Ļ░£ļ░£ņ×Éļź╝ ņ£äĒĢ£ Ļ│ĀĻĖē Git ĒÖ£ņÜ®ņĀäļץ - TRACK B, Session 4 ! ņäĖĻ│äņØś Ļ░£ļ░£ņ×ÉĻ░Ć 'ņĮöļō£'ļĪ£ ļīĆĒÖöĒĢśļŖö ĒÖśĻ▓Į, ļČäņé░ļ▓äņĀäĻ┤Ćļ”¼ņŗ£ņŖżĒģ£ņØĖ Git ņØä ļ®ŗņ¦ĆĻ▓ī ņé¼ņÜ®ĒĢśļŖö ļ░®ļ▓ĢņØä Ļ│Ąņ£ĀĒĢ®ļŗłļŗż. ņŗżņĀ£ņŚģļ¼┤ņÖĆ Ļ░£ņØĖņĀü Ļ░£ļ░£ņŚÉņä£ļÅä Ļ▒░ņ╣©ņŚåņØ┤ Git ņØä ņé¼ņÜ®ĒĢśļŖö ļģĖĒĢśņÜ░ļź╝ ņĢīņĢäļ┤ģļŗłļŗż.
- 7. ņäĖņģś ņÜöņĀÉ #1 Git ļ¬ģļĀ╣ņØś ļīĆļČĆļČäņØĆ File ļ│┤ļŗżļŖö Commit Ļ░Øņ▓┤ļź╝ ļŗżļŻ¼ļŗż.
- 8. ņäĖņģś ņÜöņĀÉ #2 Git ļ¬ģļĀ╣ņØä ļ│┤ļŗż ņל ņØ┤ĒĢ┤ĒĢśĻĖ░ ņ£äĒĢ┤ HEAD ņÖĆ ļĖīļ×£ņ╣śļŖö ĒżņØĖĒä░ņ×äņØä ĻĖ░ņ¢ĄĒĢśņ×É.
- 9. ļ»Ėļ”¼ ņĢīņĢäļæś Ļ▓ā #1 Javascript ļĪ£ Ēæ£ĒśäļÉśļŖö Pointer
- 10. var HEAD = ŌĆśmasterŌĆÖ; ! console.log( HEAD ); ! ŌĆśmasterŌĆÖ HEAD ļŖö ļŗ©ņł£ ļ│Ćņłś
- 11. var refs = { heads: { master: ŌĆśmasterŌĆÖ, develop: ŌĆśdevelopŌĆÖ } }; ! console.log( refs. heads. master ); ! ŌĆśmasterŌĆÖ refs.heads.master ņŚŁņŗ£ ļŗ©ņł£ ļ│Ćņłś
- 12. var refs = { heads: { master: ŌĆśmasterŌĆÖ, develop: ŌĆśdevelopŌĆÖ } }; ! HEAD = refs. heads. master; ! console.log( HEAD ); ! ŌĆśmasterŌĆÖ HEAD
- 13. ŌĆ£masterŌĆØ refs.heads.master refs. heads. master HEAD ņ░ĖņĪ░
- 14. ļ»Ėļ”¼ ņĢīņĢäļæś Ļ▓ā #2 Javascript ļĪ£ ņĢīņĢäļ│┤ļŖö HEAD ņé¼ņÜ®ņśł
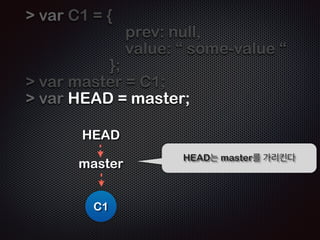
- 15. var C1 = { prev: null, value: ŌĆ£ some-value ŌĆ£ }; ! ! ! C1 Ļ░Øņ▓┤ C1ņØä ļéśĒāĆļéĖļŗż
- 16. var C1 = { prev: null, value: ŌĆ£ some-value ŌĆ£ }; ! var HEAD = C1; HEAD C1 HEADļŖö C1ņØä Ļ░Ćļ”¼Ēé©ļŗż (pointing)
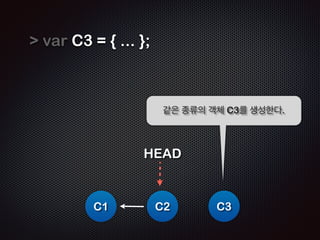
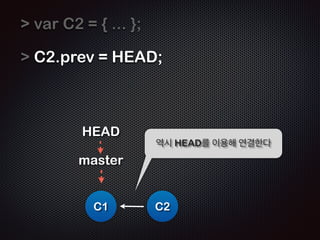
- 17. var C2 = { ... }; ! HEAD C1 Ļ░ÖņØĆ ņóģļźśņØś Ļ░Øņ▓┤ C2ļź╝ ņāØņä▒ĒĢ£ļŗż. C2
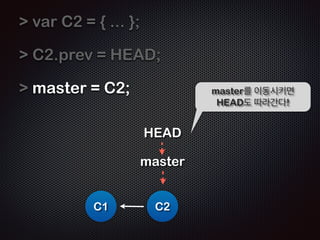
- 18. var C2 = { ... }; ! C2.prev = HEAD; ! HEAD C1 HEADļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņØ┤ņĀä Ļ░Øņ▓┤ņÖĆ ņŚ░Ļ▓░ĒĢ©ņØä ņŻ╝ņØś C2 Ļ╣ŖĻ▓ī ļ│┤ņ×É
- 19. var C2 = { ... }; ! C2.prev = HEAD; ! HEAD = C2; C1 HEAD C2 ļŗżņŗ£ HEADļź╝ ņāłļĪ£ņÜ┤ C2ļĪ£ Ļ░Ćļ”¼Ēé©ļŗż (pointing)
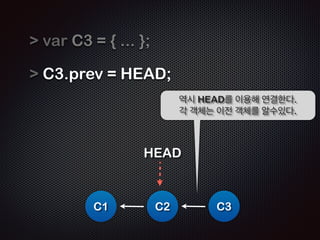
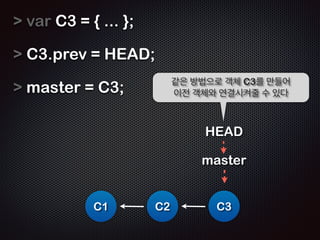
- 20. var C3 = { ... }; ! C1 Ļ░ÖņØĆ ņóģļźśņØś Ļ░Øņ▓┤ C3ļź╝ ņāØņä▒ĒĢ£ļŗż. HEAD C2 C3
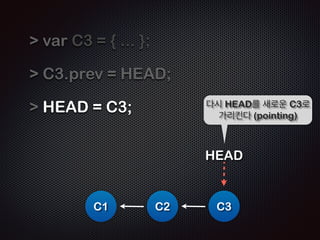
- 21. var C3 = { ... }; ! C3.prev = HEAD; ! ! C1 ņŚŁņŗ£ HEADļź╝ ņØ┤ņÜ®ĒĢ┤ ņŚ░Ļ▓░ĒĢ£ļŗż. Ļ░ü Ļ░Øņ▓┤ļŖö ņØ┤ņĀä Ļ░Øņ▓┤ļź╝ ņĢīņłśņ׳ļŗż. HEAD C2 C3
- 22. var C3 = { ... }; ! C3.prev = HEAD; ! HEAD = C3; ! C1 ļŗżņŗ£ HEADļź╝ ņāłļĪ£ņÜ┤ C3ļĪ£ Ļ░Ćļ”¼Ēé©ļŗż (pointing) HEAD C2 C3
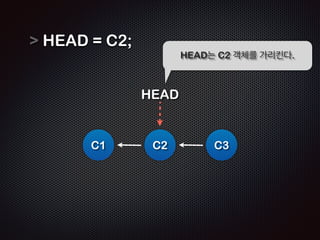
- 23. HEADļź╝ ņØ┤ļÅÖņŗ£Ēé┤ņ£╝ļĪ£ņŹ© ņ×äņØśņØś ņŚ░Ļ▓░ņØä ņ×Éņ£Ā ļĪŁĻ▓ī ļ¦īļōżņ¢┤ Ļ░ł ņłś ņ׳ņØīņØä ļ│┤ņŚ¼ņŻ╝ļŖö ņśł
- 24. HEAD = C2; C1 HEAD HEADļŖö C2 Ļ░Øņ▓┤ļź╝ Ļ░Ćļ”¼Ēé©ļŗż. C2 C3
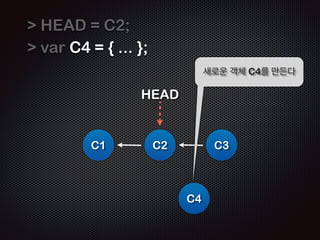
- 25. HEAD = C2; var C4 = { ... }; ! C1 HEAD C2 C3 C4 ņāłļĪ£ņÜ┤ Ļ░Øņ▓┤ C4ļź╝ ļ¦īļōĀļŗż
- 26. HEAD = C2; var C4 = { ... }; C4.prev = HEAD; C1 HEAD HEADĻ░Ć Ļ░Ćļ”¼ĒéżļŖö Ļ░Øņ▓┤ņÖĆ C2 C3 C4 ņŚ░Ļ▓░ ĒĢĀ ņłś ņ׳ļŗż. (ļĖīļ×£ņ╣śĻ░Ć Ļ║Šņ¢┤ņ¦ĆļŖö ļ¬©ņŖĄ)
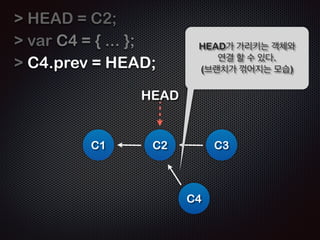
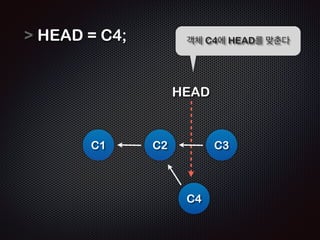
- 27. HEAD = C4; ! C1 Ļ░Øņ▓┤ C4ņŚÉ HEADļź╝ ļ¦×ņČśļŗż HEAD C2 C3 C4
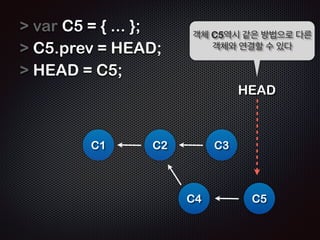
- 28. var C5 = { ... }; C5.prev = HEAD; HEAD = C5; ! Ļ░Øņ▓┤ C5ņŚŁņŗ£ Ļ░ÖņØĆ ļ░®ļ▓Ģņ£╝ļĪ£ ļŗżļźĖ Ļ░Øņ▓┤ņÖĆ ņŚ░Ļ▓░ĒĢĀ ņłś ņ׳ļŗż C1 C2 C3 HEAD C4 C5
- 29. HEADļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Ļ░ü Ļ░Øņ▓┤ļŖö ņŚ░Ļ▓░ņØä ņØ┤ņ¢┤Ļ░ł ņłś ņ׳ļŗż.
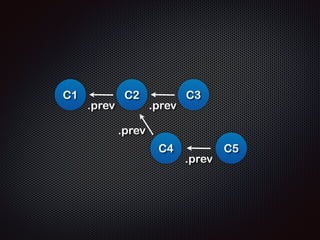
- 30. C1 C2 C3 C4 C5 .prev .prev .prev .prev
- 31. ļśÉĒĢ£, HEADĻ░Ć ņ¢┤ļööļź╝ Ļ░Ćļ”¼ĒéżļāÉņŚÉ ļö░ļØ╝ ņŚ░Ļ▓░ Ļ│╝ņĀĢņØ┤ ļŗ¼ļØ╝ ļ│┤ņØ╝ ņłś ņ׳ļŗż. ! (ļĖīļ×£ņ╣śļ¦łļŗż ņ╗żļ░ŗ ļĪ£ĻĘĖĻ░Ć ļŗ¼ļØ╝ļ│┤ņØ┤ļŖö ņØ┤ņ£Ā)
- 32. C1 C2 C3 HEAD C4 C5 .prev .prev .prev
- 33. HEAD C1 C2 C3 .prev .prev C4 C5
- 34. GitņØś Branch ņ×æļÅÖļ▓ĢļÅä ļ╣äņŖĘĒĢśĻ▓ī ņäżļ¬ģļÉĀ ņłś ņ׳ļŗż
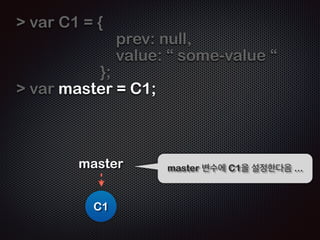
- 35. var C1 = { prev: null, value: ŌĆ£ some-value ŌĆ£ }; ! ! C1 C1ņØä ņāØņä▒ĒĢśĻ│Ā...
- 36. var C1 = { prev: null, value: ŌĆ£ some-value ŌĆ£ }; var master = C1; master master ļ│ĆņłśņŚÉ C1ņØä ņäżņĀĢĒĢ£ļŗżņØī ... C1
- 37. var C1 = { prev: null, value: ŌĆ£ some-value ŌĆ£ }; var master = C1; var HEAD = master; ! HEAD master C1 HEADļŖö masterļź╝ Ļ░Ćļ”¼Ēé©ļŗż
- 38. var C2 = { ... }; ! ! HEAD master C1 C2 C2ņØä ņāØņä▒ĒĢśĻ│Ā...
- 39. var C2 = { ... }; ! C2.prev = HEAD; ! HEAD master ņŚŁņŗ£ HEADļź╝ ņØ┤ņÜ®ĒĢ┤ ņŚ░Ļ▓░ĒĢ£ļŗż C1 C2
- 40. var C2 = { ... }; ! C2.prev = HEAD; ! master = C2; ! HEAD master C1 C2 masterļź╝ ņØ┤ļÅÖņŗ£Ēéżļ®┤ HEADļÅä ļö░ļØ╝Ļ░äļŗż!
- 41. var C3 = { ... }; ! C3.prev = HEAD; ! master = C3; Ļ░ÖņØĆ ļ░®ļ▓Ģņ£╝ļĪ£ Ļ░Øņ▓┤ C3ļź╝ ļ¦īļōżņ¢┤ ņØ┤ņĀä Ļ░Øņ▓┤ņÖĆ ņŚ░Ļ▓░ņŗ£ņ╝£ņżä ņłś ņ׳ļŗż HEAD master C1 C2 C3
- 42. ņØ┤ļ▓łņŚö ļĖīļ×£ņ╣ś ļ│Ćņłśļź╝ ļéśĒāĆļé┤ļŖö developņØä ļ¦īļōż ņ¢┤ masterņÖĆ ļŗżļźĖ Ļ░Øņ▓┤ļź╝ Ļ░Ćļ”¼Ēé©ļŗż var develop = C2; HEAD master develop C1 C2 C3
- 43. var develop = C2; var HEAD = develop; masterņØś ņ£äņ╣śļŖö ĻĘĖļīĆļĪ£ ļæÉĻ│Ā, HEADļź╝ masterļĪ£ ņØ┤ļÅÖņŗ£ņ╝£ ļŗżņØīļ▓ł Ļ░Øņ▓┤ļź╝ ņŚ░Ļ▓░ņŗ£Ēé¼ ņżĆļ╣äļź╝ ĒĢ£ļŗż. master HEAD develop C1 C2 C3
- 44. var C4 = { .. }; ! master HEAD develop C1 C2 C3 C4 C4ļź╝ ļ¦īļōżĻ│Ā..
- 45. var C4 = { .. }; C4.prev = HEAD; master HEAD develop C1 C2 C3 C4 HEADļź╝ ņØ┤ņÜ®ĒĢ┤ ņŚ░Ļ▓░ņØä ņØ┤ ņ¢┤ļéśĻ░ł ņłś ņ׳ļŗż
- 46. var C5 = { .. }; C5.prev = HEAD; develop = C5; master C1 C2 C3 HEAD develop C4 C5 Ļ│äņåŹĒĢ┤ņä£ ļŗżļźĖ ņŚ░Ļ▓░ļÅä ņØ┤ņ¢┤Ļ░ł ņłś ņ׳ļŗż.
- 47. ņØ┤ļĢī HEADļź╝ ļ│ĆĻ▓ĮĒĢ©ņ£╝ļĪ£ņŹ© ļæÉĻ░£ņØś ŌĆśņØ┤ļ”äŌĆÖ Ļ░Ćņ¦ä ņŚ░Ļ▓░ņØä ļ¦īļōż ņłś ņ׳ļŗż. ! ( Git Branch ņŚŁņŗ£ Ļ░ÖņØĆ ļ░®ņŗØņØ┤ļŗż)
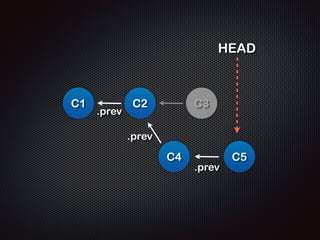
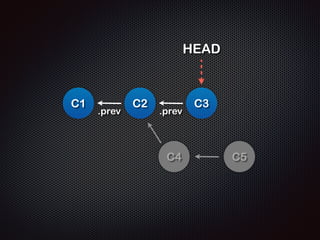
- 48. HEAD = master; HEAD master C1 C2 C3 develop C4 C5 masterļź╝ Ļ░Ćļ”¼Ēé¼ļĢīļŖö C3 - C2 - C1 ņł£ņ£╝ļĪ£ ņŚ░Ļ▓░ (history)
- 49. HEAD = develop; ! developļź╝ Ļ░Ćļ”¼Ēé¼ļĢīļŖö HEAD master C1 C2 C3 develop C4 C5 C5 - C4 - C2 - C1 ņł£ņ£╝ļĪ£ ņŚ░Ļ▓░ (history)
- 50. GitņØś HEADļŖö ļ│Ćņłśņ▓śļ¤╝ ļÅÖņ×æĒĢśļ®░ ĒŖ╣ņĀĢ ļĖīļ×£ņ╣śļź╝ Ļ░Ćļ”¼Ēé©ļŗż. ! GitņØś BranchļŖö ļ│Ćņłśņ▓śļ¤╝ ļÅÖņ×æĒĢśļ®░ ĒŖ╣ņĀĢ ņ╗żļ░ŗņØä Ļ░Ćļ”¼Ēé©ļŗż.
- 51. ļ»Ėļ”¼ ņĢīņĢäļæś Ļ▓ā #2 Git ņĀĆņןņåī ĒĢ┤ļČĆ
- 52. . ./.git ./.git/branches ./.git/config ./.git/description ./.git/HEAD ./.git/hooks ./.git/hooks/applypatch-msg.sample ./.git/hooks/commit-msg.sample ./.git/hooks/post-commit.sample ./.git/hooks/post-receive.sample ./.git/hooks/post-update.sample ./.git/hooks/pre-applypatch.sample ./.git/hooks/pre-commit.sample ./.git/hooks/pre-rebase.sample ./.git/hooks/prepare-commit-msg.sample ./.git/hooks/update.sample ./.git/info ./.git/info/exclude ./.git/objects ./.git/objects/info ./.git/objects/pack ./.git/refs ./.git/refs/heads git init ļ¬ģļĀ╣Ēøä ņāØņä▒ļÉśļŖö ĒīīņØ╝ļōż
- 53. . ./.git ./.git/branches ./.git/config ./.git/description ./.git/HEAD ./.git/hooks ./.git/hooks/applypatch-msg.sample ./.git/hooks/commit-msg.sample ./.git/hooks/post-commit.sample ./.git/hooks/post-receive.sample ./.git/hooks/post-update.sample ./.git/hooks/pre-applypatch.sample ./.git/hooks/pre-commit.sample ./.git/hooks/pre-rebase.sample ./.git/hooks/prepare-commit-msg.sample ./.git/hooks/update.sample ./.git/info ./.git/info/exclude ./.git/objects ./.git/objects/info ./.git/objects/pack ./.git/refs ./.git/refs/heads ./.git/refs/tags ņøÉĒÖ£ĒĢ£ ņäżļ¬ģņØä ņ£äĒĢ┤ ļ¼┤ņŗ£..
- 54. . ./.git ./.git/branches ./.git/config ./.git/description ./.git/HEAD ./.git/info ./.git/info/exclude ./.git/objects ./.git/objects/info ./.git/objects/pack ./.git/refs ./.git/refs/heads ./.git/refs/tags ņĢ×ņä£ Javascript ļ│ĆņłśļĪ£ ņäżļ¬ģĒĢ£ Ļ▓āļōżņØ┤ ĒīīņØ╝ļĪ£ ņĪ┤ņ×¼ĒĢ£ļŗż!
- 55. git init ļ¬ģļĀ╣ņ¦üĒøäņŚÉļŖö master ĒīīņØ╝ ļé┤ ņÜ®ņŚÉ ņĢäļ¼┤Ļ▓āļÅä ņŚåļŗż $ cat ./git/HEAD ref: refs/heads/master ! $ cat .git/refs/heads/master cat: .git/refs/heads/master: No such file or directory ! $ git branch ! $ ! ļĖīļ×£ņ╣ś ņŚŁņŗ£ ņŚåļŖö ņāüĒā£
- 56. Ļ░äļŗ©Ē׳ README ĒīīņØ╝ņØä ņāØņä▒ĒĢ£ļŗż $ echo ŌĆśjust createdŌĆÖ README ! $ ls -la total 0 drwxr-xr-x 4 andrwj staff 136 11 25 00:18 . drwxr-xr-x 3 andrwj staff 102 11 25 00:14 .. drwxr-xr-x 14 andrwj staff 476 11 26 17:21 .git -rw-r--r-- 1 andrwj staff 0 11 25 00:16 README ! $ cat README just created ! $ Ēśäņ×¼ ĒÅ┤ļŹöņŚÉļŖö READņÖĆ .git ĒÅ┤ļŹö ļ┐ÉņØ┤ļŗż
- 57. . ./.git ./.git/branches ./.git/COMMIT_EDITMSG ./.git/config ./.git/description git add README ņ¦üĒøä, ./.git/HEAD ĻĖ┤ņØ┤ļ”äņØś ĒīīņØ╝ņØ┤ ņāØĻĖ┤ļŗż ./.git/index ./.git/objects ./.git/objects/4e ./.git/objects/4e/8238248ad38d598515adb865b818ec9381f967 ./.git/objects/info ./.git/objects/pack ./.git/objects/info ./.git/objects/pack ./.git/refs ./.git/refs/heads ./.git/refs/heads/master ./.git/refs/tags ./README
- 58. $ cat .git/HEAD ! ref: refs/heads/master !! ĻĘĖļ¤¼ļéś ņŚ¼ņĀäĒ׳ master ĒīīņØ╝ņØś ļé┤ņÜ®ņØĆ ļ╣äņ¢┤ņ׳ļŗż $ cat .git/refs/heads/master cat: .git/refs/heads/master: No such file or directory !!! $ cat .git/object/4e/8238248ad38d598515adb865b818ec9381f967 ! x??Q B!??????? ??-?ied?]?? ?;03K?? @???9Cd?9%t?I???╬ē?(J+B?%e4?=n??? ??L?s?^k(?????!???zk═żs3?▀é????????/? ņāØņä▒ļÉ£ ĻĖ┤ ņØ┤ļ”äņØś ĒīīņØ╝ņØä ņČ£ļĀźĒĢ┤ļ│┤ļŗł TEXT Ēżļ¦ĘņØś ĒīīņØ╝ņØ┤ ņĢäļŗśņØä ņĢīņłśņ׳ļŗż
- 59. git blob format ĒŚżļŹö ņĀĢļ│┤ļź╝ ĒżĒĢ©ĒĢśņŚ¼ zlibļĪ£ ņĢĢņČĢļÉśņ¢┤ ņĀĆņןļÉ£ļŗż ĒŚżļŹö ĒśĢņŗØ: ŌĆ£blob ņøÉļ│ĖĒīīņØ╝Ēü¼ĻĖ░ nullŌĆØ
- 60. blob format $ cd .git/object/4e/ $ python fd = open(ŌĆ£8238248ad38d598515adb865b818ec9381f967ŌĆØ) line = fd.read() import zlib zlib.decompress(line) ŌĆśblob 13x00just creatednŌĆÖ Ļ░Øņ▓┤ ņóģļźśļŖö ŌĆśblobŌĆÖ ņøÉļ│Ė Ēü¼ĻĖ░ļŖö 13 ļ░öņØ┤ĒŖĖ null ļ░öņØ┤ĒŖĖ ņøÉļ│Ė ļé┤ņÜ®
- 61. git hash-object README $ git hash-object README 4e8238248ad38d598515adb865b818ec9381f967 ! $ git cat-file -p 4e8238 just created ĒīīņØ╝ņØ┤ļ”äņ£╝ļĪ£ ĒĢ┤ņē¼ļ¬ģņØä ņĢī ņłś ņ׳ļŗż ĒīīņØ╝ņØ┤ļ”ä ļ¬ćĻĖĆņ×ÉļĪ£ ļé┤ņÜ®ņØä ņČ£ļĀźĒĢĀ ņłś ņ׳ļŗż
- 62. why hash ? ļé┤ņÜ®ņŚÉ ļö░ļØ╝ ņżæļ│ĄļÉ£ ņØ┤ļ”äņØ┤ ļéśņś¼ Ļ░ĆļŖźņä▒ņØ┤ ĻĘ╣Ē׳ ļō£ļ¼╝ļŗż ņ£ĪņĢłņ£╝ļĪ£ ļČäļ│äĒĢśĻĖ░ ĒלļōĀ ņ░©ņØ┤ļÅä ņēĮĻ▓ī Ļ▓ĆņČ£ Ļ░ĆļŖźĒĢśļŗż ļ▓łĒśĖļĪ£ļÉ£ ĒīīņØ╝ ņØ┤ļ”äļ│┤ļŗż Ļ┤Ćļ”¼ ĒĢśĻĖ░ ņēĮļŗż(?) ĒīīņØ╝ļ¬ģņØ┤ ļ│ĆĻ▓ĮļÉśņ¢┤ļÅä ļé┤ņÜ®ņØ┤ Ļ░Öņ£╝ļ®┤ ļÅÖņØ╝ĒĢ£ Ļ▓āņ£╝ļĪ£ ņØĖņŗØĒĢ£ļŗż.
- 63. README ! ŌĆśjust createdŌĆÖ README ! ŌĆśjust created ŌĆś $ cat README ! ŌĆśjust createdŌĆÖ !! ļüØļČĆļČä Ļ│Ąļ░▒ļÅä ļ¬ģĒÖĢĒ׳ ņĢī ņłś ņ׳ļŗż $ git hash-object README ! ec53c2432a2e9c2fadaa9d5982bd3cf31f9b38d2 ! $ cat README ! ŌĆśjust created ŌĆÖ !! $ git hash-object README ! a6014d70c71eab934f3ac1248f8bad19ad3d451c !
- 64. README.1 ! ŌĆśjust createdŌĆÖ README.2 ! ŌĆśjust createdŌĆś $ cat README.1 ! ŌĆśjust createdŌĆÖ !! ļé┤ņÜ®ņØ┤ Ļ░Öņ£╝ļ®┤ ĒīīņØ╝ņØ┤ļ”äņØ┤ ļŗ¼ļØ╝ļÅä Ļ░ÖņØĆ Ļ░ÆņØä ņČ£ļĀźĒĢ£ļŗż $ git hash-object README.1 ! ec53c2432a2e9c2fadaa9d5982bd3cf31f9b38d2 ! $ cat README.2 ! ŌĆśjust createdŌĆÖ !! $ git hash-object README.2 ! ec53c2432a2e9c2fadaa9d5982bd3cf31f9b38d2 !
- 65. git use hash !
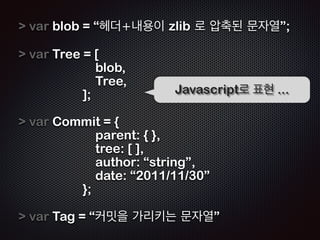
- 67. four object Blob Commit Tag Tree GitņŚÉļŖö 4Ļ░Ćņ¦Ć Ļ░Øņ▓┤Ļ░Ć ņ׳ļŗż
- 68. var blob = ŌĆ£ĒŚżļŹö+ļé┤ņÜ®ņØ┤ zlib ļĪ£ ņĢĢņČĢļÉ£ ļ¼Ėņ×ÉņŚ┤ŌĆØ; ! var Tree = [ blob, Tree, ]; ! var Commit = { JavascriptļĪ£ Ēæ£Ēśä ... parent: { }, tree: [ ], author: ŌĆ£stringŌĆØ, date: ŌĆ£2011/11/30ŌĆØ }; ! var Tag = ŌĆ£ņ╗żļ░ŗņØä Ļ░Ćļ”¼ĒéżļŖö ļ¼Ėņ×ÉņŚ┤ŌĆØ
- 69. blob object Blob header + content ! zlibļĪ£ ņĢĢņČĢļÉśņ¢┤ ņ׳ļŗż ! .git/objects/ ņĢäļל ņ׳ļŗż
- 70. tree object Tree blob + ļŗżļźĖ tree Ļ░Øņ▓┤ ! ŌĆśĒÅ┤ļŹöŌĆÖņÖĆ Ļ░ÖņØĆ Ļ░£ļģÉ ! .git/objects/ ņĢäļל ņ׳ļŗż
- 71. commit object Commit blobs + trees + author + date + message ! .git/objects/ ņĢäļל ņ׳ļŗż
- 72. tag object Tag pointer to commit object ! .git/refs/tags/ ņĢäļלņ׳ļŗż
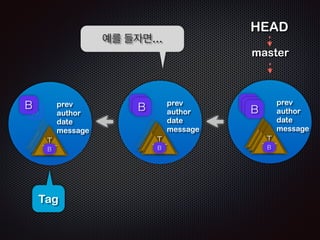
- 73. B BB T TBT T TBT T prev author date message BTT TBT Tag BBB prev author date message T TBT T TBT T TBT BBB prev author date message T TBT T TBT T TBT Tag BB BT HEAD master ņśłļź╝ ļōżņ×Éļ®┤...
- 74. ņżæĻ░ä ņĀĢļ”¼ ĒīīņØ╝ņØĆ blob Ēżļ¦Ęņ£╝ļĪ£ ņĀĆņןļÉ£ļŗż. ĒÅ┤ļŹöļŖö tree Ļ░Øņ▓┤ļĪ£, ĒīīņØ╝ņØĆ blob Ļ░Øņ▓┤ļĪ£ Ēæ£ĒśäļÉ£ļŗż. commit, tag ņŚŁņŗ£ Ļ░Øņ▓┤ļĪ£ ņĘ©ĻĖēļÉśņ¢┤ ĒīīņØ╝ĒśĢĒā£ļĪ£ ņĀĆņןļÉ£ļŗż. ļ¬©ļōĀ ĒīīņØ╝ņØĆ SHA ļ░®ņŗØņØś ĒĢ┤ņē¼ļĪ£ Ēæ£ĒśäļÉ£ļŗż. GitņØś branchņÖĆ commit ņØĆ pointer ņØ┤ļŗż.
- 75. three spaces - Working area ! - Staging or Index ! - Local Repository
- 76. but, these are just concept!!
- 77. Staging Repo ! - ņśüĻĄ¼ņĀĆņן ņśüņŚŁ - .git/object/* ! - ņ×æņŚģ ĒÅ┤ļŹö ņśüņŚŁ - ./ ! Working 3Ļ░£ņØś Ļ│ĄĻ░ä ! - ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁ - .git/index
- 78. ņ▓½ļ▓łņ¦Ė ņ╗żļ░ŗ
- 79. Repo !R Working Staging EADME $ cat ŌĆśjust createdŌĆÖ README Ļ│╝ņĀĢ1 /11 - ņ▓śņØīņ£╝ļĪ£ ņ╗żļ░ŗĒĢĀ ĒīīņØ╝ņØä ņāØņä▒
- 80. Repo !R Working Staging EADME $ cat README just created Ļ│╝ņĀĢ2 /11 - ĒīīņØ╝ ļé┤ņÜ® ļ│┤ĻĖ░
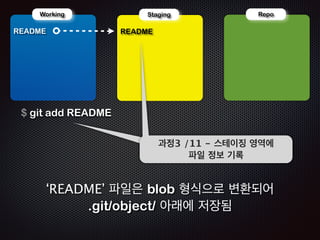
- 81. ! Repo !R Working EADME !R Staging EADME $ git add README ņŖżĻ│╝ĒģīņĀĢņØ┤3 ņ¦Ģ/1 ņśü1ņŚŁ -ņŚÉ ņŖż ĒīīĒģīņØ╝ņØ┤ ņ¦ĢņĀĢ ļ│┤ņśü ņŚŁĻĖ░ņŚÉļĪØ ĒīīņØ╝ ņĀĢļ│┤ ĻĖ░ļĪØ ŌĆśREADMEŌĆÖ ĒīīņØ╝ņØĆ blob ĒśĢņŗØņ£╝ļĪ£ ļ│ĆĒÖśļÉśņ¢┤ .git/object/ ņĢäļלņŚÉ ņĀĆņןļÉ©
- 82. ! Repo !R Working EADME !R Staging EADME $ git ls-files -s 100644 4e8238248ad38d598515adb865b818ec9381f967 0 README ! Ļ│╝ņĀĢ4 /11 - ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁņØś ĒīīņØ╝ ņĀĢļ│┤ ņŚ┤ļ×ī (.git/index ĒīīņØ╝ ļé┤ņÜ®ņØä ņ░ĖņĪ░)
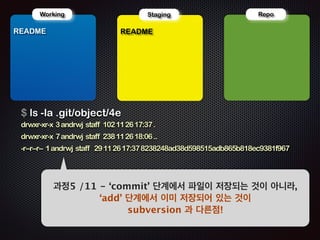
- 83. ! Repo !R Working EADME !R Staging EADME $ ls -la .git/object/4e drwxr-xr-x 3 andrwj staff 102 11 26 17:37 . drwxr-xr-x 7 andrwj staff 238 11 26 18:06 .. -r--r--r-- 1 andrwj staff 29 11 26 17:37 8238248ad38d598515adb865b818ec9381f967 Ļ│╝ņĀĢ5 /11 - ŌĆścommitŌĆÖ ļŗ©Ļ│äņŚÉņä£ ĒīīņØ╝ņØ┤ ņĀĆņןļÉśļŖö Ļ▓āņØ┤ ņĢäļŗłļØ╝, ŌĆśaddŌĆÖ ļŗ©Ļ│äņŚÉņä£ ņØ┤ļ»Ė ņĀĆņןļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØ┤ subversion Ļ│╝ ļŗżļźĖņĀÉ!
- 84. ! Repo !R Working EADME !R Staging EADME $ cat .git/index ??~?){???e?ņōü?gREADME'mh?$ Ļ│╝ņĀĢ6 /11 - .git/index ĒīīņØ╝ņØĆ TEXT ĒśĢņŗØņØś ĒīīņØ╝ņØ┤ ņĢä ļŗś.
- 85. ! ! Repo !R Working EADME !R Staging EADME $ git commit -m ŌĆśfirst commitŌĆÖ [master (root-commit) b3d38eb] first commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 README !R C1: b3d38eb EADME ! Ļ│╝ņĀĢ7 /11 - ņØ┤ļ»Ė README ņĀĆņןļÉśņ¢┤ ņ׳ņ£╝ļ»ĆļĪ£ ŌĆścommitŌĆÖ ļŗ©Ļ│äņŚÉņäĀ ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁņØś ļ”¼ņŖżĒŖĖļź╝ ņ░ĖņĪ░ ĒĢśņŚ¼ commit objectļź╝ ļ¦īļōĀļŗż
- 86. ! ! Repo !R Working EADME !R Staging EADME $ git commit -m ŌĆśfirst commitŌĆÖ [master (root-commit) b3d38eb] first commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 README !R C1: b3d38eb EADME ! Ļ│╝ņĀĢ8 /11 - ņŖżĒģīņØ┤ņ¦Ģ (.git/index) ņśüņŚŁņØś ņĀĢļ│┤ļÅä ĻĘĖļīĆļĪ£ ļé©ņĢäņ׳ļŗż!!
- 87. ! ! Repo !R Working EADME !R Staging EADME !R EADME ! $ cat .git/HEAD ref: refs/heads/master ! $ cat .git/refs/heads/master b3d38eb6591fc4737509a00471e9a64ba4f79c5c C1: b3d38eb Ļ│╝ņĀĢ9 /11 - ņØ┤ņĀ£ ŌĆśmasterŌĆÖ ļĖīļ×£ņ╣śļŖö ņāłļĪ£ņÜ┤ ņ╗żļ░ŗņØä Ļ░Ćļ”¼Ēé©ļŗż
- 88. ! ! Repo !R Working EADME !R Staging EADME !R C1: b3d38eb EADME ! $ git cat-file -p b3d38eb6591fc4737509a00471e9a64ba4f79c5c tree b529edd1315d7d85716378eb7829ba0772542851 author AJ andrwj@gmail.com 1322298365 +0900 committer AJ andrwj@gmail.com 1322298365 +0900 Ļ│╝ņĀĢ10 /11 - ņ╗żļ░ŗĻ░Øņ▓┤(ĒīīņØ╝)ņØś ļé┤ņÜ®ņØä ņČ£ļĀźĒĢ┤ļ│┤ļ®┤ tree Ļ░Øņ▓┤ņÖĆ ņ╗żļ░ŗĒĢ£ ņé¼ņÜ®ņ×ÉņÖĆ ļéĀņ¦£ ļ░Å ņ╗żļ░ŗ ļ®öņäĖņ¦Ćļź╝ ļ│╝ ņłś ņ׳ļŗż.
- 89. ! ! Repo !R Working EADME !R Staging EADME !R C1: b3d38eb EADME ! $ file . -name ŌĆś*d38eb6591fc4737509a00471e9a64ba4f79c5cŌĆÖ ./.git/objects/b3/d38eb6591fc4737509a00471e9a64ba4f79c5c Ļ│╝ņĀĢ11 /11 - ņ╗żļ░ŗĻ░Øņ▓┤(ĒīīņØ╝) ņŚŁņŗ£ .git/objects/ ĒÅ┤ļŹö ņĢäļלņŚÉ ņ׳ļŗż.
- 90. HEAD master C1 b3d38eb ņ▓½ļ▓łņ¦Ė ņ╗żļ░ŗĒøäņØś ņāüĒā£
- 91. when you ŌĆścommitŌĆÖ - youŌĆÖre making a snapshot
- 92. ļæÉļ▓łņ¦Ė ņ╗żļ░ŗ
- 93. ! ! Repo !R Working EADME doc/ doc/index.html !R Staging EADME $ mkdir doc $ echo ŌĆśindex fileŌĆÖ ./doc/index.html !R C1: b3d38eb EADME ! Ļ│╝ņĀĢ1 /5 - ĒÅ┤ļŹö(doc/)ņÖĆ ĒīīņØ╝(index.html)ņØä ņāłļĪ£ ļ¦īļōĀļŗż
- 94. ! ! Repo !R Working EADME doc/ doc/index.html !R Staging EADME $ mkdir doc $ echo ŌĆśindex fileŌĆÖ ./doc/index.html !R C1: b3d38eb EADME ! Ļ│╝ņĀĢ2 /5 - ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁņØś ļŹ░ņØ┤Ēä░ļŖö ĻĘĖļīĆļĪ£ ļé©ņĢäņ׳ļŗż
- 95. ! ! Repo !R Working EADME doc/ doc/index.html !R Staging EADME doc/ doc/index.html $ git add doc !R C1: b3d38eb EADME ! Ļ│╝ņĀĢ3 /5 - ņŖżĒģīņØ┤ņ¦Ģ(.git/index) ņśüņŚŁņŚÉ ĒīīņØ╝ ņĀĢļ│┤ļź╝ ņČöĻ░ĆĒĢ£ļŗż
- 96. ! ! Repo !R Working EADME doc/ doc/index.html !R Staging EADME doc/ doc/index.html !R C1: b3d38eb EADME ! $ find .git/object/ ./.git/objects/4e/8238248ad38d598515adb865b818ec9381f967 ./.git/objects/b3/d38eb6591fc4737509a00471e9a64ba4f79c5c ./.git/objects/b5/29edd1315d7d85716378eb7829ba0772542851 ./.git/objects/c3/d940db4a30ccfdaa29ffa322dc080b8a193734 Ļ│╝ņĀĢ4 /5 - ĒīīņØ╝ņØĆ .git/objects/ ņĢäļלņŚÉ blob/tree Ļ░Øņ▓┤ļĪ£ ļ¦īļōżņ¢┤ņ¦äļŗż
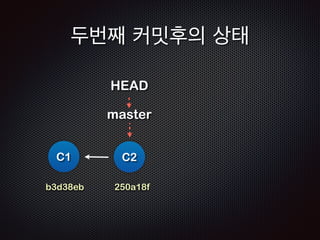
- 97. ! ! Repo !R Working EADME doc/ doc/index.html !R Staging EADME doc/ doc/index.html !R C2: 250a18f EADME ! $ git commit -m ŌĆśsecond commitŌĆÖ [master 250a18f] second commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 doc/index.html ! C1: b3d38eb !R EADME doc/ doc/index.html Ļ│╝ņĀĢ5 /5 - ņāłļĪ£ņÜ┤ ņ╗żļ░ŗ(ļ”¼ņŖżĒŖĖ)ĒīīņØ╝ņØ┤ ļ¦īļōżņ¢┤ņ¦ĆĻ│Ā HEADļŖö ņØ┤ ņ╗żļ░ŗ(C2)ņØä Ļ░Ćļ”¼Ēé©ļŗż
- 98. ļæÉļ▓łņ¦Ė ņ╗żļ░ŗĒøäņØś ņāüĒā£ C1 b3d38eb HEAD master C2 250a18f
- 99. ņäĖļ▓łņ¦Ė ņ╗żļ░ŗ
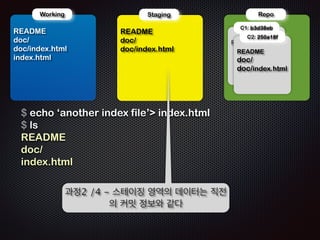
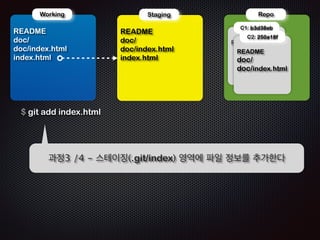
- 100. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html $ echo ŌĆśanother index fileŌĆÖ index.html $ ls README doc/ index.html ! ! !R C1: b3d38eb C2: 250a18f EADME ! !R EADME doc/ doc/index.html Ļ│╝ņĀĢ1 /4 - ņ×æņŚģĒÅ┤ļŹö ņĄ£ņāüņ£äņŚÉ ĒīīņØ╝(index.html)ņØä ņāłļĪ£ ļ¦īļōĀļŗż
- 101. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html $ echo ŌĆśanother index fileŌĆÖ index.html $ ls README doc/ index.html ! ! !R C1: b3d38eb C2: 250a18f EADME ! !R EADME doc/ doc/index.html Ļ│╝ņĀĢ2 /4 - ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁņØś ļŹ░ņØ┤Ēä░ļŖö ņ¦üņĀä ņØś ņ╗żļ░ŗ ņĀĢļ│┤ņÖĆ Ļ░Öļŗż
- 102. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ git add index.html ! !R C1: b3d38eb C2: 250a18f EADME ! !R EADME doc/ doc/index.html Ļ│╝ņĀĢ3 /4 - ņŖżĒģīņØ┤ņ¦Ģ(.git/index) ņśüņŚŁņŚÉ ĒīīņØ╝ ņĀĢļ│┤ļź╝ ņČöĻ░ĆĒĢ£ļŗż
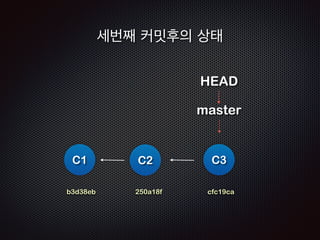
- 103. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ git commit -m ŌĆśthird commitŌĆÖ [master cfc19ca] third commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 index.html !R C1: b3d38eb C2: 250a18f EADME ! !R !R C3:cfc19ca EADME doc/ doc/index.html EADME doc/ doc/index.html index.html Ļ│╝ņĀĢ4 /4 - ņāłļĪ£ņÜ┤ ņ╗żļ░ŗ(ļ”¼ņŖżĒŖĖ)ĒīīņØ╝ņØ┤ ļ¦īļōżņ¢┤ņ¦ĆĻ│Ā HEADļŖö ņØ┤ ņ╗żļ░ŗ(C3)ņØä Ļ░Ćļ”¼Ēé©ļŗż
- 104. C1 b3d38eb ņäĖļ▓łņ¦Ė ņ╗żļ░ŗĒøäņØś ņāüĒā£ C2 HEAD master 250a18f C3 cfc19ca
- 105. ņ▓½ļ▓łņ¦Ė ļ”¼ņģŗ: --soft ņśĄņģś
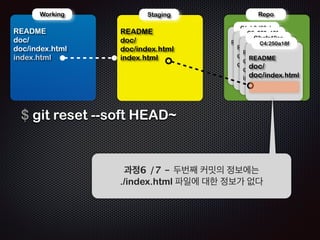
- 106. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R EADME doc/ doc/index.html EADME doc/ doc/index.html index.html $ git reflog cfc19ca HEAD@{0}: commit: third commit 250a18f HEAD@{1}: commit: second commit b3d38eb HEAD@{2}: commit (initial): first commit ! Ļ│╝ņĀĢ1 /7 - ņ¦ĆĻĖłĻ╣īņ¦Ć ļ¬©ļæÉ ņäĖĻ░£ņØś ņ╗żļ░ŗņØä ĒĢśņśĆļŗż
- 107. Working Ļ│╝ņĀĢ ! ! Repo !R EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R EADME doc/ doc/index.html EADME doc/ doc/index.html index.html $ git reflog cfc19ca HEAD@{0}: commit: third commit 250a18f HEAD@{1}: commit: second commit b3d38eb HEAD@{2}: commit (initial): first commit ! Ļ│╝Ļ│╝ņĀĢņĀĢ2 /7 - ņäĖ ņśüņŚŁļ¬©ļæÉ ļ”¼ņŖżĒŖĖ ņĀĢļ│┤Ļ░Ć ņØ╝ņ╣śĒĢ£ļŗż
- 108. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ git reset --soft HEAD~ !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R EADME doc/ doc/index.html EADME doc/ doc/index.html index.html Ļ│╝ņĀĢ3 /7 - HEADļź╝ ļæÉļ▓łņ¦Ė ņ╗żļ░ŗ(C2)ļĪ£ ņś«ĻĖ┤ļŗż
- 109. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R C4:250a18f EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reset --soft HEAD~ Ļ│╝ņĀĢ3 /7 - HEADļź╝ ņś«Ļ▓╝ļŗżļŖö ņĀĢļ│┤ļź╝ ļŗ┤ņØĆ ņāłļĪ£ņÜ┤ ņ╗żļ░ŗņØĖ C4Ļ░Ć ņāØņä▒ļÉ£ļŗż. ĒĢśņ¦Ćļ¦ī, ļæÉļ▓łņ¦Ė ņ╗żļ░ŗņØś ņĀĢļ│┤ņÖĆ Ļ░Öļŗż!
- 110. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R C4:250a18f EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reflog 250a18f HEAD@{0}: HEAD~: updating HEAD cfc19ca HEAD@{1}: commit: third commit 250a18f HEAD@{2}: commit: second commit b3d38eb HEAD@{3}: commit (initial): first commit Ļ│╝ņĀĢ5 /7 - reflogļź╝ ĒåĄĒĢ┤ ĒÖĢņØĖ!
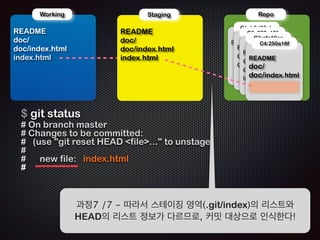
- 111. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reset --soft HEAD~ Ļ│╝ņĀĢ6 /7 - ļæÉļ▓łņ¦Ė ņ╗żļ░ŗņØś ņĀĢļ│┤ņŚÉļŖö ./index.html ĒīīņØ╝ņŚÉ ļīĆĒĢ£ ņĀĢļ│┤Ļ░Ć ņŚåļŗż
- 112. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ git status # On branch master # Changes to be committed: # (use git reset HEAD file... to unstage) # # new file: index.html # !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html Ļ│╝ņĀĢ7 /7 - ļö░ļØ╝ņä£ ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁ(.git/index)ņØś ļ”¼ņŖżĒŖĖņÖĆ HEADņØś ļ”¼ņŖżĒŖĖ ņĀĢļ│┤Ļ░Ć ļŗżļź┤ļ»ĆļĪ£, ņ╗żļ░ŗ ļīĆņāüņ£╝ļĪ£ ņØĖņŗØĒĢ£ļŗż!
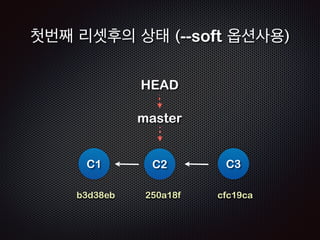
- 113. ņ▓½ļ▓łņ¦Ė ļ”¼ņģŗĒøäņØś ņāüĒā£ (--soft ņśĄņģśņé¼ņÜ®) C1 b3d38eb HEAD C2 250a18f C3 cfc19ca master
- 114. git reset --soft Local RepositoryņØś HEAD ņĀĢļ│┤ļź╝ ņ¦ĆņĀĢļÉ£ ņ£äņ╣śļĪ£ ņś«ĻĖ┤ļŗż. Staging ņśüņŚŁļ░Å Working ņśüņŚŁņØĆ ņśüĒ¢źņØä ļ░øņ¦Ć ņĢŖļŖöļŗż.
- 115. ļæÉļ▓łņ¦Ė ļ”¼ņģŗ: --mixed ņśĄņģś
- 116. ņ▓½ļ▓łņ¦Ė ļ”¼ņģŗĻ│╝ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ņäĖļ▓łņ¦Ė ņ╗żļ░ŗ (C3)ņŚÉņä£ ļŗżņŗ£ ņŗ£ņ×æĒĢ£ļŗż
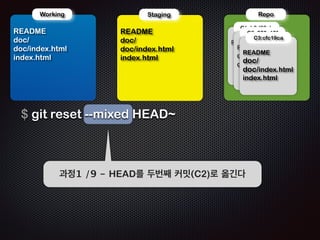
- 117. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ git reset --mixed HEAD~ !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R EADME doc/ doc/index.html EADME doc/ doc/index.html index.html Ļ│╝ņĀĢ1 /9 - HEADļź╝ ļæÉļ▓łņ¦Ė ņ╗żļ░ŗ(C2)ļĪ£ ņś«ĻĖ┤ļŗż
- 118. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R C4:250a18f EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reset --mixed HEAD~ Ļ│╝ņĀĢ2 /9 - HEADļź╝ ņś«Ļ▓╝ļŗżļŖö ņĀĢļ│┤ļź╝ ļŗ┤ņØĆ ņāłļĪ£ņÜ┤ ņ╗żļ░ŗņØĖ C4Ļ░Ć ņāØņä▒ļÉ£ļŗż. ņŚŁņŗ£, ļæÉļ▓łņ¦Ė ņ╗żļ░ŗņØś ņĀĢļ│┤ņÖĆ Ļ░Öļŗż!
- 119. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca EADME ! !R C4:250a18f EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reflog 250a18f HEAD@{0}: HEAD~: updating HEAD cfc19ca HEAD@{1}: commit: third commit 250a18f HEAD@{2}: commit: second commit b3d38eb HEAD@{3}: commit (initial): first commit Ļ│╝ņĀĢ3 /9 - reflogļź╝ ĒåĄĒĢ┤ ĒÖĢņØĖ!
- 120. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reset --mixed HEAD~ Ļ│╝ņĀĢ4 /9 - Local RepositoryņØś HEADļź╝ C2ļĪ£ ņś«ĻĖ░ļ®┤ ./index.html ĒīīņØ╝ņŚÉ ļīĆĒĢ£ ņĀĢļ│┤Ļ░Ć ņŚåļŗż
- 121. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git reset --mixed HEAD~ Ļ│╝ņĀĢ5 /9 - --mixed ņśĄņģśņØĆ Staging ņśüņŚŁņØś ņĀĢļ│┤ļź╝ Local RepositoryņØś HEADļé┤ņÜ®ņ£╝ļĪ£ Ļ░▒ņŗĀĒĢ£ļŗż! ! Staging ņĀĢļ│┤ļŖö HEADņÖĆ Ļ░ÖņĢäņ¦äļŗż!
- 122. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html $ git status # On branch master # Untracked files: # (use git add file... to include in what will be committed) # # index.html nothing added to commit but untracked files present (use git add to track) Ļ│╝ņĀĢ6 /9 - ļö░ļØ╝ņä£ Working ņśüņŚŁĻ│╝ ņŖżĒģīņØ┤ņ¦Ģ ņśüņŚŁ (.git/index)ņØś ļ”¼ņŖżĒŖĖņĀĢļ│┤Ļ░Ć ļŗżļź┤ļ»ĆļĪ£, ņČöĻ░Ć ļīĆņāüņ£╝ļĪ£ ņØĖņŗØĒĢ£ļŗż!
- 123. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html $ git add index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R EADME doc/ doc/index.html index.html EADME doc/ doc/index.html index.html Ļ│╝ņĀĢ7 /9 - ļ¦īņĢĮ ņŚ¼ĻĖ░ņä£ git add ļ¬ģļĀ╣ņØä ĒåĄĒĢ┤ Staging ņśüņŚŁņŚÉ ņĀĢ ļ│┤ļź╝ ņČöĻ░ĆĒĢśĻ│Ā ..
- 124. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R C5:0815eb5 EADME doc/ doc/index.html index.html EADME doc/ doc/index.html index.html $ git commit -m ŌĆś4th commitŌĆÖ [master 0815eb5] 4th commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 index.html Ļ│╝ņĀĢ8 /9 - ŌĆścommitŌĆÖņØä ĒĢśļ®┤ ņāłļĪ£ņÜ┤ ņ╗żļ░ŗĻ░Øņ▓┤(C5)Ļ░Ć ļ¦īļōżņ¢┤ņ¦äļŗż! !R EADME doc/ doc/index.html ! index.html
- 125. !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html ! ! Repo !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4:250a18f EADME ! !R EADME doc/ doc/index.html !R C5:0815eb5 EADME doc/ doc/index.html index.html !R EADME doc/ doc/index.html EADME doc/ doc/index.html index.html $ git reflog 0815eb5 HEAD@{0}: commit: 4th commit 250a18f HEAD@{1}: HEAD~: updating HEAD cfc19ca HEAD@{2}: commit: third commit 250a18f HEAD@{3}: commit: second commit b3d38eb HEAD@{4}: commit (initial): first commit Ļ│╝ņĀĢ9 /9 - ŌĆśreflogŌĆÖ ļĪ£ ĻĖ░ļĪØņØä ņé┤ĒÄ┤ļ│Ėļŗż
- 126. ļæÉļ▓łņ¦Ė ļ”¼ņģŗĒøäņØś ņāüĒā£ (--mixed ņśĄņģśņé¼ņÜ®) C1 b3d38eb C2 HEAD 250a18f C3 cfc19ca master C4 250a18f C5 0815eb5
- 127. git reset --mixed Local RepositoryņØś HEAD ņĀĢļ│┤ļź╝ ņ¦ĆņĀĢļÉ£ ņ£äņ╣śļĪ£ ņś«ĻĖ┤ļŗż. Staging ņśüņŚŁņŚÉ HEAD ņĀĢļ│┤ļź╝ ļ│Ąņé¼ĒĢ£ļŗż. Working ņśüņŚŁņØĆ ņśüĒ¢źņØä ļ░øņ¦Ć ņĢŖļŖöļŗż
- 128. ņäĖļ▓łņ¦Ė ļ”¼ņģŗ: --hard ņśĄņģś
- 129. ļŗżļźĖ ļ”¼ņģŗĻ│╝ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ņäĖļ▓łņ¦Ė ņ╗żļ░ŗ (C3)ņŚÉņä£ ļŗżņŗ£ ņŗ£ņ×æĒĢ£ļŗż
- 130. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C3:cfc19ca EADME ! EADME doc/ doc/index.html $ git reset --hard b3d38eb HEAD is now at b3d38eb first commit C2: 250a18f !R EADME doc/ doc/index.html index.html Ļ│╝ņĀĢ1 /5 - HEADļź╝ ņ▓½ļ▓łņ¦Ė ņ╗żļ░ŗ(C1)ļĪ£ ņś«ĻĖ┤ļŗż
- 131. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4: b3d38eb EADME ! !R EADME doc/ doc/index.html !R EADME EADME doc/ ! doc/index.html index.html $ git reset --hard b3d38eb HEAD is now at b3d38eb first commit Ļ│╝ņĀĢ1 /5 - Local RepositoryņØś HEADļź╝ ņ▓½ļ▓łņ¦Ė ņ╗żļ░ŗ(C1)ļĪ£ ņś«ĻĖ┤ļŗż
- 132. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4: b3d38eb EADME ! !R EADME doc/ doc/index.html !R EADME EADME doc/ ! doc/index.html index.html $ git reset --hard b3d38eb HEAD is now at b3d38eb first commit Ļ│╝ņĀĢ1 /5 - LocalStaging ņśüņŚŁņØś ņĀĢļ│┤Ļ░Ć HEADņÖĆ Ļ░ÖņĢäņ¦äļŗż! ļö░ļØ╝ņä£, doc/, doc/index.html ņĀĢļ│┤ļŖö ņŚåņ¢┤ņ¦äļŗż.
- 133. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4: b3d38eb EADME ! !R EADME doc/ doc/index.html !R EADME EADME doc/ ! doc/index.html index.html $ git reset --hard b3d38eb HEAD is now at b3d38eb first commit Ļ│╝ņĀĢ1 /5 - Staging ņśüņŚŁņØś ņĀĢļ│┤ņŚÉ ļö░ļØ╝ Working FolderņØś ĒīīņØ╝ņØä ņéŁņĀ£ĒĢśĻ▒░ļéś ņāØņä▒ĒĢ£ļŗż. ļö░ļØ╝ņä£, doc/, doc/index.html ĒīīņØ╝ņØĆ ņéŁņĀ£ļÉ£ļŗż!
- 134. ! ! Repo !R Working EADME doc/ doc/index.html index.html !R Staging EADME doc/ doc/index.html index.html $ ls README !R C1: b3d38eb !R C2: 250a18f C3:cfc19ca C4: b3d38eb EADME ! !R EADME doc/ doc/index.html !R EADME EADME doc/ ! doc/index.html index.html Ļ│╝ņĀĢ1 /5 - Working FolderņØś ļé┤ņÜ®ņØä ĒÖĢņØĖĒĢ┤ļ│┤ļ®┤ README ĒīīņØ╝ļ░¢ņŚÉ ņŚåļŗż!
- 135. ņäĖļ▓łņ¦Ė ļ”¼ņģŗĒøäņØś ņāüĒā£ (--hard ņśĄņģśņé¼ņÜ®) C1 b3d38eb C2 HEAD 250a18f C3 cfc19ca master C4 b3d38eb
- 136. git reset --hard Local RepositoryņØś HEAD ņĀĢļ│┤ļź╝ ņ¦ĆņĀĢļÉ£ ņ£äņ╣śļĪ£ ņś«ĻĖ┤ļŗż. Staging ņśüņŚŁņŚÉ HEAD ņĀĢļ│┤ļź╝ ļ│Ąņé¼ĒĢ£ļŗż. Staging ņśüņŚŁņØś ņĀĢļ│┤ņŚÉ ļö░ļØ╝ Working folder ņśüņŚŁņØś ĒīīņØ╝ņØä ņéŁņĀ£ĒĢśĻ▒░ļéś ņāłļĪ£ ļ¦īļōĀļŗż.
- 137. conclusion Git ļ¬ģļĀ╣ņØĆ Commit Ļ░Øņ▓┤ļź╝ ņĪ░ņ×æĒĢ£ļŗż. HEADņÖĆ ļĖīļ×£ņ╣śļŖö Pointer ļŗż.
- 138. http://andrwj.com/
- 139. composited by A.J @andrwj 2011.12.22 v1.0