









![MapReduce
- MapReduce job 은 대용량의 입력 데이터 세트를 여러 덩어리들로 나누고, 해당 덩어리들
을 병렬적으로 "Map" 를 통해 처리, Job 의 입력은 입력 스플릿이라고 부르는 고정된 크기
의 조각으로 나눈다
- Map 의 결과물을 Reduce 태스크로 전달하여 처리
- Combiner 를 사용하여 Reduce 로 보내는 데이터를 줄임 (네트워크 대역폭 고려)
년도별 특정 달의 평균 기온 정보
(2000, 20)
(2000, 30)
(2000, 10)
--------------
(2000, 5)
(2000, 22)
(2000, 20
가장 더운 달의 기온은?
Map 수행 결과 :
(2000, [20,30,10])
(2000, [5,22,20])
미리 최고 기온 계산 (combiner)
(2000, 30), (2000, 22) -> (2000, [30,20])
13년 2월 2일 토요일](https://image.slidesharecdn.com/hadoopjnsbookconcert-150402044817-conversion-gate01/85/2013-02-02-17-320.jpg)















2013.02.02 지앤선 테크니컬 세미나 - 하둡으로 배우는 대용량 데이터 분산처리 기술(이현남)
- 1. Distributed Programming Framework 13년 2월 2일 토요일
- 2. Who am I? 13년 2월 2일 토요일
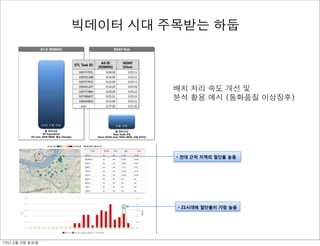
- 3. Windows에서 사용가능한 Hadoop 발표 (Microsoft HDInsight Server), 이미 Azure 에서 사용 가능 빅데이터 시대 주목받는 하둡 네이버 라인, NoSQL 로 구성 (Redis -> HBASE 로 마이그레이션) 13년 2월 2일 토요일
- 4. 배치 처리 속도 개선 및 분석 활용 예시 (통화품질 이상징후) 빅데이터 시대 주목받는 하둡 13년 2월 2일 토요일
- 5. splunk : 모든 로그 데이터(방화벽,IDS/ IPS, 서버, OS, DB, 웹로그, WAS로그, 어 플리케이션 로그 등등)를 수집/저장하여 손쉽게 검색 및 분석 빅데이터 시대 주목받는 하둡 13년 2월 2일 토요일
- 6. 구글에게 물어봐? Google Trend 13년 2월 2일 토요일
- 7. - About Hadoop - Hadoop Components - MapReduce - 하둡 관련 프로젝트 - Case studies 13년 2월 2일 토요일
- 8. what is hadoop? “Flexible and available architecture for large scale computation and data processing on a network of commodity hardware” opensource + commodity hardware = IT costs reduction 13년 2월 2일 토요일
- 9. History of hadoop - 오픈소스 자바 검색엔진 Lucene, Nutch 프로젝트 후속으로 만든 오픈소스 분산처리 플랫폼 cf) Hadoop 이름은 더그커팅의 아들이 가지고 올던 노란 코끼리 - 야후는 2006 년에 더그를 채용했고, Hadoop 을 오픈소스 프로젝트 로 Start 함. 2년 후 Apache Top Level 프로젝트가 됨 - Hadoop running on a 10,000+ core Linux cluster 13년 2월 2일 토요일
- 10. what is hadoop? - Yahoo, Facebook,Twitter... Scaling Challenges - Accessible / Robust / Simple / Scalable - High-end Machine vs Cluster of Commodity Machines - SETI@home : move data between client and server - Hadoop : move-code-to-data philosophy - RDB vs Hadoop : Scale-up / Table vs Key-Value / Online, Offline 13년 2월 2일 토요일
- 11. hadoop components HDFS (Hadoop Distributed File System) MapReduce (Job Sche. / Task Exec.) Hbase Pig Hive Sqoop ETL BI Report RDBMS ETL(Extract, Transform, Load) 13년 2월 2일 토요일
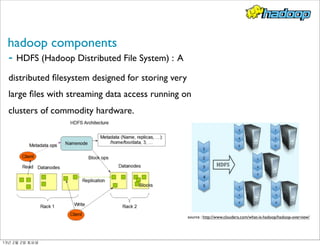
- 12. hadoop components - HDFS (Hadoop Distributed File System) : A distributed filesystem designed for storing very large files with streaming data access running on clusters of commodity hardware. source : http://www.cloudera.com/what-is-hadoop/hadoop-overview/ 13년 2월 2일 토요일
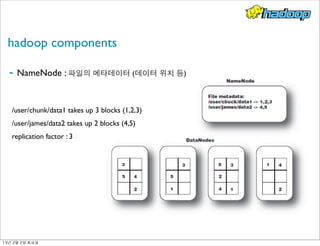
- 13. hadoop components ! - NameNode : 파일의 메타데이터 (데이터 위치 등) /user/chunk/data1 takes up 3 blocks (1,2,3) /user/james/data2 takes up 2 blocks (4,5) replication factor : 3 13년 2월 2일 토요일
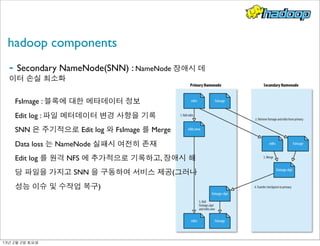
- 14. hadoop components - Secondary NameNode(SNN) : NameNode 장애시 데 이터 손실 최소화 FsImage : 블록에 대한 메타데이터 정보 Edit log : 파일 메터데이터 변경 사항을 기록 SNN 은 주기적으로 Edit log 와 FsImage 를 Merge Data loss 는 NameNode 실패시 여전히 존재 Edit log 를 원격 NFS 에 추가적으로 기록하고, 장애시 해 당 파일을 가지고 SNN 을 구동하여 서비스 제공(그러나 성능 이슈 및 수작업 복구) 13년 2월 2일 토요일
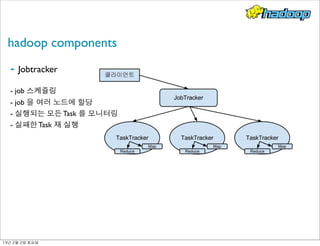
- 15. hadoop components - Jobtracker - job 스케쥴링 - job 을 여러 노드에 할당 - 실행되는 모든 Task 를 모니터링 - 실패한 Task 재 실행 13년 2월 2일 토요일
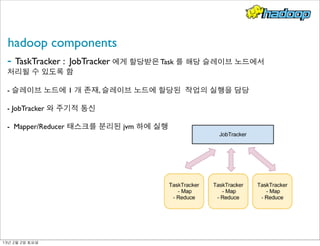
- 16. hadoop components - TaskTracker : JobTracker 에게 할당받은 Task 를 해당 슬레이브 노드에서 처리될 수 있도록 함 - 슬레이브 노드에 1 개 존재, 슬레이브 노드에 할당된 작업의 실행을 담당 - JobTracker 와 주기적 통신 - Mapper/Reducer 태스크를 분리된 jvm 하에 실행 13년 2월 2일 토요일
- 17. MapReduce - MapReduce job 은 대용량의 입력 데이터 세트를 여러 덩어리들로 나누고, 해당 덩어리들 을 병렬적으로 "Map" 를 통해 처리, Job 의 입력은 입력 스플릿이라고 부르는 고정된 크기 의 조각으로 나눈다 - Map 의 결과물을 Reduce 태스크로 전달하여 처리 - Combiner 를 사용하여 Reduce 로 보내는 데이터를 줄임 (네트워크 대역폭 고려) 년도별 특정 달의 평균 기온 정보 (2000, 20) (2000, 30) (2000, 10) -------------- (2000, 5) (2000, 22) (2000, 20 가장 더운 달의 기온은? Map 수행 결과 : (2000, [20,30,10]) (2000, [5,22,20]) 미리 최고 기온 계산 (combiner) (2000, 30), (2000, 22) -> (2000, [30,20]) 13년 2월 2일 토요일
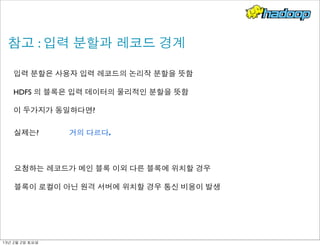
- 18. 참고 : 입력 분할과 레코드 경계 입력 분할은 사용자 입력 레코드의 논리작 분할을 뜻함 HDFS 의 블록은 입력 데이터의 물리적인 분할을 뜻함 이 두가지가 동일하다면? 실제는? 요청하는 레코드가 메인 블록 이외 다른 블록에 위치할 경우 블록이 로컬이 아닌 원격 서버에 위치할 경우 통신 비용이 발생 거의 다르다. 13년 2월 2일 토요일
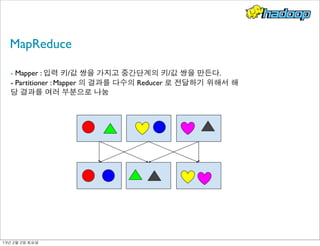
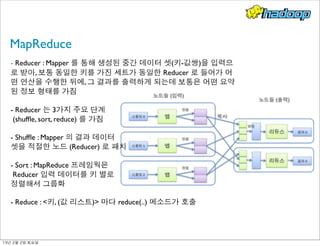
- 19. MapReduce - Mapper : 입력 키/값 쌍을 가지고 중간단계의 키/값 쌍을 만든다. - Partitioner : Mapper 의 결과를 다수의 Reducer 로 전달하기 위해서 해 당 결과를 여러 부분으로 나눔 13년 2월 2일 토요일
- 20. MapReduce - Reducer : Mapper 를 통해 생성된 중간 데이터 셋(키-값쌍)을 입력으 로 받아, 보통 동일한 키를 가진 세트가 동일한 Reducer 로 들어가 어 떤 연산을 수행한 뒤에, 그 결과를 출력하게 되는데 보통은 어떤 요약 된 정보 형태를 가짐 - Reducer 는 3가지 주요 단계 (shuffle, sort, reduce) 를 가짐 - Shuffle : Mapper 의 결과 데이터 셋을 적절한 노드 (Reducer) 로 패치 - Sort : MapReduce 프레임웍은 Reducer 입력 데이터를 키 별로 정렬해서 그룹화 - Reduce : <키, (값 리스트)> 마다 reduce(..) 메소드가 호출 13년 2월 2일 토요일
- 21. word counting 예제 - 단어세기에 포함시키지 않을 패턴(ex: tomato) 을 파일에 에 등록 - 대소문자 구분할지 여부 설정 참고 : http://blog.eduby.me/2012/05/mapreduce-8-wordcount2.html apple
- 22. ��orange
- 23. ��apple
- 24. ��banana
- 25. ��mango banana
- 26. ��mango
- 27. ��mango
- 28. ��tomato
- 29. ��tomato
- 30. �� orange
- 31. ��tomato
- 32. ��tomato
- 33. ��mango
- 34. ��apple
- 35. �� 입력 분할 apple
- 36. ��1 orange
- 37. ��1 apple
- 38. ��1 banana
- 39. ��1 mango
- 40. ��1 map banana
- 41. ��1 mango
- 42. ��1 mango
- 43. ��1 orange
- 44. ��1 mango
- 45. ��1 apple
- 46. ��1 apple
- 47. ��[1,
- 48. ��1,
- 49. ��1] banana
- 50. ��[1,
- 51. ��1] mango
- 54. ��3 banana
- 55. ��2 mango
- 56. ��4 orange
- 57. ��2 13년 2월 2일 토요일
- 59. ��다른
- 60. ��언어를
- 61. ��사용해서
- 62. ��Map/Reduce
- 63. ��프로그램을
- 64. ��작성할
- 65. ��수
- 66. ��있다. -
- 67. ��지정된
- 68. ��파일을
- 69. ��명렁어
- 70. ��라인에서
- 71. ��실행하게
- 72. ��된다. -
- 73. ��결과값은
- 74. ��파이프라인을
- 75. ��통해
- 77. Hadoop 관련 프로젝트 13년 2월 2일 토요일
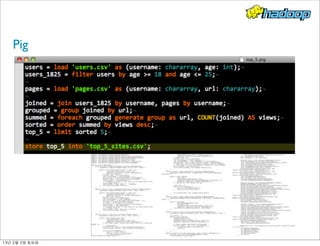
- 78. Pig MapReduce - 하나의 입력, 두 단계의 데이터 처리 흐름 - 조인 : 코드 길어지고, 에러 발생하기 쉬움 - N 단계의 job 들은 관리하기 어렵다. - Java 는 컴파일이 필요 - 프로그래밍 하기가 어렵다. - High-level 언어 - 프로그램을 간단히 -Yahoo, Hadoop job 의 40% Pig 로 처리 - Pig Latin 스크립트, 컴파일러가 자동으로 최적화 수행 - 관계형 데이터 처리 스타일의 오퍼레이션(filter, union, group, join)을 지원 13년 2월 2일 토요일
- 79. Pig 13년 2월 2일 토요일
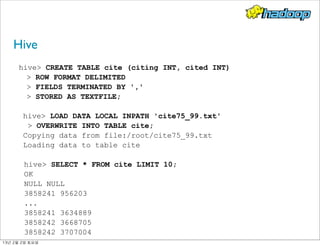
- 80. Hive - 데이터 웨어하우징 패키지, 다수의 사용자 및 대용량 로그 데이터 처리를 위해 페이스북에서 먼저 Hive를 만들기 시작 - 구조화된 데이터를 쿼리하고, 다소 복잡한 MapReduce 프로 그램 대신 HiveQL을 사용해서 쉽게 데이터를 처리 - 테이블, 행, 컬럼, 스키마 같이 쉽게 배울 수 있는, 관계형 데 이터베이스와 유사한 개념을 사용 13년 2월 2일 토요일
- 81. Hive hive CREATE TABLE cite (citing INT, cited INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; hive LOAD DATA LOCAL INPATH 'cite75_99.txt' OVERWRITE INTO TABLE cite; Copying data from file:/root/cite75_99.txt Loading data to table cite hive SELECT * FROM cite LIMIT 10; OK NULL NULL 3858241 956203 ... 3858241 3634889 3858242 3668705 3858242 3707004 13년 2월 2일 토요일
- 82. 에이브로(Avro) 이기종
- 83. ��간
- 84. ��데이터
- 85. ��타입을
- 86. ��교환할
- 87. ��수
- 88. ��있는
- 89. ��체계를
- 90. ��제공하는
- 91. ��프레임워크로,
- 92. �� 아파치
- 93. ��하둡
- 94. ��프로젝트의
- 95. ��서브
- 96. ��프로젝트로
- 97. ��시작된
- 98. ��후
- 99. ��아파치
- 100. ��메인
- 101. ��프로젝트로
- 102. ��승격 쓰리프트(Thrift)가
- 103. ��RPC(Remote
- 104. ��Procedure
- 105. ��Call)
- 106. ��요청을
- 107. ��안정적으
- 108. ��로
- 109. ��처리하면서
- 110. ��이기종
- 111. ��간
- 112. �� RPC
- 113. ��호출을
- 114. ��지원하는
- 115. ��개념으로
- 116. ��접근했다면,
- 117. ��에이브로는
- 118. ��데이터
- 119. ��직렬화를
- 120. ��기본
- 121. ��개념으로
- 122. ��해
- 123. �� RPC
- 124. ��호출을
- 125. ��이기종
- 126. ��간에
- 127. ��가능케
- 128. ��하는
- 129. ��개념 13년 2월 2일 토요일
- 130. 주키퍼(ZooKeeper) 분산
- 131. ��환경에서
- 132. ��노드간의
- 133. ��정보
- 134. ��공유,
- 135. ��락(lock),
- 136. ��이벤트
- 137. ��처리
- 138. ��등
- 139. ��보조
- 140. ��기능을
- 141. ��제공 하둡(코끼리),
- 142. ��pig(돼지)
- 143. ��같이
- 144. ��동물
- 145. ��이름이
- 146. ��많이
- 147. ��사용되어,
- 148. ��동물
- 149. ��사육사라는
- 150. ��의미대로
- 151. ��하둡
- 152. ��분산
- 153. �� 처리
- 154. ��시스템을
- 155. ��일괄적으로
- 156. ��관리해
- 157. ��주는
- 158. ��시스템 분산환경에서
- 159. ��서버가
- 160. ��수백/수천대에서
- 161. ��예상치
- 162. ��못한
- 163. ��예외
- 164. ��부분
- 165. ��(ex:네트웍
- 166. ��장애,
- 167. ��서버
- 168. ��다운,
- 169. ��일부
- 170. �� 서비스
- 171. ��중지,
- 172. ��서버
- 173. ��확장
- 174. ��문제등)
- 175. ��을
- 176. ��총체적으로
- 177. ��관리
- 178. ��-
- 179. ��동시
- 180. ��작업을
- 181. ��위한
- 182. ��부하
- 183. ��분산
- 184. ��-
- 185. ��하나의
- 186. ��서버에서
- 187. ��처리된
- 188. ��결과가
- 189. ��또
- 190. ��다른
- 191. ��서버들과
- 192. ��동기화
- 193. ��되어
- 194. ��처리되게
- 195. ��하는
- 196. ��분산
- 197. ��락관리
- 198. ��-
- 199. ��액티브
- 200. ��서버가
- 201. ��처리중엔
- 202. ��작업이
- 203. ��문제가
- 204. ��발생하여
- 205. ��대기
- 206. ��서버가
- 207. ��하던
- 208. ��서비스를
- 209. ��처리
- 210. ��등 13년 2월 2일 토요일
- 211. Case Studies 뉴욕 타임즈 보관소에 있는 천백만 개의 이미지 문서 변환 - 1851년과 1922년 사이에 있는 모든 종류의 기사 - 이미지로 변환할 기사가 총 천백만 개, 총 4테라바이트의 데이터 - Hadoop framework,Amazon Web Servcies, S3 이용, 100개의 노드 - 24시간 동안 수행, 1개의 인스턴스를 1시간 사용했을 때 비용 : 10센 트, 총 100개 인스턴스, 240달러 지출 13년 2월 2일 토요일
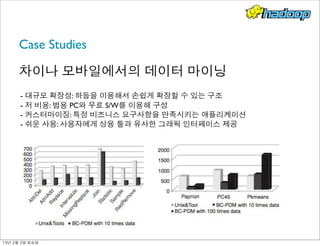
- 212. Case Studies 차이나 모바일에서의 데이터 마이닝 - 대규모 확장성: 하둡을 이용해서 손쉽게 확장할 수 있는 구조 - 저 비용: 범용 PC와 무료 S/W를 이용해 구성 - 커스터마이징: 특정 비즈니스 요구사항을 만족시키는 애플리케이션 - 쉬운 사용: 사용자에게 상용 툴과 유사한 그래픽 인터페이스 제공 13년 2월 2일 토요일
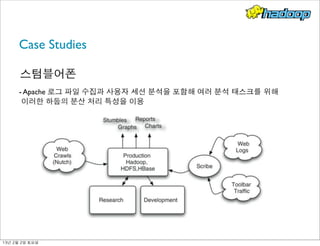
- 213. Case Studies 스텀블어폰 - Apache 로그 파일 수집과 사용자 세션 분석을 포함해 여러 분석 태스크를 위해 이러한 하둡의 분산 처리 특성을 이용 13년 2월 2일 토요일
- 214. Hadoop - 빅 데이터에만 사용되는 것은 아니다. - 진정한 의미의 NoSQL 툴도 아니다. (SQL 과 유사한 쿼리 언어를 쉽게 사용) - 하둡 스토리지는 막대한 양의 데이터를 처리할 수 있다. (야후는 5만 개의 노드로 구성된 하둡 네트워크, Facebook 은 1만개) - 가장 강력한 능력은? 확장성이다. - 가장 큰 장점? 저렴한 비용
- 215. ��
- 216. ��
- 217. ��
- 218. ��(RDBMS와는
- 219. ��다르게
- 220. ��하둡은
- 221. ��고가의
- 222. ��하드웨어나
- 223. ��고성능
- 224. ��프로세서를
- 225. ��필요로
- 226. ��하지
- 227. �� 않음) -
- 228. ��미션
- 229. ��크리티컬,
- 230. ��초
- 231. ��단위
- 232. ��이하로
- 233. ��상호간에
- 234. ��보고
- 235. ��하거나
- 236. ��다단계
- 237. ��복잡한
- 238. ��트랜젝션이
- 239. ��필 요하다면
- 240. ��RDBMS
- 241. ��를
- 242. ��그대로
- 243. ��사용해라. -
- 244. ��보통
- 245. ��한
- 246. ��두명의
- 247. ��엔지니어가
- 248. ��하둡을
- 249. ��다운로드
- 250. ��받아
- 251. ��4-5개의
- 252. ��노드로
- 253. ��구성해
- 254. ��놓고
- 255. ��사용 한
- 256. ��뒤에
- 257. ��이후에는
- 258. ��거의
- 259. ��같은
- 260. ��패턴이므로
- 261. ��그
- 262. ��가치를
- 263. ��알기
- 264. ��시작한다.
- 265. ��(야후에서도
- 266. ��이런
- 267. �� 과정을
- 268. ��거쳤다고
- 269. ��함) 13년 2월 2일 토요일
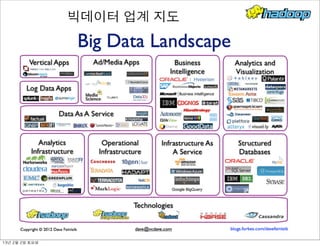
- 270. 빅데이터 업계 지도 13년 2월 2일 토요일
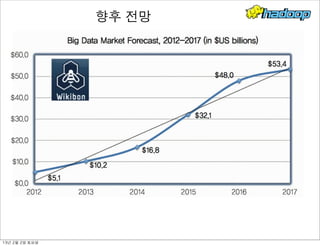
- 271. 향후 전망 13년 2월 2일 토요일
- 272. 국내외 사례(1/5) 1.미국국세청,
- 273. ��탈세방지시스템통한국가재정강화 2.
- 274. ��일본,
- 275. ��센서데이터를
- 276. ��활용한
- 277. ��지능형
- 278. ��교통안내
- 279. ��시스템 3.
- 280. ��밀라노,
- 281. ��지능형
- 282. ��교통정보
- 283. ��시스템으로
- 284. ��신속·・정확하고
- 285. ��손쉬운
- 286. ��길안내서비스
- 287. ��4.
- 288. ��뉴욕 주
- 289. ��시라큐스시,
- 290. ��데이터
- 291. ��분석을
- 292. ��기반으로
- 293. ��스마터
- 294. ��시티
- 295. ��추진 5.
- 296. ��덴마크
- 297. ��베스타스
- 298. ��윈드
- 299. ��시스템,
- 300. ��풍력
- 301. ��에너지
- 302. ��관리로
- 303. ��에너지
- 304. ��생산
- 305. ��효과
- 306. ��극대화
- 307. ��6.
- 308. ��구 글,
- 309. ��실시간
- 310. ��자동
- 311. ��번역시스템을
- 312. ��통한
- 313. ��의사소통의
- 314. ��불편해소 7.
- 315. ��월마트,
- 316. ��데이터
- 317. ��분석을
- 318. ��통한
- 319. ��투자수익
- 320. ��증대 8.
- 321. ��자라,
- 322. ��점포별·・상품별
- 323. ��등
- 324. ��실시간
- 325. ��데이터
- 326. ��분석을
- 327. ��통한
- 328. ��판매량
- 329. ��증대 9.
- 330. ��마이크론
- 331. ��테크놀로지,
- 332. ��제품생산시간
- 333. ��분석을
- 334. ��통한
- 335. ��비용절감 10.
- 336. ��코카콜라의
- 337. ��SNS
- 338. ��데이터
- 339. ��활용을
- 340. ��통한
- 341. ��가치향상
- 342. ��노력 11.
- 343. ��리츠칼튼
- 344. ��호텔,
- 345. ��데이터
- 346. ��관리를
- 347. ��통한
- 348. ��고객맞춤형
- 349. ��서비스
- 350. ��제공 12.
- 351. ��SNS를
- 352. ��활용한
- 353. ��할리우드
- 354. ��흥행
- 355. ��수익
- 356. ��예측 13.
- 357. ��넷플릭스,
- 358. ��데이터
- 359. ��분석으로
- 360. ��온라인
- 361. ��DVD
- 362. ��판매제고
- 363. ��및
- 364. ��고객
- 365. ��서비스
- 366. ��향상 13년 2월 2일 토요일
- 367. 국내외 사례 (2/5) 1.
- 368. ��한국석유공사,
- 369. ��국내
- 370. ��유가
- 371. ��예보
- 372. ��서비스를
- 373. ��통한
- 374. ��비즈니스
- 375. ��최적화 2.
- 376. ��국민권익위원회,
- 377. ��민원정보분석
- 378. ��시스템을
- 379. ��통한
- 380. ��국민과
- 381. ��정부의
- 382. ��소통
- 383. ��활성화
- 384. ��3.
- 385. ��한국 도로공사,
- 386. ��고객
- 387. ��목소리
- 388. ��분석
- 389. ��시스템을
- 390. ��통한
- 391. ��서비스
- 392. ��혁신 4.
- 393. ��통계청,
- 394. ��임금근로일자리
- 395. ��통계로
- 396. ��일자리
- 397. ��현황
- 398. ��파악
- 399. ��지원 5.
- 400. ��한국수자원공사,
- 401. ��스마트워터
- 402. ��그리드를
- 403. ��기반으로
- 404. ��물
- 405. ��부족
- 406. ��현상
- 407. ��해결 6.
- 408. ��포스코,
- 409. ��원료가격의
- 410. ��효율적
- 411. ��구매를
- 412. ��통한
- 413. ��가격
- 414. ��경쟁력
- 415. ��제고 7.
- 416. ��GS
- 417. ��EPS,
- 418. ��전력시장
- 419. ��분석
- 420. ��시스템을
- 421. ��통한
- 422. ��전력시장
- 423. ��전망
- 424. ��및
- 425. ��분석 8.
- 426. ��SK텔레콤,
- 427. ��소셜네트워크에서의
- 428. ��여론분석을
- 429. ��위한
- 430. ��스마트
- 431. ��인사이트
- 432. ��시스템
- 433. ��9.
- 434. ��현 대ᆞ기아자동차,
- 435. ��문서
- 436. ��중앙화
- 437. ��시스템으로
- 438. ��통합적
- 439. ��기업
- 440. ��정보
- 441. ��관리 13년 2월 2일 토요일
- 442. 국내외 사례 (3/5) 1.
- 443. ��미국
- 444. ��국립보건원,
- 445. ��유전자
- 446. ��데이터
- 447. ��공유를
- 448. ��통한
- 449. ��질병치료체계
- 450. ��마련 2.
- 451. ��미국
- 452. ��국립보건원,
- 453. ��Pillbox
- 454. ��프로젝트를
- 455. ��통한
- 456. ��의료개혁 3.
- 457. ��미국
- 458. ��퇴역군인의
- 459. ��전자의료기록
- 460. ��분석을
- 461. ��통한
- 462. ��맞춤형
- 463. ��의료
- 464. ��서비스
- 465. ��지원
- 466. ��4.
- 467. ��싱가포르,
- 468. �� 주민위원회
- 469. ��센터
- 470. ��네트워크를
- 471. ��기반으로
- 472. ��맞춤형
- 473. ��복지사회
- 474. ��구현
- 475. ��5.
- 476. ��캐나다
- 477. ��온타리오공과 대병원,
- 478. ��미숙아
- 479. ��모니터링을
- 480. ��통한
- 481. ��감염
- 482. ��예방
- 483. ��및
- 484. ��예측
- 485. ��6.
- 486. ��건강보험회사
- 487. ��웰포인트,
- 488. ��슈퍼컴 퓨터를
- 489. ��활용한
- 490. ��효율적인
- 491. ��환자치료 7.
- 492. ��구글,
- 493. ��검색어
- 494. ��분석을
- 495. ��통한
- 496. ��독감예보
- 497. ��서비스
- 498. ��제공 8.
- 499. ��네덜란드
- 500. ��스파크드,
- 501. ��빅데이터를
- 502. ��활용하여
- 503. ��건강한
- 504. ��소
- 505. ��사육
- 506. ��환경
- 507. ��구축 13년 2월 2일 토요일
- 508. 국내외 사례 (4/5) 1.
- 509. ��싱가포르,
- 510. ��국가위험관리시스템을
- 511. ��통한
- 512. ��국가안전관리 2.FBI,
- 514. ��샌프란시스코,
- 515. ��범죄
- 516. ��예방
- 517. ��시스템으로
- 518. ��안전
- 519. ��지역사회
- 520. ��구축 4.
- 521. ��싱가포르
- 522. ��출입국관리소,
- 523. ��통합적
- 524. ��정보분석으로
- 525. ��출입국
- 526. ��보안
- 527. ��및
- 528. ��국경
- 529. ��통제
- 530. ��강화
- 531. ��5.
- 532. ��일 본,
- 533. ��다양한
- 534. ��센서
- 535. ��데이터를
- 536. ��활용한
- 537. ��재난대응
- 538. ��능력
- 539. ��강화 6.
- 540. ��위키리크스,
- 541. ��데이터
- 542. ��분석을
- 543. ��통한
- 544. ��효과적인
- 545. ��전술
- 546. ��제공
- 547. ��서비스 7.
- 548. ��서울시,
- 549. ��시민과
- 550. ��함께
- 551. ��만드는
- 552. ��실시간
- 553. ��폭우지도로
- 554. ��수해
- 555. ��예방
- 556. ��및
- 557. ��대책
- 558. ��마련 8.
- 559. ��KSTEC,
- 560. ��보험사기
- 561. ��방지시스템으로
- 562. ��보험사기
- 563. ��방지 13년 2월 2일 토요일
- 565. ��시민의
- 566. ��자발적인
- 567. ��참여와
- 568. ��창의성을
- 569. ��기반으로
- 570. ��정책수립에
- 571. ��기여
- 572. ��2.
- 573. ��미국
- 574. �� 미시간
- 575. ��주,
- 576. ��데이터웨어하우스
- 577. ��구축으로
- 578. ��공공서비스
- 579. ��질적
- 580. ��향상 3.
- 581. ��영국
- 582. ��패치베이,
- 583. ��국민참여형
- 584. ��안전관리
- 585. ��플랫폼
- 586. ��구현 4.
- 587. ��케냐
- 588. ��우샤히디,
- 589. ��집단지성으로
- 590. ��이루어진
- 591. ��재난관리
- 592. ��오픈소스
- 593. ��플랫폼 5.
- 594. ��IBM
- 595. ��왓슨,
- 596. ��인공지능
- 597. ��슈퍼컴퓨터로
- 598. ��인류의
- 599. ��창조성과
- 600. ��혁신
- 601. ��촉진 6.
- 602. ��애플
- 603. ��시리,
- 604. ��지능형
- 605. ��음성인식을
- 606. ��통해
- 607. ��더
- 608. ��똑똑해지는
- 609. ��창의적
- 610. ��사고
- 611. ��가능
- 612. ��7.
- 613. ��프랑스,
- 614. ��시 민
- 615. ��건강
- 616. ��보호를
- 617. ��위한
- 618. ��스마트폰
- 619. ��소음지도
- 620. ��작성 8.
- 621. ��새로운
- 622. ��과학적
- 623. ��발견
- 624. ��:
- 625. ��대형강입자충돌기를
- 626. ��이용한
- 627. ��힉스입자
- 628. ��검출 9.
- 629. ��솔트룩스,
- 630. ��부산지식네트워크
- 631. ��시스템으로
- 632. ��체계적
- 633. ��인적
- 634. ��네트워크
- 635. ��마련 13년 2월 2일 토요일
- 636. 감사합니다. 이현남
- 637. ��/
- 638. ��@brian02k
- 639. ��/
- 641. ��/
- 642. ��010-8080-8124 13년 2월 2일 토요일