SparkмҷҖ Hadoop, мҷ„лІҪн•ң мЎ°н•© (н•ңкөӯм–ҙ)
99 likes6,554 views

SparkмҷҖ Hadoopмқҙ м–ҙл–»кІҢ мӢӨмӢңк°„ мҳҲмёЎмқ„ мң„н•ҙ н•Ёк»ҳ м“°мқј мҲҳ мһҲлҠ”м§Җ л°©н–Ҙмқ„ лӘЁмғүн•ңлӢӨ.























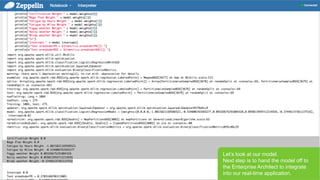





![Page 51 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
Storm Boltм—җм„ң SparkлҘј нҳём¶ң
В§пӮ§вҖҜ лЎңм§ҖмҠӨнӢұ нҡҢк·Җ лӘЁлҚёмқҳ м¶ңл ҘмқҖ к°ҖмӨ‘м№ҳл“Өкіј н•ҳлӮҳмқҳ м ҲнҺё:
val algorithm = new LogisticRegressionWithSGD()
val model = algorithm.run(training).clearThreshold()
println(model.weights)
println(model.intercept)
Weights[-0.40819922025591465,0.06392530395655666,-0.1346227352186122,-0.07188217286407801,0.7277326276521062
,0.508779221680863,-0.024689093098281954]
Intercept 0.0
В§пӮ§вҖҜ н•ҙлӢ№ лӘЁлҚёмқҖ мҳҲмёЎмқ„ л§Ңл“Өкё° мң„н•ҙ мң„мқҳ к°ҖмӨ‘м№ҳмҷҖ н•Ёк»ҳ Storm boltм—җм„ң мһ¬мғқм„ұлҗ мҲҳ мһҲ
мқҢ
import org.apache.spark.mllib.classification.LogisticRegressionModel;
import org.apache.spark.mllib.linalg.Vectors;
вҖҰвҖҰвҖҰ..
Vector weights = (Vectors.dense(new double[] <array of weights like above>)
LogisticRegressionModel model = new LogisticRegressionModel(weights, 0.0);
double prediction = model.predict(<input features>)](https://image.slidesharecdn.com/hdpacc12-150827015134-lva1-app6891/85/Spark-Hadoop-51-320.jpg)



![[Td 2015]microsoft к°ңл°ңмһҗл“Өмқ„ мң„н•ң лӢ¬мҪӨн•ң hadoop, hd insight(мөңмў…мҡұ)](https://cdn.slidesharecdn.com/ss_thumbnails/td2015microsofthadoophdinsight-151104051358-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)

![[Open Technet Summit 2014] м“°кё° мү¬мҡҙ Hadoop кё°л°ҳ л№…лҚ°мқҙн„° н”Ңлһ«нҸј м•„нӮӨн…ҚмІҳ л°Ҹ нҷңмҡ© л°©м•Ҳ](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=560&fit=bounds)
























![(Red hat]private cloud-osp-introduction(samuel)2017-0530(printed)](https://cdn.slidesharecdn.com/ss_thumbnails/redhatprivate-cloud-osp-introductionsamuel2017-0530printed-210414071244-thumbnail.jpg?width=560&fit=bounds)

More Related Content
What's hot (20)
Similar to SparkмҷҖ Hadoop, мҷ„лІҪн•ң мЎ°н•© (н•ңкөӯм–ҙ) (20)

![[OpenStack Day in Korea 2015] Keynote 3 - м—”н„°н”„лқјмқҙмҰҲ кё°м—…мқ„ мң„н•ң к°ңл°©нҳ• нҒҙлқјмҡ°л“ң м»ҙн“ЁнҢ…](https://cdn.slidesharecdn.com/ss_thumbnails/03-150213033416-conversion-gate01-thumbnail.jpg?width=560&fit=bounds)



![[Mpis17,red hat] SMART Health, innovative opensoruce and security with red ha...](https://cdn.slidesharecdn.com/ss_thumbnails/mpis17redhathealthcaresysteminnovativeopensoruceandsecuritywithredhatredhatsamuel2017-0515printed-210409030241-thumbnail.jpg?width=560&fit=bounds)












SparkмҷҖ Hadoop, мҷ„лІҪн•ң мЎ°н•© (н•ңкөӯм–ҙ)
- 1. SparkмҷҖ HDP, мҷ„лІҪн•ң мЎ°н•© (Hortonworks Data Platform) мөңмў…мҡұ кё°мҲ мқҙмӮ¬, Hortonworks Korea В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 2. мҷң мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқёк°Җ? л№…лҚ°мқҙн„° мӢңлҢҖмқҳ 분мӮ° м ҖмһҘ/분м„қ н”Ңлһ«нҸј В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 3. 4ZB DATA MOBILE DEVICES HUMAN CONTENT INTERNET OF THINGS 44ZB DATA Page 3 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Source: http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm
- 4. мң„кё° кё°мЎҙмқҳ лҚ°мқҙн„° м•„нӮӨн…ҚмІҳлҠ” лҚ°мқҙн„°лҘј м ‘к·ј л¶Ҳ к°ҖлҠҘн•ҳкІҢ, л¶Ҳмҷ„м „н•ҳкІҢ, л¬ҙкҙҖн•ҳкІҢ, к·ёлҰ¬кі 비 мӢёкІҢ л§Ңл“ӯлӢҲлӢӨ Page 4 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 5. кё°нҡҢ Apacheв„ў HadoopВ® мқҖ м—¬лҹ¬л¶„мқҳ мӮ¬м—…мқ„ ліҖнҷ”мӢңмјң, м–ҙл–Ө кі кёү 분м„қ мқ‘мҡ© н”„лЎңк·ёлһЁлҸ„ л№…лҚ°мқҙн„°м—җ м ‘к·ј к°ҖлҠҘн•ҳкІҢ л§Ңл“ӯлӢҲлӢӨ Page 5 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 6. Page 6 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hadoopмқ„ н–Ҙн•ң л‘җ к°Җм§Җ м ‘к·јлІ• мӮ¬ мң мҶҢ н”„ нҠё мӣЁ м–ҙ App App App App App App Page 6 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved мҳӨ н”Ҳ м—” н„° н”„ лқј мқҙ мҰҲ H A D O O P мҳӨ н”Ҳ м»Ө л®Ө лӢҲ нӢ°
- 7. мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoop к°ңл°©м„ұ нҳёнҷҳм„ұ 집мӨ‘м„ұ мӨҖ비м„ұ Page 7 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 8. Page 8 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Payment Tracking Call Analysis Machine Data Product Design Social Mapping Factory Yields Defect Detection Due Diligence M & A Proactive Repair Disaster Mitigation Investment Planning Next Product Recs Store Design Risk Modeling Ad Placement Inventory Predictions Sentiment Analysis Ad Placement Basket Analysis Segments Customer Support Supply Chain Cross- Sell Customer Retention Vendor Scorecards Optimize Inventories кё°м—…мқҳ кІҪмҳҒ진л“ӨмқҖ мғҲлЎңмҡҙ нҶөм°°, мў…н•©м Ғ кҙҖм җ, мҳҲмёЎм Ғ 분м„қмқҙлқјлҠ” л№…лҚ°мқҙн„°мқҳ мғҲлЎңмҡҙ нҷңмҡ©мқ„ к°•нҷ”н•ҳлҠ” м°Ём„ё лҢҖ мқ‘мҡ© н”„лЎңк·ёлһЁл“Өмқ„ нҷңмҡ©н•ҳм—¬ ліҖнҷ”лҗң м„ұкіјлҘј мқҙлҒҢм–ҙлӮҙкі мһҲмҠөлӢҲлӢӨ.мӮ¬м—…м Ғ м„ұкіј мғҲлЎңмҡҙ нҶөм°° мў…н•©м Ғ кҙҖм җ мҳҲмёЎм Ғ 분м„қ
- 9. Page 9 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Historical Records OPEX Reduction Mainframe Offloads Fraud Prevention Data as a Service Public Data Capture 비мҡ© м Ҳк°җ IT кІҪмҳҒ진л“ӨмқҖ мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқ„ мӮ¬мҡ©н•ҳм—¬ кё°мЎҙ лҚ°мқҙн„° м•„нӮӨн…ҚмІҳлҘј нҳ„лҢҖнҷ”н•ҳм—¬ мғҒлӢ№н•ң мҡҙмҳҒ 비мҡ© м Ҳк°җмқ„ лӢ¬м„ұн•ҳкі мһҲмҠөлӢҲлӢӨ. мқҙлҹ¬н•ң 비мҡ© м Ҳк°җ нҳҒмӢ мқҖ мҪңл“ң лҚ°мқҙн„°мқҳ нҷңм„ұ ліҙмЎҙліё, ETL мҳӨн”„лЎңл“ң, к·ёлҰ¬ кі кё°мЎҙ лҚ°мқҙн„°мқҳ ліҙк°•мқ„ нҸ¬н•Ён•©лӢҲлӢӨ. Digital Protection Device Data Ingest Rapid Reporting нҷңм„ұ ліҙмЎҙліё ETL мҳӨн”„лЎңл“ң лҚ°мқҙн„° ліҙк°•
- 10. Page 10 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hortonworksмқҳ кі к°қл“ӨмқҖ мҡ°лҰ¬мқҳ кё°мҲ мқ„ нҷңмҡ©н•ҳм—¬ мғҲлЎңмҡҙ мӮ¬м—…м Ғмқё м„ұкіјлҘј мқҙлЈЁкұ°лӮҳ 비мҡ©мқ„ мӨ„м—¬ к·ёл“Өмқҳ мӮ¬м—…мқ„ ліҖнҷ”мӢңнӮөлӢҲлӢӨ. мқҙ л‘җ лӘ©н‘ңмқҳ м—¬м •мқҖ ліҙнҶө лӢӨм–‘н•ң мҡ©лҸ„м—җ кұёміҗ н•Ёк»ҳ мқҙлЈЁм–ҙ집лӢҲлӢӨ.кі к°қмқҳ м—¬м • Social Mapping Payment Tracking Factory Yields Defect Detection Call Analysis Machine Data Product Design M & A Due Diligence Next Product Recs Store Design Risk Modeling Ad Placement Proactive Repair Disaster Mitigation Investment Planning Inventory Predictions Customer Support Sentiment Analysis Supply Chain Ad Placement Basket Analysis Segments Cross- Sell Customer Retention Vendor Scorecards Optimize Inventories OPEX Reduction Mainframe Offloads Historical Records Data as a Service Public Data Capture Fraud Prevention Device Data Ingest Rapid Reporting Digital Protection мғҲлЎңмҡҙ нҶөм°° мў…н•©м Ғ кҙҖм җ мҳҲмёЎм Ғ 분м„қ нҷңм„ұ ліҙмЎҙліё ETL мҳӨн”„лЎңл“ң лҚ°мқҙн„° ліҙк°• нғҗ мғү мөң м Ғ нҷ” м „ нҷҳ
- 11. мҷң Hortonworksмқёк°Җ? мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқҳ лҰ¬лҚ” В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 12. Page 12 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hortonworksл§Ңмқҙ мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқ„ м ңкіө H O R T O N W O R K S D ATA P L AT F O R M YARN: лҚ°мқҙн„° мҡҙмҳҒ мІҙм ң нҒҙлҰӯмҠӨнҠёлҰј м„јм„ң мҶҢм…ң лӘЁл°”мқј мң„м№ҳ м„ңлІ„ лЎңк·ё л°°м№ҳ мқён„°лһҷнӢ°лёҢ кІҖмғү мҠӨнҠёлҰ¬л°Қ кё°кі„ н•ҷмҠө кё°мЎҙ
- 13. Page 13 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved HortonworksлҠ” Apache м»Өл®ӨлӢҲнӢ°м—җ нҒ° мҳҒн–Ҙл Ҙмқ„ н–үмӮ¬ м»ӨлҜён„°л“Өмқ„ кі мҡ© Apache Hadoopв„ў н”„лЎңм қнҠё м»ӨлҜён„°мқҳ 1/3, лӢӨлҘё мӨ‘ мҡ”н•ң н”„лЎңм қнҠём—җм„ңлҸ„ лӢӨмҲҳ кі мҡ© мҡ°лҰ¬мқҳ м»ӨлҜён„°л“Өмқҙ нҳҒмӢ мқ„ мЈјлҸ„ мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқ„ нҷ•мһҘ Hadoop лЎңл“ңл§өм—җ мҳҒн–Ҙл Ҙмқ„ н–үмӮ¬ мҡ°лҰ¬мқҳ лҰ¬лҚ”лҘј нҶөн•ҙм„ң мӨ‘мҡ”н•ң мҡ”кө¬мӮ¬н•ӯл“Өмқ„ м»Өл®ӨлӢҲ нӢ°м—җ мЈјкі л°ӣмқҢ A PA C H E H A D O O P C O M M I T T E R S
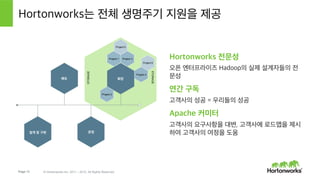
- 14. Page 14 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved STORAGE STORAGE HortonworksлҠ” м „мІҙ мғқлӘ…мЈјкё° м§Җмӣҗмқ„ м ңкіө Hortonworks м „л¬ём„ұ мҳӨн”Ҳ м—”н„°н”„лқјмқҙмҰҲ Hadoopмқҳ мӢӨм ң м„Өкі„мһҗл“Өмқҳ м „ л¬ём„ұ м—°к°„ кө¬лҸ… кі к°қмӮ¬мқҳ м„ұкіө = мҡ°лҰ¬л“Өмқҳ м„ұкіө Apache м»ӨлҜён„° кі к°қмӮ¬мқҳ мҡ”кө¬мӮ¬н•ӯмқ„ лҢҖліҖ, кі к°қмӮ¬м—җ лЎңл“ңл§өмқ„ м ңмӢң н•ҳм—¬ кі к°қмӮ¬мқҳ м—¬м •мқ„ лҸ„мӣҖм„Өкі„ л°Ҹ кө¬нҳ„ л°°нҸ¬ мҡҙмҳҒ Project 1 Project 5 Project 4 Project 3 Project 2 Project 6 нҷ•мһҘ
- 15. Page 15 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved HortonworksлҠ” м„ м ңм Ғмқё м§Җмӣҗмқ„ м ңкіө Hortonworks SmartSenseв„ў кі к°қмӮ¬мқҳ нҒҙлҹ¬мҠӨн„°м—җ лҢҖн•ң кё°кі„ н•ҷмҠөкіј мҳҲмёЎм Ғ 분м„қ нҶөн•© кі к°қ нҸ¬н„ё м§ҖмӢқ лІ мқҙмҠӨ л°Ҹ мҳЁл””л©ҳл“ң көҗмңЎ м§ҖмӢқ лІ мқҙмҠӨ нҶөн•© кі к°қ нҸ¬н„ё мҳЁл””л©ҳл“ң көҗмңЎ кі к°қмӮ¬ нҷҳкІҪ лӘЁл“ нҒҙлқјмҡ°л“ң вҖў н•ҳмқҙлёҢлҰ¬л“ң нҷҳкІҪ вҖў л©ҖнӢ°н„°л„ҢнҠё Hortonworks SmartSense
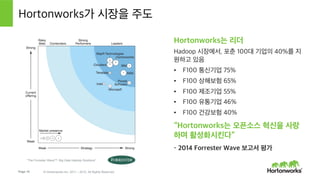
- 16. Page 16 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hortonworksк°Җ мӢңмһҘмқ„ мЈјлҸ„ HortonworksлҠ” лҰ¬лҚ” Hadoop мӢңмһҘм—җм„ң, нҸ¬м¶ҳ 100лҢҖ кё°м—…мқҳ 40%лҘј м§Җ мӣҗн•ҳкі мһҲмқҢ вҖўвҖҜ F100 нҶөмӢ кё°м—… 75% вҖўвҖҜ F100 мғҒн•ҙліҙн—ҳ 65% вҖўвҖҜ F100 м ңмЎ°кё°м—… 55% вҖўвҖҜ F100 мң нҶөкё°м—… 46% вҖўвҖҜ F100 кұҙк°•ліҙн—ҳ 40% вҖңHortonworksлҠ” мҳӨн”ҲмҶҢмҠӨ нҳҒмӢ мқ„ мӮ¬лһ‘ н•ҳл©° нҷңм„ұнҷ”мӢңнӮЁлӢӨвҖқ вҖ“ 2014 Forrester Wave ліҙкі м„ң нҸүк°Җ вҖңThe Forrester Waveв„ў: Big Data Hadoop SolutionsвҖқ
- 17. Page 17 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hortonworks мҶҢк°ң кі к°қ нҷ•мһҘм„ё вҖўвҖҜ 556к°ң кі к°қмӮ¬ (2015л…„ 8мӣ” 5мқј кё°мӨҖ) вҖўвҖҜ 2015л…„ 2분기 119к°ң мӢ к·ң кі к°қмӮ¬ вҖўвҖҜ NASDAQм—җ мғҒмһҘлҗЁ: HDP Hortonworks Data Platform вҖўвҖҜ лӘЁл“ мқ‘мҡ©кіј лӘЁл“ лҚ°мқҙн„°лҘј мң„н•ҙ мҷ„м „н•ң мҳӨн”Ҳ л©ҖнӢ°н„°л„Ң нҠё н”Ңлһ«нҸј вҖўвҖҜ ліҙм•Ҳ, мҡҙмҳҒ, кұ°лІ„л„ҢмҠӨлҘј мң„н•ҙ мқјкҙҖлҗң кё°м—… м„ң비мҠӨ кі к°қ м„ұкіөмқҳ лҸҷл°ҳмһҗ вҖўвҖҜ мҳӨн”ҲмҶҢмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ лҰ¬лҚ”мқҙл©°, кё°м—…мқҙ н•„мҡ”лЎң н•ҳлҠ” нҳҒ мӢ м—җ 집мӨ‘ вҖўвҖҜ 비көҗ л¶Ҳн—Ҳмқҳ Hadoop кё°мҲ м§Җмӣҗ кө¬лҸ… 2011л…„ м„ӨлҰҪ Yahoo!мқҳ мөңмҙҲ 24лӘ…мқҳ Hadoop м„Өкі„мһҗ, к°ңл°ңмһҗ, мҡҙмҳҒмһҗ 740+ мһ„ м§Ғ мӣҗ 1350+ мғқ нғң кі„ нҳ‘ л Ҙ мӮ¬
- 18. Page 18 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Hortonworksк°Җ мөңкі IT н•„мҲҳн’ҲмңјлЎң нҸүк°ҖлҗЁ мөңкі мқҳ IT н•„мҲҳн’Ҳ л№…лҚ°мқҙн„°, мӣЁм–ҙн•ҳмҡ°м§•, 분м„қ мҡ©лҸ„мӨ‘м—җм„ң HortonworksлҠ” мғҒмң„м—җ нҸүк°ҖлҗЁ лӘЁл“ лӢӨлҘё Hadoop л°°нҸ¬нҢҗмқҖ н•ҳмң„м—җ нҸүк°ҖлҗЁ к°ңл°©м„ұ, мҷ„м „м„ұ, 집мӨ‘нҳ• м•„нӮӨн…ҚмІҳ нҠ№лі„н•ң кё°лҠҘмңјлЎң мқёмҡ©лҗЁ 2015л…„ 6мӣ” м§Җм¶ң лӘ©м Ғ Shared Accounts of Hortonworks (A, I) (All Cut, n=35) Hortonworks, Big Data#1 Microsoft, Hosting#2 MongoDB, Warehousing#3 Tableau, Big Data#4 мөңкі лІӨлҚ” 20 Source: https://hortonworks.com/blog/cio-survey-hortonworks-data-platform-now-a-top-it-imperative/
- 19. SparkмҷҖ HDP, мҷ„лІҪн•ң мЎ°н•© Spark on YARN, к·ёлҰ¬кі к·ё мқҙмғҒ В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 20. Page 20 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved мҡ°м•„н•ң к°ңл°ңмһҗ API DataFrames, кё°кі„ н•ҷмҠө, к·ёлҰ¬кі SQL мқён„°лһҷнӢ°лёҢ лҚ°мқҙн„° кіјн•ҷ лӘЁл“ мқ‘мҡ© н”„лЎңк·ёлһЁл“ӨмқҖ лҢҖмҡ©лҹүмқё лҸҷмӢңм—җ м •л°Җн•ң мҳҲмёЎмқҙ н•„мҡ” кё°кі„ н•ҷмҠөмқ„ лҢҖмӨ‘нҷ” Hiveк°Җ Hadoopм—җм„ң SQLмқ„ н–Ҳл“Ҝмқҙ Sparkк°Җ Hadoopм—җм„ң кё°кі„ н•ҷмҠө мқ„ мҲҳн–ү м»Өл®ӨлӢҲнӢ° к°ңл°ңмһҗ, кі к°қ, к·ёлҰ¬кі нҢҢнҠёл„Ҳмқҳ нҸӯ л„“мқҖ кҙҖмӢ¬ лҚ°мқҙн„° мҡҙмҳҒ мІҙм ңмқҳ к°Җм№ҳлҘј нҳ„мӢӨнҷ” Hadoop лҸ„кө¬ мғҒмһҗмқҳ мЈјмҡ”н•ң лҸ„кө¬ Hortonworksк°Җ SparkлҘј мӮ¬лһ‘н•ҳлҠ” мқҙмң Storage YARN: Data Operating System Governance Security Operations Resource Management
- 21. Page 21 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved лҰ¬мҶҢмҠӨ кҙҖлҰ¬ YARNмқҙ мҳҲмёЎ к°ҖлҠҘн•ң SLA м•Ҳм—җм„ң л©ҖнӢ°н„°л„ҢнҠё, лӢӨм–‘н•ң мӣҢнҒ¬лЎңл“ңлҘј м ңкіө кі„мёөм Ғ л©”лӘЁлҰ¬ м ҖмһҘмҶҢ мҳӨн”„-нһҷ RDD мәҗмӢңлҘј мң„н•ң HDFS мқёл©”лӘЁлҰ¬ нӢ°м–ҙ SQLм—җлҠ” SparkSQLмҷҖ Hive мөңмӢ л©”нғҖмҠӨнҶ м–ҙмҷҖ мғҒнҳёмһ‘мҡ©, HS2; мөңм Ғнҷ”лҗң ORC м§Җмӣҗ SparkмҷҖ NoSQL RDDs for predicate pushdownмқ„ нҶөн•ң HBaseмҷҖ к№ҠмқҖ нҶөн•© м•Ңкі лҰ¬мҰҳм—җм„ң мҡ©лЎҖлЎң вҖ“ нқ©м–ҙ진 м җл“Өмқ„ м—°кІ° кі мҲҳмӨҖ кё°кі„ н•ҷмҠө 추мғҒнҷ” вҖ“ кІҖмҰқ, нҠңлӢқ, нҢҢмқҙн”„лқјмқё мЎ°лҰҪвҖҰ мҳҲ: мң„м№ҳ мӮ¬мҡ© нҺёмқҳм„ұ мқён„°лһҷнӢ°лёҢ л…ёнҠёл¶Ғ мҡ©мңјлЎң Apache Zeppelinмқ„ мӮ¬мҡ© SparkмҷҖ Hadoop вҖ“ м–ҙл–»кІҢ лӮҳм•„м§Ҳ мҲҳ мһҲмқ„к№Ң? Storage YARN: Data Operating System Governance Security Operations Resource Management
- 22. Page 22 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved л©”нғҖлҚ°мқҙн„° л°Ҹ кұ°лІ„л„ҢмҠӨ л©”нғҖлҚ°мқҙн„°лҘј мң„н•ң Apache Atlas, Spark нҢҢмқҙн”„лқјмқёмқ„ мң„н•ң Apache Falcon м§Җмӣҗ ліҙм•Ҳ л°Ҹ мҡҙмҳҒ Apache RangerлЎң кҙҖлҰ¬лҗҳлҠ” мқёмҰқ, Apache AmbariлҘј нҶөн•ң л°°нҸ¬ л°Ҹ кҙҖлҰ¬ м–ҙлҠҗ кіім—җм„ң л°°нҸ¬ к°ҖлҠҘ Linux, Windows, мҳЁн”„л ҲлҜёмҠӨ лҳҗлҠ” нҒҙлқјмҡ°л“ң м…Җн”„ м„ң비мҠӨлҗң нҒҙлқјмҡ°л“ң мғҒмқҳ Spark CloudbreakмҷҖ AmbariлҘј нҶөн•ҙ лҚ°мқҙн„° кіјн•ҷ нҒҙлҹ¬мҠӨн„°лҘј мүҪкІҢ мӢӨн–ү - Azure, AWS, GCP, OpenStack, DockerлҘј лӘЁл‘җ м§Җмӣҗ SparkмҷҖ Hadoop вҖ“ м–ҙл–»кІҢ лӮҳм•„м§Ҳ мҲҳ мһҲмқ„к№Ң? Storage YARN: Data Operating System Governance Security Operations Resource Management
- 23. Page 23 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved мӢӨм ң м„ёкі„мқҳ мҡ©лЎҖм—җ лҢҖн•ҙ мқҙм•јкё°н•©мӢңлӢӨ!
- 24. Page 24 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved CDO (мөңкі лҚ°мқҙн„° кҙҖлҰ¬мһҗ) мҡ”кө¬ м•Ҳм •м„ұмқ„ лҶ’мқҙкі л¶ҲлҰ¬н•ң мғҒнҷ©мқ„ мӨ„мһ„ мҡҙм „ мң„л°ҳмқҙ л°ңмғқн•ҳкё° м „м—җ лҢҖмқ‘н•ҳкі мҳҲл°©м Ғмқё н–ү лҸҷмқ„ м·Ён•Ё к°ңл°ң нҢҖмқҳ мқ‘лӢө н”„лЎңк·ёлһЁм—җ лӮ м”Ё лҚ°мқҙн„°мҷҖ мҡҙм „ кё°мӮ¬ н”„лЎңн•„мқ„ 추к°Җ мҳҲмёЎ лӘЁлҚё нҠ№м§•мқ„ мң„н•ҙ лҚ°мқҙн„°лҘј нғҗмғү мҳҲмёЎ лӘЁлҚёмқ„ нӣҲл Ё л°Ҹ мғқм„ұ мҡҙм „ мң„л°ҳ мӮ¬н•ӯмқ„ мӢӨмӢңк°„мңјлЎң мҳҲмёЎн•ҳлҸ„лЎқ лӘЁлҚёмқ„ ліёлһҳ мқ‘мҡ© н”„лЎңк·ёлһЁм—җ 추к°Җ нҠёлҹӯ мҡҙн–ү мҡ©лЎҖ: мӢӨмӢңк°„, мҳҲмёЎм Ғ мқ‘мҡ©
- 25. Page 25 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved лҚ°мқҙн„° кіјн•ҷ: нҒҙлқјмҡ°л“ңм—җм„ң лҚ°мқҙн„° нғҗмғү л°Ҹ лӘЁлҚё мғқм„ұ нҒҙлҰӯ-мҠӨлЈЁ лҚ°лӘЁ нҒҙлқјмҡ°л“ңм—җм„ң лҚ°мқҙн„° кіјн•ҷ нҷҳкІҪ мқ„ л°°нҸ¬ лҚ°мқҙн„° кіјн•ҷ л…ёнҠёл¶Ғмқ„ мӮ¬мҡ©н•ҳм—¬ лҚ°мқҙн„°лҘј нғҗмғү мҳҲмёЎм Ғ лӘЁлҚёмқ„ мғқм„ұн•ҳкё° мң„н•ҙ м•Ңкі лҰ¬мҰҳмқ„ мӢӨн–ү Cloudbreak 1.вҖҜ нҒҙлқјмҡ°л“ң м„ нғқ 2.вҖҜ Spark blueprint м„ нғқ 3.вҖҜ HDP мӢӨн–ү Microsoft Azure
- 26. Page 26 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Login to launch.hortonworks.com which is a self-service portal for launching HDP clusters to the cloud (cloudbreak.sequenceiq.com)
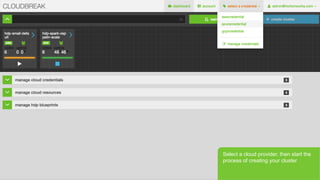
- 27. Page 27 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Select a cloud provider, then start the process of creating your cluster
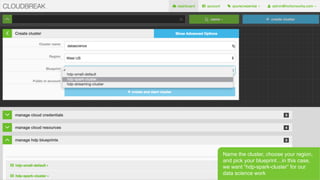
- 28. Page 28 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Name the cluster, choose your region, and pick your blueprintвҖҰin this case, we want вҖңhdp-spark-clusterвҖқ for our data science work
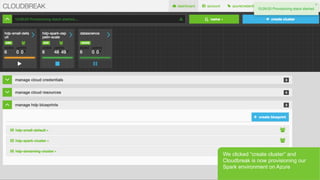
- 29. Page 29 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved We clicked вҖңcreate clusterвҖқ and Cloudbreak is now provisioning our Spark environment on Azure
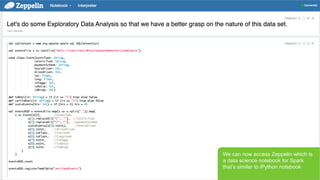
- 30. Page 30 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved We can now access Zeppelin which is a data science notebook for Spark thatвҖҷs similar to iPython notebook
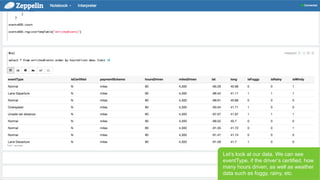
- 31. Page 31 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved LetвҖҷs look at our data. We can see eventType, if the driverвҖҷs certified, how many hours driven, as well as weather data such as foggy, rainy, etc.
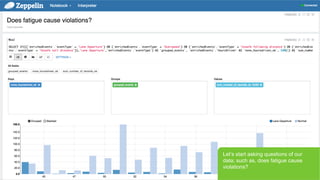
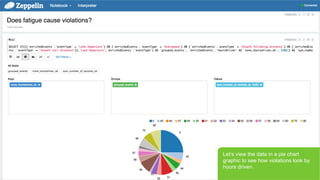
- 32. Page 32 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved LetвҖҷs start asking questions of our data; such as, does fatigue cause violations?
- 33. Page 33 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved LetвҖҷs view the data in a pie chart graphic to see how violations look by hours driven.
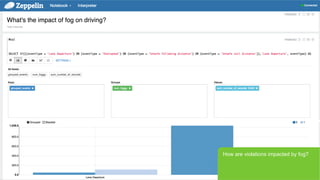
- 34. Page 34 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved How are violations impacted by fog?
- 35. Page 35 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Does location have an impact on incidents?
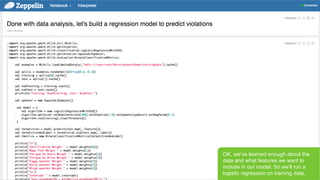
- 36. Page 36 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved OK, weвҖҷve learned enough about the data and what features we want to include in our model. So weвҖҷll run a logistic regression on training data.
- 37. Page 37 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved LetвҖҷs run our code
- 38. Page 38 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved LetвҖҷs look at our model. Next step is to hand the model off to the Enterprise Architect to integrate into our real-time application.
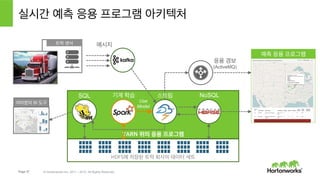
- 39. Page 39 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved YARN мң„мқҳ мқ‘мҡ© н”„лЎңк·ёлһЁ HDFSм—җ м ҖмһҘлҗң нҠёлҹӯ нҡҢмӮ¬мқҳ лҚ°мқҙн„° м„ёнҠё мӢӨмӢңк°„ мҳҲмёЎ мқ‘мҡ© н”„лЎңк·ёлһЁ м•„нӮӨн…ҚмІҳ м—¬лҹ¬л¶„мқҳ BI лҸ„кө¬ мҳҲмёЎ мқ‘мҡ© н”„лЎңк·ёлһЁ нҠёлҹӯ м„јм„ң мқ‘мҡ© кІҪліҙ (ActiveMQ) л©”мӢңм§Җ SQL мҠӨнҠёлҰј NoSQLкё°кі„ н•ҷмҠө Use Model
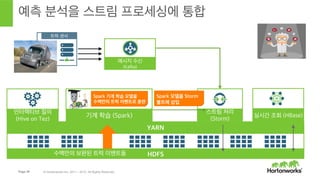
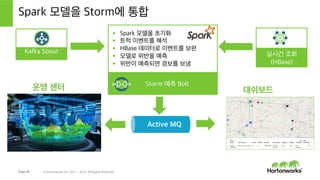
- 40. Stormм—җ Spark кё°кі„ н•ҷмҠөмқ„ нҶөн•© мӢӨмӢңк°„ мҳҲмёЎмқ„ мң„н•ң м•„нӮӨн…ҚмІҳ В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
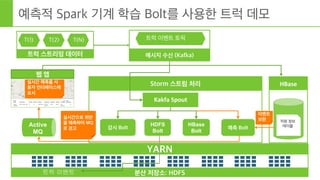
- 41. Page 41 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved нҠёлҹӯ м„јм„ң HDFS YARN мҳҲмёЎ 분м„қмқ„ мҠӨнҠёлҰј н”„лЎңм„ёмӢұм—җ нҶөн•© мҠӨнҠёлҰј мІҳлҰ¬ (Storm) л©”мӢңм§Җ мҲҳмӢ (Kafka) мқён„°лһҷнӢ°лёҢ м§Ҳмқҳ (Hive on Tez) мӢӨмӢңк°„ мЎ°нҡҢ (HBase) мҲҳл°ұл§Ңмқҳ ліҙмҷ„лҗң нҠёлҹӯ мқҙлІӨнҠёл“Ө Predic'on МэBolt Мэ Spark лӘЁлҚёмқ„ Storm ліјнҠём—җ мӮҪмһ… кё°кі„ н•ҷмҠө (Spark) Spark кё°кі„ н•ҷмҠө лӘЁлҚёмқ„ мҲҳл°ұл§Ңмқҳ нҠёлҹӯ мқҙлІӨнҠёлЎң нӣҲл Ё
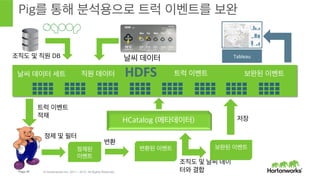
- 42. Page 42 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved PigлҘј нҶөн•ҙ 분м„қмҡ©мңјлЎң нҠёлҹӯ мқҙлІӨнҠёлҘј ліҙмҷ„ HDFS Мэ нҠёлҹӯ мқҙлІӨнҠёлӮ м”Ё лҚ°мқҙн„° м„ёнҠё лӮ м”Ё лҚ°мқҙн„° HCatalog (л©”нғҖлҚ°мқҙн„°) м§Ғмӣҗ лҚ°мқҙн„° мЎ°м§ҒлҸ„ л°Ҹ м§Ғмӣҗ DB нҠёлҹӯ мқҙлІӨнҠё м Ғмһ¬ м •м ң л°Ҹ н•„н„° м •м ңлҗң мқҙлІӨнҠё ліҖнҷҳлҗң мқҙлІӨнҠё ліҖнҷҳ мЎ°м§ҒлҸ„ л°Ҹ лӮ м”Ё лҚ°мқҙ н„°мҷҖ кІ°н•© ліҙмҷ„лҗң мқҙлІӨнҠё ліҙмҷ„лҗң мқҙлІӨнҠё м ҖмһҘ Tableau Мэ Мэ
- 43. Page 43 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved мҳҲмёЎм Ғ Spark кё°кі„ н•ҷмҠө BoltлҘј мӮ¬мҡ©н•ң нҠёлҹӯ лҚ°лӘЁ 분мӮ° м ҖмһҘмҶҢ: HDFS YARN Storm мҠӨнҠёлҰј мІҳлҰ¬ Kakfa МэSpout Мэ HBase Мэ м§Ғмӣҗ м •ліҙ н…Ңмқҙлё”HBase Bolt HDFS Bolt нҠёлҹӯ мқҙлІӨнҠё Active MQ к°җмӢң Bolt мӣ№ м•ұ нҠёлҹӯ мҠӨнҠёлҰ¬л°Қ лҚ°мқҙн„° T(1) T(2) T(N) л©”мӢңм§Җ мҲҳмӢ (Kafka) нҠёлҹӯ мқҙлІӨнҠё нҶ н”Ҫ мҳҲмёЎ Bolt мқҙлІӨнҠё ліҙмҷ„мӢӨмӢңк°„мңјлЎң мң„л°ҳ мқ„ мҳҲмёЎн•ҳм—¬ MQ лЎң кІҪкі мӢӨмӢңк°„ мҳҲмёЎмқ„ мӮ¬ мҡ©мһҗ мқён„°нҺҳмқҙмҠӨм—җ н‘ңмӢң
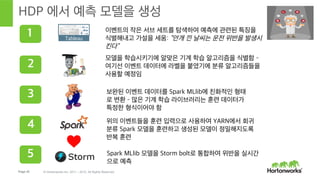
- 44. Page 44 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved HDP м—җм„ң мҳҲмёЎ лӘЁлҚёмқ„ мғқм„ұ Tableau мқҙлІӨнҠёмқҳ мһ‘мқҖ м„ңлёҢ м„ёнҠёлҘј нғҗмғүн•ҳм—¬ мҳҲмёЎм—җ кҙҖл Ёлҗң нҠ№м§•мқ„ мӢқлі„н•ҙлӮҙкі к°Җм„Өмқ„ м„ёмӣҖ: вҖңм•Ҳк°ң лӮҖ лӮ м”ЁлҠ” мҡҙм „ мң„л°ҳмқ„ л°ңмғқмӢң нӮЁлӢӨвҖқ 1 лӘЁлҚёмқ„ н•ҷмҠөмӢңнӮӨкё°м—җ м•Ңл§һмқҖ кё°кі„ н•ҷмҠө м•Ңкі лҰ¬мҰҳмқ„ мӢқлі„н•Ё вҖ“ м—¬кё°м„ мқҙлІӨнҠё лҚ°мқҙн„°м—җ лқјлІЁмқ„ л¶ҷмҳҖкё°м—җ 분лҘҳ м•Ңкі лҰ¬мҰҳл“Өмқ„ мӮ¬мҡ©н• мҳҲм •мһ„ 2 ліҙмҷ„лҗң мқҙлІӨнҠё лҚ°мқҙн„°лҘј Spark MLlibм—җ м№ңнҷ”м Ғмқё нҳ•нғң лЎң ліҖнҷҳ вҖ“ л§ҺмқҖ кё°кі„ н•ҷмҠө лқјмқҙлёҢлҹ¬лҰ¬лҠ” нӣҲл Ё лҚ°мқҙн„°к°Җ нҠ№м •н•ң нҳ•мӢқмқҙм–ҙм•ј н•Ё 3 мң„мқҳ мқҙлІӨнҠёл“Өмқ„ нӣҲл Ё мһ…л ҘмңјлЎң мӮ¬мҡ©н•ҳм—¬ YARNм—җм„ң нҡҢк·Җ 분лҘҳ Spark лӘЁлҚёмқ„ нӣҲл Ён•ҳкі мғқм„ұлҗң лӘЁлҚёмқҙ м •л°Җн•ҙм§ҖлҸ„лЎқ л°ҳліө нӣҲл Ё 4 Spark MLlib лӘЁлҚёмқ„ Storm boltлЎң нҶөн•©н•ҳм—¬ мң„л°ҳмқ„ мӢӨмӢңк°„ мңјлЎң мҳҲмёЎ 5
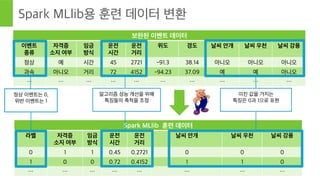
- 45. Page 45 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Spark MLlibмҡ© нӣҲл Ё лҚ°мқҙн„° ліҖнҷҳ ліҙмҷ„лҗң мқҙлІӨнҠё лҚ°мқҙн„° мқҙлІӨнҠё мў…лҘҳ мһҗкІ©мҰқ мҶҢм§Җ м—¬л¶Җ мһ„кёҲ л°©мӢқ мҡҙм „ мӢңк°„ мҡҙм „ кұ°лҰ¬ мң„лҸ„ кІҪлҸ„ лӮ м”Ё м•Ҳк°ң лӮ м”Ё мҡ°мІң лӮ м”Ё к°•н’Қ м •мғҒ мҳҲ мӢңк°„ 45 2721 -91.3 38.14 м•„лӢҲмҳӨ м•„лӢҲмҳӨ м•„лӢҲмҳӨ кіјмҶҚ м•„лӢҲмҳӨ кұ°лҰ¬ 72 4152 -94.23 37.09 мҳҲ мҳҲ м•„лӢҲмҳӨ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ Spark MLlib нӣҲл Ё лҚ°мқҙн„° лқјлІЁ мһҗкІ©мҰқ мҶҢм§Җ м—¬л¶Җ мһ„кёҲ л°©мӢқ мҡҙм „ мӢңк°„ мҡҙм „ кұ°лҰ¬ лӮ м”Ё м•Ҳк°ң лӮ м”Ё мҡ°мІң лӮ м”Ё к°•н’Қ 0 1 1 0.45 0.2721 0 0 0 1 0 0 0.72 0.4152 1 1 0 вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ вҖҰ м •мғҒ мқҙлІӨнҠёлҠ” 0, мң„л°ҳ мқҙлІӨнҠёлҠ” 1 м•Ңкі лҰ¬мҰҳ м„ұлҠҘ к°ңм„ мқ„ мң„н•ҙ нҠ№м§•л“Өмқҳ 축мІҷмқ„ мЎ°м • мқҙ진 к°’мқ„ к°Җм§ҖлҠ” нҠ№м§•мқҖ 0кіј 1мңјлЎң н‘ңнҳ„
- 46. Page 46 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Spark кё°кі„ н•ҷмҠөмқ„ YARNм—җм„ң мӢӨн–ү 1 spark-submit --class org.apache.spark.examples.mllib.BinaryClassification --master yarn-cluster --num-executors 3 --driver-memory 512m --executor-memory 512m --executor-cores 1 truckml.jar --algorithm LR --regType L2 --regParam 1.0 /user/root/ truck_training --numIterations 100 spark-submit мҠӨнҒ¬лҰҪнҠёлҘј мӢӨн–үн•ҳм—¬ Spark jobмқ„ YARN мң„ м—җ кө¬лҸҷ HDFS мғҒмқҳ нӣҲл Ё лҚ°мқҙн„° мң„м№ҳ 2 YARN лҰ¬мҶҢмҠӨ кҙҖлҰ¬мһҗ UIм—җм„ң Spark jobмқҳ 진н–үмқ„ к°җмӢң
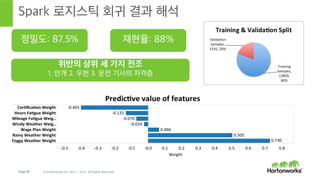
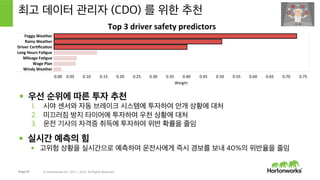
- 47. Page 47 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Spark лЎңм§ҖмҠӨнӢұ нҡҢк·Җ кІ°кіј н•ҙм„қ м •л°ҖлҸ„: 87.5% мһ¬нҳ„мңЁ: 88% мң„л°ҳмқҳ мғҒмң„ м„ё к°Җм§Җ м „мЎ° 1. м•Ҳк°ң 2. мҡ°мІң 3. мҡҙм „ кё°мӮ¬мқҳ мһҗкІ©мҰқ
- 48. Page 48 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Spark лӘЁлҚёмқ„ Stormм—җ нҶөн•© Kafka Spout Storm мҳҲмёЎ Bolt В§пӮ§вҖҜ Spark лӘЁлҚёмқ„ мҙҲкё°нҷ” В§пӮ§вҖҜ нҠёлҹӯ мқҙлІӨнҠёлҘј н•ҙм„қ В§пӮ§вҖҜ HBase лҚ°мқҙн„°лЎң мқҙлІӨнҠёлҘј ліҙмҷ„ В§пӮ§вҖҜ лӘЁлҚёлЎң мң„л°ҳмқ„ мҳҲмёЎ В§пӮ§вҖҜ мң„л°ҳмқҙ мҳҲмёЎлҗҳл©ҙ кІҪліҙлҘј ліҙлғ„ мӢӨмӢңк°„ мЎ°нҡҢ (HBase) Active MQ мҡҙмҳҒ м„јн„° лҢҖмү¬ліҙл“ң
- 49. Page 49 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved мөңкі лҚ°мқҙн„° кҙҖлҰ¬мһҗ (CDO) лҘј мң„н•ң 추мІң В§пӮ§вҖҜ мҡ°м„ мҲңмң„м—җ л”°лҘё нҲ¬мһҗ 추мІң 1.вҖҜ мӢңм•ј м„јм„ңмҷҖ мһҗлҸҷ лёҢл ҲмқҙнҒ¬ мӢңмҠӨн…ңм—җ нҲ¬мһҗн•ҳм—¬ м•Ҳк°ң мғҒнҷ©м—җ лҢҖмІҳ 2.вҖҜ лҜёлҒ„лҹ¬м§җ л°©м§Җ нғҖмқҙм–ҙм—җ нҲ¬мһҗн•ҳм—¬ мҡ°мІң мғҒнҷ©м—җ лҢҖмІҳ 3.вҖҜ мҡҙм „ кё°мӮ¬мқҳ мһҗкІ©мҰқ м·Ёл“қм—җ нҲ¬мһҗн•ҳм—¬ мң„л°ҳ нҷ•лҘ мқ„ мӨ„мһ„ В§пӮ§вҖҜ мӢӨмӢңк°„ мҳҲмёЎмқҳ нһҳ В§пӮ§вҖҜ кі мң„н—ҳ мғҒнҷ©мқ„ мӢӨмӢңк°„мңјлЎң мҳҲмёЎн•ҳм—¬ мҡҙм „мӮ¬м—җкІҢ мҰүмӢң кІҪліҙлҘј ліҙлӮҙ 40%мқҳ мң„л°ҳмңЁмқ„ мӨ„мһ„
- 50. Page 50 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved HDPм—җм„ң лҢҖмҡ©лҹү кё°кі„ н•ҷмҠөмқҳ к°Җм№ҳ В§пӮ§вҖҜ мӢңмһҘ л°Ҹ к°Җм№ҳ 진мһ… мӢңк°„мқ„ к°ҖмҶҚ В§пӮ§вҖҜ лӢӨм–‘н•ң кё°кі„ н•ҷмҠө м•Ңкі лҰ¬мҰҳмқ„ TBмқҳ нӣҲл Ё лҚ°мқҙн„°м—җ лҢҖн•ҙ н•©лҰ¬м Ғмқё мӢңк°„ лІ”мң„ лӮҙм—җм„ң мҲҳн–ү В§пӮ§вҖҜ к°Җм„Өмқ„ мӢ лў°м„ұмқ„ к°–кі TBмқҳ нӣҲл Ё лҚ°мқҙн„°лЎң кІҖмҰқ В§пӮ§вҖҜ мҡ°лҰ¬лҠ” м•Ҳк°ңк°Җ м•Ҳм „м„ұм—җ мҳҒн–Ҙмқ„ лҒјм№ҳлҠ” л°ҳл©ҙ мһ„кёҲ кі„мӮ° л°©мӢқмқҙ мҳҒн–Ҙмқ„ лҒјм№ҳм§Җ м•ҠмқҢмқ„ кІҖмҰқн–ҲмңјлӮҳ, BI лҸ„кө¬л“ӨмқҖ лӢӨлҘё кІ°кіјлҘј лӮҙм—ҲмқҢ В§пӮ§вҖҜ мҳҲмёЎ лӘЁлҚёмқ„ лҚ°мқҙн„° мЈјлҸ„ мқ‘мҡ© н”„лЎңк·ёлһЁм—җ мүҪкІҢ нҶөн•© В§пӮ§вҖҜ мҳҲмёЎ лӘЁлҚёмқ„ StormмқҙлӮҳ м—¬лҹ¬л¶„ нҡҢмӮ¬ лӮҙмқҳ лӢӨлҘё м–ҙл–Ө мқ‘мҡ© н”„лЎңк·ёлһЁм—җ лқјлҸ„ кө¬лҸҷ В§пӮ§вҖҜ мң„мқҳ лӘЁл“ лӮҙмҡ©мқ„ л©ҖнӢ°н„°л„ҢнҠё YARN нҒҙлҹ¬мҠӨн„°м—җ кө¬лҸҷ В§пӮ§вҖҜ YARNм—җм„ң лҢҖк·ңлӘЁ кё°кі„ н•ҷмҠөмқҖ HDP нҒҙлҹ¬мҠӨн„°мқҳ лӢӨлҘё мһ‘м—…л“Өмқ„ мЎҙмӨ‘
- 51. Page 51 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved Storm Boltм—җм„ң SparkлҘј нҳём¶ң В§пӮ§вҖҜ лЎңм§ҖмҠӨнӢұ нҡҢк·Җ лӘЁлҚёмқҳ м¶ңл ҘмқҖ к°ҖмӨ‘м№ҳл“Өкіј н•ҳлӮҳмқҳ м ҲнҺё: val algorithm = new LogisticRegressionWithSGD() val model = algorithm.run(training).clearThreshold() println(model.weights) println(model.intercept) Weights[-0.40819922025591465,0.06392530395655666,-0.1346227352186122,-0.07188217286407801,0.7277326276521062 ,0.508779221680863,-0.024689093098281954] Intercept 0.0 В§пӮ§вҖҜ н•ҙлӢ№ лӘЁлҚёмқҖ мҳҲмёЎмқ„ л§Ңл“Өкё° мң„н•ҙ мң„мқҳ к°ҖмӨ‘м№ҳмҷҖ н•Ёк»ҳ Storm boltм—җм„ң мһ¬мғқм„ұлҗ мҲҳ мһҲ мқҢ import org.apache.spark.mllib.classification.LogisticRegressionModel; import org.apache.spark.mllib.linalg.Vectors; вҖҰвҖҰвҖҰ.. Vector weights = (Vectors.dense(new double[] <array of weights like above>) LogisticRegressionModel model = new LogisticRegressionModel(weights, 0.0); double prediction = model.predict(<input features>)
- 52. Page 52 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved к°җмӮ¬н•©лӢҲлӢӨ Page 52 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved
- 53. Page 53 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved This presentation contains forward-looking statements involving risks and uncertainties. Such forward- looking statements in this presentation generally relate to future events, our ability to increase the number of support subscription customers, the growth in usage of the Hadoop framework, our ability to innovate and develop the various open source projects that will enhance the capabilities of the Hortonworks Data Platform, anticipated customer benefits and general business outlook. In some cases, you can identify forward-looking statements because they contain words such as вҖңmay,вҖқ вҖңwill,вҖқ вҖңshould,вҖқ вҖңexpects,вҖқ вҖңplans,вҖқ вҖңanticipates,вҖқ вҖңcould,вҖқ вҖңintends,вҖқ вҖңtarget,вҖқ вҖңprojects,вҖқ вҖңcontemplates,вҖқ вҖңbelieves,вҖқ вҖңestimates,вҖқ вҖңpredicts,вҖқ вҖңpotentialвҖқ or вҖңcontinueвҖқ or similar terms or expressions that concern our expectations, strategy, plans or intentions. You should not rely upon forward-looking statements as predictions of future events. We have based the forward-looking statements contained in this presentation primarily on our current expectations and projections about future events and trends that we believe may affect our business, financial condition and prospects. We cannot assure you that the results, events and circumstances reflected in the forward-looking statements will be achieved or occur, and actual results, events, or circumstances could differ materially from those described in the forward-looking statements. The forward-looking statements made in this prospectus relate only to events as of the date on which the statements are made and we undertake no obligation to update any of the information in this presentation. Trademarks Hortonworks is a trademark of Hortonworks, Inc. in the United States and other jurisdictions. Other names used herein may be trademarks of their respective owners. Page 53 В© Hortonworks Inc. 2011 вҖ“ 2015. All Rights Reserved