










![14
Spark SQL application (in Java)
? (DataFrame example 2) Text File : Specifying the Schema
SparkConf sparkConf = new SparkConf().setAppName("dataFrame");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx);
JavaRDD<String> people = ctx.textFile("examples/src/main/resources/people.txt");
String schemaString = "name age";
List<StructField> fields = new ArrayList<StructField>();
for (String fieldName: schemaString.split(" ")) {
fields.add(DataTypes.createStructField(fieldName, DataTypes.StringType, true));
}
StructType schema = DataTypes.createStructType(fields);
JavaRDD<Row> rowRDD = people.map(new Function<String, Row>() {
public Row call(String record) throws Exception {
String[] fields = record.split(",");
return RowFactory.create(fields[0], fields[1].trim());
}
});
DataFrame peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema);
peopleDataFrame.show();//1
peopleDataFrame.printSchema();//2
ctx.stop();
1.
2.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.DataFrame;
import java.util.List;](https://image.slidesharecdn.com/sparksql-160119142112/85/Spark-sql-14-320.jpg)

![16
Spark SQL application (in Java)
? (DataFrame example 3) Text File : Inferring the Schema(JavaBean)
SparkConf sparkConf = new SparkConf().setAppName("dataFrame");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx);
JavaRDD<Person> people = ctx.textFile("examples/src/main/resources/people.txt").map(
new Function<String, Person>() {
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
}});
DataFrame schemaPeople = sqlContext.createDataFrame(people, Person.class);
schemaPeople.registerTempTable("people");
DataFrame teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19");
teenagers.show();//1
teenagers.printSchema();//2
ctx.stop();
1.
2.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import java.util.ArrayList;
import java.util.List;](https://image.slidesharecdn.com/sparksql-160119142112/85/Spark-sql-16-320.jpg)














![[NDC18] ??? ? ???? ??? ????? ???: ?? ??? ?? ?? ?? (2?)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=560&fit=bounds)
![[135] ???? ????????? ??????????? ??? ?? ???????? ????????](https://cdn.slidesharecdn.com/ss_thumbnails/135-161023163934-thumbnail.jpg?width=560&fit=bounds)


![[Play.node] node.js ? ??? ??? ???(+??) ???](https://cdn.slidesharecdn.com/ss_thumbnails/playnode20161123slideshare-161125153022-thumbnail.jpg?width=560&fit=bounds)







![[NDC2016] TERA ??? Modern C++ ???](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=560&fit=bounds)



![[AIS 2018] [Team Tools_Basic] Confluence? ??? ??? - ?????](https://cdn.slidesharecdn.com/ss_thumbnails/teamtoolsbasicconfluencemou-180619235214-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Viewers also liked (20)






![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)



![[NoSQL] 2?. ??? ??? ??](https://cdn.slidesharecdn.com/ss_thumbnails/2-130323002448-phpapp02-thumbnail.jpg?width=560&fit=bounds)


![[NDC 2011] ?? ???? ?? ?????? ??](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2011ver5-140313211642-phpapp01-thumbnail.jpg?width=560&fit=bounds)




Similar to Spark sql (20)


![[2015 07-06-???] Oracle ?? ??? ? ?? ??? 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)

















Spark sql
- 2. 2 ?? ? Spark SQL ?? ? Tungsten execution engine ? Catalyst optimizer ? RDD, DataFrame ? Dataset ? Spark SQL application (in Java) ? Linking ? example ? ?? ??
- 3. 3 Spark SQL ? ??/??? ???(structured/semi-structured Data) ??? ??? Spark Library ? Tungsten execution engine & Catalyst optimizer ?? ? ??? interface ?? ? SQL, HiveSQL queries ? Dataframe API ? Scala, Java, Python, and R?? ?? ?? ? Spark 1.3 ? Dataset API ? Scala, Java ?? ?? ?? ? Spark 1.6 ? ??? Input source? ?? ? RDD & ?? ??? ? JSON ??? ? ? Parquet file ? Hive Table ? ODBC/JCBC ???? ??
- 4. 4 Tungsten execution engine ? ???? bottleneck?? ? I/O? network bandwidth? ?? ? High bandwidth SSD & striped HDD? ?? ? 10Gbps network? ?? ? CPU ? memory?? bottleneck ??? ?? ? ???? processing workload? ?? ? Disk I/O? ????? ?? input data pruning workload ? Shuffle? ?? serialization? hashing? ?? key bottleneck ? CPU? memory? ??? ???ˇ ? ????? ??? ??? ??? ??? ? ?? System Engine? ??! ? Project Tungsten ? Spark 1.4?? DataFrame? ?? ? spark 1.6?? Dataset?? ?? ??: 1. Project Tungsten ¨C databrick 2. https://issues.apache.org/jira/browse/SPARK-7075
- 5. 5 Tungsten execution engine ¨C three Goal ? Memory Management and Binary Processing ? JVM object ??? garbage collection? overhead? ? =>????? data? ??? ?? Java objects ??? binary format?? ?? ? ???? ?? ???? ??? ??? ?? => denser in-memory data format? ???? ??? ???? ??? ? ? ?? memory accounting (size of bytes) ?? ??(??? Heuristics ??) ? ?? ???? ??? domain semantics? ??? ??? data processing? ???? ? =>binary format? in memory data? ???? data type? ???? operator? ?? (serialization/deserialization ?? data processing) ? Cache-aware Computation ? sorting and hashing for aggregations, joins, and shuffle? ??? ??? ?? =>memory hierarchy? ???? algorithm? data struncture ? Code Generation ? expression evaluation, DataFrame/SQL operators, serializer? ?? ??? ?? =>modern compilers and CPUs? ??? ??? ??? ? ?? code generation
- 6. 6 Catalyst optimizer ? ??? ??? ????? ?? ??? ?? ??? extensible optimizer ? extensible design ? ??? optimization techniques? feature?? ??? ?? ? ?? ???? optimizer? ???? ???? ?? ? Catalyst? ?? (In Spark SQL) ( ??? ??? paper ??) ? Tree ??? ???? optimization ? ?? 4??? ?? ?? ??: Catalyst Optimizer - databrick x+(1+2) ? tree ?? Catalyst? phase
- 7. 7 RDD, DataFrame DataFrames / SQL Structured Binary Data (Tungsten) ? High level relational operation ?? ?? ? Catalyst optimization ?? ?? ? Lower memory pressure ? Memory accounting (avoid OOMs) ? Faster sorting / hashing / serialization RDDs Collections of Native JVM Objects ? ?? ?? ?? data type ??? ?? ? Compile-time type-safety ?? ? ??? ????? ?? ? ? ?? ?? ??? ?? ???.. ? ?? ?? cost ? ??? ?? boilerplate(?? ??, ??) ?? ?? ? ?? ??? ???? API? ??? ? ???? ? Catalyst optimizer & Tungsten execution engine? ??? ??? ? ??? ? ? Domain object? type? ??? ? ?? ?? ??? ? ??? ? ?? ˇü??? & ??? ˇü
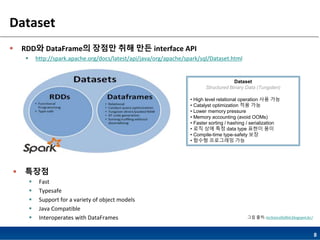
- 8. 8 Dataset ? RDD? DataFrame? ??? ?? ?? interface API ? http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Dataset.html ? ??? ? Fast ? Typesafe ? Support for a variety of object models ? Java Compatible ? Interoperates with DataFrames Dataset Structured Binary Data (Tungsten) ? High level relational operation ?? ?? ? Catalyst optimization ?? ?? ? Lower memory pressure ? Memory accounting (avoid OOMs) ? Faster sorting / hashing / serialization ? ?? ?? ?? data type ??? ?? ? Compile-time type-safety ?? ? ??? ????? ?? ?? ??: technicaltidbit.blogspot.kr/
- 9. 9 Dataset ? Encoder ? Dataset? ??? ??? Structured Binary data? ?? ? JVM object? RDD? ??, DataFrame?? ??? ?? ? Processing ? ??? ???? serialization? ?? ? RDD/DataFrame type? data? Dataset?? ???? ???? Object? ??? ?? ??? Encoder? ??(?? ????? ???? ??) ? ?? ???? ???? java, kyro Serialization? ?? ?? ??? Data Serialization ?? ?? ?? ??: Introducing Spark Datasets- databrick
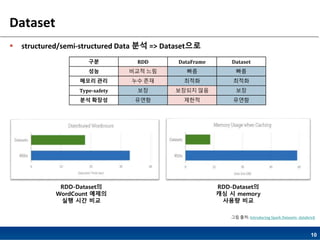
- 10. 10 Dataset ? structured/semi-structured Data ?? => Dataset?? ?? RDD DataFrame Dataset ?? ??? ?? ?? ?? ??? ?? ?? ?? ??? ??? Type-safety ?? ???? ?? ?? ?? ??? ??? ??? ??? RDD-Dataset? WordCount ??? ?? ?? ?? RDD-Dataset? ?? ? memory ??? ?? ?? ??: Introducing Spark Datasets- databrick
- 11. 11 Spark SQL application (in Java) ? Linking ? Pom.xml? ?? ?? ??
- 12. 12 Spark SQL application (in Java) ? sample examples/src/main/resources/people.json examples/src/main/resources/people.txt
- 13. 13 Spark SQL application (in Java) ? (DataFrame example 1) Jason File SparkConf sparkConf = new SparkConf().setAppName("dataFrame"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx); DataFrame df = sqlContext.read().json("examples/src/main/resources/people.json"); df.show();//1 df.printSchema();//2 df.select("name").show(); //3 df.select(df.col("name"), df.col("age").plus(1)).show(); //4 df.filter(df.col("age").gt(21)).show(); //5 df.groupBy("age").count().show();//6 df.registerTempTable("people"); DataFrame results = sqlContext.sql("SELECT name FROM people"); List<String> names = results.javaRDD().map(new Function<Row, String>() { public String call(Row row) {return "Name: " + row.getString(0); } }).collect(); for(String tuple : names){ //7 System.out.println(tuple); } ctx.stop(); 1. 2. 3. 4. 5. 6. 7. import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row;
- 14. 14 Spark SQL application (in Java) ? (DataFrame example 2) Text File : Specifying the Schema SparkConf sparkConf = new SparkConf().setAppName("dataFrame"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx); JavaRDD<String> people = ctx.textFile("examples/src/main/resources/people.txt"); String schemaString = "name age"; List<StructField> fields = new ArrayList<StructField>(); for (String fieldName: schemaString.split(" ")) { fields.add(DataTypes.createStructField(fieldName, DataTypes.StringType, true)); } StructType schema = DataTypes.createStructType(fields); JavaRDD<Row> rowRDD = people.map(new Function<String, Row>() { public Row call(String record) throws Exception { String[] fields = record.split(","); return RowFactory.create(fields[0], fields[1].trim()); } }); DataFrame peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema); peopleDataFrame.show();//1 peopleDataFrame.printSchema();//2 ctx.stop(); 1. 2. import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.DataFrame; import java.util.List;
- 15. 15 Spark SQL application (in Java) ? (DataFrame example 3) Text File : Inferring the Schema(JavaBean) import java.io.Serializable; public class Person implements Serializable { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
- 16. 16 Spark SQL application (in Java) ? (DataFrame example 3) Text File : Inferring the Schema(JavaBean) SparkConf sparkConf = new SparkConf().setAppName("dataFrame"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx); JavaRDD<Person> people = ctx.textFile("examples/src/main/resources/people.txt").map( new Function<String, Person>() { public Person call(String line) throws Exception { String[] parts = line.split(","); Person person = new Person(); person.setName(parts[0]); person.setAge(Integer.parseInt(parts[1].trim())); return person; }}); DataFrame schemaPeople = sqlContext.createDataFrame(people, Person.class); schemaPeople.registerTempTable("people"); DataFrame teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19"); teenagers.show();//1 teenagers.printSchema();//2 ctx.stop(); 1. 2. import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructType; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import java.util.ArrayList; import java.util.List;
- 17. 17 Spark SQL application (in Java) ? (Dataset example) SparkConf sparkConf = new SparkConf().setAppName("dataset"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx); ... DataFrame schemaPeople = sqlContext.createDataFrame(people, Person.class); Dataset<Person> schools = schemaPeople.as(Encoders.bean(Person.class)); Dataset<String> strings = schools.map(new BuildString(), Encoders.STRING()); //Dataset<String> strings = schools.map(p-> p.getName()+" is "+ p.getAge()+" years old.", Encoders.STRING()); List<String> result = strings.collectAsList(); for(String tuple : result){//1 System.out.println(tuple); } ctx.stop(); class BuildString implements MapFunction<Person, String> { public String call(Person p) throws Exception { return p.getName() + " is " + p.getAge() + " years old."; } } 1. import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.MapFunction; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Encoders; import java.util.List;
- 18. 18 Spark SQL application (in Java) ? (Dataset example) Encoder ? http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Encoder.html ? http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Encoders.html 1. Primitive type ??? List<String> data = Arrays.asList("abc", "abc", "xyz"); Dataset<String> ds = context.createDataset(data, Encoders.STRING()); 2. tuple type(K,V pair) ??? Encoder<Tuple2<Integer, String>> encoder2 = Encoders.tuple(Encoders.INT(), Encoders.STRING()); List<Tuple2<Integer, String>> data2 = Arrays.asList(new scala.Tuple2(1, "a"); Dataset<Tuple2<Integer, String>> ds2 = context.createDataset(data2, encoder2); 3. Java Beans? ??? reference type ??? Encoders.bean(MyClass.class);
- 19. 19 ?? ?? ? Dataset ? https://issues.apache.org/jira/browse/SPARK-9999 ? http://spark.apache.org/docs/latest/sql-programming-guide.html ? http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Dataset.html ? http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Encoder.html ? https://databricks.com/blog/2015/11/20/announcing-spark-1-6-preview-in-databricks.html ? https://docs.cloud.databricks.com/docs/spark/1.6/index.html#examples/Dataset%20Aggregator.html ? http://technicaltidbit.blogspot.kr/2015/10/spark-16-datasets-best-of-rdds-and.html ? http://www.slideshare.net/databricks/apache-spark-16-presented-by-databricks-cofounder-patrick-wendell ? Tungsten ? https://issues.apache.org/jira/browse/SPARK-7075 ? https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html ? catalyst ? https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html ? Michael Armbrust et al. Spark SQL: Relational Data Processing in Spark, In SIGMOD , 2015