
















![手法 BRISK ORB
パッチ方向
推定
Local gradientの
平均ベクトル
Intensity Centroid
ペアの
選び方
規則的に決定 教師なし学習
BRIEFに Scale/Rotation Invariance を導入
Fast Corner Detector + BRIEF
BRISK: Binary Robust Invariant Scalable Keypoints. [ICCV2011]より図を引用
ORB: An Efficient Alternative to SIFT and SURF. [ICCV2011]より図を引用
BRISKとORB](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-23-320.jpg)




![Greedy Algorithmによるサンプリング位置の決定
ORB: Oriented FAST and Rotated BRIEF
[ 戦略 ]
パッチ内の考えられうる全てのペア(205590通り)について、
ビットの分散最大&ビット間の相関最小な256個のペアを選出
Step 1.
学習用画像を処理し、全ペアの
分散を求め、分散最大のペアを採用
Step 2.
残りのペアの中で、採用済みペア
と相関が低くかつ分散最大なもの
を採用
Step 3.
256個決まるまで、Step2を繰り返す](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-30-320.jpg)



































![深層学習を用いた手法
Discriminative Learning of Deep Convolutional
Feature Point Descriptors (CNN Descriptor)
[Simo-serra, ICCV2015]
Learning to Compare Image Patches via
Convolutional Neural Networks (CNN Similarity)
[Zagoruyko, CVPR2015]](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-74-320.jpg)

![CNN Descriptor [Simo-serra, ICCV2015]
CNNを利用したパッチ画像の特徴量抽出
畳み込み層のみを使用し,全結合層は使用しない
CNNの構成
入力:パッチ画像,出力:特徴量(128次元)
活性化関数:hyperbolic tangent
プーリング:L2プーリング
畳み込み層 (特徴抽出部)
特徴量](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-76-320.jpg)


![Hard negative and positive mining
マッチングが困難なペアに対するCNNの更新
順伝播によりhard negative, positiveのペアを求める
hard negativeとhard positiveに対して再度逆伝播
Simo-serra, et al., “Discriminative Learning of Deep Convolutional Feature Point Descriptors”,
ICCV, 2015. ポスターより、図の一部を引用
? Consistent improvements over the state of the art.
? Trained in one dataset, but generalizes very well to scaling, rota-
tion, deformation and illumination changes.
? Computational ef?ciency (on GPU: 0.76 ms; dense SIFT: 0.14 ms).
Code is available: https:/ / github.com/ etrulls/ deepdesc-release
Key observation
1. We train a Siamese architecture with pairs of patches. We want
to bringmatching pairstogether and otherwise pull them apart.
2. Problem? Randomly sampled pairs are already easy to separate.
3. Solution: To train discriminative networks we use hard negative
and positive mining. This proves essential for performance.
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
positives (+, long blue segments) and sim-
ilar negatives (× , short red segments):
(d) Random sampling results in easy pairs.
(e) Mined pairs with harder correspondences.
(d) Random pairs
(e) Mined pairs
This allows us to train discriminative models with a small number
of parameters (~45k), which also alleviates over?tting concerns.
Stride 2 3 4
Train on the M VS Dataset [1]. 64 × 64 grayscale pat
Statue of Liberty (LY, top), NotreDame (ND, center)
bottom). ~150k points and ~450k patches each ? 10
and 1012
negative pairs? Ef?cient exploration wit
Weminimizethehingeembedding loss. With 3D po
l(x1, x2)=
∥D(x1) ? D(x2)∥2,
max(0, C ? ∥D(x1) ? D(x2)∥2),
This penalizes corresponding pairs that are placed
non-corresponding pairs that are less than C units a
M ethodology: Train over two setsand test over third
with cross-validation. Metric: precision-recall (PR
haystack’ setting: pick 10k unique points and gen
tive pair and 1k negative pairs for each, i.e. 10k po
negatives. Results summarized by ‘Area Under the
Effect of mining
(a) Forward-propagate positives sp ≥ 128 and negat
(b) Pick the 128 with the largest loss (for each) and b
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, training LY+YO, test ND
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
PR curve, training LY+ND, test YO
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
0 0.1 0.2 0.3
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, tr
sp sn PR AUC
128 128 0.366
256 256 0.374
512 512 0.369
1024 1024 0.325
Table 1: (a) No mining.
Larger batches do not help.
sp sn rp rn Cos
128 256 1 2 20%
256 256 2 2 35%
512 512 4 4 48%
1024 1024 8 8 67%
Table 2: (b) Mining with rp =
The mining cost is incurred d
available: https:/ / github.com/ etrulls/ deepdesc-release
bservation
ain a Siamese architecture with pairs of patches. We want
ngmatching pairstogether and otherwisepull them apart.
em? Randomly sampled pairs are already easy to separate.
ion: To train discriminative networks we use hard negative
positive mining. This proves essential for performance.
points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
samples from [1], for illustration. Cor-
ing patchesareshown with samecolor:
bottom). ~150k points
and 1012
negative pa
Weminimizethehing
l(x1, x2)=
m
This penalizes corres
non-corresponding p
M ethodology: Train o
with cross-validation
haystack’ setting: pic
tive pair and 1k nega
negatives. Results sum
Effect of mining
(a) Forward-propaga
(b) Pick the 128 with
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
(d) Random pairs
各パッチ画像の特徴量の距離空間
同じ色のパッチ
↓
対応点
赤:negativeペア
青:positiveペア
hard positive
hard negative
hard negativeとhard positiveに適したネットワークに更新](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-79-320.jpg)

![CNN Similarity [Zagoruyko, CVPR2015]
CNNによりパッチ画像間の類似度を算出
畳み込み層で特徴抽出,全結合層で2枚のパッチ画像の
類似度を算出
CNNの構成
入力:パッチ画像,出力:パッチ画像間の類似度
活性化関数:Rectified Linear Unit (ReLU)
プーリング:Maxプーリング
5種類のCNNモデルを提案
2-channelモデル
Siameseモデル
Pseudo-siameseモデル
Central-surround two-stream networkモデル
Spatial Pyramid Pooling networkモデル](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-82-320.jpg)





![深層学習による特徴量表現 まとめ
学習でマイニング等の工夫を加えることで
特徴量記述の性能向上
特徴抽出と類似度をend-to-endで学習
特徴量記述の処理速度が課題
1つの特徴量記述に要する時間
CNN Descriptor (CPU) 4.81 [ms]
CNN Descriptor (GPU) 0.76 [ms]
SIFT 0.14 [ms]
今後の予想される展開
キーポイント検出も含めてend-to-endで学習
可視光カメラと赤外光カメラ間での対応点探索](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-90-320.jpg)



![従来のキーポイント検出
Rotation invariant
Scale invariant
Affine invariant
アフィン不変なキーポイント検出が
提案されていない
提案手法
[Hasegawa2015]](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-94-320.jpg)





![関連文献
— [SIFT]
David G. Lowe, "Distinctive image features from scale-Invariant
keypoints," IJCV2004
— [SURF]
Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool, “Speeded-
up robust features (SURF),” CVIU2008.
— [PCA-SIFT]
Yan Ke and Rahul Sukthankar, “PCA-SIFT: A more distinctive
representation for local image descriptors,” CVPR2004
— [GLOH]
Krystian Mikolajczyk and Cordelia Schmid, “A performance evaluation of
local descriptors,“ TPAMI2005
— [RIFF]
Gabriel Takacs, Vijay Chandrasekhar, Sam Tsai, David Chen, Radek
Grzeszczuk, and Bernd Girod, "Unified real-time tracking and recognition
with rotation-invariant fast features," CVPR2010
— [ASIFT]
Jean-Michel Morel and Guoshen Yu, "ASIFT: A new framework for fully
affine invariant image comparison" SIAM Journal on Imaging Sciences,
Vol. 2, No. 2, pp. 438-469, April 2009.
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-101-320.jpg)
![関連文献
— [BRIEF]
M.Calonder, V.Lepetit, and P.Fua, “BRIEF: Binary Robust Independent
Elementary Features,” ECCV2010
— [BRISK]
S.Leutenegger, M.Chli and R.Siegwart, "BRISK: Binary Robust Invariant
Scalable Keypoints,“ ICCV2011
— [ORB]
E.Rublee, V.Rabaud, K.Konolige and G.Bradsk, "ORB: an efficient
alternative to SIFT or SURF,“ ICCV2011
— [FREAK]
Alexandre Alahi, Raphael Ortiz, and Pierre Vandergheynst, “FREAK: Fast
retina keypoint," CVPR2012
— [D-BRIEF]
Tomasz Trzcinski and Vincent Lepetit, "Efficient discriminative projections
for compact binary descriptors," ECCV2012
— [BinBoost]
T. Trzcinski, M. Christoudias, V. Lepetit, and P. Fua, "Boosting binary
keypoint descriptors," CVPR2013
— [BOLD]
V. Balntas, L. Tang, and K. Mikolajczyk. BOLD - binary online learned
descriptor for efficient image matching. CVPR2015
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-102-320.jpg)
![関連文献
— [CARD]
M.Ambai and Y.Yoshida, “Compact And Real-time Descriptors, ” in Proc.
ICCV2011
— [LDA Hash]
C. Strecha, A.M. Bronstein, M.M. Bronstein, and Pee. Fua, "LDAHash:
Improved matching with smaller descriptors," TPAMI2012
— [CNN Descriptor]
E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-
Noguer, "Discriminative learning of deep convolutional feature point
descriptors," ICCV2015
— [CNN Similarity]
S. Zagoruyko and N. Komodakis. Learning to compare image patches via
convolutional neural networks," CVPR2015
— [Spectral Affine SIFT]
Takahiro Hasegawa, Mitsuru Ambai, Kohta Ishikawa, Gou Koutaki, Yuji
Yamauchi, Takayoshi Yamashita, Hironobu Fujiyoshi, "Multiple-Hypothesis
Affine Region Estimation With Anisotropic LoG Filters," ICCV2015
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-103-320.jpg)











![[DL輪読会]EfficientDet: Scalable and Efficient Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/191122dlseminar-191122013544-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=560&fit=bounds)



















More Related Content
What's hot (20)
Recently uploaded (13)






![ElasticsearchでSPLADEする [Search Engineering Tech Talk 2025 Winter]](https://cdn.slidesharecdn.com/ss_thumbnails/searchtech-250228102455-ddc5ce09-thumbnail.jpg?width=560&fit=bounds)




2015年12月PRMU研究会 対応点探索のための特徴量表現
- 1. 対応点探索のための特徴量表現 安倍 満 (デンソーアイティーラボラトリ) 長谷川 昂宏, 藤吉 弘亘 (中部大学) 2015/12/21 PRMU研究会 ~サーベイ論文発表~
- 3. 今日の話のポイントは? 過去に提案されてきた手法を, (1) 実数ベクトルで局所特徴量を表現する方法 (2) 二値ベクトルで局所特徴量を表現する方法 (3) 深層学習による方法 以上3つの分類に整理してご紹介します.
- 4. ? 対応点探索の基本概念と動向 ? 実数ベクトルで局所特徴量を表現する方法 ? 二値ベクトルで局所特徴量を表現する方法 ? 深層学習による方法 ? まとめ
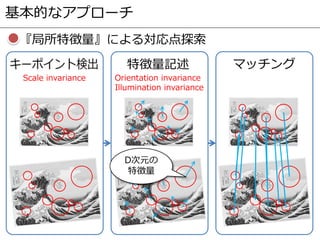
- 5. 基本的なアプローチ 特徴量記述 マッチング Scale invariance Orientation invariance Illumination invariance D次元の 特徴量 『局所特徴量』による対応点探索
- 8. ? 対応点探索の基本概念と動向 ? 実数ベクトルで局所特徴量を表現する方法 ? 二値ベクトルで局所特徴量を表現する方法 ? 深層学習による方法 ? まとめ
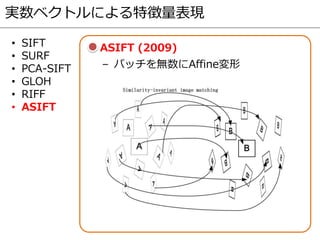
- 9. 実数ベクトルによる特徴量表現 ? SIFT ? SURF ? PCA-SIFT ? GLOH ? RIFF ? ASIFT SIFT (1999) SURF (2006) – スケール&方向正規化 – 勾配方向ヒストグラム抽出 – Integral imageの活用による高速化
- 10. 実数ベクトルによる特徴量表現 ? SIFT ? SURF ? PCA-SIFT ? GLOH ? RIFF ? ASIFT GLOH (2005) – 勾配方向ヒストグラムのbin配置を変更 – PCAによる次元削減 PCA-SIFT (2004) – 勾配画像+PCAによる次元削減
- 11. 実数ベクトルによる特徴量表現 ? SIFT ? SURF ? PCA-SIFT ? GLOH ? RIFF ? ASIFT RIFF (2010) – 局所特徴量自体に回転不変性を導入 回転不変な輝度勾配 パッチのセル分割
- 12. 実数ベクトルによる特徴量表現 ? SIFT ? SURF ? PCA-SIFT ? GLOH ? RIFF ? ASIFT ASIFT (2009) – パッチを無数にAffine変形
- 14. ? 対応点探索の基本概念と動向 ? 実数ベクトルで局所特徴量を表現する方法 ? 二値ベクトルで局所特徴量を表現する方法 ? 深層学習による方法 ? まとめ
- 16. ユークリッド距離の二乗 v.s. ハミング距離 128 dim. 512 bits 128 bits 64 bits 32 bits 256 bits 0 0.05 0.1 0.15 0.2 0.25 CPU: Intel Core2 Duo 2.66GHz (nsec) バイナリコード ベクトル (単精度実数) 類似度計算速度の比較 ※ルックアップテーブルによる計算
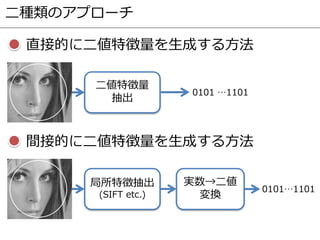
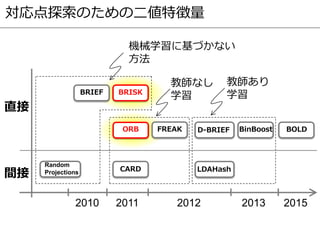
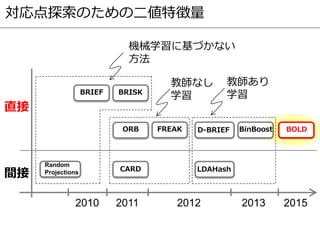
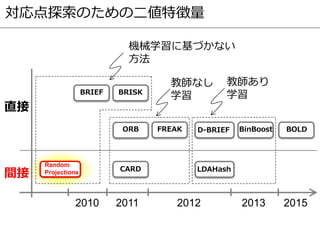
- 18. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 19. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
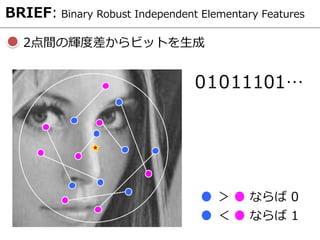
- 20. 2点間の輝度差からビットを生成 0 101 1101… > ならば 0 < ならば 1 BRIEF: Binary Robust Independent Elementary Features
- 21. BRIEF: Binary Robust Independent Elementary Features 正規分布に基づく乱数でサンプリング位置を決定
- 22. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 23. 手法 BRISK ORB パッチ方向 推定 Local gradientの 平均ベクトル Intensity Centroid ペアの 選び方 規則的に決定 教師なし学習 BRIEFに Scale/Rotation Invariance を導入 Fast Corner Detector + BRIEF BRISK: Binary Robust Invariant Scalable Keypoints. [ICCV2011]より図を引用 ORB: An Efficient Alternative to SIFT and SURF. [ICCV2011]より図を引用 BRISKとORB
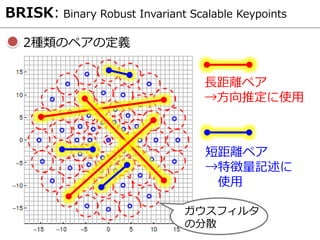
- 24. 2種類のペアの定義 BRISK: Binary Robust Invariant Scalable Keypoints 長距離ペア →方向推定に使用 短距離ペア →特徴量記述に 使用 ガウスフィルタ の分散
- 25. パッチ方向推定 BRISK: Binary Robust Invariant Scalable Keypoints 長距離ペアの Local gradientを定義 方向:暗→明 長さ:輝度差 Local gradientの 平均をパッチ方向 として使用
- 26. BRISK: Binary Robust Invariant Scalable Keypoints バイナリコード生成 Step 1. パッチ方向に 従ってサンプリング パターンを回転 (Lookup tableを使用) Step 2. 短距離ペアを用いて 512bitのバイナリ コードを生成
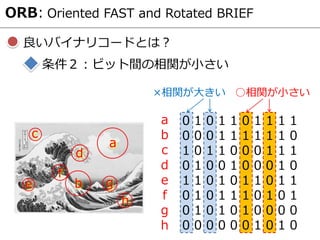
- 27. ORB: Oriented FAST and Rotated BRIEF パッチ方向推定 (Intensity centroid) Intensity centroid (パッチの重心) C ? ?? = ?,? ? ? ? ? ?(?, ?) ? = ?10 ?00 , ?01 ?00
- 28. 良いバイナリコードとは? ORB: Oriented FAST and Rotated BRIEF 条件1:各ビットの分散が大きい 0 1 0 1 1 0 1 1 1 1 0 0 0 1 1 1 1 1 1 0 1 0 1 1 0 0 0 1 1 1 0 1 0 0 1 0 0 0 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 a b c d e f g h a b c d e f g h ×分散が小さい ○分散が大きい
- 29. 良いバイナリコードとは? ORB: Oriented FAST and Rotated BRIEF 条件2:ビット間の相関が小さい 0 1 0 1 1 0 1 1 1 1 0 0 0 1 1 1 1 1 1 0 1 0 1 1 0 0 0 1 1 1 0 1 0 0 1 0 0 0 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 a b c d e f g h a b c d e f g h ○相関が小さい×相関が大きい
- 30. Greedy Algorithmによるサンプリング位置の決定 ORB: Oriented FAST and Rotated BRIEF [ 戦略 ] パッチ内の考えられうる全てのペア(205590通り)について、 ビットの分散最大&ビット間の相関最小な256個のペアを選出 Step 1. 学習用画像を処理し、全ペアの 分散を求め、分散最大のペアを採用 Step 2. 残りのペアの中で、採用済みペア と相関が低くかつ分散最大なもの を採用 Step 3. 256個決まるまで、Step2を繰り返す
- 31. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
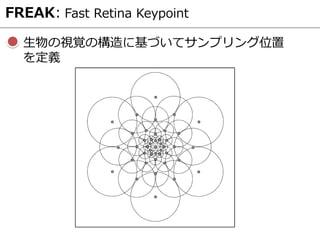
- 32. FREAK: Fast Retina Keypoint 生物の視覚の構造に基づいてサンプリング位置 を定義
- 33. FREAK: Fast Retina Keypoint ORBの教師なし学習により512ペアを選定 1~128 129~256 257~384 385~512 coarse fine 最初に選定されたペアほど、パッチの大局的な構造をとらえて いることに着目し、マッチングするときは128ビット単位で 早期棄却を行う。→ 90%が上位の128ビットで棄却
- 34. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 36. D-BRIEF: Discriminative BRIEF 輝度 ? に対する線形の Binary Hashing Hashのパラメータ ??, ?? を教師あり学習で求める ? = ?? = sgn(?? ? ? + ??)? 番目のビット: ?? = ? ― +
- 37. D-BRIEF: Discriminative BRIEF 輝度 ? に対する線形の Binary Hashing Hashのパラメータ ??, ?? を教師あり学習で求める ? = ?? = sgn(?? ? ? + ??)? 番目のビット: ?? = ― + BRIEF, BRISK, ORB, FREAKの場合 (??=0) サンプリング ペア
- 38. D-BRIEF: Discriminative BRIEF 輝度 ? に対する線形の Binary Hashing Hashのパラメータ ??, ?? を教師あり学習で求める ? = ?? = sgn(?? ? ? + ??)? 番目のビット: ?? = ― + D-BRIEFの場合
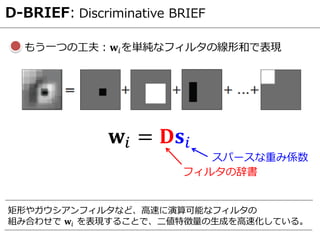
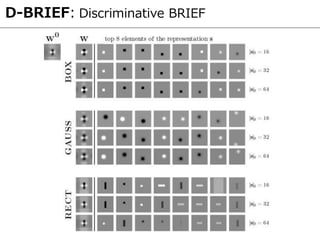
- 39. D-BRIEF: Discriminative BRIEF もう一つの工夫:??を単純なフィルタの線形和で表現 ?? = ??? フィルタの辞書 スパースな重み係数 矩形やガウシアンフィルタなど、高速に演算可能なフィルタの 組み合わせで ?? を表現することで、二値特徴量の生成を高速化している。
- 40. D-BRIEF: Discriminative BRIEF 定式化まとめ Negative ペア間のHamming 距離 Positive ペア間のHamming 距離 係数を疎に誘導 ビット間の相関を取り除く コスト関数の定義 ?? = sgn(?? ? ? + ??)? 番目のビット: ?? = ???? 番目の重み係数:
- 41. コスト関数最小化の方針 D-BRIEF: Discriminative BRIEF まともに解くのは不可能なので、?? → ?? → ??の順番に解く ??の解き方 ??に関するL1正則化を無視/sgn関数を取り除いて緩和 ??の解き方 ??の解き方 一次元サーチで網羅的に探索 (??はビット毎に独立)
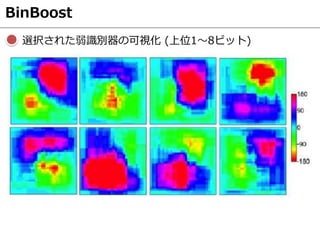
- 43. BinBoost D-BRIEFとの違い 非線形の弱識別器の出力 + 線形のBinary Hashing 弱識別器の選択方法としてBoostingの考え方を応用 ? 番目のビット ?? ? : K個の弱識別器の出力(K次元のベクトル) ??: 重みベクトル 定式化 求めたいパラメータ
- 44. BinBoost 弱識別器の設計 勾配方向ヒストグラム h ?; ?, ?, ? ? ? ? h ?; ?, ?, ? = ?1 しきい値? より大きい場合
- 45. BinBoost 弱識別器の設計 勾配方向ヒストグラム h ?; ?, ?, ? ? ? ? h ?; ?, ?, ? = +1 しきい値? より小さい場合
- 46. BinBoost 弱識別器の設計 h ?; ?, ?, ? K個の弱識別器の重み付き和の符号で?番目のビットを定義
- 47. BinBoost Positive Positive Negative Negative 重み ? ?’ Step 1. ?1 ? ,?1を学習 学習サンプル
- 48. BinBoost Positive Positive Negative Negative 重み ? ?’ Step 2. 重みの更新 +1 +1 OK NG OK NG ?1(?) ?1(?′) +1 +1 +1 -1 -1 +1 学習サンプル
- 49. BinBoost Positive Positive Negative Negative 重み ? ?’ Step 3. ?2 ? ,?2を学習 (以下、繰り返し) 学習サンプル
- 51. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 52. BOLD: Binary Online Learned Descriptor パッチにaffine変形を適用し、変化しにくい ビットだけを使用
- 53. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 54. = × B×1 B×D D×1 変換行列 局所 特徴量 二値 特徴量 間接的に二値特徴量を生成する手法 局所特徴抽出 + 線形のBinary Hashing +? sgn ? ? ? D×1 しきい値 (SIFT, SURFなど)
- 55. 線形のBinary Hashingの幾何学的なイメージ ?? ? ? + ?? = 0 ? 番目のビット??は、特徴量 ? が 超平面?? ? ? + ?? = 0のどちら側にあるかで決まる 超平面 ? ? ? ? +1 ?1 線形のBinary Hashingの式: ? = ???(?? + ?)
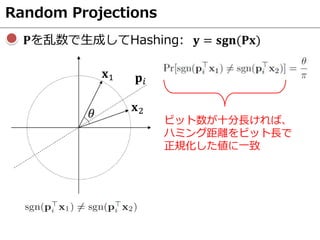
- 56. Random Projections ?を乱数で生成してHashing: ? = ???(??) ビット数が十分長ければ、 ハミング距離をビット長で 正規化した値に一致
- 57. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 58. キーポイント検出 (DoG) 勾配方向ヒストグラム 特徴量の抽出 LUTによる 勾配方向ヒストグラム 特徴量の抽出 キーポイント検出 (ピラミッド画像) 二値特徴量 変換 マッチング (ベクトル間角度) マッチング (ハミング距離) 128 dim. SIFT CARD 128 bits 136 dim. CARD: Compact And Real-time Descriptors
- 59. 計算のボトルネック B×D D×1 回数 D=136次元, B=128bits の場合 乗算 B×D 17408 加算 (D-1)×B 17280 ? = ???( ?? ) CARD: 二値特徴量変換
- 60. 高速化のための制約条件 回数 D=136次元, B=128bits の場合 乗算 0 0 加算 ?の 非ゼロ数 約1740 (※90%がゼロのとき) 変換行列?が疎 ?の要素は{-1,0,1}いずれかの値のみ CARD: 二値特徴量変換
- 61. 最適化による変換行列? の算出 2 ),( )),(),(()( ??? ?? vu vuhvu DDC bbddP ? Minimize Subject to the following conditions: }1,0,1{??ijp ? ? Spij 変換前の類似度(正規化ベクトル間角度) 変換後の類似度(正規化ハミング距離)学習用のペア — 変換前後で、類似度(距離)が保存される ように?を最適化 CARD: 二値特徴量変換
- 63. 対応点探索のための二値特徴量 2010 2011 2012 2013 間接 直接 BRIEF BinBoost BRISK FREAKORB D-BRIEF LDAHash Random Projections CARD 教師なし 学習 教師あり 学習 機械学習に基づかない 方法 BOLD 2015
- 64. LDAHash 間のHamming距離 → 最大化 間のHamming距離 → 最小化 Negativeペア Positiveペア 基本的な考え方はD-BRIEFと同じ (定式化も似ている) Positiveペア間の Hamming距離 Negativeペア間の Hamming距離 minimize ? = ???(?? + ?)
- 66. 各手法のまとめ 分類 特徴量 学習の 有無 記述能力 特徴抽出 の速度 特徴量の サイズ 直接 BRIEF 不要 ☆ ☆☆☆ ☆ 直接 BRISK 不要 ☆☆ ☆☆☆ ☆ 直接 ORB 教師なし ☆☆ ☆☆☆ ☆☆ 直接 FREAK 教師なし ☆☆ ☆☆☆ ☆ 直接 D-BRIEF 教師あり ☆☆☆ ☆☆ ☆☆☆ 直接 BinBoost 教師あり ☆☆☆☆ ☆ ☆☆☆ 直接 BOLD 教師なし ☆☆☆☆ ☆☆☆ ☆ 間接 Random Projections 不要 ☆ ☆ ☆ 間接 CARD 教師なし ☆☆ ☆☆☆ ☆☆ 間接 LDAHash 教師あり ☆☆☆ ☆ ☆☆☆
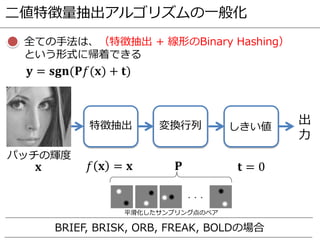
- 67. 二値特徴量抽出アルゴリズムの一般化 全ての手法は、(特徴抽出 + 線形のBinary Hashing) という形式に帰着できる ? = ???(??(?) + ?) 特徴抽出 変換行列 パッチの輝度 しきい値 ? ?(?) ? ? 出 力
- 68. 二値特徴量抽出アルゴリズムの一般化 全ての手法は、(特徴抽出 + 線形のBinary Hashing) という形式に帰着できる ? = ???(??(?) + ?) 特徴抽出 変換行列 パッチの輝度 しきい値 ? ? ? = ? ? ? = 0 出 力 BRIEF, BRISK, ORB, FREAK, BOLDの場合 平滑化したサンプリング点のペア ???
- 69. 二値特徴量抽出アルゴリズムの一般化 全ての手法は、(特徴抽出 + 線形のBinary Hashing) という形式に帰着できる ? = ???(??(?) + ?) 特徴抽出 変換行列 パッチの輝度 しきい値 ? ? ? = ? ? ? 出 力 D-BRIEFの場合 Pの各行は単純なフィルタの線形和 一次元探索で 計算
- 70. 二値特徴量抽出アルゴリズムの一般化 全ての手法は、(特徴抽出 + 線形のBinary Hashing) という形式に帰着できる ? = ???(??(?) + ?) 特徴抽出 変換行列 パッチの輝度 しきい値 ? ? ? ? ? = 0 出 力 BinBoostの場合 非線形の 弱識別器 弱識別器の 重み
- 71. 二値特徴量抽出アルゴリズムの一般化 全ての手法は、(特徴抽出 + 線形のBinary Hashing) という形式に帰着できる ? = ???(??(?) + ?) 特徴抽出 変換行列 パッチの輝度 しきい値 ? ? ? ? ? 出 力 Random Projections, CARD, LDAHashの場合 SIFT, SURF などの局所特徴量 一次元探索、 Mean centering など RP: CARD: LDAHash: ランダム 疎行列 の固有ベクトル
- 72. 特徴量 変換行列 ? しきい値 ? 特徴抽出 ?(?) BRIEF サンプリング点の輝度差 ? = 0 ?(?) = ? BRISK サンプリング点の輝度差 ? = 0 ?(?) = ? ORB サンプリング点の輝度差 ? = 0 ?(?) = ? FREAK サンプリング点の輝度差 ? = 0 ?(?) = ? D-BRIEF フィルタの線形和 一次元探索 ?(?) = ? BinBoost 弱識別器の重み ? = 0 非線形の弱識別器 BOLD サンプリング点の輝度差 ? = 0 ?(?) = ? Random Projections ランダム ? = 0 従来手法(SIFT, SURFな ど)+mean centering CARD {-1,0,+1}のいずれかの要素の みを取る疎行列 ? = 0 LUTによる勾配ヒスト グラム特徴量抽出 +mean centering LDAHash 固有ベクトル 一次元探索 従来手法 (SIFT, SURFなど) 二値特徴量抽出アルゴリズムの一般化
- 73. ? 対応点探索の基本概念と動向 ? 実数ベクトルで局所特徴量を表現する方法 ? 二値ベクトルで局所特徴量を表現する方法 ? 深層学習による方法 ? まとめ
- 74. 深層学習を用いた手法 Discriminative Learning of Deep Convolutional Feature Point Descriptors (CNN Descriptor) [Simo-serra, ICCV2015] Learning to Compare Image Patches via Convolutional Neural Networks (CNN Similarity) [Zagoruyko, CVPR2015]
- 75. Convolutional Neural Network (CNN) CV分野の多岐にわたるタスクで飛躍的に発展 一般物体認識,文字認識,顔認識,歩行者検出等 畳み込み層(特徴抽出)と全結合層(識別)で 構成されるニューラルネットワーク 教師信号との誤差を最小にする重みwを学習 → 順伝播と逆伝播を繰り返して重みwを更新 畳み込み層 (特徴抽出部) 全結合層 (識別部) 重みw 重みw 出力値 教師信号
- 76. CNN Descriptor [Simo-serra, ICCV2015] CNNを利用したパッチ画像の特徴量抽出 畳み込み層のみを使用し,全結合層は使用しない CNNの構成 入力:パッチ画像,出力:特徴量(128次元) 活性化関数:hyperbolic tangent プーリング:L2プーリング 畳み込み層 (特徴抽出部) 特徴量
- 78. CNN Descriptorの学習 学習画像:MVSデータセット 対応点パッチ:positiveペア,非対応点パッチ:negativeペア 特徴量のL2ノルムとヒンジ関数を組み合わせた ロス関数を使用 誤差逆伝播法により CNNを学習 ロス関数が最小となる重みフィルタwを更新 :ロス関数 :入力パッチ画像 :特徴量 :任意の定数 → PositiveペアはL2ノルムが小さく, NegativeペアはL2ノルムが大きくなるように学習
- 79. Hard negative and positive mining マッチングが困難なペアに対するCNNの更新 順伝播によりhard negative, positiveのペアを求める hard negativeとhard positiveに対して再度逆伝播 Simo-serra, et al., “Discriminative Learning of Deep Convolutional Feature Point Descriptors”, ICCV, 2015. ポスターより、図の一部を引用 ? Consistent improvements over the state of the art. ? Trained in one dataset, but generalizes very well to scaling, rota- tion, deformation and illumination changes. ? Computational ef?ciency (on GPU: 0.76 ms; dense SIFT: 0.14 ms). Code is available: https:/ / github.com/ etrulls/ deepdesc-release Key observation 1. We train a Siamese architecture with pairs of patches. We want to bringmatching pairstogether and otherwise pull them apart. 2. Problem? Randomly sampled pairs are already easy to separate. 3. Solution: To train discriminative networks we use hard negative and positive mining. This proves essential for performance. (a) 12 points/ 132 patches with t-SNE [8] (b) All pairs: pos/ neg (c) “ Hard” pairs: pos/ neg We take samples from [1], for illustration. Cor- responding patchesareshown with samecolor: (a) Representation from t-SNE [8]. Distance encodessimilarity. (b) Random sampling: similar (close) posi- tivesand different (distant) negatives. (c) We mine the samples to obtain dissimilar positives (+, long blue segments) and sim- ilar negatives (× , short red segments): (d) Random sampling results in easy pairs. (e) Mined pairs with harder correspondences. (d) Random pairs (e) Mined pairs This allows us to train discriminative models with a small number of parameters (~45k), which also alleviates over?tting concerns. Stride 2 3 4 Train on the M VS Dataset [1]. 64 × 64 grayscale pat Statue of Liberty (LY, top), NotreDame (ND, center) bottom). ~150k points and ~450k patches each ? 10 and 1012 negative pairs? Ef?cient exploration wit Weminimizethehingeembedding loss. With 3D po l(x1, x2)= ∥D(x1) ? D(x2)∥2, max(0, C ? ∥D(x1) ? D(x2)∥2), This penalizes corresponding pairs that are placed non-corresponding pairs that are less than C units a M ethodology: Train over two setsand test over third with cross-validation. Metric: precision-recall (PR haystack’ setting: pick 10k unique points and gen tive pair and 1k negative pairs for each, i.e. 10k po negatives. Results summarized by ‘Area Under the Effect of mining (a) Forward-propagate positives sp ≥ 128 and negat (b) Pick the 128 with the largest loss (for each) and b Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Precision 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 PR curve, training LY+YO, test ND SIFT CNN3, mined 1/2 CNN3, mined 2/2 CNN3, mined 4/4 CNN3, mined 8/8 Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Precision 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 PR curve, training LY+ND, test YO SIFT CNN3, mined 1/2 CNN3, mined 2/2 CNN3, mined 4/4 CNN3, mined 8/8 0 0.1 0.2 0.3 Precision 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 PR curve, tr sp sn PR AUC 128 128 0.366 256 256 0.374 512 512 0.369 1024 1024 0.325 Table 1: (a) No mining. Larger batches do not help. sp sn rp rn Cos 128 256 1 2 20% 256 256 2 2 35% 512 512 4 4 48% 1024 1024 8 8 67% Table 2: (b) Mining with rp = The mining cost is incurred d available: https:/ / github.com/ etrulls/ deepdesc-release bservation ain a Siamese architecture with pairs of patches. We want ngmatching pairstogether and otherwisepull them apart. em? Randomly sampled pairs are already easy to separate. ion: To train discriminative networks we use hard negative positive mining. This proves essential for performance. points/ 132 patches with t-SNE [8] (b) All pairs: pos/ neg (c) “ Hard” pairs: pos/ neg samples from [1], for illustration. Cor- ing patchesareshown with samecolor: bottom). ~150k points and 1012 negative pa Weminimizethehing l(x1, x2)= m This penalizes corres non-corresponding p M ethodology: Train o with cross-validation haystack’ setting: pic tive pair and 1k nega negatives. Results sum Effect of mining (a) Forward-propaga (b) Pick the 128 with (a) 12 points/ 132 patches with t-SNE [8] (b) All pairs: pos/ neg (c) “ Hard” pairs: pos/ neg We take samples from [1], for illustration. Cor- responding patchesareshown with samecolor: (a) Representation from t-SNE [8]. Distance encodessimilarity. (b) Random sampling: similar (close) posi- tivesand different (distant) negatives. (c) We mine the samples to obtain dissimilar (d) Random pairs 各パッチ画像の特徴量の距離空間 同じ色のパッチ ↓ 対応点 赤:negativeペア 青:positiveペア hard positive hard negative hard negativeとhard positiveに適したネットワークに更新
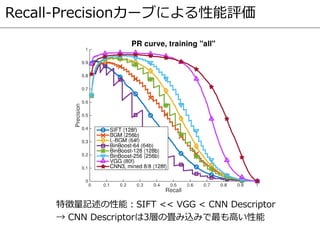
- 80. Recall-Precisionカーブによる性能評価 特徴量記述の性能:SIFT << VGG < CNN Descriptor → CNN Descriptorは3層の畳み込みで最も高い性能
- 81. 対応点探索における処理の変化 Hand-crafted Feature Descriptor CNN Descriptor CNN Similarity キーポイント検出 特徴量記述 距離計算 キーポイント検出 特徴量記述 距離計算 キーポイント検出 特徴量記述 類似度計算 DoG, MSER … DoG, MSER … DoG, MSER … SIFT, ORB … ユークリッド距離 ユークリッド距離 CNN CNN
- 82. CNN Similarity [Zagoruyko, CVPR2015] CNNによりパッチ画像間の類似度を算出 畳み込み層で特徴抽出,全結合層で2枚のパッチ画像の 類似度を算出 CNNの構成 入力:パッチ画像,出力:パッチ画像間の類似度 活性化関数:Rectified Linear Unit (ReLU) プーリング:Maxプーリング 5種類のCNNモデルを提案 2-channelモデル Siameseモデル Pseudo-siameseモデル Central-surround two-stream networkモデル Spatial Pyramid Pooling networkモデル
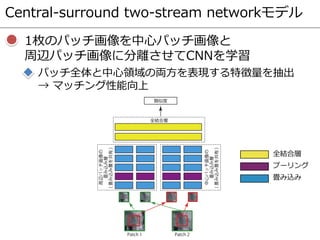
- 86. Central-surround two-stream networkモデル 1枚のパッチ画像を中心パッチ画像と 周辺パッチ画像に分離させてCNNを学習 パッチ全体と中心領域の両方を表現する特徴量を抽出 → マッチング性能向上 全結合層 プーリング 畳み込み
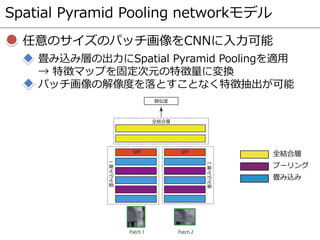
- 87. Spatial Pyramid Pooling networkモデル 任意のサイズのパッチ画像をCNNに入力可能 畳み込み層の出力にSpatial Pyramid Poolingを適用 → 特徴マップを固定次元の特徴量に変換 パッチ画像の解像度を落とすことなく特徴抽出が可能 全結合層 プーリング 畳み込み
- 89. Mean Average Precisionによる性能評価 性能:畳み込み層のみ < 畳み込み層+全結合層(CNN Similarity) → 全結合層による類似度計算を導入することでマッチング性能が向上
- 90. 深層学習による特徴量表現 まとめ 学習でマイニング等の工夫を加えることで 特徴量記述の性能向上 特徴抽出と類似度をend-to-endで学習 特徴量記述の処理速度が課題 1つの特徴量記述に要する時間 CNN Descriptor (CPU) 4.81 [ms] CNN Descriptor (GPU) 0.76 [ms] SIFT 0.14 [ms] 今後の予想される展開 キーポイント検出も含めてend-to-endで学習 可視光カメラと赤外光カメラ間での対応点探索
- 91. ICCV 2015 (12/13~16) CV分野のトップカンファレンス 開催国:Santiago, Chile 参加者:1460人 採択率:Oral 3.30%, Poster 27.62% オーラル会場 ポスター会場 リセプション会場
- 92. ICCV2015での関連論文 Local Convolutional Features with Unsupervised Training for Image Retrieval 2層のConvolutional Kernel Networkによる特徴量記述 入力パッチ画像にホワイトニングや勾配抽出等の 前処理を加えることで性能向上 Aggregating Deep Convolutional Features for Image Retrieval 畳み込み層で出力された各2次元特徴マップの線形和を 特徴量として表現 特徴量にPCAを適用してコンパクト化,過剰適合の防止 RIDE: Reversal Invariant Descriptor Enhancement 画像反転に不変なSIFT特徴量を提案 Bag-of-Featuresの問題に対して性能向上 CNNをベースとした手法
- 93. ICCV2015での関連論文 アフィン変換に不変なキーポイント検出 無数の異方性LoGフィルタの畳み込みを効率化 キーポイントに対して複数のアフィン領域を推定 Multiple-hypothesis affine region estimation with anisotropic LoG filters T. Hasegawa, Y. Yamauchi, T. Yamashita, H. Fujiyoshi (Chubu Univ.) M. Ambai, K. Ishikawa (Denso IT Laboratory, Inc.) G. Koutaki (Kumamoto Univ.)
- 94. 従来のキーポイント検出 Rotation invariant Scale invariant Affine invariant アフィン不変なキーポイント検出が 提案されていない 提案手法 [Hasegawa2015]
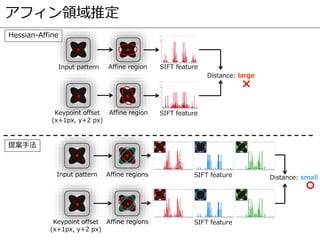
- 95. アフィン領域推定 Input pattern Keypoint offset (x+1px, y+2 px) Affine region Affine region Distance: large SIFT feature SIFT feature Distance: smallInput pattern Keypoint offset (x+1px, y+2 px) Affine regions Affine regions SIFT feature SIFT feature Hessian-Affine 提案手法
- 98. アフィン領域推定結果 画像1 画像2 2画像間のアフィン領域推定精度:16.0% 向上 (贬别蝉蝉颈补苍-础蹿蹿颈苍别との比较)
- 99. ? 対応点探索の基本概念と動向 ? 実数ベクトルで局所特徴量を表現する方法 ? 二値ベクトルで局所特徴量を表現する方法 ? 深層学習による方法 ? まとめ
- 100. まとめ 過去に提案されてきた手法を, (1) 実数ベクトルで局所特徴量を表現する方法 (2) 二値ベクトルで局所特徴量を表現する方法 (3) 深層学習による方法 以上3つの分類に整理してご紹介しました. 目的に応じて賢く使い分けましょう!
- 101. 関連文献 — [SIFT] David G. Lowe, "Distinctive image features from scale-Invariant keypoints," IJCV2004 — [SURF] Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool, “Speeded- up robust features (SURF),” CVIU2008. — [PCA-SIFT] Yan Ke and Rahul Sukthankar, “PCA-SIFT: A more distinctive representation for local image descriptors,” CVPR2004 — [GLOH] Krystian Mikolajczyk and Cordelia Schmid, “A performance evaluation of local descriptors,“ TPAMI2005 — [RIFF] Gabriel Takacs, Vijay Chandrasekhar, Sam Tsai, David Chen, Radek Grzeszczuk, and Bernd Girod, "Unified real-time tracking and recognition with rotation-invariant fast features," CVPR2010 — [ASIFT] Jean-Michel Morel and Guoshen Yu, "ASIFT: A new framework for fully affine invariant image comparison" SIAM Journal on Imaging Sciences, Vol. 2, No. 2, pp. 438-469, April 2009. 本資料では、下記に記載の論文から図を一部引用した。
- 102. 関連文献 — [BRIEF] M.Calonder, V.Lepetit, and P.Fua, “BRIEF: Binary Robust Independent Elementary Features,” ECCV2010 — [BRISK] S.Leutenegger, M.Chli and R.Siegwart, "BRISK: Binary Robust Invariant Scalable Keypoints,“ ICCV2011 — [ORB] E.Rublee, V.Rabaud, K.Konolige and G.Bradsk, "ORB: an efficient alternative to SIFT or SURF,“ ICCV2011 — [FREAK] Alexandre Alahi, Raphael Ortiz, and Pierre Vandergheynst, “FREAK: Fast retina keypoint," CVPR2012 — [D-BRIEF] Tomasz Trzcinski and Vincent Lepetit, "Efficient discriminative projections for compact binary descriptors," ECCV2012 — [BinBoost] T. Trzcinski, M. Christoudias, V. Lepetit, and P. Fua, "Boosting binary keypoint descriptors," CVPR2013 — [BOLD] V. Balntas, L. Tang, and K. Mikolajczyk. BOLD - binary online learned descriptor for efficient image matching. CVPR2015 本資料では、下記に記載の論文から図を一部引用した。
- 103. 関連文献 — [CARD] M.Ambai and Y.Yoshida, “Compact And Real-time Descriptors, ” in Proc. ICCV2011 — [LDA Hash] C. Strecha, A.M. Bronstein, M.M. Bronstein, and Pee. Fua, "LDAHash: Improved matching with smaller descriptors," TPAMI2012 — [CNN Descriptor] E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno- Noguer, "Discriminative learning of deep convolutional feature point descriptors," ICCV2015 — [CNN Similarity] S. Zagoruyko and N. Komodakis. Learning to compare image patches via convolutional neural networks," CVPR2015 — [Spectral Affine SIFT] Takahiro Hasegawa, Mitsuru Ambai, Kohta Ishikawa, Gou Koutaki, Yuji Yamauchi, Takayoshi Yamashita, Hironobu Fujiyoshi, "Multiple-Hypothesis Affine Region Estimation With Anisotropic LoG Filters," ICCV2015 本資料では、下記に記載の論文から図を一部引用した。
- 104. Denso IT Laboratory, Inc. Chubu University