2017 tensor flow dev summit
30 likes3,448 views

2017 tensor flow dev summit (Sequence Models and the RNN API) ņ×æņä▒ļÉ£ ņ×ÉļŻīļĪ£ 2017ļģä 2ņøö 22ņØ╝ ņśżĒøä 8ņŗ£ ļČĆĒä░ Maru180ņŚÉņä£ GDG Seoul ņŚÉņä£ ņŻ╝ņĄ£ĒĢ£ 2017 Tensorflow Dev Summit Extended SeouņŚÉņä£ ļ░£Ēæ£ļź╝ ņ¦äĒ¢ē Sequence Models and the RNN API ņĀĢļ”¼ ļé┤ņŚŁ Ļ│Ąņ£Ā































































![[Tf2017] day1 jwkang_pub](https://cdn.slidesharecdn.com/ss_thumbnails/tf2017day1jwkangpub-171028123944-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Similar to 2017 tensor flow dev summit (20)



![[ļŹ░ļĖīļŻ©Ēéż] Ļ▓īņ×ä ņŚöņ¦ä ņĢäĒéżĒģŹņ│É_3ņן_Ļ▓īņ×äņØä ņ£äĒĢ£ ņåīĒöäĒŖĖņø©ņ¢┤ ņŚöņ¦Ćļŗłņ¢┤ļ¦ü ĻĖ░ņ┤ł](https://cdn.slidesharecdn.com/ss_thumbnails/3se-250315052624-8b8f2ffa-thumbnail.jpg?width=560&fit=bounds)





![[2B2]ßäĆßģĄßäĆßģ© ßäÄßģĄßå½ßäÆßģ¬ßäēßģźßå╝ßäŗßģ│ßå» ßäīßģ«ßå╝ßäēßģĄßåĘßäŗßģ│ßäģßģ® ßäīßģźßåĖßäĆßģ│ßå½ßäÆßģĪßå½ ßäÄßģ¼ßäīßģźßå©ßäÆßģ¬ ßäĆßģĄßäćßģźßåĖ](https://cdn.slidesharecdn.com/ss_thumbnails/2b2-140929202533-phpapp01-thumbnail.jpg?width=560&fit=bounds)







![[ĒĢ£ĻĄŁņ¢┤] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=560&fit=bounds)
More from Tae Young Lee (20)




















2017 tensor flow dev summit
- 1. 2017 TensorFlow Dev Summit Sequence Models and the RNN API Produced By Tae Young Lee
- 3. ņØ┤ņĀäņØś ĻĖ░ņ¢ĄļōżņØ┤ Ēśäņ×¼ņŚÉ ņśüĒ¢źņØä ļ»Ėņ╣£ļŗż
- 4. ņØīņä▒ ņØĖņŗØ ņ¢Ėņ¢┤ ļ¬©ļŹĖ ļ▓łņŚŁ ņśüņāüņŚÉ ņŻ╝ņäØ ļŗ¼ĻĖ░ chatbot
- 5. Chatbot code
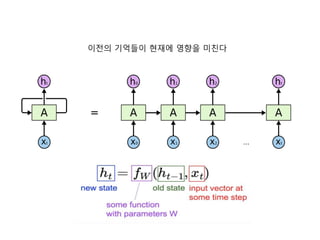
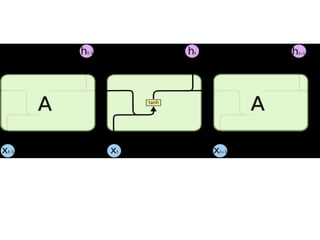
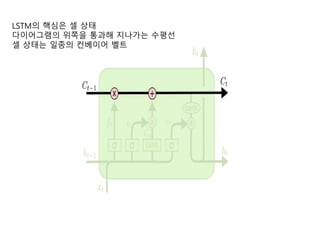
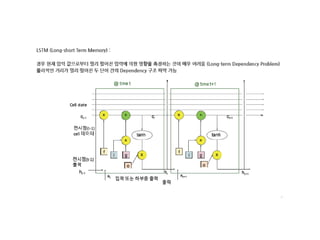
- 12. LSTM ļäżĒŖĖņøīĒü¼ ņןļŗ©ĻĖ░ ĻĖ░ņ¢Ą ļäżĒŖĖņøīĒü¼(Long Short Term Memory networks)ļŖö ļ│┤ĒåĄ ņŚśņŚÉņŖżĒŗ░ņŚĀņ£╝ ļĪ£ ļČłļ”Įļŗłļŗż. ņŚśņŚÉņŖżĒŗ░ņŚĀņØĆ ņןĻĖ░ ņØśņĪ┤ņä▒(Vanishing Gradient)ņØä ĒĢÖņŖĄņØä ņłś ņ׳ļŖö ĒŖ╣ ļ│äĒĢ£ ņóģļźśņØś ņł£ĒÖś ņŗĀĻ▓Įļ¦Øņ×ģļŗłļŗż. ņŚśņŚÉņŖżĒŗ░ņŚĀņØĆ HochreiterņÖĆ Schmidhuber (1997) ņŚÉ ņØśĒĢ┤ ņåīĻ░£ļÉśņŚłņŖĄļŗłļŗż. ĻĘĖļ”¼Ļ│Ā ņØ┤Ēøä ņŚ░ĻĄ¼ņŚÉņä£ ļ¦ÄņØĆ ņé¼ļ×īņŚÉ ņØśĒĢ┤ ļŗżļō¼ņ¢┤ņ¦ĆĻ│Ā ļäÉļ”¼ ņĢīļĀżņĪīņŖĄļŗłļŗż.1 ņŚśņŚÉņŖżĒŗ░ ņŚĀņØĆ ļ¦żņÜ░ ļŗżņ¢æĒĢ£ ņóģļźśņØś ļ¼ĖņĀ£ļōżņŚÉ ļīĆĒĢ┤ ņĀĢļ¦É ņל ļÅÖņ×æĒĢ®ļŗłļŗż. ĻĘĖļ”¼Ļ│Ā Ēśäņ×¼ ņŚśņŚÉņŖż Ēŗ░ņŚĀņØĆ ļäÉļ”¼ ņé¼ņÜ®ļÉśĻ│Ā ņ׳ņŖĄļŗłļŗż. ņŚśņŚÉņŖżĒŗ░ņŚĀņØĆ ņןĻĖ░ ņØśņĪ┤ņä▒ ļ¼ĖņĀ£ļź╝ Ēö╝ĒĢśĻ│Āņ×É ņäżĻ│äļÉśņŚłņŖĄļŗłļŗż. ņśżļ×½ļÅÖņĢł ņĀĢļ│┤ļź╝ ĻĖ░ ņ¢ĄĒĢśļŖö Ļ▓āņØ┤ ņé¼ņŗżņāü ņŚśņŚÉņŖżĒŗ░ņŚĀņØś ĻĖ░ļ│Ė ļÅÖņ×æņ×ģļŗłļŗż. ļ¼┤ņ¢ĖĻ░Ć ļ░░ņÜ░ļĀżĻ│Ā ņĢĀņō░ĻĖ░ļ│┤ļŗż ļŖöņÜö. ļ¬©ļōĀ ņł£ĒÖś ņŗĀĻ▓Įļ¦ØņØĆ ņé¼ņŖ¼ ĒśĢĒā£ņØś ļ░śļ│ĄļÉśļŖö ņŗĀĻ▓Įļ¦Ø ļ¬©ļōłļōżņØä Ļ░Ćņ¦æļŗłļŗż. Ēæ£ņżĆ ņł£ĒÖś ņŗĀĻ▓Įļ¦ØņŚÉņä£, ņØ┤ ļ░śļ│ĄļÉśļŖö ļ¬©ļōłņØĆ ĒĢ£ Ļ░£ņØś tanh ņĖĄ Ļ░ÖņØĆ ļ¦żņÜ░ Ļ░äļŗ©ĒĢ£ ĻĄ¼ņĪ░ļź╝ Ļ░Ćņ¦ł Ļ▓ā ņ×ģļŗłļŗż. https://docs.google.com/document/d/1M25vrmJHp21lK- C8Xhg42zFzXke9_NrvhHBqH2qISfY/edit#
- 15. LSTMņØś ĒĢĄņŗ¼ņØĆ ņģĆ ņāüĒā£ ļŗżņØ┤ņ¢┤ĻĘĖļשņØś ņ£äņ¬ĮņØä ĒåĄĻ│╝ĒĢ┤ ņ¦ĆļéśĻ░ĆļŖö ņłśĒÅēņäĀ ņģĆ ņāüĒā£ļŖö ņØ╝ņóģņØś ņ╗©ļ▓ĀņØ┤ņ¢┤ ļ▓©ĒŖĖ
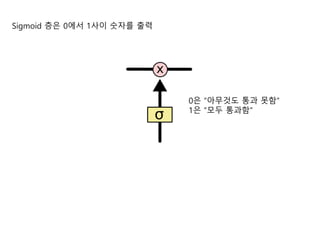
- 16. Sigmoid ņĖĄņØĆ 0ņŚÉņä£ 1ņé¼ņØ┤ ņł½ņ×Éļź╝ ņČ£ļĀź 0ņØĆ ŌĆ£ņĢäļ¼┤Ļ▓āļÅä ĒåĄĻ│╝ ļ¬╗ĒĢ©ŌĆØ 1ņØĆ ŌĆ£ļ¬©ļæÉ ĒåĄĻ│╝ĒĢ©ŌĆØ
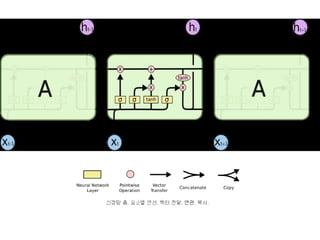
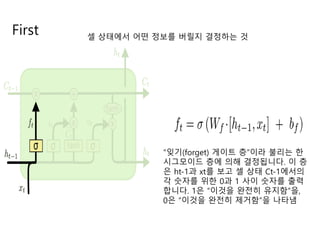
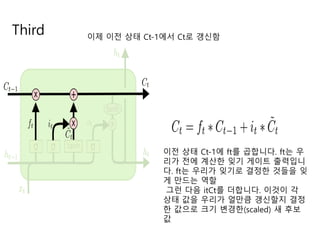
- 17. First ņģĆ ņāüĒā£ņŚÉņä£ ņ¢┤ļ¢ż ņĀĢļ│┤ļź╝ ļ▓äļ”┤ņ¦Ć Ļ▓░ņĀĢĒĢśļŖö Ļ▓ā ŌĆ£ņ×ŖĻĖ░(forget) Ļ▓īņØ┤ĒŖĖ ņĖĄŌĆØņØ┤ļØ╝ ļČłļ”¼ļŖö ĒĢ£ ņŗ£ĻĘĖļ¬©ņØ┤ļō£ ņĖĄņŚÉ ņØśĒĢ┤ Ļ▓░ņĀĢļÉ®ļŗłļŗż. ņØ┤ ņĖĄ ņØĆ ht-1Ļ│╝ xtļź╝ ļ│┤Ļ│Ā ņģĆ ņāüĒā£ Ct-1ņŚÉņä£ņØś Ļ░ü ņł½ņ×Éļź╝ ņ£äĒĢ£ 0Ļ│╝ 1 ņé¼ņØ┤ ņł½ņ×Éļź╝ ņČ£ļĀź ĒĢ®ļŗłļŗż. 1ņØĆ ŌĆ£ņØ┤Ļ▓āņØä ņÖäņĀäĒ׳ ņ£Āņ¦ĆĒĢ©ŌĆØņØä, 0ņØĆ ŌĆ£ņØ┤Ļ▓āņØä ņÖäņĀäĒ׳ ņĀ£Ļ▒░ĒĢ©ŌĆØņØä ļéśĒāĆļāä
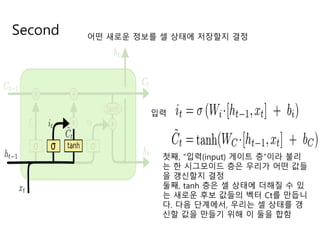
- 18. Second ņ¢┤ļ¢ż ņāłļĪ£ņÜ┤ ņĀĢļ│┤ļź╝ ņģĆ ņāüĒā£ņŚÉ ņĀĆņןĒĢĀņ¦Ć Ļ▓░ņĀĢ ņ×ģļĀź ņ▓½ņ¦Ė, ŌĆ£ņ×ģļĀź(input) Ļ▓īņØ┤ĒŖĖ ņĖĄŌĆØņØ┤ļØ╝ ļČłļ”¼ ļŖö ĒĢ£ ņŗ£ĻĘĖļ¬©ņØ┤ļō£ ņĖĄņØĆ ņÜ░ļ”¼Ļ░Ć ņ¢┤ļ¢ż Ļ░Æļōż ņØä Ļ░▒ņŗĀĒĢĀņ¦Ć Ļ▓░ņĀĢ ļæśņ¦Ė, tanh ņĖĄņØĆ ņģĆ ņāüĒā£ņŚÉ ļŹöĒĢ┤ņ¦ł ņłś ņ׳ ļŖö ņāłļĪ£ņÜ┤ Ēøäļ│┤ Ļ░ÆļōżņØś ļ▓ĪĒä░ Ctļź╝ ļ¦īļōŁļŗł ļŗż. ļŗżņØī ļŗ©Ļ│äņŚÉņä£, ņÜ░ļ”¼ļŖö ņģĆ ņāüĒā£ļź╝ Ļ░▒ ņŗĀĒĢĀ Ļ░ÆņØä ļ¦īļōżĻĖ░ ņ£äĒĢ┤ ņØ┤ ļæśņØä ĒĢ®ĒĢ©
- 19. Third ņØ┤ņĀ£ ņØ┤ņĀä ņāüĒā£ Ct-1ņŚÉņä£ CtļĪ£ Ļ░▒ņŗĀĒĢ© ņØ┤ņĀä ņāüĒā£ Ct-1ņŚÉ ftļź╝ Ļ│▒ĒĢ®ļŗłļŗż. ftļŖö ņÜ░ ļ”¼Ļ░Ć ņĀäņŚÉ Ļ│äņé░ĒĢ£ ņ×ŖĻĖ░ Ļ▓īņØ┤ĒŖĖ ņČ£ļĀźņ×ģļŗł ļŗż. ftļŖö ņÜ░ļ”¼Ļ░Ć ņ×ŖĻĖ░ļĪ£ Ļ▓░ņĀĢĒĢ£ Ļ▓āļōżņØä ņ×Ŗ Ļ▓ī ļ¦īļō£ļŖö ņŚŁĒĢĀ ĻĘĖļ¤░ ļŗżņØī itCtļź╝ ļŹöĒĢ®ļŗłļŗż. ņØ┤Ļ▓āņØ┤ Ļ░ü ņāüĒā£ Ļ░ÆņØä ņÜ░ļ”¼Ļ░Ć ņ¢╝ļ¦īĒü╝ Ļ░▒ņŗĀĒĢĀņ¦Ć Ļ▓░ņĀĢ ĒĢ£ Ļ░Æņ£╝ļĪ£ Ēü¼ĻĖ░ ļ│ĆĻ▓ĮĒĢ£(scaled) ņāł Ēøäļ│┤ Ļ░Æ
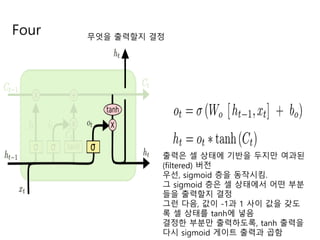
- 20. Four ļ¼┤ņŚćņØä ņČ£ļĀźĒĢĀņ¦Ć Ļ▓░ņĀĢ ņČ£ļĀźņØĆ ņģĆ ņāüĒā£ņŚÉ ĻĖ░ļ░śņØä ļæÉņ¦Ćļ¦ī ņŚ¼Ļ│╝ļÉ£ (filtered) ļ▓äņĀä ņÜ░ņäĀ, sigmoid ņĖĄņØä ļÅÖņ×æņŗ£Ēé┤. ĻĘĖ sigmoid ņĖĄņØĆ ņģĆ ņāüĒā£ņŚÉņä£ ņ¢┤ļ¢ż ļČĆļČä ļōżņØä ņČ£ļĀźĒĢĀņ¦Ć Ļ▓░ņĀĢ ĻĘĖļ¤░ ļŗżņØī, Ļ░ÆņØ┤ -1Ļ│╝ 1 ņé¼ņØ┤ Ļ░ÆņØä Ļ░¢ļÅä ļĪØ ņģĆ ņāüĒā£ļź╝ tanhņŚÉ ļäŻņØī Ļ▓░ņĀĢĒĢ£ ļČĆļČäļ¦ī ņČ£ļĀźĒĢśļÅäļĪØ, tanh ņČ£ļĀźņØä ļŗżņŗ£ sigmoid Ļ▓īņØ┤ĒŖĖ ņČ£ļĀźĻ│╝ Ļ│▒ĒĢ©
- 22. 1
- 23. 2
- 24. 3
- 25. 4
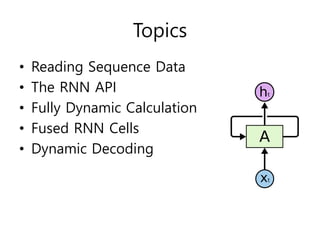
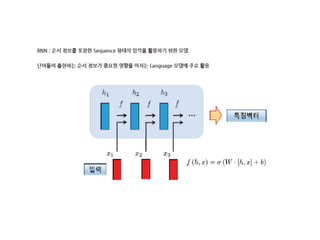
- 26. Topics ŌĆó Reading Sequence Data ŌĆó The RNN API ŌĆó Fully Dynamic Calculation ŌĆó Fused RNN Cells ŌĆó Dynamic Decoding
- 27. Reading and Batching Sequence Data
- 28. 1
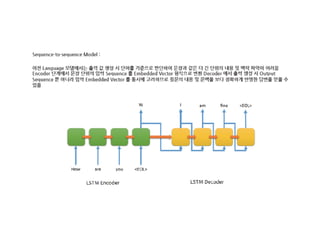
- 29. Feeding Sequence Data SequenceExample proto to store sequence ŌĆó Efficient storage of multiple sequence ŌĆó Per time step variable feature counts ŌĆó Efficient Parser Op ŌĆó tf.parse_single_sequence_example ŌĆó Coming soon : TensorFlow Serving ŌĆ£First ClassŌĆØ citizen https://www.tensorflow.org/api_docs/python/tf/parse_single_sequence_example
- 31. Batching Sequence Data : Static Padding Pad each input sequence yourself, use FIFOQueue : tf.train.batch(ŌĆ”) https://www.tensorflow.org/api_docs/python/tf/train/batch
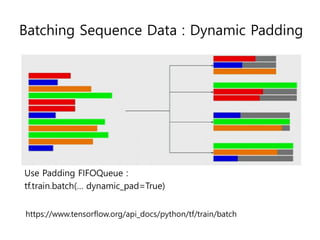
- 32. Batching Sequence Data : Dynamic Padding Use Padding FIFOQueue : tf.train.batch(ŌĆ” dynamic_pad=True) https://www.tensorflow.org/api_docs/python/tf/train/batch
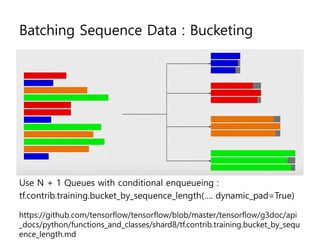
- 33. Batching Sequence Data : Bucketing Use N + 1 Queues with conditional enqueueing : tf.contrib.training.bucket_by_sequence_length(ŌĆ”. dynamic_pad=True) https://github.com/tensorflow/tensorflow/blob/master/tensorflow/g3doc/api _docs/python/functions_and_classes/shard8/tf.contrib.training.bucket_by_sequ ence_length.md
- 34. Batching Sequence Data : Truncated BPTT via State Saver Use Barrier + Queues, you must call save_state each training step : tf.contrib.training.batch_sequences_with_states(ŌĆ”) https://github.com/tensorflow/tensorflow/blob/master/tensorflow/g3doc/api _docs/python/contrib.training.md
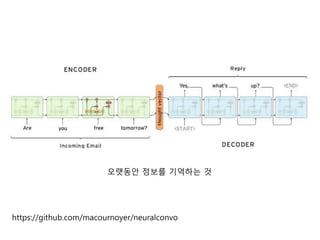
- 35. BPTT (Backpropagation Through Time) BPTTļŖö ņł£ĒÖśņŗĀĻ▓Įļ¦Ø(RNN)ņŚÉņä£ ņé¼ņÜ®ļÉśļŖö (Ēæ£ņżĆ) ņŚŁņĀäĒīī ņĢīĻ│Āļ”¼ņ”śņ×ģļŗłļŗż. RNNņØ┤ ļ¬©ļōĀ ņŗ£Ļ░ä ņŖżĒģØņŚÉņä£ ĒīīļØ╝ļ®öĒä░ļź╝ Ļ│Ąņ£ĀĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ, ĒĢ£ ņŗ£ņĀÉņŚÉņä£ ņśżļźśĻ░Ć ņŚŁņĀäĒīīļÉś ļ®┤ ļ¬©ļōĀ ņØ┤ņĀä ņŗ£ņĀÉņ£╝ļĪ£ ĒŹ╝ņĀĖ BPTTļ×Ć ņØ┤ļ”äņØ┤ ļČÖņŚłņŖĄļŗłļŗż. ņłśļ░▒ Ļ░£ņØś ĻĖĖņØ┤ļź╝ Ļ░¢ļŖö ĻĖ┤ ņ×ģļĀź ņŗ£ĒĆĆņŖżĻ░Ć ļōżņ¢┤ņśżļ®┤, Ļ│äņé░ ļ╣äņÜ®ņØä ņżäņØ┤ĻĖ░ ņ£äĒĢ┤ Ļ│ĀņĀĢļÉ£ ļ¬ć ņŖżĒģØ ņØ┤ĒøäņŚÉ ņśż ļźśļź╝ ļŹöņØ┤ņāü ņŚŁņĀäĒīīĒĢśņ¦Ć ņĢŖĻ│Ā ļ®łņČöĻĖ░ļÅä ĒĢ®ļŗłļŗż.
- 36. The RNN API Evolution and Design Decisions
- 39. Simple RNN
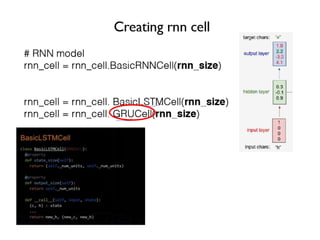
- 42. RNNCell ŌĆó Provide knowledge about the specific RNN architecture ŌĆó Represent a time step as a layer (c.f. Keras layers) Kerasļ×Ć? KerasņŚÉ ļīĆĒĢ£ ņäżļ¬ģņØĆ http://keras.io/ ņŚÉņä£ ņ░ŠņĢäļ│Ėļŗż. theanoļéś tensor flowļź╝ ņØ┤ņÜ®ĒĢ£ ņśłņĀ£ļź╝ ļ│┤ļ®┤ ņĮöļō£ņŚÉļŖö ĒÖĢņŗżĒ׳ ļ│┤ņØ┤ļŖö ņØĖņŖżĒä┤ņŖżĻ░Ć ņŚåļŖöļŹ░ ļ░▒ĻĘĖļØ╝ņÜ┤ļō£ņŚÉņä£ ļŁöĻ░ĆĻ░Ć ļ¦īļōżņ¢┤ņ¦ĆĻ│Ā ņ׳ļŗżļŖö ņāØĻ░üņØ┤ ļōĀļŗż. ļŗżļźĖ ņ¢Ėņ¢┤ļź╝ ņō░ļŹś ņé¼ļ×īļōżņØĆ ņ¢┤ļ¢©ņ¦Ć ļ¬©ļź┤Ļ▓Āņ¦Ćļ¦ī C++ņØä ņŻ╝ļĪ£ ņé¼ņÜ®ĒĢ┤ņśżļŹś ļéśļĪ£ņä£ļŖö ņØ┤ĒĢ┤Ļ░Ć ņĢł ļÉśļŖö ņĮöļō£Ļ░Ć ļ¦Äļŗż. KerasļŖö ĻĘĖļ¤¼ĒĢ£ 'ĒØæļ¦łņłĀ'ņØä ņŚåņĢĀĻ│Ā ļłłņŚÉ ĒÖĢņŗżĒ׳ ļ│┤ņØ┤ļŖö ņĮöļō£ļĪ£ theanoļéś tensor flowļź╝ wrapping ĒĢ£ Ēī©Ēéżņ¦Ć
- 45. Fully Dynamic Calculation Fast and Memory Efficient Custom Loops
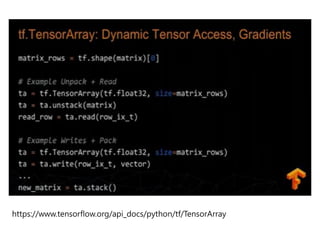
- 46. Fully Dynamic Calculation Goal : Handle sequence of unknown length Tools : ŌĆó tf.while_loop dynamic loops + gradients ŌĆó tf.TensorArray dynamic Tensor slice access, gradients
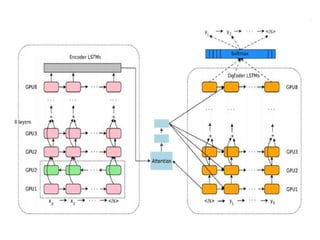
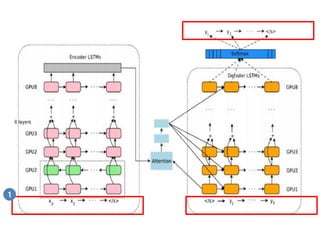
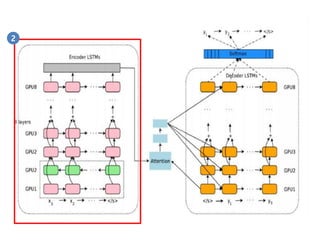
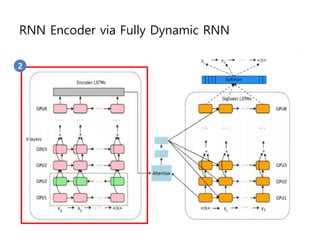
- 50. RNN Encoder via Fully Dynamic RNN 2
- 52. Fused RNN Cells Optimizations for Special Cases
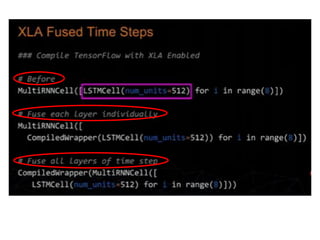
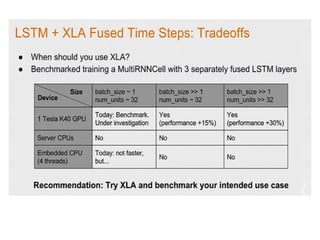
- 53. Type of Fusion ŌĆó XLA Fused time steps ŌĆó Manually fused time steps ŌĆó Manually fused loops Fusion tradeoffs : ŌĆó Flexibility for Speed ŌĆó ŌĆ£Works EverywhereŌĆØ to ŌĆ£Fast on XOR(GPU, Android,ŌĆ”)ŌĆØ
- 54. XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that optimizes TensorFlow computations. The results are improvements in speed, memory usage, and portability on server and mobile platforms. Initially, most users will not see large benefits from XLA, but are welcome to experiment by using XLA via just-in-time (JIT) compilaton or ahead-of-time (AOT) compilation. Developers targeting new hardware accelerators are especially encouraged to try out XLA XLA (Accelerated Linear Algebra)ļŖö TensorFlow Ļ│äņé░ņØä ņĄ£ņĀüĒÖöĒĢśļŖö ņäĀĒśĢ ļīĆņłśĒĢÖņØä ņ£äĒĢ£ ļÅäļ®öņØĖ ļ│ä ņ╗┤ĒīīņØ╝ļ¤¼ņ×ģļŗłļŗż. ĻĘĖ Ļ▓░Ļ│╝ ņä£ļ▓ä ļ░Å ļ¬©ļ░öņØ╝ Ēöīļ×½ĒÅ╝ņŚÉņä£ ņåŹļÅä, ļ®öļ¬©ļ”¼ ņé¼ņÜ® ļ░Å ņØ┤ņŗØņä▒ņØ┤ Ļ░£ņäĀļÉśņŚłņŖĄļŗłļŗż. ņ▓śņØīņŚÉļŖö ļīĆļČĆļČäņØś ņé¼ņÜ®ņ×ÉĻ░Ć XLAņŚÉņä£ Ēü░ ņØ┤ņØĄ ņØä ļ│╝ ņłśļŖö ņŚåņ¦Ćļ¦ī JIT (Just-In-Time) ņ╗┤ĒīīņØ╝ ļśÉļŖö AOT (Ahead-Of-Time) ņ╗┤ĒīīņØ╝ņØä ĒåĄĒĢ┤ XLAļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņŗżĒŚś ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ņāłļĪ£ņÜ┤ ĒĢśļō£ņø©ņ¢┤ Ļ░ĆņåŹĻĖ░ļź╝ ļ¬®Ēæ£ļĪ£ĒĢśļŖö Ļ░£ļ░£ņ×ÉļŖö ĒŖ╣Ē׳ XLAļź╝ ņé¼ņÜ®ĒĢ┤ ļ│┤ļŖö Ļ▓āņØ┤ ņóŗņŖĄļŗłļŗż. https://www.tensorflow.org/versions/master/experimental/xla/
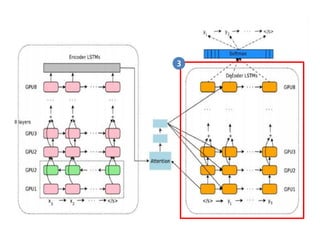
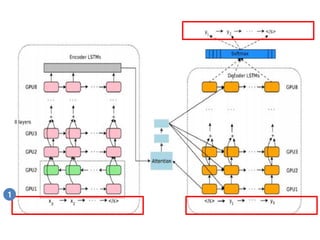
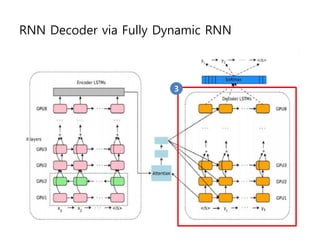
- 60. RNN Decoder via Fully Dynamic RNN 3
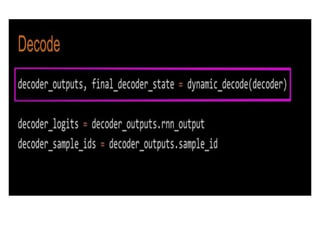
- 61. Dynamic Decoder ŌĆó New OO API ŌĆó Under active development ŌĆó Base decoder library for Open Source Neural Machine Translation tutorial (coming soon) ŌĆó tf.contrib.seq2seq
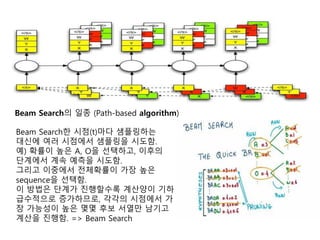
- 65. Beam SearchņØś ņØ╝ņóģ (Path-based algorithm) Beam SearchĒĢ£ ņŗ£ņĀÉ(t)ļ¦łļŗż ņāśĒöīļ¦üĒĢśļŖö ļīĆņŗĀņŚÉ ņŚ¼ļ¤¼ ņŗ£ņĀÉņŚÉņä£ ņāśĒöīļ¦üņØä ņŗ£ļÅäĒĢ©. ņśł) ĒÖĢļźĀņØ┤ ļåÆņØĆ A, OņØä ņäĀĒāØĒĢśĻ│Ā, ņØ┤ĒøäņØś ļŗ©Ļ│äņŚÉņä£ Ļ│äņåŹ ņśłņĖĪņØä ņŗ£ļÅäĒĢ©. ĻĘĖļ”¼Ļ│Ā ņØ┤ņżæņŚÉņä£ ņĀäņ▓┤ĒÖĢļźĀņØ┤ Ļ░Ćņן ļåÆņØĆ sequenceņØä ņäĀĒāØĒĢ©. ņØ┤ ļ░®ļ▓ĢņØĆ ļŗ©Ļ│äĻ░Ć ņ¦äĒ¢ēĒĢĀņłśļĪØ Ļ│äņé░ņ¢æņØ┤ ĻĖ░ĒĢś ĻĖēņłśņĀüņ£╝ļĪ£ ņ”ØĻ░ĆĒĢśļ»ĆļĪ£, Ļ░üĻ░üņØś ņŗ£ņĀÉņŚÉņä£ Ļ░Ć ņן Ļ░ĆļŖźņä▒ņØ┤ ļåÆņØĆ ļ¬ćļ¬ć Ēøäļ│┤ ņä£ņŚ┤ļ¦ī ļé©ĻĖ░Ļ│Ā Ļ│äņé░ņØä ņ¦äĒ¢ēĒĢ©. => Beam Search
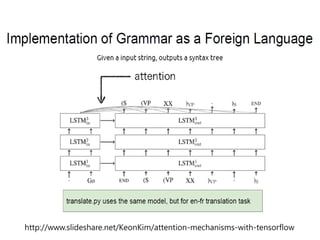
- 66. Helper functions for preparing translation data. https://www.tensorflow.org/tutorials/seq2seq
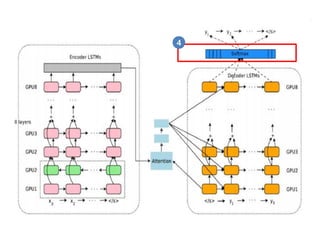
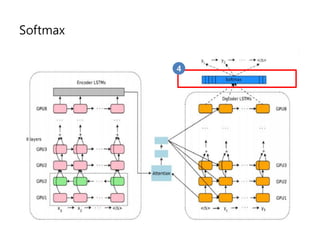
- 70. Softmax 4
- 71. Softmax (ņåīĒöäĒŖĖļ¦źņŖż) ŌĆō cost function ņåīĒöäĒŖĖļ¦źņŖżļŖö Ēü┤ļלņŖż ļČäļźś ļ¼ĖņĀ£ļź╝ ĒÆĆ ļĢī (ņĀÉņłś ļ▓ĪĒä░)ļź╝ (Ļ░ü Ēü┤ļלņŖżļ│ä ĒÖĢļźĀ)ļĪ£ ļ│Ć ĒÖśĒĢśĻĖ░ ņ£äĒĢ┤ ĒØöĒ׳ ņé¼ņÜ®ĒĢśļŖö ĒĢ©ņłśņ×ģļŗłļŗż. Ļ░ü ņĀÉņłśņŚÉ ņ¦Ćņłś(exp)ļź╝ ņĘ©ĒĢ£ Ēøä, ņĀĢĻĘ£ĒÖö ņāüņłśļĪ£ ļéśļłäņ¢┤ ņ┤ØĒĢ®ņØ┤ 1ņØ┤ ļÉśļÅäļĪØ Ļ│äņé░ĒĢ®ļŗłļŗż. ņŚ¼ĻĖ░ņä£ ļ¦īņĢĮ ĻĖ░Ļ│äļ▓łņŚŁ ļ¼ĖņĀ£ņ▓śļ¤╝ Ēü┤ļלņŖżņØś ņóģļźśĻ░Ć ņĢäņŻ╝ ļ¦Äļŗżļ®┤ ņĀĢĻĘ£ĒÖö ņāüņłśļź╝ Ļ│äņé░ĒĢśļŖö ņ×æņŚģņØĆ ļäłļ¼┤ ļ╣äņŗ╝ ņŚ░ņé░ņØ┤ ļÉ®ļŗłļŗż. ĒÜ©ņ£©ņĀüņ£╝ļĪ£ Ļ│äņé░ĒĢśĻĖ░ ņ£äĒĢ£ ļīĆņĢłņ£╝ļĪ£ Ļ│äņĖĄņĀü ņåīĒöäĒŖĖļ¦źņŖżļéś NCE ļō▒ ļĪ£ņŖż ĻĖ░ļ░ś ņāśĒöīļ¦ü ĻĖ░ļ▓Ģ ļō▒ņØ┤ ņ׳ņŖĄļŗłļŗż. noise-contrastive estimation (NCE) ņåÉņŗż ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢĀ Ļ▓āņØ┤ļŗż. ņØ┤ļŖö ĒģÉņä£ Ēöī ļĪ£ņÜ░ņŚÉ ļ»Ėļ”¼ ĻĄ¼ĒśäļÉ£ tf.nn.nce_loss() ĒĢ©ņłśļź╝ ņØ┤ņÜ®