DeepSeekßäģßģ│ßå» ßäÉßģ®ßå╝ßäÆßģó ßäćßģ®ßå½ Trend (Faculty Tae Young Lee)

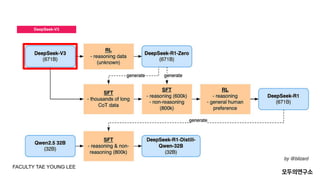
The document titled "Trends Observed Through DeepSeek" explores advancements in AI and reinforcement learning through the lens of DeepSeek's latest developments. It is structured into three main sections: DeepSeek-V3 Focuses on context length extension, initially supporting 32,000 characters and later expanding to 128,000 characters. Introduces Mixture of Experts (MoE) architecture, optimizing computational efficiency using a novel Auxiliary-Loss-Free Load Balancing strategy. Multi-Head Latent Attention (MLA) reduces memory consumption while maintaining performance, enhancing large-scale model efficiency. DeepSeek-R1-Zero Explores advancements in reinforcement learning algorithms, transitioning from RLHF to GRPO (Group Relative Policy Optimization) for cost-effective optimization. Direct Preference Optimization (DPO) enhances learning by leveraging preference-based optimization instead of traditional reward functions. DeepSeek-R1 and Data Attribution Discusses a Cold Start approach using high-quality data (SFT) to ensure stable initial training. Incorporates reasoning-focused reinforcement learning, balancing logical accuracy with multilingual consistency. Utilizes rejection sampling and data augmentation to refine AI-generated outputs for enhanced usability and safety. The document provides a detailed analysis of these methodologies, positioning DeepSeek as a key player in AI model development and reinforcement learning.



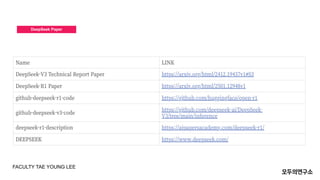
















DeepSeekßäģßģ│ßå» ßäÉßģ®ßå╝ßäÆßģó ßäćßģ®ßå½ Trend (Faculty Tae Young Lee)
- 1. DeepSeekļź╝ ĒåĄĒĢ┤ ļ│Ė Trend A.I. Educating Service FACULTY TAE YOUNG LEE
- 2. ŌĆ£Share Value, Grow togetherŌĆØ ņÜ░ļ”¼ļŖö ņ¦ĆņåŹņĀüņ£╝ļĪ£ ņä▒ņןĒĢśĻ│Ā ņŗČņØĆ ņŚ┤ņĀĢņØ┤ ņ׳ņ¢┤ņÜö ļ│ĆĒÖöļź╝ ļæÉļĀżņøīĒĢśņ¦Ć ņĢŖĻ│Ā, ņ×ÉņŗĀņØś ņŚŁļ¤ēņØä Ļ│äņåŹ ļ░£ņĀäņŗ£Ēéżļ®░ ņä▒ņןĒĢ┤ņÜö ņāłļĪ£ņÜ┤ ņŚģļ¼┤ļź╝ ļæÉļĀżņøīĒĢśĻĖ░ļ│┤ļŗż ņĀüĻĘ╣ņĀüņ£╝ļĪ£ ņłśņÜ®ĒĢśņŚ¼ ņ×ÉņŗĀĻ░É ņ׳Ļ▓ī ņČöņ¦äĒĢ┤ņÜö
- 3. Index 01 DeepSeek-V3 MOEņÖĆ MLA 02 DeepSeek-R1-Zero RLHFŌåÆRLAIFŌåÆPPOŌåÆDPOŌåÆGRPO 03 DeepSeek-R1 Data Attribution FACULTY TAE YOUNG LEE
- 4. DeepSeek Paper FACULTY TAE YOUNG LEE
- 5. ļ¬©ļæÉņØśņŚ░ĻĄ¼ņåī PPT Ēæ£ņ¦Ć ņĀ£ļ¬®ņØä ņ×ģļĀźĒĢ┤ņŻ╝ņäĖņÜö. 01 MOEņÖĆ MLA DeepSeek-V3
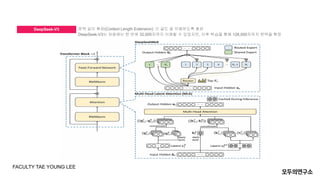
- 7. DeepSeek-V3 FACULTY TAE YOUNG LEE ļ¼Ėļ¦ź ĻĖĖņØ┤ ĒÖĢņן(Context Length Extension): ĻĖ┤ ĻĖĆļÅä ņל ņØ┤ĒĢ┤ĒĢśļÅäļĪØ ĒøłļĀ© DeepSeek-V3ļŖö ņ▓śņØīņŚÉļŖö ĒĢ£ ļ▓łņŚÉ 32,000ņ×ÉĻ╣īņ¦Ć ņØ┤ĒĢ┤ĒĢĀ ņłś ņ׳ņŚłņ¦Ćļ¦ī, ņØ┤Ēøä ĒĢÖņŖĄņØä ĒåĄĒĢ┤ 128,000ņ×ÉĻ╣īņ¦Ć ļ¼Ėļ¦źņØä ĒÖĢņן
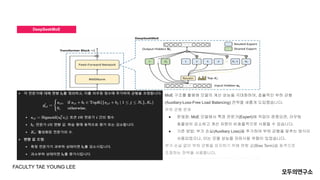
- 8. DeepSeekMoE MoE ĻĄ¼ņĪ░ļź╝ ĒÖ£ņÜ®ĒĢ┤ ļ¬©ļŹĖņØś Ļ│äņé░ ņä▒ļŖźņØä ĻĘ╣ļīĆĒÖöĒĢśļ®░, ĒÜ©ņ£©ņĀüņØĖ ļČĆĒĢś ĻĘĀĒśĢ (Auxiliary-Loss-Free Load Balancing) ņĀäļץņØä ņāłļĪŁĻ▓ī ļÅäņ×ģĒ¢łņŖĄļŗłļŗż. ļČĆĒĢś ĻĘĀĒśĢ ļ¼ĖņĀ£ ŌŚÅ ļ¼ĖņĀ£ņĀÉ: MoE ļ¬©ļŹĖņŚÉņä£ ĒŖ╣ņĀĢ ņĀäļ¼ĖĻ░Ć(Expert)ņŚÉ ņ×æņŚģņØ┤ ĒÄĖņżæļÉśļ®┤, ļØ╝ņÜ░Ēīģ ĒÜ©ņ£©ņä▒ņØ┤ Ļ░ÉņåīĒĢśĻ│Ā Ļ│äņé░ ņ×ÉņøÉņØ┤ ļ╣äĒÜ©ņ£©ņĀüņ£╝ļĪ£ ņé¼ņÜ®ļÉĀ ņłś ņ׳ņŖĄļŗłļŗż. ŌŚÅ ĻĖ░ņĪ┤ ļ░®ļ▓Ģ: ļČĆĻ░Ć ņåÉņŗż(Auxiliary Loss)ņØä ņČöĻ░ĆĒĢśņŚ¼ ļČĆĒĢś ĻĘĀĒśĢņØä ļ¦×ņČöļŖö ļ░®ņŗØņØ┤ ņé¼ņÜ®ļÉśņŚłņ£╝ļéś, ņØ┤ļŖö ļ¬©ļŹĖ ņä▒ļŖźņØä ņĀĆĒĢśņŗ£Ēé¼ ņ£äĒŚśņØ┤ ņ׳ņŚłņŖĄļŗłļŗż. ļČĆĻ░Ć ņåÉņŗż ņŚåņØ┤ ļČĆĒĢś ĻĘĀĒśĢņØä ņ£Āņ¦ĆĒĢśĻĖ░ ņ£äĒĢ┤ ĒÄĖĒ¢ź Ļ░Æ(Bias Term)ņØä ļÅÖņĀüņ£╝ļĪ£ ņĪ░ņĀĢĒĢśļŖö ņĀäļץņØä ņé¼ņÜ®ĒĢ®ļŗłļŗż. FACULTY TAE YOUNG LEE
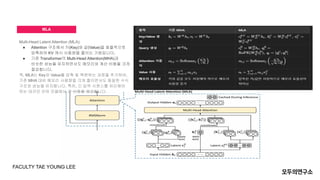
- 9. MLA Multi-Head Latent Attention (MLA): ŌŚÅ Attention ĻĄ¼ņĪ░ņŚÉņä£ Ēéż(Key)ņÖĆ Ļ░Æ(Value)ņØä ĒÜ©ņ£©ņĀüņ£╝ļĪ£ ņĢĢņČĢĒĢśņŚ¼ KV ņ║Éņŗ£ ņé¼ņÜ®ļ¤ēņØä ņżäņØ┤ļŖö ĻĖ░ļ▓Ģņ×ģļŗłļŗż. ŌŚÅ ĻĖ░ņĪ┤ TransformerņØś Multi-Head Attention(MHA)Ļ│╝ ļ╣äņŖĘĒĢ£ ņä▒ļŖźņØä ņ£Āņ¦ĆĒĢśļ®┤ņä£ļÅä ļ®öļ¬©ļ”¼ņÖĆ Ļ│äņé░ ļ╣äņÜ®ņØä Ēü¼Ļ▓ī ņĀłĻ░ÉĒĢ®ļŗłļŗż. ņ”ē, MLAļŖö KeyņÖĆ Valueļź╝ ņĢĢņČĢ ļ░Å ļ│ĄņøÉĒĢśļŖö Ļ│╝ņĀĢņØä ņČöĻ░ĆĒĢśņŚ¼, ĻĖ░ņĪ┤ MHA ļīĆļ╣ä ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļ¤ēņØä Ēü¼Ļ▓ī ņżäņØ┤ļ®┤ņä£ļÅä ļÅÖņØ╝ĒĢ£ ņłśņŗØ ĻĄ¼ņĪ░ņÖĆ ņä▒ļŖźņØä ņ£Āņ¦ĆĒĢ®ļŗłļŗż. ĒŖ╣Ē׳, ĻĖ┤ ņ×ģļĀź ņŗ£ĒĆĆņŖżļź╝ ņ▓śļ”¼ĒĢ┤ņĢ╝ ĒĢśļŖö ļīĆĻĘ£ļ¬© ņ¢Ėņ¢┤ ļ¬©ļŹĖņŚÉņä£ Ēü░ ņØ┤ņĀÉņØä ņĀ£Ļ│ĄĒĢ®ļŗłļŗż FACULTY TAE YOUNG LEE
- 10. ļ¬©ļæÉņØśņŚ░ĻĄ¼ņåī PPT Ēæ£ņ¦Ć ņĀ£ļ¬®ņØä ņ×ģļĀźĒĢ┤ņŻ╝ņäĖņÜö. 02 RLHFŌåÆRLAIFŌåÆPPOŌåÆDPOŌåÆGRPO DeepSeek-R1-Zero
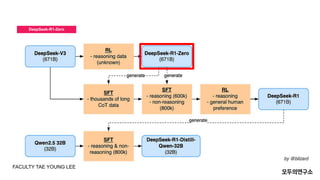
- 12. DeepSeek-R1-Zero FACULTY TAE YOUNG LEE DeepSeek-R1-ZeroļŖö Ļ░ĢĒÖö ĒĢÖņŖĄ ĒÜ©ņ£©ņä▒ņØä ņ£äĒĢ┤ GRPO ņĢīĻ│Āļ”¼ņ”śņØä ņé¼ņÜ®ĒĢ®ļŗłļŗż. GRPOņØś ņŻ╝ņÜö ĒŖ╣ņ¦ĢņØĆ Critic ļ¬©ļŹĖ ņŚåņØ┤ ĻĘĖļŻ╣ ņĀÉņłśļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒĢÖņŖĄĒĢ£ļŗżļŖö ņĀÉņ×ģļŗłļŗż. ņØ┤ ņĀæĻĘ╝ļ▓ĢņØĆ ĒĢÖņŖĄ ļ╣äņÜ®ņØä ņżäņØ┤ļ®┤ņä£ļÅä ļåÆņØĆ ņä▒ļŖźņØä ņĀ£Ļ│ĄĒĢ®ļŗłļŗż. GRPO ņĢīĻ│Āļ”¼ņ”śņØś ļ¬®Ēæ£ ĒĢ©ņłśļŖö ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀĢņØśļÉ®ļŗłļŗż: ĻĘĖļŻ╣ņØś ņĀĢņØś ŌŚÅ ĒĢśļéśņØś ņ¦łļ¼Ė (q): ņĀĢņ▒ģ ļ¬©ļŹĖņØ┤ ņ▓śļ”¼ĒĢ┤ņĢ╝ ĒĢĀ ņ×ģļĀź ņ¦łļ¼Ėņ×ģļŗłļŗż. ŌŚÅ ņČ£ļĀź ĻĘĖļŻ╣: ņ¦łļ¼Ė qņŚÉ ļīĆĒĢ┤ ņĀĢņ▒ģ ļ¬©ļŹĖ ŽĆoldpi_{text{old}}ŽĆoldņØ┤ ņāØņä▒ĒĢ£ ņŚ¼ļ¤¼ Ļ░£ņØś ņČ£ļĀź (o1,o2,ŌĆ”,oGo_1, o_2, ldots, o_Go1,o2,ŌĆ”,oG)ņ£╝ļĪ£ ĻĄ¼ņä▒ļÉ®ļŗłļŗż. ņśłļź╝ ļōżņ¢┤, qqqĻ░Ć "2+2ļŖö ņ¢╝ļ¦łņØĖĻ░Ć?"ļØ╝ļŖö ņ¦łļ¼ĖņØ┤ļØ╝ļ®┤, ņČ£ļĀź ĻĘĖļŻ╣ņØĆ ļ¬©ļŹĖņØ┤ ņāØņä▒ĒĢ£ ļŗżņØīĻ│╝ Ļ░ÖņØĆ ņŚ¼ļ¤¼ ļŗĄļ│ĆņØ┤ ļÉĀ ņłś ņ׳ņŖĄļŗłļŗż: a. o1="4"o_1 = "4"o1="4" b. o2="4ņ×ģļŗłļŗż."o_2 = "4ņ×ģļŗłļŗż."o2="4ņ×ģļŗłļŗż." c. o3="ļŗĄņØĆ4ņ×ģļŗłļŗż."o_3 = "ļŗĄņØĆ 4ņ×ģļŗłļŗż."o3="ļŗĄņØĆ4ņ×ģļŗłļŗż." d. o4="ņĀĢĒÖĢĒ׳4."o_4 = "ņĀĢĒÖĢĒ׳ 4."o4=" ņĀĢĒÖĢĒ׳4."
- 13. RLHF RM ŌåÆ PPO RLHF ŌåÆ RLAIF FACULTY TAE YOUNG LEE
- 14. ņāØĻ░üĒĢ┤ ļ│┤ņ×É!! FACULTY TAE YOUNG LEE
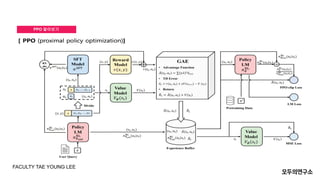
- 15. PPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
- 16. PPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
- 17. PPOņØś ĒĢ£Ļ│ä FACULTY TAE YOUNG LEE
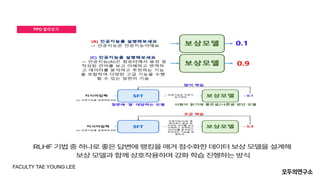
- 18. DPOņØś ņČ£Ēśä FACULTY TAE YOUNG LEE
- 19. DPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
- 20. DPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
- 21. DPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
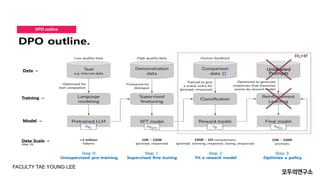
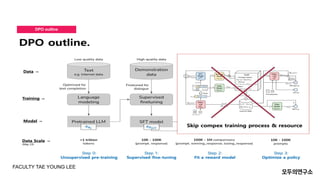
- 22. DPO outline FACULTY TAE YOUNG LEE
- 23. DPO outline FACULTY TAE YOUNG LEE
- 24. DPO ņĢīņĢäļ│┤ĻĖ░ FACULTY TAE YOUNG LEE
- 25. DPO ĒĢ£Ļ│ä FACULTY TAE YOUNG LEE
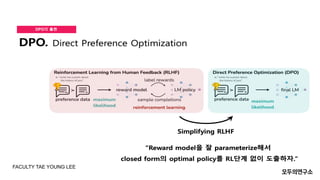
- 26. DPO Direct Preference Optimization (DPO) Direct Preference Optimization (DPO)ļŖö ņĀĢņ▒ģ ņĄ£ņĀüĒÖö ļ░®ļ▓Ģņ£╝ļĪ£, ņŚÉņØ┤ņĀäĒŖĖņØś Ē¢ēļÅÖ ņäĀĒāØņŚÉ ļīĆĒĢ£ ņäĀĒśĖļÅäļź╝ ņ¦üņĀæņĀüņ£╝ļĪ£ ļ░śņśüĒĢśņŚ¼ ņĄ£ņĀüĒÖöĒĢśļŖö ļ░®ņŗØņ×ģļŗłļŗż. ņØ┤ļŖö ņŻ╝ņ¢┤ņ¦ä Ē¢ēļÅÖļōżņØś ņäĀĒśĖļÅäļéś ņł£ņ£äļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢ®ļŗłļŗż. ĒŖ╣ņ¦Ģ: ŌŚÅ ņäĀĒśĖļÅäļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒĢ£ ņĀĢņ▒ģ ņĄ£ņĀüĒÖö: DPOļŖö Ē¢ēļÅÖņØś ņäĀĒśĖļÅäņŚÉ ļö░ļØ╝ ņĀĢņ▒ģņØä ņŚģļŹ░ņØ┤ĒŖĖĒĢ®ļŗłļŗż. ņ”ē, ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ņäĀĒāØĒĢĀ Ē¢ēļÅÖņŚÉ ļīĆĒĢ┤ ļŹö ņäĀĒśĖļÉśļŖö Ē¢ēļÅÖņØä ņäĀĒāØĒĢśļÅäļĪØ ĒĢÖņŖĄĒĢ®ļŗłļŗż. ŌŚÅ ļ¬ģņŗ£ņĀü ļ│┤ņāü ĒĢ©ņłśĻ░Ć ņĢäļŗī ņäĀĒśĖļÅä: ņØ╝ļ░śņĀüņØĖ Ļ░ĢĒÖöĒĢÖņŖĄņŚÉņä£ļŖö ļ│┤ņāü ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢśņ¦Ćļ¦ī, DPOņŚÉņä£ļŖö ņäĀĒśĖļÅäļź╝ ņ¦üņĀæņĀüņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņŚ¼ ņĄ£ņĀüĒÖöļź╝ ņ¦äĒ¢ēĒĢ®ļŗłļŗż. ŌŚÅ ņé¼ņÜ® ņśłņŗ£: DPOļŖö ņé¼ļ×īņØś ņäĀĒśĖļź╝ ļ░śņśüĒĢ£ Ļ░ĢĒÖöĒĢÖņŖĄ ņŗ£ņŖżĒģ£ņŚÉņä£ ņ£ĀņÜ®ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ņśłļź╝ ļōżņ¢┤, ņé¼ņÜ®ņ×ÉĻ░Ć ņäĀĒśĖĒĢśļŖö Ē¢ēļÅÖņØä ņÜ░ņäĀņĀüņ£╝ļĪ£ ĒĢÖņŖĄĒĢśĻ│Ā ņØ┤ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ņĀĢņ▒ģņØä ņĄ£ņĀüĒÖöĒĢśļŖö Ļ▓ĮņÜ░ņ×ģļŗłļŗż. ņןņĀÉ: ŌŚÅ ļ│┤ņāü ĒĢ©ņłśņØś ĒĢäņÜö ņŚåņØī: DPOļŖö ļ│┤ņāü ĒĢ©ņłś ņŚåņØ┤ ņäĀĒśĖļÅä ļŹ░ņØ┤Ēä░ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ĒĢÖņŖĄņØä ņ¦äĒ¢ēĒĢśļ»ĆļĪ£, ļ│┤ņāü ņäżĻ│äĻ░Ć ņ¢┤ļĀżņÜ┤ ĒÖśĻ▓ĮņŚÉņä£ ņ£ĀņÜ®ĒĢ®ļŗłļŗż. ŌŚÅ ņé¼ļ×īņØś ņäĀĒśĖļź╝ ļ░śņśü: ņØĖĻ░äņØś ĒīÉļŗ©ņØä ņ¦üņĀæņĀüņ£╝ļĪ£ ļ░śņśüĒĢĀ ņłś ņ׳ņ¢┤, ņé¼ļ×ī ņżæņŗ¼ņØś ņŗ£ņŖżĒģ£ņŚÉņä£ ĒÜ©Ļ│╝ņĀüņ×ģļŗłļŗż. ĒĢ£Ļ│ä: ŌŚÅ ņĀĢĒÖĢĒĢ£ ņäĀĒśĖļÅä ņłśņ¦æņØś ņ¢┤ļĀżņøĆ: ņäĀĒśĖļÅäļź╝ ņĀĢĒÖĢĒĢśĻ▓ī ņłśņ¦æĒĢśĻ│Ā ļ░śņśüĒĢśļŖö Ļ│╝ņĀĢņŚÉņä£ ņŗ£Ļ░äĻ│╝ ņ×ÉņøÉņØ┤ ļ¦ÄņØ┤ ņåīņÜöļÉĀ ņłś ņ׳ņŖĄļŗłļŗż. ŌŚÅ ĒāÉņāēĻ│╝ ņ░®ņĘ©ņØś ĻĘĀĒśĢ ļ¼ĖņĀ£: ņäĀĒśĖļÅä ĻĖ░ļ░ś ĒĢÖņŖĄņØĆ ĒāÉņāēĻ│╝ ņ░®ņĘ©ņØś ĻĘĀĒśĢņØä ļ¦×ņČöļŖö ļŹ░ ņ¢┤ļĀżņøĆņØ┤ ņ׳ņØä ņłś ņ׳ņŖĄļŗłļŗż. ņäĀĒśĖļÅäĻ░Ć ļ¬ģĒÖĢĒĢśņ¦Ć ņĢŖĻ▒░ļéś ļČĆņĪ▒ĒĢśļ®┤ ņĄ£ņĀüĒÖöņŚÉ ņ¢┤ļĀżņøĆņØä Ļ▓¬ņØä ņłś ņ׳ņŖĄļŗłļŗż. FACULTY TAE YOUNG LEE
- 27. GRPO Group Relative Policy Optimization (GRPO) Group Relative Policy Optimization (GRPO)ļŖö ĻĘĖļŻ╣ Ļ░äņØś ņāüļīĆņĀüņØĖ ņäĀĒśĖļÅäļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ņĄ£ņĀüĒÖöĒĢśļŖö ņĢīĻ│Āļ”¼ņ”śņ×ģļŗłļŗż. DPOņÖĆ ļŗ¼ļ”¼, GRPOļŖö ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖ Ļ░äņØś ņāüļīĆņĀüņØĖ Ē¢ēļÅÖ ņäĀĒśĖļÅäļź╝ Ļ│ĀļĀżĒĢśņŚ¼ ņĀĢņ▒ģņØä ņŚģļŹ░ņØ┤ĒŖĖĒĢ®ļŗłļŗż. ĒŖ╣ņ¦Ģ: ŌŚÅ ĻĘĖļŻ╣ Ļ░ä ņäĀĒśĖļÅä ļ╣äĻĄÉ: GRPOļŖö ņŚ¼ļ¤¼ Ļ░£ņ▓┤ļéś ĻĘĖļŻ╣ņØ┤ ņāüļīĆņĀüņ£╝ļĪ£ ņäĀĒśĖĒĢśļŖö Ē¢ēļÅÖļōżņØä ļ╣äĻĄÉĒĢśĻ│Ā, ĻĘĖļŻ╣ ļé┤ ņāüĒśĖņ×æņÜ®ņØä Ļ│ĀļĀżĒĢśņŚ¼ ņĀĢņ▒ģņØä ņĄ£ņĀüĒÖöĒĢ®ļŗłļŗż. ŌŚÅ ņāüļīĆņĀüņØĖ ņĄ£ņĀüĒÖö: Ļ░ü Ļ░£ņ▓┤Ļ░Ć ņäĀĒāØĒĢĀ ņłś ņ׳ļŖö Ē¢ēļÅÖņŚÉ ļīĆĒĢ£ ņāüļīĆņĀüņØĖ ņäĀĒśĖļÅäļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ņĄ£ņĀüĒÖöĒĢśļ»ĆļĪ£, ņ¦æļŗ©ņĀü ņ░©ņøÉņŚÉņä£ņØś ĒÜ©ņ£©ņä▒ņØä ĻĘ╣ļīĆĒÖöĒĢ®ļŗłļŗż. ŌŚÅ ņ¦æļŗ©ņĀü ņØśņé¼Ļ▓░ņĀĢ: ņØ┤ ļ░®ņŗØņØĆ ņé¼ĒÜīņĀü ņäĀĒāØ ņØ┤ļĪĀņØ┤ļéś ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖ Ļ░äņØś ĒśæļĀź/Ļ▓Įņ¤üņØä Ļ│ĀļĀżĒĢśļŖö ļ¼ĖņĀ£ņŚÉņä£ ņ£Āļ”¼ĒĢ®ļŗłļŗż. ņןņĀÉ: ŌŚÅ ņ¦æļŗ©ņĀü ĒÜ©ņ£©ņä▒: ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ņāüĒśĖņ×æņÜ®ĒĢśļŖö ĒÖśĻ▓ĮņŚÉņä£, ĻĘĖļŻ╣ Ļ░äņØś ĒÜ©ņ£©ņä▒ņØä ļ░śņśüĒĢśņŚ¼ ņĄ£ņĀüĒÖöĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ņśłļź╝ ļōżņ¢┤, ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ĒśæļĀźĒĢśļŖö ņāüĒÖ®ņŚÉņä£ ĒÜ©Ļ│╝ņĀüņØĖ ņĀĢņ▒ģņØä ņāØņä▒ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ŌŚÅ ņāüļīĆņĀü ņäĀĒśĖļÅä ĒÖ£ņÜ®: ņāüļīĆņĀüņØĖ ņäĀĒśĖļÅäļź╝ ļ╣äĻĄÉĒĢśņŚ¼ ņĄ£ņĀüĒÖöĒĢśļ»ĆļĪ£, ĻĘĖļŻ╣ Ļ░äņØś ņÜ░ņäĀņł£ņ£äļéś ņäĀĒāØņØä ļ░śņśüĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ĒĢ£Ļ│ä: ŌŚÅ ļ│Ąņ×ĪĒĢ£ Ļ│äņé░: ņŚ¼ļ¤¼ ĻĘĖļŻ╣ņØś ņāüļīĆņĀü ņäĀĒśĖļÅäļź╝ Ļ│ĀļĀżĒĢ┤ņĢ╝ ĒĢśļ»ĆļĪ£, Ļ│äņé░ ļ╣äņÜ®ņØ┤ ļ¦ÄņØ┤ ļōż ņłś ņ׳ņŖĄļŗłļŗż. ĒŖ╣Ē׳ ņāüĒśĖņ×æņÜ®ņØ┤ ļ│Ąņ×ĪĒĢ£ ĒÖśĻ▓ĮņŚÉņä£ļŖö ļŹö ļ¦ÄņØĆ Ļ│äņé░ ņ×ÉņøÉņØ┤ ĒĢäņÜöĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ŌŚÅ ĻĘĖļŻ╣ ļé┤ ļ│ĆļÅÖņä▒ ļ¼ĖņĀ£: Ļ░ü ĻĘĖļŻ╣ ļé┤ņØś Ļ░£ņ▓┤ļōżņØ┤ Ļ░Ćņ¦ĆļŖö ņāüļīĆņĀüņØĖ ņäĀĒśĖļÅäņØś ņ░©ņØ┤ļź╝ ņ▓śļ”¼ĒĢśļŖö ļŹ░ ņ¢┤ļĀżņøĆņØ┤ ņ׳ņØä ņłś ņ׳ņŖĄļŗłļŗż. FACULTY TAE YOUNG LEE
- 28. DPO vs GRPO FACULTY TAE YOUNG LEE
- 29. ļ¬©ļæÉņØśņŚ░ĻĄ¼ņåī PPT Ēæ£ņ¦Ć ņĀ£ļ¬®ņØä ņ×ģļĀźĒĢ┤ņŻ╝ņäĖņÜö. 03 Data Attribution DeepSeek-R1
- 30. DeepSeek-R1 FACULTY TAE YOUNG LEE
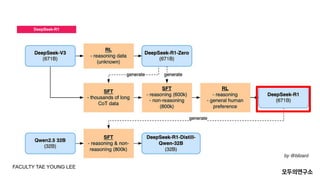
- 31. DeepSeek-R1 DeepSeek-R1: Cold StartņÖĆ ļŗżļŗ©Ļ│ä ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ ņäżĻ│äņØś ņØśņØś ŌŚÅ Cold Start ļŹ░ņØ┤Ēä░: RL ĒĢÖņŖĄ ņ┤łĻĖ░ņØś ļČłņĢłņĀĢņØä ņĀ£Ļ▒░ĒĢśĻ│Ā, ļ¬©ļŹĖņØś ņ┤łĻĖ░ ņä▒ļŖźņØä Ļ░ĆļÅģņä▒ ļ░Å ņé¼ņÜ®ņ×É ņ╣£ĒÖöņĀüņØĖ ĒśĢĒā£ļĪ£ ļ│┤ņן. ŌŚÅ Reasoning ļŹ░ņØ┤Ēä░: ņĀĢĒÖĢļÅäņÖĆ ļģ╝ļ”¼ņĀü ņĀĢĒĢ®ņä▒ņØä ļ│┤ņןĒĢśļ®┤ņä£ ļ¬©ļŹĖņØś ļģ╝ļ”¼ ņČöļĪĀ ņä▒ļŖźņØä ĻĘ╣ļīĆĒÖö. ŌŚÅ Non-Reasoning ļŹ░ņØ┤Ēä░: ļŗżļ¬®ņĀü ņä▒ļŖźņØä Ļ░ĢĒÖöĒĢśĻ│Ā, ņé¼ņÜ®ņ×É Ļ▓ĮĒŚśņØä Ļ░£ņäĀĒĢśļŖö ļŹ░ ĻĖ░ņŚ¼. ŌŚÅ ņĀäņ▓┤ ļŹ░ņØ┤Ēä░ ņäżĻ│ä: ŌŚÅ ņ┤łĻĖ░ ļŗ©Ļ│äņŚÉņä£ Ļ░ĆļÅģņä▒ ļåÆņØĆ ļŹ░ņØ┤Ēä░ļź╝ ņłśņ¦æĒĢśņŚ¼ ĻĖ░ļ░śņØä ļŗżņ¦ĆĻ│Ā, ĒøäņåŹ ļŗ©Ļ│äļź╝ ĒåĄĒĢ┤ ļŗżņ¢æĒĢ£ ļÅäļ®öņØĖĻ│╝ ņ×æņŚģņŚÉ ļīĆĒĢ£ ņØ╝ļ░śņĀü ņä▒ļŖźņØä Ļ░ĢĒÖö. ĒĢĄņŗ¼ ĒŖ╣ņ¦Ģ Cold Start ļŹ░ņØ┤Ēä░ DeepSeek-R1ņØĆ ņåīļ¤ēņØś Ļ│ĀĒÆłņ¦ł ļŹ░ņØ┤Ēä░(SFT)ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņ┤łĻĖ░ RL ņĢłņĀĢņä▒ņØä ļ│┤ņןĒĢ®ļŗłļŗż. ŌŚÅ Cold Start ļŹ░ņØ┤Ēä░ ņäżĻ│ä: ŌŚÅ ņČöļĪĀ Ļ│╝ņĀĢ(CoT)ņØä ļ¬ģĒÖĢĒ׳ ĒżĒĢ©ĒĢśļŖö ļŹ░ņØ┤Ēä░ ņłśņ¦æ. ŌŚÅ ņØĖĻ░ä ņŻ╝ņäØņØä ĒåĄĒĢ┤ ņØĮĻĖ░ ņē¼ņÜ┤ ņČ£ļĀź Ēī©Ēä┤ ņāØņä▒. Reasoning ņżæņŗ¼ RL SFTļĪ£ ņ┤łĻĖ░ ļ¬©ļŹĖņØä ĒĢÖņŖĄĒĢ£ ļÆż, DeepSeek-R1-ZeroņÖĆ ļÅÖņØ╝ĒĢ£ RL ĒöäļĪ£ņäĖņŖżļź╝ ņĀüņÜ®ĒĢśņŚ¼ ņČöļĪĀ ļŖźļĀźņØä Ļ░ĢĒÖöĒ¢łņŖĄļŗłļŗż. ŌŚÅ ņ¢Ėņ¢┤ ņØ╝Ļ┤Ćņä▒(Language Consistency) ļ│┤ņāüņØä ņČöĻ░ĆĒĢ┤ ļŗżĻĄŁņ¢┤ Ēś╝ĒĢ® ļ¼ĖņĀ£ ĒĢ┤Ļ▓░. Rejection SamplingĻ│╝ ņČöĻ░Ć SFT RLļĪ£ ņłśņ¦æĒĢ£ ļŹ░ņØ┤Ēä░ļź╝ ņäĀļ│äĒĢśņŚ¼ 80ļ¦ī Ļ░£ņØś Ļ│ĀĒÆłņ¦ł ļŹ░ņØ┤Ēä░ļź╝ ĒÖĢļ│┤. ŌŚÅ ņĢĮ 60ļ¦ī Ļ░£: ņłśĒĢÖ, ņĮöļö®, ļģ╝ļ”¼ ļō▒ ņČöļĪĀ ņżæņŗ¼ ļŹ░ņØ┤Ēä░. ŌŚÅ ņĢĮ 20ļ¦ī Ļ░£: ĻĖĆņō░ĻĖ░, ļ▓łņŚŁ ļō▒ ņØ╝ļ░ś ņ×æņŚģ ļŹ░ņØ┤Ēä░. ņĀäļ░®ņ£ä RL ņĄ£ņóģ RL ļŗ©Ļ│äņŚÉņä£ļŖö ļ¬©ļōĀ ņŗ£ļéśļ”¼ņśżņŚÉ ļīĆņØæĒĢśļŖö ļ¬©ļŹĖņØä ĒĢÖņŖĄ. ŌŚÅ ļÅäņøĆ ļ░Å ļ¼┤ĒĢ┤ņä▒ ĒÅēĻ░Ć: ŌŚÅ ļÅäņøĆņØ┤ ļÉśļŖö ņØæļŗĄ(Helpful)Ļ│╝ ņĢłņĀäĒĢ£ ņØæļŗĄ(Harmless)ņØä ĒÅēĻ░Ć ļ░Å ņĄ£ņĀüĒÖö. FACULTY TAE YOUNG LEE
- 32. DeepSeek-R1 ļŹ░ņØ┤Ēä░ņäżĻ│ä FACULTY TAE YOUNG LEE
- 33. Thank You FACULTY TAE YOUNG LEE