[261] ???????? ??????????? ???????????? ?????????
?
508 likes?46,276 views

DEVIEW2015 DAY2. ??? ???? ????? ????








![[261] ???????? ??????????? ???????????? ?????????](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-9-320.jpg)





![[261] ???????? ??????????? ???????????? ?????????](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-17-320.jpg)





![[261] ???????? ??????????? ???????????? ?????????](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-24-320.jpg)





























![? ??? ???? high TPS? ??
save minhash(110)[1 DB write] =
load minhash(100)[1 DB read] x
compute minhash(101~110)[input buffer]
old minhash new new new
local minhash
memorystorage
updated minhash
??? ????
??? ?????
?????.
micro batch
?? ???
????? ???
?? ??.
(????)](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-69-320.jpg)







![?? ??? ??? string?? ??? ???? ? ???.
sig45 Tom Jerry Robert Jack
string?? ??? ??
Ī░[Tom, Jerry, Robert, Jack]Ī▒
??? ? ?? ???
json.dumps(data)
json.loads(data_str)
[write] [read]
Ī░[Tom, Jerry, Robert, Jack]Ī▒](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-79-320.jpg)
![??? ??? String??. ??!
Order! O(1) vs O(N)
In [24]: %time gs.load_benchmark('user','key')
CPU times: user 0.32 s, sys: 0.03 s, total: 0.34 s
Wall time: 0.42 s
In [25]: %time gs.load_benchmark('user','set')
CPU times: user 32.34 s, sys: 0.13 s, total: 32.47 s
Wall time: 33.88 s
1)
? ????? String? Set?? ?? ??.
string set](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-80-320.jpg)
![Ī«redis stringĪ» ? mget ??? ????.
(multiple get at once)
N call round trip -> 1 call
In [9]: %timeit [redis.get(s) for s in sigs]
100 loops, best of 3: 9.99 ms per loop
In [10]: %timeit redis.mget(sigs)
1000 loops, best of 3: 759 us per loop
2)](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-81-320.jpg)




















![[KAIST ?????] ??? ????? ?? ?? ????](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=560&fit=bounds)
![[??? ???? ?? ?] ??? ?? ?? ??? ?? ??? - ????? ??? ??](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=560&fit=bounds)




![[NDC18] ??? ? ???? ??? ????? ???: ?? ??? ?? ?? ??](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=560&fit=bounds)




![[NDC18] ??? ? ???? ??? ????? ???: ?? ??? ?? ?? ?? (2?)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=560&fit=bounds)


![? 17? ???(BOAZ) ???? ???? - [?????] : ??? ???? ??? Elasticsearch ???? ???](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=560&fit=bounds)

![[NDC ??] ??? ??????? ? ?? ??](https://cdn.slidesharecdn.com/ss_thumbnails/20140529-140529031622-phpapp02-thumbnail.jpg?width=560&fit=bounds)






![[2B2]???? ??????????? ?????????? ????????? ??????? ?????](https://cdn.slidesharecdn.com/ss_thumbnails/2b2-140929202533-phpapp01-thumbnail.jpg?width=560&fit=bounds)
More Related Content
What's hot (20)
Similar to [261] ???????? ??????????? ???????????? ????????? (20)


![[E-commerce & Retail Day] ??????? ????](https://cdn.slidesharecdn.com/ss_thumbnails/random-171027021822-thumbnail.jpg?width=560&fit=bounds)














![NDC 2016, [???] ???? ??? ?? ??? ??????](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=560&fit=bounds)
More from NAVER D2 (20)
![[211] ????? ???? ??? ???](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=560&fit=bounds)
![[233] ?? ???? ??????? ???? Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=560&fit=bounds)
![[215] Druid? ?? ??? ??? ????](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=560&fit=bounds)
![[245]Papago Internals: ????? ???? ??](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=560&fit=bounds)
![[236] ??? ??? ??? ???: ??? ??????? ?? ??](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=560&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=560&fit=bounds)
![[244]??? ?? ??? ?? ????? ???](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=560&fit=bounds)
![[243] Deep Learning to help studentĪ»s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=560&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=560&fit=bounds)
![Old version: [233]?? ???? ??????? ???? Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=560&fit=bounds)
![[226]NAVER ?? deep click prediction: ????? ????](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=560&fit=bounds)
![[225]NSML: ???? ??? ????? & ?? ?? ?????](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=560&fit=bounds)
![[224]??? ??? ???](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=560&fit=bounds)
![[216]Search Reliability Engineering (??: ???? ???? ?? ??? ?????)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=560&fit=bounds)
![[214] Ai Serving Platform: ?? ? ? ?? ????? ???? ?? ?????](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=560&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=560&fit=bounds)
![[232] TensorRT? ??? ??? Inference ???](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=560&fit=bounds)
![[242]??? ??? ??? ?? ?? ?? ???? ??: ???? ?? POI ?? ??](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=560&fit=bounds)
![[212]C3, ??? ???? ???? ??? ?? ????](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=560&fit=bounds)
![[223]???? QA: ????, NLP???](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=560&fit=bounds)
[261] ???????? ??????????? ???????????? ?????????
- 1. ??? ???? ????: ??? ????? ????? ?? ????? ??? NUMBERWORKS ??
- 2. ??? ? ? ??? Ī«????Ī»?? data science firm? ?????
- 3. ?? ??? ????? 1. ????? ?? ?? ???? 2. ?? ???? ???? ?? 3. ???? ? ??? ?????. 4. ??
- 4. ?????? ? ?? ?? ???.
- 5. Recommendation systems come in two types
- 8. Collaborative Filtering ??? ??? ?????? ? ???.
- 10. 10 Collaborative Filtering ?? 2??? ??? ???. Memory-based Model-based ??? ?? ??(hybrid)?? ???.
- 11. 11 Memory-based? ??? ??? ????? ?? ? ??? ?????.
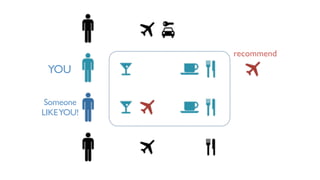
- 13. YOU
- 15. ?? ?? ??? Jaccard similarity ???? ??? ??? ???? ?? A? ??? ?? B? ??? ??
- 19. ?? ??? ??? Hadoop? ??? ????
- 20. img from : http://thepage.time.com/2009/04/18/why-is-this-elephant-crying/ ?? Hadoop??? ?? ? ?? ???
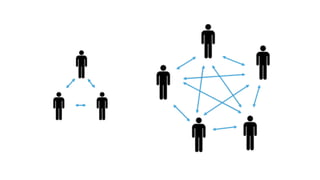
- 21. ?? ??? ??? ?? pre-clustering? ?????
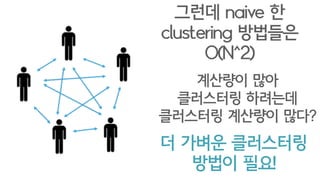
- 22. ??? naive ? clustering ???? O(N^2) ???? ?? ????? ???? ????? ???? ??? ? ??? ????? ??? ??!
- 23. pre-clustering? ??? ??? ??? ??? ????
- 25. Use MinHASH as LSH(min-wiseindependentpermutationslocalitysensitivehashing) ? ??? ?? ?????
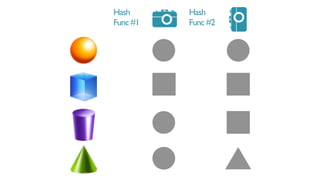
- 26. ?? ? ????? ????. Locality Sensitive Hashing
- 27. ?? ?????? hash? ? ???? ?? ?? ??? ?????
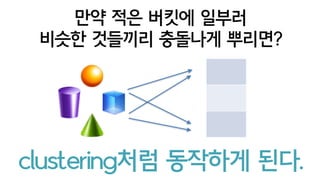
- 28. ?? ?? ??? ??? ? ??? ???? ???? ???? clustering?? ???? ??.
- 29. Make hash functions Hash function #1 Hash function #2 HOW DOES LSH WORK? (localitysensitivehashing)
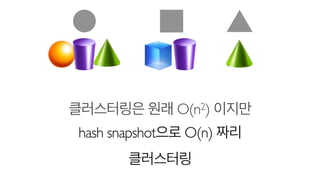
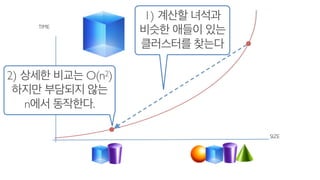
- 31. ?????? ?? O(n2) ??? hash snapshot?? O(n) ?? ?????
- 32. TIME SIZE 2) ??? ??? O(n2) ??? ???? ?? n?? ????. 1) ??? ??? ??? ??? ?? ????? ???
- 33. ?? hash function? ??? ??? ??? ?? ????? ?? hash??. ??? ??? ??? ??? ??? ????, ????? ??? ?? ??? hash function? ????.
- 34. - cosine similarity - hamming distance - euclidean distance - jaccard similarity ??? ??? ??.
- 35. MinHash? Jaccard similarity? ???? ??? LSH ?? ?? ????!
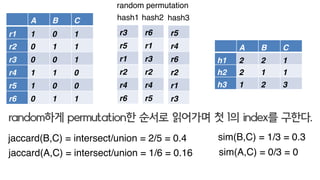
- 36. A B C r1 1 0 1 r2 0 1 1 r3 0 0 1 r4 1 1 0 r5 1 0 0 r6 0 1 1 A B C h1 2 4 1 h2 2 1 1 h3 1 2 3 r3 r5 r1 r2 r4 r6 r6 r1 r3 r2 r4 r5 hash1 hash2 random permutation r5 r4 r6 r2 r1 r3 hash3 random?? permutation? ??? ???? ? 1? index? ???. jaccard(B,C) = 2/5 = 0.4 jaccard(A,C) = 1/6 = 0.16 sim(B,C) = 1/3 = 0.3 sim(A,C) = 0/3 = 0 jaccard = intersect/union sim = intersect/length
- 37. ???? random permutation? ??? ?? ???? ?? ???? ??? universal hash? ?? random generation ?? random permutation? ???(proxy)? ???? ??. ?? ?? ??? ???? ??? ??? ???? minhash? ?? ? ????.
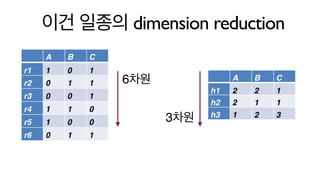
- 38. ?? ??? dimension reduction A B C r1 1 0 1 r2 0 1 1 r3 0 0 1 r4 1 1 0 r5 1 0 0 r6 0 1 1 A B C h1 2 2 1 h2 2 1 1 h3 1 2 3 6?? 3??
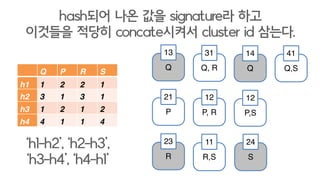
- 39. Q P R S s1 1 2 2 1 s2 3 1 3 1 s3 1 2 1 2 s4 4 1 1 4 hash?? ?? ?? signature? ?? ???? ??? concate??? cluster id ???. Ī«s1-s2Ī», Ī«s2-s3Ī», Ī«s3-s4Ī», Ī«s4-s1Ī» Q 13 Q, R 31 Q 14 Q,S 41 P 21 P, R 12 P,S 12 R 23 R,S 11 S 24
- 40. ??? typical? Batch Implementation? ??? ????. (item to item ???? ??)
- 41. minhash? ???? ??? for ?? in ?? ???: ? ??? ?? click stream ???? ??? ??? minhash signature ???? signature?? concate?? ??? cluster id ? ??? ?? cluster id?? ???? for cluster in ???? ?????: if length(????) > threshold: ????? ??? ?? ??
- 42. ???? ??? ???? ?? item? ??? ? ?? item? minhash?? ??? minhash?? concate?? ???? cluster ? ? ?? for cluster in ??? ??? ?????: ????? ??? ?? ?? item? ?? ? item?? click stream? ?? click stream??? ??? ?? pair ??? ?? ? ????? ?? ??? ?? ??? top N?? ??
- 43. It is typical implementation. but not attractive :(
- 44. ? ??? ??? ??!
- 45. ?? ??? 2?? ??? ??. ?? ??
- 46. Heavy I/O ? ?? : ???? I/O ??? ?? ??? ?? ??! minhash? ????? for ?? in ?? ???: ? ??? ?? click stream ???? ??? ??? minhash signature ???? signature?? concate?? ??? cluster id ? ??? ?? cluster id?? ???? for cluster in ???? ?????: if length(????) > threshold: ????? ??? ?? ?? ???? ??? ???? ?? item? ??? ? ?? item? minhash?? ??? minhash?? concate?? cluster id ????? ?? ?? ??? ??? cluster?? ? ?? for cluster in ??? ??? ?????: ????? ??? ?? item? ?? ? item?? click stream? ?? click stream??? ??? ?? pair ??? ?? ? ????? ?? ??? ?? ??? top N?? ?? ?? ??? ???? ??
- 47. - speed gain ??? ????. ??? ????. - quality loss ?? : ?? : ????? ??
- 48. ??? ?? ???? ?? ??? ??? ???? ??? ???? ? ????
- 49. ? I/O ??? ?? ???? ??? ??? ??? ??? ??????.
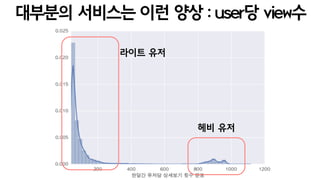
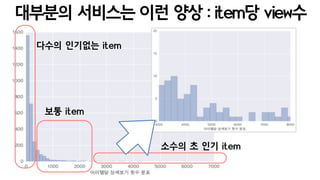
- 50. ???? ???? ?? ?? : user? view? ??? ?? ?? ??
- 51. ???? ???? ?? ?? : item? view? ??? ???? item ?? item ??? ? ?? item
- 53. ?? ???? ??? ??? ?? = ?????? ?? ?? (??????) = ???? ? click stream = ????? ?? ??? = ????? ?? ??? ?? ????. = ?? page out? ????. =????? ????.
- 54. ?? ??? ?? ??? ?? ???? ?? ?? ??? ?? ??? ? ?? ???? ??? ???? ?? ??? ??? ???? ?? ?? ?? ?? ? ??.
- 55. ?? ?? = ?? ??? ?? ??, ?? ??? = use good dimension reducer = ????? ??? ?? ???? ???. = ? ??? ?? ?? ???? = minhash
- 56. ?? ??? S1 S2 ĪŁ Sn S1 S2 ĪŁ Sn ?? ??? hash function? n?? signature?? ??? ?? ? ?? ??
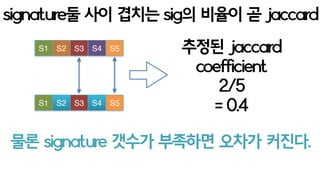
- 57. S1 S2 S3 S4 signature? ?? ??? sig? ??? ? jaccard S5 S1 S2 S3 S4 S5 ??? jaccard coefficient 2/5 = 0.4 ??? ??? ???, ? ???? ?? jaccard?? ??? ????
- 58. ? ?? hash func? ?? signature? ??? ?? ??? ??? ????!
- 59. ??? ???? ???? ??????? 100?? signature? root mean square error ??? ?? RMSE 0.03 ?? ??? ????! ???? ????
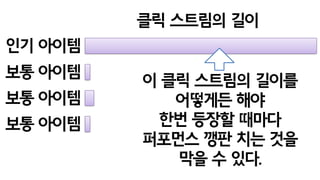
- 60. ?? ??? ??? ???? ?? ?? ??? ?? signature? ?? ?? ??? ???? ?? clustering ?? ?? ??? ? click stream? ??? signature? ?? ?? ??? ??? ?? ??? click stream?? signature overlap? ???
- 61. ? ??? ?? ??? ??? in-memory? fit?? ????? ??? ?? ??? ??
- 62. +??? ??? in-memory? fit?? +??? ??? ???? ?? ?? ???? ?????? ?????? ??? ??? ?? ?? ???. ???? ?? disk io?? ??
- 63. item??? 4byte?? ???? 100? 100 x 4 + 200 = 600 byte ?? ?? ?? 200 byte ? ?? ?? ??? 1G? ??? 1024^3 / 800 = 1,789,569 1??? 180? ?? item? click stream? ???? ?? ?? ? ??! (?? ?? ?? ??)
- 64. +??? ??? ??? ? ?? ?? Job Ī░?? ? ??? ?????Ī▒ +?? ?? ?? ??? ??????? ??. Ī░??? ??? ??? ?? ???? ?? ?? ??? ?? ????Ī▒, Ī░??? ????Ī▒
- 65. ??? click? ???? ??? ??? ?? signature??? ? ?? ?? ?? ??? No! minhash? Ī«min ??Ī»? Ī«chainĪ»??. ??? ?? ??? ??? ??.
- 67. Associative property ???? ? ???? ???? ?? ???? ?? Idempotence ???? ???? ???? ?? ???? ??.
- 68. ???? ???? ??? ??? = ? ??? ?? ???? ??? ? ?? ??? ?????, ???? ??? ???! click? ?????? ?? ????!
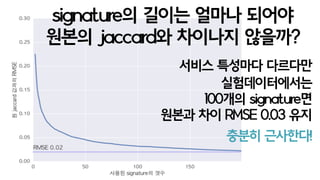
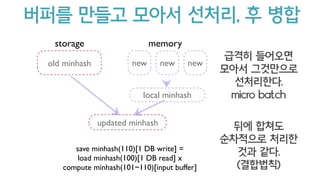
- 69. ? ??? ???? high TPS? ?? save minhash(110)[1 DB write] = load minhash(100)[1 DB read] x compute minhash(101~110)[input buffer] old minhash new new new local minhash memorystorage updated minhash ??? ???? ??? ????? ?????. micro batch ?? ??? ????? ??? ?? ??. (????)
- 70. ?~ ??? ? ?? ?? ???? ? ????. ??? ??? ?? ??? ??? ????
- 71. S1 S2 ĪŁ Sn ??? ? ???. S1 S2 ĪŁ Sn S1 S2 ĪŁ Sn S1 S2 ĪŁ Sn S1 S2 ĪŁ Sn ??? n^2? ??? item A item B item C item D item E
- 72. ?? ?? ?? ?? Secondary Index? ???.
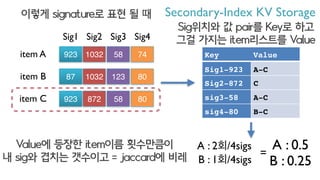
- 73. item A item B item C 923 1032 58 74 87 1032 123 80 923 872 58 80 Sig1 Sig2 Sig3 Sig4 ??? signature? ?? ? ? Secondary-Index KV Storage Sig??? ? pair? Key? ?? ?? ??? item???? Value Key Value Sig1-923 A-C Sig2-872 C sig3-58 A-C sig4-80 B-C A : 2?/4sigs B : 1?/4sigs A : 0.5 B : 0.25 Value? ??? item?? ????? ? sig? ??? ???? = jaccard? ?? =
- 74. Secondary Index lookup??? Jaccard? ??? ? ??. ???~!
- 75. requirement: minhash??? ?????? 2nd idx? ?? ?? ?? ???? = ??? ????? ???? ???!
- 76. Large Secondary-Index? ?? ????? ?????
- 77. Key Value Sig1-923 A-C Sig2-872 C sig3-58 A-C sig4-80 B-C ??? membership ??? ???? ??. REDIS? ?? ?????? ? ?? ???
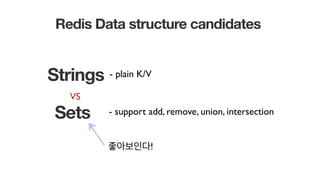
- 78. Redis Data structure candidates Strings Sets - support add, remove, union, intersection - plain K/V ?????! VS
- 79. ?? ??? ??? string?? ??? ???? ? ???. sig45 Tom Jerry Robert Jack string?? ??? ?? Ī░[Tom, Jerry, Robert, Jack]Ī▒ ??? ? ?? ??? json.dumps(data) json.loads(data_str) [write] [read] Ī░[Tom, Jerry, Robert, Jack]Ī▒
- 80. ??? ??? String??. ??! Order! O(1) vs O(N) In [24]: %time gs.load_benchmark('user','key') CPU times: user 0.32 s, sys: 0.03 s, total: 0.34 s Wall time: 0.42 s In [25]: %time gs.load_benchmark('user','set') CPU times: user 32.34 s, sys: 0.13 s, total: 32.47 s Wall time: 33.88 s 1) ? ????? String? Set?? ?? ??. string set
- 81. Ī«redis stringĪ» ? mget ??? ????. (multiple get at once) N call round trip -> 1 call In [9]: %timeit [redis.get(s) for s in sigs] 100 loops, best of 3: 9.99 ms per loop In [10]: %timeit redis.mget(sigs) 1000 loops, best of 3: 759 us per loop 2)
- 82. 3) string ? ??? ?????? ????. = ???? ? ?? ?? ?? ? ?? ??? compress speed(”╠s) 0.0 35.0 70.0 105.0 140.0 snappy zlib 134.0 17.3 size(%) 0% 25% 50% 75% 100% snappy zlib 40% 70% snappy?? ????? ?? ????? ??
- 83. redis ? pipe??? ??? transaction ? ???. ??? set? ???? ?? ??? ???? 4) item A 923 1032 58 74 item B 87 1032 123 80 item C 923 973 58 80 sig2-1032 sig2-973 A-B C Secondary-Index 973 sig2-1032 sig2-973 B A-C sig1 sig2 sig3 sig4 key: pos-value value: member case) sig2-1032? A? ???? sig2-973? ?? - atomic?? minhash signature ????
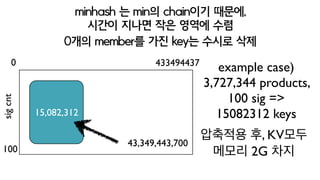
- 84. ?? ? ?? ??? 2nd index key space? ?????? ?????? hash max val * sig cnt? key? ?? hash max? 433,494,437? Fibonacci primes? ?? 100?? signature? ??? ?? ????? 433,494,437,00 ?? key?? ??. ???.
- 85. minhash ? min? chain?? ???, ? ??? ??? ?? ??? ?? 100 15,082,312 4334944370 sigcnt 43,349,443,700 0?? member? ?? key? ??? ?? example case)? 3,727,344 products, ? 100 sig => 15082312 keys ???? ?, KV?? ??? 2G ?? ??
- 86. REDIS? ???? transaction? ????? ?? update? ?? Secondary Index? ??????.
- 87. ??
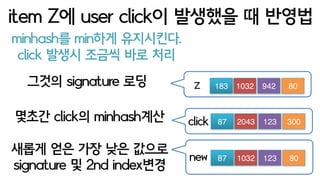
- 88. minhash? min?? ?????. item Z? user click? ???? ? ??? Z 183 1032 942 80??? signature ?? click ? minhash?? 87 2043 123 300click ??? ?? ?? ?? ??? signature ? 2nd index?? new 87 1032 123 80 click ??? ??? ?? ??
- 89. ?? item Z? ?? ?? ??? ???? Secondary Index ? ?? ? ?? flow item Z 87 1032 123 80 ??? signature ?? Sig1 - 87 Sig2 - 1032 Sig3 - 123 Sig4 - 80 A-B-D-F-Z C-G-Z A-B-D-Z B-D-F-Zredis.mget?? ??? ??? ??? ?????, ??? A:2/4 =0.5 B:3/4 =0.75 C:1/4 =0.25 D:3/4 =0.75
- 90. ???? ???? ?????? minhash?1G 2ndindex?2G ??? Mem Size ??1G ??? CPU Power REDIS1core minhash??1core ????1core
- 91. ???? ?????.
- 92. ?? ??? ????? ?? ??? Memory based ??? ??? ?? ???? ? (ALS, NMF, Markov Chain??) ??? ??????? ? ??? ???.
- 93. ?? ??? ???? No!
- 94. 99.9% ???? ?? ? ??? ??? ? 1169KB 51KB logo.bmp logo.jpg 1/
- 95. ?22
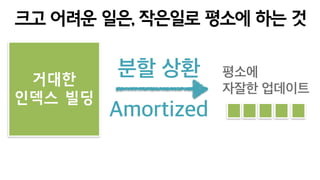
- 96. ?? ??? ??, ???? ??? ?? ? ??? ??? ?? Amortized ?? ?? ??? ? ??? ????
- 97. ?? ?? ??? ?? ????? ????? ??? ?? ?? ?? ??????.
- 98. ??? ????? ???? ?? ??? ?? ???? ??? ??? ???? ??? ??
- 99. Thank You