






















![2018?Seitaro Shinagawa AHC-lab NAIST
サーベイしたら研究の計画を立てる
最初に指導教員と綿密な議論をしておく
? この研究のウリはどこか
? 手法は何を使うか(比較手法はどうするか)
? データは何を使うか(新規に集めるならその方法についても)
? 評価はどうするか
? どこの国際会議?論文誌に出すか
[事前執筆型のススメ]
事前執筆して実際に文章におこしてみると、気づいていなかった穴
にも事前に察知できる
参考文献:スタンフォードで学んだ研究の生産性を上げる4つの方法
https://note.mu/ryosuzuki/n/ndae1d84d6103
2018/6/11 33/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-33-320.jpg)
![2018?Seitaro Shinagawa AHC-lab NAIST
論文をどこに出す?
[修士の狙い目] 最低でもここで成仏だ!
採択率が高い会議(50%以上)
? EMBC (CC)
? IWSDS (NL, SD)
? COCOSDA (NL, SD)
? トップ会議のworkshop (NIPSなど)
[目標]
各分野のトップ会議(採択率30%)
? NIPS, ICML, ICLR, IJCNN
? IJCAI, AAAI (人工知能系なんでも)
? ICASSP, INTERSPEECH (SP, CC, SD, 採択率50%)
? ASRU (SP, SD)
? ACL, EMNLP, NAACL ([2nd tier] COLING, IJCNLP, EACL) (NL, SD)
? CVPR, ECCV, ICCV, ([2nd tier] BMVC) (画像系)
? KDD, PAKDD (データ系)
2018/6/11 34/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-34-320.jpg)


![2018?Seitaro Shinagawa AHC-lab NAIST
実際おススメなのは予備実験型
待ちきれない型も最初の実験が予備実験ならよい
むしろ予備実験してアタリをつけられるとより安全
アイデア→予備実験
→(実験回しつつ)サーベイ
→(実験回しつつ)事前執筆(比較対象の検討など)
→本実験&執筆
[データ収集が間に入る場合]
アイデア→(人工データで)予備実験
→(データ収集しつつ)サーベイ
→(データ収集しつつ)事前執筆 (比較対象の検討
など)
→本実験&執筆
この部分を予備実験
として捉える
2018/6/11 37/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-37-320.jpg)


![2018?Seitaro Shinagawa AHC-lab NAIST
基本的にどうすると落ちるか
当たり前のことですがツッコミどころが多いと落ちます!
例:データセットが小さい、人工データ(簡単なデータ)でしか実験してない、比較
対象が間違っている、比較実験が十分でない、ストーリーが理解できない、etc.
その他、図が汚い、参考文献の書式が揃ってない、タイポが沢山あるがあれば
それだけで査読者の心象が悪くなる
論文のウリに対して、ツッコミどころがあるごとに評価が削られていくとみて良い
[ウリ]
? 驚愕の新規の発見をした
? 今までできなかったようなことができるようになった
? 徹底的に網羅的な調査をした
など
2018/6/11 40/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-40-320.jpg)

良い研究をする
? この研究のウリはどこか
? 手法は何を使うか
? データは何を使うか(新規に集めるならその方法についても)
? 評価はどうするか
事前執筆して文章におこしてみると、気づいていなかった穴にも事
前に察知できる
[表象レベル]
図が汚い、参考文献の書式が揃ってない、タイポなど
対処:ひたすら添削→reviseを繰り返すしかない
参考文献:スタンフォードで学んだ研究の生産性を上げる4つの方法
https://note.mu/ryosuzuki/n/ndae1d84d6103
2018/6/11 41/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-41-320.jpg)








![2018?Seitaro Shinagawa AHC-lab NAIST
悪い点を克服するには
ボスに相談したい
議論できるのは基本的に面談の時と先生ありミーティングの時(足りない!)
→必要に応じてメールでアポを取って突撃、自ら議論できる時間をつくる
[必要な場合とは?]
研究のおおまかな方針を決めたい場合
「こういうデータ、手法、評価方法でこういうことを明らかにするのはどうですか?」
ボスの研究の勘所はほぼ正しいので難色を示された場合は再考した方がいい
他の先生に相談したい
やはりアポをとるのが安全。研究の方針、困っていることなど自分からどんどん
聞きに行こう。「先生は死なぬよう」積極的に使おう(僕らは授業料を払っている!)
先に先輩に相談した方がいいこと
計算機の使い方、ライブラリがインストールできない、など。学生で解決できること
が増えるほど先生が指導に集中できるのでどんどん増やしていきたいところ
2018/6/11 51/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-51-320.jpg)











![2018?Seitaro Shinagawa AHC-lab NAIST
Q&Aまとめ
Q.発表者は実際どのくらい読んでいるか(一本あたり、数)
A.
速読: 大体10分~20分。一通り要点まとめができるまで読む
要点まとめを真面目につくるのはそんなにやってない(大体はTwitterに書く)
精読: 4時間~数日。大体はパワポのスライドでまとめてる(一部はslideshareへ)
一気に読まずに通学中に少しずつ読み進めていくことも多い
[ArXiv]
? タイトル&アブストだと週10本くらい≒(Twitterでの論文つぶやき、RT数)
? 図表?式まで読むのは5本程度
? イントロ関連研究までは1,2本程度→だいたい精読リストに積まれる
最近はとりあえずタイトル&アブストで引っかかったのをgithubにリストしておいて誰
かが日本語で解説してくれるのを少し待つ→出なかったら自分で精読するスタイル
[国際会議論文]
? accepted paper listが公開されたら、タイトルには一通り目を通してアブストだと
100本くらい→10~20本ほど精読へ(読めてるとは言ってない)
? タイトル全読みは最近少しさぼり気味(語彙に見当ついてるのでCtrl+Fで検索)
2018/6/11 65/65](https://image.slidesharecdn.com/180611m1studyreadingwritingpublic-180613223014/85/AHC-Lab-M1-65-320.jpg)






![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=560&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 ? 足りない情報をどのように補うか??](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)


















More Related Content
What's hot (20)
More from Shinagawa Seitaro (11)









AHC-Lab M1勉強会 論文の読み方?書き方
- 1. 2018.06.11 M1勉強会(改訂版) 「論文の読み方?書き方」改め ArXiv時代の論文の読み方 こう書くと落ちる論文の書き方 研究室でこの先生きのこるには AHC-Lab D3 品川 政太朗 2018?Seitaro Shinagawa AHC-lab NAIST2018/6/11 1/65
- 2. 2018?Seitaro Shinagawa AHC-lab NAIST はじめに 対象:グラム先生のチュートリアル資料「国際会議論文の 読み方?書き方」に一通り目を通した人 http://phontron.com/slides/neubig15nlptutorial.pdf 2018/6/11 2/65
- 3. 2018?Seitaro Shinagawa AHC-lab NAIST どんな研究生活を送りたいですか? ?授業料?奨学金免除?学振を取りたい! ?機械学習を扱う有名企業への就職がしたい! ?精神的に安定した研究生活が送りたい! ?研究も私生活も充実させたい! などなど 研究(生活)が順調にいけばすべてうまくいきます 皆さんいろいろな目標があると思います 2018/6/11 3/65
- 4. 2018?Seitaro Shinagawa AHC-lab NAIST 充実した研究生活に必要なスキル 1.論文を読むスキル ? 先行研究をサーベイするため ? 良い論文を書く技術を盗むため 2.論文を書くスキル ? 研究の価値(ストーリー)を伝えるため ? 自分の業績を積み重ねるため 3.研究発表をするスキル(今回はout of scope) ? 分かりやすく伝えることで有益なコメントをもらうため 4.研究室で生き抜くスキル 今日はこんなかんじでざっと話します 2018/6/11 4/65
- 5. 2018?Seitaro Shinagawa AHC-lab NAIST ArXiv時代の論文の読み方 2018/6/11 5/65
- 6. 2018?Seitaro Shinagawa AHC-lab NAIST 世はまさに大ArXiv時代 ArXiv:オープンアクセスのプレプリントサイト 分野:数学、物理学、統計、機械学習など ? 「論文のオープンアクセス化」と 「新規発見?知見の高速な共有」を理念としている ? 査読プロセスがないので怪しい論文も投稿される 研究の速度は世界的に高速化している! 時代の流れをうまく乗りこなしたい??? 論文 論文 論文 論文 2018/6/11 6/65
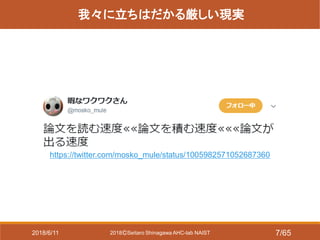
- 7. 2018?Seitaro Shinagawa AHC-lab NAIST 我々に立ちはだかる厳しい現実 https://twitter.com/mosko_mule/status/1005982571052687360 2018/6/11 7/65
- 8. 2018?Seitaro Shinagawa AHC-lab NAIST 伝えたいこと ? 精読と速読を使い分けよう ? ArXivとはほどほどにうまく付き合おう ? 論文を読んだら要点をまとめて共有しよう 2018/6/11 8/65
- 9. 2018?Seitaro Shinagawa AHC-lab NAIST なんのためにサーベイするのか? 1.自分の研究テーマを決めるため ? やりたいこと=今新規性があるとは限らない ? 現状を把握して、まだやられてないことを吟味 自分がこれから何をできるか考える 2.最新の研究動向を知るため ? 車輪の再発明はできるだけ避けたい ? 「後追いに過ぎない」ことは心得ておく 3.執筆時に先行研究と比較するため ? 自分の研究との差分を明確に書くのに必要 (書かないともれなく落ちる) サーベイ力さえあれば??? https://pbs.twimg.com/media/DbIB -I5UwAA3G1s.jpg 速読?精読 速読 精読 2018/6/11 9/65
- 10. 2018?Seitaro Shinagawa AHC-lab NAIST 論文読みには目的に応じて精読?速読を使い分けます 精読の目的 自分の研究テーマにより深く潜るためにやる ? 論文の詳しい理解、検討のため ? しばしば再現実装も含める ? 良い論文のやりかたを盗んで自分の研究?論文執筆に生かすため 速読の目的 分野の大まかなトピック、流れ(トレンド)の把握(重要) ? 研究テーマの策定(解決すべき問題の発見) 2018/6/11 10/65
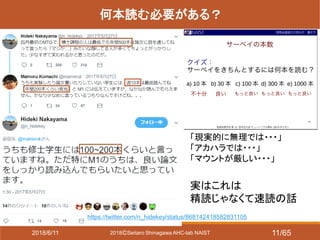
- 11. 2018?Seitaro Shinagawa AHC-lab NAIST 何本読む必要がある? 「現実的に無理では???」 「アカハラでは???」 「マウントが厳しい???」 実はこれは 精読じゃなくて速読の話 https://twitter.com/n_hidekey/status/868142418582831105 2018/6/11 11/65
- 12. 2018?Seitaro Shinagawa AHC-lab NAIST 違うレベルで読む習慣をつけよう 速読 精読 タイトル?アブストを読む (結論?実験結果?手法の)図、テーブルを見る イントロ?関連研究も読む 深く読み込む(どういう発想でこの研究が出た?) 論文紹介、再現実装、(全訳) 2018/6/11 12/65
- 13. 2018?Seitaro Shinagawa AHC-lab NAIST それでもキツイ→ArXiv時代は群れで戦う時代 cvpaperchallenge CVPR2018まとめ (https://github.com/cvpaperchallenge/CVPR2018_Survey) 論文をサーベイしたら「要点まとめ」を作って知見を共有しよう (個人のblogとか) 先進的な取り組み→ArXivtimes, cvpaperchallenge 2018/6/11 13/65
- 14. 2018?Seitaro Shinagawa AHC-lab NAIST 要点まとめは落合フォーマットがおススメ /Ochyai/1- ftma15?ref=http://lafrenze.hatenablog.com/ entry/2015/08/04/120205 論文を代表する図と6つのトピックから 成る ?どんなもの? ?先行研究と比べてどこがすごい? ?技術や手法のキモはどこ? ?どうやって有効だと検証した? ?議論はある? ?次に読むべき論文は? 機械学習(自然言語処理とか)の例はこちらが参考になります しゅんけー(@shunk031)さん paper survey http://shunk031.me/paper-survey/ ymym@やむやむ(@ymym3412)さん acl-papers https://github.com/ymym3412/acl-papers/ 2018/6/11 14/65
- 15. 2018?Seitaro Shinagawa AHC-lab NAIST 要点まとめはどこに出す? https://rnavi.org/ https://github.com/arXivTimes/arXivTimes / ? よく使われるスライド置き場(PDF) ? ログインするとダウンロード可能 ? 勉強会で発表したスライドを置く ? 論文紹介記事を投稿できる ? 著者が自身の研究を紹介するの にも使われている ? 最も有名どころ ? githubのissueで論文を管理 ? レビューのレビューをしてもらえる もちろん個人のブログやgithubとかでやってもOK! 2018/6/11 15/65
- 16. 2018?Seitaro Shinagawa AHC-lab NAIST チームをつくってプロジェクトを走らせているところもある ? 画像系の会議論文サーベイ 例:CVPR2018読破チャレンジなど http://hirokatsukataoka.net/project/cc/index_cv paperchallenge.html ? 国際会議CHIの論文サーベイ 「全666本を7時間で一気に読破」 などコンセプトを工夫している http://hirokatsukataoka.net/project/cc/index_cv paperchallenge.html 2018/6/11 16/65
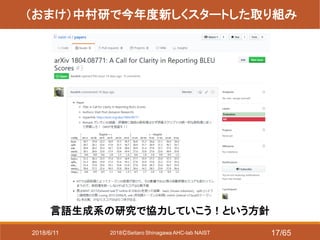
- 17. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)中村研で今年度新しくスタートした取り組み 言語生成系の研究で協力していこう!という方針 2018/6/11 17/65
- 18. 2018?Seitaro Shinagawa AHC-lab NAIST どうやってサーベイする? 結論:目的、場合によってことなる トップダウン方式で探す >自分がある程度知ってる分野(検索する語彙を知っている) ? google scholarで検索→関連研究から芋づる式にさかのぼる >自分が全く知らない分野(どう検索していいか分からない) ? 詳しい人に聞く(研究室内にいなければツテを頼ってでも探す) ? Twitterでつぶやいてみる(親切な人が教えてくれるかも) どちらにしても、キーになる 論文にさえ出会えれば 芋づる式にさかのぼれる ボトムアップ方式で探す(カクジツ!) ? トップの国際会議の近年の論文のタイトルに全部目を通してみる タイトルで絞り込み→アブストで絞り込み→論文リストを作成 ? ArXivを追ってみる(Twitter, Arxiv sanity, Arxiv vanity) (Arxiv sanityではTwitterのイイねが集計されている) 2018/6/11 18/65
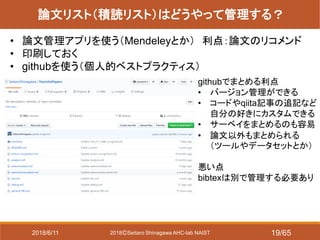
- 19. 2018?Seitaro Shinagawa AHC-lab NAIST 論文リスト(積読リスト)はどうやって管理する? ? 論文管理アプリを使う(Mendeleyとか) 利点:論文のリコメンド ? 印刷しておく ? githubを使う(個人的ベストプラクティス) githubでまとめる利点 ? バージョン管理ができる ? コードやqiita記事の追記など 自分の好きにカスタムできる ? サーベイをまとめるのも容易 ? 論文以外もまとめられる (ツールやデータセットとか) 悪い点 bibtexは別で管理する必要あり 2018/6/11 19/65
- 20. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)hikiにも載せてる「研究の進め方」は このリポジトリの一部をまとめたもの 2018/6/11 20/65
- 21. 2018?Seitaro Shinagawa AHC-lab NAIST 論文を速く読めません! 分野の知識?経験値が足りないだけです(あと速読自体の慣れ) そんなばなな??? あ~これKmeans みたいな手法か あの問題は扱 いにくいはずだ けどどうやった んだろ? データはどう とったの? 速読?精読を繰り返していけば自然と速くなります(時間を測ろう!) 速読:10分~数時間 精読:数時間~数日 十分な背景知識 のある人 初学者 ちなみに:慣れてても速く読めない論文は地雷 の可能性が高い(ただし理論系を除く) 2018/6/11 21/65
- 22. 2018?Seitaro Shinagawa AHC-lab NAIST 結局ArXivは追わなきゃだめなんですか? 結論:追えるならいいですが無理して追わなくてもいいです 無理して追わない方法: ? 他の詳しい人に教えてもらう ? ArXiv Sanityを使う ? Twitterを使う: 論文を紹介してくれるアカウントをフォローする ArXiv垂れ流しアカウント 2018/6/11 22/65
- 23. 2018?Seitaro Shinagawa AHC-lab NAIST いますぐフォローすべき論文紹介アカウント(敬称略) arXivTimes @arxivtimes 多様な論文のまとめ Daisuke Okanohara @hillbig 機械学習手法の理論? 解析系の話が多め Kyosuke Nishida @kyoun 言語系が多め 画像や音声も ymym@やむやむ @ymym3412 言語 ACLの論文サーベイ 暇なワクワクさん @mosko_mule 機械学習手法の理論?解析 画像や言語も しゅんけー @shunk031 言語多め 画像も Ryobot @_Ryobot ニューラル系の翻訳?対話 モデル,画像生成モデル cvpaper.challenge @CVpaperChalleng 画像系の論文まとめ 2018/6/11 23/65
- 24. 2018?Seitaro Shinagawa AHC-lab NAIST いますぐフォローすべき論文紹介アカウント(敬称略) hardmaru @hardmaru 多様な論文 画像が多い? DLHacks @DL_Hacks 東大松尾研の論文読 み会スライド紹介 piqcy @icoxfog417 多様な論文、ツール (ArXivtimesの中の人) dhgrs @__dhgrs__ 音声の深層学習 WaveNet、 VQ-VAE imenurok @dosei_sanga 画像に関係する DNNの各手法の理論 Shinya Yuki @shinyaelix GANなど重要手法の 手法の解説記事 @mushokudon 手法の解説記事 http://musyoku.github.io/ 2018/6/11 24/65 Hironsan @Hironsan13 自然言語処理 手法の解説記事
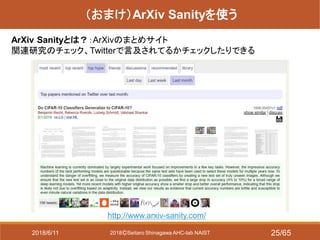
- 25. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXiv Sanityを使う ArXiv Sanityとは?:ArXivのまとめサイト 関連研究のチェック、Twitterで言及されてるかチェックしたりできる http://www.arxiv-sanity.com/ 2018/6/11 25/65
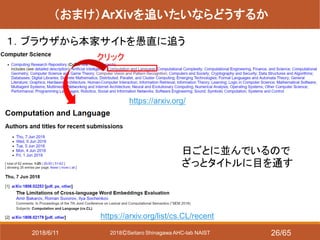
- 26. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXivを追いたいならどうするか 1.ブラウザから本家サイトを愚直に追う https://arxiv.org/ 日ごとに並んでいるので ざっとタイトルに目を通す クリック https://arxiv.org/list/cs.CL/recent 2018/6/11 26/65
- 27. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXivを追いたいならどうするか 2.本家サイトのRSSを購読する http://ensekitt.hatenablog.co m/entry/2017/12/15/200000 こういうRSSリーダとかがある 使うとこんな感じ (ちなみに私はスマ ホのRSSリーダを昔 使ってたが、未読が 999になったところで 心が挫けた) 2018/6/11 27/65
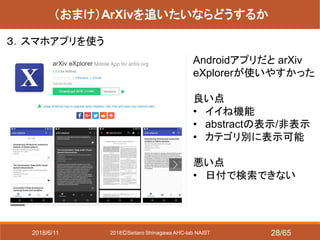
- 28. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXivを追いたいならどうするか 3.スマホアプリを使う Androidアプリだと arXiv eXplorerが使いやすかった 良い点 ? イイね機能 ? abstractの表示/非表示 ? カテゴリ別に表示可能 悪い点 ? 日付で検索できない 2018/6/11 28/65
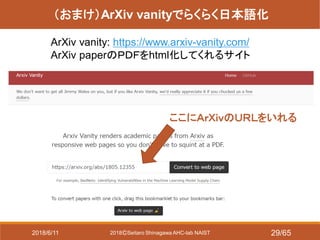
- 29. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXiv vanityでらくらく日本語化 ArXiv vanity: https://www.arxiv-vanity.com/ ArXiv paperのPDFをhtml化してくれるサイト ここにArXivのURLをいれる 2018/6/11 29/65
- 30. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)ArXiv vanityでらくらく日本語化 htmlで出力されたらあとはgoogle翻訳にかけよう まあ急いでて英語読んでられない時とかに重宝する? (もちろん翻訳結果への過信はダメです) 2018/6/11 30/65
- 31. 2018?Seitaro Shinagawa AHC-lab NAIST (おまけ)その他効率を上げるTips 論文が見当たらないとき→著者名でググる 著者の論文、コード、project pageのリンクがある可能性 Review,巷の口コミを参考にする ? NIPS, ICLRは査読者のレビューが見れる ? ArXivtimes, cvpaperchallenge, 各種勉強会などの 論文の日本語解説資料 ? Reddit(海外の雑談掲示板) ? Twitter 日本語資料を参考にする とっつきにくい論文は近い内容で日本語の資料がないか探してみる ? 言語処理学会?人工知能学会の全国大会?論文誌 ? ArXivtimesなどの論文要点まとめ,個人による解説記事 2018/6/11 31/65
- 32. 2018?Seitaro Shinagawa AHC-lab NAIST 「ArXiv時代の論文の読み方」 まとめ https://github.com/SeitaroShinagawa/FavoritePapers/blob/master/summary/how_to_ma ke_progress.md#%E8%AB%96%E6%96%87%E3%81%AE%E8%AA%AD%E3%81%B F%E6%96%B9 他、一読すると良い資料 ?ArXiv時代において速読をこなすのがますます困難に ?論文まとめやTwitterを使って広いアンテナを持っておこう 2018/6/11 32/65
- 33. 2018?Seitaro Shinagawa AHC-lab NAIST サーベイしたら研究の計画を立てる 最初に指導教員と綿密な議論をしておく ? この研究のウリはどこか ? 手法は何を使うか(比較手法はどうするか) ? データは何を使うか(新規に集めるならその方法についても) ? 評価はどうするか ? どこの国際会議?論文誌に出すか [事前執筆型のススメ] 事前執筆して実際に文章におこしてみると、気づいていなかった穴 にも事前に察知できる 参考文献:スタンフォードで学んだ研究の生産性を上げる4つの方法 https://note.mu/ryosuzuki/n/ndae1d84d6103 2018/6/11 33/65
- 34. 2018?Seitaro Shinagawa AHC-lab NAIST 論文をどこに出す? [修士の狙い目] 最低でもここで成仏だ! 採択率が高い会議(50%以上) ? EMBC (CC) ? IWSDS (NL, SD) ? COCOSDA (NL, SD) ? トップ会議のworkshop (NIPSなど) [目標] 各分野のトップ会議(採択率30%) ? NIPS, ICML, ICLR, IJCNN ? IJCAI, AAAI (人工知能系なんでも) ? ICASSP, INTERSPEECH (SP, CC, SD, 採択率50%) ? ASRU (SP, SD) ? ACL, EMNLP, NAACL ([2nd tier] COLING, IJCNLP, EACL) (NL, SD) ? CVPR, ECCV, ICCV, ([2nd tier] BMVC) (画像系) ? KDD, PAKDD (データ系) 2018/6/11 34/65
- 35. 2018?Seitaro Shinagawa AHC-lab NAIST 国内の学会や研究会に出す意味はある? 直接的な業績としての意味はほぼない 補足:一応中村研では国内外問わず最低1回の研究発表が修士の修論提出の 最低要件になってる 間接的には重要(だと思う) ? 外部の研究者と議論することで研究の質を向上させられる →国際会議論文へのたたき台になる ? 外部の研究者コミュニティと関わりを持つ →情報交換や共同研究の種になる ? 自分の名前を売り込む →名前が売れてると路頭に迷っても貰い手がある 2018/6/11 35/65
- 36. 2018?Seitaro Shinagawa AHC-lab NAIST 従来型?事前執筆型? 従来型 事前執筆型 アイデア→サーベイ→実験→執筆 アイデア→サーベイ→執筆→実験 あ、これ実験足りなくね? 想定外の追加実験発生 実験に戻る 利点 ? 事前に論文におこすことで論点の穴を議論できる ? 必要なタスクを予め見積もれる 難点 結果出てないのに書き始めるのは結構つらい 2018/6/11 36/65
- 37. 2018?Seitaro Shinagawa AHC-lab NAIST 実際おススメなのは予備実験型 待ちきれない型も最初の実験が予備実験ならよい むしろ予備実験してアタリをつけられるとより安全 アイデア→予備実験 →(実験回しつつ)サーベイ →(実験回しつつ)事前執筆(比較対象の検討など) →本実験&執筆 [データ収集が間に入る場合] アイデア→(人工データで)予備実験 →(データ収集しつつ)サーベイ →(データ収集しつつ)事前執筆 (比較対象の検討 など) →本実験&執筆 この部分を予備実験 として捉える 2018/6/11 37/65
- 38. 2018?Seitaro Shinagawa AHC-lab NAIST 論文の構成はどうする? 結構悩ましい問題 関連研究を前に置くメリット ? イントロからつなげやすい 関連研究を後ろに置くメリット ? 問題の定式化から説明できる ? 先行研究は長いし複雑 (個人的には、タスク自体が特殊で込 み入った定式化が必要な場合は後ろ に回ってることが多いような???) (ちなみにこの場合でも関連研究の内 容は「はじめに」で軽く触れている. ベースラインを紹介する場所は必要) 2018/6/11 38/65
- 39. 2018?Seitaro Shinagawa AHC-lab NAIST こう書くと落ちる論文の書き方 2018/6/11 39/65
- 40. 2018?Seitaro Shinagawa AHC-lab NAIST 基本的にどうすると落ちるか 当たり前のことですがツッコミどころが多いと落ちます! 例:データセットが小さい、人工データ(簡単なデータ)でしか実験してない、比較 対象が間違っている、比較実験が十分でない、ストーリーが理解できない、etc. その他、図が汚い、参考文献の書式が揃ってない、タイポが沢山あるがあれば それだけで査読者の心象が悪くなる 論文のウリに対して、ツッコミどころがあるごとに評価が削られていくとみて良い [ウリ] ? 驚愕の新規の発見をした ? 今までできなかったようなことができるようになった ? 徹底的に網羅的な調査をした など 2018/6/11 40/65
- 41. 2018?Seitaro Shinagawa AHC-lab NAIST (落ちない)良い論文を書くには [内容レベル](再掲) 良い研究をする ? この研究のウリはどこか ? 手法は何を使うか ? データは何を使うか(新規に集めるならその方法についても) ? 評価はどうするか 事前執筆して文章におこしてみると、気づいていなかった穴にも事 前に察知できる [表象レベル] 図が汚い、参考文献の書式が揃ってない、タイポなど 対処:ひたすら添削→reviseを繰り返すしかない 参考文献:スタンフォードで学んだ研究の生産性を上げる4つの方法 https://note.mu/ryosuzuki/n/ndae1d84d6103 2018/6/11 41/65
- 42. 2018?Seitaro Shinagawa AHC-lab NAIST 良い研究とは(from 金出先生) 「良い研究は現実に起きている問題に取り組む中で生まれる」 問題を見つけるところから始めよう(そのためのサーベイでもある) だからといって優等生な問題設定ばかりが研究とは限らない! でも価値があると思うなら 覚悟を決めて取り組もう (研究の醍醐味でもある) エンタメ系とか結構きつい (なぜなら無くてもなんとかなるから) 2018/6/11 42/65
- 43. 2018?Seitaro Shinagawa AHC-lab NAIST 査読者は誤解する 人工知能ブームの昨今、提出される論文は爆発的に増 えたが査読者の数は大して増えてない 査読者の心境: ? 負担がヤバい ? (論文に)穴があったらリジェクトしたい??? ? できるだけ速く雑に読んでもはっきり採択できる論 文が読みたい 雑に読まれて勝手に脳内補完されても問題のない論文 (誤解のおきにくい論文)を書く必要がある 2018/6/11 43/65
- 44. 2018?Seitaro Shinagawa AHC-lab NAIST 概要(Abstract)の注意点 「最後」に書く!(“概要”なので) CMU教授直伝の論文の書き方 http://yamaguchiyuto.hatenablog.com/entry/2016/01/18/154613 “Don‘t go into detail in abstract”(特に手法?実験についての説明) “アブストには詳細を書かない。…読者がアブストに期待しているのは「その 論文によって何ができるようになったのか(What)」を知ることであって、「ど のようにしたのか(How)」ではない。” 我々は~~という問題に取り組んだ 我々は~~という手法でこの問題を解決する (想定している)利点は(収束が速い?小さいデー タサイズでも動く、ノイズ耐性があるetc.)である ~~という(タスク?データセット)実験によって提 案法が有効であることを示す 2018/6/11 44/65
- 45. 2018?Seitaro Shinagawa AHC-lab NAIST 序論(Introduction)の注意点 主張とやってることのズレ(overstatement/understatement) に気を付ける Crown jewel(最初に見せる実験結果のアピール図)の誤解 ? 問題の説明のために用意した図をcrown jewelと勘違いされた →問題の説明の図もなるべく実際のデータで説明する 調子に乗った言い過ぎによる誤解 ? “様々なドメインに手法で応用可能な汎用的な手法を提案する” →実験が画像だけだと× 色々なドメインでの実験が必要 言わなさすぎもダメ ? 査読者「このデータでしか有効じゃないんじゃないの?」 →主張を通すのに適切(必要十分)な実験設計が必要 2018/6/11 45/65
- 46. 2018?Seitaro Shinagawa AHC-lab NAIST 優れた研究論文の書き方―7つの提案 /kdmsnr/writing-a-paper-seven-suggestions overstatementをうまくかわす例 適切な大きさの問題に着地させるようストーリーを展開しよう コンピュータプログラムのバグ ある特殊な場合 に起きるバグ 研究の焦点 主語がでかい 公知の事実 2018/6/11 46/65
- 47. 2018?Seitaro Shinagawa AHC-lab NAIST 単数/複数に気を付ける 基本的に英文校正に出すことを想定 ? a/theは校正者にも見分けやすい ? 単数/複数は見分けられない(らしい) 他にも受動態を能動態に変えたりなど色々テクニックがありますが、 こちらに譲ります(読む?受講してください) 英文校正会社が教える 英語論文のミス100 なぜあなたは論文が書けないのか? Graham先生 論文執筆スタイルガイド: http://www.phontron.com/paper-guide.php writing in science(coursera): https://www.coursera.org/learn/sciwrite 2018/6/11 47/65
- 48. 2018?Seitaro Shinagawa AHC-lab NAIST 「こう書くと落ちる論文の書き方」 まとめ ツッコミどころを事前につぶす ? (内容)事前に良い研究の設計を指導教員と十分相談しておこう。 予備実験+事前執筆型がおススメ ? (形式)レビュー&リビジョンを繰り返す とにかく査読者は誤解するので紛らわしい要素を排除しよう 英文校正を前提にして論文を書く(a/theで消耗しない) 2018/6/11 48/65
- 49. 2018?Seitaro Shinagawa AHC-lab NAIST 研究室でこの先生きのこるには 2018/6/11 49/65
- 50. 2018?Seitaro Shinagawa AHC-lab NAIST 中村研 良い点悪い点 良い点 悪い点 いわゆるビッグラボ ? ボスが強い ? プロジェクトに乗れば研究費にあまり困らない(コーパス収集という手段も 比較的積極的に推奨されている) ? 色々な人にすぐ相談できる ? 多様な研究スタイルが可能 ? ボスが忙しい(研究議論できる時間は限られる) ? 他の先生方も忙しい(同上) ? 研究テーマに統一性が無い(修士でも研究を1から組み立てる必要が出てく ることがある(これは本来博士に求められるレベル))醍醐味でもあるが??? ? NAISTという陸の孤島に適応できず辛い思いをする人もいる ? 前半は授業に忙殺される上に就活もあるので実質とれる研究時間は短い 2018/6/11 50/65
- 51. 2018?Seitaro Shinagawa AHC-lab NAIST 悪い点を克服するには ボスに相談したい 議論できるのは基本的に面談の時と先生ありミーティングの時(足りない!) →必要に応じてメールでアポを取って突撃、自ら議論できる時間をつくる [必要な場合とは?] 研究のおおまかな方針を決めたい場合 「こういうデータ、手法、評価方法でこういうことを明らかにするのはどうですか?」 ボスの研究の勘所はほぼ正しいので難色を示された場合は再考した方がいい 他の先生に相談したい やはりアポをとるのが安全。研究の方針、困っていることなど自分からどんどん 聞きに行こう。「先生は死なぬよう」積極的に使おう(僕らは授業料を払っている!) 先に先輩に相談した方がいいこと 計算機の使い方、ライブラリがインストールできない、など。学生で解決できること が増えるほど先生が指導に集中できるのでどんどん増やしていきたいところ 2018/6/11 51/65
- 52. 2018?Seitaro Shinagawa AHC-lab NAIST 悪い点を克服するには 研究テーマに統一性が無い(修士でも研究を1から組み立てる必要が出てく ることがある(これは本来博士に求められるレベル))醍醐味でもあるが??? テーマが幅広いSD班が特によくこの状況に陥る インターンに行く ? NTT CS研、NEC、PFN、Yahoo!、TISなどの研究インターンに応募する ? インターンでの研究がうまく進めばそのまま自分の研究にするのも手 ? テーマによっては指導教員より詳しい場合がある ? とりあえず指導教員に相談してみるとよい(指導教員から勧められる場合も) 詳しい人に弟子入りする ? 他の研究室だろうと関係ない、詳しそうな人にアポをとってみる ? 指導教員を通してできると嬉しい(共同研究に発展しやすい) 2018/6/11 52/65
- 53. 2018?Seitaro Shinagawa AHC-lab NAIST 辛い時に誰に相談するか NAISTという陸の孤島に適応できず辛い思いをする人もいる 人には色々な事情がある。辛い時にどうするか? ? 先生に相談する ? 同僚(先輩?同期?後輩)に相談する ? 友人に相談する ? 家族に相談する ? カウンセラーに相談する(NAIST保健管理センター) 先生、同僚はあなたが研究室に来れば助けられるが、来れなけ れば助けようがない。研究室に来よう。それもできそうにないなら カウンセラーへ相談だ。一人で考え込むのが一番危ない 2018/6/11 53/65
- 54. 2018?Seitaro Shinagawa AHC-lab NAIST 研究できる時間は意外と少ない 前半は授業に忙殺される上に就活もあるので実質とれる研究時間は短い M1 M2 4月 5月 6月 7月 8月 9月 10月 11月 12月 1月 2月 3月 4月 就活 研究 夏 合 宿 授業 授業 研究 研究 就活 研究 修論 卒 業 研究 M1 ? 夏合宿までに研究テーマの骨子を固める(データ、方法、評価尺度) ? 12月~3月の投稿シーズンには最初の国際会議論文の投稿 M2 ? うまく論文が通ったら国際会議論文のジャーナル化(9月くらいから?) ? 11月に修論に着手開始、12月中に初稿完成、1月~学生間添削 ? 1月2月はGO/NO GOゼミ(研究室内修論発表前審査)、修論発表 研究 2018/6/11 54/65
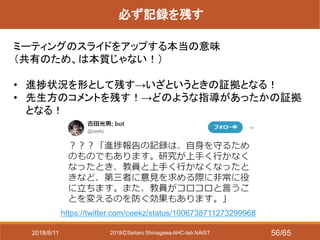
- 55. 2018?Seitaro Shinagawa AHC-lab NAIST 必ず記録を残す ミーティング、先生への相談の時 なるべく記録媒体を用意する(ICレコーダ、メモ) ? 後から振り返って反省?整理に使うため ? 自分の身を守るため(何かのきっかけで揉める可能性もある) Amazonで3,000円くらいで買える 例:(品川所持品) Tenswall ボイスレコーダー 8GB ICレコーダー https://www.amazon.co.jp/gp/product/B076RY6SCT/ref=oh_aui_detailpa ge_o02_s00?ie=UTF8&psc=1 2018/6/11 55/65
- 56. 2018?Seitaro Shinagawa AHC-lab NAIST 必ず記録を残す ミーティングのスライドをアップする本当の意味 (共有のため、は本質じゃない!) ? 進捗状況を形として残す→いざというときの証拠となる! ? 先生方のコメントを残す!→どのような指導があったかの証拠 となる! https://twitter.com/ceekz/status/1006738711273299968 2018/6/11 56/65
- 57. 2018?Seitaro Shinagawa AHC-lab NAIST 研究室外に仲間をつくろう! 多様な情報ルートが君を過酷な研究生活から救ってくれる! (かもしれない) 研究コミュニティによる企画 ? YANS – NLP若手の会 ? MIRU若手プログラム など 学外勉強会への参加(論文読み会、ハッカソンなど) ?関西MT勉強会 ?NIPS+読み会?関西もよろしく! 2018/6/11 57/65
- 58. 2018?Seitaro Shinagawa AHC-lab NAIST All you need is Twitter Twitter:研究を進める上で情報収集、意見交換に使える 最強のツール ?大学の教員をフォローしておくと、学振やら色々な情報が得られる ?学外の学生とも交流できる ただし、ずっと見てると研究時間が無限に溶けるので 時間的な制約を設けるなど工夫した方が良い 2018/6/11 58/65
- 59. 2018?Seitaro Shinagawa AHC-lab NAIST 学振を書こう! 学振とは? ? 研究室合宿から自分の研究を再考する良い機会 ? 修論で研究のイントロを書くたたき台ができる! ? 気が変わってD進するときにも研究費+給料!充実したD生活! ? (D進すると奨学金免除ポイントがつくので一度D進してフェードアウトまである) ? 通ったら他の同期マウントできる(*「俺、就職希望やけど学振通ったで~?」) 学振をいつ書く? 某研究室ではM1半ば(サーベイが一段落した時点)で書く →研究を順調に進めるためのマイルストーンになる 学振を書く利点 ? 給料月20万と年100万の研究費、副業OK(研究に関連してれば) ? 修士2年向けのDC1は計画重視(業績が無くてもチャンス!) 2018/6/11 59/65
- 60. 2018?Seitaro Shinagawa AHC-lab NAIST 学振を書こう! 学振書いてくれた場合 余裕のあるうちに添削できる →現状の状態で研究上の問題を再度文章の形で議論可能! ぼやけた研究計画を明確化、軌道修正が可能 →順調な研究生活の実現!研究者としての成長! 学振書いてない場合 進捗最悪の場合で文章化されるのが修論スタート →これ、結構やばいんじゃね?と気づく(本人、先輩、先生) →デスマーチに突入(全員死ぬ) 学振writingは将来への保険 事前にある程度のコストを払っておくことで、全員が将来的に 発生しうる恐ろしいコストをかなり低減できる まれによくある? 2018/6/11 60/65
- 61. 2018?Seitaro Shinagawa AHC-lab NAIST ゼミ?輪講との向き合い方 参加は必須なので避けられない(中村研のコアタイム)→どう付き合うか ゼミ ? 全部理解しようとするのを諦める(人間の集中力はせいぜい45分しかもたない) ? 寝落ちするよりは話半分にでも聞いていた方がまし ? ゼミ一回当たり1つ質問することを目標にする ? 発表の不明点をスライドから探してアタリをつけておく ? メモ帳やslackなどにサマリを書いておくと質問しやすい ? 特にM1の間はチュートリアル期間なので頓珍漢な質問でも良い ? 先生方の質問?コメントをちゃんと聞いておく(どこに注目しているのか?) →近い視点を持てるようになるほど、論文を批判的に読めるようになる 輪講 1. 教科書の該当部分には事前に一通り目を通しておく 2. 分からない部分をリスト化 3. 当日発表者にぶつける 4. 発表担当の場合、計算の導出や演習もやっておくと良い(ツッコまれると死ぬ) 2018/6/11 61/65
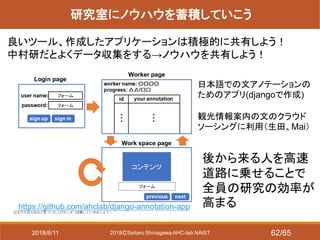
- 62. 2018?Seitaro Shinagawa AHC-lab NAIST 研究室にノウハウを蓄積していこう 良いツール、作成したアプリケーションは積極的に共有しよう! 中村研だとよくデータ収集をする→ノウハウを共有しよう! https://github.com/ahclab/django-annotation-app 日本語での文アノテーションの ためのアプリ(djangoで作成) 観光情報案内の文のクラウド ソーシングに利用(生田、Mai) 後から来る人を高速 道路に乗せることで 全員の研究の効率が 高まる 2018/6/11 62/65
- 63. 2018?Seitaro Shinagawa AHC-lab NAIST 研究をうまく進めるためにータイムマネジメントTips 余談: NAISTではキャリア支援室のセミナーが定期的に開かれるのでおススメ 「研究者のためのタイムマネジメント講座」(上記のTipsはここから) 「研究者のためのコミュニケーションスキル向上セミナー」 「アカデミックライティング講座」 研究に限らず超重要 コツ:スケジュールに「この時間に何をする」を細かく設定する 13:00~14:00 13:00 〇〇先生にメール 論文添削依頼?英文校正提出の確認 14:00~15:00 ××の作業を●●まで終わらせる 15:00~17:00 15:10~17:00 ゼミ ゼミ後に△△の件について□□さんに確認 google calendarなどのスケジュール表を利用 タスクの細分化?具体化によって作業時間を正確に見積もれる 2018/6/11 63/65
- 64. 2018?Seitaro Shinagawa AHC-lab NAIST まとめ 論文読み(サーベイ)について ?精読と速読を使い分けよう ?広いアンテナ(外部との関係)を持っておこう ?読んだ論文はまとめて共有しよう 論文書きについて ?予備実験で手を動かすことから始めよう ?どんどん文章を書く練習をしよう(事前執筆、学振) ?雑に読まれても理解できるような論文を目指そう 研究室生活について ?学生の多い研究室であるメリットとデメリットを念頭に動こう ?広いアンテナ(外部との関係)を持っておこう(強調) ?気軽に相談する癖をつけておこう 2018/6/11 64/65
- 65. 2018?Seitaro Shinagawa AHC-lab NAIST Q&Aまとめ Q.発表者は実際どのくらい読んでいるか(一本あたり、数) A. 速読: 大体10分~20分。一通り要点まとめができるまで読む 要点まとめを真面目につくるのはそんなにやってない(大体はTwitterに書く) 精読: 4時間~数日。大体はパワポのスライドでまとめてる(一部はslideshareへ) 一気に読まずに通学中に少しずつ読み進めていくことも多い [ArXiv] ? タイトル&アブストだと週10本くらい≒(Twitterでの論文つぶやき、RT数) ? 図表?式まで読むのは5本程度 ? イントロ関連研究までは1,2本程度→だいたい精読リストに積まれる 最近はとりあえずタイトル&アブストで引っかかったのをgithubにリストしておいて誰 かが日本語で解説してくれるのを少し待つ→出なかったら自分で精読するスタイル [国際会議論文] ? accepted paper listが公開されたら、タイトルには一通り目を通してアブストだと 100本くらい→10~20本ほど精読へ(読めてるとは言ってない) ? タイトル全読みは最近少しさぼり気味(語彙に見当ついてるのでCtrl+Fで検索) 2018/6/11 65/65