










![DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork
Learning Social Responsibility Respect for IndividualDeliver The Promise
GMRInstituteofTechnology,Rajam REFERENCES
•[1] Shankar Ganesh Manikandan, Siddarth Ravi , “Big Data Analysis using Apache
Hadoop”, IEEE,2014
•[2] Ankita Saldhi, Abhinav Goel”,” Big Data Analysis Using Hadoop Cluster”,
IEEE,2014
•[3] Amrit Pal, Pinki Agrawal, Kunal Jain, Kunal Jain, ”A Performance Analysis of
MapReduce Task with Large Number of Files Dataset in Big Data Using Hadoop”,
2014 Fourth International Conference on Communication Systems and Network
Technologies
•[4] Aditya B. Patel, Manashvi Birla, Ushma Nair,” “Big Data Problem Using Hadoop
and Map Reduce”, NIRMA UNIVERSITY INTERNATIONAL CONFERENCE ON
ENGINEERING, NUiCONE -2012
14November 13, 2016](https://image.slidesharecdn.com/mkappt-copy-161113145327/85/Big-data-hadoop-MapReduce-14-320.jpg)































More Related Content
Similar to Big data- hadoop -MapReduce (20)
Recently uploaded (20)


















Big data- hadoop -MapReduce
- 1. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam Term Paper Final-Review GMR Institute of Technology An Autonomous Institute Affiliated to JNTUK, Kakinada 1 Department of Computer Science Engineering
- 2. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam Performance analysis of MapReduce task in Big data using Hadoop 2November 13, 2016 TITLE by M. S. V. S. K .Avadhani (14341A05A4) Under the Guidance and supervision Of Mrs. K . Jayasri Assistant Professor Department Of Computer Science Engineering
- 3. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam ABSTRACT  Big Data is a huge amount of data that cannot be managed by the traditional data management system.  There can be three forms of data, structured form, unstructured form and semi structured form. Most of the part of big data is in unstructured form.  Unstructured data is difficult to handle.  Hadoop is a technological answer to Big Data.  The Apache Hadoop project provides better tools and techniques to handle this huge amount of data.  A Hadoop Distributed File System (HDFS) for storage and the MapReduce techniques for processing the data.  This paper discusses the work done on Hadoop by applying a number of files as input to the system and then analysing the performance of the Hadoop .
- 4. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam ABSTRACT(contd..) Besides it discusses the behaviour of the map method and the reduce method with increasing number of files and the amount of bytes written and read by these tasks. oKeywords: Big data Hadoop  HDFS  MapReduce. 4November 13, 2016
- 5. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam 5November 13, 2016
- 6. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam Hadoop • Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of commodity hardware. • Storing HDFS(Hadoop Distributed File System) • Processing MapReduce 6November 13, 2016
- 7. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam • HDFS: Specially designed file system for storing huge data sets in cluster of commodity hardware with streaming access pattern. 5 services :  Name node  Secondary node Job tracker Data node Task tracker 7November 13, 2016
- 8. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam 8November 13, 2016
- 9. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam • MapReduce: MapReduce is a processing technique and a program model for distributed computing based on java.  The MapReduce algorithm contains two important tasks, namely Map and Reduce.  Map stage : The map or mapper’s job is to process the input data.  Reduce stage : This stage is the combination of the Shuffle stage and the Reduce stage. 9November 13, 2016
- 10. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam 10November 13, 2016
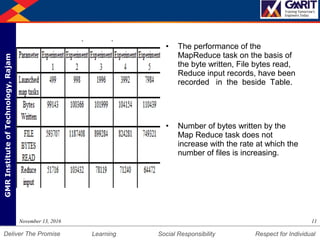
- 11. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam • The performance of the MapReduce task on the basis of the byte written, File bytes read, Reduce input records, have been recorded in the beside Table. • Number of bytes written by the Map Reduce task does not increase with the rate at which the number of files is increasing. 11November 13, 2016
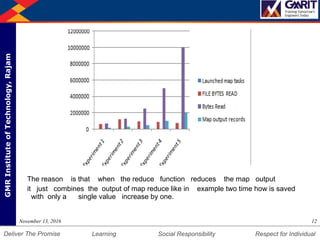
- 12. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam The reason is that when the reduce function reduces the map output it just combines the output of map reduce like in example two time how is saved with only a single value increase by one. 12November 13, 2016
- 13. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam Conclusion: We have analyzed the performance of the map reduce task with the increase number of files. We have used the word count application of the Map reduce for this analysis. The output shows that the Bytes written do not increase in the same proportion as compared to the amount of files increase. 13November 13, 2016
- 14. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam REFERENCES •[1] Shankar Ganesh Manikandan, Siddarth Ravi , “Big Data Analysis using Apache Hadoop”, IEEE,2014 •[2] Ankita Saldhi, Abhinav Goel”,” Big Data Analysis Using Hadoop Cluster”, IEEE,2014 •[3] Amrit Pal, Pinki Agrawal, Kunal Jain, Kunal Jain, ”A Performance Analysis of MapReduce Task with Large Number of Files Dataset in Big Data Using Hadoop”, 2014 Fourth International Conference on Communication Systems and Network Technologies •[4] Aditya B. Patel, Manashvi Birla, Ushma Nair,” “Big Data Problem Using Hadoop and Map Reduce”, NIRMA UNIVERSITY INTERNATIONAL CONFERENCE ON ENGINEERING, NUiCONE -2012 14November 13, 2016
- 15. DepartmentofMechanicalEngineering Humility Entrepreneurship Teamwork Learning Social Responsibility Respect for IndividualDeliver The Promise GMRInstituteofTechnology,Rajam Thank you…. -Avadhani M.k 15November 13, 2016