





































More Related Content
Similar to Breadth First Search with example and solutions (20)
Recently uploaded (20)


















Breadth First Search with example and solutions
- 1. BFS
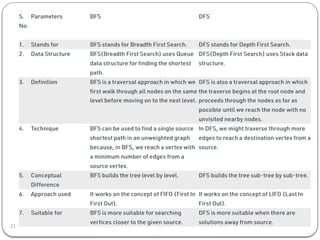
- 2. Breadth-first search ’éŚ Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures. ’éŚ It starts at the tree root (or some arbitrary node of a graph, sometimes referred to as a ŌĆśsearch keyŌĆÖ), and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level. ’éŚ It is implemented using a queue(FIFO). ’éŚ BFS traverses the tree ŌĆ£shallowest node firstŌĆØ, it would always pick the shallower branch until it reaches the solution (or it runs out of nodes, and goes to the next branch).
- 3. Algorithm 3 ’éŚ Declare a queue and insert the starting vertex. ’éŚ Initialize a visited array and mark the starting vertex as visited. ’éŚ Follow the below process till the queue becomes empty: ’éŚ Remove the first vertex of the queue. ’éŚ Mark that vertex as visited. ’éŚ Insert all the unvisited neighbors of the vertex into the queue.
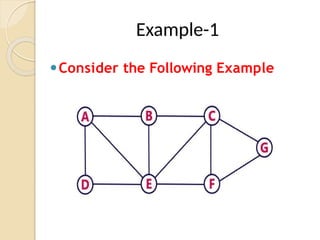
- 4. ŌܽConsider the Following Example Example-1
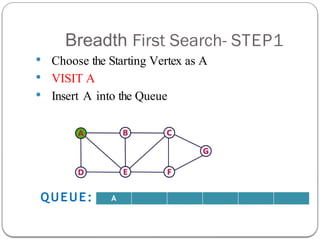
- 5. Breadth First Search- STEP1 ’éŚ Choose the Starting Vertex as A ’éŚ VISIT A ’éŚ Insert A into the Queue A QUEUE:
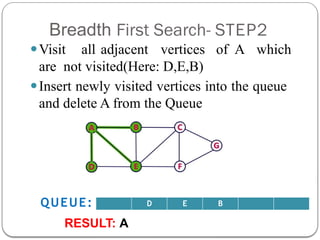
- 6. Breadth First Search- STEP2 ŌܽVisit all adjacent vertices of A which are not visited(Here: D,E,B) ŌܽInsert newly visited vertices into the queue and delete A from the Queue D E B QUEUE: RESULT: A
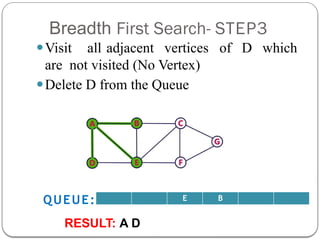
- 7. Breadth First Search- STEP3 ŌܽVisit all adjacent vertices of D which are not visited (No Vertex) ŌܽDelete D from the Queue E B QUEUE: RESULT: A D
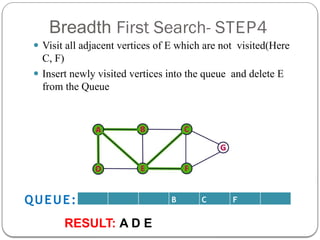
- 8. Breadth First Search- STEP4 Ōܽ Visit all adjacent vertices of E which are not visited(Here C, F) Ōܽ Insert newly visited vertices into the queue and delete E from the Queue B C F QUEUE: RESULT: A D E
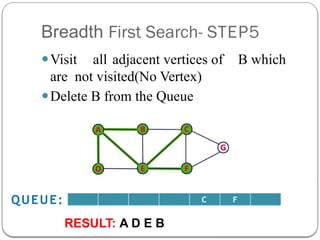
- 9. Breadth First Search- STEP5 ŌܽVisit all adjacent vertices of B which are not visited(No Vertex) ŌܽDelete B from the Queue C F QUEUE: RESULT: A D E B
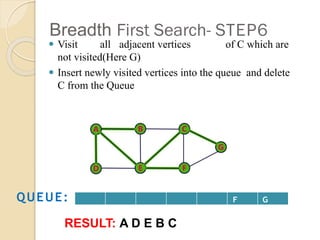
- 10. Breadth First Search- STEP6 Ōܽ Visit all adjacent vertices of C which are not visited(Here G) Ōܽ Insert newly visited vertices into the queue and delete C from the Queue F G QUEUE: RESULT: A D E B C
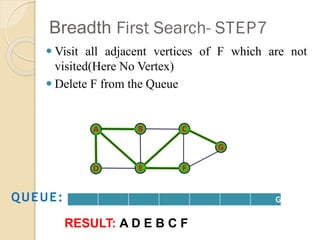
- 11. Breadth First Search- STEP7 Ōܽ Visit all adjacent vertices of F which are not visited(Here No Vertex) Ōܽ Delete F from the Queue G QUEUE: RESULT: A D E B C F
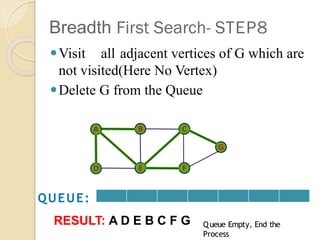
- 12. Breadth First Search- STEP8 ŌܽVisit all adjacent vertices of G which are not visited(Here No Vertex) ŌܽDelete G from the Queue QUEUE: Queue Empty, End the Process RESULT: A D E B C F G
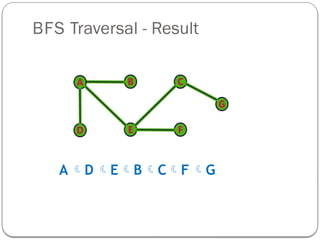
- 13. BFS Traversal - Result A’āĀD ’āĀE’āĀB’āĀC’āĀF ’āĀG
- 14. 14 Advantages ŌĆó BFS will provide a solution if any solution exists. ŌĆó If there are more than one solution for a given problem, then BFS will provide minimum solution which requires the least number of steps. Disadvantage ŌĆó It requires lot of memory since each level of the tree must be saved into memory to expand the next level. ŌĆó BFS needs lot of time if the solution is far a way from the root.
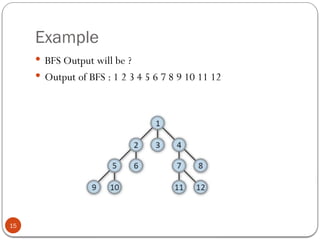
- 15. Example 15 ’éŚ BFS Output will be ? ’éŚ Output of BFS : 1 2 3 4 5 6 7 8 9 10 11 12
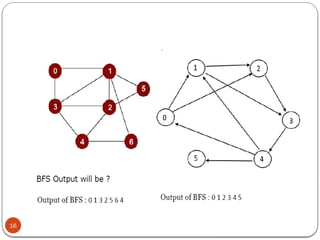
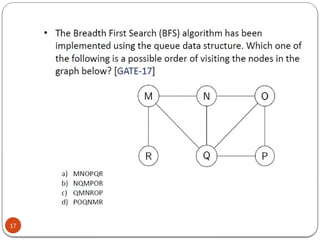
- 16. 16
- 17. 17
- 19. 19 Time complexity: Equivalent to the number of nodes traversed in BFS until the shallowest solution. T(n) = 1 + n^2 + n^3 + ... + n^s = O(n^s) ŌĆó s = the depth of the shallowest solution. ŌĆó n^i = number of nodes in level i. Space complexity: Equivalent to how large can the fringe get. S(n) = O(n^s)
- 20. 20 ŌĆó Completeness: BFS is complete, meaning for a given search tree, BFS will come up with a solution if it exists. ŌĆó Optimality: BFS is optimal as long as the costs of all edges are equal.
- 21. 21
- 22. 22
- 23. 23