





![[ýïáÛ▓¢ÙºØÛ©░ý┤ê] ýï¼ý©ÁýïáÛ▓¢ÙºØÛ░£ýÜö](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=560&fit=bounds)












![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=560&fit=bounds)








![[Paper Review] Image captioning with semantic attention](https://cdn.slidesharecdn.com/ss_thumbnails/imagecaptioningwithsemanticattention-180709045819-thumbnail.jpg?width=560&fit=bounds)
![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=560&fit=bounds)
![[paper review] ýåÉÛÀ£Ù╣ê - Eye in the sky & 3D human pose estimation in video with ...](https://cdn.slidesharecdn.com/ss_thumbnails/190321eyeposegyubin-190517100712-thumbnail.jpg?width=560&fit=bounds)
More Related Content
Similar to [Ùì░ýØ┤Ýä░ ÙÂäýäØ ýåîÙ¬¿ý×ä] Convolution Neural Network Û╣ÇÙáñÙª░ (20)
[Ùì░ýØ┤Ýä░ ÙÂäýäØ ýåîÙ¬¿ý×ä] Convolution Neural Network Û╣ÇÙáñÙª░
- 2. ýïáÛ▓¢ÙºØ CNNÛÁ¼ýí░ CNNCode 01 02 03 TABLE OF CONTENTS
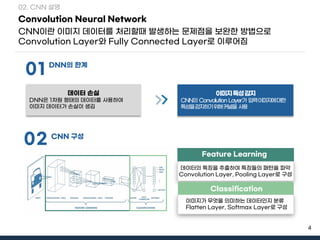
- 3. 3 Deep Neural Network DNNýØÇ Û©░ýí┤ýØÿ Neural NetworkýÖÇ ÙïñÙÑ┤Û▓î ýØÇÙïëý©ÁýØ┤ ýù¼Ùƒ¼ Û░£ ýí┤ý×¼Ýòÿýù¼ Ù╣äýäáÝÿò Û┤ÇÛ│äÙÑ╝ ÝòÖýèÁÝòÿÙèöÙì░ ýáüÝò®Ýò¿ 01. ýïáÛ▓¢ÙºØ DNNýØ┤Ù×Ç? ý×àÙáÑý©ÁÛ│╝ ý£ÙáÑý©Á ýé¼ýØ┤ýùÉ ýù¼Ùƒ¼ Û░£ýØÿ ýØÇÙïëý©ÁÙôñÙí£ ýØ┤Ùú¿ýû┤ýºä ýØ©Û│ÁýïáÛ▓¢ÙºØ 01. Input Layer 02. Hidden Layer 03. Output Layer ý×àÙáÑÛ░Æ ýáäÙï¼ ÔÇó ý×àÙáÑÛ░ÆÙôñýØä Ù░øýòä Hidden LayerýùÉ ýáäÙï¼ÝòÿÙèö Ùà©Ùô£ÙôñÙí£ ÛÁ¼ýä▒ÙÉ£ Layer Ù╣äýäáÝÿò Û┤ÇÛ│ä ÝòÖýèÁ ÔÇó Input LayerýÖÇ Output Layer ýé¼ýØ┤ýùÉ ýí┤ý×¼ÝòÿÙèö Layer ÔÇó Ùì░ýØ┤Ýä░ýØÿ Ýî¿Ýä┤ýØä ý░¥Ùèö ýù¡ÝòáýØä Ýò¿ ýÿêý©í Û▓░Û│╝ ý£ÙáÑ ÔÇó ýÿêý©í Û▓░Û│╝ÙÑ╝ ý£ÙáÑÝòÿÙèö Ùà©Ùô£ÙôñÙí£ ÛÁ¼ýä▒ÙÉ£ Layer Output Layer Input Layer Hidden Layer Deep Neural Network
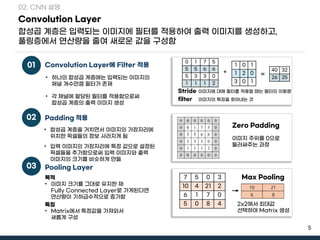
- 4. 4 Convolution Neural Network CNNýØ┤Ù×Ç ýØ┤Ù»©ýºÇ Ùì░ýØ┤Ýä░ÙÑ╝ ý▓ÿÙª¼ÝòáÙòî Ù░£ýâØÝòÿÙèö Ù¼©ýá£ýáÉýØä Ù│┤ýÖäÝò£ Ù░®Ù▓òý£╝Ùí£ Convolution LayerýÖÇ Fully Connected LayerÙí£ ýØ┤Ùú¿ýû┤ýºÉ 02. CNN ýäñÙ¬à Ùì░ýØ┤Ýä░ ýåÉýïñ DNNýØÇ 1ý░¿ýøÉ ÝÿòÝâ£ýØÿ Ùì░ýØ┤Ýä░ÙÑ╝ ýé¼ýÜ®Ýòÿýù¼ ýØ┤Ù»©ýºÇ Ùì░ýØ┤Ýä░Û░Ç ýåÉýïñýØ┤ ýâØÛ╣Ç ýØ┤Ù»©ýºÇÝè╣ýä▒Û░ÉýºÇ CNNýØÿ Convolution LayerÛ░Ç ý×àÙáÑýØ┤Ù»©ýºÇýùÉÙîÇÝò£ Ýè╣ýä▒ýØäÛ░ÉýºÇÝòÿÛ©░ý£äÝò┤ý╗ñÙäÉýØä ýé¼ýÜ® DNNýØÿ Ýò£Û│ä 01 CNN ÛÁ¼ýä▒ 02 ýØ┤Ù»©ýºÇÛ░Ç Ù¼┤ýùçýØä ýØÿÙ»©ÝòÿÙèö Ùì░ýØ┤Ýä░ýØ©ýºÇ ÙÂäÙÑÿ Flatten Layer, Softmax LayerÙí£ ÛÁ¼ýä▒ Ùì░ýØ┤Ýä░ýØÿ Ýè╣ýºòýØä ýÂöý£Ýòÿýù¼ Ýè╣ýºòÙôñýØÿ Ýî¿Ýä┤ýØä Ýîîýòà Convolution Layer, Pooling LayerÙí£ ÛÁ¼ýä▒ Feature Learning Classification
- 5. 5 Convolution Layer Ýò®ýä▒Û│▒ Û│äý©ÁýØÇ ý×àÙáÑÙÉÿÙèö ýØ┤Ù»©ýºÇýùÉ ÝòäÝä░ÙÑ╝ ýáüýÜ®Ýòÿýù¼ ý£ÙáÑ ýØ┤Ù»©ýºÇÙÑ╝ ýâØýä▒ÝòÿÛ│á, ÝÆÇÙºüý©ÁýùÉýä£ ýù░ýé░ÙƒëýØä ýñäýù¼ ýâêÙí£ýÜ┤ Û░ÆýØä ÛÁ¼ýä▒Ýò¿ 02. CNN ýäñÙ¬à ÔÇó ÝòÿÙéÿýØÿ Ýò®ýä▒Û│▒ Û│äý©ÁýùÉÙèö ý×àÙáÑÙÉÿÙèö ýØ┤Ù»©ýºÇýØÿ ý▒äÙäÉ Û░£ýêÿÙºîÝü╝ ÝòäÝä░Û░Ç ýí┤ý×¼ 01 Convolution LayerýùÉ Filter ýáüýÜ® ÔÇó ý×àÙáÑ ýØ┤Ù»©ýºÇýØÿ Û░Çý×Ñý×ÉÙª¼ýùÉ Ýè╣ýáò Û░Æý£╝Ùí£ ýäñýáòÙÉ£ Ýö¢ýàÇÙôñýØä ýÂöÛ░ÇÝò¿ý£╝Ùí£ýì¿ ý×àÙáÑ ýØ┤Ù»©ýºÇýÖÇ ý£ÙáÑ ýØ┤Ù»©ýºÇýØÿ Ýü¼Û©░ÙÑ╝ Ù╣äýèÀÝòÿÛ▓î ÙºîÙôª ÔÇó Ýò®ýä▒Û│▒ Û│äý©ÁýØä Û▒░ý╣ÿÙ®┤ýä£ ýØ┤Ù»©ýºÇýØÿ Û░Çý×Ñý×ÉÙª¼ýùÉ ý£äý╣ÿÝò£ Ýö¢ýàÇÙôñýØÿ ýáòÙ│┤ ýé¼ÙØ╝ýºÇÛ▓î ÙÉ¿ 02 Padding ýáüýÜ® Ù¬®ýáü ÔÇó ýØ┤Ù»©ýºÇ Ýü¼Û©░ÙÑ╝ ÛÀ©ÙîÇÙí£ ý£áýºÇÝò£ ý▒ä Fully Connected LayerÙí£ Û░ÇÛ▓îÙÉ£ÙïñÙ®┤ ýù░ýé░ÙƒëýØ┤ Û©░ÝòÿÛ©ëýêÿýáüý£╝Ùí£ ýªØÛ░ÇÝò¿ Ýè╣ýºò ÔÇó MatrixýùÉýä£ Ýè╣ýáòÛ░ÆýØä Û░Çýá©ýÖÇýä£ ýâêÙí¡Û▓î ÛÁ¼ýä▒ 03 Pooling Layer * = filter ýØ┤Ù»©ýºÇýùÉ ÙîÇÝò┤ ÝòäÝä░ÙÑ╝ ýáüýÜ®Ýòá ÙòîÙèö ÝòäÝä░ýØÿ ýØ┤ÙÅÖÙƒë Stride ÔÇó Û░ü ý▒äÙäÉýùÉ ÝòáÙï╣ÙÉ£ ÝòäÝä░ÙÑ╝ ýáüýÜ®Ýò¿ý£╝Ùí£ýì¿ Ýò®ýä▒Û│▒ Û│äý©ÁýØÿ ý£ÙáÑ ýØ┤Ù»©ýºÇ ýâØýä▒ Zero Padding ýØ┤Ù»©ýºÇ ýú╝ý£äÙÑ╝ 0ý£╝Ùí£ ÙæÿÙƒ¼ýï©ýú╝Ùèö Û│╝ýáò 10 21 6 8 Max Pooling 2x2ýùÉýä£ ýÁ£ÙîÇÛ░Æ ýäáÝâØÝòÿýù¼ Matrix ýâØýä▒ ýØ┤Ù»©ýºÇýØÿ Ýè╣ýºòýØä ý░¥ýòäÙé┤Ùèö Û▓â 0 1 7 5 5 5 6 6 5 3 3 0 1 1 1 2 1 0 1 1 2 0 3 0 1 40 32 26 25 7 5 0 3 10 4 21 2 6 1 7 0 5 0 8 4
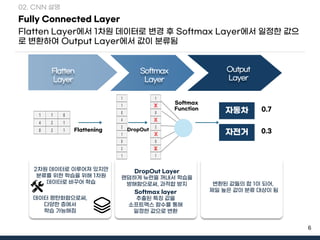
- 6. 6 Fully Connected Layer Flatten LayerýùÉýä£ 1ý░¿ýøÉ Ùì░ýØ┤Ýä░Ùí£ Ù│ÇÛ▓¢ Ýøä Softmax LayerýùÉýä£ ýØ╝ýáòÝò£ Û░Æý£╝ Ùí£ Ù│ÇÝÖÿÝòÿýù¼ Output LayerýùÉýä£ Û░ÆýØ┤ ÙÂäÙÑÿÙÉ¿ 02. CNN ýäñÙ¬à Flatten Layer Softmax Layer Output Layer 2ý░¿ýøÉ Ùì░ýØ┤Ýä░Ùí£ ýØ┤Ùú¿ýû┤ýá© ý×êýºÇÙºî ÙÂäÙÑÿÙÑ╝ ý£äÝò£ ÝòÖýèÁýØä ý£äÝò┤ 1ý░¿ýøÉ Ùì░ýØ┤Ýä░Ùí£ Ù░öÛ¥©ýû┤ ÝòÖýèÁ Softmax layer ýÂöý£ÙÉ£ Ýè╣ýºò Û░ÆýØä ýåîÝöäÝè©ÙºÑýèñ Ýò¿ýêÿÙÑ╝ ÝåÁÝò┤ ýØ╝ýáòÝò£ Û░Æý£╝Ùí£ Ù│ÇÝÖÿ Ù│ÇÝÖÿÙÉ£ Û░ÆÙôñýØÿ Ýò® 1ýØ┤ ÙÉÿýû┤, ýá£ýØ╝ ÙåÆýØÇ Û░ÆýØ┤ ÙÂäÙÑÿ ÙîÇýâüýØ┤ ÙÉ¿ Ùì░ýØ┤Ýä░ ÝÅëÝâäÝÖöÝò¿ý£╝Ùí£ýì¿, ÙïñýûæÝò£ ý©ÁýùÉýä£ ÝòÖýèÁ Û░ÇÙèÑÝò┤ýºÉ 1 1 0 4 2 1 0 2 1 1 1 0 4 2 1 0 2 1 Flattening DropOut Layer Ù×£ÙìñÝòÿÛ▓î Ùë┤Ùƒ░ýØä Û║╝Ùé┤ýä£ ÝòÖýèÁýØä Ù░®Ýò┤Ýò¿ý£╝Ùí£ýì¿, Û│╝ýáüÝò® Ù░®ýºÇ Softmax Function DropOut ý×ÉÙÅÖý░¿ 1 1 0 4 2 1 0 2 1 X X X X ý×ÉýáäÛ▒░ 0.7 0.3
- 7. 7 CNN Code Fashion MNIST Data ýÜ┤ÙÅÖÝÖö, ýàöý©á, ýâîÙôñÛ│╝ Û░ÖýØÇ ý×æýØÇ ýØ┤Ù»©ýºÇÙôñýØä Û░ÇýºÇÛ│á DNN, CNN Ù¬¿Ùì©ýùÉ ýáüýÜ®Ýòÿýù¼ AccuracyÙÑ╝ ÝÖòýØ©Ýò¿ 03. ÛÁ¼Ýÿä Fashion MNIST Data ýÜ┤ÙÅÖÝÖö, ýàöý©á, ýâîÙôñÛ│╝ Û░ÖýØÇ ý×æýØÇ ýØ┤Ù»©ýºÇÙôñýØÿ Ù¬¿ýØî 83 85 87 100 83.41 85.01 84.93 86.48 DNN ýáüýÜ® 3000 2000 1000 500 Ùï¿ý£ä : % 80 85 90 100 89.56 90.04 89.18 89.00 CNN ýáüýÜ® 3000 2400 1800 600 Ùï¿ý£ä : %