


























![[????] ??? ??? EEG ?? ??](https://cdn.slidesharecdn.com/ss_thumbnails/20180404a-gistintroeegdldkim-180622112533-thumbnail.jpg?width=560&fit=bounds)






















More Related Content
What's hot (20)
Similar to Deep Learning & Convolutional Neural Network (20)




![[???] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=560&fit=bounds)


![[paper review] ??? - Eye in the sky & 3D human pose estimation in video with ...](https://cdn.slidesharecdn.com/ss_thumbnails/190321eyeposegyubin-190517100712-thumbnail.jpg?width=560&fit=bounds)










Deep Learning & Convolutional Neural Network
- 1. Deep Learning & Convolutional Neural Network 1 ? ? ? 2018. 3. 23.
- 2. 2 Deep Learning? Deep Neural Network ? Deep Neural Network ??? (1986~2006) ó┘ Ī«DeepĪ» learning? ?? ???? ?? ? Local optimization? ??? initialization? ?? ??? ??? Learning? Network? ????? ??? overfitting ?? ? Vanishing gradient : ????? Sigmoid?? ??? Gradient Descent?? ???? 0? ???? Backpropagation? ?? weight ????? ?? ó┌ Computation Cost ?? ??? ?? ?? ? ??????? ?? ó┘ Ī«DeepĪ» Learning? ???? ?? ?? : Deep network? initialization ??? ?? ??? Deep Beilf Network(2007)? ???? ?? ó┌ Regularization Method(Drop out, ReLu) ?? ó█ Computer Vision ???? ??? CNN ?? ????? ???? ?? ó▄ ??? ??? ?? : ???? ??? GPU ???? ??? ?? ?? : http://sanghyukchun.github.io/75/
- 3. 3 ? Deep Belief Network (DBN, Hinton et al.,2007) ? Bengio et al.(2006)? Restricted Boltzmann Machine(RBM) ???? ?? ? Gradient approximation ?????? weight ? ???? MCMC (Gibbs Sampling)? step? converge? ? ?? ??? ?? ???, ? ?? ??? weight? approximate - ??? ???? converge? distribution??, ??? ?? distribution?? ??? ??? ? ????? ??? gradient ?? Gibbs sampling? ??? ??? ? approximation ? ? update? ???? pre-training ?? ?? ? Deep Belief Network? RBM? ???? ? ?? layer? ?? joint distribution? ? ??? graphical model? weight ???? unsupervised pre-training ? ? ?? ? Initial weight ?? ?? ?? Deep Learning? Deep Neural Network ?? : http://sanghyukchun.github.io/75/
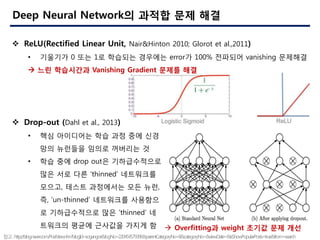
- 4. 4 ? Drop-out (Dahl et al., 2013) ? ?? ????? ?? ?? ?? ?? ?? ???? ??? ???? ? ? ?? ?? drop out? ??????? ?? ?? ?? Ī«thinnedĪ» ????? ???, ??? ????? ?? ??, ?, Ī«un-thinnedĪ» ????? ???? ? ??????? ?? Ī«thinnedĪ» ? ???? ??? ???? ??? ? ? Overfitting? weight ??? ?? ?? Deep Neural Network? ??? ?? ?? ? ReLU(Rectified Linear Unit, Nair&Hinton 2010; Glorot et al.,2011) ? ???? 0 ?? 1? ???? ???? error? 100% ???? vanishing ???? ? ?? ????? Vanishing Gradient ??? ?? ??:http://blog.naver.com/PostView.nhn?blogId=sogangori&logNo=220454579396&parentCategoryNo=8&categoryNo=&viewDate=&isShowPopularPosts=true&from=search
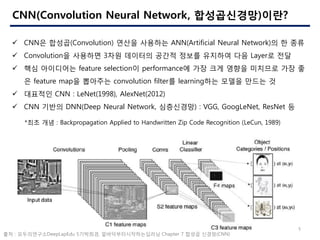
- 5. 5 CNN(Convolution Neural Network, ??????)??? ? CNN? ???(Convolution) ??? ???? ANN(Artificial Neural Network)? ? ?? ? Convolution? ???? 3?? ???? ??? ??? ???? ?? Layer? ?? ? ?? ????? feature selection? performance? ?? ?? ??? ???? ?? ? ? feature map? ???? convolution filter? learning?? ??? ??? ? ? ???? CNN : LeNet(1998), AlexNet(2012) ? CNN ??? DNN(Deep Neural Network, ?????) : VGG, GoogLeNet, ResNet ? *?? ?? : Backpropagation Applied to Handwritten Zip Code Recognition (LeCun, 1989) ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
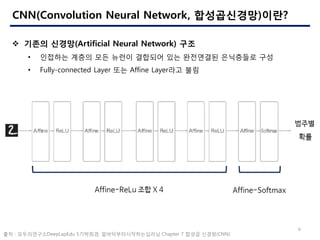
- 6. 6 CNN(Convolution Neural Network, ??????)??? ? ??? ???(Artificial Neural Network) ?? ? ???? ??? ?? ??? ???? ?? ????? ????? ?? ? Fully-connected Layer ?? Affine Layer?? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 7. 7 CNN(Convolution Neural Network, ??????)??? ? CNN(Convolution Neural Network) ?? ? ??? ???? ??? ??(Conv), ?? ??(Pooling)? ??? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 8. 8 Convolutional Layer : Fully-connected Layer? ?? ? ?? ???? ??? ?? ?? ? ??Īż??Īż??(??)? ??? 3?? ???? ???? ??????(fully- connected layer)? ??? ?, 1?? ???? ???? ??? ?? ?? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 9. 9 Convolutional Layer : Fully-connected Layer? ?? ? ?? ???? ??? ??? ?? ? ?? ??, ????? ??? ??? ?? ?????, RGB? ? ??? ?? ???? ???? ???, ??? ? ????? ???? ?? ?, 3?? ? ??? ?? ???? ??? ??? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 10. 10 Convolutional Layer : ??? ?? ? ???(Convolution) ? ??(??, ??)? ?? ??(Filter, Kernel)? ????(Stride)?? ????? ?????? ??(????, ??: ????-??) ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 11. 11 Convolutional Layer : ??? ?? ? ???(Convolution) ?? ? ??? ??? ??? ??? Shift ???? ???? ??? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 12. 12 Convolutional Layer : ??? ?? ? ???(Convolution) ??? ?? ? ??? ??? ??(Feature)? ???? ??? ??? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 13. 13 Convolutional Layer : ??? ?? ? ???(Convolution) ??? ?? ? ????? ?? ?? ? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 14. 14 Convolutional Layer : ??? ?? ? ???(Convolution) ??? ?? ? ????? ?? ?? ? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 15. 15 Convolutional Layer : ??? ?? ? ???(Convolution) ????? ????(Parameter) ? ??? ??? ?, ?? ??? ??(bias)? ??? ? ??(???), ??? ??? ?? ????? ? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 16. 16 Convolutional Layer : ??? ?? ? ??(Padding) ? ??? ??? ???? ?? ????? ??? ??? (?? 0©CZero paddig)? ??? ???, ?????? ?????? ??? ??? ?? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 17. 17 Convolutional Layer : ??? ?? ? ?????(Stride) - 2 Dimension ? ? ??? ???? ??? ????, Stride? ??? ????? ??? ? ????(OH(????), OW(????))? ??? ??? ???? ???? ? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
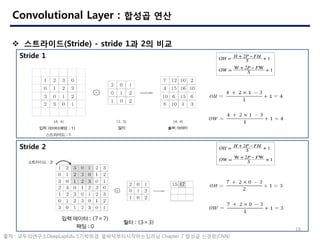
- 18. 18 Convolutional Layer : ??? ?? ? ?????(Stride) - stride 1? 2? ?? Stride 1 Stride 2 ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 19. 19 Convolutional Layer : ??? ?? ? 3?? ???? ??? ?? ? 3?? ???(RGB) ???? ??, ??? ???? ?? ?? ??? ?? ? Convolution Layer? ?? Layer? ?? ??? ???? ??? ??? ??? ?? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 20. 20 Convolutional Layer : ??? ?? ? 3?? ???? ??? ?? : FN?? ?? ? ??? ?????(FN), ?????(C), ??(FH), ??(FW)? ??? ?? ? ?????? ??? FN?? FN?? ???(Feature map)? ??? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 21. 21 Convolutional Layer : Parameter Learning ? Sparse weights ? Full connection ?? ?? ?? ???? learning?? ?? ??? ???, ?? complexity? ????? ??? ? ? ???? ?? feauture? ?? ???? ?? ??? ?????? ??? ? Shared(tied) weights ? ??? ??? ???? ?? ??? ??? weight? ???(bias? ??) ? ??? ?? ??? ?? ??? ?? ??? feature? detect? ? ?? ? ????? ? parameter ?? ??? Learning ??? ?? ?? : http://sanghyukchun.github.io/75/
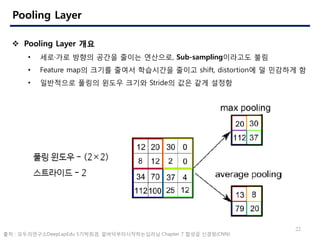
- 22. 22 Pooling Layer ? Pooling Layer ?? ? ??Īż?? ??? ??? ??? ????, Sub-sampling???? ?? ? Feature map? ??? ??? ????? ??? shift, distortion? ? ???? ? ? ????? ??? ??? ??? Stride? ?? ?? ??? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
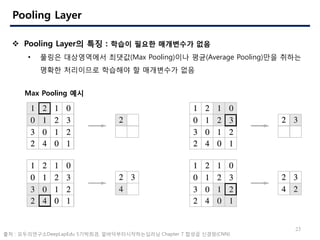
- 23. 23 Pooling Layer ? Pooling Layer? ?? : ??? ??? ????? ?? ? ??? ?????? ???(Max Pooling)?? ??(Average Pooling)?? ??? ??? ????? ???? ? ????? ?? Max Pooling ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
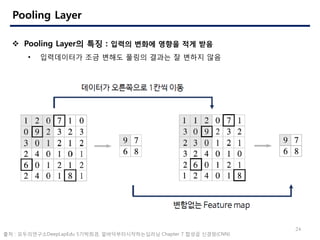
- 24. 24 Pooling Layer ? Pooling Layer? ?? : ??? ??? ??? ?? ?? ? ?????? ?? ??? ??? ??? ? ??? ?? ?? : ??????DeepLapEdu 5????, ???????????? Chapter 7 ??? ???(CNN)
- 25. 25 Pooling Layer ? Pooling Layer ?? ?? ?? :Convolutional neural networks - Abin - Roozgard
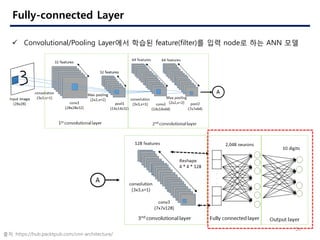
- 26. 26 Fully-connected Layer ? Convolutional/Pooling Layer?? ??? feature(filter)? ?? node? ?? ANN ?? ?? :https://hub.packtpub.com/cnn-architecture/
- 27. 27 ??? CNN ?? ?? : Speech Recognition Covolutional neural networks for speech recognition, IEEE/ACM Transactions on Audio, Speech, and Language Processing, Abdel-Hamid et al.(2014)
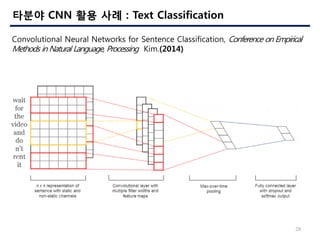
- 28. 28 ??? CNN ?? ?? : Text Classification Convolutional Neural Networks for Sentence Classification, Conference on Empirical Methods in Natural Language, Processing Kim.(2014)
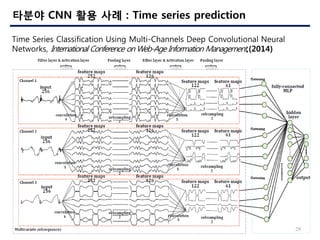
- 29. 29 ??? CNN ?? ?? : Time series prediction Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks, International Conference on Web-Age Information Management,(2014)
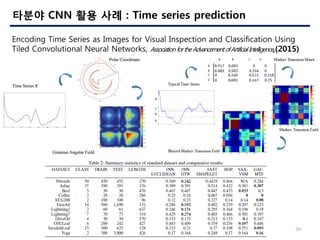
- 30. 30 ??? CNN ?? ?? : Time series prediction Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks, Association fortheAdvancement ofArtificial Intelligence,(2015)
- 31. 31 ??? CNN ?? ?? : Time series prediction Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction, Sensors, (2017)