[paper review] ??? - Eye in the sky & 3D human pose estimation in video with TCN, semi-supervised training
0 likes624 views

1. Eye in the Sky: Real-time Drone Surveillance System (DSS) for Violent Individuals Identification using ScatterNet Hybrid Deep Learning Network https://arxiv.org/abs/1806.00746 2. 3D human pose estimation in video with temporal convolutions and semi-supervised training https://arxiv.org/abs/1811.11742









![2. SHDL : ScatterNet Hybrid Deep Network 11
(1) ScatterNet : ??? ?? ??? [Dual-tree wavelet ScatterNet]? ??? ??
?CNN ???? Input
image? ???? ?
?? Conv block ??
(Coarse to fine)
?DT-CWT ??? ???
feature ???? 2?
layer? ??
?Hand crafted feature
? ? ????, CNN?
??? ?? ??? ??
??? ?? ??](https://image.slidesharecdn.com/190321eyeposegyubin-190517100712/85/paper-review-Eye-in-the-sky-3D-human-pose-estimation-in-video-with-TCN-semi-supervised-training-11-320.jpg)
![2. SHDL : ScatterNet Hybrid Deep Network 12
(1) ScatterNet : ??? ?? ??? [Dual-tree wavelet ScatterNet]? ??? ??
? Input signal x? dual-tree complex wavelets? ???? feature ??
?j : scale ??. 2? scale ??
?r : rotaion ??. 15, 45, 75, 105, 135, 165? ? 6?? ??
??? ???? scale, rotation? ????, ?? wavelet transform ??
?L2 normalization?, Log transform, Smoothing? ???? ??
??? ???? ? ???? coefficients? concatenate ? vector
”ūj,r](https://image.slidesharecdn.com/190321eyeposegyubin-190517100712/85/paper-review-Eye-in-the-sky-3D-human-pose-estimation-in-video-with-TCN-semi-supervised-training-12-320.jpg)






















![4. Experiments
(4) Results - Reconstruction error
35
??? Joint ??? Ground truth ??? ????? ??(MPJPE)
????? ? ?? ??? ??? ??,
? ?? ??? ?? [24]??? Ground truth? ??? ??](https://image.slidesharecdn.com/190321eyeposegyubin-190517100712/85/paper-review-Eye-in-the-sky-3D-human-pose-estimation-in-video-with-TCN-semi-supervised-training-35-320.jpg)
![4. Experiments
(4) Results
36
[?????]
Semi supervised ??? ?? ??? ?
? ? ?? ??? ??
[?? ??? ??]
Supervised ??? ?????
? ???? ?? 14.7mm ?? ?? ??](https://image.slidesharecdn.com/190321eyeposegyubin-190517100712/85/paper-review-Eye-in-the-sky-3D-human-pose-estimation-in-video-with-TCN-semi-supervised-training-36-320.jpg)






























More Related Content
What's hot (10)

Similar to [paper review] ??? - Eye in the sky & 3D human pose estimation in video with TCN, semi-supervised training (20)






![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)

[paper review] ??? - Eye in the sky & 3D human pose estimation in video with TCN, semi-supervised training
- 1. Eye in the Sky: Real-time Drone Surveillance System (DSS) forViolent Individuals Identi?cation using ScatterNet Hybrid Deep Learning Network Amarjot Singh et al. ??? ????? ??????? Data Science & Business Analytics ???
- 2. 0. Summary 1. Feature Pyramid Network 2. SHDL networks - Human pose estimation 3. Support Vector Machine - Detect violent individuals 4. Aerial Violent Individual(AVI) dataset 5. Experiments Index
- 3. 0. Summary 1. FPN?? human region ?? 2. SHDL network? human region?? keypoint ??? regression 3. Key-point? ???? ?? ?? ?? 3
- 4. 1. FPN: Feature Pyramid Networks Ī░Eye in the skyĪ▒ ???? human region? ???? ?? 4 ?FPN ??? ??? ??? object detection task?? pyramid ??? ? ?? ?? ?? ??? ??? ??, ??? ???? ?? ??? FPN ??? Faster R-CNN ??? ???? ?? cost ???? ?? ??? ?? ?GPU?? 6 FPS(COCO dataset) ?Pyramid ??? ???? ?? ?? ? ?? ?Featurized image pyramid ?Single feature map ?Pyramidal feature hierarchy ?Feature Pyramid Network
- 5. 1. FPN: Feature Pyramid Networks Pyramid ?? (1) Featurized image pyramid 5 ?hand craft feature? ???? ?? ????? ??? ??, scale? pyramid ?? ???? pyramid? ? level??? ????? feature ?? ?? ?? ???? ?? Object detection ?? ?????? ??, ?? ??
- 6. 1. FPN: Feature Pyramid Networks Pyramid ?? (2) Single feature map 6 ?????? feature? ???? ????? ??? feature layer? ???? ???? ?? ?CNN? ?? ??? ??, ??, ?? ??? invariant?? ??? ??? ????? ?? ?? ???? ??? ??? ???? ???? ???? ?? ?? ??? ??? ??? ? ??
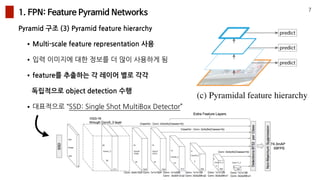
- 7. 1. FPN: Feature Pyramid Networks Pyramid ?? (3) Pyramid feature hierarchy 7 ?Multi-scale feature representation ?? ??? ???? ?? ??? ? ?? ???? ? ?feature? ???? ? ??? ?? ??? ????? object detection ?? ?????? Ī░SSD: Single Shot MultiBox DetectorĪ▒
- 8. 1. FPN: Feature Pyramid Networks Pyramid ?? (4) Feature Pyramid Network 8 ?? ??? FPN ?? ??? ???? Feature? ???? ?????? ????? FPN? Upsampling ??? ?? ?Feature map? Upsampling ????? lateral connection?? ?? ?? ???? ????? Object detection ?Multi-scale feature representation???? ?? ? ? ????? ???? ?? Feature? extraction? (Spatial Info) Upsampling (Semantic Info)
- 9. 1. FPN: Feature Pyramid Networks FPN ?? ?? ?? 9 ?Bottom-up ?????? ResNet ??? ?? ???? stride ??? receptive field ?? ?Top-down ?Upsampling? ???? ?? nearest neighbor upsampling ??(2? ??) ?feature map? 1x1 conv? ???? ?? element-wise addtion ?Final ?3x3 conv ???? ?? feaure map P ?? ?P?? 1x1 conv 2?? ??? class, bbox ????: github.com/hwkim94
- 10. 1. FPN: Feature Pyramid Networks FPN Application ?? 10 ?RPN : ?? FPN ??? Predictor Head? ? level? ?? ?? 5?? level?? Anchor ratio {1:2, 1:1, 2:1} 3?? ??? -> 15 anchors ?IoU threshold ?0.7 ?? : positive ?0.3 ?? : negative ?Predictor head? parameter? ?? level?? ?? ?MS COCO 80 category detection ?????? pretrain P 1x1 conv 3x3 conv 1x1 conv Class BBox
- 11. 2. SHDL : ScatterNet Hybrid Deep Network 11 (1) ScatterNet : ??? ?? ??? [Dual-tree wavelet ScatterNet]? ??? ?? ?CNN ???? Input image? ???? ? ?? Conv block ?? (Coarse to fine) ?DT-CWT ??? ??? feature ???? 2? layer? ?? ?Hand crafted feature ? ? ????, CNN? ??? ?? ??? ?? ??? ?? ??
- 12. 2. SHDL : ScatterNet Hybrid Deep Network 12 (1) ScatterNet : ??? ?? ??? [Dual-tree wavelet ScatterNet]? ??? ?? ? Input signal x? dual-tree complex wavelets? ???? feature ?? ?j : scale ??. 2? scale ?? ?r : rotaion ??. 15, 45, 75, 105, 135, 165? ? 6?? ?? ??? ???? scale, rotation? ????, ?? wavelet transform ?? ?L2 normalization?, Log transform, Smoothing? ???? ?? ??? ???? ? ???? coefficients? concatenate ? vector ”ūj,r
- 13. 2. SHDL : ScatterNet Hybrid Deep Network 13 (2) Regression Network : CNN ?? ?? ??? ScatterNet? output? ???? ?? CNN ???? ?? ?Conv block 4? ?? : { Convolution, ReLU, Pooling, Normalization } 4 blocks ?Fully connected layer 2?(+Dropout) : 1024, 2048 hidden units Scatter Network Conv block Conv block Conv block Conv block Dense Dense
- 14. 2. SHDL : ScatterNet Hybrid Deep Network 14 (2) Regression Network : ?? ?? ?Key-point 14?? ?? (x, y) ?? -> 28? ? regression ?Stochastic gradient descent ??? layer? output? prior? ???? PCANet ????? ?? ?TukeyĪ»s Biweight loss function ?? - ???? ?? f(n) = { x(1 ? x2 c2 )2 ?for|x| < c 0 for|x| > c
- 15. 3. Violent individual classification 15 Key-point ?? SVM?? ???? 6? ??? ??(??5+??1) ?SHDL network?? ??? keypoint? ?? ???? SVM ?? ?6? ??? ?? : 5?? ?? ??, ?? ?? ??? ?? ?Gaussian kernel ?C = 14 ?gamma = 0.00002 ?5-fold cross validation
- 16. 4. Aerial Violent Individual(AVI) Dataset 16 ?? task? ???? ?? ?? ???? ?? ?2,000?? ???(?? 10? ??) ?? 10,863?? ?? ?? ?48%? 5,124?? ??? ?? ??? ?? 5??: Punching, Stabbing(???),? Shooting, Kicking, Strangling(????, ??) ????? ??? 14?? key-point annotation ????? 2, 4, 6, 8?? ???? ?? ???? ?? ??? ????, ??? ???? ?? ???? ??? ? ?? ??? ??
- 17. 5. Experiments 17 (1) FPN? ??? Human detect accuracy 97.2% ?? ?? ?MS COCO ?????? pretrain ? ??? fine tuning ?AVI ????? ??? 10,863?? ?? ? 10,558? ?? detect ?? -> 97.2% (2) SHDL ?? ?? ?FPN? ?? ?? human region? 120 x 80 ???? resize ? normalize?? ?? ?10,558?? region? ???? train:validation:test ??? 6:2:2? ??
- 18. 5. Experiments 18 (2) SHDL Key-point regression ?? ?Distance from GT : Ground Truth ??? ?? ??? ?? ???? ???? ??? ??? ???? ??? ???? ???? 5?? ???? ???? ? ?? ??? ??
- 19. 5. Experiments 19 (2) SHDL Key-point regression ?? ?Distance from GT ?? d=5? ???? ?? accuracy ??? ? ?? ??? ?? ?? ???? ?? ?CN : Coordinate network ?CNE : Coordinate extended network SHDL CN CNE SpatialNet AVI Dataset 87.6% 79.6% 80.1% 83.4%
- 20. 5. Experiments 20 (3) Violent individuals identification with SVM ?AVI ????? ?? ?? ??? ?? ?? Punching Kicking Strangling Shooting Stabbing DSS 89% 94% 85% 82% 92 Surya 80% 84% 73% 73% 79% Number of Violent individuals per image 1 2 3 4 5 DSS 94.1% 90.6% 88.3% 87.8% 84.0% ?????? ???? ??? ?????? ??? ??
- 21. 3D human pose estimation in video with temporal convolutions and semi-supervised training Dario Pavllo et al. ??? ????? ??????? Data Science & Business Analytics ???
- 22. 1. Introduction 2. Temporal Dilated Convolutional model 3. Semi-supervised approach 4. Experiments Index
- 23. 1. Introduction Dilated Convolution? ??? 2d->3D mapping Semi-supervised ?? 23 ??? : 3D human pose estimation in video ?Problem formulation : Mapping ?2D keypoint detection -> 3D pose estimation ?2D?? 3D???? mapping? ? ???? ?? ???? RNN ??? ?? ?Main contribution ?3D human pose estimation in video based on? dilated temporal convolutions on 2D keypoint trajectories ?semi-supervised approach which exploits unlabeled video
- 24. 2. Temporal dilated convolutional model 2D joint coordinates? Sequence? ?? 3D joint? ??? ?? 24
- 25. 2. Temporal dilated convolutional model ?? ?? 25 ?Input data : 243(frame) x 34(17 joints * 2dim(x,y)) ?4 Residual blocks, 0.25 dropout rate, 243 frames, filter size 3, output feature 1024 ?TCN layer notation ?ex) 2J, 3d1, 1024 => ?? ?? 2J, Conv filter size 3, Dilation 1, ???? 1024 ?VALID convolution? ???? ??? Skip connection?? ??? ? ?? ??? -> Residual? ?? ???? Slice?? ??? ????.
- 26. 2. Temporal dilated convolutional model Normal convolution(Acausal) for train 26 ???? ? ????? ???? ?? ??
- 27. 2. Temporal dilated convolutional model Causal convolution for test 27 ?test ? ?? ?? ??? ??????? ????? ???? ??
- 28. 2. Temporal dilated convolutional model Padding with replica of the boundary frames 28 ????? frame? ???? padding(?? ???? Acausal) ????? ? ?? ???? zero pdding? ?? ? loss? ? ??? ?
- 29. 3. Semi-supervised approach Supervised, Unsupervised loss ? ?? ???? ??? ??? 29 ?Batch? Labeled, Unlabeled ??? ?? ?Supervised loss ?Ground truth 3d joint ?? ?Unsupervised loss(+Regularizer) ?Autoencoder ??? ?? ?encoder: 3D pose estimator ?3D joint? ?? projected back? ??? ? reconstruction loss? ?? ?Bone length? L2 loss? ?? Reconstruction error MPJPE(Mean Per-Joint Position Error) : ???? joint ?? ????? ??? ??
- 30. 3. Semi-supervised approach Trajectory model 30 ?Trajectory model? 2D pose? ????? => 3D trajectory? ???? ???? ?? ??? ??? 2D -> 3D mapping? ??? trajectory ??? ?? ?Unlabled data? back projection? ?? 3D trajectory?? ???? reconstruct ?Back projection? ???? ?? ??? Reconstruction error
- 31. 3. Semi-supervised approach Loss function 31 ?Supervised loss ?3D Ground truth? MPJPE ?? ?Global trajectory loss ?Camera?? Ground-truth depth?? ??? ?? ?? ???? ?? ?Weighted Mean Per-Joint? Position Error(WMPJPE) ?? E = 1 yz ||f(x) ? y|| Reconstruction error
- 32. 4. Experiments (1) ??? ???? : Human3.6M, HumanEva-I 32 ?Human 3.6M ?360?? video frame ?11 subjects(7?? 3D pose annotated) ?? subject ?? 15? action ?? ?HumanEva-I ??? ???? ?3? subject, 3? action(Walk, Jog, Box) ?15 joint skeleton ???? ??
- 33. 4. Experiments (3) 2D pose estimation : Mask R-CNN & Cascaded pyramid network 33 ?Backbone model ?Mask R-CNN with ResNet-101-FPN ?Cascaded Pyramid Network with ResNet-50 ??? ?? ?MS COCO ????? pre-train ?Human3.6M? fine-tune
- 34. 4. Experiments (4) Results - Qualitative 34 ?Top : ??? 2D pose? ?? ? ?Bottom : 3D joint mapping
- 35. 4. Experiments (4) Results - Reconstruction error 35 ??? Joint ??? Ground truth ??? ????? ??(MPJPE) ????? ? ?? ??? ??? ??, ? ?? ??? ?? [24]??? Ground truth? ??? ??
- 36. 4. Experiments (4) Results 36 [?????] Semi supervised ??? ?? ??? ? ? ? ?? ??? ?? [?? ??? ??] Supervised ??? ????? ? ???? ?? 14.7mm ?? ?? ??
- 37. ?????.