Cvpr 2019 pvnet
2 likes1,161 views

Introduce "PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation"(CVPR2019)






![PVNet
Ī± ķv▀B蹊┐ż“╠żż▐ż©żŲż╬ĘĮßś
Ī 2┤╬į¬ż╬╠žÅšĄŃ═ŲČ©Ī·PnPż╬2Č╬ļAżŪĮŌż»
Ī ėŗ╦Ń┴┐ż╬ėQĄŃż½żķRe?nementżŽąąż’ż╩żżżŪĮŌżŁż┐żż
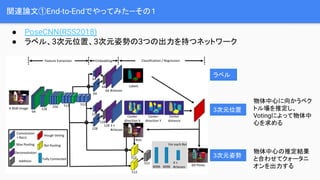
Ī ╠žÅšĄŃ═ŲČ©ż╦ź┘ź»ź╚źļł÷ż╬═ŲČ©ż╚Votingż“╚ĪżĻ╚ļżņżļ(źĒźąź╣ź╚ąįŽ“╔Ž)
Ī ═ŲČ©żĄżņż┐╠žÅšĄŃż╬▓╗┤_īgąįż“┐╝æ]żĘżŲPnPż“ĮŌż»(Š½Č╚Ž“╔Ž)
╠žÅšĄŃżžŽ“ż½ż”ź┘ź»ź╚źļ
źķź┘źļ
VotingPnP](https://image.slidesharecdn.com/cvpr2019pvnet-190701130940/85/Cvpr-2019-pvnet-16-320.jpg)

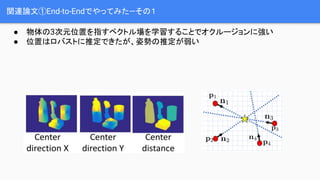
![Uncertainty-driven PnP
Ī± ═ŲČ©żĄżņż┐╠žÅšĄŃż╚Ęų╔óż╬üIĘĮż“┐╝æ]żĘż┐PnPå¢Ņ}ż“ĮŌż»](https://image.slidesharecdn.com/cvpr2019pvnet-190701130940/85/Cvpr-2019-pvnet-19-320.jpg)




Cvpr 2019 pvnet
- 1. PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation 2019/6/30 neka-nat
- 2. ūį╝║ĮBĮķ Ī± ├¹Ū░Ż║neka-nat Ī± ┬ÜśIŻ║ż╚żóżļčuįņźß®`ź½ż╬źĮźšź╚ź”ź¦źóź©ź¾źĖź╦źó Ī± ŲšČ╬ż╬ż¬╩╦╩┬ Ī ╗ŁŽ±äI└ĒżõźĒź▄ź├ź╚ż╬źĮźšź╚ķ_░k Ī± ūŅĮ³ż╬┼d╬ČŻ║ĄŃ╚║äI└ĒĪóCG Ī± https://twitter.com/neka_nat
- 3. ż│ż╬šō╬─ż“▀xż¾ż└└Ēė╔ Ī± Oralż╬šō╬─ż½żķ▀xÆk Ī± ╬¶ż½żķżóżļå¢Ņ}įOČ©ż└ż¼Īó╔Ņīėč¦┴Ģż╦żĶż├żŲż½ż╩żĻŠ½Č╚ż¼╔Žż¼ż├żŲżŁżŲżżżļ Ī± LINEMODźŪ®`ź┐ź╗ź├ź╚żŪSOTA Ī± ▒Š╚šż╬─┌╚▌ Ī å¢Ņ}įOČ©ż╦ż─żżżŲ Ī ķv▀B蹊┐ż╦ż─żżżŲ Ī PVNetż╦ż─żżżŲ
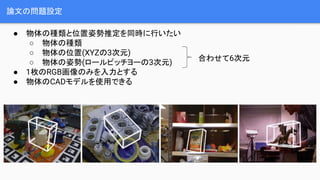
- 4. šō╬─ż╬å¢Ņ}įOČ© Ī± ╬’╠Õż╬ĘNŅÉż╚╬╗ų├ū╦ä▌═ŲČ©ż“═¼Ģrż╦ąążżż┐żż Ī ╬’╠Õż╬ĘNŅÉ Ī ╬’╠Õż╬╬╗ų├(XYZż╬3┤╬į¬) Ī ╬’╠Õż╬ū╦ä▌(źĒ®`źļźįź├ź┴źĶ®`ż╬3┤╬į¬) Ī± 1├Čż╬RGB╗ŁŽ±ż╬ż▀ż“╚ļ┴”ż╚ż╣żļ Ī± ╬’╠Õż╬CADźŌźŪźļż“╩╣ė├żŪżŁżļ ║Žż’ż╗żŲ6┤╬į¬
- 5. ÅĻė├└² Ī± źĒź▄ź├ź╚źėźĖźńź¾ Ī± AR Ī± źŪźūź╣ź╗ź¾źĄż╩ż╔ż¼╩╣ė├żĘż╦ż»żżŁhŠ│?ū┤ør Ī ąĪą═╗» Ī ╬▌═ŌżŪż╬╩╣ė├ Ī ź│ź╣ź╚Ž„£p
- 6. AR demo
- 7. żĶż»ė├żżżķżņżļźŪ®`ź┐ź╗ź├ź╚ Ī± żĮżņżŠżņCADźŌźŪźļż╚RGBD╗ŁŽ±ż¼ė├ęŌżĄżņżŲżżżļ Ī± LINEMOD, Occlusion LINEMOD Ī 15ĘNŅÉż╬ę╗░Ń╬’╠ÕĪ󟬟»źļ®`źĖźńź¾ż¼żóżļ?¤ożżźŪ®`ź┐ż¼Ęųż½żņżŲżżżļ Ī± T-LESS Ī 30ĘNŅÉż╬«bśI╬’╠ÕĪóźŲź»ź╣ź┴źŃż¼¤oż»╦Ųż┐╬’╠Õż¼ČÓżż Ī± YCB Ī 5ż─ż╦ź½źŲź┤źĻĘųż▒żĄżņż┐77ż╬ę╗░Ń╬’╠Õ
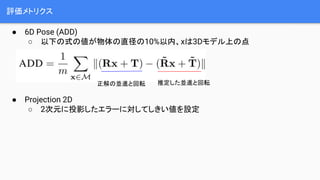
- 8. įuü²źßź╚źĻź»ź╣ Ī± 6D Pose (ADD) Ī ęįŽ┬ż╬╩Įż╬éÄż¼╬’╠Õż╬ų▒ŠČż╬10%ęį─┌ĪóxżŽ3DźŌźŪźļ╔Žż╬ĄŃ Ī± Projection 2D Ī 2┤╬į¬ż╦═Čė░żĘż┐ź©źķ®`ż╦īØżĘżŲżĘżŁżżéÄż“įOČ© š²ĮŌż╬üK▀Mż╚╗ž▄× ═ŲČ©żĘż┐üK▀Mż╚╗ž▄×
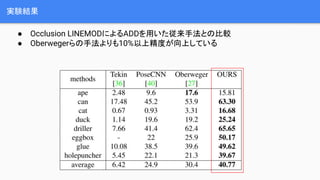
- 11. ķv▀Bšō╬─ó┌End-to-EndżŪżõż├żŲż▀ż┐©DżĮż╬Ż▓ Ī± SSD-6D(ICCV2017) Ī± SSDż“ź┘®`ź╣ż╦ū╦ä▌═ŲČ©ż“5ĪŃ┐╠ż▀ż╬ź»źķź╣ź┐źĻź¾ź░å¢Ņ}ż╦żĘżŲĮŌż» Ī żĶżĻźĒźąź╣ź╚ż╦ū╦ä▌ż¼Ū¾ż▐żļż¼Š½Č╚ż¼┬õż┴żļ Ī± │÷┴”ż“żĄżķż╦RGB╗ŁŽ±ż“ė├żżż┐ź©ź├źĖź┘®`ź╣ż╬Re?nementż╦ż½ż▒żļ
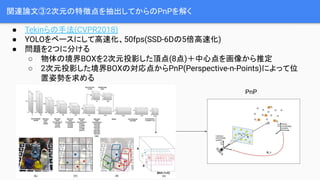
- 12. ķv▀Bšō╬─ó█2┤╬į¬ż╬╠žÅšĄŃż“│ķ│÷żĘżŲż½żķż╬PnPż“ĮŌż» Ī± Tekinżķż╬╩ųĘ©(CVPR2018) Ī± YOLOż“ź┘®`ź╣ż╦żĘżŲĖ▀╦┘╗»Īó50fps(SSD-6Dż╬5▒ČĖ▀╦┘╗») Ī± å¢Ņ}ż“2ż─ż╦Ęųż▒żļ Ī ╬’╠Õż╬Š│ĮńBOXż“2┤╬į¬═Čė░żĘż┐ĒöĄŃ(8ĄŃ)Ż½ųąą─ĄŃż“╗ŁŽ±ż½żķ═ŲČ© Ī 2┤╬į¬═Čė░żĘż┐Š│ĮńBOXż╬īØÅĻĄŃż½żķPnP(Perspective-n-Points)ż╦żĶż├żŲ╬╗ ų├ū╦ä▌ż“Ū¾żßżļ PnP
- 13. ķv▀Bšō╬─ó▄Re?nementżŌźŪźŻ®`źūż╦żĘżŲż▀ż┐ Ī± BB8(ICCV2017) Ī± ╠žÅšĄŃ│ķ│÷(Š│ĮńBOXż╬ĒöĄŃ)Ż½PnPŻ½Re?nementż╬śŗ│╔ Ī± Re?nementż╦CNNż“ė├żżż┐ ╬’╠Õų▄▐xż“ŪążĻ ╚Īż├ż┐╚ļ┴”╗ŁŽ± CADźŌźŪźļż“│§Ų┌ū╦ ä▌żŪźņź¾ź└źĻź¾ź░ CNN Š│ĮńBOXż╬ĒöĄŃż╬ęŲäė┴┐
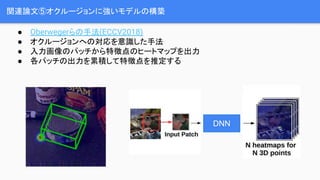
- 14. ķv▀Bšō╬─ó▌ź¬ź»źļ®`źĖźńź¾ż╦ÅŖżżźŌźŪźļż╬śŗ║B Ī± Oberwegerżķż╬╩ųĘ©(ECCV2018) Ī± ź¬ź»źļ®`źĖźńź¾żžż╬īØÅĻż“ęŌūRżĘż┐╩ųĘ© Ī± ╚ļ┴”╗ŁŽ±ż╬źčź├ź┴ż½żķ╠žÅšĄŃż╬źę®`ź╚ź▐ź├źūż“│÷┴” Ī± Ė„źčź├ź┴ż╬│÷┴”ż“└█ĘeżĘżŲ╠žÅšĄŃż“═ŲČ©ż╣żļ DNN
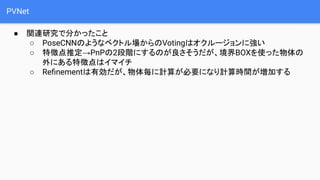
- 15. PVNet Ī± ķv▀B蹊┐żŪĘųż½ż├ż┐ż│ż╚ Ī PoseCNNż╬żĶż”ż╩ź┘ź»ź╚źļł÷ż½żķż╬VotingżŽź¬ź»źļ®`źĖźńź¾ż╦ÅŖżż Ī ╠žÅšĄŃ═ŲČ©Ī·PnPż╬2Č╬ļAż╦ż╣żļż╬ż¼┴╝żĄżĮż”ż└ż¼ĪóŠ│ĮńBOXż“╩╣ż├ż┐╬’╠Õż╬ ═Ōż╦żóżļ╠žÅšĄŃżŽźżź▐źżź┴ Ī Re?nementżŽėąä┐ż└ż¼Īó╬’╠ÕÜ░ż╦ėŗ╦Ńż¼▒žę¬ż╦ż╩żĻėŗ╦ŃĢrķgż¼ēł╝ėż╣żļ
- 16. PVNet Ī± ķv▀B蹊┐ż“╠żż▐ż©żŲż╬ĘĮßś Ī 2┤╬į¬ż╬╠žÅšĄŃ═ŲČ©Ī·PnPż╬2Č╬ļAżŪĮŌż» Ī ėŗ╦Ń┴┐ż╬ėQĄŃż½żķRe?nementżŽąąż’ż╩żżżŪĮŌżŁż┐żż Ī ╠žÅšĄŃ═ŲČ©ż╦ź┘ź»ź╚źļł÷ż╬═ŲČ©ż╚Votingż“╚ĪżĻ╚ļżņżļ(źĒźąź╣ź╚ąįŽ“╔Ž) Ī ═ŲČ©żĄżņż┐╠žÅšĄŃż╬▓╗┤_īgąįż“┐╝æ]żĘżŲPnPż“ĮŌż»(Š½Č╚Ž“╔Ž) ╠žÅšĄŃżžŽ“ż½ż”ź┘ź»ź╚źļ źķź┘źļ VotingPnP
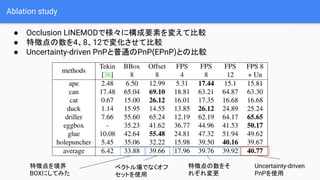
- 17. ╠žÅšĄŃ═ŲČ© Ī± Farthest-Point-Samplingż“ė├żżżŲ╩┬Ū░ż╦CADźŌźŪźļ╔Žż╬8ĄŃż╬╠žÅšĄŃż╚ųąą─ĄŃż“ Ū¾żßżļ Ī± RGB╗ŁŽ±ż½żķĖ„╠žÅšĄŃŻ½ųąą─ĄŃż╬ĘĮŽ“ż“╩Šż╣ź┘ź»ź╚źļł÷ż“═ŲČ©ż╣żļ Ī± Ė„źįź»ź╗źļż╬│÷┴”┤╬į¬żŽĪĖ(╠žÅšĄŃŻ½ųąą─ĄŃ)Ī┴ź┘ź»ź╚źļż╬┤╬į¬+ź½źŲź┤źĻ╩²Ī╣
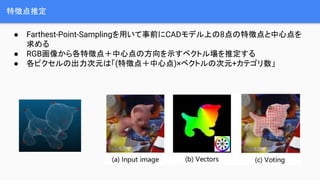
- 18. Uncertainty-driven PnP Ī± RANSACź┘®`ź╣ż╬Votingż╦żĶż├żŲ╠žÅšĄŃż╬║“čaĄŃhż“żżż»ż─Ū¾żßżļ Ī± ║“čaĄŃż“╠žÅšĄŃż╚żĘż┐ł÷║Žż╬ź┘ź»ź╚źļł÷ż╚═ŲČ©żĄżņż┐ź┘ź»ź╚źļł÷ż╚ż╬ę╗ų┬Č╚║Žżżż“║“ čaĄŃż╬ź╣ź│źóż╚ż╣żļ Ī± ║“čaĄŃż╚żĮż╬ź╣ź│źóż½żķ╠žÅšĄŃż╬ŲĮŠ∙éÄż╚Ęų╔óż“Ū¾żßżļ ║“čaĄŃż╬ųžż▀ ╠žÅšĄŃż╬═ŲČ©éÄ ═ŲČ©éÄż╬Ęų╔ó
- 20. ź═ź├ź╚ź’®`ź»źó®`źŁźŲź»ź┴źŃ Ī± Pretrained ResNet18ż“źąź├ź»ź▄®`ź¾ż╦żĘżŲżżżļ Ī± ųąķg╗ŁŽ±ż╬źĄźżź║ż¼H/8Ī┴W/8ż╦ż╩ż├ż┐ĢrĄŃżŪPoolingż“ąąż’ż╩żż Ī± ųąķg╗ŁŽ±ż╬źĄźżź║ż“ŠS│ųżĘż─ż─Ūķł¾╝»╝sż“ąąż”ż┐żßż╦Dilated Convż“╩╣ė├ Ī± ź╣źŁź├źūż╣żļż╚ż│żĒżŽStrideżŪš{š¹
- 21. č¦┴ĢĘĮĘ© Ī± š²ĮŌż╬ź┘ź»ź╚źļł÷ż╚═ŲČ©ĮY╣¹ż“ė├żżżŲSmooth L1 lossż“ėŗ╦Ń Ī± ▀^č¦┴Ģż“Ę└ż░ż┐żß║Ž│╔╗ŁŽ±ż“20000├ČūĘ╝ė
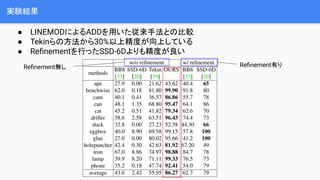
- 22. Ablation study Ī± Occlusion LINEMODżŪśöĪ®ż╦śŗ│╔ę¬╦žż“ēõż©żŲ▒╚▌^ Ī± ╠žÅšĄŃż╬╩²ż“4Īó8Īó12żŪēõ╗»żĄż╗żŲ▒╚▌^ Ī± Uncertainty-driven PnPż╚Ųš═©ż╬PnP(EPnP)ż╚ż╬▒╚▌^ ╠žÅšĄŃż“Š│Įń BOXż╦żĘżŲż▀ż┐ ╠žÅšĄŃż╬╩²ż“żĮ żņżŠżņēõĖ³ Uncertainty-driven PnPż“╩╣ė├ ź┘ź»ź╚źļł÷żŪż╩ż»ź¬źš ź╗ź├ź╚ż“╩╣ė├
- 23. īg“YĮY╣¹ Ī± LINEMODż╦żĶżļADDż“ė├żżż┐ÅŠ└┤╩ųĘ©ż╚ż╬▒╚▌^ Ī± Tekinżķż╬ĘĮĘ©ż½żķ30%ęį╔ŽŠ½Č╚ż¼Ž“╔ŽżĘżŲżżżļ Ī± Re?nementż“ąąż├ż┐SSD-6DżĶżĻżŌŠ½Č╚ż¼┴╝żż Re?nement¤ożĘ Re?nementėążĻ
- 24. īg“YĮY╣¹ Ī± Occlusion LINEMODż╦żĶżļADDż“ė├żżż┐ÅŠ└┤╩ųĘ©ż╚ż╬▒╚▌^ Ī± ░┐▓·▒░∙Ę╔▒▓Ą▒░∙żķż╬╩ųĘ©żĶżĻżŌ10%ęį╔ŽŠ½Č╚ż¼Ž“╔ŽżĘżŲżżżļ
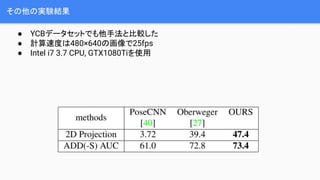
- 26. żĮż╬╦¹ż╬īg“YĮY╣¹ Ī± YCBźŪ®`ź┐ź╗ź├ź╚żŪżŌ╦¹╩ųĘ©ż╚▒╚▌^żĘż┐ Ī± ėŗ╦Ń╦┘Č╚żŽ480Ī┴640ż╬╗ŁŽ±żŪ25fps Ī± Intel i7 3.7 CPU, GTX1080Tiż“╩╣ė├
- 27. ż▐ż╚żß Ī± CVPR2019żŪ░k▒ĒżĄżņż┐6┤╬į¬ū╦ä▌═ŲČ©╩ųĘ©PVNetż“ĮBĮķżĘż┐ Ī± Re?nement¤ożĘżŪĖ▀Š½Č╚ż╦═ŲČ©┐╔─▄ Ī± Occlusion, truncationż╦żŌīØÅĻżŪżŁżļ Ī± ų°š▀ż╦żĶżļPytorchż╬źĮ®`ź╣ź│®`ź╔ż¼└¹ė├żŪżŁżļ Ī https://github.com/zju3dv/pvnet Ī± ź╚źņ®`ź╦ź¾ź░╗ŁŽ±╔·│╔ Ī https://github.com/zju3dv/pvnet-rendering
- 28. ż¬ż’żĻ