Data-Intensive Text Processing with MapReduce ch6.1
3 likes598 views

This document is written about "Data-Intensive Text Processing with MapReduce" Chapter 6.1. Chapter 6 describes how to design Expectation Maximization with MapReduce algorithm. Section 6.1 focus to Expectation Maximization algorithm itself, and so there are no description about MapReduce.









![ÖCąĄč¦┴Ģż╬ĘųŅÉ
Ī± Į╠ĤżóżĻč¦┴Ģ
Ī± Ī░╩┬Ū░ż╦ėļż©żķżņż┐źŪ®`ź┐ż“żżż’żąĪĖ└²Ņ}Ż©ŻĮŽ╚╔·ż½żķ
ż╬ų·čįŻ®Ī╣ż╚ż▀ż╩żĘżŲĪóżĮżņż“ź¼źżź╔ż╦č¦┴ĢŻ©ŻĮźŪ®`
ź┐żžż╬║╬żķż½ż╬źšźŻź├źŲźŻź¾ź░Ż®ż“ąąż”Ī▒ [5]
Ī± └²) SVM, ź╩źż®`źųź┘źżź║
Ī± Į╠Ĥż╩żĘč¦┴Ģ
Ī± Ī░│÷┴”ż╣ż┘żŁżŌż╬ż¼żóżķż½żĖżßøQż▐ż├żŲżżż╩żżż╚żżż”ĄŃ
żŪĮ╠ĤżóżĻč¦┴Ģż╚żŽ┤¾żŁż»«Éż╩żļĪŻ źŪ®`ź┐ż╬▒│ßßż╦┤µ
į┌ż╣żļ▒Š┘|Ą─ż╩śŗįņż“│ķ│÷ż╣żļż┐żßż╦ė├żżżķżņżļĪ▒ [6]
Ī± └²) ź»źķź╣ź┐źĻź¾ź░, ūį╝║ĮM┐Ś╗»ź▐ź├źū](https://image.slidesharecdn.com/mapreduce1010172-101017090123-phpapp01/85/Data-Intensive-Text-Processing-with-MapReduce-ch6-1-10-320.jpg)



![EMźóźļź┤źĻź║źÓ
Ī± "┤_┬╩źŌźŪźļż╬źčźķźß®`ź┐ż“ūŅė╚Ę©ż╦╗∙ż┼żżżŲ═ŲČ©ż╣żļ╩ų
Ę©ż╬żęż╚ż─żŪżóżĻĪó ėQ£y▓╗┐╔─▄ż╩Ū▒į┌ēõ╩²ż╦┤_┬╩źŌźŪźļ
ż¼ę└┤µż╣żļł÷║Žż╦ė├żżżķżņżļ" [7]
Ī± Eź╣źŲź├źūĪóMź╣źŲź├źūż╬└RżĻĘĄżĘżŪäI└Ēż“ąąż”
Ī± Eź╣źŲź├źū
Ī± ėļż©żķżņż┐źčźķźß®`ź┐ż“į¬ż╦Īóė╚Č╚ķv╩²ż╬Ų┌┤²éÄż“╦Ń│÷
Ī± Mź╣źŲź├źū
Ī± Ų┌┤²éÄż“ūŅ┤¾╗»ż╣żļźčźķźß®`ź┐ż“╦Ń│÷
Ī± ż│ż╬ź╗ź»źĘźńź¾żŪżŽĪóż│ż╬EMźóźļź┤źĻź║źÓż╦ż─żżżŲĮŌšh
ż╣żļ(MapReduceę╗Ūąż╩żĘ)](https://image.slidesharecdn.com/mapreduce1010172-101017090123-phpapp01/85/Data-Intensive-Text-Processing-with-MapReduce-ch6-1-14-320.jpg)





















![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=560&fit=bounds)



























More Related Content
Viewers also liked (19)
Similar to Data-Intensive Text Processing with MapReduce ch6.1 (20)






![[The Elements of Statistical Learning]Chapter18: High Dimensional Problems](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter18highdimensionalproblems-181109005557-thumbnail.jpg?width=560&fit=bounds)

![[DL▌åši╗ß]Deep Learning Ą┌5š┬ ÖCąĄč¦┴Ģż╬╗∙ĄA](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=560&fit=bounds)








Data-Intensive Text Processing with MapReduce ch6.1
- 1. Data-Intensive Text Processing with MapReduce (Ch6 EM Algorithms for Text Processing, Part 1) 2010/10/17 shiumachi http://d.hatena.ne.jp/shiumachi/ http://twitter.com/shiumachi http://www.facebook.com/sho.shimauchi
- 2. Agenda Ī± 6š┬ĪĪźŲźŁź╣ź╚äI└Ēż╬ż┐żßż╬EMźóźļź┤źĻź║źÓ Ī± źżź¾ź╚źĒź└ź»źĘźńź¾ Ī± 6.1 Expectation Maximization(Ų┌┤²éÄūŅ┤¾╗») ©C 6.1.1 ūŅė╚═ŲČ© ©C 6.1.2 Ū▒į┌ēõ╩²ż─żŁźė®`ė±ź▓®`źÓ ©C 6.1.3 Ū▒į┌ēõ╩²ż─żŁūŅė╚═ŲČ© ©C 6.1.4 Expectation Maximization ©C 6.1.5 EMż╬└²
- 3. Chapter 6 EM Algorithms for Text Processing 6š┬ źŲźŁź╣ź╚äI└Ēż╬ż┐żßż╬EMźóźļź┤źĻź║źÓ
- 5. źŲźŁź╣ź╚äI└Ēż╬Üs╩Ę Ī± 1980─Ļ┤·ż╬ĮKż’żĻż▐żŪżŽźļ®`źļź┘®`ź╣ Ī± Ęų╬÷żõēõōQż╬źļ®`źļż“żęż┐ż╣żķ╚╦┴”żŪĢ°ż»ą╬╩Į Ī± źļ®`źļż╦Ą▒żŲżŽż▐żņżążżżżż▒ż╔Īó═ŲČ©ż¼╚½ż»żŪżŁż╩ żż Ī± 1990─Ļż½żķ¼F┤·ż▐żŪżŽźŪ®`ź┐ź╔źĻźųź¾ż¼ų„┴„ Ī± ė¢ŠÜźŪ®`ź┐ż“ė├żżżŲźčźķźß®`ź┐š{š¹ ©C ź╣źčźÓźšźŻźļź┐ż╚ż½ Ī± żõż¼żŲĪóźóźļź┤źĻź║źÓūį╠ÕżŌė¢ŠÜźŪ®`ź┐żŪĖ─╔ŲżĘżŲ żżż»żĶż”ż╦Ī·ÖCąĄč¦┴Ģż╬╩└Įńżž
- 6. źŪ®`ź┐ź╔źĻźųź¾ż╬└¹ĄŃ Ī± Ü▌ż¼└¹ż» Ī± ė¢ŠÜźŪ®`ź┐ż╦żĶżĻąņĪ®ż╦źóźļź┤źĻź║źÓż“ą▐š²żŪżŁżļ ż╬żŪĪó¼Fīg╩└Įńż╬č}ļjżĄż╦īØÅĻżĘżõż╣żż Ī± ░▓żż Ī± į¬ż╬źŪ®`ź┐żŽż│ż╬źĘź╣źŲźÓż“ū„żļż┐żßż╦ą┬żĘż»╔·│╔ ż╣żļ▒žę¬ż¼ż╩żżż│ż╚ż¼ČÓżż ©C źŲźŁź╣ź╚äI└Ēė├ż╬ė¢ŠÜźŪ®`ź┐ż└ż├ż┐żķĪó▒Šżõwebż╦╝╚ż╦ ┤¾┴┐ż╦┤µį┌żĘżŲżżżļ Ī± źļ®`źļź┘®`ź╣ż└ż╚Ü░╗žĢ°żŁų▒ż╣▒žę¬ż¼żóżļ
- 7. ĮyėŗźŌźŪźļ Ī± ż│ż╬š┬żŪÆQż”źŪ®`ź┐ź╔źĻźųź¾ż╬╩ųĘ©żŽĮyėŗźŌźŪźļ Ī± 3ż─ż╬šnŅ}ż¼żóżļ Ī± źŌźŪźļ▀xÆk ©C HMM(ļLżņź▐źļź│źšźŌźŪźļ) Ī± źčźķźß®`ź┐═ŲČ©?č¦┴Ģ ©C ūŅė╚═ŲČ©ż╚EMźóźļź┤źĻź║źÓ Ī± źŪź│®`źŪźŻź¾ź░ Ī± ż│ż╬š┬żŪżŽźčźķźß®`ź┐═ŲČ©ż¼źßźżź¾ż└ż¼ĪóźŪ ź│®`źŪźŻź¾ź░ż╦żŌ┤źżņżļ
- 8. ėø║┼ż╬Č©┴xż╚ż½ X : ╚ļ┴”źŪ®`ź┐ź╗ź├ź╚(ėQ£y┐╔─▄) Y : ┤µį┌żĘĄ├żļźóź╬źŲ®`źĘźńź¾ż╬╝»║Ž (źóź╬źŲ®`źĘźńź¾ż╚żŽźßź┐źŪ®`ź┐ż╬żĶż”ż╩żŌż╬) x Ī╩ X, y Ī╩ Y ż│ż╬ż╚żŁėļż©żķżņż┐ x ż╦īØż╣żļ y ż╬┤_┬╩ż“ęįŽ┬ż╬ 2═©żĻżŪ▒Ēėøż╣żļ Pr(x, y) ĪŁ źĖźńźżź¾ź╚źŌźŪźļ Pr(y | x) ĪŁ ź│ź¾źŪźŻźĘźńź╩źļźŌźŪźļ
- 9. źŪź│®`źŪźŻź¾ź░ż╬╩ųĘ© ėļż©żķżņż┐ x ż╦īØżĘżŲPrż╬ūŅ┤¾éÄż“ż╚żļ y ż“│÷ż╣ źĖźńźżź¾ź╚źŌ®`ź╔żŪĢ°ż»ż╚ż│ż¾ż╩ĖążĖ żżż║żņż╦ż╗żĶŲ¼ż├Č╦ż½żķėŗ╦Ńż╣żņżą╦Ń│÷┐╔─▄
- 10. ÖCąĄč¦┴Ģż╬ĘųŅÉ Ī± Į╠ĤżóżĻč¦┴Ģ Ī± Ī░╩┬Ū░ż╦ėļż©żķżņż┐źŪ®`ź┐ż“żżż’żąĪĖ└²Ņ}Ż©ŻĮŽ╚╔·ż½żķ ż╬ų·čįŻ®Ī╣ż╚ż▀ż╩żĘżŲĪóżĮżņż“ź¼źżź╔ż╦č¦┴ĢŻ©ŻĮźŪ®` ź┐żžż╬║╬żķż½ż╬źšźŻź├źŲźŻź¾ź░Ż®ż“ąąż”Ī▒ [5] Ī± └²) SVM, ź╩źż®`źųź┘źżź║ Ī± Į╠Ĥż╩żĘč¦┴Ģ Ī± Ī░│÷┴”ż╣ż┘żŁżŌż╬ż¼żóżķż½żĖżßøQż▐ż├żŲżżż╩żżż╚żżż”ĄŃ żŪĮ╠ĤżóżĻč¦┴Ģż╚żŽ┤¾żŁż»«Éż╩żļĪŻ źŪ®`ź┐ż╬▒│ßßż╦┤µ į┌ż╣żļ▒Š┘|Ą─ż╩śŗįņż“│ķ│÷ż╣żļż┐żßż╦ė├żżżķżņżļĪ▒ [6] Ī± └²) ź»źķź╣ź┐źĻź¾ź░, ūį╝║ĮM┐Ś╗»ź▐ź├źū
- 11. Į╠ĤżóżĻč¦┴Ģ ╝╚ż╦ x ż╚ y ż╬īØÅĻż¼Ęųż½ż├żŲżżżļźŪ®`ź┐ź╗ź├ź╚ż“ ė¢ŠÜźŪ®`ź┐ż╚ż╣żļ Z = < <x1, y1>, <x2,y2> ...> ż│ż│żŪ <xi, yi> Ī╩ X * Y ż│ż╬īØÅĻż┼ż▒żŽź▐ź╦źÕźóźļżŪąąż’ż╩ż▒żņżążżż▒ż╩ żżż┐żßĘŪ│Żż╦┤¾ēõ
- 12. Į╠Ĥż╩żĘč¦┴Ģ x żĄż©ė├ęŌżĘżŲż¬ż▒żąOK Z = < x1, x2, x3 ...> ż│ż│żŪ xi Ī╩ X ╝»║ŽYż“Č©┴xżĘżŲč¦┴Ģ╗∙£╩ż╚źŌźŪźļśŗįņż“ū„ż├żŲ ż¬ż▒żąĪó╩┬Ū░ż╦źķź┘źĻź¾ź░żĘżŲżżż╩ż»żŲżŌč¦┴ĢżŪ żŁżļ Į╠Ĥż╩żĘč¦┴Ģźóźļź┤źĻź║źÓż╬ę╗ż─ĪóEMźóźļź┤źĻ ź║źÓ ż╚ MapReduce ż╬ŽÓąįż¼żżżżż┐żßĪóż│ż╬▒Š żŪżŽEMźóźļź┤źĻź║źÓż“╚ĪżĻÆQż”
- 14. EMźóźļź┤źĻź║źÓ Ī± "┤_┬╩źŌźŪźļż╬źčźķźß®`ź┐ż“ūŅė╚Ę©ż╦╗∙ż┼żżżŲ═ŲČ©ż╣żļ╩ų Ę©ż╬żęż╚ż─żŪżóżĻĪó ėQ£y▓╗┐╔─▄ż╩Ū▒į┌ēõ╩²ż╦┤_┬╩źŌźŪźļ ż¼ę└┤µż╣żļł÷║Žż╦ė├żżżķżņżļ" [7] Ī± Eź╣źŲź├źūĪóMź╣źŲź├źūż╬└RżĻĘĄżĘżŪäI└Ēż“ąąż” Ī± Eź╣źŲź├źū Ī± ėļż©żķżņż┐źčźķźß®`ź┐ż“į¬ż╦Īóė╚Č╚ķv╩²ż╬Ų┌┤²éÄż“╦Ń│÷ Ī± Mź╣źŲź├źū Ī± Ų┌┤²éÄż“ūŅ┤¾╗»ż╣żļźčźķźß®`ź┐ż“╦Ń│÷ Ī± ż│ż╬ź╗ź»źĘźńź¾żŪżŽĪóż│ż╬EMźóźļź┤źĻź║źÓż╦ż─żżżŲĮŌšh ż╣żļ(MapReduceę╗Ūąż╩żĘ)
- 15. 6.1.1 ūŅė╚═ŲČ©
- 16. ūŅė╚═ŲČ©(MLE) Ī± ėļż©żķżņż┐źŪ®`ź┐ x ż╦īØżĘę╗Ę¼ė╚żŌżķżĘżżźčźķ źß®`ź┐ ”╚ ż“═Ų£yż╣żļĘĮĘ©(╩Į6.1) Ī± └²ż©żąźė®`ė±ź▓®`źÓ(ćĒ6.1Īó┤╬ź┌®`źĖ)żŪżŽĪó źļ®`źļź┘®`ź╣żŪżóżņżą╬’└ĒźŌźŪźļż“ū„żķż╩ż▒żņ żążżż▒ż╩żżż¼ĪóMLEżŪżóżņżąż╔ż┴żķż╬źąź╣ź▒ź├ ź╚ż╦║╬╗ž╚ļż├ż┐ż½ż“ėQ£yż╣żļż└ż▒żŪżżżż
- 18. ┤_┬╩ż“│÷żĘżŲż▀żļ 10╗žįćąążĘĪóa ż╦2╗žĪób ż╦8╗ž╚ļż├ż┐ż╚ż╣żļĪŻ a ż╦╚ļżļ┤_┬╩ż“ p ż╚ż╣żļż╚Īó Pr ż“ūŅ┤¾ż╦ż╣żļż╚żŁż╬ p ż“│÷ż╣ż╦żŽ╬óĘųż╣żņżą żżżż
- 19. ┤_┬╩ż“│÷żĘżŲż▀żļ(ŠAżŁ) īØ╩²ż“ż╚ż├żŲ╬óĘųż╣żļż╚ż│ż”ż╩żļ ż│żņż“ĮŌż▒żą p = 0.2 ż╚ż’ż½żļĪŻ żĄżķż╦š{ż┘żŲżżż▒żąĪóN╗žįćąążŪaż╦N0╗žĪóbż╦N1╗ž╚ļż├ż┐ż╚żŁż╦ ė╚żŌżķżĘżż p żŽĪóp = N0 / (N0 + N1) Ī∙ źŲźŁź╣ź╚ż╬╩ĮżŽš`ų▓
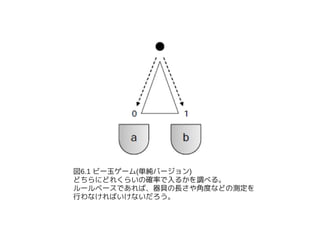
- 21. źė®`ė±ź▓®`źÓĖ─ Ī± źąź╣ź▒ź├ź╚ż“3ż─ż╦żĘĪóČ╬ż“1ż─ēłżõż╣ Ī± Ą┌1Č╬żŪėęż╦ąąż»┤_┬╩ż“ p0, Ą┌1Č╬żŪū¾ż╦ąążŁĪó Ą┌2Č╬żŪėęż╦ąąż»┤_┬╩ż“ p1, Ą┌1Č╬?Ą┌2Č╬ż╚żŌ ż╦ėęż╦ąąż»┤_┬╩ż“ p2 ż╚ż╣żļ(┤╬ź┌®`źĖ▓╬šš) Ī± ĪĖż╔ż╬źčź╣ż“═©ż├ż┐ż½Ī╣ż¼ėQ£yżŪżŁżļł÷║ŽżŽ ż╚ż├żŲżŌ║åģg
- 22. p0 p1 p2 ćĒ6.2 źė®`ė±ź▓®`źÓĖ─ ż╔ż╬źčź╣ż“═©ż├ż┐ż½ż“ėQ£yżŪżŁżļł÷║ŽżŽ║åģgĪŻ żĘż½żĘĪóźąź╣ź▒ź├ź╚ż╦╚ļż├ż┐źė®`ė±ż╬╩²ż└ż▒żĘż½ ėQ£yżŪżŁż╩żżł÷║Žż╔ż”ż╣żļż½Ż┐
- 24. źčź╣ż“ėQ£yżŪżŁż╩żżż╚żŁ Ī± Į╠Ĥż╩żĘč¦┴Ģż╬│÷Ę¼ Ī± ▓┐ĘųĄ─ż╩Ūķł¾ż└ż▒żŪ Pr ż“═ŲČ©ż╣żļ Ī± Ys ż“╚½żŲż╬Ū▒į┌ēõ╩² y ż╬║Žėŗż╚żĘżŲŪ░╩÷ż╬╩Į ż“Ģ°żŁų▒ż╣ Ī± ż│ż│żŪż╬ y żŽ x ż╚═¼śöźżź¾źūź├ź╚é╚ż╬źčźķźß®`ź┐ żŪżóżļż│ż╚ż╦ūóęŌ(ūŅĮKĄ─ż╦żŽŪ¾żßżļéÄż└ż¼)
- 25. ūŅė╚éÄż“Ū¾żßżļ żóżļėQ£yéÄ x ż╦īØż╣żļ Pr żŽĪó ╚½żŲż╬ėQ£yź┘ź»ź╚źļ x = <x1, x2 ...> ż╦īØż╣żļ Pr żŽĪó żĶż├żŲę╗Ę¼ė╚żŌżķżĘżżźčźķźß®`ź┐ ”╚ żŽĪó
- 27. EMźóźļź┤źĻź║źÓż╬ĮŌšh Ī± EMźóźļź┤źĻź║źÓżŽė¢ŠÜźŪ®`ź┐ż╬ų▄▐x┤_┬╩ż“ēł ╝ėżĄż╗żŲżżż»ę╗▀Bż╬źčźķźß®`ź┐ż“Ū¾żßżļż┐żßż╬ └RżĻĘĄżĘźóźļź┤źĻź║źÓ Ī± EMźóźļź┤źĻź║źÓżŽęįŽ┬ż╬╩Įż“▒Żį^ż╣żļ
- 28. Eź╣źŲź├źū ¼Fį┌ż╬źčźķźß®`ź┐ż╦╗∙ż┼żŁĪóżĮżņżŠżņż╬ėQ£yéÄ x ż╦īØż╣żļ y ż╬╩┬ ßß┤_┬╩ż“Ū¾żßżļ ż│ż╬ż╚żŁĪóx ż¼╝»║Ž X ż╦│÷żŲż»żļŽÓīØ┤_┬╩ż╦╗∙ż┼żŁųžż▀ĖČż▒ż╣żļ ż│ż╬╩┬ßß┤_┬╩ż“ q(X = x, Y = y; ”╚(i)) ż╚ż╣żļ
- 29. Mź╣źŲź├źū Eź╣źŲź├źūżŪŪ¾żßż┐ qż╬Ęų▓╝ż╦ż¬ż▒żļĮY║ŽĘų▓╝ż╬┤_┬╩ż╬īØ╩²ż“ūŅ┤¾ ╗»ż╣żļ ”╚(i+1) ż“Ū¾żßżļ ”╚(i+1) ż╦żĶżļė╚Č╚żŽ▒žż║ ”╚(i) ęį╔Žż╦ż╩żļż╚żżż”ż│ż╚żŽį^├„żĄżņżŲ żļżķżĘżż(źŲźŁź╣ź╚żŪżŽżĮż│ż▐żŪšh├„żĘżŲżżż╩żż)
- 30. 6.1.5 EMż╬└²
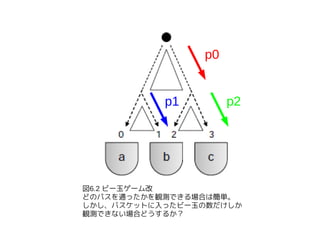
- 31. źė®`ė±å¢Ņ}ż╦EMż“▀mė├ż╣żļ x Ī╩ {a,b,c}, y Ī╩ {0,1,2,3} ż╚żĘżŲ EM źóźļź┤źĻź║źÓż“▀mė├ż╣żļ ż▐ż║ x ż╬ŽÓīØŅlČ╚żŽĪó ćĒ6.2ż½żķĪó├„żķż½ż╦ Pr(0|a)=1, Pr(3|c)=1 ż╩ż╬żŪėŗ╦Ń▓╗ę¬ĪŻ ▓ążĻż╬ y = {1,2} ż╦ż─żżżŲėŗ╦Ńż╣żļż╚Īó
- 33. ▓╬┐╝╬─Žū
- 34. 1. Facebook has the world's largest Hadoop cluster!, Facebook has the world's largest Hadoop cluster!, http://hadoopblog.blogspot.com/2010/05/facebook-has-worlds-largest- hadoop.html 2. źµ®`źŲźŻźĻźŲźŻź│ź¾źįźÕ®`źŲźŻź¾ź░, wikipedia, http://ja.wikipedia.org/wiki/ %E3%83%A6%E3%83%BC%E3%83%86%E3%82%A3%E3%83%AA %E3%83%86%E3%82%A3%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3 %83%BC%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0 3.Hadoop Ą┌1░µ, Tom White, ź¬źķźżźĻ®`?źĖźŃźčź¾, 2009 4.Simple-9ż╦ż─żżżŲĮŌšh ©C tsubosakaż╬╚šėø, http://d.hatena.ne.jp/tsubosaka/20090810/1249915586 5.Ī▒Į╠ĤżóżĻč¦┴ĢĪ▒, wikipedia, http://ja.wikipedia.org/wiki/%E6%95%99%E5%B8%AB %E3%81%82%E3%82%8A%E5%AD%A6%E7%BF%92 6. Ī░Į╠Ĥż╩żĘč¦┴ĢĪ▒, wikipedia, http://ja.wikipedia.org/wiki/%E6%95%99%E5%B8%AB %E3%81%AA%E3%81%97%E5%AD%A6%E7%BF%92 7.Ī▒EMźóźļź┤źĻź║źÓĪ▒, wikipedia, http://ja.wikipedia.org/wiki/EM %E3%82%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0
- 35. Thank you !