Model seminar shibata_100710
Download as ppt, pdf0 likes466 views

„â„Ç„ëĂă»á Soetaert and Herman "A practical guide to Ecological model" Chapter 4ĄĄParameter






![[198,] 10.435 1.60 209.633 [199,] 45.229 -1.60 -209.632 [200,] 5.284 12.12 -70.093 [201,] 10.435 1.60 209.632 [1,] 10.435 1.60 209.632 [2,] 10.435 1.60 209.633 [3,] 10.435 1.60 209.632 ??? ??? Ąû ±Ÿ (p125) €ÈÒ»Ÿw€Î łőÆÚ€Ź€€€ÈŽ_€«€ËÁŒ€Ż€Ê€€€è€Š€À 4. 4 „±©`„č„č„ż„Ç„Ł 4.4.1 P-I „«©`„Ö](https://image.slidesharecdn.com/modelseminarshibata100710-100713105047-phpapp02/85/Model-seminar-shibata_100710-8-320.jpg)

![sum(LL$residuals^2) [1] 0.1073133 sum(summary(fit)$residuals^2) [1] 0.08434943 ČĐČîÆœ·œș̀ϷǟĐλ۹€Î·œ€ŹĐĄ€”€«€Ă€ż ( œÌżÆű€Ï x ĘS€È y ĘS€ŹÄæÜ€·€Æ€Æ·ÇłŁ€ËҀˀŻ€€€Î€ÇĄąÙÊÖ€Ë䀚€Ț€·€ż .Appendix2) ŸĐ΄â„Ç„ë ( łà ) ·ÇŸĐÎ „â„Ç„ë ( Çà ) Žó€€Ê x €ÈĐĄ€”€Ê x €Ç ”±€Æ€Ï€Ț€ê€ËČî](https://image.slidesharecdn.com/modelseminarshibata100710-100713105047-phpapp02/85/Model-seminar-shibata_100710-10-320.jpg)







![minmod <- function(t, Carbon, parameters) { with(as.list(c(Carbon, parameters)), { minrate <- k*Carbon Depo <- approx(Flux[, 1], Flux[, 2], xout=t)$y dCarbon <- mult*Depo - minrate list(dCarbon, minrate) }) } rżÌ t €Ç€Î flux €òÓ뀚€Æ€€€ë costt <- sum((minrate- oxcon$cons)^2) Ą](https://image.slidesharecdn.com/modelseminarshibata100710-100713105047-phpapp02/85/Model-seminar-shibata_100710-22-320.jpg)

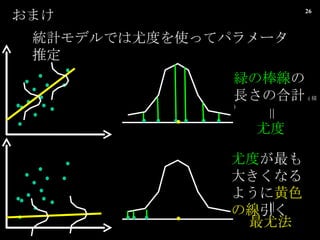
![Ő`Čî€òżŒ]€č€ë€ł€È€ÇĄą Č»Ž_gĐÔ€òÒ·e€â€ë €ł€È€Ź€Ç€€ë €Ș€Ț€±€Î€Ț€È€á Śîßmœâ€òŚ·€€Çó€á€ëÒÔÍâ€Î„ą„ë„Ž„ê„ș„à€Ç€âĄą ÍŹ€žœYŐ €Ë€Ê€ë ÈË”Ä€Ë€ÏĄą „Ń„é„á©`„ż€Ë€ÏŐ`Č€ą€ë€â€Î €È€·€ÆQ€Ă€Æ€Û€·€€ €ł€È€â€ą€ë ŹFg”Ä€ËoÀí€ÊöșÏ€Ź¶àĄ©€ą€ê€Ț€č€·](https://image.slidesharecdn.com/modelseminarshibata100710-100713105047-phpapp02/85/Model-seminar-shibata_100710-31-320.jpg)
Model seminar shibata_100710
- 1. Chapter 4 ĄĄșáäșčúÁąŽóѧĄĄ D1 ĄĄČńÌïÌ©ÖæĄĄ Parameterization
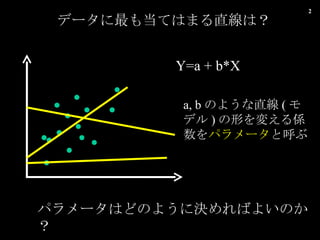
- 2. „Ç©`„ż€ËŚî€â”±€Æ€Ï€Ț€ëÖ±Ÿ€ÏŁż Y=a + b*X a, b €Î€è€Š€ÊÖ±Ÿ ( „â„Ç„ë ) €ÎĐ΀ò䀚€ëSÊę€ò „Ń„é„á©`„ż €Èșô€Ö „Ń„é„á©`„ż€Ï€É€Î€è€Š€ËQ€á€ì€Đ€è€€€Î€«Łż
- 3. ÊęÀí„â„Ç„ë€òșB€č€ë€Ë”±€ż€Ă€Æ€ÏĄą „Ń„é„á©`„ż€ä¶šÊꀏ±ŰÒȘ €œ€ì€é€ò”À뀿€á€Î·œ·š 4.1. Éú„Ç©`„ż €œ€Î€Ț€Ț 4.2. Éú„Ç©`„ż€ò äQ €·€Æ€«€é 4.3. Éú„Ç©`„ż€ò äQ €·€ÆĄą„â„Ç„ë€â ÔĐĐćeŐ`
- 4. 4.1. Éú„Ç©`„ż €œ€Î€Ț€Ț Śî€âÖ±œÓ”Ä (Y=X €Ê„â„Ç„ë ) ( ”±€ż€êÇ°€À€Ź ) „Ń„é„á©`„ż€ÏÍƶš€”€ì€ë€â€Î€Ç€ą€ë€ł€È€ËÁôÒâ 4.2. Éú„Ç©`„ż€ò äQ €·€Æ€«€é ÏÈĐĐŃĐŸż€ËŸ€Ă€ÆäQ ( ÊÂÀę€Ç€Ï log(Y)=log(X)) €·€«€·Ąą€œ€ÎäQ€Ź€€€Ä€Ç€âŚîÁŒ€È€ÏÏȚ€é€Ê€€
- 5. 4.3. Éú„Ç©`„ż€ò äQ €·€ÆĄą„â„Ç„ë€â ÔĐĐćeŐ` ÓQy€ÈÓèy€ÎČŚîĐĄ€Ë€Ê€ë€è€Š€ËĄą„Ń„é„á©`„ż€òŐ{Őû Öۀ߀ĀČĐČîÆœ·œșÍ error €ÏĄą i ·ŹÄż€Î„Ç©`„ż€ÎłÖ€Ä·ÖÉą€È€·€Æ€€€ë (i ·ŹÄż€Î„Ç©`„ż€Ï j €Î„Ç©`„ż€ÎÆœŸùQ€€ ) „Ç©`„ż¶à ->·ÖɹХ-> Cost Žó->€À€«€éĄą „ș„ì€Á€ă€À€á (AIC ”ĀˀÏ??? )
- 6. 4.3.1 ŸĐλ۹ »ù±ŸĐÎ ÖžÊę ÄæÊę ÖžÊę 2 ( œÌżÆű€Èß`€Š )
- 7. 4. 3. 2 ·ÇŸĐλ۹ ·ÇŸĐ΀ζšÁx€ÏŁż ŸĐ΀ǀʀ€€ł€È ŸĐ΄â„Ç„ë€Ë±È€ÙĄąŚî€â ModelCost €Î”Í€€”ă€ŹÒ€Ä€±€Ë€Ż€€€Î€ÇĄąłőÆÚ€ò䀚€ÆÔ€č±ŰÒȘ€ą€ê ±Ÿ”±€ËҀĀ±€Ë€Ż€€Łż ( Àę€Ï”±€Æ€Ï€á€ż€À€±€Ç€Ä€Ț€é€Ê€€€Î€ÇÙÊÖ€Ë ) łőÆÚ€òÂÒÊę€Ç䀚€Æ€ß€ż
- 8. [198,] 10.435 1.60 209.633 [199,] 45.229 -1.60 -209.632 [200,] 5.284 12.12 -70.093 [201,] 10.435 1.60 209.632 [1,] 10.435 1.60 209.632 [2,] 10.435 1.60 209.633 [3,] 10.435 1.60 209.632 ??? ??? Ąû ±Ÿ (p125) €ÈÒ»Ÿw€Î łőÆÚ€Ź€€€ÈŽ_€«€ËÁŒ€Ż€Ê€€€è€Š€À 4. 4 „±©`„č„č„ż„Ç„Ł 4.4.1 P-I „«©`„Ö
- 9. 4.4.2 ŸĐ΄â„Ç„ë vs ·ÇŸĐ΄â„Ç„ë P126 €Î (4. 10) Êœ€òŸĐ΄â„Ç„ë€È·ÇŸĐ΄â„DŽ륹I·œ€Ç„Ń„é„á©`„żÍƶš€·€Ț€č ((4.10) Êœ€Î§łö€Ï Appendix 1) ŸĐ΄â„Ç„ë €Î„â„Ç„ëÊœ ·ÇŸĐ΄â„Ç„ë €Î„â„Ç„ëÊœ €ÈÖĂ€Ż €ż€À€·
- 10. sum(LL$residuals^2) [1] 0.1073133 sum(summary(fit)$residuals^2) [1] 0.08434943 ČĐČîÆœ·œș̀ϷǟĐλ۹€Î·œ€ŹĐĄ€”€«€Ă€ż ( œÌżÆű€Ï x ĘS€È y ĘS€ŹÄæÜ€·€Æ€Æ·ÇłŁ€ËҀˀŻ€€€Î€ÇĄąÙÊÖ€Ë䀚€Ț€·€ż .Appendix2) ŸĐ΄â„Ç„ë ( łà ) ·ÇŸĐÎ „â„Ç„ë ( Çà ) Žó€€Ê x €ÈĐĄ€”€Ê x €Ç ”±€Æ€Ï€Ț€ê€ËČî
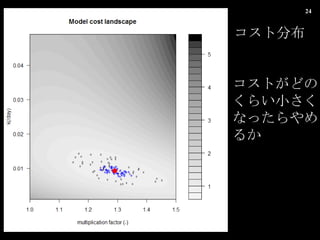
- 11. 4.4.3 ÒÉËÆÂÒÊę€Ë€è€ë„Ń„é„á©`„żÌœËś ÊÖí 1. €ż€Ż€”€ó€Î„Ń„é„á©`„żșòŃa€ò°kÉú€”€»€ë 2. €œ€ì€é€Î„Ń„é„á©`„ż€òÊč€Ă€ż ModelCost €òÓËă 3. „Ń„é„á©`„ż€ò€€€Ż€Ä€«ßx€ó€Ç€œ€ÎÆœŸù€òÓËă 4. €â€ŠÒ»€Äe€Î„Ń„é„á©`„ż€òßx€ó€ÇĄą€œ€ì€òĘS€ËłÆ€Ë€ą€ë„Ń„é„á©`„ż€òßxk 5. €œ€Î„Ń„é„á©`„ż€Î ModelCost €ŹÒ»·Ź€€ ModelCost €è€êĐĄ€”€±€ì€Đńk
- 12. Àę (p133 €Î€ä€Ä€Ï„ł©`„É€òŽò€Æ€Đ€Ç€€ë€Î€Ç ) Y = a + bX €Î„Ń„é„á©`„ż a €È b €òÍƶš€·€Æ€ß€ë (Appendix3) 1. €ż€Ż€”€ó€Î„Ń„é„á©`„żșòŃa€ò°kÉú€”€»€ë a2 <- runif(100, 0, 10) b2 <- runif(100, 0, 10) 2. €œ€ì€é€Î„Ń„é„á©`„ż€òÊč€Ă€ż ModelCost €òÓËă €ł€ÎöșÏĄą 100 €Î ModelCost €ŹÓË〔€ì€ë a <- 5 b <- 3
- 13. 3. „Ń„é„á©`„ż€ò€€€Ż€Ä€«ßx€ó€Ç€œ€ÎÆœŸù€òÓËă a_mean <- mean(sample(a2, 3)) 4. €â€ŠÒ»€Äe€Î„Ń„é„á©`„ż€òßx€ó€ÇĄą€œ€ì€òĘS€ËłÆ€Ë€ą€ë„Ń„é„á©`„ż€òßxk ( Àꀚ€ĐĄą a_mean €Ź 5 €À€Ă€ż€È€·€ÆĄą a_mirror €Ź 3 €À€È€č€ë€ÈĄą 2*5-3=7 €È€Ê€êĄą 3 €òÖĐĐĀ˔Ȁ·€€Ÿàëx (2) €À€±ÒÆÓ€·€ż€ł€È€Ë€Ê€ëĄŁŸÖËùœâ€Ë„È„é„Ă„Ś€”€ì€Ê€€č€·ò€À€ÈËŒ€ï€ì€ë ) a_mirror <- sample(a2, 1) new_a <- 2*a_mean - a_mirror 5. €œ€Î„Ń„é„á©`„ż€Î ModelCost €ŹÒ»·Ź€€ ModelCost €è€êĐĄ€”€±€ì€Đńk Śîßmœâ€À€±Çó€á€è€Š€È€·€Æ€€€ë€ł€È€ËÁôÒâ
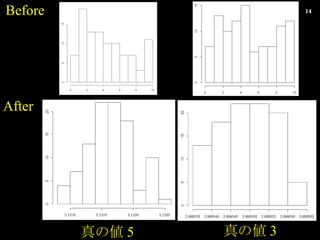
- 14. Őæ€Î 5 Őæ€Î 3 Before After
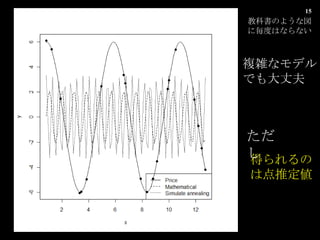
- 15. Ń}ëj€Ê„â„Ç„ë€Ç€âŽóŐÉ·ò ”Ă€é€ì€ë€Î€Ï”ăÍƶš €ż€À€· œÌżÆÊé€Î€è€Š€Êí€Ë°¶È€Ï€Ê€é€Ê€€
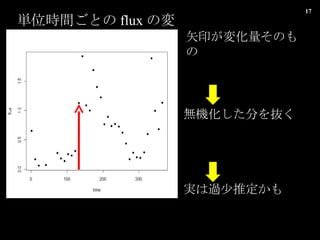
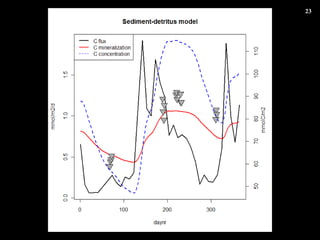
- 16. 4.4.4 ĄĄÏȀۀɀ΄ą„ë„Ž„ê„ș„à€òÊč€Ă€ÆĄąÎą·Ö·œłÌÊœ ĄĄĄĄĄĄĄĄ€Î„Ń„é„á©`„żÍƶš http://geos.ees.hokudai.ac.jp/noriki/Trap.html „»„ž„á„ó„È„È„é„Ă„Ś șŁËźÖĐ€òÉòœ”€č€ëÁŁŚÓ€òŒŻ€á€ëŚ°ÖĂ œń»Ű€ÏĄą ÓĐCÌżËŰ€Ź€É€Î€è€Š€ËoCÌżËŰ€ËÊŻ»Ò»Ż€·€Æ€€€Ż€Î€«„â„Ç„ê„ó„° €·€Æ€ß€ë ÓĐC?oCÌżËŰÁż ( flux ) ËáËŰÏûÙMÁż ( oxycon ) ÉÏÓ€ÎrégĘS < ÊÖłÖ€Á€Î„Ç©`„ż€Ï 3 €Ä >
- 17. gλrég€Ž€È€Î flux €Î仯 ÊžÓĄ€Źä»ŻÁż€œ€Î€â€Î oC»Ż€·€ż·Ö€òi€Ż g€Ïß^ÉÙÍƶš€«€â
- 18. „Ń„é„á©`„żÍƶš€ÎÁś€ì 1. ÓQy€ÈÎą·Ö·œłÌÊœ€«€é€ÎÓèy€ÎČî€òŚîĐĄ€Ë€č€ë€è€Š€Ë„Ń„é„á©`„ż k, mult €òÍƶš€č€ë .flux €Î€Ï offset €Î€è€Š€ËÖƔĀËÓ뀚€ż 2. ”Ă€é€ì€ż„Ń„é„á©`„ż€ÇĄą€â€ŠÒ»¶ÈÎą·Ö·œłÌÊœ €Ë”±€Æ€Ï€á€ë 3. Óèy€ò„Ś„í„Ă„È€·€Æ€ß€ÆĄągëH€Î€â€Î€ÈșÏ€Ă €Æ€€€ë€«Ž_ŐJ
- 19. €Á€ç€Ă€ÈŐhĂśŁș R €ÇÎą·Ö·œłÌÊœ ode évÊę (Ordinary differential equation) €òÊčÓĂ ode( łőÆÚĄąrégĄąÎą·Ö·œłÌÊœĄą„Ń„é„á©`„ż ) < ÓĂ·š > Àę : ÌćÈșŒÓ„â„Ç„ë€òœâ€€€Æ€ß€ë (Appendix 4) N €ÏÌćÊꥹ r €ÏŒÓÂÊĄą K €ÏhŸł §ÈĘÁŠ „í„ž„č„Æ„Ł„Ă„Ż„â„Ç„ë
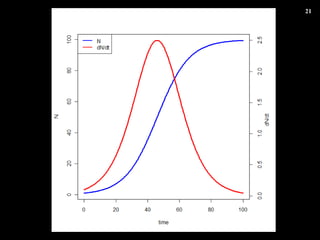
- 20. Growth_model <- function ( t , state, pars) { with (as.list(c(state, pars)), { dN <- r * N *(K - N)/K return(list(dN, r * N *(K - N)/K))}) } pars <- c(r=0.3, K=100) ini <- c(N=1) times <- seq(0, 100) out <- as.data.frame(ode(func= Growth_model , y= ini , parms= pars , times= times )) Îą·Ö·œłÌÊœŚśłÉ łőÆÚ€È„Ń„é„á©`„ż Îą·Ö·œłÌÊœœâ€«€»€ë
- 22. minmod <- function(t, Carbon, parameters) { with(as.list(c(Carbon, parameters)), { minrate <- k*Carbon Depo <- approx(Flux[, 1], Flux[, 2], xout=t)$y dCarbon <- mult*Depo - minrate list(dCarbon, minrate) }) } rżÌ t €Ç€Î flux €òÓ뀚€Æ€€€ë costt <- sum((minrate- oxcon$cons)^2) Ą
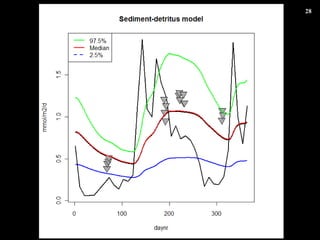
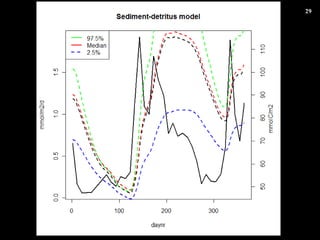
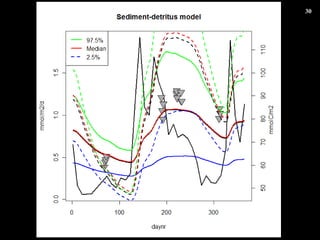
- 25. ”ÚËÄŐ€΀Ț€È€á ŸĐλ۹€È·ÇŸĐλ۹ €òœBœé€·€ż ·ÇŸĐλ۹€Î łőÆÚÒÀŽæ €ÎŚÓ€òÊŸ€·€ż „ł„č„È€ò€ą€é€«€ž€áÓË〷€ÆĄą ÁŒ€”€œ€Š€Ê„Ń„é„á©`„ż€«€é„č„ż©`„È €č€ëÖŰÒȘĐÔ€ÎÊŸËô „ß„é©`évÊę (Price évÊę ) €Ç„Ń„é„á©`„żÍƶš€č€ë€ł€È€ÎÓĐżĐÔ€ÎÊŸËô
- 26. €Ș€Ț€± œyÓ„â„Ç„ë€Ç€ÏÓȶȀòÊč€Ă€Æ„Ń„é„á©`„żÍƶš Ÿv€Î°ôŸ €ÎéL€”€ÎșÏÓ ( ·e ) ÓÈ¶È ÓÈ¶È €ŹŚî€âŽó€€Ż€Ê€ë€è€Š€Ë »ÆÉ«€ÎŸ Òꀯ ŚîÓÈ·š Łœ Łœ
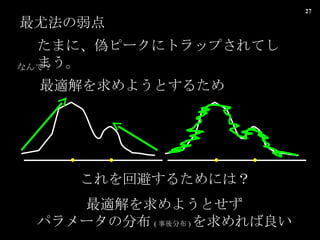
- 27. ŚîÓÈ·š€ÎÈő”ă €ż€Ț€ËĄąÎ„Ô©`„Ż€Ë„È„é„Ă„Ś€”€ì€Æ€·€Ț€ŠĄŁ €ł€ì€ò»Ű±Ü€č€ë€ż€á€Ë€ÏŁż Śîßmœâ€òÇó€á€è€Š€È€č€ë€ż€á €Ê€ó€ÇŁż Śîßmœâ€òÇó€á€è€Š€È€»€ș „Ń„é„á©`„ż€Î·ÖČŒ ( ÊÂáá·ÖČŒ ) €òÇó€á€ì€ĐÁŒ€€
- 31. Ő`Čî€òżŒ]€č€ë€ł€È€ÇĄą Č»Ž_gĐÔ€òÒ·e€â€ë €ł€È€Ź€Ç€€ë €Ș€Ț€±€Î€Ț€È€á Śîßmœâ€òŚ·€€Çó€á€ëÒÔÍâ€Î„ą„ë„Ž„ê„ș„à€Ç€âĄą ÍŹ€žœYŐ €Ë€Ê€ë ÈË”Ä€Ë€ÏĄą „Ń„é„á©`„ż€Ë€ÏŐ`Č€ą€ë€â€Î €È€·€ÆQ€Ă€Æ€Û€·€€ €ł€È€â€ą€ë ŹFg”Ä€ËoÀí€ÊöșÏ€Ź¶àĄ©€ą€ê€Ț€č€·
Editor's Notes
- #2: €œ€ì€Ç€Ï€è€í€·€Ż€ȘÔž€€€·€Ț€čĄŁ±ŸŃĐŸż€Ç€ÏĄążŐŒä„â„Ç„ë€È€€€ŠÊÖ·š€ŹËźČúÉúÎï€ÎŚÊÔŽÁżÍƶš·š€È€·€Æ€É€ÎłÌ¶È€ÎĐÔÄÜ€ò°k»Ó€č€ë€Î€«Ąą±ÈœÏÊÌÖ€·€żŃĐŸż€ò€ŽÉܜ退€ż€·€Ț€čĄŁ