

![Autonomous Systems Laboratory
3/21
DQN to DDPG: DQN algorithm
Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
? DQN is capable of human level performance on many Atari games
? Off policy training: replay buffer breaks the correlation of samples that are sampled from agent
? High dimensional observation: deep neural network can extract feature from high dimensional input
? Learning stability: target network make training process stable
Environment Q Network
Target
Q Network
DQN Loss
Replay buffer
?????? ? ?(??, ? ?; ?)
??
Update
Copy
?(??, ? ?; ?)
store
(??, ? ?, ??, ??+1)
??
??+1(??, ? ?)
??? ? ?(??
Īõ
, ? ?; ?Īõ)
? ??, ? ? Ī¹ ? ??, ? ? + ?[??+1 + ???? ? ? ??+1, ? ?+1 ? ? ??, ? ? ]
Q learning
? ? ?
??, ? ? Ī¹ ? ? ?
??, ? ? + ?[??+1 + ???? ? ? ? ?Īõ
??+1, ? ?+1 ? ? ? ?
??, ? ? ]
DQN
Policy(?): ? ? = ?????? ? ? ? ?
(??, ? ?)??: state
? ?: action
??: reward
?(??, ? ?): reward to go](https://image.slidesharecdn.com/ddpgseminar-200605011914/85/ddpg-seminar-3-320.jpg)
![Autonomous Systems Laboratory
4/21
DQN to DDPG: Limitation of DQN (discrete action spaces)
? Discrete action spaces
- DQN can only handle discrete and low-dimensional action spaces
- If the dimension increases, action spaces(the number of node) increase exponentially
- i.e. ? discrete action spaces with ? dimension -> ? ?action spaces
? DQN cannot be straight forwardly applied to continuous domain
? Why? -> 1. Policy(?): ? ? = ?????? ? ? ? ?
(??, ? ?)
2. Update: ? ? ?
??, ? ? Ī¹ ? ? ?
??, ? ? + ?[??+1 + ???? ? ? ? ?Īõ
? ?+?, ? ?+? ? ? ? ?
??, ? ? ]
Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).](https://image.slidesharecdn.com/ddpgseminar-200605011914/85/ddpg-seminar-4-320.jpg)






![Autonomous Systems Laboratory
11/21
Policy gradient: DPG
Silver, David, et al. "Deterministic policy gradient algorithms." 2014.
? Deterministic policy gradient (DPG) models the actor policy as a deterministic decision: ?t = ? ?(?t)
1. Sample ??, ? ?, ??, ??+1 from ? ?(?) ? times
2. Update ? ?(??, ? ?) to samples
3. ?? ?(?) Īų ”ę? ?? ? ? ?? ? ? ? ?(??, ? ?)| ? ?=? ?(? ?)
4. ? Ī¹ ? + ??? ?(?)
? ? ?1,?1,?,? ?,? ?
= ?(?1) ?
?=1
?
? ? ? ? ?? ?(??+1|??, ? ?)
trajectory distribution
? ? ?1,?2,?3?,? ?
= ?(?1) ?
?=1
?
?(??+1|??, ? ?(??))
? ? = ??,?~? ?(?) ? ?(??, ? ?)
objective
? ?
? ? = ??~? ?(?)[?(?, ? ? ? )]
loss: ? = ?? + ?? ? ??+1, ? ?(??+1) ? ? ?(??, ? ?)](https://image.slidesharecdn.com/ddpgseminar-200605011914/85/ddpg-seminar-11-320.jpg)






































More Related Content
What's hot (20)
Similar to ddpg seminar (20)


















Recently uploaded (20)




















ddpg seminar
- 1. CONTACT Autonomous Systems Laboratory Mechanical Engineering 5th Engineering Building Room 810 Web. https://sites.google.com/site/aslunist/ Deep deterministic policy gradient Minjae Jung May. 19, 2020
- 2. Autonomous Systems Laboratory 2/21 DQN to DDPG: DQN overview Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533. Q learning DQN (2015) 1. replay buffer 2. neural network 3. target network
- 3. Autonomous Systems Laboratory 3/21 DQN to DDPG: DQN algorithm Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533. ? DQN is capable of human level performance on many Atari games ? Off policy training: replay buffer breaks the correlation of samples that are sampled from agent ? High dimensional observation: deep neural network can extract feature from high dimensional input ? Learning stability: target network make training process stable Environment Q Network Target Q Network DQN Loss Replay buffer ?????? ? ?(??, ? ?; ?) ?? Update Copy ?(??, ? ?; ?) store (??, ? ?, ??, ??+1) ?? ??+1(??, ? ?) ??? ? ?(?? Īõ , ? ?; ?Īõ) ? ??, ? ? Ī¹ ? ??, ? ? + ?[??+1 + ???? ? ? ??+1, ? ?+1 ? ? ??, ? ? ] Q learning ? ? ? ??, ? ? Ī¹ ? ? ? ??, ? ? + ?[??+1 + ???? ? ? ? ?Īõ ??+1, ? ?+1 ? ? ? ? ??, ? ? ] DQN Policy(?): ? ? = ?????? ? ? ? ? (??, ? ?)??: state ? ?: action ??: reward ?(??, ? ?): reward to go
- 4. Autonomous Systems Laboratory 4/21 DQN to DDPG: Limitation of DQN (discrete action spaces) ? Discrete action spaces - DQN can only handle discrete and low-dimensional action spaces - If the dimension increases, action spaces(the number of node) increase exponentially - i.e. ? discrete action spaces with ? dimension -> ? ?action spaces ? DQN cannot be straight forwardly applied to continuous domain ? Why? -> 1. Policy(?): ? ? = ?????? ? ? ? ? (??, ? ?) 2. Update: ? ? ? ??, ? ? Ī¹ ? ? ? ??, ? ? + ?[??+1 + ???? ? ? ? ?Īõ ? ?+?, ? ?+? ? ? ? ? ??, ? ? ] Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
- 5. Autonomous Systems Laboratory 5/21 DDPG: DQN with Policy gradient methods Q learning DQN 1. replay buffer 2. deep neural network 3. target network Policy gradient (REINFORCE) Actor critic DPG DDPG Continuous action spaces Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
- 6. Autonomous Systems Laboratory 6/21 Policy gradient: The goal of Reinforcement learning ? ? ?1,?1,?,? ?,? ? = ?(?1) ? ?=1 ? ? ? ? ? ?? ?(??+1|??, ? ?) Agent World action ?(??+1|??, ? ?) model reward & next state ?? ? ? ??+1 state& ?? policy ?(? ?|??) ?? = ?????? ? ??~? ?(?) ? ? ? ??, ? ? Markov decision process ?1 ?1 ?2 ?2 ?3 ?(?2|?1, ?1) ?(?3|?2, ?2) ?3 ?(?4|?3, ?3) ? objective: ?(?) trajectory distribution Goal of reinforcement learning policy(? ?): stochastic policy with weights ?
- 7. Autonomous Systems Laboratory 7/21 Policy gradient: REINFORCE ? REINFORCE models the policy as a stochastic policy: ? ? ~ ? ?(? ?|??) Sutton, Richard S., et al. "Policy gradient methods for reinforcement learning with function approximation." Advances in neural information processing systems. 2000. ?? ? ?(? ?|??) probability 0.1 0.1 0.2 0.2 0.4
- 8. Autonomous Systems Laboratory 8/21 Policy gradient: REINFORCE ? ? = ??~? ?(?) ? ? ? ??, ? ? ?? ? =??~? ?(?) ( ”ę ?=1 ? ?? ??? ? ?(? ?|??) (”ę ?=1 ? ?(??, ? ?)) ?? ? Īų 1 ? ? ?=1 ? ? ?=1 ? ?? ??? ? ?(? ?|??) ? ?=1 ? ?(??, ? ?) ? Ī¹ ? + ???(?) The number of episodes problem Must experience some episodes to update 1. Slow training process 2. High gradient variance initial state ?1 ?2 ? ? ? REINFORCE models the policy as a stochastic decision: ? ? ~ ? ?(? ?|??) Sutton, Richard S., et al. "Policy gradient methods for reinforcement learning with function approximation." Advances in neural information processing systems. 2000. ?: weights of actor network ?: learning rate
- 9. Autonomous Systems Laboratory 9/21 Ī· ? ?(??, ? ?) Policy gradient: Actor critic (actor critic) ? Actor(? ?(? ?|??)): output action distribution by policy network and updates in the direction suggested by critic ? Critic(? ?(? ?, ? ?)): evaluate actorĪ»s action initial state sample data ? times update critic & actor sample data ? times update critic & actor 1. Sample ??, ? ?, ??, ??+1 from ? ?(? ?|??) ? times 2. Update ? ?(??, ? ?) to sampled data 3. ?? ?(?) Īų ”ę? ????? ? ? ? ?? ? ?(??, ? ?) 4. ? Ī¹ ? + ??? ?(?) Konda, Vijay R., and John N. Tsitsiklis. "Actor-critic algorithms." Advances in neural information processing systems. 2000. ?: weights of critic network 1. High gradient variance 2. Slow training policy ? ?(? ?|??) ? ?(??, ? ?) Env.? ? ?? (??, ? ?, ??, ??+1)0~???(?) actor critic update critic
- 10. Autonomous Systems Laboratory 10/21 Policy gradient: DPG Silver, David, et al. "Deterministic policy gradient algorithms." 2014. ? Deterministic policy gradient (DPG) models the actor policy as a deterministic policy: ?t = ? ?(?t) ? ? ? ? Stochastic policy ? ?(? ?|??) ?? ? Need 10 action spaces for 5 discretized 2 dimensional actions ? ? ? ? Deterministic policy ? ?(? ?) ?? ? Only 2 action spaces are needed
- 11. Autonomous Systems Laboratory 11/21 Policy gradient: DPG Silver, David, et al. "Deterministic policy gradient algorithms." 2014. ? Deterministic policy gradient (DPG) models the actor policy as a deterministic decision: ?t = ? ?(?t) 1. Sample ??, ? ?, ??, ??+1 from ? ?(?) ? times 2. Update ? ?(??, ? ?) to samples 3. ?? ?(?) Īų ”ę? ?? ? ? ?? ? ? ? ?(??, ? ?)| ? ?=? ?(? ?) 4. ? Ī¹ ? + ??? ?(?) ? ? ?1,?1,?,? ?,? ? = ?(?1) ? ?=1 ? ? ? ? ? ?? ?(??+1|??, ? ?) trajectory distribution ? ? ?1,?2,?3?,? ? = ?(?1) ? ?=1 ? ?(??+1|??, ? ?(??)) ? ? = ??,?~? ?(?) ? ?(??, ? ?) objective ? ? ? ? = ??~? ?(?)[?(?, ? ? ? )] loss: ? = ?? + ?? ? ??+1, ? ?(??+1) ? ? ?(??, ? ?)
- 12. Autonomous Systems Laboratory 12/21 DDPG: DQN + DPG Q learning DQN Policy gradient (REINFORCE) Actor critic DPG DDPG + continuous action spaces - no replay buffer: sample correlation - no target network: unstable - high variance + lower variance + off policy: replay buffer + stable update: target network + high dimensional observation spaces - discrete action spaces - low dimensional observation spaces Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
- 13. Autonomous Systems Laboratory 13/21 DDPG: algorithm(1/2) Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015). ? policy ? exploration ? Add noise for exploration: white Gaussian noise ? soft target update ? Target network is constrained to change slowly ? Stabilize training process ? = ?????? ? ? ? ? (?, ?) ? = ? ?(?) ?Īõ ? = ? ? ? + ? ?Īõ Ī¹ ?? + ? ? ? ?Īõ where ? ? ?
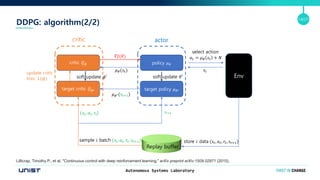
- 14. Autonomous Systems Laboratory 14/21 soft update ?Īõ DDPG: algorithm(2/2) Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015). policy ? ? target policy ? ?Īõ critic ? ? target critic ? ?Īõ ? ? = ? ? ?? + ? Env actorcritic ?? Replay buffer store ? data (??, ? ?, ??, ??+1)sample ? batch (??, ? ?, ??, ??+1) ? ?Īõ(??+1) update critic loss: ?(?) soft update ?Īõ ? ?(??) ??(?) select action ??+1(??, ? ?, ??)
- 15. Autonomous Systems Laboratory 15/21 DDPG example: landing on a moving platform Rodriguez-Ramos, Alejandro, et al. "A deep reinforcement learning strategy for UAV autonomous landing on a moving platform." Journal of Intelligent & Robotic Systems 93.1-2 (2019): 351-366.
- 16. Autonomous Systems Laboratory 16/21 DDPG example: long-range robotic navigation Faust, Aleksandra, et al. "PRM-RL: Long-range robotic navigation tasks by combining reinforcement learning and sampling-based planning." 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018. ? DDPG used as local planner for long range navigation
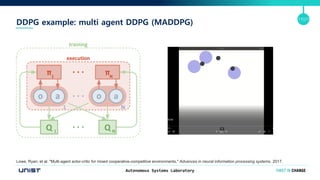
- 17. Autonomous Systems Laboratory 17/21 DDPG example: multi agent DDPG (MADDPG) Lowe, Ryan, et al. "Multi-agent actor-critic for mixed cooperative-competitive environments." Advances in neural information processing systems. 2017.
- 18. Autonomous Systems Laboratory 18/21 Conclusion & Future work ? DQN have problem to adjust continuous action space directly ? DDPG is able to consider continuous action spaces via policy gradient method and actor critic architecture ? MADDPG for multi agent RL ? Use DDPG for continuous action space decision making problem ? ex) navigation, obstacle avoidance
- 19. Autonomous Systems Laboratory 19/21 Appendix: Objective gradient derivation objective gradient
- 20. Autonomous Systems Laboratory 20/21 Appendix: DPG objective
- 21. Autonomous Systems Laboratory 21/21 Appendix: DDPG algorithm