




























![[RLkorea] ??? ??? ??](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-robotarm-190303021332-thumbnail.jpg?width=560&fit=bounds)







More Related Content
What's hot (20)
Similar to Soft Actor-Critic Algorithms and Applications ??? ?? (20)


















Soft Actor-Critic Algorithms and Applications ??? ??
- 1. Soft Actor-Critic Algorithms and Applications Goals ? ??? "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor" ??? ?????, continuous action space ???? ???? off-policy ??? ?? SAC? ?????. ?? ??? ??? ????. 1. Off-policy ????? ?? sample inefficiency ?? On-policy ????? ?? ????? ??? ???? ?? ?? ?? ??? policy?? ??? ?? ?? ??? ?? ??? ???? ?? ?? ??? ??? ????. 2. Objective? Entropy term? ??? ?? near-optimal policy ??? exploration ?? ?? Policy? ????? ??? ?? ??? ??? ?? ?????? ?? action? ??? ??? ? ???. ? action? ??? ?? ??? ? ????? ??? ?? ????. ??? ???? ? ????? ???? objective? ???? ? ??? action? ???? ? ???, ? ?? exploration? ??? ? ????. ? ?? ???? optimal action? ?? ?? ??? ?? sub-optimal action? ?? ? ?? action? ?? ????? ?? sub-optimal solution ?? ?? ??? ? ??? ???. ?? ? ?? ??? ??? ?? ?? optimal solution? ???? ???? ?? ? ???, sub-optimal solution? ? ?????? ??? ??? ??? Agent? ??? ????? ? robust?? ?? ?? ??? ? ????. 3. ?? ???? ??????? ???? Robust?? ??? ? ??? Entropy Coefficient ?? ?? ?? SAC ????? ?? Entropy term? ??? ? ??? Reward-based objective? Entropy ? ???? Entropy term? ???????? ??? ??? ??????, ? ??????? ? ?? ??? ?? ??? ??? ??????. ??? ????? ??????? ? ?? ?? ???? ??? ???????. ??? ?? ??? ????. (1)? (2)? ?? SAC? ????? ? ? ?? Soft Q-learning?? ?? ??? ?????. ?? ? ?? Differences?? SAC? SQL ?? ?? ?? ??? ??? ? ? ????. ??? ??? ??? ???? ????? ?????. Differences ? ??? ??? ?? ??? ?? ?? ??? ????????. ?? ??? ? ???? ?? ?? ?? Method? ??? ? ?? ??? ?? ? ???? ?? ????. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor https://arxiv.org/abs/1801.01290
- 2. Goals?? ??? ?? ?? ?? SAC??? ????? ???? ???????? ????, ? ? ?? ????? ?? ????? ????? ??? ?????. ??? ??? Method? Automating Entropy Adjustment ???? ???????. Reinforcement Learning with Deep Energy-Based Policies (Soft Q-learning, SQL) https://arxiv.org/abs/1702.08165 SAC? ?? ???? ? ? ?? ?????. SQL? ??? ??? ???? ??? ????. ? ???? ??? ???? ?, ? ???? policy? ???? ?? policy? maximum-entropy RL objective? optimal solution? ???. ?, ??? ?? ???? ???. ?? ?? Q-learning? ???? ?? ??? ?? ???, maximum-entropy RL objective? ?? optimal Q ??? ??? ? ????. (2)? ?? ???? ??? ?? ?? ?? bellman equation ?? max ? softmax ? ?? ?? ? ? ????. ? Soft bellman equation? ?? bellman equation?? contraction operator??, optimal Q ??? ?? ?? ????? ??? Q-learning? ?? ???? ??? ???? optimal Q ??? ? ? ? ????. ? ??? ??? ??? ??? ? ????? ???. SAC? ????? ?? ??? Actor-Critic ??? ??? ????. Objective? ???? ?? ?? ??? ???? ??? ?????, SAC? SQL? ?? ??? ??? ? ????. 1. Q-learning?? Soft Q-learning??? Optimal Q, Optimal V ??? ???? ???. ? ?? ? ? ???? (soft)max operator? expectation? ? ? ???? ???, ??? ?? ??? biased estimation? ???(??? Double Q-learning? ??? ????? ???) 1 . ??? SAC??? ?? policy? Q, V ??? ???? ???? ??? (soft)max operator? ? ??? ??, ??? sampling??? ???? bias? ???? ?? ? ???? ??? ??? ? ????. 2. SQL? policy? ?? ????? ?? exp Q ? ??? ??? ?????, ?? intractable?? ??? ? ???? action? sampling?? ?? MCMC? Stein variational gradient descent? ? ? ???? ??? ?????. ?? SAC? policy? ????? ???? function approximator? ???? ??? ?? ?? ???? ????, ??????? ??? ?? ?? ?. SQL? ???? ? SAC? ????? ????? ?? ??? ??? ???? Actor-Critic ??? ??? ?? ?? ? ? ????. ?? Policy Gradients & DQN ?? (A3C, ACER, Q-learning, ...) ?? Exploration? ??? ?? Entropy? ????? ???? ??? SQL?? SAC?? ?? ?? ?? ????. 2016??? ?? ??? A3C? ??? policy? negative entropy? loss?? ??? ? ???? exploration? ? ??? ???? ????. A3C? ?? on-policy ????? (behavior policy? target policy? ???? ??? on-policy ??? ????) -greedy? ?? ??? ? ??
- 3. ???, ?? ?????? ? ???? ????? ??? ????? ?? ???? ???? 2 . ? ? SAC? ?? ???? ??? regularization?? ??? ?? ???, ?? objective? ???? ? ? ???? ??? ??? ????. ? ??? ??? ????, ??? policy gradient ????? policy improvement? 1. initial state? value? objective? ?? 2. ?? ????? ??? ?????? estimation? 3. ?? ?????? ??? ????? ?? ?? ??????, ?? (2)? ???? "????? ???? state-action pair? ?? ?? action? target policy? ??? ??? ??" ?? ??? ?? ??? ?? ???? ???? ??? importance sampling ?? ?? ?? ??? ?????. ? ? ???? ratio ?? ??? ??? ?? ? ??? ?????? ??? ?? ???? ?? bound ??? ? ?? ??? ??? off-policy ? ????? ??? ? ????. ??? SAC? ?? policy improvement ??? 1. ?? policy? ?? Q ??? estimation? ???? policy? exp Q? ???? ???? ???? improvement? ?????, ????? ??? Q ??? ??? ??? Q-learning? ??? off-policy ???? 3 ?? ???? ??? ???? ?? ?? ?? ????? off-policy ????? ???. ??? ?? ???? ?? off-policy policy gradient ??? ?? ? ?? ????. Method ? ??? ??? ?? 1. ??? ?? ???? 2. Tabular ????? ?? 3. ?? ???? Practical?? ??? ? ?? ?? 4. Entropy coefficient ??????? ?? ?? ??? ??? ?????? ?????. ????? ????? ??, ?? ????? ?? notation? ?? ??? ?? ???????. ? ?? notation? ???, ?? ? ??? ? state? state-action? marginal distribution ???. ? ?? ??? ? ? ?? ???? ? ????? ??? ? ?? t?? ??? ??? ???? ????. ???? ?? ????? objective? ??? ??? ? ????? ???, ?? ?? ??? ???? ?? ??? ?? ???? policy ? ????? ???. ??? policy? ????? ?????? ??? ??? ?? Maximum entropy objective? ????. ?? ???? ???? ??? ????. ??? ? ????? ???? ???? ????, ? ??? ????? ??? ???? ?? ?? ??????????. ???? ??? ???? ????? ??? ?? ??? ????.
- 4. 1. ?? ?? ??? ????? ????? ???? ??? Exploration? ? ??????. ?? ? ?? ?? ???? ??? ?? ??? ?? ?? ??? ??? ??? ????. 2. Q-learning?? ??? ??? ???? ?? ???? near-optimal policy? ?? ??, ?? ? ??? near-optimal action ??? ?? ???? ???. Maximum entropy objective? optimal policy? exp Q? ???? ?? ???? ????? ???? ???? 4 . ?? ??? ????? Exploration? ? ??? ?? ??? ????? ???. Soft Policy Iteration ?? ????? ?? objective? ???? policy? ??? ???? ???????. ??? ??? ??? ?? ?? tabular ??? ????? ?????. ???? ??? Policy Iteration???. ?? policy ? ?? Soft Q ?? ? ???? Policy Evaluation ???, ??? ? ???? ?? ? ?? ??? policy ? ?? ?? ??? optimal policy ? ?? ???. ? ??? ?? Q-learning? ?? ??? ??????. Bellman backup operator ? ????, ? ?? ? ???? ? ? ????. ??? ?? optimal value function? ?? ?? policy? ?? value function ??? ?? ?? ?????. ??? log ?? ?? ??? ???? ?? Expectation ?? log ?? ? ? ????. ?? ? ???? ? (5)? ????? ?? ???? ? ?? Soft Q function? ?? ? ???? 5 . ? ? ??? policy ? ? ???? ????? ??? ???, SQL?? ???? ?? ? ?? ?? exp Q ? ???? ??? intractable ???. ?? ??? ?? ??? ?? policy parametrization space? exp Q? projection ? ??? ? ???? ?? ???? ??? ? ?? ??. ?? ?? ??? KL Divergence? ???? ??? ?? ???. ??? ? ??? ?? normalization term??, ???? intractable ? ???? ??? Gradient Descent? ? ????? ?? ???? ?? ??? intractable ??? ??? ??? ? ????. ??? ??? exp Q ??? ???, exp Q? ???? ??? tractable? ?? ???? ?? projection?? ??? ??? ?? ??? policy ? ?? policy ?? ??? ? 6 ? ???? ??? ?? Policy Improvement? ?????? ?? ?????. ??? ???? ??? argmin operator? ????? KL div ?? ?? ? ?? ??? ?? ??, ???? ?? ???
- 5. ? ???? ????. ?? Evaluation? Improvement? ???? Optimal Policy? ?? ? ????. Soft Actor-Critic ??? ?? ????? ?? ???? ??? ???? ? ?? ????. Continuous action space ? ? ??? ?? state-action pair? ??? ? ??, discrete?? ?? evaluation? ???? ???? ?? improvement? ?? ?? ??? ???? ?????. ??? function approximtor? ?? Q ? ?? policy? ????, evaluation? improvement? ?? ???? ??? ??? ???? ?? ?? ? stochastic gradient descent? ?? ????? ???? ?????? ?? ????? ??? ? ???. Policy Evaluation, ? Q ??? ?? Optimization objective? ??? ????. ? DDPG? ?? ? moving average ???. (6)?? ?? ? ??? ??, ? expectation? ? ?? policy ?? ??? ? ? (6)? ?? ? ???? ??? ??? ? ????. ???? Replay Memory? ????? ? ? ??? ???? ?? ??? ??? ???? ???? ???. ? ?? ?? ??? ???? ?? ? ???. ? ?? ?? ?????? ??? SGD? ??? ? ????. ?? Policy Improvement? ??, KL Divergence ?? ??????. KL Divergence ?? ???? ? ?? ?? ??? ?? ? ????. 7 ??? policy ? ?? Optimization Objective? ??? ?? ??? ? ????. ????? ? Replay Memory?? ????? ? ?? policy?? ??? ??? ? ?? ?? ? ? ???? ??? SGD? ????? ? ? ????. ??? (10)? ?? ?? ??? ? ?? ?????? DDPG? ???? Objectvie? ???? ??? ??? ?, ? ??? ???? ? ???? SGD? ?? policy? ????? ??? ?? ????. ????? reparameterization trick? ??? ????? ?? action? ??? ? ? ???? ??? variance? ?? ?? ????. TD3? target policy smoothing? ??? ????? ? ? ????.
- 6. Automating Entropy Adjustment ???? ????? ???? ???? ? ? ???????? ????, ?? ????? ??? ???? ?? ?? ??? ??? ????? Policy? ???? ?? ??? ??? ??? ??? ? ?? ?? ?? ?? ?? ?????. ???? ?? ???? ?? Objective? ??? ??? constraint? ? ? contrained optimization problem?? ??? ???, ?? dual problem? ?? dual variable ? ?? ?? ???? ??? ?????. Constraint ?? ? ? ????? ??? ? ?? ? ????. ????? ?? ? ??? ? ? ?? policy ? Reward Objective? ?????? policy? ?? ???? ?? ? ? ????. ??? ??? ??? MDP ?? ???, ?? state? ???? ?? ? ???? policy? ? ??? policy? ?? ??? ?? ????. ?? state? ??? ???? ?? policy? ??? ????, ? ??? ????? ??? ?? ??? ?? objective? ??? ?? ??? ??? ? ????. ?? ??? ???? ?? ???? ?? ?? ??? ???? ????? ??? ?? ????? ?? ? ?????. ?? ? ?? ?? ?????. ??? constraint ? ???? dual problem? ??? ????. Dual problem? ? ??? ???? ???? ??? , if else ? ?? ? ???, ? ???? ?? ? ? ??? ??? ????? ???? ???? 8 . ?? Iterative ? ???? ??? ?? ? ?? ? ??? optimal policy ? ???, ?? ? ?? ? ??? optimal coefficient ? ?? ? ????. ?? ??? ????? ???? ?? step? ?? ???? ?? ?? ?? ?? ????? ???? ?? ? ? ????.
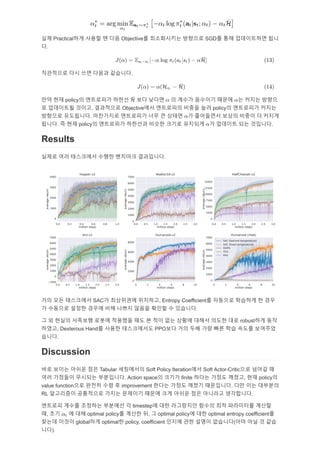
- 7. ?? Practical?? ??? ? ?? Objective? ?????? ???? SGD? ?? ?????? ?? ?. ????? ?? ?? ??? ????. ?? ?? policy? ????? ??? ?? ??? ? ??? ???? ??? ? ??? ??? ? ????? ???, ????? Objective?? ????? ??? ?? policy? ????? ??? ???? ?????. ????? ????? ?? ? ??? ? ????? ??? ??? ? ??? ???. ? ?? policy? ????? ???? ??? ??? ???? ? ???? ?? ????. Results ??? ?? ????? ??? ???? ?????. ?? ?? ????? SAC? ????? ????, Entropy Coefficient? ???? ???? ? ?? ? ???? ??? ??? ?? ??? ??? ??? ? ????. ? ? ??? ???? ??? ???? ?? ? ?? ?? ??? ??? ??? ?? robust?? ?? ???, Dexterous Hand? ??? ?????? PPO?? ?? ?? ?? ?? ?? ??? ???? ???. Discussion ?? ??? ??? ?? Tabular ????? Soft Policy Iteration?? Soft Actor-Critic?? ??? ? ?? ???? ???? ?????. Action space? ??? finite ??? ??? ???, ?? policy? value function?? ??? ?? ? improvement ??? ??? ??? ?????. ?? ?? ???? RL ????? ????? ??? ???? ??? ?? ??? ?? ???? ?????. ???? ??? ???? ???? ? timestep? ?? ????? ??? ?? ????? ??? ?, ?? ? ?? optimal policy? ??? ?, ? optimal policy? ?? optimal entropy coefficient? ??? ??? global?? optimal? policy, coefficient ??? ?? ??? ????(?? ?? ? ?? ??).
- 8. 1. Notation ??: http://rail.eecs.berkeley.edu/deeprlcourse/static/homeworks/hw5b.pdf ? 2. ?? OU noise? ???? DDPG ? ?? ?? ???? Exploration? ???? ??? ????.? 3. ? ? ??? ?????, ???? ????? ???? ???? ???? ?? ?? ??? ?? ?? Expectation ? ?? ?? ? ??? ?? ???? off-policy ??????, ???? ????? ???? ???? (s, a, s'), ?? policy (i.e. target policy)? , ???? ???? ???? ??? ??? policy (i.e. behavior policy)? ?? ?? ? ??? policy gradient ?? ????? a ? ?? ??? ??? ??? ?????. ??? a ? ?? ??? ??? ??? ?? ???? ??? ???? ???. ??? Soft Q-learning? ?? ???? ??? Q ??? target value? ??? ?, ?? ??? ??? action? ?? ??? ?? ????. ? s'? ?? action? a'? ? ??? ???, ?? ????? ??? ? ??? ???? ??? ?? ??? ??? ?? ?? off-policy ?????? ??? ? ????. ????? Q-learning? ??? ??? target value? ??? ? action? ?? expectation? ??? max? ??? ??? ??? ?? off-policy ?????? ?????.? 4. ?? ??: https://bair.berkeley.edu/blog/2017/10/06/soft-q-learning/? 5. ?? ??? ???? ??? ??? ??? ? ?????. ?? ??, ?? Soft Q update? ??? ??? ??? ?? ?? ?? ??? ??? ??? Q-learning ?? ?? ??? ??? ???? ?????. ? ???? ??? ??? ? ? ??(????? ??? ??)? unbounded ?? ??? ?? ??? ???? ???.? 6. ?? ?? ?? ?? ????.? 7. ?? ??: https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#sac? 8. ???? ??: https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#sac? ?? ?????? ? timestep?? ??? policy? ?? ?? ???? ??? coefficient? ??? ? ? ?? ??????? ?? policy? ???? coefficient? ???? ??? ????. Timestep ? policy? ????? ??? policy? ? ????? ? timestep? ?? ??? policy? ??? ??? ??? ? ? ????, ? ?? timestep? ?? ?? ?? ???? ?? ?????? ??? ?? ????. ?? ? ?? ??? ??? ????? ???? ?? ???? ???? ???. ??? Future Work?? Function Approximator? ???? ? Soft Policy Iteration ??? ????? ?????? Automating Entropy Adjustment ?? minimum entropy? ??? ???? ?? ??? ? ? ?????. ?? ??? ??? ???? ?? ?? ?? ?? ???? ???? ???? tight ???, ? Entropy? Minimum entropy ??? ?? ? ??? ???? ??? ? ??? ? ??? ? ???(??? ???? ???). ? ?? ????? Maximum Entropy Objective? ???? Improvement? ???? Policy Gradient ?? initial state? value function? ?? ???? ?? ??? ? ?? ?????. Evaluation "??? ??, ???? ???? ????, ?? ??"? ??? ? ?????. Soft Q-learning?? Path Consistency Learning???? ???? Maximum Entropy Objective? ?? ?? ???, Automating Entropy Adjustment? ?????? ??? ?? ??? ???? ?? ?? ?? ???? ??? ? ??? ??? ????. ?? ???? ?? ?? ??? ?? ?????? ??? ??? Appendix? ????, ? ? ??? Notation? ????? ? ??? ??? ??? ? ??? ??? ? ???. ?? ?? ????? ? ???? ???? ??? ?? ??? ??? ??? ??? ?? ???? ???? ??? ???? ????? ??? ????? ?????. ??????? ??? ?? ? ??? ??, ?? ??????? ?? ??? ?? ?? ?? ????.