

![BACKGROUND
? ├ū╣·żŪż╬å╦¤¤š▀ż“īØŽ¾ż╚żĘż┐Ę╬ż¼ż¾Ś╩į\ż╬┼R┤▓įć“Y(NLST)ż╬ĮY╣¹Ż¼ąž▓┐XŠĆ
ż╦▒╚ż┘Ż¼LDCTŚ╩į\żŽĘ╬ż¼ż¾╦└═÷š▀ż“20%£pżķż╗żļż╚Ęų╬÷żĘż┐Ż«[Aberle et al.
2011]
? Ę╬ż¼ż¾ż“įńŲ┌░kęŖż╣żļż┐żßż╦żŽŻ¼╗ŁŽ±ųąż╬ĮY╣Øż“▀mŪąż╦Ś╩ų¬ż╣żļ▒žę¬ż¼żóżļ
? ż┐ż└żĘŻ¼ČÓż»ż╬ĮY╣ØżŽÉÖąįżŪżŽż╩żżż┐żßŻ¼ęŖ╠ėżĘż╬źĻź╣ź»ż╚ź│ź╣ź╚ż╬źąźķź¾
ź╣ż¼ųžę¬
? American College of RadiologyŻ©ACRŻ®żŽĪĖLung-RADSĪ╣ż╚║¶żążņżļCTż╬
ź╣ź»źĻ®`ź╦ź¾ź░ż╦ķvż╣żļś╦£╩Ą─ż╩ųĖś╦ż“ķ_░kżĘż┐Ż«
3](https://image.slidesharecdn.com/end-to-endlungcancerscreeningwiththree-dimensionaldeeplearningonlow-dosechestcomputedtomography-190612063146/85/End-to-end-lung-cancer-screening-with-three-dimensional-deep-learning-on-low-dose-chest-computed-tomography-3-320.jpg)










![Data selection
? NLST DatasetŻ©NIHż╦żĶżĻ╣½ķ_żĄżņżŲżżżļopen datasetŻ®ż“└¹ė├
? ę╗▓┐ż“īØŽ¾ż½żķ│²żŁŻ¼14,851╚╦ż½żķ│╔żļ42,290├Čż╬CT╗ŁŽ±ż“▀xÆk
? ė¢ŠÜźŪ®`ź┐Ż║70%Ż©10,306╚╦ [398]Ż»29,541├Č [401]Ż®
? Ś╩į^źŪ®`ź┐Ż║15%Ż©2,198╚╦ [94]Ż»6,034├Č [94]Ż®
? źŲź╣ź╚źŪ®`ź┐Ż║15%Ż©2,347╚╦ [86]Ż»6,716├Č [86]Ż®
16
Ī∙[ ]żŽcancer positiveż╬╩²
ź╣ź»źĻ®`ź╦ź¾ź░ż½żķ1─Ļęį─┌ż╦╔·Ś╩ż╦żĶżĻ░®ż╚į\ČŽżĄżņż┐└²ż“cancer positive caseż╚
Č©┴x](https://image.slidesharecdn.com/end-to-endlungcancerscreeningwiththree-dimensionaldeeplearningonlow-dosechestcomputedtomography-190612063146/85/End-to-end-lung-cancer-screening-with-three-dimensional-deep-learning-on-low-dose-chest-computed-tomography-16-320.jpg)











![[DLHacks]Comet ML -ÖCąĄč¦┴Ģż╬ż┐żßż╬GitHub-](https://cdn.slidesharecdn.com/ss_thumbnails/180625dlhacksltcometml-180629052128-thumbnail.jpg?width=560&fit=bounds)
















![[DL Hacks]Learning Cross-modal Embeddings for Cooking Recipes and Food Images...](https://cdn.slidesharecdn.com/ss_thumbnails/im2recipe2-180427043855-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]Pay Attention to MLPs Ż©gMLPŻ®](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=560&fit=bounds)
![SSII2020 [OS2-02] Į╠ĤżóżĻ╩┬Ū░č¦┴Ģż“┴Ķ±{ż╣żļĪĖ╚§Ī╣Į╠ĤżóżĻ╩┬Ū░č¦┴Ģ](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=560&fit=bounds)




More Related Content
What's hot (20)
End to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography
- 1. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography
- 2. ABSTRACT ? ├ū╣·żŪżŽŻ¼2018─Ļż╦╝s160,000╚╦ż¼Ę╬░®żŪ╦└═÷żĘżŲżżżļ ? Ę╬░®ż╬įńŲ┌░kęŖż╦żŽŻ¼Ą═ŠĆ┴┐CTŻ©LDCTŻ®ż╦żĶżļź╣ź»źĻ®`ź╦ź¾ź░ż¼ėąä┐ ? ź╣ź»źĻ®`ź╦ź¾ź░ż╬é╬Ļ¢ąįż╚é╬ĻÄąįż╬Ė▀żĄż¼šnŅ}ż╚ż╩ż├żŲżżżļ ? 3D╗ŁŽ±šJūRż“ė├żżż┐LDCTżŪż╬Ę╬ż¼ż¾ż╬ź╣ź»źĻ®`ź╦ź¾ź░ż“╠ß░Ė ? Ę╬ż¼ż¾ėĶ£yż╦ķvż╣żļAUCżŽ94.4ŻźŻ©Ę┼╔õŠĆ┐ŲęĮż“╔Ž╗žżļŠ½Č╚Ż® 2
- 3. BACKGROUND ? ├ū╣·żŪż╬å╦¤¤š▀ż“īØŽ¾ż╚żĘż┐Ę╬ż¼ż¾Ś╩į\ż╬┼R┤▓įć“Y(NLST)ż╬ĮY╣¹Ż¼ąž▓┐XŠĆ ż╦▒╚ż┘Ż¼LDCTŚ╩į\żŽĘ╬ż¼ż¾╦└═÷š▀ż“20%£pżķż╗żļż╚Ęų╬÷żĘż┐Ż«[Aberle et al. 2011] ? Ę╬ż¼ż¾ż“įńŲ┌░kęŖż╣żļż┐żßż╦żŽŻ¼╗ŁŽ±ųąż╬ĮY╣Øż“▀mŪąż╦Ś╩ų¬ż╣żļ▒žę¬ż¼żóżļ ? ż┐ż└żĘŻ¼ČÓż»ż╬ĮY╣ØżŽÉÖąįżŪżŽż╩żżż┐żßŻ¼ęŖ╠ėżĘż╬źĻź╣ź»ż╚ź│ź╣ź╚ż╬źąźķź¾ ź╣ż¼ųžę¬ ? American College of RadiologyŻ©ACRŻ®żŽĪĖLung-RADSĪ╣ż╚║¶żążņżļCTż╬ ź╣ź»źĻ®`ź╦ź¾ź░ż╦ķvż╣żļś╦£╩Ą─ż╩ųĖś╦ż“ķ_░kżĘż┐Ż« 3
- 5. Lung-RADS ? ĮY╣Øż╬ąįū┤żõ┤¾żŁżĄż╩ż╔ż╦ÅĻżĖżŲŻ¼ ÉÖąįČ╚ż“┼ąČ© ? ź½źŲź┤źĻż╦ÅĻżĖżŲŻ¼äIų├ż╬ųžę¬Č╚ż“ øQČ© 5
- 6. BACKGROUND ? Lung-RADSż╩ż╔ż╬ę╗ž×ąįż╬żóżļųĖś╦ż¼ķ_░kżĄżņż┐ż¼Ż¼įuü²ż╬źąźķż─żŁżõ╗ŁŽ± ╦∙ęŖż╬╠žÅšż“╩«Ęųż╦ŠW┴_żŪżŁżŲżżż╩żżż╩ż╔ż╬å¢Ņ}żŽ▓ążļ ? ╔Ņīėč¦┴Ģż╬ł÷║ŽŻ¼╗ŁŽ±╦∙ęŖż╬╬ó├Ņż╩╠žÅšż▐żŪūįäėżŪŚ╩│÷┐╔─▄ ? ż│żņż▐żŪż╦żŌŻ¼computer-aided detection (CADe) ż╚║¶żążņżļ╗ŁŽ±ųąż╬«É│Ż╦∙ ęŖż“Ś╩│÷ż╣żļźĘź╣źŲźÓżŽżżż»ż─ż½┤µį┌żĘż┐ ? CADeżŽ╗ŁŽ±ųąż╬«É│Ż╦∙ęŖŻ©ĮY╣Øż╩ż╔Ż®ż“Ś╩│÷żŪżŁżļż¼Ż¼ÉÖąįČ╚ż╬įuü²żõ┼R ┤▓Ą─ż╩ęŌ╦╝øQČ©żŽ┼R┤▓ęĮż╦╬»ż═żŲżżżļ ? computer-aided diagnosis (CADx) żŽŻ¼╩┬Ū░ż╦╠žČ©żĄżņż┐▓Īēõż╦īØż╣żļį\ČŽų¦ į«ż“ąąż”źĘź╣źŲźÓżŪżóżĻŻ¼┤¾żŁż╩ķvą─ż“╝»żßżŲżżżļ ? FDAż╬ūŅ│§ż╬│ąšJż“Ą├żŲżżżļCADxżŌ┤µį┌ż╣żļż¼Ż¼Ę╬ż¼ż¾ż╦ķvż╣żļCADxżŽšō ╬─ł╠╣Pż╬ĢrĄŃżŪżŽ┤µį┌żĘż╩żż 6
- 7. METHOD ? Ę╬ż¼ż¾ż╬ź╣ź»źĻ®`ź╦ź¾ź░ż╦ķvż╣żļCADxż╚żĘżŲŻ¼CT╗ŁŽ±ż½żķĘ╬ż¼ż¾ż╬źĻź╣ź» ĘųŅÉż“ąąż”end-to-endż╬źóźūźĒ®`ź┴ż“╠ß░Ė ? ▒Ššō╬─ż╬źóźūźĒ®`ź┴żŪż╬ųžę¬ż╩ĄŃżŽęįŽ┬ż╬Ż│ż─ 1. Ż│D CNNźŌźŪźļż╦żĶżĻŻ¼CT╚½╠Õż“č¦┴Ģż╣żļźŌźŪźļż“śŗ║BŻ©Full-volume modelŻ® 2. Ę╬ż¼ż¾ż╬║“čaż╚ż╩żļROIż╬Ś╩│÷źŌźŪźļż“śŗ║BŻ©Cancer ROI detectionŻ® 3. 1.2.ż╬│÷┴”ż½żķŻ¼ż¼ż¾ż╬źĻź╣ź»ż“ėĶ£yż╣żļźŌźŪźļż“śŗ║BŻ©Cancer risk prediction modelŻ® 7
- 9. Cancer ROI detection model ? RetinaNetż“ÆłÅłżĘż┐źŌźŪźļż“ė├żżżŲROIż“Ś╩│÷ ? Ž┬ćĒż╬│Ó╔½ż╬bounding boxż¼detection modelż╦żĶżĻŚ╩│÷żĄżņż┐żŌż╬ ? bounding boxżŽŻ¼ų„ż╦Ę┼╔õŠĆ┐ŲęĮż╦żĶżļźóź╬źŲ®`źĘźńź¾źŪ®`ź┐ż“ė├żżżŲč¦┴Ģ ? Ś╩│÷żĄżņż┐bounding boxż“╣╠Č©źĄźżź║ż╬Cancer ROIŻ©╦«╔½Ż®ż╦š{š¹ 9
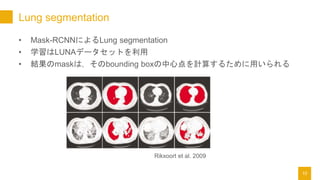
- 10. Lung segmentation ? Mask-RCNNż╦żĶżļLung segmentation ? č¦┴ĢżŽLUNAźŪ®`ź┐ź╗ź├ź╚ż“└¹ė├ ? ĮY╣¹ż╬maskżŽŻ¼żĮż╬bounding boxż╬ųąą─ĄŃż“ėŗ╦Ńż╣żļż┐żßż╦ė├żżżķżņżļ 10 Rikxoort et al. 2009
- 11. Full-volume model ? Lung segmentationż╦żĶżĻŻ¼│ķ│÷żĄżņż┐źčź├ź┴ż“╚ļ┴”╗ŁŽ±ż╚żĘżŲ└¹ė├ ? Inception V1ż“3Dż╦ÆłÅłżĘż┐źŌźŪźļż“Ʊė├ ? 1─Ļęį─┌ż╦Ę╬ż¼ż¾ż╦ż╩żļ┤_┬╩ż“ėĶ£y ? ImageNetż╦żĶżĻė¢ŠÜ£gż╬źčźķźß®`ź┐ż“Fine-tuning ? │÷┴”īėż╬ų▒Ū░ż╬īėŻ©1,024 featuresŻ®ż“╠žÅš┴┐ż╚żĘżŲßßż╬źŌźŪźļż╦└¹ė├ 11
- 12. Inception V1 (GoogLeNet) ? InceptionźŌźĖźÕ®`źļŻ©║¶żążņżļ«Éż╩żļźĄźżź║ż╬«Æż▀▐zż▀īėżõpoolingīėż½żķ śŗ│╔żĄżņżļąĪżĄż╩ź═ź├ź╚ź’®`ź»Ż®ż“Č©┴x 12 Christian et al. 2014
- 13. Inception V1 (GoogLeNet) ? ILSVRC 2014 Classification żŪā×ä┘żĘż┐źŌźŪźļ 13
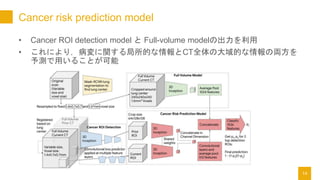
- 14. Cancer risk prediction model ? Cancer ROI detection model ż╚ Full-volume modelż╬│÷┴”ż“└¹ė├ ? ż│żņż╦żĶżĻŻ¼▓Īēõż╦ķvż╣żļŠų╦∙Ą─ż╩Ūķł¾ż╚CT╚½╠Õż╬┤¾ė“Ą─ż╩Ūķł¾ż╬üIĘĮż“ ėĶ£yżŪė├żżżļż│ż╚ż¼┐╔─▄ 14
- 15. Output (Malignancy probability) ? ╚½╠Õż╦īØżĘżŲģgę╗źķź┘źļż╬ż▀ż“╩╣ė├żĘż┐č¦┴ĢżŽļyżĘżż┐╔─▄ąįż¼żóżļ ? detection modelż╦żĶżĻ▀xÆkżĘż┐2ż─ż╬ROI║“čaż½żķŽ┬╩Įż╦żĶżĻŻ¼ź╣ź│źóż“ėŗ ╦Ń ????? = 1 ? (1 ? ?1)(1 ? ?2) 15 Ī∙ROI║“čaż╬╩²żŽź┴źÕ®`ź╦ź¾ź░ż╦żĶżĻš{š¹
- 16. Data selection ? NLST DatasetŻ©NIHż╦żĶżĻ╣½ķ_żĄżņżŲżżżļopen datasetŻ®ż“└¹ė├ ? ę╗▓┐ż“īØŽ¾ż½żķ│²żŁŻ¼14,851╚╦ż½żķ│╔żļ42,290├Čż╬CT╗ŁŽ±ż“▀xÆk ? ė¢ŠÜźŪ®`ź┐Ż║70%Ż©10,306╚╦ [398]Ż»29,541├Č [401]Ż® ? Ś╩į^źŪ®`ź┐Ż║15%Ż©2,198╚╦ [94]Ż»6,034├Č [94]Ż® ? źŲź╣ź╚źŪ®`ź┐Ż║15%Ż©2,347╚╦ [86]Ż»6,716├Č [86]Ż® 16 Ī∙[ ]żŽcancer positiveż╬╩² ź╣ź»źĻ®`ź╦ź¾ź░ż½żķ1─Ļęį─┌ż╦╔·Ś╩ż╦żĶżĻ░®ż╚į\ČŽżĄżņż┐└²ż“cancer positive caseż╚ Č©┴x
- 17. LUMAS ? ▒ŠčąŠ┐żŪLUMAS (lung malignancy scores) ż“ķ_░k ? LUMASżŽŻ¼Malignancy probabilityż╦╗∙ż┼żżżŲ4ż─éÄż╦ĘųŅÉżĄżņżļ ? Lung-RADS Categoryż╬Malignancy probabilityż╚ę╗ų┬ż╣żļżĶż”ż╦ź½ź├ź╚ź¬źš ż“š{š¹ 17 Pinsky et al. 2015
- 18. Reader studies ? 6╚╦ż╬Ę┼╔õŠĆ┐ŲęĮż¼šiė░ęĮż╚żĘżŲ蹊┐ż╦▓╬╝ė ? ╚½åTż¼USšJČ©ęĮżŪŲĮŠ∙ĮU“Y─Ļ╩²żŽ8─Ļ ? Ė„šiė░ęĮżŽŻ¼Ė„╗ŁŽ±ż╬▓Īēõż╦ROIż╚Lung-RADS Scoreż“▀mė├ ? źŌźŪźļż╬LUMASż╦╗∙ż┼ż»ź╣ź│źóż╚šiė░ęĮż╬Lung-RADS Scoreż╬ŲĮŠ∙żŪŠ½Č╚ ▒╚▌^ 18
- 19. Clinical validation ? LUMASż╚Lung-RADS Scoreż½żķŻ¼cancer-positiveż“ėĶ£y ? Ė„Categoryäeż╦ęįŽ┬ż╬żĶż”ż╩cutofféÄż“įOČ© 19 No cancer-negative cancer-positive (1) 1,2 3+ (2) 1,2,3 4A+ (3) 1,2,3,4A 4B/X (1)żŽcutofféÄż¼Ą═żżż╬żŪŻ¼SensibilityĪ³ & SpecificityĪ² (3) żŽcutofféÄż¼Ė▀żżż╬żŪŻ¼SensibilityĪ² & SpecificityĪ³
- 20. lung cancer screening on a single CT volume 1├Čż╬CT╗ŁŽ±żŪż╬īg“YĮY╣¹ ? AUCżŽ95.9% ? ż╔ż╬cutofféÄżŪżŌšiė░ęĮż╬Š½Č╚ż“╔Ž╗ž żļ ? Lung-RADS 3+ ż“cancer-positiveż╚żĘ ż┐cutofféÄż╦ż¬żżżŲżŽŻ¼šiė░ęĮż╚▒╚▌^ żĘżŲ ? Sensibility + 5.2% ? Specificity + 11.6% 20
- 21. lung cancer screening using current and prior CT volume 21 ▀^╚źż╚¼Fį┌ż╬CT╗ŁŽ±żŪż╬īg“YĮY╣¹ ? AUCżŽ92.6% ? źŌźŪźļż╚šiė░ęĮż╬üIĘĮżŪ1├Čż╬╗ŁŽ±żŪ ż╬įuü²ĮY╣¹ż“Ž┬╗žż├ż┐
- 22. DISCUSSION ? ▀^╚ź╗ŁŽ±ż“║¼żßżļż╚Ż¼Š½Č╚ż¼Ą═Ž┬ ? ░®ż“░kęŖżĘżõż╣żż╗╝š▀ż╬╗ŁŽ±ż¼ź┘®`ź╣źķźżź¾ż╬─Ļż╦╝╚ż╦į\ČŽżĄżņŻ¼│²═ŌżĄżņżŲż¬żĻŻ¼▀^╚ź ╗ŁŽ±ż“│ųż─╗╝š▀żŽ┼ąČŽż¼ļyżĘżż╬ó├Ņż╩░®ųó└²żĘż½▓ążĄżņżŲżżż╩ż½ż├ż┐ż┐żßż╚┐╝ż©żķżņżļ ? ╚ļ╩ų┐╔─▄ż╩░®ųó└²ż╬╗ŁŽ±ż╬▓╗ūŃ ? Ü°ė├ąįż“Ė▀żßżļż┐żßŻ¼ČÓśöż╩╠žÅšż╬░®ż╬ųó└²ż“║¼żßż┐č¦┴Ģż¼═¹ż▐żņżļ ? šiė░ęĮż╚źŌźŪźļż╬Š½Č╚▒╚▌^ż╬ż┐żßŻ¼cutofféÄż“įOČ©żĘżŲįuü²ż“ąąż├ż┐ ? ┼R┤▓ÅĻė├ż“┐╝ż©żļł÷║ŽŻ¼ęŖ╠ėżĘż╬źĻź╣ź»ż╚ź│ź╣ź╚ż╦ķvż╣żļĖ³ż╩żļ蹊┐ż¼▒žę¬ 22
- 23. Example LUMAS 4B/X false positives 23
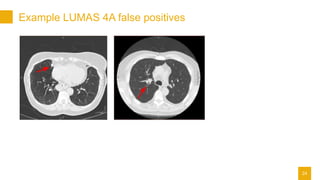
- 24. Example LUMAS 4A false positives 24
- 25. References ? Aberle DR, Adams AM, Berg CD, Black WC, Clapp JD, Fagerstrom RM. Gareen IF, Gatsonis C, Marcus PM, Sicks JD; National Lung Screening Trial Research Team. Reduced lung-cancer mortality with low- dose computed tomographic screening (2011) ? van Rikxoort EM, de Hoop B, Viergever MA, Prokop M, van Ginneken B. Automatic lung segmentation from thoracic computed tomography scans using a hybrid approach with error detection (2009) ? Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Going Deeper with Convolutions (2014) ? Pinsky PF, Gierada DS, Black W, Munden R, Nath H, Aberle D, Kazerooni E. Performance of Lung- RADS in the National Lung Screening Trial: a retrospective assessment (2015) 25