Fluentd with MySQL
1 like2,428 views

MySQL PowerGroup Tech Seminar (2015.2) - 6.Fluentd with MySQL (by ėīėīęĩŽ) - URL : cafe.naver.com/mysqlpg




![11
Install
"ėė§ëė(Client)" ėëēëĄ ė ėíėŽ Fluentd ėĪėđ
http://docs.fluentd.org/v0.12/categories/installation
# sudo su -
cd /usr1/program/
curl -L https://td-toolbelt.herokuapp.com/sh/install-redhat-td-agent2.sh | sh
# /etc/init.d/td-agent start
/etc/init.d/td-agent status
/etc/init.d/td-agent restart
/etc/init.d/td-agent stop
# cat /etc/td-agent/td-agent.conf
# curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test
tail -f /var/log/td-agent/td-agent.log
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-11-320.jpg)

![13
Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ
https://github.com/yuku-t/fluent-plugin-mysqlslowquery
https://github.com/tagomoris/fluent-plugin-mysql
https://github.com/toyama0919/fluent-plugin-mysql-bulk
# yum -y install ruby-rdoc ruby-devel rubygems
find / -name fluent-gem
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysqlslowquery
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql-bulk
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.1 MySQL slowquery logging](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-13-320.jpg)
![14
Test.1 MySQL slowquery logging
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í
ėīëļ ėėą
$ mysql -u root -p
use test;
drop table if exists test.t_mysql_slow;
create table test.t_mysql_slow (
log_date datetime default current_timestamp
, user varchar(100)
, host varchar(100)
, host_ip varchar(20)
, query_time decimal(20,10)
, lock_time decimal(20,10)
, rows_sent bigint
, rows_examined bigint
, sql_text varchar(10000)
);](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-14-320.jpg)
![15
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė
$ sudo vi /etc/td-agent/td-agent.conf
âĶ
âĶ
<source>
type mysql_slow_query
path /data/mysql/ADMIN/slowquery.log
tag ec-ldb-m2.mysql_slow
</source>
<match ec-ldb-m2.mysql_slow>
type copy
<store>
type stdout
</store>
<store>
type mysql_bulk
host ec-ldb-m2
port 19336
database test
username root
password testpasswd12#$
column_names user,host,host_ip,query_time,lock_time,rows_sent,rows_examined,sql_text
key_names user,host,host_ip,query_time,lock_time,rows_sent,rows_examined,sql_text
table t_mysql_slow
flush_interval 5s
</store>
</match>
Test.1 MySQL slowquery logging](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-15-320.jpg)
![16
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.4 td-agent ėŽėė ë° ëķíėŋžëĶŽ ėí
$ sudo /etc/init.d/td-agent stop
sudo /etc/init.d/td-agent start
tail -f /var/log/td-agent/td-agent.log
Test.1 MySQL slowquery logging
$ mysql -u root -p
select sleep(1);
select sleep(1);](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-16-320.jpg)
![17
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ
$ mysql -u root âp
select sleep(1);
select sleep(1);
Test.1 MySQL slowquery logging
$ mysql -u root -p
select * from t_mysql_slow;](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-17-320.jpg)
![19
Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ
https://github.com/y-ken/fluent-plugin-mysql-query
https://github.com/shunwen/fluent-plugin-rename-key
# yum -y install ruby-rdoc ruby-devel rubygems
find / -name fluent-gem
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql-query
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-rename-key
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.2 MySQL process list logging](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-19-320.jpg)
![20
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.2 MySQL process list logging
Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í
ėīëļ ėėą
$ mysql -u root -p
use test;
drop table if exists test.t_mysql_process;
create table test.t_mysql_process (
log_date datetime default current_timestamp
, hostname varchar(100)
, id bigint
, user varchar(100)
, host varchar(100)
, db varchar(64)
, command varchar(50)
, duration_time bigint
, state varchar(4000)
, info varchar(10000)
);](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-20-320.jpg)
![21
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.2 MySQL process list logging
Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė
$ sudo vi /etc/td-agent/td-agent.conf
âĶ
âĶ
<source>
type mysql_query
host ec-ldb-s2
port 19336
database test
username root
password 433dlxjsjf12!@!
interval 1m
tag ec-ldb-s2.processlist
query show full processlist;
record_hostname yes
nest_result no
nest_key data
#row_count yes
#row_count_key row_count
</source>
<match ec-ldb-s2.processlist>
type rename_key
remove_tag_prefix ec-ldb-s2.
append_tag ec-ldb-s2
rename_rule1 Time duration_time
</match>
<match processlist.ec-ldb-s2>
type copy
<store>
type stdout
</store>
<store>
type mysql_bulk
host ec-ldb-m2
port 19336
database test
username root
password testpasswd12#$
column_names hostname,Id,User,Host,db,Command,State,Info,duration_time
key_names hostname,Id,User,Host,db,Command,State,Info,duration_time
table t_mysql_process
flush_interval 5s
</store>
</match>](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-21-320.jpg)
![22
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.2 MySQL process list logging
Step.4 td-agent ėŽėė
$ sudo /etc/init.d/td-agent stop
sudo /etc/init.d/td-agent start
tail -f /var/log/td-agent/td-agent.log](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-22-320.jpg)
![23
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.2 MySQL process list logging
Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ
$ mysql -u root âp
use test;
select * from t_mysql_process;](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-23-320.jpg)
![25
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.1 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í
ėīëļ ėėą
$ mysql -u root -p
use test;
drop table if exists test.log_game_play;
create table test.log_game_play (
log_date datetime default current_timestamp
, useridx bigint
, play_time bigint
, char_type varchar(1)
, result varchar(1)
);
alter table log_game_play add primary key(log_date,useridx);
Test.3 Game Log Collect](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-25-320.jpg)
![26
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.2 ėė§ëė ėëēëĄ ė ėíėŽ Log í
ėīëļ ėėą ë° ë°ėīí° ė
ë Ĩ
$ mysql -u root -p
use test;
drop table if exists test.log_game_play;
create table test.log_game_play (
log_date datetime default current_timestamp
, useridx bigint
, play_time bigint
, char_type varchar(1)
, result varchar(1)
);
alter table log_game_play add primary key(log_date,useridx);
Test.3 Game Log Collect
set @i=0;
insert ignore into test.log_game_play
select date_sub(now(), interval @i:=@i+1 minute) as log_date
, @i
, rand()*10000
, mod(@i,10)
, mod(@i,3)
from mysql.proc
limit 100;
select date_format(log_date, '%Y%m%d%h') as dt, count(*) from
test.log_game_play group by date_format(log_date, '%Y%m%d%h');
select * from test.log_game_play where log_date between date_sub(now(),
interval 10 minute) and now();](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-26-320.jpg)
![27
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė
$ sudo vi /etc/td-agent/td-agent.conf
âĶ
âĶ
<source>
type mysql_query
host ec-ldb-s2
port 19336
database test
username root
password 433dlxjsjf12!@!
interval 10s
tag ec-ldb-s2.log_game_play
query select * from test.log_game_play where log_date
between date_sub(now(), interval 10 minute) and now();
record_hostname yes
nest_result no
nest_key data
#row_count yes
#row_count_key row_count
</source>
<match ec-ldb-s2.log_game_play>
type copy
<store>
type stdout
</store>
<store>
type mysql_bulk
host ec-ldb-m2
port 19336
database test
username root
password 433dlxjsjf12!@!
column_names log_date,useridx,play_time,char_type,result
key_names log_date,useridx,play_time,char_type,result
table log_game_play
on_duplicate_key_update true
on_duplicate_update_keys log_date,useridx
flush_interval 15s
</store>
</match>
Test.3 Game Log Collect](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-27-320.jpg)
![28
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.4 td-agent ėŽėė
$ sudo /etc/init.d/td-agent stop
sudo /etc/init.d/td-agent start
tail -f /var/log/td-agent/td-agent.log
Test.3 Game Log Collect](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-28-320.jpg)
![29
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ
$ mysql -u root âp
use test;
select * from test.log_game_play;
Test.3 Game Log Collect](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-29-320.jpg)
![31
Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ
https://github.com/tagomoris/fluent-plugin-mysql
# yum -y install ruby-rdoc ruby-devel rubygems
find / -name fluent-gem
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Test.4 Log Server ęĩŽėķ
Client
Client
Client
Server
Server
HAProxy(L4)](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-31-320.jpg)
![32
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í
ėīëļ ėėą
$ mysql -u root -p
use test;
drop table if exists test.t_log_connect;
create table test.t_log_connect (
log_date datetime default current_timestamp
, jsondata text
);
drop table if exists test.t_log_money;
create table test.t_log_money (
log_date datetime default current_timestamp
, jsondata text
);
Test.4 Log Server ęĩŽėķ](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-32-320.jpg)
![33
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė
$ sudo vi /etc/td-agent/td-agent.conf
âĶ
âĶ
<source>
type http
port 8888
body_size_limit 1mb
keepalive_timeout 10s
</source>
<match ec-ldb-s2.t_log_connect>
type copy
<store>
type stdout
</store>
<store>
type mysql
host ec-ldb-m2
port 19336
database test
username root
password testpasswd12#$
table t_log_connect
columns jsondata
format json
flush_interval 5s
</store>
</match>
<match ec-ldb-s2.t_log_money>
type copy
<store>
type stdout
</store>
<store>
type mysql
host ec-ldb-m2
port 19336
database test
username root
password testpasswd12#$
table t_log_money
columns jsondata
format json
flush_interval 5s
</store>
</match>
Test.4 Log Server ęĩŽėķ](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-33-320.jpg)
![34
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.4 td-agent ėŽėė
$ sudo /etc/init.d/td-agent stop
sudo /etc/init.d/td-agent start
-- ëĄę·ļ ë°ė
curl -X POST -d 'json={"ver":"1.0","action":"login","user":1}' http://localhost:8888/ec-ldb-s2.t_log_connect
curl -X POST -d 'json={"ver":"1.0","action":"login","user":1}' http://localhost:8888/ec-ldb-s2.t_log_money
tail -f /var/log/td-agent/td-agent.log
Test.4 Log Server ęĩŽėķ](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-34-320.jpg)
![35
Collector
[ec-ldb-m2]
Service DB
[ec-ldb-s2]
Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ
$ mysql -u root âp
use test;
select count(*) from test.t_log_money;
select count(*) from test.t_log_connect;
Test.4 Log Server ęĩŽėķ](https://image.slidesharecdn.com/08-1-170430125208/85/Fluentd-with-MySQL-35-320.jpg)
















![[pgday.Seoul 2022] PostgreSQLęĩŽėĄ° - ėĪėąėŽ](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=560&fit=bounds)



![[ėĪíėėĪėŧĻėĪí
]Day #2 MySQL Tuning, Replication, Cluster](https://cdn.slidesharecdn.com/ss_thumbnails/day2mysqltuningreplicationcluster-141212190228-conversion-gate02-thumbnail.jpg?width=560&fit=bounds)










More Related Content
What's hot (20)
Similar to Fluentd with MySQL (20)


![[ėĪíėėĪėŧĻėĪí
]Nginx 1.2.7 ėĪėđę°ėīë__v1](https://cdn.slidesharecdn.com/ss_thumbnails/nginx1-2-7v1-130506223255-phpapp01-thumbnail.jpg?width=560&fit=bounds)
![[ėĪíėėĪėŧĻėĪí
]Nginx jboss ė°ëę°ėīë__v1](https://cdn.slidesharecdn.com/ss_thumbnails/nginxjbossv1-130506223401-phpapp02-thumbnail.jpg?width=560&fit=bounds)





![[ėĪíėėĪėŧĻėĪí
] ėĪėđīė°í° ėŽėĐė ę°ėīë 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=560&fit=bounds)



![[Ansible] Solution Guide V0.4_20181204.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ansiblesolutionguidev0-240329014429-50cc2cc4-thumbnail.jpg?width=560&fit=bounds)




More from I Goo Lee (20)




















Fluentd with MySQL
- 1. Fluentd with MySQL V1.0 ėėąėžė : 2015.08 ė ėą ė : ėī ėī ęĩŽ 1
- 2. 2 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
- 3. 3 Intro
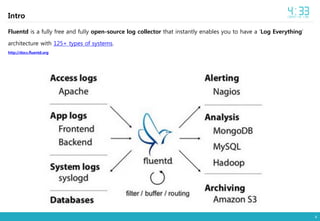
- 4. 4 Intro Fluentd is a fully free and fully open-source log collector that instantly enables you to have a âLog Everythingâ architecture with 125+ types of systems. http://docs.fluentd.org
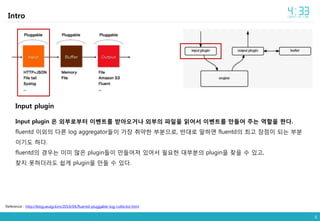
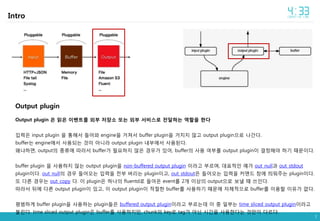
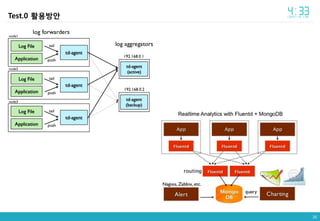
- 6. 6 Intro Input plugin Input plugin ė ėļëķëĄëķí° ėīëēĪíļëĨž ë°ėėĪęą°ë ėļëķė íėžė ė―ėīė ėīëēĪíļëĨž ë§ëĪėī ėĢžë ėí ė íëĪ. fluentd ėīėļė ëĪëĨļ log aggregatorëĪėī ę°ėĨ ė·Ļė―í ëķëķėžëĄ, ë°ëëĄ ë§íëĐī fluentdė ėĩęģ ėĨė ėī ëë ëķëķ ėīęļ°ë íëĪ. fluentdė ęē―ė°ë ėīëŊļ ë§ė pluginëĪėī ë§ëĪėīė ļ ėėīė íėí ëëķëķė pluginė ė°ūė ė ėęģ , ė°ūė§ ëŠŧíëëžë ė―ęē pluginė ë§ëĪ ė ėëĪ. Reference : http://blog.seulgi.kim/2014/04/fluentd-pluggable-log-collector.html
- 7. 7 Intro Output plugin Output plugin ė ė―ė ėīëēĪíļëĨž ėļëķ ė ėĨė ëë ėļëķ ėëđėĪëĄ ė ëŽíë ėí ė íëĪ ė ë Ĩė input plugin ė íĩíīė ëĪėīė engineė ęą°ėģė buffer pluginė ęą°ėđė§ ėęģ output pluginėžëĄ ëę°ëĪ. bufferë engineėė ėŽėĐëë ęēėī ėëëž output plugin ëīëķėė ėŽėĐëëĪ. ėëíëĐī, outputė ėĒ ëĨė ë°ëžė bufferę° íėíė§ ėė ęē―ė°ę° ėėī, bufferė ėŽėĐ ėŽëķëĨž output pluginėī ęē°ė íīėž íęļ° ëëŽļėīëĪ. buffer plugin ė ėŽėĐíė§ ėë output pluginė non-buffered output plugin ėīëžęģ ëķëĨīëĐ°, ëíė ėļ ėę° out_nullęģž out_stdout pluginėīëĪ. out_nullė ęē―ė° ëĪėīėĪë ė ë Ĩė ė ëķ ëēëĶŽë pluginėīęģ , out_stdoutė ëĪėīėĪë ė ë Ĩė ėŧĪë§Ļë ė°―ė ëėėĢžë pluginėīëĪ. ë ëĪëĨļ ęē―ė°ë out_copy ëĪ. ėī pluginė íëė fluentdëĄ ëĪėīėĻ eventëĨž 2ę° ėīėė outputėžëĄ ëģīëž ë ė°ėļëĪ. ë°ëžė ëĪė ëĪëĨļ output pluginėī ėęģ , ėī output pluginėī ė ė í bufferëĨž ėŽėĐíęļ° ëëŽļė ėėēīė ėžëĄ bufferëĨž ėīėĐí ėīė ę° ėëĪ. íëēíęē buffer pluginė ėŽėĐíë pluginëĪė buffered output pluginėīëžęģ ëķëĨīëë° ėī ėĪ ėžëķë time sliced output pluginėīëžęģ ëķëĶ°ëĪ. time sliced output pluginė bufferëĨž ėŽėĐíė§ë§, chunkė keyëĄ tagę° ėë ėę°ė ėŽėĐíëĪë ęēë§ėī ëĪëĨīëĪ.
- 8. 8 Intro Buffer plugin 1. Output ė íĻėĻė ėžëĄ ëīëģīëīë ęļ°ëĨ log aggregatorë ėĪėę°ėžëĄ ëĄę·ļëĨž ëŠĻėėĢžė§ë§, ëŠĻė ëĄę·ļëĨž ë°ëĄ ë°ëĄ output ėžëĄ ëģīëž ėīė ë ėëĪ. ę·ļëė fluentd ëĨž ëđëĄŊí ëëķëķė aggregatorë ėëēėė ėžė ëė ëĄę·ļëĨž ëŠĻėëĪę° ėēëĶŽíëëĄ íīėĪëĪ. fluentdėėë ėī ëĻėëĨž chunkëžęģ ëķëĨīëĐ°, chunkë logė tag ëģëĄ ëķëĨëėī ė ėĨëëĪ. output pluginė ė°ė chunkëĨž queueė ė§ėīëĢė§ ėęģ ëĪėīėĪë logëĨž chunkė ė ëëĪ. ę·ļëŽëĪę° chunkė íŽęļ°ę° ėžė ėīė ėŧĪė§ęą°ë, chunkę° ėęļīė§ ėžė ėę° ėīė ė§ëëĐī queueė ëĪėīę°ëĪ. chunkë tagëĨž keyëĄ íëŊëĄ bufferė ëĪėīę°ė§ ėęģ ėë chunkę° í ę° ėīėėž ėë ėëĪ. queueė íŽęļ°ëĨž ėžė ėīė íĪė°ė§ ėęļ° ėíī queueė chunkëĨž ė§ėīëĢė ë, queueėė chunkëĨž 1ę° ëđžė outputėžëĄ ëīëģīëļëĪ. 2. Collector ėëē ėĨė ė log ė ėĪ ėĩėííë ęļ°ëĨ Buffer ëĨž ėŽėĐíëĪęģ íīë ëĐëŠĻëĶŽę° ëŽīíí ęēėī ėëëŊëĄ ėëēė ėĪëŦëė ëŽļė ėėžëĐī ëēë Īė§ë ë°ėīí°ę° ėęļ°ęē ëëĪ. fluentd ë ėŽėëëĨž íęģ ę·ļëë ė ëëĐī ëēëĶŽë ęēė ė ėą ėžëĄ ėžęģ ėëĪ. ėĶ, outputėžëĄ ëę°ėž íë dataę° ëę°ė§ ëŠŧíė ë ėžė ėę°ėī ė§ë í ëĪė ėëíëĐ°, ę·ļëë ėĪíĻíëĪëĐī, ęļ°ëĪë ļë ėę°ė 2ë°°ë§íž ë ęļ°ëĪëĶŽęģ ëĪė ėëíęļ°ëĨž ë°ëģĩíëĪ. ėžė íėëĨž ęļ°ëĪë Īë ëģīëīë ęēė ėĪíĻíëĐī ėī ë°ėīí°ë ëĪėėžëĄ ëģīëīė§ė§ ėęģ ëēë Īė§ëĪ. (ėŽėëėę°: retry_wait, ėŽėëíė: retry_limitëĄ ėĪė ) fluentd ėėēīę° ëŽļė ę° ėęēĻė ęšžė§ë ęē―ė°ë ėëë°, ėīęēë bufferė pluginėžëĄ ėíë ėĒ ëĨëĨž ėĻė íīęē°í ė ėëĪ. ęļ°ëģļė ėžëĄ fluentdę° bufferė ėŽėĐíë ęēė buf_memory ëžë pluginėžëĄ chunkëĨž memoryė ęļ°ëĄíë plugin ėīëĪ. íė§ë§ ėëēę° ėĢ―ėëĪ ėīėë ëë ëģīėĨíęģ ėķëĪëĐī buf_file pluginė ėīėĐíëĐī ëëĪ. buf_file pluginė ėŽėĐíëĐī chunkė ëīėĐė fileė ëģīęīíī ėĢžęļ° ëëŽļė ėëēę° ëĪė ėžė§ ë fileė ė―ėīė buffer ëīėĐė ëģĩęĩŽíīėĪëĪ. fileė ė°ë ë§íž ėëę° ëë Īė§ė§ë§, ėė ėąėī ėĶę°íęļ°ë íęģ , ėŽėĐí ė ėë bufferė íŽęļ°ë ėŧĪė§ëĪ.
- 9. 9 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
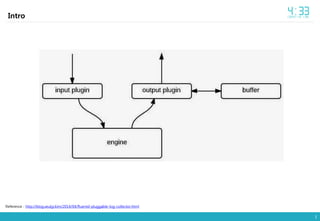
- 10. 10 Intro Fluentd nested plugin URL(input) : http://docs.fluentd.org/articles/input-plugin-overview URL(output) : http://docs.fluentd.org/articles/output-plugin-overview
- 11. 11 Install "ėė§ëė(Client)" ėëēëĄ ė ėíėŽ Fluentd ėĪėđ http://docs.fluentd.org/v0.12/categories/installation # sudo su - cd /usr1/program/ curl -L https://td-toolbelt.herokuapp.com/sh/install-redhat-td-agent2.sh | sh # /etc/init.d/td-agent start /etc/init.d/td-agent status /etc/init.d/td-agent restart /etc/init.d/td-agent stop # cat /etc/td-agent/td-agent.conf # curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test tail -f /var/log/td-agent/td-agent.log Collector [ec-ldb-m2] Service DB [ec-ldb-s2]
- 12. 12 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
- 13. 13 Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ https://github.com/yuku-t/fluent-plugin-mysqlslowquery https://github.com/tagomoris/fluent-plugin-mysql https://github.com/toyama0919/fluent-plugin-mysql-bulk # yum -y install ruby-rdoc ruby-devel rubygems find / -name fluent-gem /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysqlslowquery /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql-bulk Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.1 MySQL slowquery logging
- 14. 14 Test.1 MySQL slowquery logging Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í ėīëļ ėėą $ mysql -u root -p use test; drop table if exists test.t_mysql_slow; create table test.t_mysql_slow ( log_date datetime default current_timestamp , user varchar(100) , host varchar(100) , host_ip varchar(20) , query_time decimal(20,10) , lock_time decimal(20,10) , rows_sent bigint , rows_examined bigint , sql_text varchar(10000) );
- 15. 15 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė $ sudo vi /etc/td-agent/td-agent.conf âĶ âĶ <source> type mysql_slow_query path /data/mysql/ADMIN/slowquery.log tag ec-ldb-m2.mysql_slow </source> <match ec-ldb-m2.mysql_slow> type copy <store> type stdout </store> <store> type mysql_bulk host ec-ldb-m2 port 19336 database test username root password testpasswd12#$ column_names user,host,host_ip,query_time,lock_time,rows_sent,rows_examined,sql_text key_names user,host,host_ip,query_time,lock_time,rows_sent,rows_examined,sql_text table t_mysql_slow flush_interval 5s </store> </match> Test.1 MySQL slowquery logging
- 16. 16 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.4 td-agent ėŽėė ë° ëķíėŋžëĶŽ ėí $ sudo /etc/init.d/td-agent stop sudo /etc/init.d/td-agent start tail -f /var/log/td-agent/td-agent.log Test.1 MySQL slowquery logging $ mysql -u root -p select sleep(1); select sleep(1);
- 17. 17 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ $ mysql -u root âp select sleep(1); select sleep(1); Test.1 MySQL slowquery logging $ mysql -u root -p select * from t_mysql_slow;
- 18. 18 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
- 19. 19 Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ https://github.com/y-ken/fluent-plugin-mysql-query https://github.com/shunwen/fluent-plugin-rename-key # yum -y install ruby-rdoc ruby-devel rubygems find / -name fluent-gem /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql-query /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-rename-key Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.2 MySQL process list logging
- 20. 20 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.2 MySQL process list logging Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í ėīëļ ėėą $ mysql -u root -p use test; drop table if exists test.t_mysql_process; create table test.t_mysql_process ( log_date datetime default current_timestamp , hostname varchar(100) , id bigint , user varchar(100) , host varchar(100) , db varchar(64) , command varchar(50) , duration_time bigint , state varchar(4000) , info varchar(10000) );
- 21. 21 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.2 MySQL process list logging Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė $ sudo vi /etc/td-agent/td-agent.conf âĶ âĶ <source> type mysql_query host ec-ldb-s2 port 19336 database test username root password 433dlxjsjf12!@! interval 1m tag ec-ldb-s2.processlist query show full processlist; record_hostname yes nest_result no nest_key data #row_count yes #row_count_key row_count </source> <match ec-ldb-s2.processlist> type rename_key remove_tag_prefix ec-ldb-s2. append_tag ec-ldb-s2 rename_rule1 Time duration_time </match> <match processlist.ec-ldb-s2> type copy <store> type stdout </store> <store> type mysql_bulk host ec-ldb-m2 port 19336 database test username root password testpasswd12#$ column_names hostname,Id,User,Host,db,Command,State,Info,duration_time key_names hostname,Id,User,Host,db,Command,State,Info,duration_time table t_mysql_process flush_interval 5s </store> </match>
- 22. 22 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.2 MySQL process list logging Step.4 td-agent ėŽėė $ sudo /etc/init.d/td-agent stop sudo /etc/init.d/td-agent start tail -f /var/log/td-agent/td-agent.log
- 23. 23 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.2 MySQL process list logging Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ $ mysql -u root âp use test; select * from t_mysql_process;
- 24. 24 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
- 25. 25 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.1 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í ėīëļ ėėą $ mysql -u root -p use test; drop table if exists test.log_game_play; create table test.log_game_play ( log_date datetime default current_timestamp , useridx bigint , play_time bigint , char_type varchar(1) , result varchar(1) ); alter table log_game_play add primary key(log_date,useridx); Test.3 Game Log Collect
- 26. 26 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.2 ėė§ëė ėëēëĄ ė ėíėŽ Log í ėīëļ ėėą ë° ë°ėīí° ė ë Ĩ $ mysql -u root -p use test; drop table if exists test.log_game_play; create table test.log_game_play ( log_date datetime default current_timestamp , useridx bigint , play_time bigint , char_type varchar(1) , result varchar(1) ); alter table log_game_play add primary key(log_date,useridx); Test.3 Game Log Collect set @i=0; insert ignore into test.log_game_play select date_sub(now(), interval @i:=@i+1 minute) as log_date , @i , rand()*10000 , mod(@i,10) , mod(@i,3) from mysql.proc limit 100; select date_format(log_date, '%Y%m%d%h') as dt, count(*) from test.log_game_play group by date_format(log_date, '%Y%m%d%h'); select * from test.log_game_play where log_date between date_sub(now(), interval 10 minute) and now();
- 27. 27 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė $ sudo vi /etc/td-agent/td-agent.conf âĶ âĶ <source> type mysql_query host ec-ldb-s2 port 19336 database test username root password 433dlxjsjf12!@! interval 10s tag ec-ldb-s2.log_game_play query select * from test.log_game_play where log_date between date_sub(now(), interval 10 minute) and now(); record_hostname yes nest_result no nest_key data #row_count yes #row_count_key row_count </source> <match ec-ldb-s2.log_game_play> type copy <store> type stdout </store> <store> type mysql_bulk host ec-ldb-m2 port 19336 database test username root password 433dlxjsjf12!@! column_names log_date,useridx,play_time,char_type,result key_names log_date,useridx,play_time,char_type,result table log_game_play on_duplicate_key_update true on_duplicate_update_keys log_date,useridx flush_interval 15s </store> </match> Test.3 Game Log Collect
- 28. 28 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.4 td-agent ėŽėė $ sudo /etc/init.d/td-agent stop sudo /etc/init.d/td-agent start tail -f /var/log/td-agent/td-agent.log Test.3 Game Log Collect
- 29. 29 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ $ mysql -u root âp use test; select * from test.log_game_play; Test.3 Game Log Collect
- 30. 30 Index 1. Intro 2. Install 3. Test ïž MySQL slowquery logging ïž MySQL process list logging ïž Game Log Data Collect ïž Log Server ęĩŽėķ 4. QnA
- 31. 31 Step.1 ėė§ëė ėëēëĄ ė ėíėŽ Fluentd plugin ėĪėđ https://github.com/tagomoris/fluent-plugin-mysql # yum -y install ruby-rdoc ruby-devel rubygems find / -name fluent-gem /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-mysql Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Test.4 Log Server ęĩŽėķ Client Client Client Server Server HAProxy(L4)
- 32. 32 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.2 ėė§ęļ°(Collector) ėëēëĄ ė ėíėŽ Log í ėīëļ ėėą $ mysql -u root -p use test; drop table if exists test.t_log_connect; create table test.t_log_connect ( log_date datetime default current_timestamp , jsondata text ); drop table if exists test.t_log_money; create table test.t_log_money ( log_date datetime default current_timestamp , jsondata text ); Test.4 Log Server ęĩŽėķ
- 33. 33 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.3 ėė§ëė(DB) ėëēëĄ ė ėíėŽ td-agent.conf ėĪė $ sudo vi /etc/td-agent/td-agent.conf âĶ âĶ <source> type http port 8888 body_size_limit 1mb keepalive_timeout 10s </source> <match ec-ldb-s2.t_log_connect> type copy <store> type stdout </store> <store> type mysql host ec-ldb-m2 port 19336 database test username root password testpasswd12#$ table t_log_connect columns jsondata format json flush_interval 5s </store> </match> <match ec-ldb-s2.t_log_money> type copy <store> type stdout </store> <store> type mysql host ec-ldb-m2 port 19336 database test username root password testpasswd12#$ table t_log_money columns jsondata format json flush_interval 5s </store> </match> Test.4 Log Server ęĩŽėķ
- 34. 34 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.4 td-agent ėŽėė $ sudo /etc/init.d/td-agent stop sudo /etc/init.d/td-agent start -- ëĄę·ļ ë°ė curl -X POST -d 'json={"ver":"1.0","action":"login","user":1}' http://localhost:8888/ec-ldb-s2.t_log_connect curl -X POST -d 'json={"ver":"1.0","action":"login","user":1}' http://localhost:8888/ec-ldb-s2.t_log_money tail -f /var/log/td-agent/td-agent.log Test.4 Log Server ęĩŽėķ
- 35. 35 Collector [ec-ldb-m2] Service DB [ec-ldb-s2] Step.5 ėė§ęļ°(Collector) ėëēėė ëĄę·ļ íėļ $ mysql -u root âp use test; select count(*) from test.t_log_money; select count(*) from test.t_log_connect; Test.4 Log Server ęĩŽėķ
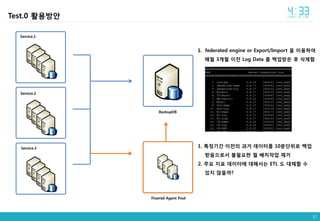
- 37. 37 Test.0 íėĐë°Đė BackupDB Service.1 Service.2 Service.3 1. federated engine or Export/Import ė ėīėĐíėŽ ë§Īė 3ę°ė ėīė Log Data ëĨž ë°ąė ë°ė í ėė íĻ 1. íđė ęļ°ę° ėīė ė ęģžęą° ë°ėīí°ëĨž 10ëķëĻėëĄ ë°ąė ë°ėėžëĄė ëķíėí ė ë°°ėđėė ė ęą° 2. ėĢžė ė§í ë°ėīí°ė ëíīėë ETL ë ëėēīí ė ėė§ ėėęđ? Fluentd Agent Pool
- 38. 38 Reference RubyConf 2014 - Build the Unified Logging Layer with Fluentd and Ruby by Kiyoto Tamura https://www.youtube.com/watch?v=sIVGsQgMHIo
- 39. 39