











贬补诲辞辞辫ことはし?め
- 1. Hadoop ことはじめ
- 2. もくじ 1. はじめに 2. Hadoop アーキテクチャ概要 3. Hadoop を動かす手段 4. Hive
- 3. 1. はじめに
- 4. はじめに ? 「Hadoop 徹底入門」第2版1部 ~ 2部まで読み終 わったので、書籍の内容をかいつまんでご紹介します CDH(Cloudera s Distribution including Apache Hadoop) の利用を前 提に書かれているため、環境構築が簡単(yum一発) Hadoop の基礎知識からクラスタ構成、アプリケー ションの開発方法まで網羅されています 第2版がオススメです(前提知識が拡充されてます)
- 6. Hadoop とは ? 大量のデータを処理するための並列分散処理ソフトウェア ? 既存のバッチ処理の置き換えのみならず、今までできなかったことや諦めて いたことが出来るようになる ? Google 社の論文? "The Google File Ssytem (2003), MapReduce: Simpli?ed Data Processing on Large Clusters (2004)? をもとに OSS として実装を始めたのが Hadoop プロジェクト の始まり ? Hadoop の適用領域 ? 数百GB ~ 数TBなどの大量データのバッチ処理に適している ? 拡張性に優れる(スケールアウトでの処理性能向上) ? 柔軟なデータ構造に対応
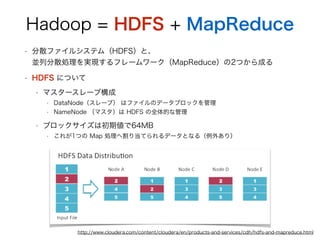
- 7. Hadoop = HDFS + MapReduce ? 分散ファイルシステム(HDFS)と、? 並列分散処理を実現するフレームワーク(MapReduce)の2つから成る ? HDFS について ? マスタースレーブ構成 ? DataNode(スレーブ) はファイルのデータブロックを管理 ? NameNode (マスタ)は HDFS の全体的な管理 ? ブロックサイズは初期値で64MB ? これが1つの Map 処理へ割り当てられるデータとなる(例外あり) http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/hdfs-and-mapreduce.html
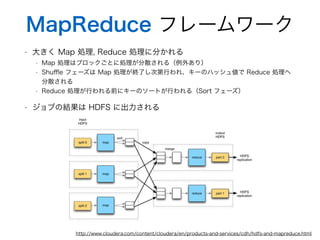
- 8. MapReduce フレームワーク ? 大きく Map 処理, Reduce 処理に分かれる ? Map 処理はブロックごとに処理が分散される(例外あり) ? Shu?e フェーズは Map 処理が終了し次第行われ、キーのハッシュ値で Reduce 処理へ 分散される ? Reduce 処理が行われる前にキーのソートが行われる(Sort フェーズ) ? ジョブの結果は HDFS に出力される http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/hdfs-and-mapreduce.html
- 10. 4つの開発手段 ? Java による開発 ? 柔軟な開発が可能だが、その分記述量も多い ? Java への精通、毎度のコンパイルなど手間や負担が多い ? Hadoop Streaming ? 標準入出力を利用したインタフェース ? 言語を選ばないが、柔軟性は低い ? Apache Pig ? Pig Latin という命令型の言語で処理を記述 ? MapReduce 特有の複雑な処理が隠 される ? アドホックな処理が可能 ? Hive と比べると、パフォーマンスに難点 ? Hive ? SQL ライクな HiveQL と呼ばれる言語で処理を記述できるため、書きやすい ? アドホックな処理が可能
- 11. 4. Hive
- 12. サンプルコード // テーブル定義! CREATE TABLE puella (id STRING, weapon STRING)! ROW FORMAT DELIMITED! FIELDS TERMINATED BY ‘,’! STORED AS TEXTFILE;! CREATE TABLE gem (id STRING, color STRING, turbidity INT)! ROW FORMAT DELIMITED! FIELDS TERMINATED BY ‘,’! STORED AS TEXTFILE;! CREATE TABLE witch (id STRING, weapon STRING, color STRING)! ROW FORMAT DELIMITED! FIELDS TERMINATED BY ‘,’! STORED AS TEXTFILE;! ! // データロード! LOAD DATA LOCAL INPATH ‘/tmp/puella.csv’ INTO TABLE puella;! LOAD DATA LOCAL INPATH ‘/tmp/gem.csv’ INTO TABLE gem;! ! // MapReduce の実行、データの挿入! INSERT OVERWRITE TABLE witch! SELECT puella.id, puella.weapon, gem.color! FROM luella! JOIN gem! ON puella.id = gem.id! WHERE gem.turbidity >= 80;! ! // データ出力! INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/output’ SELECT * FROM witch; どのようなデータ形式で読み込み、 出力するのかを設定 テーブルへデータを流し込む (HDFS 上の特定ディレクトリ へファイルを分割?保存) ローカル / HDFS 上のファイル どちらでも指定可能 テーブルの結果をファイル出力
- 13. SQL と違う点 ? オンライン処理に不向き ? SQL のようだが、裏ではもちろん Hadoop ? 扱うのは HDFS 上のファイルのため、行更新不可 ? クエリの結果をテーブルやファイルに書き出すが、どちらも HDFS 上にファ イルとして書き出される ? 追記は可能(INSERT OVERWRITE を INSERT INTO にする) ? インデックスではなくパーティションでクエリ最適化 ? 特定カラムの特定値でデータファイルを分割する ? SQL の機能が全て使えるわけではない JOIN 句での NOT 条件 WHERE IN, WHERE EXISTS によるサブクエリ UNION (重複判定を行わない UNION ALL は可)
- 14. インデックスではなく パーティションでクエリ最適化 // テーブル定義! CREATE TABLE puella (id STRING, weapon STRING)! PARTITIONED BY (weapon STRING)! ROW FORMAT DELIMITED! FIELDS TERMINATED BY ‘,’! STORED AS TEXTFILE;! . . .! ! // データロード! LOAD DATA LOCAL INPATH ‘/tmp/puella.csv’ INTO TABLE puella! PARTITION (weapon=‘Sword’);! ! // MapReduce の実行、データの挿入! INSERT OVERWRITE TABLE witch! SELECT puella.id, puella.weapon, gem.color! FROM luella! JOIN gem! ON (puella.id = gem.id AND puella.weapon = ‘Sword’)! WHERE gem.turbidity >= 80; weapon カラムによりパーティションを 作成することを宣言 weapon= Sword の行のみを読み込み、 HDFS 上の下記パスへ保存する: /user/hive/warehouse/ <DB名>/<テーブル名>/weapon=Sword/<ファイル名> on 句 や where 句で指定することにより 特定のパーティションのみ読み込むことが可能 (この場合、where 句に条件を指定しても、全件読み込み 後なのでパーティション指定とはならない)