More Related Content Similar to Hadoop(emr) (20)
ż╚żóżļźĘź╣źŲźÓŻ»ķ_░kš▀ż╬╗ņŃń Ęų╔óXxżžż╬Ą└ ż╚żóżļźĘź╣źŲźÓŻ»ķ_░kš▀ż╬╗ņŃń Ęų╔óXxżžż╬Ą└
M S ?
ż╚żĻżóż©ż║Īó═╗╚╗ż│ż╬żóż┐żĻż╦Īóż█ż”żĻż│ż▐żņż┐╔Ē─┌ż╦šh├„ż╣żļĢrż╦╩╣ż├ż┐┘Y┴Žż╦ż┴żńż├ż╚Īó╩ųż“╚ļżņż┐╬’żŪż╣ĪŻ
š²┤_żĄżĶżĻżŌĪóżČż├ż»żĻż╚żĘż┐ļāćņÜ▌ż╚Ī󿬿¬żČż├żčż╩┴„żņųžęĢżŪĪŻĪŻ
ČÓĘųĪóż▀żŲżŌĪóżõż»ż╦ż┐ż┐ż╩żżĪŻĪŻ (??”ž?`)
WDD2012_SC-004 WDD2012_SC-004
Kuninobu SaSaki ?
Windows Developer DaysżŪ╩╣ż├ż┐Hadoop on Windows (Server|Azure)ĮBĮķ┘Y┴ŽżŪż╣ĪŻĪĖįOėŗ?īgū░?╗Ņė├Ę©Ī╣ż╚żżż”ź┐źżź╚źļż╚żŽčYĖ╣ż╦ż┐ż└ż╬Ė┼ę¬ĮBĮķż╦ż╩ż├żŲżĘż▐ż├ż┐ż╬żŪĪóżŌż”╔┘żĘż▐żĘż╩żŌż╬ż“ū„żĻż┐żżż╚╦╝ż├żŲżżż▐ż╣???
Apache Spark ź┴źÕ®`ź╚źĻźóźļ Apache Spark ź┴źÕ®`ź╚źĻźóźļ
K Yamaguchi ?
2015-4-28ż╦¢|▒▒┤¾č¦ Ū¼?ī∙Ųķ蹊┐╩ężŪż¬ż│ż╩ż├ż┐ź┴źÕ®`ź╚źĻźóźļż╬┘Y┴ŽżŪż╣ĪŻ
蹊┐╩ęż╦żŽHadoopź»źķź╣ź┐Ż©CDH5.3Ż®ż¼żóżĻż▐ż╣ĪŻīg“Yżõīg“Yż╬Ū░äI└Ēż╚żżż├ż┐ź┐ź╣ź»żŪżĮż╬ź»źķź╣ź┐ż“└¹ė├ż╣żļż┐żßż╬ź┴źÕ®`ź╚źĻźóźļĪóż╚żżż”Ū░╠ßżŪż╣ĪŻ
(ūĘėø)PMIż╬ėŗ╦ŃżŽżŌż├ż╚īgąąä┐┬╩ż¼żżżż╩ųĒśż¼żóżĻż▐ż╣ĪŻż╚żżż”šh├„ż“╚ļżņ═³żņżŲż▐żĘż┐ĪŻ
(ūĘėø)PMIėŗ╦ŃżŪIntż╚Ģ°żżżŲżóżļ▓┐ĘųżŽ╚½▓┐Longż╬ķg▀`żżżŪżĘż┐ĪŻ
16. ▒ß▓╣╗Õ┤Ū┤Ū▒Ķż╬╠žÅšżŽźėź├ź░źŪ®`ź┐ż╦īØżĘżŲĖ▀╦┘ż╦źąź├ź┴äI└Ēż“ąąż”ż│
ż╚ż╦żóżĻż▐ż╣ĪŻ
żĶż»└¹ė├żĄżņżļż╬żŽĪóźĒź░ż╬ĮŌ╬÷ĪóĘų╬÷żŪż╣ĪŻ
╠žČ©ż╬╠§╝■żŪż╬╝»ėŗżõĪóźµ®`źČż╬ąąäė┬─ÜsĄ╚ż“ĮŌ╬÷ż╣żļż│ż╚żŪĪó
żĮż╬ĮY╣¹ż“źņź│źßź¾ź╔Ą╚ź▐®`ź▒źŲźŻź¾ź░Ą╚ż╦└¹ė├żĘż▐ż╣ĪŻ
╔┘żĘŪ░ż└ż╚ź»ź├ź»źčź├ź╔żĄż¾ĪóūŅĮ³ż└ż╚ź█ź├ź╚ź┌ź├źč®`żĄż¾ż╬┬─
ÜsźŪ®`ź┐ż╬Ęų╬÷ż╦żŌ▒ŠĖ±└¹ė├żĄżņżļżĶż”ż╦ż╩ż├ż┐żĮż”żŪż╣ĪŻ
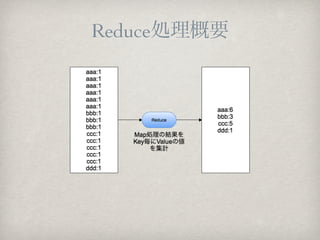
?
?COOKPADż╬╩│▓─ż╬Ś╩╦„źŪ®`ź┐ż“Ąžė“äeĪó▀LäeĪóį┬äeżŪęŖżņżļĪĖż┐ż┘ż▀żļĪ╣
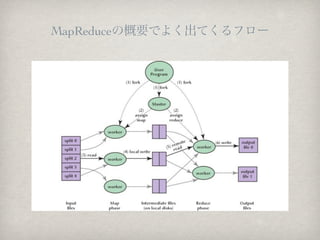
??Mysqlż└ż╚7000ĢrķgŻ©═ŲČ©Ż®ż½ż½żļäI└Ēż¼Īó30Ģrķgż╦Č╠┐sŻĪŻĪ
??http://www.slideshare.net/sasata299/hadoop-in
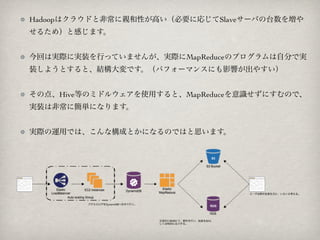
?ź█ź├ź╚ź┌ź├źč®`ż╬└¹ė├┬─ÜsĘų╬÷ż╦Hadoop╗Ņė├
??źßźļź▐ź¼ż╬ż¬ż╣ż╣żßż╬ż¬ĄĻż╬źĻź¾ź»ż╬ź»źĻź├ź»┬╩ż¼1.6▒Čż╦Ž“╔Ž
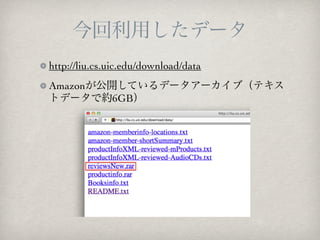
??http://itpro.nikkeibp.co.jp/article/JIREI/20120125/379353/
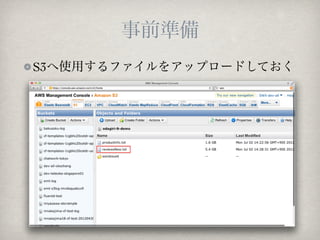
39. ź’®`ź╔ź½ź”ź¾ź╚ż╬ĮY╣¹
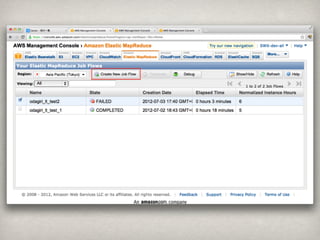
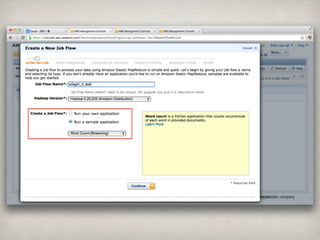
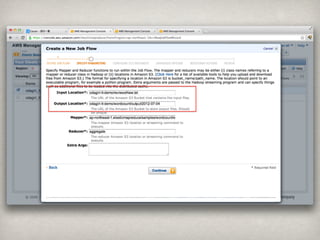
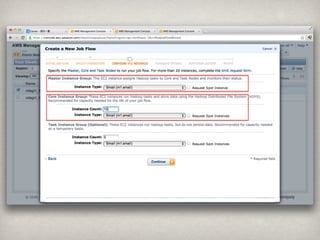
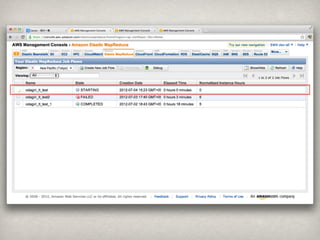
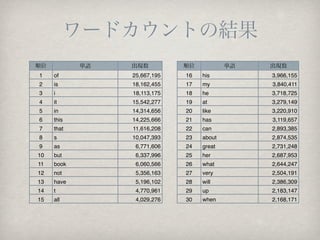
Ēś╬╗ ģgšZ │÷¼F╩² Ēś╬╗ ģgšZ │÷¼F╩²
1 of 25,667,195 16 his 3,966,155
2 is 18,162,455 17 my 3,840,411
3 i 18,113,175 18 he 3,718,725
4 it 15,542,277 19 at 3,279,149
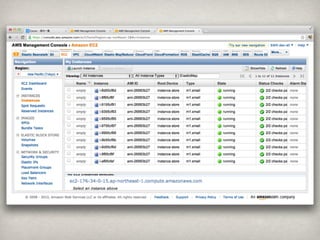
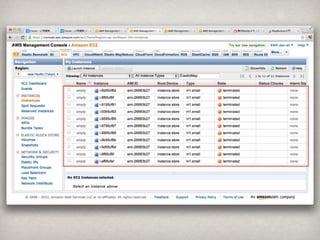
5 in 14,314,656 20 like 3,220,910
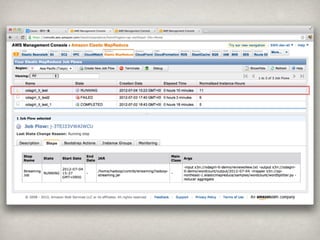
6 this 14,225,666 21 has 3,119,657
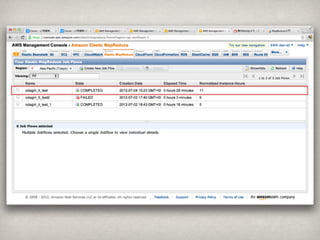
7 that 11,616,208 22 can 2,893,385
8 s 10,047,393 23 about 2,874,535
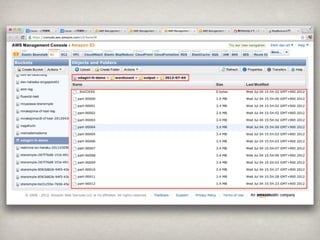
9 as 6,771,606 24 great 2,731,248
10 but 6,337,996 25 her 2,687,953
11 book 6,060,566 26 what 2,644,247
12 not 5,356,163 27 very 2,504,191
13 have 5,196,102 28 will 2,386,309
14 t 4,770,961 29 up 2,183,147
15 all 4,029,276 30 when 2,168,171
Editor's Notes #2: それでは、発表を始めさせて頂きます。宜しくお願いします。\n#3: 本日のアジェンダはこのようになっております。\n#4: まずは、今回、初LTなので簡単に自己紹介をさせて頂きます。\n#5: ちなみに自分の名前の由来は千葉さんが詳しいので、気になる方は千葉さんに聞いてください。\n出身地は、埼玉県行田市です。\n現在住んでいるところは埼玉県川口市です。\nといっても、皆さんどこかよく分からないと思いますので、地図を用意しました。\n#6: これが埼玉県の地図ですが\n#7: 行田市はこちらになります。\n#8: ちなみに、営業チームの中嶋さんのすんでいる熊谷市の隣でして、熊谷同様とても暑いところです。\n#9: 川口市はこちらです。\n今回は、せっかくなので、行田の名物を2つばかり紹介させて頂きます。\n#10: 埼玉の人にはこのCMで有名な十万石まんじゅうです。まあ、普通のまんじゅうです。\n#11: 次がゼリーフライです。どんな物なのか、名前からは想像できないと思います。特にどんな物かここではあえて教えませんので、気になる方は是非、行田に食べに行って頂ければと思います。\n#12: ちなみに、こちらで購入可能です。ただ、ゼリーフライは休日のみの営業で、しかも雨の日以外しか営業しないという緩い感じなので注意が必要です。\n#13: では本題に入らさせて頂きます。まずはHadoopの歴史について簡単に説明させて頂きます。\n#14: Hadoopはgoogleから発表された2つの論文を元に開発が行われていいます。\n1つが、GFSという分散ファイルシステムに関する論文です。こちらはHadoopではHDFSという形で実装されています。\nもう一つが、MapReduceに関する論文でこちらは、論文を元に実装されています。\nなお、実装は、米Yahooが中心となり進められました。\n\nまた、Googleの分散ファイルシステム、分散処理に関してはこちらの本に詳しく書かれています。\n会社にもありますので気になる方は是非呼んでみてください。\n#15: ちなみに、Hadoopという名前の由来なのですが、プロジェクト創始者の子供が持っていた、黄色いゾウのぬいぐるみにつけた名前から取っているそうです。\nなので、Hadoopのロゴは黄色い像になっています。\n#16: では、Hadoopって実際どんなことに使うの?ということで、実例と共に紹介させて頂きます。\n#17: まずHadoopの特徴はビッグデータに対して、高速にバッチ処置を行うことにあります。\nですので、よく利用されるのは、ログデータの解析、分析が多いかと思います。\n\n少し前だと、クックパッドさん、最近だとホットペッパーさんが実際にHadoopを利用しているそうです。\n\n・クックパッドさんは「たべみる」というサービスがあるのですが、その為のデータ集計がMysqlだと、7,000時間かかると見られた処理がHadoopを使用することによって30時間に短縮されたそうです。\n・ホットペッパーさんでは、ホットペッパー利用履歴の分析にHadoopを活用することで、メルマガでの「おすすめのお店リンク」のクリック率が1.6倍に向上したそうです。\n\n#18: 続いて、簡単にHadoopのサーバ構成について説明させて頂きます。\n#19: Hadoopのサーバ構成は非常にシンプルで、JOBのコントロールを行うMasterサーバが1台と実際にJOBを処理するSlaveサーバが複数台存在する構成になります。\n#20: 実際にどのようにJOBが振り分けられるかというと、Masterサーバが各SlaveサーバへJOBの処理依頼を送ります。この時、あるサーバでJOBが失敗した場合は、そのJobは別のサーバへ再度依頼されます。Jobが失敗したサーバへはまた別のJobが割り振られ順次処理が行われて行き、すべてのJOBが完了するまで処理を行います。\n#21: 続いて、Hadoopの一番キモになるMap&Reduce処理に関してです。\n#22: まずは、Map処理についてです。\nMap処理では、入力データをKey:Valueの形に変換します。また、ここでシャッフル処理が実行され、Key:Valueのデータをソートしておきます。\n#23: Reduce処理では、Mapでの結果を集計します。\n\n実際には、もっと複雑な処理を行いますが、すごくシンプルに説明すると、MapReduceはこのような処理を行います。\n#24: こちらは、MapReduce処理の説明でよく目にするフローです。こちらは参考程度に目を通してください。\n#25: 今回は簡単にMapReduceを説明しましたが、実際に実装を行おうとすると、結構大変です。\nパフォーマンスが思うように出なかったり、そもそもMapReduceをちゃんと理解するには結構時間がかかるかと思います。\nそこで、HadoopにはMapReduceを隠蔽してくれる便利なミドルウェアがいくつかあります。\n\n#26: Pig、Hbase、Zookeeper、Hiveと様々なミドルウェアが存在します。\n最近、AWSのブログで、Hive0.8.1が利用可能になったと発表がありました。\n自分が以前Hadoopの実装を行った際もHiveを利用してシステムの構築を行っています。\n\n#27: では、実際にHadoopを使ってみたいと思います。ただ、時間がかかるため今回はデモという形ではなく、どのように使ったかと、その結果について紹介します。\n\n#28: 今回はAWSのEMRを使用します。\n使用したデータは、Amazonが公開しているレビューデータのアーカイブを使用して、ワードカウントを行っています。\n#29: まずは事前にS3へ使用するデータを上げておきます。\n#30: 実際にEMRを使用するにはAWSのマネージメントコンソールより[ElasticMapReduce]を選択し、「Create New Job Flow」をクリックします。\n#31: ウィザードが起動しますので、ジョブの名前を指定します。\nまた、今回はAWSで提供されているワードカウントプログラムを選択します。\n\n#32: 次に、先ほどS3にあげたデータをInputLocationへ指定します。\nあと、処理結果が出力される場所をOutputLocationへ指定します。\n#33: あとは、Masterサーバのインスタンスサイズ、スレーブサーバの台数とインスタンスを指定して、完了です。\n今回は、スレーブサーバを10台使用しています。\n#34: 処理が開始されますと、このようにジョブの表示が行われStateが「Starting」になっていることが確認できます。\n#35: EC2のインスタンス一覧を見ますと、このように指定した台数分(Master1台+Slave10台で11台)起動していることが分かります。\n#36: ElasticMapReduceのタブを見ますと、Stateが「Running」になり、処理が実行されていることが分かります。\n#37: しばらく待ちますと、Stateが「Completed」になり処理が完了していることが分かります。\n今回は29分処理に時間がかかったことが分かります。 \n#38: なお、ElasticMapReduceの処理が完了しますと、EC2のインスタンスは自動的に停止します。\n#39: 次に、S3のバケットを確認しますと、OutputLocationで指定したフォルダに処理結果が出力されます。\n#40: なお、今回の結果はこんな感じでした。\n一般的な単語がやはり多く使用されているようで、あまり面白くない結果となりました。\n#41: ではまとめに入ります。\n\n#42: ・Hadoopは必要に応じてサーバの台数を変更できるため、クラウドと非常に親和性が高いと感じます。\n・また、Hive等のミドルウェアが豊富にあり、Map&Reduceを意識せずに開発を行うことが出来るのは非常に便利です。\n\n・今回は、AWSのサンプルスクリプトを利用しましたが、今後は別の形でMapReduce、Hiveの実装を行って検証をしてみたいと思います。\n・個人的にはEMRには非常に可能性を感じているので、皆さんも是非いろいろ試してもらえたらと思います。\n\n・なお、実際のシステムではこんな構成が考えられるかなと思います。\n\n#43: 以上となります。\nご清聴ありがとうございました。\n