Introduction to Apache Tajo
41 likes3,532 views

2015ļģä 9ņøö Tajo TechTalk ļ░£Ēæ£ ņ×ÉļŻī (ņĀĢņ×¼ĒÖö ņłśņäØ) - Tajo ņåīĻ░£ ļ░Å ĒĢĄņŗ¼ ĻĖ░ļŖź - Tajo vs Spark - ļĪ£ļō£ļ¦Ą ļ░Å ņĀüņÜ® ņé¼ļĪĆ


















Introduction to Apache Tajo
- 1. Introduction to Apache Tajo ņĀĢņ×¼ĒÖö ņłśņäØ ņŚ░ĻĄ¼ņøÉ / ĻĘĖļŻ©Ēä░
- 2. About me ŌĆó Gruter Corp / BigData Engineer ŌĆó Apache Tajo Committer ŌĆó jhjung@gruter.com ŌĆó Home Page: http://blrunner.com ŌĆó Twitter: @blrunner78 ŌĆó The author of Hadoop book
- 3. ļ¬®ņ░© 1. Tajo Ļ░£ņÜö 2. ĒĢĄņŗ¼ ĻĖ░ļŖź 3. Tajo vs Spark 4. ļ▓żņ╣śļ¦łĒü¼ Ļ▓░Ļ│╝ 5. ļĪ£ļō£ļ¦Ą 6. ņĀüņÜ® ņé¼ļĪĆ
- 5. 5 1.1 Tajoļ×Ć? ŌĆó ĒĢśļæĪ ĻĖ░ļ░śņØś ļ╣ģļŹ░ņØ┤Ēä░ ņø©ņ¢┤ĒĢśņÜ░ņŖż ņŗ£ņŖżĒģ£ ŌĆó 2013ļģä ņĢäĒīīņ╣ś ņØĖĒüÉļ▓ĀņØ┤ņģś, 2014ļģä ņĢäĒīīņ╣ś ĒāæļĀłļ▓© ĒöäļĪ£ņĀØĒŖĖ ŌĆó ANSI SQL ņ¦ĆņøÉ ŌĆó ņŻ╝ņÜö ĒŖ╣ņ¦Ģ ŌĆō ņ×Éņ▓┤ Ļ│Āņä▒ļŖź ļČäņé░ ņ▓śļ”¼ ņŚöņ¦ä (Not MapReduce) ŌĆō ļŗżņ¢æĒĢ£ ņ┐╝ļ”¼ ņĄ£ņĀüĒÖö ĻĖ░ļ▓Ģ ļ░Å ņĢīĻ│Āļ”¼ņ”ś ņĀüņÜ® ŌĆō ņłśņŗ£Ļ░ä ņØ┤ņāü ņŗżĒ¢ēļÉśļŖö ETL ņ┐╝ļ”¼ ņ¦ĆņøÉ ŌĆō ņłśļ░▒ ļ░Ćļ”¼ņäĖņ╗©ļō£ ņØ┤ļé┤ ņŗżĒ¢ēļÉśļŖö ņØĖĒä░ļ×ÖĒŗ░ļĖī ņ┐╝ļ”¼ ņ¦ĆņøÉ
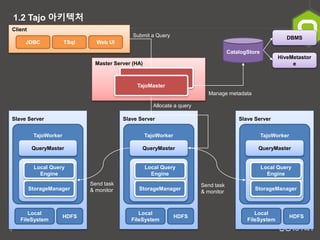
- 6. 6 1.2 Tajo ņĢäĒéżĒģŹņ▓ś Master Server (HA) Client JDBC TSql Web UI CatalogStore DBMS HiveMetastor e Submit a Query Manage metadata Allocate a query Send task & monitor Send task & monitor Slave Server TajoWorker QueryMaster Local FileSystem HDFS Local Query Engine StorageManager Slave Server TajoWorker QueryMaster Local FileSystem HDFS Local Query Engine StorageManager Slave Server TajoWorker QueryMaster Local FileSystem HDFS Local Query Engine StorageManager TajoMaster TajoMaster
- 7. 7 1.3 Tajo ļ╣äĻĄÉņÜ░ņ£ä ŌĆó ANSI SQL ņ¦ĆņøÉ - ĒĢÖņŖĄļ╣äņÜ® ņĄ£ņåīĒÖö ļ░Å ĻĖ░ņĪ┤ ņŗ£ņŖżĒģ£ņØś ņĀäĒÖś ņÜ®ņØ┤ - ļ╣äĒæ£ņżĆ SQLņØś Ļ▓ĮņÜ░, OracleĻ│╝ PostgreSQLņØä ņ░ĖĻ│Ā ŌĆó Ēü┤ļ¤¼ņŖżĒä░ ĒÖĢņןņä▒ - ņłśņ▓£ļīĆ ļģĖļō£Ļ╣īņ¦Ć ĒÖĢņן Ļ░ĆļŖźĒĢ© ŌĆó Ļ│Āņä▒ļŖź ļČäņé░ ņ▓śļ”¼ ņŚöņ¦ä - ņŖżņ║öņåŹļÅä: ļ¼╝ļ”¼ņĀü ļööņŖżĒü¼ļŗ╣ 100MB/sec (SATA ĻĖ░ņżĆ) - 1TBļź╝ 10 ņŚ¼ļīĆņØś ļģĖļō£ļĪ£ ņ▓śļ”¼ ’ā╝ Ļ░äļŗ©ĒĢ£ aggregation ņ┐╝ļ”¼: 30ņ┤ł ~ 1ļČä ļé┤ņÖĖ ’ā╝ Ļ░äļŗ©ĒĢ£ join ņ┐╝ļ”¼: 1 ~ 2 ļČä ļé┤ņÖĖ ’ā╝ ļ│Ąņ×ĪĒĢ£ join ļ░Å distinct aggregation : ņłś ļČäņŚÉņä£ 10ņŚ¼ļČä
- 9. 9 2.1 SQL ņä▒ņłÖļÅä ņ×Éņ▓┤ ļČäņé░ ņ▓śļ”¼ ņŚöņ¦äņØä ņØ┤ņÜ®ĒĢśņŚ¼, ņāüļŗ╣ņłś ņ┐╝ļ”¼ ļČäņé░ ņŗżĒ¢ē ņ¦ĆņøÉ ĻĖ░ņĪ┤ ļŹ░ņØ┤Ēä░ ĒāĆņ×ģ ļ░Å ĒīīņØ╝ Ēżļ¦ĘĻ│╝ ĒśĖĒÖś ŌĆó ņ¦łņØś ļČäņé░ ņ▓śļ”¼ - Inner join, and left/right/full outer join - Groupby, sort, multiple distinct aggregation - window function ŌĆó SQL ļŹ░ņØ┤Ēä░ ĒāĆņ×ģ - CHAR, BOOL, INT, DOUBLE, TEXT, DATE, Etc ŌĆó ļŗżņ¢æĒĢ£ ĒīīņØ╝ Ēżļ¦Ę - Text file (CSV), SequenceFile, RCFile, ORC, Parquet, Avro
- 10. 10 2.2 ņ┐╝ļ”¼ ņĄ£ņĀüĒÖö ŌĆó Cost-based Join Optimization (Greedy Heuristic) - ņé¼ņÜ®ņ×ÉĻ░Ć ņĄ£ņäĀņØś Join ņł£ņä£ļź╝ ņČöņĖĪĒĢśļŖö ņłśĻ│Ā ņĀ£Ļ▒░ ŌĆó ĒÖĢņן Ļ░ĆļŖźĒĢ£ rewrite rule ņŚöņ¦ä - rewrite rule ņØĖĒä░ĒÄśņØ┤ņŖż ņĀ£Ļ│ĄĻ│╝ ļŗżņ¢æĒĢ£ ņ£ĀĒŗĖļ”¼Ēŗ░ ņĀ£Ļ│Ą ŌĆó ņĀÉņ¦äņĀü ņ┐╝ļ”¼ ņĄ£ņĀüĒÖö (Progressive Query Optimization) - ņŗżĒ¢ē ņŗ£Ļ░ä ĒåĄĻ│ä ņłśņ¦æ - ļČäņé░ ņĀĢļĀ¼ņØä ņ£äĒĢ£ ļ▓öņ£ä ļČäĒĢĀ (range partitioning)ņØś ņĀüņĀłĒĢ£ ĒīīĒŗ░ņģś ļ▓öņ£ä, Ļ░£ņłś ļō▒ņØä ļ¤░ĒāĆņ×äņŚÉ ņĪ░ņĀĢ - ļČäņé░ Join, ĻĘĖļŻ╣ļ░öņØ┤ļź╝ ņ£äĒĢ£ ĒīīĒŗ░ņģś Ļ░£ņłśļź╝ ļ¤░ĒāĆņ×äņŚÉ ņĪ░ņĀĢ
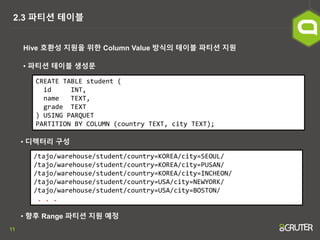
- 11. 11 2.3 ĒīīĒŗ░ņģś ĒģīņØ┤ļĖö ŌĆó ĒīīĒŗ░ņģś ĒģīņØ┤ļĖö ņāØņä▒ļ¼Ė CREATE TABLE student ( id INT, name TEXT, grade TEXT ) USING PARQUET PARTITION BY COLUMN (country TEXT, city TEXT); /tajo/warehouse/student/country=KOREA/city=SEOUL/ /tajo/warehouse/student/country=KOREA/city=PUSAN/ /tajo/warehouse/student/country=KOREA/city=INCHEON/ /tajo/warehouse/student/country=USA/city=NEWYORK/ /tajo/warehouse/student/country=USA/city=BOSTON/ . . . Hive ĒśĖĒÖśņä▒ ņ¦ĆņøÉņØä ņ£äĒĢ£ Column Value ļ░®ņŗØņØś ĒģīņØ┤ļĖö ĒīīĒŗ░ņģś ņ¦ĆņøÉ ŌĆó ļööļĀēĒä░ļ”¼ ĻĄ¼ņä▒ ŌĆó Ē¢źĒøä Range ĒīīĒŗ░ņģś ņ¦ĆņøÉ ņśłņĀĢ
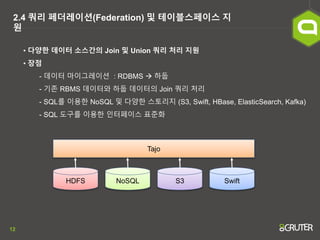
- 12. 12 2.4 ņ┐╝ļ”¼ ĒÄśļŹöļĀłņØ┤ņģś(Federation) ļ░Å ĒģīņØ┤ļĖöņŖżĒÄśņØ┤ņŖż ņ¦Ć ņøÉ ŌĆó ļŗżņ¢æĒĢ£ ļŹ░ņØ┤Ēä░ ņåīņŖżĻ░äņØś Join ļ░Å Union ņ┐╝ļ”¼ ņ▓śļ”¼ ņ¦ĆņøÉ ŌĆó ņןņĀÉ - ļŹ░ņØ┤Ēä░ ļ¦łņØ┤ĻĘĖļĀłņØ┤ņģś : RDBMS ’āĀ ĒĢśļæĪ - ĻĖ░ņĪ┤ RBMS ļŹ░ņØ┤Ēä░ņÖĆ ĒĢśļæĪ ļŹ░ņØ┤Ēä░ņØś Join ņ┐╝ļ”¼ ņ▓śļ”¼ - SQLļź╝ ņØ┤ņÜ®ĒĢ£ NoSQL ļ░Å ļŗżņ¢æĒĢ£ ņŖżĒåĀļ”¼ņ¦Ć (S3, Swift, HBase, ElasticSearch, Kafka) - SQL ļÅäĻĄ¼ļź╝ ņØ┤ņÜ®ĒĢ£ ņØĖĒä░ĒÄśņØ┤ņŖż Ēæ£ņżĆĒÖö HDFS NoSQL S3 Swift Tajo
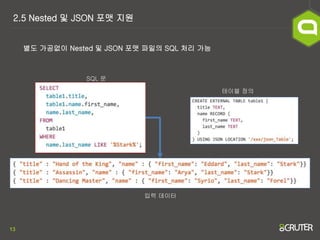
- 13. 13 2.5 Nested ļ░Å JSON Ēżļ¦Ę ņ¦ĆņøÉ ļ│äļÅä Ļ░ĆĻ│ĄņŚåņØ┤ Nested ļ░Å JSON Ēżļ¦Ę ĒīīņØ╝ņØś SQL ņ▓śļ”¼ Ļ░ĆļŖź ņ×ģļĀź ļŹ░ņØ┤Ēä░ ĒģīņØ┤ļĖö ņĀĢņØś SQL ļ¼Ė
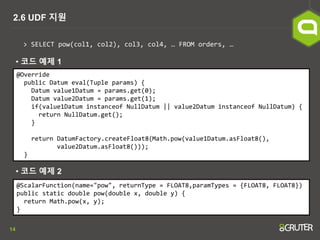
- 14. 14 2.6 UDF ņ¦ĆņøÉ > SELECT pow(col1, col2), col3, col4, ŌĆ” FROM orders, ŌĆ” @Override public Datum eval(Tuple params) { Datum value1Datum = params.get(0); Datum value2Datum = params.get(1); if(value1Datum instanceof NullDatum || value2Datum instanceof NullDatum) { return NullDatum.get(); } return DatumFactory.createFloat8(Math.pow(value1Datum.asFloat8(), value2Datum.asFloat8())); } @ScalarFunction(name="pow", returnType = FLOAT8,paramTypes = {FLOAT8, FLOAT8}) public static double pow(double x, double y) { return Math.pow(x, y); } ŌĆó ņĮöļō£ ņśłņĀ£ 1 ŌĆó ņĮöļō£ ņśłņĀ£ 2
- 15. 3. Tajo vs Spark
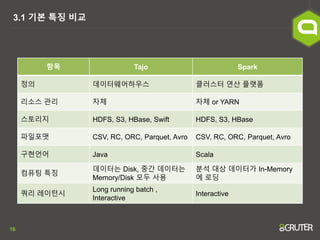
- 16. 16 3.1 ĻĖ░ļ│Ė ĒŖ╣ņ¦Ģ ļ╣äĻĄÉ ĒĢŁļ¬® Tajo Spark ņĀĢņØś ļŹ░ņØ┤Ēä░ņø©ņ¢┤ĒĢśņÜ░ņŖż Ēü┤ļ¤¼ņŖżĒä░ ņŚ░ņé░ Ēöīļ×½ĒÅ╝ ļ”¼ņåīņŖż Ļ┤Ćļ”¼ ņ×Éņ▓┤ ņ×Éņ▓┤ or YARN ņŖżĒåĀļ”¼ņ¦Ć HDFS, S3, HBase, Swift HDFS, S3, HBase ĒīīņØ╝Ēżļ¦Ę CSV, RC, ORC, Parquet, Avro CSV, RC, ORC, Parquet, Avro ĻĄ¼Ēśäņ¢Ėņ¢┤ Java Scala ņ╗┤Ēō©Ēīģ ĒŖ╣ņ¦Ģ ļŹ░ņØ┤Ēä░ļŖö Disk, ņżæĻ░ä ļŹ░ņØ┤Ēä░ļŖö Memory/Disk ļ¬©ļæÉ ņé¼ņÜ® ļČäņäØ ļīĆņāü ļŹ░ņØ┤Ēä░Ļ░Ć In-Memory ņŚÉ ļĪ£ļö® ņ┐╝ļ”¼ ļĀłņØ┤Ēä┤ņŗ£ Long running batch , Interactive Interactive
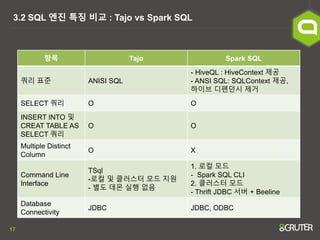
- 17. 17 3.2 SQL ņŚöņ¦ä ĒŖ╣ņ¦Ģ ļ╣äĻĄÉ : Tajo vs Spark SQL ĒĢŁļ¬® Tajo Spark SQL ņ┐╝ļ”¼ Ēæ£ņżĆ ANISI SQL - HiveQL : HiveContext ņĀ£Ļ│Ą - ANSI SQL: SQLContext ņĀ£Ļ│Ą, ĒĢśņØ┤ļĖī ļööĒÄ£ļŹśņŗ£ ņĀ£Ļ▒░ SELECT ņ┐╝ļ”¼ O O INSERT INTO ļ░Å CREAT TABLE AS SELECT ņ┐╝ļ”¼ O O Multiple Distinct Column O X Command Line Interface TSql -ļĪ£ņ╗¼ ļ░Å Ēü┤ļ¤¼ņŖżĒä░ ļ¬©ļō£ ņ¦ĆņøÉ - ļ│äļÅä ļŹ░ļ¬¼ ņŗżĒ¢ē ņŚåņØī 1. ļĪ£ņ╗¼ ļ¬©ļō£ - Spark SQL CLI 2. Ēü┤ļ¤¼ņŖżĒä░ ļ¬©ļō£ - Thrift JDBC ņä£ļ▓ä + Beeline Database Connectivity JDBC JDBC, ODBC
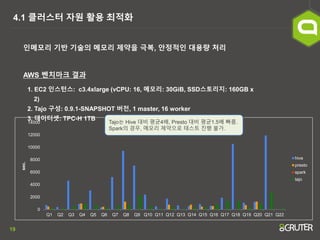
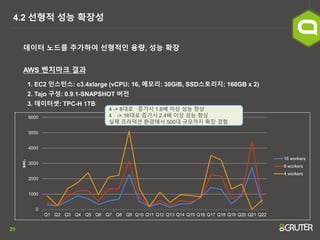
- 19. 19 4.1 Ēü┤ļ¤¼ņŖżĒä░ ņ×ÉņøÉ ĒÖ£ņÜ® ņĄ£ņĀüĒÖö ņØĖļ®öļ¬©ļ”¼ ĻĖ░ļ░ś ĻĖ░ņłĀņØś ļ®öļ¬©ļ”¼ ņĀ£ņĢĮņØä ĻĘ╣ļ│Ą, ņĢłņĀĢņĀüņØĖ ļīĆņÜ®ļ¤ē ņ▓śļ”¼ 1. EC2 ņØĖņŖżĒä┤ņŖż: c3.4xlarge (vCPU: 16, ļ®öļ¬©ļ”¼: 30GiB, SSDņŖżĒåĀļ”¼ņ¦Ć: 160GB x 2) 2. Tajo ĻĄ¼ņä▒: 0.9.1-SNAPSHOT ļ▓äņĀä, 1 master, 16 worker 3. ļŹ░ņØ┤Ēä░ņģŗ: TPC-H 1TB AWS ļ▓żņ╣śļ¦łĒü¼ Ļ▓░Ļ│╝ 0 2000 4000 6000 8000 10000 12000 14000 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20 Q21 Q22 sec. hive presto spark tajo TajoļŖö Hive ļīĆļ╣ä ĒÅēĻĘĀ4ļ░░, Presto ļīĆļ╣ä ĒÅēĻĘĀ1.5ļ░░ ļ╣Āļ”ä. SparkņØś Ļ▓ĮņÜ░, ļ®öļ¬©ļ”¼ ņĀ£ņĢĮņ£╝ļĪ£ ĒģīņŖżĒŖĖ ņ¦äĒ¢ē ļČłĻ░Ć.
- 20. 20 4.2 ņäĀĒśĢņĀü ņä▒ļŖź ĒÖĢņןņä▒ ļŹ░ņØ┤Ēä░ ļģĖļō£ļź╝ ņČöĻ░ĆĒĢśņŚ¼ ņäĀĒśĢņĀüņØĖ ņÜ®ļ¤ē, ņä▒ļŖź ĒÖĢņן 1. EC2 ņØĖņŖżĒä┤ņŖż: c3.4xlarge (vCPU: 16, ļ®öļ¬©ļ”¼: 30GiB, SSDņŖżĒåĀļ”¼ņ¦Ć: 160GB x 2) 2. Tajo ĻĄ¼ņä▒: 0.9.1-SNAPSHOT ļ▓äņĀä 3. ļŹ░ņØ┤Ēä░ņģŗ: TPC-H 1TB AWS ļ▓żņ╣śļ¦łĒü¼ Ļ▓░Ļ│╝ 0 1000 2000 3000 4000 5000 6000 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20 Q21 Q22 sec. 16 workers 8 workers 4 workers 4 -> 8ļīĆļĪ£ ņ”ØĻ░Ćņŗ£ 1.6ļ░░ ņØ┤ņāü ņä▒ļŖź Ē¢źņāü 4 -> 16ļīĆļĪ£ ņ”ØĻ░Ćņŗ£ 2.4ļ░░ ņØ┤ņāü ņä▒ļŖź Ē¢źņāü ņŗżņĀ£ Ēöäļ¤¼ļŹĢņģś ĒÖśĻ▓ĮņŚÉņä£ 500ļīĆ ĻĘ£ļ¬©Ļ╣īņ¦Ć ĒÖĢņן Ļ▓ĮĒŚś
- 21. 5. ļĪ£ļō£ļ¦Ą
- 22. 22 5.1 0.11.0 ļ▓äņĀä ŌĆó ļ”┤ļ”¼ņ”ł : 2015ļģä 9ņøö ņśłņĀĢ ŌĆó ĒĢĄņŗ¼ ĻĖ░ļŖź ŌæĀ ļ®ĆĒŗ░Ēģīļäīņŗ£(Multi-tenancy) ņŖżņ╝Ćņź┤ļ¤¼ ŌæĪ ĒģīņØ┤ļĖöņŖżĒÄśņØ┤ņŖż Ōæó Nested Ēżļ¦Ę ņ¦ĆņøÉ ŌæŻ IN ņä£ļĖīņ┐╝ļ”¼ ņ¦ĆņøÉ Ōæż ALTER TABLE ADD/DROP PARTITION ņ¦ĆņøÉ Ōæź ORC Ēżļ¦Ę ņ¦ĆņøÉ Ōæ” ĒīīņØ┤ņŹ¼ UDF/UDAF ņ¦ĆņøÉ
- 23. 23 5.2 0.11.0 ņØ┤Ēøä ļĪ£ļō£ļ¦Ą ŌæĀ YARN ņ¦ĆņøÉ ŌæĪ ņé¼ņÜ®ņ×É ņØĖņ”Ø ņ¦ĆņøÉ Ōæó Scalar ļ░Å Exist ņä£ļĖīņ┐╝ļ”¼ ņ¦ĆņøÉ ŌæŻ ņ×Éļ░ö ņŖżĒü¼ļ”ĮĒŖĖ ĻĖ░ļ░ś Stored Procedure ņ¦ĆņøÉ Ōæż ļé┤Ļ│Āņןņä▒ (Fault Tolerance) Ōæź ĒĢśņØ┤ļĖī UDF ĒśĖĒÖś Ōæ” Map ĒāĆņ×ģ ļ░Å Array ĒāĆņ×ģ ņ¦ĆņøÉ Ōæ¦ ņŖżĒéżļ¦łļ”¼ņŖż(Schema-less) ļŹ░ņØ┤Ēä░ Ēżļ¦Ę ņ¦ĆņøÉ Ōæ© WITH ņĀł ņ¦ĆņøÉ Ōæ® ĒīīņØ┤ņŹ¼ ļ░Å C++ Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖ ņ¦ĆņøÉ
- 24. 6. ņĀüņÜ® ņé¼ļĪĆ
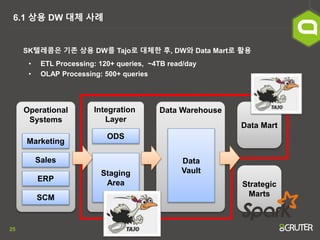
- 25. 25 6.1 ņāüņÜ® DW ļīĆņ▓┤ ņé¼ļĪĆ SKĒģöļĀłņĮżņØĆ ĻĖ░ņĪ┤ ņāüņÜ® DWļź╝ TajoļĪ£ ļīĆņ▓┤ĒĢ£ Ēøä, DWņÖĆ Data MartļĪ£ ĒÖ£ņÜ® ŌĆó ETL Processing: 120+ queries, ~4TB read/day ŌĆó OLAP Processing: 500+ queries Operational Systems Integration Layer Data Warehouse Data Mart Marketing Sales ERP SCM ODS Staging Area Strategic Marts Data Vault
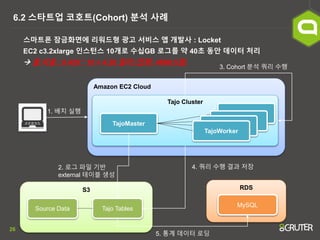
- 26. 26 6.2 ņŖżĒāĆĒŖĖņŚģ ņĮöĒśĖĒŖĖ(Cohort) ļČäņäØ ņé¼ļĪĆ ņŖżļ¦łĒŖĖĒÅ░ ņ×ĀĻĖłĒÖöļ®┤ņŚÉ ļ”¼ņøīļō£ĒśĢ Ļ┤æĻ│Ā ņä£ļ╣äņŖż ņĢ▒ Ļ░£ļ░£ņé¼ : Locket EC2 c3.2xlarge ņØĖņŖżĒä┤ņŖż 10Ļ░£ļĪ£ ņłśņŗŁGB ļĪ£ĻĘĖļź╝ ņĢĮ 40ņ┤ł ļÅÖņĢł ļŹ░ņØ┤Ēä░ ņ▓śļ”¼ ’āĀ ņ┤Ø ļ╣äņÜ® : 0.420 * 10 = 4.20 ļŗ¼ļ¤¼ (ĒĢ£ĒÖö: 4898.5ņøÉ) Amazon EC2 Cloud Tajo Cluster TajoWorker TajoMaster TajoWorker TajoWorker TajoWorker S3 Source Data Tajo Tables RDS MySQL 1. ļ░░ņ╣ś ņŗżĒ¢ē 2. ļĪ£ĻĘĖ ĒīīņØ╝ ĻĖ░ļ░ś external ĒģīņØ┤ļĖö ņāØņä▒ 3. Cohort ļČäņäØ ņ┐╝ļ”¼ ņłśĒ¢ē 4. ņ┐╝ļ”¼ ņłśĒ¢ē Ļ▓░Ļ│╝ ņĀĆņן 5. ĒåĄĻ│ä ļŹ░ņØ┤Ēä░ ļĪ£ļö®
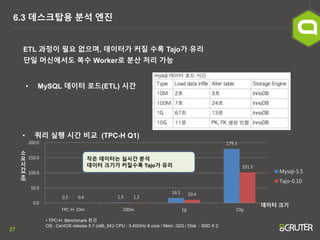
- 27. 27 6.3 ļŹ░ņŖżĒü¼ĒāæņÜ® ļČäņäØ ņŚöņ¦ä ETL Ļ│╝ņĀĢņØ┤ ĒĢäņÜö ņŚåņ£╝ļ®░, ļŹ░ņØ┤Ēä░Ļ░Ć ņ╗żņ¦ł ņłśļĪØ TajoĻ░Ć ņ£Āļ”¼ ļŗ©ņØ╝ ļ©ĖņŗĀņŚÉņä£ļÅä ļ│Ąņłś WorkerļĪ£ ļČäņé░ ņ▓śļ”¼ Ļ░ĆļŖź ŌĆó MySQL ļŹ░ņØ┤Ēä░ ļĪ£ļō£(ETL) ņŗ£Ļ░ä 0.3 1.5 16.5 179.3 0.4 1.2 10.4 101.5 0.0 50.0 100.0 150.0 200.0 TPC-H 10m 100m 1g 10g Mysql-5.5 Tajo-0.10 ņåī ņÜö ņŗ£ Ļ░ä ( ņ┤ł ) ļŹ░ņØ┤Ēä░ Ēü¼ĻĖ░ ŌĆó ņ┐╝ļ”¼ ņŗżĒ¢ē ņŗ£Ļ░ä ļ╣äĻĄÉ (TPC-H Q1) ŌĆó TPC-H Benchmark ĒÖśĻ▓Į OS : CentOS release 5.7 (x86_64)/ CPU : 3.40GHz 8 core / Mem :32G / Disk : SSD X 2 ņ×æņØĆ ļŹ░ņØ┤Ēä░ļŖö ņŗżņŗ£Ļ░ä ļČäņäØ ļŹ░ņØ┤Ēä░ Ēü¼ĻĖ░Ļ░Ć ņ╗żņ¦łņłśļĪØ TajoĻ░Ć ņ£Āļ”¼
- 28. 28 6.4 ļŗżņ¢æĒĢ£ ļČäņäØ ļÅäĻĄ¼ņÖĆ ĒåĄĒĢ® ĒÖśĻ▓Į ņĀ£Ļ│Ą ŌĆó JDBC ĻĖ░ļ░ś ņāüņÜ® OLAP ļÅäĻĄ¼: Birst, Spotfire ŌĆó JDBC ĻĖ░ļ░ś ņøīĒü¼ļ▓żņ╣ś ļÅäĻĄ¼: DbVisualizer, SQLWorkbench J, Flamingo ŌĆó ļŹ░ņØ┤Ēä░ ņé¼ņØ┤ņ¢ĖņŖż ļÅäĻĄ¼: Zeppelin ŌĆó DB ĒśæņŚģĒł┤: ņś¼ņ▒ÖņØ┤(Tedpole DB hub)
- 29. Welcome to Tajo 1. Homepage: http://tajo.apache.org 2. ĒĢ£ĻĄŁ ĒāĆņĪ░ ņé¼ņÜ®ņ×É ĻĘĖļŻ╣ - ĻĄ¼ĻĖĆ ĻĘĖļŻ╣: https://groups.google.com/forum/#!forum/tajo-user-kr - ĒÄśņØ┤ņŖżļČü: https://www.facebook.com/groups/tajokorea/ 3. ĒāĆņĪ░ ĒĢ£ĻĖĆ ļ¼Ėņä£ĒÖö ĒöäļĪ£ņĀØĒŖĖ: http://bit.ly/1Ir417T 4. ĻĖ░ĒāĆ ņ░ĖĻ│Ā ņé¼ņØ┤ĒŖĖ - http://www.gruter.com/blog/tag/apache-tajo - http://teamblog.gruter.com/tag/apache-tajo - http://blrunner.com/category/Development/Tajo
- 30. Q&A
- 31. GRUTER: YOUR PARTNER IN THE BIG DATA REVOLUTION Phone +82-2-508-5911 Fax +82-2-508-5912 E-mail contact@gruter.com Web www.gruter.com
Editor's Notes
- #18: Join ņ▓śļ”¼ Join ņĄ£ņĀüĒÖö ņ¦ĆņøÉ, ļŗżņ¢æĒĢ£ ļ░®ņŗØņØś Join ņ¦ĆņøÉ Join ņĄ£ņĀüĒÖö ļ»Ėņ¦ĆņøÉ, Hash Join ņ¦ĆņøÉ