„Ó„ø„Ķ„¹»łµAÖv׳£ŗ½yÓѧČėéT introduction to statistics
0 likes62 views

„Ó„ø„Ķ„¹»łµAÖv׳£ŗ½yÓѧČėéT introduction to statistics

















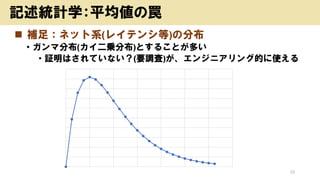
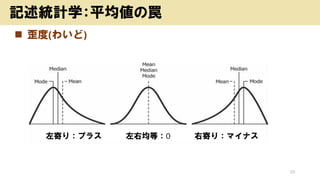
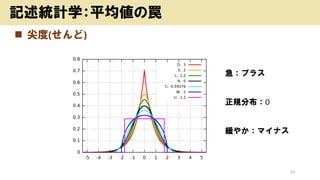




![? ČėĮ¦
? ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)¤ĪĘ½¾łÉķéL¤¬157.5cm”¢ĖŹĘ«²ī5.4cm¤Ē¤¢¤ėöŗĻ”¢ČÕ
±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤ĒÓčy¤¹¤ė¤Č¤É¤Ī¹ ģ¤Ė¤Ź¤ė£æ
? »Ų“š
? ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)¤ĪĘ½¾łÉķéL¤¬157.5cm”¢ĖŹĘ«²ī¤¬5.4cm¤ĪÕżŅ·Ö²¼¤ņ
¢¶Ø¤·¤Ž¤¹”£95%¤ĪŠÅīmĒųég¤ņĒó¤į¤ė¤æ¤į¤Ė”¢ŅŌĻĀ¤ĪÓĖć¤ņŠŠ¤¤¤Ž¤¹”£
? 95%¤ĪŠÅīmĒųég¤Ļ”¢Ę½¾ł¤«¤é×óÓŅ¤ĖĖŹĘ«²ī¤Ī1.96±¶¤ņæ¼]¤·¤æ¹ ģ¤Ė¤Ź
¤ź¤Ž¤¹”£ĖŹĘ«²ī¤¬5.4cm¤Ź¤Ī¤Ē”¢1.96±¶¤¹¤ė¤Č¼s10.584cm¤Ė¤Ź¤ź¤Ž¤¹”£
? ¤·¤æ¤¬¤Ć¤Ę”¢ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤Ī“_ĀŹ¤ĒÓčy¤¹¤ė¤Č”¢
Ę½¾łÉķéL¤«¤é10.584cm¤ņÉĻĻĀ¤Ė×椷Ņż¤¤¤æ¹ ģ¤Ė¤Ź¤ź¤Ž¤¹”£
? 157.5”Ą1.96”Į5.4157.5”Ą1.96”Į5.4
? 157.5”Ą10.584157.5”Ą10.584
? ¤·¤æ¤¬¤Ć¤Ę”¢ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤Ī“_ĀŹ¤ĒÓčy¤¹¤ė¤Č”¢
¼s146.916cm¤«¤é¼s168.084cm¤Īég¤Ė¤Ź¤ź¤Ž¤¹”£
31
ĖŹĘ«²ī¤«¤é¤ĪÓčy(ĄżChatGPT)](https://image.slidesharecdn.com/stat-intro-240910142929-ee0f85b5/85/introduction-to-statistics-31-320.jpg)





















„Ó„ø„Ķ„¹»łµAÖv׳£ŗ½yÓѧČėéT introduction to statistics
- 1. ½yÓѧČėéT „Ó„ø„Ķ„¹„Ž„ó¤Ī»łµAÖŖ×R¢ß Masaaki NABESHIMA Mar 29, 2024 1 Version 1.2
- 2. ? ¶ą¤Æ¤ĪĻČČĖ¤Ė¤č¤ź“_Į¢¤µ¤ģ¤æ„Õ„ģ©`„ą„ļ©`„Æ ? ß^Č„¤ĪĆć»į ? „Ę„Æ„Ė„«„ė„鄤„Ę„£„ó„° ? „ׄģ„¼„ó„Ę©`„·„ē„ó¢Ł¢Ś ? „ׄķ„ø„§„Æ„Č„Ž„Ķ©`„ø„į„ó„Č¢Ł¢Ś ? „»„„å„ź„Ę„£„Ž„Ķ©`„ø„į„ó„Č ? Č”¤źQ¤Ć¤Ę¤¤¤Ź¤¤ī}²Ä ? ½yÓ ? „Ž©`„±„Ę„£„ó„° 2 „Ó„ø„Ķ„¹„Ž„ó¤Ī»łµAÖŖ×R
- 3. ? „Ē©`„愵„¤„Ø„ó„Ę„£„¹„ȤĪ„Ä©`„ė ? „Ē©`„æ„Ø„ó„ø„Ė„¢”¢„Ē©`„愵„¤„Ø„ó„Ę„£„¹„Č ? „Ø„ó„ø„Ė„¢Ļµ¤Ē×ī¤ā„Ū„ƄȤŹĀI ? ČÕ”©¤ĪIÕ¤Ų¤ĪßmÓĆ ? “óĘóI¤äŅ»Į÷ĘóI¤Ē¤ĻĘÕĶؤĖŹ¹¤ļ¤ģ¤ģ¤ė ? ČÕ”©¤ĪÉś»ī ? „Ē©`„æ¤ĪÕż¤·¤¤Ņ·½¤ĪĮµĆ(Éś»ī¤Ī¾«¶ČĻņÉĻ) 3 ¤Ļ¤ø¤į¤Ė£ŗ½yÓѧ
- 4. ? „Ē©`„愵„¤„Ø„ó„Ę„£„¹„Č f»į ? DS(„Ē©`„愵„¤„Ø„ó„Ę„£„¹„Č)Ź¶Ø „ź„Ę„é„·©`„ģ„Ł„ė ? ¹ ģ ? „Ē©`„愵„¤„Ø„ó„Ę„£„¹„Č(ø÷·NŹżŃ§)Į¦ ? „Ē©`„æ„Ø„ó„ø„Ė„¢„ź„ó„°(„ׄķ„°„é„ß„ó„°?g×°)Į¦ ? „Ó„ø„Ķ„¹Į¦ ? Ńa×ć ? „ź„Ę„é„·©`„ģ„Ł„ė(ČėéT)¤Ī¤ß 4 „Ē©`„愵„¤„Ø„ó„Ę„£„¹„ČŁYøń
- 5. ? ČÕ±¾ŹżŃ§Ź¶Ø f»į ? „Ē©`„愵„¤„Ø„ó„¹ŹżŃ§„¹„Č„é„Ę„ø„¹„Č ? ÖŠ¼ ? øߊ£1Äź„ģ„Ł„ė¤ĪŹżŃ§Ņ»°ć ? ÉĻ¼ ? “óѧ½ĢšB„ģ„Ł„ė¤ĪŹżŃ§Ņ»°ć ? „Ē„£©`„ׄé©`„Ė„ó„° f»į ? GŹ¶Ø ? AI?„Ē„£©`„ׄé©`„Ė„ó„°Ņ»°ć ? EŹ¶Ø ? AI?„Ē„£©`„ׄé©`„Ė„ó„°Ō¼ 5 „Ē©`„愵„¤„Ø„ó„Ę„£„¹„ČŁYøń
- 6. ? ½yÓŁ|±£Ō^(¤·¤Ä¤Ū¤·¤ē¤¦)ĶĘßM f»į ? ½yÓŹ¶Ø ? ½yÓÕ{ĖŹæ ? ½yÓÕ{ĖŹæ”¢éT½yÓÕ{ĖŹæ ? DS(„Ē©`„愵„¤„Ø„ó„¹) ? »łµA”¢°kÕ¹”¢„Ø„„¹„Ń©`„Č 6 „Ē©`„愵„¤„Ø„ó„Ę„£„¹„ČŁYøń „ģ„Ł„ė Ńa×ć 1¼ “óѧéT(3”¢4Äź) ¬FgµÄ¤Ė¤ĻŠŽŹæ„ģ„Ł„ė Ź1¼ 2¼ “óѧ½ĢšB(1”¢2Äź) ÓĖćī}±Ųķ 3¼ øߊ£ 4¼ ֊ѧ
- 7. ? ½yÓ¤ņÉŁ¤·¤«¤ø¤Ć¤æ„¢„Ž„Į„å„¢¤¬ų¤¤¤æŁYĮĻ¤Ē¤¹ ? ½yÓŹ¶Ø2¼¤ĻŗĻøń ? “óѧѧ²æ¤ĻŹżĄķæĘѧ(ŹżŃ§¹„) ? ±¾ŁYĮĻ¤Ī¾Ń¤¤ ? “óѧ½ĢšB(½yÓŹ¶Ø2¼)„ģ„Ł„ė ? ½yÓ¤ņ„Ä©`„ė¤Č¤·¤ĘÕhĆ÷ ? ¹«Ź½¤ĪŌ^Ć÷¤ĻŅ»ĒŠ¤Ź¤· 7 ×¢ŅāŹĀķ
- 8. ? ÓŹö½yÓѧ ? Óė¤Ø¤é¤ģ¤æ(Č«)„Ē©`„æ¤ĪŠŌŁ|¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? évSŠŌ¤Ī×·Ēó ? Ąż£ŗø÷·N„Ž©`„±„Ę„£„ó„°(ŌŅņ×·¼°”¢Ī“Ą“ÓčĻė) ? ĶĘy½yÓѧ ? ÉŁŹż¤Ī„Ē©`„椫¤éÄø¼Æā¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? ÉŁŹż„Ē©`„æ¤Ī×·Ēó(“_ĀŹÕ¤Ī»īÓĆ) ? Ąż£ŗŅĀĀŹÕ{Ė”¢ßx¤ĖŁó 8 ½yÓѧ·Öī
- 9. ? ÓŹö½yÓѧ ? øÅŅŖ ? Óė¤Ø¤é¤ģ¤æ(Č«)„Ē©`„æ¤ĪŠŌŁ|¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? ŹÖ·Ø ? “ś±ķ”¢·Ö²¼”¢±ķŹ¾·½·Ø ? Ļąév·ÖĪö”¢ g»Ų¢·ÖĪö”¢¶ąäĮæ½āĪö(ÖŲ»Ų¢·ÖĪö”¢ÅŠe·ÖĪö”¢Ö÷³É ·Ö·ÖĪö”¢Ņņ×Ó·ÖĪö”¢„Ƅ鄹„æ©`·ÖĪö) ? „Ä©`„ė ? „Ø„Æ„»„ė”¢R ? ČėĮ¦£ŗ„Ē©`„æ ? ³öĮ¦£ŗø÷·N½yÓ 9 ½yÓѧ·Öī(1)
- 10. ? ĶĘy½yÓѧ ? øÅŅŖ ? ÉŁŹż¤Ī„Ē©`„椫¤éÄø¼Æā¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? ŹÖ·Ø ? ĶʶØ(µćĶĘ¶Ø”¢ĒųégĶʶØ) ? Ź¶Ø ? „Ä©`„ė ? ¤Ź¤·£ŗ×÷IÕߤ¬½yÓÖŖ×R¤ņ¤ā¤Č¤Ė×÷I¤¹¤ė ? Ńa×ć£ŗChat GPT ? Õż¤·¤¤ŅĄīmĪĤņČė¤ģ¤ģ¤Š½Y¹ū¤¬¤Ē¤ėöŗĻ¤ā¤¢¤ė 10 ½yÓѧ·Öī(2)
- 11. ? Ė±¾¤Ī“󤤵¤ČŹż ? Ė±¾Źż(Number of samples ”¢„µ„ó„ׄėŹż) ? ŅāĪ¶ ? gņY(„¢„󄱩`„Č)¤Ī»ŲŹż ? Ė±¾¤Ī“󤤵(Sample size ”¢„µ„ó„ׄė„µ„¤„ŗ) ? ŅāĪ¶ ? 1»Ų¤ĪgņY(„¢„󄱩`„Č)¤ĒµĆ¤é¤ģ¤æ„Ē©`„æŹż ? Ąż ? gņY¤ņ2»ŲŠŠ¤¤”¢¤½¤ģ¤¾¤ģ5¤Ī„Ē©`„椬µĆ¤é¤ģ¤æ ? Ė±¾Źż(„µ„ó„ׄėŹż)£ŗ2 ? Ė±¾¤Ī“󤤵(„µ„ó„ׄė„µ„¤„ŗ)£ŗ5 11 Ńa×ć£ŗĖ±¾¤Ī”ø“󤤵¤ČŹż”¹
- 13. ? ÄæµÄ£ŗ„Ē©`„æČŗ¤ĪĢŲÕ¤ņÕhĆ÷¤¹¤ė ? ½yÓ ? Ę½¾ł”¢ĖŹĘ«²ī(·ÖÉ¢)”¢¹²·ÖÉ¢ ? „į„Ē„£„¢„ó(ÖŠŃė)”¢„ā©`„É(×īīl)”¢Ķį¶Č”¢Ķ»¶Č ? „Ż„¤„ó„Č ? Ę½¾ł¤Ą¤±¤Ē¤Ļ„Ē©`„æČŗ¤ĪĢŲÕ¤ņÕhĆ÷¤Ē¤¤Ź¤¤ ? ¤Ŗ½šévßB(ø»¤ĻÉĻĪ»Ó¤ĖĘ«¤ė) ? ĢåņYévßB(ĢåņY¤Ī¤¢¤Ö¤ź³ö¤·) ? ¹¤IŃuĘ·(Ę½¾ł¤Ļ¹Ģ¶Ø”¢¾«¶Č¤¬ī}) 13 ÓŹö½yÓѧ
- 14. ? ¤Ŗ½šévßB(Äź §”¢ŁAŠī”¢×”Õ¬żøń) ? ÓŅ¤ĖĘ«¤ė ? Ąż£ŗČÕ±¾¤ĪŁAŠīī~ ? ÉĻĪ»2øī¤¬¼s6øī¤ĪŁAŠī¤ņ³Ö¤Ä ? „Ä©`„ė ? ¶ČŹż·Ö²¼±ķ”¢„Ņ„¹„Č„°„é„ą ? ÖŠŃė ? Ńa×ć£ŗŗ£Ķā„į„Ē„£„¢¤Ē¤ĻÖŠŃė¤¬Ź¹¤ļ¤ģ¤ėŹĀ¤¬¶ą¤¤ ? Äź §”¢×”Õ¬żøń 14 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF
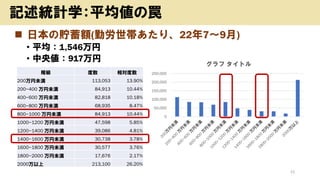
- 15. ? ČÕ±¾¤ĪŁAŠīī~(ĒŚŗŹĄ”¤¢¤æ¤ź”¢22Äź7”«9ŌĀ) ? Ę½¾ł£ŗ1,546ĶņŅ ? ÖŠŃė£ŗ917ĶņŅ 15 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF 0 50,000 100,000 150,000 200,000 250,000 „°„é„Õ „愤„Č„ė ėA¼ ¶ČŹż Ļą¶ČŹż 200ĶņŅĪ“ŗ 113,053 13.90% 200~400 ĶņŅĪ“ŗ 84,913 10.44% 400~600 ĶņŅĪ“ŗ 82,818 10.18% 600~800 ĶņŅĪ“ŗ 68,935 8.47% 800~1000 ĶņŅĪ“ŗ 84,913 10.44% 1000~1200 ĶņŅĪ“ŗ 47,598 5.85% 1200~1400 ĶņŅĪ“ŗ 39,086 4.81% 1400~1600 ĶņŅĪ“ŗ 30,738 3.78% 1600~1800 ĶņŅĪ“ŗ 30,577 3.76% 1800~2000 ĶņŅĪ“ŗ 17,676 2.17% 2000ĶņŅŌÉĻ 213,100 26.20%
- 16. ? Ńa×ć£ŗ„Ń„ģ©`„ȤĪ·Øt(2?8¤Ī·Øt) ? ÉĻĪ»2øī¤¬Č«Ģå¤Ī8øī¤ņÕ¼¤į¤ė ? Ę½¾ł¤Ī×hÕ¤Ē¤Ļ±¾Ł|µÄ¤ŹÕż½ā¤ĻµĆ¤é¤ģ¤Ź¤¤ ? ¤ā¤¦Ņ»¶ĪĢ¤¤ßŽz¤ó¤Ą×hÕ¤¬±Ųķ ? (Ąż)ÓÉĻ£ŗÉĻĪ»2øī¤Ī(īæĶorÉĢĘ·orŅŖŅņ)¤¬Ó¤źÉĻ¤²¤Ī8øī¤ĖÓ°ķ¤¹¤ė ? ÉĻĪ»2øī(īæĶorÉĢĘ·orŅŖŅņ)¤Ī¤¢¤Ö¤ź³ö¤·?²ß ? īæĶ?ÉĢĘ··ÖĪö£ŗ„Ē„·„ė”¢RFM”¢CPM·ÖĪö ? ŅŖŅņ·ÖĪö£ŗ¶ąäĮæ½āĪö ? Ńa×ć£ŗ„ķ„ó„°„Ę©`„ė(„Ķ„Ć„ČŲÓ¤Ī¤ß) ? µźī^ŲÓ£ŗÉĻĪ»2øī¤·¤«Q¤Ø¤Ź¤¤ ? „Ķ„Ć„ČŲÓ£ŗ¤¢¤Ž¤źÓ¤ģ¤Ź¤¤8øī¤āQ¤Ø¤ė 16 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF
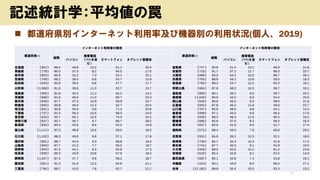
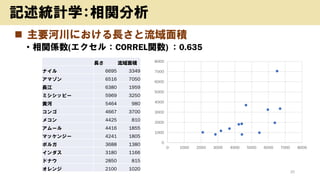
- 17. ? ¶¼µĄø®±he„¤„ó„æ©`„Ķ„Ć„ČĄūÓĆĀŹ¼°¤ÓCĘ÷e¤ĪĄūÓĆדr(ČĖ”¢2019) 17 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF ¶¼µĄø®±h(n) „¤„ó„æ©`„Ķ„Ć„ČĄūÓĆÕߤĪøīŗĻ ¶¼µĄø®±h(n) „¤„ó„æ©`„Ķ„Ć„ČĄūÓĆÕߤĪøīŗĻ ¾tŹż ¾tŹż „Ń„½„³„ó ŠÆ”ėŌ £ØPHS¤ņŗ¬ ¤ą£© „¹„Ž©`„Č„Õ„©„ó „æ„Ö„ģ„Ć„ČŠĶ¶ĖÄ© „Ń„½„³„ó ŠÆ”ėŌ £ØPHS¤ņŗ¬ ¤ą£© „¹„Ž©`„Č„Õ„©„ó „æ„Ö„ģ„Ć„ČŠĶ¶ĖÄ© ±±ŗ£µĄ £Ø661£© 88.4 48.8 10.2 61.1 20.4 ×ĢŁR±h £Ø747£© 90.8 51.4 13.1 66.9 21.8 ĒąÉ±h £Ø778£© 80.0 37.0 8.2 45.5 17.0 ¾©¶¼ø® £Ø733£© 91.7 57.2 11.7 68.3 25.7 ŃŅŹÖ±h £Ø803£© 85.9 32.2 7.0 52.1 15.1 “óŚęø® £Ø669£© 93.3 54.2 15.0 66.7 28.1 m³Ē±h £Ø769£© 86.2 38.4 9.8 54.7 15.9 ±ųģ±h £Ø793£© 88.8 49.1 10.6 59.5 19.3 ĒļĢļ±h £Ø933£© 82.8 39.5 8.8 47.7 17.7 ÄĪĮ¼±h £Ø760£© 89.3 54.7 12.2 65.3 19.1 ɽŠĪ±h £Ø1,068£© 81.0 39.6 11.0 52.7 13.7 ŗĶøčɽ±h £Ø664£© 87.6 48.2 10.0 56.7 19.1 ø£u±h £Ø900£© 81.8 40.3 11.2 54.4 14.2 ųBČ”±h £Ø860£© 86.1 46.2 9.0 59.7 20.2 “ijĒ±h £Ø696£© 91.6 49.4 11.0 60.7 22.3 uøł±h £Ø1,049£© 84.9 42.5 8.3 54.4 20.5 ŠÄ¾±h £Ø849£© 87.7 47.3 10.9 58.9 23.7 łÉ½±h £Ø816£© 90.6 45.4 9.2 58.0 21.9 ČŗńR±h £Ø850£© 90.8 49.4 12.3 62.7 20.5 Śu±h £Ø820£© 87.8 46.2 11.9 59.6 22.7 ĪÓń±h £Ø691£© 90.8 54.9 9.8 71.4 25.8 É½æŚ±h £Ø767£© 84.9 36.6 8.8 54.1 14.3 Ē§Č~±h £Ø727£© 91.5 59.3 10.9 68.3 24.6 Ōu±h £Ø698£© 87.1 43.5 9.9 56.4 17.6 |¾©¶¼ £Ø622£© 95.7 65.1 10.4 74.5 33.2 Ļć“رh £Ø926£© 88.3 48.3 11.5 60.5 19.2 ÉńÄĪ“رh £Ø627£© 92.7 56.7 9.7 68.7 28.2 ŪęĀ±h £Ø696£© 84.9 37.5 8.2 58.4 16.3 ŠĀ±h £Ø935£© 84.0 40.6 8.9 52.5 14.8 øßÖŖ±h £Ø627£© 85.6 41.9 9.0 51.7 17.4 ø»É½±h £Ø1,111£© 87.0 48.8 10.6 59.0 19.5 ø£ł±h £Ø572£© 88.4 49.0 7.9 65.6 25.0 ŹÆ“رh £Ø1,105£© 88.3 46.6 9.8 57.1 17.8 ×ōŁR±h £Ø931£© 84.6 39.1 10.3 52.1 18.0 ø£¾®±h £Ø891£© 88.7 44.4 9.0 58.8 19.4 éLĘé±h £Ø706£© 84.7 34.4 10.3 51.8 17.4 ɽĄę±h £Ø906£© 87.7 41.2 7.7 59.2 18.7 ŠÜ±¾±h £Ø744£© 87.7 40.3 9.1 54.9 19.0 éLŅ°±h £Ø945£© 87.2 44.1 9.3 55.6 17.3 “ó·Ö±h £Ø659£© 89.0 42.6 10.1 61.4 23.9 įŖø·±h £Ø959£© 85.3 43.6 10.8 57.9 18.4 mĘé±h £Ø616£© 85.4 32.8 8.1 53.4 14.9 ¾²ł±h £Ø1,047£© 87.4 47.7 9.9 58.2 18.7 Ā¹¹u±h £Ø587£© 85.1 34.9 7.4 53.8 19.1 ŪÖŖ±h £Ø651£© 91.3 51.5 12.3 64.6 21.1 _æI±h £Ø424£© 90.1 43.9 8.0 66.4 27.1 ČżÖŲ±h £Ø794£© 89.7 43.0 7.8 62.7 21.7 Č«Ģå £Ø37,182£© 89.8 50.4 10.5 63.3 23.2
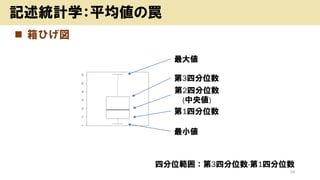
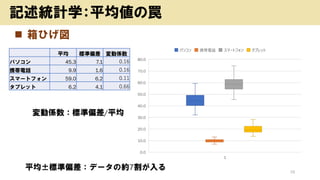
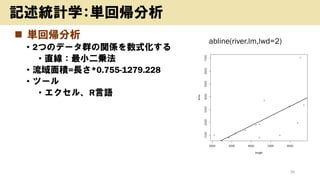
- 19. ? Ļä¤Ņ¤²ķ 19 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF Ę½¾ł”ĄĖŹĘ«²ī£ŗ„Ē©`„æ¤Ī¼s7øī¤¬Čė¤ė Ę½¾ł ĖŹĘ«²ī äÓSŹż „Ń„½„³„ó 45.3 7.1 0.16 ŠÆ”ėŌ 9.9 1.6 0.16 „¹„Ž©`„Č„Õ„©„ó 59.0 6.2 0.11 „æ„Ö„ģ„Ć„Č 6.2 4.1 0.66 äÓSŹż£ŗĖŹĘ«²ī/Ę½¾ł
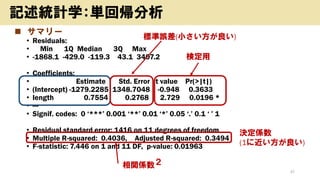
- 20. ? ĢåņY(QoE)¤Ī½Y¹ū ? „Ē©`„æ ? īæĶ„¢„󄱩`„Č”¢Ó»ŅĀQoE(Ö÷¤Ė„Š„Ć„Õ„”„ź„ó„°évßB) ? ÄæµÄ ? Č«ĢåµÄ¤ŹĘ·Ł|ĻņÉĻ?Ę½¾ł ? ½ā¼s(„Į„ć©`„ó)²ß?ĢåņY¤Ī±ČĀŹ?¤¢¤Ö¤ź³ö¤· ? „Ä©`„ė ? „Ņ„¹„Č„°„é„ą”¢¶ČŹż·Ö²¼±ķ 20 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF
- 21. ? OTT„鄤„Ö(Ę½¾ł„»„Ć„·„ē„óéL£ŗ¼s10·Ö) ? Ę½¾łŌŁ„Š„Ć„Õ„”„ź„ó„°»ŲŹż ? ¹Ģ¶Ø£ŗ0.27»Ų ? „ā„Š„¤„ė£ŗ0.36»Ų ? ¶ČŹż·Ö²¼±ķ ? „Մ鄹„Č„ģ©`„·„ē„ó(ŌŁ„Š„Ć„Õ„”„ź„ó„°4»ŲŅŌÉĻ)„»„Ć„·„ē„ó¤ĪøīŗĻ ? ¹Ģ¶Ø£ŗ1.09% ? „ā„Š„¤„ė£ŗ2.16% 21 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF 0»Ų 1»Ų 2”«3»Ų 4”«7»Ų 8»ŲŅŌÉĻ ¹Ģ¶Ø 91.21 5.49 2.2 0.75 0.34 „ā„Š„¤„ė 82.84 9.73 5.27 1.73 0.43
- 22. ? Ńa×ć£ŗ„Ķ„Ć„ČĻµ(„ģ„¤„Ę„ó„·µČ)¤Ī·Ö²¼ ? „¬„ó„Ž·Ö²¼(„«„¤¶ž\·Ö²¼)¤Č¤¹¤ė¤³¤Č¤¬¶ą¤¤ ? Ō^Ć÷¤Ļ¤µ¤ģ¤Ę¤¤¤Ź¤¤£æ(ŅŖÕ{Ė)¤¬”¢„Ø„ó„ø„Ė„¢„ź„󄰵ĤĖŹ¹¤Ø¤ė 22 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF
- 23. ? Ķį¶Č(¤ļ¤¤¤É) 23 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF ×ó¼Ä¤ź£ŗ„ׄ鄹 ×óÓŅ¾łµČ£ŗ0 ÓŅ¼Ä¤ź£ŗ„Ž„¤„Ź„¹
- 25. ? ¹¤IŃuĘ· ? Ę½¾ł£ŗ¤¤¤Ž¤É¤Ę½¾ł¤¬“ó¤¤Æ¤ŗ¤ģ¤ėŃuĘ·¤Ļ¤Ź¤¤ ? ·ÖÉ¢£ŗĪ¢Ćī¤ŹÕ`²ī(Ę«²ī)¤¬¤É¤ģ¤Ą¤±ÉŁ¤Ź¤¤¤«¤¬ęI ? „Ä©`„ė ? ĖŹĘ«²ī ? „Ē©`„æČŗ¤Ī„ŗ„ģ(Ę«²ī)¤Ī“󤤵 ? ÓĖćŹ½ ? Ę«²ī£ŗ(„Ē©`„æ-Ę½¾ł) ? ·ÖÉ¢£ŗ ¦Ņ((„Ē©`„æ?Ę½¾ł)2) „Ē©`„æ¤ĪŹż ? ĖŹĘ«²ī£ŗ ·ÖÉ¢ 25 ÓŹö½yÓѧ£ŗĘ½¾ł¤ĪĮF
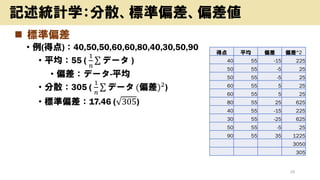
- 26. ? ĖŹĘ«²ī ? Ąż(µĆµć)£ŗ40,50,50,60,60,80,40,30,50,90 ? Ę½¾ł£ŗ55 ( 1 ? ¦Ņ „Ē©`„æ ) ? Ę«²ī£ŗ„Ē©`„æ-Ę½¾ł ? ·ÖÉ¢£ŗ305 ( 1 ? ¦Ņ „Ē©`„æ (Ę«²ī)2 ) ? ĖŹĘ«²ī£ŗ17.46 ( 305) 26 ÓŹö½yÓѧ£ŗ·ÖÉ¢”¢ĖŹĘ«²ī”¢Ę«²ī µĆµć Ę½¾ł Ę«²ī Ę«²ī^2 40 55 -15 225 50 55 -5 25 50 55 -5 25 60 55 5 25 60 55 5 25 80 55 25 625 40 55 -15 225 30 55 -25 625 50 55 -5 25 90 55 35 1225 3050 305
- 27. ? ĖŹĘ«²ī¤ĪĢŲÕ(ÕżŅ·Ö²¼) ? Ę½¾ł”ĄĖŹĘ«²ī£ŗČ«Ģå¤Ī68.26% ? 55”Ą17.46£ŗ37.54”«72.46 ? (Ę½¾ł”ĄĖŹĘ«²ī*1.96£ŗČ«Ģå¤Ī95%) ? Ę½¾ł”ĄĖŹĘ«²ī*2£ŗČ«Ģå¤Ī95.44% ? 55”Ą17.5*2£ŗ20.08”«89.92 27 ÓŹö½yÓѧ£ŗ·ÖÉ¢”¢ĖŹĘ«²ī”¢Ę«²ī µĆµć Ę½¾ł Ę«²ī Ę«²ī^2 40 55 -15 225 50 55 -5 25 50 55 -5 25 60 55 5 25 60 55 5 25 80 55 25 625 40 55 -15 225 30 55 -25 625 50 55 -5 25 90 55 35 1225 3050 305
- 28. ? Ę«²ī ? ĖŹĘ«²ī¤Ė¤č¤źµĆµć¤Ī„Ż„ø„·„ē„ó¤ņŹ¾¤·¤æ¤ā¤Ī ? Ę«²ī£ŗ µĆµć£Ę½¾łµć ĖŹĘ«²ī *10£«50 ? Ņ·½ ? 70£ŗÉĻĪ»¼s2.5% ? 60£ŗÉĻĪ»¼s15£„ ? 50£ŗÖŠŃė ? 40£ŗĻĀĪ»¼s15£„ ? 30£ŗĻĀĪ»¼s2.5% 28 ÓŹö½yÓѧ£ŗ·ÖÉ¢”¢ĖŹĘ«²ī”¢Ę«²ī µĆµć Ę½¾łµć Ę«²ī 40 55 41 50 55 47 50 55 47 60 55 53 60 55 53 80 55 64 40 55 41 30 55 36 50 55 47 90 55 70
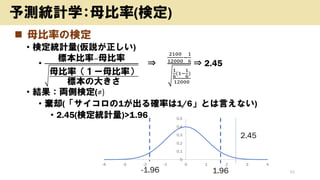
- 29. ? ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)¤ĪÉķéL ? Ę½¾ł£ŗ157.5cm ? ĖŹĘ«²ī£ŗ5.4cm ? ČÕ±¾ČĖÅ®ŠŌ?»Ø×Ó¤µ¤ó(³ÉČĖ)¤ĪÉķéL¤ņĒųégĶĘ¶Ø ? ŠÅīm¶Č£ŗ68.26% ? 157.5”ĄĖŹĘ«²ī ? 157.5”Ą5.4cm ? 152.1cm”«162.9cm ? ŠÅīm¶Č£ŗ95% ? 157.5”Ą1.96*ĖŹĘ«²ī ? 157.5”Ą1.96*5.4cm ? 146.9cm”«¼s168.1cm 29 ĖŹĘ«²ī¤«¤é¤ĪÓčy(Óčy½yÓѧ) ”øÓčy¤ĪŠÅīm¶Č”¹¤ņÉĻ¤²¤ė ?”øĒųégĶĘ¶Ø¤Ī¹ ģ”¹¤ņŚ¤²¤ė
- 30. ? ”øÓčy¤ĪŠÅīm¶Č”¹¤Č”øĒųégĶĘ¶Ø¤Ī¹ ģ”¹ ? Óčy¤ĪŠÅīm¶Č¤ņÉĻ¤²¤ė ? ĒųégĶĘ¶Ø¤Ī¹ ģ¤ņŚ¤²¤ė(Óčy¤ņµ±¤æ¤ź¤ä¤¹¤Æ¤¹¤ė) ? 95£„¤ĪŠÅīm¶Č ? ¤Ž¤ģ¤ŹŹĀ(5%)¤¬o¤¤ĻŽ¤źÕż¤·¤¤ 30 ĖŹĘ«²ī¤«¤é¤ĪÓčy(Óčy½yÓѧ) Óčy¤ĪŠÅīm¶Č ¹ ģ 68.26% ”ĄĖŹĘ«²ī 152.1 ”« 162.9 95.44% ”Ą2*ĖŹĘ«²ī 146.9 ”« 168.1
- 31. ? ČėĮ¦ ? ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)¤ĪĘ½¾łÉķéL¤¬157.5cm”¢ĖŹĘ«²ī5.4cm¤Ē¤¢¤ėöŗĻ”¢ČÕ ±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤ĒÓčy¤¹¤ė¤Č¤É¤Ī¹ ģ¤Ė¤Ź¤ė£æ ? »Ų“š ? ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)¤ĪĘ½¾łÉķéL¤¬157.5cm”¢ĖŹĘ«²ī¤¬5.4cm¤ĪÕżŅ·Ö²¼¤ņ ¢¶Ø¤·¤Ž¤¹”£95%¤ĪŠÅīmĒųég¤ņĒó¤į¤ė¤æ¤į¤Ė”¢ŅŌĻĀ¤ĪÓĖć¤ņŠŠ¤¤¤Ž¤¹”£ ? 95%¤ĪŠÅīmĒųég¤Ļ”¢Ę½¾ł¤«¤é×óÓŅ¤ĖĖŹĘ«²ī¤Ī1.96±¶¤ņæ¼]¤·¤æ¹ ģ¤Ė¤Ź ¤ź¤Ž¤¹”£ĖŹĘ«²ī¤¬5.4cm¤Ź¤Ī¤Ē”¢1.96±¶¤¹¤ė¤Č¼s10.584cm¤Ė¤Ź¤ź¤Ž¤¹”£ ? ¤·¤æ¤¬¤Ć¤Ę”¢ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤Ī“_ĀŹ¤ĒÓčy¤¹¤ė¤Č”¢ Ę½¾łÉķéL¤«¤é10.584cm¤ņÉĻĻĀ¤Ė×椷Ņż¤¤¤æ¹ ģ¤Ė¤Ź¤ź¤Ž¤¹”£ ? 157.5”Ą1.96”Į5.4157.5”Ą1.96”Į5.4 ? 157.5”Ą10.584157.5”Ą10.584 ? ¤·¤æ¤¬¤Ć¤Ę”¢ČÕ±¾ČĖÅ®ŠŌ(³ÉČĖ)A¤µ¤ó¤ĪÉķéL¤ņ95%¤Ī“_ĀŹ¤ĒÓčy¤¹¤ė¤Č”¢ ¼s146.916cm¤«¤é¼s168.084cm¤Īég¤Ė¤Ź¤ź¤Ž¤¹”£ 31 ĖŹĘ«²ī¤«¤é¤ĪÓčy(ĄżChatGPT)
- 32. ? ÕżŅ·Ö²¼¤ĪĻó ? „³„¤„óĶ¶¤² ? ÉķéL”¢ŌņY½Y¹ū”¢Öźż¤Ī §Ņę ? Ė±¾Ę½¾ł¤Ī·Ö²¼(ÖŠŠÄOĻŽ¶ØĄķ) ? »ł±¾ŠĪ ? ĖŹÕżŅ·Ö²¼(„¬„¦„¹·Ö²¼) ? Ę½¾ł£ŗ0 ? ĖŹĘ«²ī£ŗ1 32 ÓŹö½yÓѧ£ŗÕżŅ·Ö²¼Ńa×ć 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 -4 -3 -2 -1 0 1 2 3 4
- 33. ? ĻąévSŹż ? 2¤Ä¤Ī„Ē©`„æĻµĮŠ¤ĪévSŠŌ ? ¹ ģ-1”«1 ? 1£ŗÕż¤ĪĻąév”¢0£ŗĻąév¤Ź¤·”¢-1£ŗŲ¤ĪĻąév 33 ÓŹö½yÓѧ£ŗĻąév·ÖĪö
- 34. ? ĻąévSŹż ? 0.0”«0.2£ŗ¤Ū¤Č¤ó¤ÉĻąév¤¬o¤¤ ? 0.2”«0.4£ŗ¤ä¤äĻąév¤¬¤¢¤ė ? 0.4”«0.7£ŗ¤«¤Ź¤ź¤¤Ļąév ? 0.7”«1.0£ŗ¤¤Ļąév 34 ÓŹö½yÓѧ£ŗĻąév·ÖĪö
- 35. ? Ö÷ŅŖŗӓؤĖ¤Ŗ¤±¤ėéL¤µ¤ČĮ÷ÓņĆę·e ? ĻąévSŹż(„Ø„Æ„»„ė£ŗCORRELévŹż) £ŗ0.635 35 ÓŹö½yÓѧ£ŗĻąév·ÖĪö éL¤µ Į÷ÓņĆę·e „Ź„¤„ė 6695 3349 „¢„Ž„¾„ó 6516 7050 éL½ 6380 1959 „ß„·„·„Ć„Ō©` 5969 3250 »ĘŗÓ 5464 980 „³„ó„“ 4667 3700 „į„³„ó 4425 810 „¢„ą©`„ė 4416 1855 „Ž„Ć„±„ó„ø©` 4241 1805 „Ż„ė„¬ 3688 1380 „¤„ó„Ą„¹ 3180 1166 „É„Ź„¦ 2850 815 „Ŗ„ģ„ó„ø 2100 1020 0 1000 2000 3000 4000 5000 6000 7000 8000 0 1000 2000 3000 4000 5000 6000 7000 8000
- 36. ? g»Ų¢·ÖĪö ? 2¤Ä¤Ī„Ē©`„æČŗ¤ĪévS¤ņŹżŹ½»Æ¤¹¤ė ? Ö±¾£ŗ×īŠ”¶ž\·Ø ? Į÷ÓņĆę·e=éL¤µ*0.755-1279.228 ? „Ä©`„ė ? „Ø„Æ„»„ė”¢RŃŌÕZ 36 ÓŹö½yÓѧ£ŗ g»Ų¢·ÖĪö abline(river.lm,lwd=2)
- 37. ? „µ„Ž„ź©` ? Residuals: ? Min 1Q Median 3Q Max ? -1868.1 -429.0 -119.3 43.1 3407.2 ? Coefficients: ? Estimate Std. Error t value Pr(>|t|) ? (Intercept) -1279.2285 1348.7048 -0.948 0.3633 ? length 0.7554 0.2768 2.729 0.0196 * ? --- ? Signif. codes: 0 ”®***”Æ 0.001 ”®**”Æ 0.01 ”®*”Æ 0.05 ”®.”Æ 0.1 ”® ”Æ 1 ? Residual standard error: 1416 on 11 degrees of freedom ? Multiple R-squared: 0.4036, Adjusted R-squared: 0.3494 ? F-statistic: 7.446 on 1 and 11 DF, p-value: 0.01963 37 ÓŹö½yÓѧ£ŗ g»Ų¢·ÖĪö ĖŹÕ`²ī(Š”¤µ¤¤·½¤¬Į¼¤¤) Q¶ØSŹż (1¤Ė½ü¤¤·½¤¬Į¼¤¤) ĻąévSŹż£² Ź¶ØÓĆ
- 38. ? RŃŌÕZ¤Ė¤č¤ėgŠŠ ? river <- read.csv("/tmp/rever.csv",header=TRUE) ? „Õ„”„¤„ėÕi¤ßŽz¤ß ? river.lm <- lm(area~length, data=river) ? »Ų¢·ÖĪögŠŠ ? abline(river.lm,lwd=2) ? „°„é„ÕĆč» ? summary(river.lm) ? „µ„Ž„ź©`³öĮ¦ 38 ÓŹö½yÓѧ£ŗ g»Ų¢·ÖĪö length area 6695 3349 6516 7050 6380 1959 5969 3250 5464 980 4667 3700 4425 810 4416 1855 4241 1805 3688 1380 3180 1166 2850 815 2100 1020 rever.csv
- 39. ? ¶ąäĮæ½āĪö ? Ń}Źż¤ĪŅŖŅņ?³É·Ö¤Ī½āĪö ? ±¾øńµÄ¤Ź„Ž©`„±„Ę„£„ó„°·ÖĪö ? ŹÖ·Ø ? ÖŲ»Ų¢·ÖĪö”¢ÅŠe·ÖĪö”¢Ö÷³É·Ö·ÖĪö”¢Ņņ×Ó·ÖĪö”¢„Ƅ鄹„æ©`·ÖĪö ? „ģ„Ł„ė ? ½yÓŹ¶ØŹ1¼ £Ø¤“¤į¤ó¤Ź¤µ¤¤”¢½ń»Ų¤ĻQ¤¤¤Ž¤»¤ó) 39 ÓŹö½yÓѧ£ŗ¶ąäĮæ½āĪö
- 41. ? Ė±¾¤ČÄø¼Æā¤ĪÓčy”¢Ė±¾¤Ī“󤤵 ? Óčy ? Äø±ČĀŹ(Äø¼Æā¤Ė¤Ŗ¤±¤ė±ČĀŹ) ? ÄøĘ½¾ł(Äø¼Æā¤ĪĘ½¾ł) ? Äø·ÖÉ¢(Äø¼Æā¤Ī·ÖÉ¢) ? Ė±¾¤Ī“󤤵 ? ±ŲŅŖ¤Ź¾«¶Č¤ņŗ¤æ¤¹(×īŠ”¤Ī)”øĖ±¾¤Ī“󤤵”¹ 41 Óčy½yÓѧ Äø¼Æā Ė±¾
- 42. ? Ļó ? gĢå(Ąż:ÄøĘ½¾ł) ? ²ī (Ąż:”ø2¤Ä¤ĪÄøĘ½¾ł”¹¤Ī²ī) ? ±ČĀŹ (Ąż:”ø2¤Ä¤ĪÄøĘ½¾ł”¹¤Ī±ČĀŹ) ? Ėć³öĢõ¼ž ? Ė±¾¤Ī“󤤵£ŗ“óĖ±¾or Š”Ė±¾ ? Äø¼Æā¤Ī“󤤵£ŗoĻŽ or not ? Äø¼Æā¤Ī·Ö²¼£ŗÕżŅ·Ö²¼ or not ? Äø·ÖÉ¢£ŗ¼ČÖŖ or not ? Ź¶Ø ? ʬČ(ŅŌÉĻ or ŅŌĻĀ) ? IČ(= or ”Ł) 42 Óčy½yÓѧ Óčy½yÓѧ¤Īėy¤·¤µ ?Ėć³ö·½·Ø¤¬ÄŖ“ó£ŗ g¼ÓĖć¤Ē288Ķؤź (3*3*2*2*2*2*2)
- 43. ? ±¾ŁYĮĻ¤ĒÕhĆ÷¤¹¤ė„µ„ó„ׄė ? Äø±ČĀŹ( gĢå)/(“óĖ±¾) ? ĒųégĶĘ¶Ø ? Ė±¾¤Ī“󤤵 ? Ź¶Ø(IČ) ? ÄøĘ½¾ł( gĢå)/(Š”Ė±¾”¢Äø¼Æā£ŗÕżŅ·Ö²¼”¢Äø·ÖÉ¢£ŗĪ“ÖŖ) ? Ź¶Ø(ʬČ) 43 Óčy½yÓѧ
- 44. ? Äø±ČĀŹ¤ĪŠÅīmĒųég ? ÓĆĶ¾ ? ±ČĀŹ¤Ėév¤¹¤ėÕ{Ė(ÄŚéwÖ§³ÖĀŹ”¢ŅĀĀŹ”¢ßx¤½Y¹ūµČ)¤Ī½Y¹ū¤Ė¤¹ ¤ėĒųégĶĘ¶Ø ? ¹«Ź½(“óĖ±¾) ? Ė±¾Źż£ŗn ? ±ČĀŹ£ŗp ? 95%ŠÅīmĒųég ? ? ”Ą 1.96 ”Į ?(1??) ? 44 Óčy½yÓѧ£ŗÄø±ČĀŹ(ĒųégĶʶØ) ÄøĘ½¾ł¤ĪĖŹÕ`²ī
- 45. ? ÄŚéwÖ§³ÖĀŹ¤Ī„¢„󄱩`„Č£ŗÖ§³ÖĀŹ20% ? 100ČĖ¤ĖgŹ© ? Ö§³ÖĀŹ¤Ī95%ŠÅīmĒųég·ł ? ? ”Ą 1.96 ”Į 0.8(1?0.8) 100 ? ? ”Ą 1.96 ”Į 0.16 100 ? ? ”Ą 0.0784 ? 12.16 ”« 27.84 (·ł£ŗ15.7%) ? 1000ČĖ¤ĖgŹ© ? Ö§³ÖĀŹ¤Ī95%ŠÅīmĒųég ? ? ”Ą 1.96 ”Į 0.8(1?0.8) 1000 ? ? ”Ą 1.96 ”Į 0.16 1000 ? ? ”Ą 0.0248 ? 17.53 ”« 22.47 (·ł£ŗ5.0%) 45 Óčy½yÓѧ£ŗÄø±ČĀŹ(ĒųégĶʶØ)
- 46. ? ChatGPT ? ? ÄŚéwÖ§³ÖĀŹ¤Ī„¢„󄱩`„ȤņŠŠ¤Ć¤æ¤Č¤³¤ķ”¢Ö§³ÖĀŹ¤¬20%¤Ē¤¢¤Ć¤æ”¢ „¢„󄱩`„ČŹż¤¬1000ČĖ¤Ą¤Č¤·¤Ę95%¤ĪŠÅīmĒųég¤ņ¤ā¤Č¤į¤č ? »Ų“š ? 95%¤ĪŠÅīmĒųég¤ņĒó¤į¤ė¤Ė¤Ļ”¢Ķس£”¢ŅŌĻĀ¤Ī„¹„ʄƄפņgŠŠ¤·¤Ž ¤¹£ŗ ? £¼Ź”ĀŌ£¾ ? ¤·¤æ¤¬¤Ć¤Ę”¢95%¤ĪŠÅīmĖ®Ź¤Ē”¢ÄŚéw¤ĪÖ§³ÖĀŹ¤ĪĶĘ¶Ø¤Ļ¼s17.53% ¤«¤é¼s22.47%¤Īég¤Ė¤¢¤ź¤Ž¤¹”£ 46 Óčy½yÓѧ£ŗÄø±ČĀŹ(ĒųégĶʶØ)
- 47. ? ±ŲŅŖ¤ŹĖ±¾¤Ī“󤤵(»Ų“šŹż) ? ÄŚéwÖ§³ÖĀŹ¤Ī„¢„󄱩`„ȤņŠŠ¤¦¤Ė¤¢¤æ¤ź”¢ŠÅīmĒųég¤¬3%ŅŌĻĀ¤Č¤Ź¤ė»Ų “šŹżn¤ņĒó¤į¤č(Ö§³ÖĀŹ¤ĪĒ°Ģį¤Ļo¤¤¤ā¤Ī¤Č¤¹¤ė) ? 2 ? 1.96 ”Į ?(1??) ? < 0.03?1.96 ”Į ?(1??) ? < 0.015 ? ? 1?? ? < 0.015 1.96 ? ?(1??) ? < 0.0152 1.962 ? 1.962 0.0152 ?(1 ? ?) < ? ? 17074 ? ? 1 ? ? < ? ? 17074 ? 0.5 1 ? 0.5 < ? ? 4268.4 < ? ? n=4269 47 Óčy½yÓѧ£ŗÄø±ČĀŹ(±ŲŅŖ¤ŹĖ±¾¤Ī“󤤵) p(1-p)¤Ī×ī“ó 0.5*0.5=0.25 0.2*0.8=0.16 0.1*0.9=0.09
- 48. ? ChatGPT ? ? ÄŚéwÖ§³ÖĀŹ¤Ī„¢„󄱩`„ȤņŠŠ¤¦”¢ŠÅīmĒųég¤ņ3%¤Ė¤¹¤ė¤Ė¤ĻŗĪČĖ¤Ī „¢„󄱩`„Ȥ¬±ŲŅŖ¤«£æ ? »Ų“š ? ŠÅīmĒųég¤ņ3%¤Ė¤¹¤ė¤æ¤į¤Ė±ŲŅŖ¤Ź„¢„󄱩`„ȤĪ„µ„ó„ׄė„µ„¤„ŗ¤ņ Ēó¤į¤ė¤Ė¤Ļ”¢ŅŌĻĀ¤ĪŹÖķ¤Ė¾¤¤¤Ž¤¹”£ ? £¼Ź”ĀŌ£¾ ? ¤·¤æ¤¬¤Ć¤Ę”¢ŠÅīmĒųég¤ņ3%¤Ė¤¹¤ė¤æ¤į¤Ė¤Ļ”¢¼s4269ČĖ¤Ī„¢„󄱩` „Ȥ¬±ŲŅŖ¤Ē¤¹”£ 48 Óčy½yÓѧ£ŗÄø±ČĀŹ(±ŲŅŖ¤ŹĖ±¾¤Ī“󤤵)
- 49. ? „¢„ׄķ©`„Į 1. ¢o¢Õh¤ņ×÷³É 2. ¢o¢Õh¤Ė¤¹¤ėŹ¶Ø½yÓĮæ¤ņÓĖć 3. Ź¶Ø½yÓĮ椬¤½¤Ī·Ö²¼¤Ī95%¤ĪČȤĖ¤¢¤ė¤«ÅŠ¶Ø ? ĶāČ£ŗ¢o¢Õh¤ņČ“ ? ¤½¤Ī¢Õh¤¬Ęš¤³¤ė¤³¤Č¤Ļ5%Ī“ŗ(¤Ž¤ģ)¤Ē¤¢¤ė ? ÄŚČ£ŗ¢o¢Õh¤ņČ“¤Ē¤¤Ź¤¤ ? ¤½¤Ī¢Õh¤¬Ęš¤³¤ė¤³¤Č¤Ļ5%ŅŌÉĻ¤Ē¤¢¤ė 49 Óčy½yÓѧ£ŗŹ¶Ø
- 50. ? Äø±ČĀŹ¤ĪŹ¶Ø ? ¤µ¤¤¤³¤ķ¤ĪÕż“_ŠŌ ? ¤µ¤¤¤³¤ķ¤ņ12,000Ķ¶¤²¤ė¤Č1¤¬2,100»Ų³ö¤æ”¢Ķį¤ó¤Ē¤¤¤ė¤«ÓŠŅāĖ® Ź5%¤ĒŹ¶Ø¤»¤č ? ¢o¢Õh ? „µ„¤„³„ķ¤Ī1¤¬³ö¤ė“_ĀŹ¤Ļ1/6 ? Ź¶Ø½yÓĮæ ? Ė±¾±ČĀŹ?Äø±ČĀŹ Äø±ČĀŹ£Ø£±©`Äø±ČĀŹ£© Ė±¾¤Ī“󤤵 ? ·Ö²¼£ŗĖŹÕżŅ·Ö²¼ 50 Óčy½yÓѧ£ŗÄø±ČĀŹ(Ź¶Ø)
- 51. ? Äø±ČĀŹ¤ĪŹ¶Ø ? Ź¶Ø½yÓĮæ(¢Õh¤¬Õż¤·¤¤) ? Ė±¾±ČĀŹ?Äø±ČĀŹ Äø±ČĀŹ£Ø£±©`Äø±ČĀŹ£© Ė±¾¤Ī“󤤵 ? 2100 12000 ? 1 6 1 6(1? 1 6) 12000 ? 2.45 ? ½Y¹ū£ŗIČŹ¶Ø(”Ł) ? Č“(”ø„µ„¤„³„ķ¤Ī1¤¬³ö¤ė“_ĀŹ¤Ļ1/6”¹¤Č¤ĻŃŌ¤Ø¤Ź¤¤) ? 2.45(Ź¶Ø½yÓĮæ)>1.96 51 Óčy½yÓѧ£ŗÄø±ČĀŹ(Ź¶Ø) 0 0.1 0.2 0.3 0.4 0.5 -4 -3 -2 -1 0 1 2 3 4 1.96 2.45 -1.96
- 52. ? Äø±ČĀŹ¤ĪŹ¶Ø ? Č“£ŗ2.45(Ź¶Ø½yÓĮæ)>1.96 ? ŅāĪ¶ ? 2.45£ŗ¤³¤Ī¢Õh¤¬³É¤źĮ¢¤Ä¤Ī¤Ļ100»Ų¤Ė0.7»Ų ? 1.96£ŗ¤³¤Ī¢Õh¤¬³É¤źĮ¢¤Ä¤Ī¤Ļ100»Ų¤Ė2.5»Ų 52 Óčy½yÓѧ£ŗÄø±ČĀŹ(Ź¶Ø) 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.500 0.496 0.492 0.488 0.484 0.480 0.476 0.472 0.468 0.464 0.1 0.460 0.456 0.452 0.448 0.444 0.440 0.436 0.433 0.429 0.425 1.8 0.036 0.035 0.034 0.034 0.033 0.032 0.031 0.031 0.030 0.029 1.9 0.029 0.028 0.027 0.027 0.026 0.026 0.025 0.024 0.024 0.023 2.0 0.023 0.022 0.022 0.021 0.021 0.020 0.020 0.019 0.019 0.018 2.3 0.011 0.010 0.010 0.010 0.010 0.009 0.009 0.009 0.009 0.008 2.4 0.008 0.008 0.008 0.008 0.007 0.007 0.007 0.007 0.007 0.006 2.5 0.006 0.006 0.006 0.006 0.006 0.005 0.005 0.005 0.005 0.005 ĖŹÕżŅ·Ö²¼±ķ ŗįŻSÉĻĪ» ŗįŻSĻĀĪ» ÉĻČ“_ĀŹ
- 53. ? ChatGPT ? ? ¤µ¤¤¤³¤ķ¤ņ12,000Ķ¶¤²¤ė¤Č1¤¬2,100»Ų³ö¤æ”¢Ė±¾¤Ī“󤤵¤¬Ź®·Ö¤Ė “󤤤¤Č¤·¤Ę”¢Ķį¤ó¤Ē¤¤¤ė¤«ÓŠŅāĖ®Ź5%¤ĒŹ¶Ø¤»¤č ? »Ų“š ? ¤³¤Īī}¤Ē¤Ļ”¢Ė±¾¤Ī“󤤵¤¬Ź®·Ö¤Ė“󤤤¤æ¤į”¢ÖŠŠÄOĻŽ¶ØĄķ ¤Ė¤č¤ź”¢Ė±¾·Ö²¼¤¬½üĖʵĤĖÕżŅ·Ö²¼¤Ė¾¤¦¤Č¢¶Ø¤Ē¤¤Ž¤¹”£¤½ ¤Ī¤æ¤į”¢Äø¼Æā¤Ī„Ń„é„į©`„æ¤ņĶĘ¶Ø¤¹¤ė¤æ¤į¤ĪŹ¶Ø¤Ė¤Ļ”¢zŹ¶Ø¤ņ Ź¹ÓƤ·¤Ž¤¹”£ ? <Ź”ĀŌ> ? ¤·¤æ¤¬¤Ć¤Ę”¢½YÕ¤Č¤·¤Ę”¢¤µ¤¤¤³¤ķ¤ĻÓŠŅāĖ®Ź5%¤ĒĶį¤ó¤Ē¤¤¤ė¤Č ½YÕø¶¤±¤ė¤³¤Č¤¬¤Ē¤¤Ž¤¹”£ 53 Óčy½yÓѧ£ŗÄø±ČĀŹ(Ź¶Ø)
- 54. ? ÄøĘ½¾ł(Š”Ė±¾”¢Äø¼Æā£ŗÕżŅ·Ö²¼) ? ²»Ę«·ÖÉ¢£½Ė±¾·ÖÉ¢*n/(n-1) ? Ė±¾¤Ī·ÖÉ¢¤ĻŠ”¤µ¤Æ¤Ź¤ź¤¬¤Į¤Ź¤Ī¤ĒŃaÕż¤¹¤ė ? Ź¶Ø½yÓĮæ ? Ė±¾Ę½¾ł©`ÄøĘ½¾ł ²»Ę«·ÖÉ¢ Ė±¾¤Ī“󤤵 ? t·Ö²¼(×ŌÓÉ¶Č£ŗĖ±¾¤Ī“󤤵ØD1) 54 Óčy½yÓѧ£ŗÄøĘ½¾ł
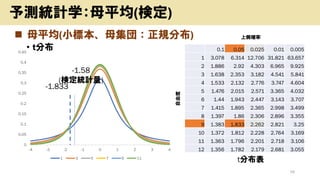
- 55. ? ÄøĘ½¾ł(Š”Ė±¾”¢Äø¼Æā£ŗÕżŅ·Ö²¼) ? Ē°Ģį ? ŃuĘ·10¤ĪŹŁĆü£ŗ1,950rég ? Äø·ÖÉ¢£ŗĪ“ÖŖ ? ²»Ę«·ÖÉ¢£ŗ(100rég)^2 ? ¢¶Ø£ŗ ? ŃuĘ·¤ĪĘ½¾łŹŁĆü£ŗ2,000rég ? Ź¶Ø½yÓĮæ ? Ė±¾Ę½¾ł©`ÄøĘ½¾ł ²»Ę«·ÖÉ¢ Ė±¾¤Ī“󤤵 ? 1950 ?2000 100?100 10 ? -1.58 ? t·Ö²¼(×ŌÓÉ¶Č£ŗĖ±¾¤Ī“󤤵ØD1) ? ʬȏ¶Ø(ŹŁĆü¤¬¶Ģ¤¤öŗĻ¤Ī¤ß¤¬ī}) 55 Óčy½yÓѧ£ŗÄøĘ½¾ł(Ź¶Ø)
- 56. ? ÄøĘ½¾ł(Š”Ė±¾”¢Äø¼Æā£ŗÕżŅ·Ö²¼) ? t·Ö²¼ 56 Óčy½yÓѧ£ŗÄøĘ½¾ł(Ź¶Ø) 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 -4 -3 -2 -1 0 1 2 3 4 1 3 5 7 9 11 0.1 0.05 0.025 0.01 0.005 1 3.078 6.314 12.706 31.821 63.657 2 1.886 2.92 4.303 6.965 9.925 3 1.638 2.353 3.182 4.541 5.841 4 1.533 2.132 2.776 3.747 4.604 5 1.476 2.015 2.571 3.365 4.032 6 1.44 1.943 2.447 3.143 3.707 7 1.415 1.895 2.365 2.998 3.499 8 1.397 1.86 2.306 2.896 3.355 9 1.383 1.833 2.262 2.821 3.25 10 1.372 1.812 2.228 2.764 3.169 11 1.363 1.796 2.201 2.718 3.106 12 1.356 1.782 2.179 2.681 3.055 -1.833 -1.58 (Ź¶Ø½yÓĮæ) t·Ö²¼±ķ ×ŌÓÉ¶Č ÉĻČ“_ĀŹ
- 57. ? ÄøĘ½¾ł(Š”Ė±¾”¢Äø¼Æā£ŗÕżŅ·Ö²¼) ? Ź¶Ø½Y¹ū: ? Č“¤µ¤ģ¤Ź¤¤ ? ”øĘ½¾łŹŁĆü¤¬2,000rég”¹¤Ē¤¢¤ė¤³¤Č¤ņ·ń¶Ø¤Ē¤¤Ź¤¤ ? -1.833<-1.58(Ź¶Ø½yÓĮæ)¤ĪŅāĪ¶ ? -1.58£ŗ¤³¤Ī¢Õh¤¬³É¤źĮ¢¤Ä¤Ī¤Ļ100»Ų¤Ė5»Ų¤č¤ź¤Ļ“󤤤 ? -1.833£ŗ¤³¤Ī¢Õh¤¬³É¤źĮ¢¤Ä¤Ī¤Ļ100»Ų¤Ė5»Ų 57 Óčy½yÓѧ£ŗÄøĘ½¾ł(Ź¶Ø) 0.1 0.05 0.025 0.01 0.005 9 1.383 1.833 2.262 2.821 3.25
- 58. ? ChatGPT ? ? ŃuĘ·10¤ĪŹŁĆü¤ņÕ{¤Ł¤æ¤é”¢Ę½¾ł1950rég¤«¤Ä²»Ę«·ÖÉ¢¤¬10000¤Ē ¤¢¤Ć¤æ”¢Äø·ÖÉ¢¤¬Ī“ÖŖ¤Č¤·¤Ę”¢ŃuĘ·¤ĪĘ½¾łŹŁĆü¤¬2000rég¤Ē¤¢¤ė¤«”¢ 95£„¤ĒŹ¶Ø¤»¤č ? »Ų“š ? ¤³¤Īī}¤Ē¤Ļ”¢Äø¼Æā¤ĪĘ½¾łŹŁĆü¤¬2000rég¤Ē¤¢¤ė¤«¤É¤¦¤«¤ņŹ¶Ø¤· ¤Ž¤¹”£ ? <Ź”ĀŌ> ? ¢o¢Õh (H?): ŃuĘ·¤ĪĘ½¾łŹŁĆü¤Ļ2000rég¤Ē¤¢¤ė”£ ? <Ź”ĀŌ> ? ¢o¢Õh¤ņČ“¤Ē¤¤Ž¤»¤ó”£¤·¤æ¤¬¤Ć¤Ę”¢¤³¤ĪŹ¶Ø¤Ē¤Ļ”¢ŃuĘ·¤ĪĘ½¾ł ŹŁĆü¤¬2000rég¤Ē¤¢¤ė¤Č¤¤¤¦Ö÷¤ņÖ§³Ö¤¹¤ėŌ^¤ĻŅ¤Ä¤«¤ź¤Ž¤»¤ó”£ 58 Óčy½yÓѧ£ŗÄøĘ½¾ł(Ź¶Ø) ¤Ź¤¤ égß`¤¤
- 59. ? ½yÓ ? Ćć¤¹¤ėż¤¢¤ź ? ČÕ”©¤ĪÉś»ī£ŗ¤¤¤ķ¤¤¤ķ¤Ź„Ē©`„æ¤ĪÕż¤·¤¤Ņ·½ ? ČÕ”©¤ĪIÕ£ŗIæ„¢„Ć„× ? „Ē©`„愵„¤„Ø„ó„Ę„£„¹„Č£ŗøß½oÓė¤Ų¤ĪµĄ ? Ćć¤Ī„“©`„ėø¶¤± ? ½yÓŹ¶Ø¤¬¤Ŗį¤į 59 ¤Ŗ¤ļ¤ź¤Ė
- 60. ? ½yÓŹ¶Ø3¼ ? „ģ„Ł„ė£ŗøߊ£ ? ±ŲŅŖ¤Ź½yÓ¤Ī¹«Ź½£ŗŹż ? ±ŲŅŖ¤ŹĆćrég£ŗ1ßLég ? ½yÓŹ¶Ø2¼ ? „ģ„Ł„ė£ŗ“óѧ½ĢšB ? ±ŲŅŖ¤Ź½yÓ¤Ī¹«Ź½£ŗ20”«30¤°¤é¤¤ ? ±ŲŅŖ¤ŹĆćrég£ŗ1¤«ŌĀ ? ×¢Ņāµć£ŗß^Č„Ö÷Ģå¤ĪĆć ? ¹«Ź½½ĢæĘų£ŗėy¤·¤¤(¤Ū¤Ü½yÓ¤Ī½ĢæĘų¤½¤Ī¤Ž¤Ž) ? ¹«Ź½ī}¼Æ£ŗ½āÕh¤¬·Ö¤«¤ź¤Ė¤Æ¤¤(„Ķ„ƄȤņ¤¢¤µ¤ė±ŲŅŖ¤¢¤ź) ? ß^Č„ ? https://www.toukei-kentei.jp/prepare/kakomon/ 60 Ńa×ć£ŗ½yÓŹ¶Ø¤Ī„ģ„Ł„ė