"Learning transferable architectures for scalable image recognition" Paper Review
2 likes517 views

"Learning transferable architectures for scalable image recognition, 2018 CVPR" Paper Review. NASNet




















![[ĒĢ£ĻĄŁņ¢┤] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=560&fit=bounds)















![[paper review] ņåÉĻĘ£ļ╣ł - Eye in the sky & 3D human pose estimation in video with ...](https://cdn.slidesharecdn.com/ss_thumbnails/190321eyeposegyubin-190517100712-thumbnail.jpg?width=560&fit=bounds)



More Related Content
What's hot (20)
Similar to "Learning transferable architectures for scalable image recognition" Paper Review (20)





![[ļČĆņŖżĒŖĖņ║ĀĒöä Tech Talk] ļ░░ņ¦ĆņŚ░_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=560&fit=bounds)




![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=560&fit=bounds)







More from LEE HOSEONG (14)













"Learning transferable architectures for scalable image recognition" Paper Review
- 1. Learning Transferable Architectures for Scalable Image Recognition Barret Zoph, Vijay Vasudevanm Jonathon Shlens, Quoc V. Le Google Brain
- 2. ļ¬®ņ░© ŌĆó Introduction ŌĆó Contribution ŌĆó Method ŌĆó Result
- 3. Introduction ŌĆó Neural Architecture Search with Reinforcement Learning(NAS) ĒøäņåŹ ļģ╝ļ¼Ė ŌĆó NAS : CNN(CIFAR-10), RNN(Penn Treebank) ĻĄ¼ņĪ░ ņäżĻ│ä ŌĆó CIFAR-10 ņØ┤ļØ╝ļŖö ņ×æņØĆ ļŹ░ņØ┤Ēä░ņģŗ ĒĢÖņŖĄņŚÉ 800 GPU, 28days ņåīņÜö ’āĀ Ēü░ ļŹ░ņØ┤Ēä░ņģŗņØĆ?? ŌĆó Learning Transferable Architectures for Scalable Image Recognition (2018, CVPR) ŌĆó CNNņŚÉ ņ┤łņĀÉņØä ļ¦×ņČöņ¢┤ ņØ┤ņŗØ Ļ░ĆļŖźĒĢśĻ│Ā ļŹö ĒÜ©ņ£©ņĀüņØĖ architectureļź╝ ņĀ£ņĢł(NASNet) ŌĆó CIFAR-10ņ£╝ļĪ£ ņ░ŠņØĆ Convolution CellņØä ņØ┤ņÜ®ĒĢśņŚ¼ ImageNetņŚÉ ņĀüņÜ® ’āĀ SOTA ņä▒ļŖź ļŗ¼ņä▒! ŌĆó NAS ļīĆļ╣ä ĒĢÖņŖĄņŚÉ ņåīņÜöļÉśļŖö ņŗ£Ļ░ä ļŗ©ņČĢ (500GPU, 4days ņåīņÜö, x7 speed up) * NAS : Nvidia K40 GPU / NASNet : Nvidia P100s GPU
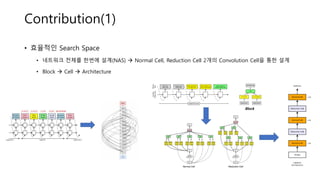
- 4. Contribution(1) ŌĆó ĒÜ©ņ£©ņĀüņØĖ Search Space ŌĆó ļäżĒŖĖņøīĒü¼ ņĀäņ▓┤ļź╝ ĒĢ£ļ▓łņŚÉ ņäżĻ│ä(NAS) ’āĀ Normal Cell, Reduction Cell 2Ļ░£ņØś Convolution CellņØä ĒåĄĒĢ£ ņäżĻ│ä ŌĆó Block ’āĀ Cell ’āĀ Architecture Block
- 5. Contribution(2) ŌĆó Transferability & Good Performance ŌĆó CIFAR-10ņ£╝ļĪ£ ņ░ŠņØĆ Convolution CellņØä ņØ┤ņÜ®ĒĢśņŚ¼ ļŹö Ēü░ DatasetņŚÉ ņĀüņÜ® Ļ░ĆļŖź ŌĆó CIFAR-10, ImageNet ĻĖ░ņżĆ SOTA ņä▒ļŖź ļŗ¼ņä▒ ŌĆó Object DetectionņŚÉ NASNet ĻĄ¼ņĪ░ļź╝ ņĀüņÜ®ĒĢśņśĆņØä ļĢī ļåÆņØĆ ņä▒ļŖź
- 6. Method(1) ŌĆó Overall architectures of the convolutional nets are manually predetermined ŌĆó Normal Cell - convolutional cells that return a feature map of the same dimension ŌĆó Reduction Cell - convolutional cells that return a feature map where the feature map height and width is reduced by a factor of two (Initial operation with stride of two conv) ŌĆó Using common heuristic to double the number of filters in the output whenever the spatial activation size is reduced ŌĆó N, ņ▓½ convolution cellņØś filter Ļ░£ņłśļŖö UserĻ░Ć ņ¦ĆņĀĢĒĢ┤ņŻ╝ņ¢┤ņĢ╝ ĒĢśļŖö ļ│Ćņłś
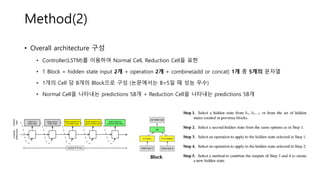
- 7. Method(2) ŌĆó Overall architecture ĻĄ¼ņä▒ ŌĆó Controller(LSTM)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Normal Cell, Reduction CellņØä Ēæ£Ēśä ŌĆó 1 Block = hidden state input 2Ļ░£ + operation 2Ļ░£ + combine(add or concat) 1Ļ░£ ņ┤Ø 5Ļ░£ņØś ļ¼Ėņ×ÉņŚ┤ ŌĆó 1Ļ░£ņØś Cell ļŗ╣ BĻ░£ņØś Blockņ£╝ļĪ£ ĻĄ¼ņä▒ (ļģ╝ļ¼ĖņŚÉņä£ļŖö B=5ņØ╝ ļĢī ņä▒ļŖź ņÜ░ņłś) ŌĆó Normal CellņØä ļéśĒāĆļé┤ļŖö predictions 5BĻ░£ + Reduction CellņØä ļéśĒāĆļé┤ļŖö predictions 5BĻ░£ Block
- 8. Method(2) ŌĆó Overall architecture ĻĄ¼ņä▒ (Cont.) ŌĆó Controller(LSTM)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Normal Cell, Reduction CellņØä Ēæ£Ēśä ŌĆó 1 Block = hidden state input 2Ļ░£ + operation 2Ļ░£ + combine(add or concat) 1Ļ░£ ņ┤Ø 5Ļ░£ņØś ļ¼Ėņ×ÉņŚ┤ ŌĆó Operation ņóģļźśļŖö ņל ņĢīļĀżņ¦ä ļ░®ļ▓ĢļĪĀ ņżæ 13Ļ░£ ŌĆó stride = 1 (Normal Cell) / stride = 1 or 2 (Reduction Cell)
- 9. Method(2) - Supplement ŌĆó Overall architecture ĻĄ¼ņä▒(Cont.) ŌĆó stride = 1 or 2 (Reduction Cell) (ņČ£ņ▓ś : https://github.com/titu1994/Keras-NASNet/blob/master/nasnet.py)
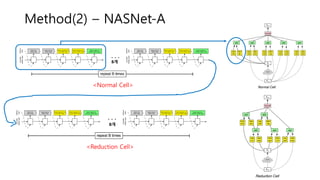
- 10. Method(2) ŌĆō NASNet-A ┬Ę ┬Ę ┬Ę <Normal Cell> ┬Ę ┬Ę ┬Ę <Reduction Cell> BĻ░£ BĻ░£
- 11. Training with RL ŌĆó Controller(LSTM)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņśłņĖĪĒĢ£ CellņØä ĒåĄĒĢ┤ Architecture ņāØņä▒ ŌĆó Ļ░ĢĒÖöĒĢÖņŖĄ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ REINFORCE ļīĆņŗĀ Proximal Policy Optimization(PPO) ņé¼ņÜ® ŌĆó PPO : 2017, OpenAI ŌĆó ņĀäņ▓┤ņĀüņØĖ ĒĢÖņŖĄ ļ░®ļ▓ĢņØĆ NASņÖĆ Ļ▒░ņØś ņ£Āņé¼ ŌĆó State : controllerņØś hidden state ŌĆó Action : controllerĻ░Ć ņāØņä▒ĒĢ£ predictions ŌĆó Reward : Overall architectureņØś accuracy
- 12. Result(CIFAR-10) ŌĆó ĻĖ░ņĪ┤ņØś SOTAļĪ£ ņĢīļĀżņ¦ä networkņŚÉ ļ╣äĒĢ┤ ņÜ░ņłśĒĢ£ ņä▒ļŖź! ŌĆó NASņØś CNN architectureļ│┤ļŗż ņÜ░ņłśĒĢ£ ņä▒ļŖź ŌĆó Ēæ£ņØś Ļ▓░Ļ│╝ļŖö 5ļ▓ł ņłśĒ¢ēĒĢśņŚ¼ ĒÅēĻĘĀ ļéĖ Ļ▓░Ļ│╝ ŌĆó Best performance : 2.19% ŌĆó Ļ┤äĒśĖ ņĢłņØś ņł½ņ×É ŌĆó (N @ # of Filters in 1st Conv Cell)
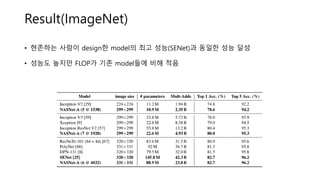
- 13. Result(ImageNet) ŌĆó ĒśäņĪ┤ĒĢśļŖö ņé¼ļ×īņØ┤ designĒĢ£ modelņØś ņĄ£Ļ│Ā ņä▒ļŖź(SENet)Ļ│╝ ļÅÖņØ╝ĒĢ£ ņä▒ļŖź ļŗ¼ņä▒ ŌĆó ņä▒ļŖźļÅä ļåÆņ¦Ćļ¦ī FLOPĻ░Ć ĻĖ░ņĪ┤ modelļōżņŚÉ ļ╣äĒĢ┤ ņĀüņØī
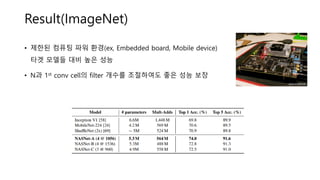
- 14. Result(ImageNet) ŌĆó ņĀ£ĒĢ£ļÉ£ ņ╗┤Ēō©Ēīģ Ēīīņøī ĒÖśĻ▓Į(ex, Embedded board, Mobile device) ĒāĆĻ▓¤ ļ¬©ļŹĖļōż ļīĆļ╣ä ļåÆņØĆ ņä▒ļŖź ŌĆó NĻ│╝ 1st conv cellņØś filter Ļ░£ņłśļź╝ ņĪ░ņĀłĒĢśņŚ¼ļÅä ņóŗņØĆ ņä▒ļŖź ļ│┤ņן
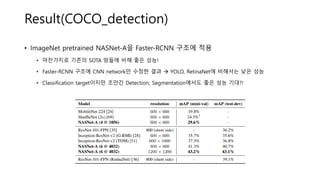
- 15. Result(COCO_detection) ŌĆó ImageNet pretrained NASNet-AņØä Faster-RCNN ĻĄ¼ņĪ░ņŚÉ ņĀüņÜ® ŌĆó ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ ĻĖ░ņĪ┤ņØś SOTA ļ¦ØļōżņŚÉ ļ╣äĒĢ┤ ņóŗņØĆ ņä▒ļŖź! ŌĆó Faster-RCNN ĻĄ¼ņĪ░ņŚÉ CNN networkļ¦ī ņłśņĀĢĒĢ£ Ļ▓░Ļ│╝ ’āĀ YOLO, RetinaNetņŚÉ ļ╣äĒĢ┤ņä£ļŖö ļé«ņØĆ ņä▒ļŖź ŌĆó Classification targetņØ┤ņ¦Ćļ¦ī ņĪ░ļ¦īĻ░ä Detection, SegmentationņŚÉņä£ļÅä ņóŗņØĆ ņä▒ļŖź ĻĖ░ļīĆ?!
- 16. Result(Random SearchņÖĆ ļ╣äĻĄÉ) ŌĆó Ļ░ĢĒÖöĒĢÖņŖĄņØä ņĀüņÜ®ĒĢśņśĆņØä ļĢīņÖĆ, Random Searchļź╝ ĒĢśņśĆņØä ļĢīņØś ņä▒ļŖź ņ░©ņØ┤ ļ╣äĻĄÉ ŌĆó RLņØä ņé¼ņÜ®ĒĢśņśĆņØä ļĢīĻ░Ć RSļź╝ ņé¼ņÜ®ĒĢśņśĆņØä ļĢī ļ│┤ļŗż ŌĆó NASņØś RL vs RS ĻĘĖļלĒöä ļīĆļ╣ä Ļ▓®ņ░©Ļ░Ć ņżäņ¢┤ļō” ’āĀ ņĀ£ņĢłĒĢ£ Search spaceĻ░Ć ĒÜ©ņ£©ņĀüņ×äņØä ņ”Øļ¬ģ
- 17. Discussion ŌĆó CNN, Classification ĒāĆĻ▓¤ņ£╝ļĪ£ ņóŗņØĆ ņä▒ļŖźĻ│╝ ĒÖĢņןņä▒ņØä ļ│┤ņŚ¼ņżĆ ņŚ░ĻĄ¼ ŌĆó ņØ┤ļ»Ėņ¦ĆņØś sizeĻ░Ć Ēü░ Ļ▓ĮņÜ░ņŚÉļÅä ņóŗņØĆ ņä▒ļŖź ĻĖ░ļīĆ ŌĆó ņĀ£ņĪ░ņŚģ ļŹ░ņØ┤Ēä░ņŚÉņä£ļÅä ņóŗņØĆ ļČäļźś ņä▒ļŖźņØ┤ ļéśņś¼ Ļ▓āņ£╝ļĪ£ ņāØĻ░ü! ŌĆó ņŚ¼ņĀäĒ׳ ĻĖ┤ ĒĢÖņŖĄ ņŗ£Ļ░ä(500GPU, 4days) ’āĀ ENAS! ŌĆó Detection, SegmentationņŚÉņä£ļŖö ņĢäņ¦ü Ļ┤äļ¬®ĒĢĀ ļ¦īĒĢ£ ņŚ░ĻĄ¼ļŖö ļéśņśżņ¦Ć ņĢŖņØī ŌĆó ClassificationņØä ņĀĢļ│ĄĒĢśņśĆņ£╝ļŗł ņĪ░ļ¦īĻ░ä ļéśņś¼ Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆ