ēŅēđąčļéąðŧåģÜģĶąð―âÕh
18 likes6,729 views

ĪČĪęĪĒĪĻĪšēŧÕýČ·ĪĘģĄËųĪÏķāĄĐÓÐĪęĪÞĪđĪŽĪĘĪóĪĮēŅēđąčļéąðŧåģÜģĶąðĪŽĪģĪóĪĘĪËĨÕĨĐĐ`ĨŦĨđĪĩĪėĪŋĪÎĪŦĪÎÕhÃũĪËĪĘĪÃĪÆĪĪĪėĪÐĪČËžĪĪĪÞĪđ






![map
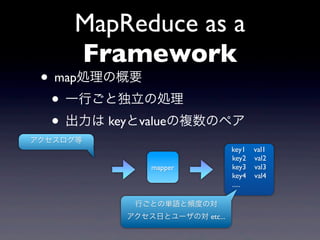
? évĘýĪōĘÜĪąČĄĪÃĪÆĪ―ĪėĪōĨęĨđĨČĪÎļũŌŠ
ËØĪË(ķĀÁĒĪË)ßmÓÃĪđĪëļßëAévĘý
map f [x1 , x2 , ..., xn ] = [f (x1 ), f (x2 ), ..., f (xn )]
? (Āý)ĨęĨđĨČĪÎŌŠËØĪōĪ―ĪėĪūĪėķþąķĪđĪë
? map(lambda x: x*2 , [1,2,3,4,5])
évĘý f(x) ĨęĨđĨČ](https://image.slidesharecdn.com/mapreducegumi-100909073448-phpapp02/85/MapReduce-7-320.jpg)
![reduce
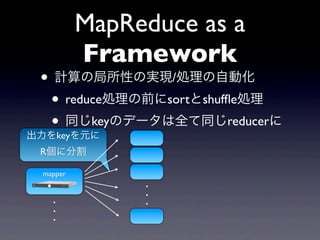
? ĨęĨđĨČĪČ,Ī―ĪÎŌŠËØĪō―YšÏĪđĪëķþíŅÝËã
ŨÓĪōĘÜĪąČĄĪÃĪÆŌŧĪÄĪÎ―YđûĪō·ĩĪđévĘý
reduce [x1 , x2 , ..., xn ] = x1 x2 , ..., xn
? (Āý)ĨęĨđĨČĪÎŌŠËØĪÎĪōŨãĪ·šÏĪïĪŧĪë
? reduce(lambda x,y: x+y),[2,4,6,8,10])
ķþíŅÝËã? ĨęĨđĨČ
·ÖÉĒIĀíĪÎĘĀ―įĪĮĪÏIĀíĪËĪčĪÃĪÆĪģĪģĪŽķþíŅÝËãĪČĪÏÏÞĪéĪĘĪĪ](https://image.slidesharecdn.com/mapreducegumi-100909073448-phpapp02/85/MapReduce-8-320.jpg)























ēŅēđąčļéąðŧåģÜģĶąð―âÕh
- 1. Introduction to MapReduce and all that jazz in Gumi Shunsuke AIHARA
- 2. Overview ? What is MapReduce? ? Product point of view ? Computational Model point of view ? Framework point of view ? Example tasks ? Simple experiments in Gumi using amazon elastic mapreduce ? Future work
- 3. Goal of this presentation ? MapReduceĪÎĪÉĪģĪŽĨĪĨąĪÆĪŋĪÎĪŦËûĪČÉŲ Ī·ß`ĪĶŌĩãĪŦĪéÕhÃũ ? MapReduceÐÍ·ÖÉĒIĀíĪÏĘđĪĶĪĀĪąĪĘĪé š gĪĀĪČŅÔĪĶĪģĪČĪōĀí―âĪ·ĪÆĪĪĪŋĪĀĪŊ ? ŧųąūĪÎŋžĪĻĪÏĪČĪÆĪâ gž ? ëyĪ·ĪĪēŋ·ÖĪÏëL ĪĩĪėĪÆĪĪĪë
- 5. MapReduce as a Product ? googleĪÎKÁзÖÉĒIĀíhūģ ? ·ÖÉĒĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāGFS ? KÁÐIĀíĨ·ĨđĨÆĨāMapReduce ? Hadoop(+HDFS)ĪÏĪ―ĪÎĨŊĨíĐ`Ĩó ? ĪģĪģĪŦĪéĪÏ, MapReduceĪČHadoopĪÏĪÛĪÜ ÍŽĪļĪâĪÎĪČĪ·ĪÆQĪĶ
- 6. MapReduce as a Computational Model ? MapReduceĪÏKÁÐÓËãĪÎĨŅĨéĨĀĨĪĨāĪŽÔŠ ? KÁÐŧŊĪ·ĪäĪđĪĪIĀíĨŅĨŋĐ`ĨóĪōĀûÓÃ ? KÁÐŧŊĪ·ĪäĪđĪĪIĀíĢŋ ? listIĀíĪÎmapévĘýĪČreduceévĘý ? ļąŨũÓÃĪÎoĪĪévĘýÐÍĨŨĨíĨ°ĨéĨßĨóĨ° KÁÐĨŨĨíĨ°ĨéĨßĨóĨ°ĪÎĨĮĨķĨĪĨóĨŅĨŋĐ`Ĩó (ĨđĨąĨëĨČĨóKÁÐĨŨĨíĨ°ĨéĨßĨóĨ°)
- 7. map ? évĘýĪōĘÜĪąČĄĪÃĪÆĪ―ĪėĪōĨęĨđĨČĪÎļũŌŠ ËØĪË(ķĀÁĒĪË)ßmÓÃĪđĪëļßëAévĘý map f [x1 , x2 , ..., xn ] = [f (x1 ), f (x2 ), ..., f (xn )] ? (Āý)ĨęĨđĨČĪÎŌŠËØĪōĪ―ĪėĪūĪėķþąķĪđĪë ? map(lambda x: x*2 , [1,2,3,4,5]) évĘý f(x) ĨęĨđĨČ
- 8. reduce ? ĨęĨđĨČĪČ,Ī―ĪÎŌŠËØĪō―YšÏĪđĪëķþíŅÝËã ŨÓĪōĘÜĪąČĄĪÃĪÆŌŧĪÄĪÎ―YđûĪō·ĩĪđévĘý reduce [x1 , x2 , ..., xn ] = x1 x2 , ..., xn ? (Āý)ĨęĨđĨČĪÎŌŠËØĪÎĪōŨãĪ·šÏĪïĪŧĪë ? reduce(lambda x,y: x+y),[2,4,6,8,10]) ķþíŅÝËã? ĨęĨđĨČ ·ÖÉĒIĀíĪÎĘĀ―įĪĮĪÏIĀíĪËĪčĪÃĪÆĪģĪģĪŽķþíŅÝËãĪČĪÏÏÞĪéĪĘĪĪ
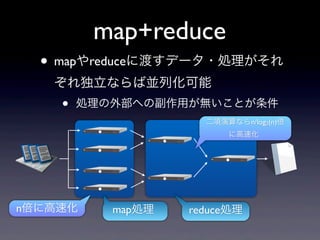
- 9. map+reduce ? mapĪäreduceĪËķÉĪđĨĮĐ`Ĩŋ?IĀíĪŽĪ―Īė ĪūĪėķĀÁĒĪĘĪéĪÐKÁÐŧŊŋÉÄÜ ? IĀíĪÎÍâēŋĪØĪÎļąŨũÓÃĪŽoĪĪĪģĪČĪŽĖõžþ ķþíŅÝËãĪĘĪén/log2(n)ąķ ĪËļßËŲŧŊ nąķĪËļßËŲŧŊ mapIĀí reduceIĀí
- 10. Simple distributed map+reduce ? IĀíĪ·ĪŋĪĪūÞīóĪĘ(ķāĘýĪÎ)ĨÕĨĄĨĪĨëĪË map+reduceĪ·ĪŋĪĪ ? ·ÖÉĒĨ·Ĩ§ĨëĪĮŅ}ĘýĨĩĐ`ĨÐĪËĨŋĨđĨŊ·ÖÉĒ ? MPIĪÏëyĪ·ĪĪ/īóŌÄĢĨĮĐ`ĨŋĪËÏōĪŦĪĘĪĪ ? ·ÖÉĒĨ·Ĩ§ĨëĪÏĨ·Ĩ§ĨëĨģĨÞĨóĨÉĪōËûĪÎ ĨĩĐ`ĨÐĪËÍķĪēĪë/ؚɷÖÉĒĪâŨÔÓŧŊ
- 11. GXP Grid and Cluster Shell ? |ūĐīóŅ§ĖïÆÖŅÐŨũģÉĪηÖÉĒĨ·Ĩ§Ĩë ? pythonĪËĪčĪëgŨ° ? ĨŊĨéĨđĨŋĨĩĐ`ĨÐĪËĪ·ĪÆssh―ÓūAĪōÐÐ ĪĪ―ÓūAÏČĨĩĐ`ĨÐÉÏĪĮĨģĨÞĨóĨÉĪōgÐÐ ? GXP ep: ·ÖÉĒĨ·Ĩ§Ĩë+ĨŋĨđĨŊĨđĨąĨļĨåĐ`Ĩé ? GXP make: ·ÖÉĒMake(gnu MakeĪηÖÉĒĨŠĨŨ Ĩ·ĨįĨóĪōĀûÓÃ)
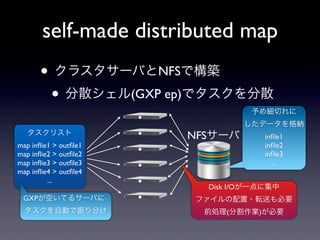
- 12. self-made distributed map ? ĨŊĨéĨđĨŋĨĩĐ`ĨÐĪČNFSĪĮšB ? ·ÖÉĒĨ·Ĩ§Ĩë(GXP ep)ĪĮĨŋĨđĨŊĪō·ÖÉĒ ÓčĪážĮÐĪėĪË Ī·ĪŋĨĮĐ`ĨŋĪōļņž{ ĨŋĨđĨŊĨęĨđĨČ NFSĨĩĐ`ĨÐ in?le1 map in?ie1 > out?le1 in?le2 map in?ie2 > out?le2 in?le3 map in?ie3 > out?le3 ... map in?ie4 > out?le4 ... Disk I/OĪŽŌŧĩãĪËžŊÖÐ GXPĪŽŋÕĪĪĪÆĪëĨĩĐ`ĨÐĪË ĨÕĨĄĨĪĨëĪÎÅäÖÃ?ÜËÍĪâąØŌŠ ĨŋĨđĨŊĪōŨÔÓĪĮÕņĪę·ÖĪą Į°IĀí(·ÖļîŨũI)ĪŽąØŌŠ
- 13. self-made distributed reduce ? maprĪČģÉĪÏĪÛĪÜÍŽĪļ ? reduceIĀíĪâŨÔ·ÖĪĮÓĘö(GXPĪĮ·ÖÉĒ) ĨŋĨđĨŊĪËŌĀīæĪŽĪĒĪėĪÐGXP makeĪĮ ÖÐégĨÕĨĄĨĪĨë ĨŋĨđĨŊĨęĨđĨČ(make) ĪōČŦĪÆąĢīæ tmp1: map1 map2 ... reduce1 map1 map2... .... out1: tmp1 tmp2 ... reduce2 tmp1 tmp2... ... result: out1 out2 ... Disk I/OĪŽŌŧĩãĪËžŊÖÐ reduce3 out1 out2 ... ĨÕĨĄĨĪĨëÜËÍĪŽąØŌŠ Ņ}ëjĪĘreduceIĀíĪōÓĘö īóÁŋĪÎÖÐégĨÕĨĄĨĪĨë
- 14. Bottleneck of distributed processing for massive data ? ĨŋĨđĨŊĨđĨąĨļĨåĐ`ĨéĪÏÐãĪĮĪâ... ? ĨÕĨĄĨĪĨëĪÎÅäÖÃĪÎî} ? ĨÕĨĄĨĪĨëĪηÖļî/·ÖÉĒÅäÖÃĪōŨÔÓŧŊĪ·ĪŋĪĪ ? Disk I/OĪō·ÖÉĒŧŊ ? ÓËãĪÎūÖËųÐÔĪÎî} ? ÅäÖÃöËųĪČÓËãöËųĪÏŨÔÓĩÄĪËÍŽĪļöËųĪĮ ? ĨÕĨĄĨĪĨëÜËÍĪōŨîÐĄÏÞĪË/ĨŋĨđĨŊĪōŨÔÓÉúģÉ KÁÐÓËã·ÖŌ°(GXP)ĪČīóŌÄĢĨĮĐ`Ĩŋ―âÎö·ÖŌ°(MapReduce)ĪÎĨÕĨĐĐ`ĨŦĨđĪÎß`ĪĪ
- 15. From map&reduce to MapReduce ? MapReduceĪÏmap+reduceĪōŋÂĘĩÄĪËKÁÐ ·ÖÉĒŧŊĪđĪëĨÕĨėĐ`ĨāĨïĐ`ĨŊ ? ŋÂĘĩÄĪĘ·ÖÉĒIĀíĪØĪÎđĪ·ōĪČÖÆžs ? ÃæĩđĪĘĘÖūAĪĪÎëL ? ĪŋĪĀĪ·ĄĒ―âĪĪŋĪĪî}ĪōMapReduceĪËšÏ ĪïĪŧĪÆÔŲÔOÓĪđĪëąØŌŠĪĒĪę
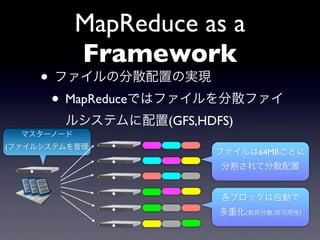
- 16. MapReduce as a Framework ? ĨÕĨĄĨĪĨëĪηÖÉĒÅäÖÃĪÎgŽF ? MapReduceĪĮĪÏĨÕĨĄĨĪĨëĪō·ÖÉĒĨÕĨĄĨĪ ĨëĨ·ĨđĨÆĨāĪËÅäÖÃ(GFS,HDFS) ĨÞĨđĨŋĐ`ĨÎĐ`ĨÉ (ĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāĪōđÜĀí ĨÕĨĄĨĪĨëĪÏ64MBĪīĪČĪË ·ÖļîĪĩĪėĪÆ·ÖÉĒÅäÖà ļũĨÖĨíĨÃĨŊĪÏŨÔÓĪĮ ķāÖØŧŊ(ؚɷÖÉĒ/ļßŋÉÓÃÐÔ)
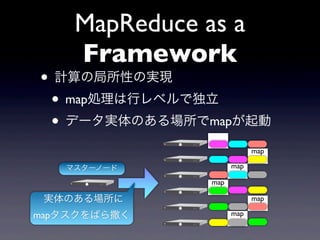
- 17. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF ? mapIĀíĪÏÐÐĨėĨŲĨëĪĮķĀÁĒ ? ĨĮĐ`ĨŋgĖåĪÎĪĒĪëöËųĪĮmapĪŽÆðÓ map map ĨÞĨđĨŋĐ`ĨÎĐ`ĨÉ map map gĖåĪÎĪĒĪëöËųĪË map mapĨŋĨđĨŊĪōĪÐĪéČöĪŊ map
- 18. MapReduce as a Framework ? mapIĀíĪÎļÅŌŠ ? ŌŧÐÐĪīĪČķĀÁĒĪÎIĀí ? ģöÁĶĪÏ keyĪČvalueĪÎŅ}ĘýĪÎĨÚĨĒ ĨĒĨŊĨŧĨđĨíĨ°ĩČ key1 val1 key2 val2 mapper key3 val3 key4 val4 ..... ÐÐĪīĪČĪÎ gÕZĪČîlķČĪÎ ĨĒĨŊĨŧĨđČÕĪČĨæĐ`ĨķĪÎ etc...
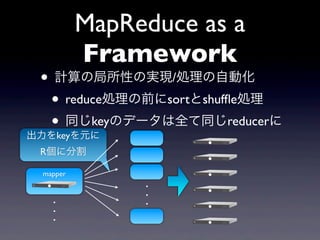
- 19. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF/IĀíĪÎŨÔÓŧŊ ? reduceIĀíĪÎĮ°ĪËsortĪČshuf?eIĀí ? ÍŽĪļkeyĪÎĨĮĐ`ĨŋĪÏČŦĪÆÍŽĪļreducerĪË mapper . . .
- 20. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF/IĀíĪÎŨÔÓŧŊ ? reduceIĀíĪÎĮ°ĪËsortĪČshuf?eIĀí ? ÍŽĪļkeyĪÎĨĮĐ`ĨŋĪÏČŦĪÆÍŽĪļreducerĪË ģöÁĶĪōkeyĪōÔŠĪË RĪË·Öļî mapper . . . . . .
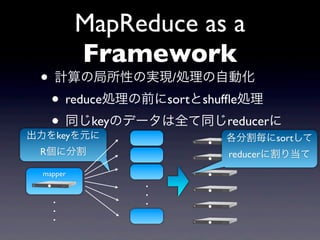
- 21. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF/IĀíĪÎŨÔÓŧŊ ? reduceIĀíĪÎĮ°ĪËsortĪČshuf?eIĀí ? ÍŽĪļkeyĪÎĨĮĐ`ĨŋĪÏČŦĪÆÍŽĪļreducerĪË ģöÁĶĪōkeyĪōÔŠĪË RĪË·Öļî mapper . . . . . .
- 22. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF/IĀíĪÎŨÔÓŧŊ ? reduceIĀíĪÎĮ°ĪËsortĪČshuf?eIĀí ? ÍŽĪļkeyĪÎĨĮĐ`ĨŋĪÏČŦĪÆÍŽĪļreducerĪË ģöÁĶĪōkeyĪōÔŠĪË ļũ·Öļî°ĪËsortĪ·ĪÆ RĪË·Öļî reducerĪËļîĪęĩąĪÆ mapper . . . . . .
- 23. MapReduce as a Framework ? ÓËãĪÎūÖËųÐÔĪÎgŽF/IĀíĪÎŨÔÓŧŊ ? reduceIĀíĪÎĮ°ĪËsortĪČshuf?eIĀí ? ÍŽĪļkeyĪÎĨĮĐ`ĨŋĪÏČŦĪÆÍŽĪļreducerĪË ģöÁĶĪōkeyĪōÔŠĪË ļũ·Öļî°ĪËsortĪ·ĪÆ RĪË·Öļî reducerĪËļîĪęĩąĪÆ mapper . reduceĪÏkeyĪĒĪŋĪę1ŧØĪÎĪßĪÎgÐÐĪĮŋÉÄÜ . . . . ËûĪÎmapIĀíĪČķĀÁĒĪËreducerĪËÍķĪēĪëĪģĪČĪŽŋÉÄÜ .
- 24. MapReduce as a Framework ? MapReduceĪÏkey-val pairĪŽIĀíĪÎÖÐÐÄ ? Ņ}ëjĪĘIĀíĪÏŌŧŧØĪÎMapReduceĪĮĪÏëy ? MapReduceĪĮŅ}ëjĪĘIĀí ? MapReduceĪōķāķÎŧŊĪ·ĪÆę ? MapReduceĪÏ gžĪĀĪŽøÓÃĩÄ
- 25. MapReduce as a Framework ? MapReduceĪÎÁžĪĩ ? ·ÖÉĒĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāĪČĪÎ―MĪßšÏĪïĪŧ ĪËĪčĪëI/O·ÖÉĒĪČmapIĀíĪÎūÖËųŧŊ ? shuf?eIĀíĪΧČëĪËĪčĪëreduceĪΚŌŨ ŧŊ?ūÖËųŧŊ?ŋÂĘĩÄĪĘKÁÐŧŊ ? ķāķÎŧŊĪËĪčĪęŅ}ëjĪĘIĀíĪËĪâę
- 26. However... ? Disk I/OĪŽÉŲĪĘĪĪ or MapReduceĪËÂäĪČĪ· ĪËĪŊĪĪöšÏĪÏGXPĪŽąãĀû ? MapReduceĪōĘđĪŠĪĶĪČĪđĪëĮ°ĪË... ? NFSĪâŨî―üĪÏÔįĪĪ(EMCĪäNetApp) ? ĘýĘŪGģĖķČĪĘĪéĨáĨâĨęĪË\Īë ? ĨĒĨëĨīĨęĨšĨāĪōŌÖąĪđ ? C++ĪäOCamlĪĮøĪŊ, sed & awkĪĮIĀí
- 27. Example tasks
- 28. simple experiment using amazon EMR ? gumiĪĮĪâĨíĨ°―âÎöĪō·ÖÉĒIĀíŧŊ ? ß^ČĨČŦĪÆĪÎĨĮĐ`ĨŋĪËĪ·ÐÂĪ·ĪĪIĀí ? ģéģöĪđĪëĨĮĐ`Ĩŋ ? ģõŧØĨĒĨŊĨŧĨđČÕĪŦĪéĪÎū@ūAĘý ? ĨæĐ`ĨķégĨĪĨóĨŋĨéĨŊĨ·ĨįĨóĨėĐ`ĨČ
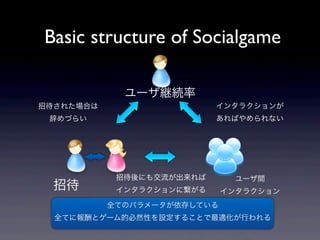
- 29. Basic structure of Socialgame ĨæĐ`Ĩķū@ūAÂĘ ÕÐīýĪĩĪėĪŋöšÏĪÏ ĨĪĨóĨŋĨéĨŊĨ·ĨįĨóĪŽ īĮĪáĪÅĪéĪĪ ĪĒĪėĪÐĪäĪáĪéĪėĪĘĪĪ ÕÐīýááĪËĪâ―ŧÁũĪŽģöĀīĪėĪÐ ĨæĐ`Ĩķég ÕÐīý ĨĪĨóĨŋĨéĨŊĨ·ĨįĨóĪËŋĪŽĪë ĨĪĨóĨŋĨéĨŊĨ·ĨįĨó ČŦĪÆĪÎĨŅĨéĨáĐ`ĨŋĪŽŌĀīæĪ·ĪÆĪĪĪë ČŦĪÆĪËóģęĪČĨēĐ`ĨāĩÄąØČŧÐÔĪōÔOķĻĪđĪëĪģĪČĪĮŨîßmŧŊĪŽÐÐĪïĪėĪë
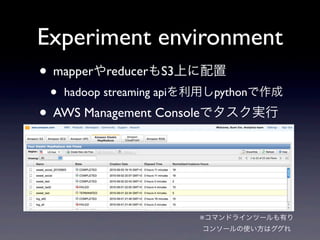
- 30. Experiment environment ? ČŦĨēĐ`ĨāĨĩĐ`ĨÐĪÎapacheĨíĨ°Īōamazon S3ĨđĨČĨėĐ`ĨļĪËąĢīæ ? HadoopĪÎHDFSÏāĩą ? ĨíĨ°ĪËĪÏĨĒĨŊĨŧĨđĨæĐ`ĨķŨReŨÓĪōļķÓë ? amazon elastic mapreduceĪōÓÃĪĪĪÆ·ÖÉĒI ĀíĪōÐÐĪĶ ? EC2ĨĪĨóĨđĨŋĨóĨđ+HadoopĪÎģÉ
- 31. Experiment environment ? ČŦĨēĐ`ĨāĨĩĐ`ĨÐĪÎapacheĨíĨ°Īōamazon S3ĨđĨČĨėĐ`ĨļĪËąĢīæ ĩŦĪ·MapReduceĪŽÓĪŊöËųĪČ ? HadoopĪÎHDFSÏāĩą ĨÕĨĄĨĪĨëĪōąĢīæĪ·ĪÆĪĪĪëöËųĪÏe ? ĨíĨ°ĪËĪÏĨĒĨŊĨŧĨđĨæĐ`ĨķŨReŨÓĪōļķÓë ? amazon elastic mapreduceĪōÓÃĪĪĪÆ·ÖÉĒI ĀíĪōÐÐĪĶ ? EC2ĨĪĨóĨđĨŋĨóĨđ+HadoopĪÎģÉ
- 32. Experiment environment ? mapperĪäreducerĪâS3ÉÏĪËÅäÖÃ ? hadoop streaming apiĪōĀûÓÃĪ·pythonĪĮŨũģÉ ? AWS Management ConsoleĪĮĨŋĨđĨŊgÐÐ ĄųĨģĨÞĨóĨÉĨéĨĪĨóĨÄĐ`ĨëĪâÓÐĪę ĨģĨóĨ―Đ`ĨëĪÎĘđĪĪ·―ĪÏĨ°Ĩ°Īė
- 33. Persistence rate http://ec2-75-101-191-9.compute-1.amazonaws.com/admin/sweet/ ? ĨæĐ`ĨķĪŽģõŧØĨĒĨŊĨŧĨđĪÎnČÕááĪËĪâĨĒĨŊĨŧĨđĪ· ĪÆĪĪĪëĪŦĪÉĪĶĪŦĪōĨÐĨÖĨëĨÁĨãĐ`ĨČĪĮŋÉŌŧŊ ? ĨēĐ`ĨāĨŨĨėĨĪĪŽĨëĐ`ĨÁĨóŧŊĪ·ĪÆĪĪĪëĪŦĪÉĪĶĪŦ
- 34. Calucurate persistence rate ? mapIĀíĪÎÄÚČÝ ķĀŨÔapachĨíĨ°ĨŅĐ`ĨĩĐ` csvĨâĨļĨåĐ`Ĩë+ĶÁĪōĀûÓÃĪ·ĪÆĨŅĐ`Ĩđ ŌŧÐÐĪīĪČĪËIĀí ĨæĐ`ĨķidĪōkey,ČÕļķĪÎisoąíÓĪōvalĪČĪ·ĪÆtabĮøĮÐĪęĪĮģö
- 35. Calucurate persistence rate ? reduceIĀíĪÎÄÚČÝ ĨæĐ`ĨķĪČČÕļķĨŧĨÃĨČĪōÓ ŌŧĨÚĨĒĪīĪČĪËIĀí ČÕļķĪōsetĪÎÐÎĪĮÓåh ĨæĐ`ĨķĪīĪČĪËĨĒĨŊĨŧĨđČÕĪōNíĪĮÓåh
- 36. Calucurate persistence rate ? ááIĀí ? MapReduceĪÎ―YđûĪōĨĀĨĶĨóĨíĐ`ĨÉĪ·ĪÆIĀí ? amChart(bubble)ÓÃĪÎĨĮĐ`ĨŋĪËžÓđĪ ÎÄŨÖÁÐĪŦĪédateĨŠĨÖĨļĨ§ĨŊĨČĪØ ģõŧØĨĒĨŊĨŧĨđČÕĪÎČĄĪęģöĪ· ģõĨĒĨŊĨŧĨđČÕĪČĨŠĨÕĨŧĨÃĨČĪō ĨÚĨĒĪËĪ·ĪÆĨŦĨĶĨóĨČ žŊÓ―YđûĪōĨÕĨĄĨĪĨëģöÁĶ
- 37. Result: Persistence rate http://ec2-75-101-191-9.compute-1.amazonaws.com/admin/sweet/ ? ŋkÝSĪŽģõŧØĨĒĨŊĨŧĨđČÕ ? šáÝSĪŽģõŧØĨĒĨŊĨŧĨđČÕĪŦĪéĪÎĨŠĨÕĨŧĨÃĨČ ? ŋkÝSšáÝSđēĪËpËĨĪŽÉŲĪĘĪĪĪģĪČĪŽÍûĪÞĪ·ĪĪ
- 38. user2user interaction rate Special Thanks!! Mr. Kamatani!! ? DAUĪËĪ·ĪÆ,ËûĪÎĨæĐ`ĨķĪËĪ·ĪÆĨĒĨŊĨ·ĨįĨó ĪōÆðĪģĪ·ĪŋĨæĐ`ĨķĪÎĘýĪōąČÝ^ ? Ĩ―Đ`Ĩ·ĨãĨëÐÔĪōÓĪëÖļËĪČĪ·ĪÆaiharaĪŽķĻÁx ? ēÎŋž:îŋÍégĨĪĨóĨŋĨéĨŊĨ·ĨįĨó(đúîIķþĀÉ)
- 39. user2user interaction rate ? ĨģĐ`ĨÉĪÏÉŲĪ·éLĪĪĪÎĪĮļîÛ ? ĨģĨáĨóĨČĩČĪÎURLĨŅĨŋĐ`ĨóĪō·ÖîžŊÓ ? DAUĪÏžČīæĪÎ―âÎögĪßĨĮĐ`ĨŋĪōĀûÓà ? mapĨŋĨđĨŊ: ? ČÕļķĪŽkey ? ĨæĐ`ĨķĐ`idĪČĨĒĨŊĨ·ĨįĨóĪÎĨÚĨĒĪŽvalue
- 40. user2user interaction rate ? reduceĨŋĨđĨŊ: ? ČÕļķĪīĪČĪËIĀí ? keyĪōĨĒĨŊĨ·ĨįĨó,valueĪōĨæĐ`ĨķĐ`idĪÎ setĪČĪ·ĪŋdictionaryĪōŨũģÉ ? ĨæĐ`ĨķidĪÎĨŧĨÃĨČĪōÔŠĪË, ČÕ-ĨĒĨŊĨ·Ĩį Ĩó-ČËĘýĪÎ3ĪÄ―MĪōŨũģÉ
- 41. Result:user2user interaction rate Special Thanks!! Mr. Kamatani!! ? ĨĪĨóĨŋĨéĨŊĨ·ĨįĨóĪŽķāĪŊĪĘĪëĪČĨģĨßĨåĨËĨąĐ` Ĩ·ĨįĨóĪÎöĪČĪĘĪęŌŨĪŊĨæĐ`ĨķĪÎĨĒĨŊĨÆĨĢĨÖÂĘ ĪŽÉÏĪŽĪë(ĨģĨßĨåĨËĨÆĨĢĪČĪ·ĪÆģÉÁĒ) ? ĨĪĨóĨŋĨéĨŊĨ·ĨįĨóČËŋÚĪŽķāĪąĪėĪÐ―ŧÁũĪŽŧî°k
- 42. Conclusion ? ĪģĪÎģĖķČ(ĨíĨ°1ĨöÔÂ*6ĖĻ·Ö)ĪĘĪé ? ÔOÓ: 5·Ö ? ĨģĐ`ĨĮĨĢĨóĨ°: 5·Ö ? gÐÐ: 10·Ö(EC2 small instance 10ĖĻ) ? ß^ČĨĪËĪĩĪŦĪÎĪÜĪÃĪÆÐÂĪ·ĪĪ―âÎöĪŽĪ·Īŋ ĪĪrĪĮĪâš gĪËĨÆĨđĨČĪŽŋÉÄÜ
- 43. Future work ? MapReduceĪÏÐĄĪĩĪĘIĀíĪËĪÏÏōĪŦĪĘĪĪ ? ĨÐĨÃĨÁIĀíĪČÉÏĘÖĪŊ―MĪßšÏĪïĪŧ ? ŽFÔÚŨũģÉÖÐ ? ĨĪĨóĨŋĨéĨŊĨ·ĨįĨóÂĘĪÏĨĒĨŊĨ·ĨįĨóĪō ÐÐĪÃĪŋČËĪĀĪąĪĮĪÏĪĘĪŊ, ÐÐĪïĪėĪŋČË(ĨģĨá ĨóĨČĪ·ĪÆĪâĪéĪÃĪŋČË)ĪâČĄĩà ? æ`đČĪĩĪóĪŽŨũģÉgĪßĢĄĢĄ
- 44. Thank you for your attention!
- 45. Thank you for your attention!
Editor's Notes
- #14: make ĪĮĪÏĨÞĨđĨŋĐ`ĪÎĨÎĐ`ĨÉĪĮĪâęĪ·ĪŋĨŨĨíĨŧĨđĪŽŨßĪëĪÎĪĮĄĒÍŽrĪËīóÁŋĪÎĨŨĨíĨŧĨđĪōÆðÓĪđĪëĪČËĀĪĖ ( KÁÐĘýĪËÏÞ―į )
- #17: ·ÖÉĒÅäÖÃĪËĪčĪëؚɷÖÉĒĪČĨĮĐ`ĨŋĨíĨđĨČĪËĪđĪëēß ·ÖÉĒĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāÉÏĪĮĪÏĨÖĨíĨÃĨŊĨĩĨĪĨšĪÏ 64MB ĪĀĪŽĄĒĨÕĨĄĨĪĨëĪÎgĖåĪÏÍĻģĢĪÎĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāÉÏĪËąĢīæĪĩĪėĪëĪÎĪĮĄĒgëHĪÎĘđÓÃČÝÁŋĪÏÍĻģĢĪÎĨÕĨĄĨĪĨëĨ·ĨđĨÆĨāĪÎĨÖĨíĨÃĨŊĨĩĨĪĨšĪĮQĪÞĪë (HDFS ÉÏĪĮĪÏĪÉĪóĪĘÐĄĪĩĪĘĪĪĨÕĨĄĨĪĨëĪĮĪâ 64MB ĪČĪČĪ·ĪÆÕJŨRĪĩĪėĪë )
- #18: ĨÐĨĪĨČĨėĨŲĨëĪĮĪηÖļîĪĘĪÎĪĮĄĒÐÐĪÎÍūÖÐĪĮ·ÖĪŦĪėĪÆĪĪĪŋĪęĪđĪëĪŦĪâĪ·ĪėĪĘĪĪ Ī―ĪÎĪĒĪŋĪęĪÎIĀíĪŽĪÉĪĶĪĘĪÃĪÆĪĪĪëĪŦĪÏÔĪ·ĪŊĪÏÖŠĪéĪĘĪĪĄĢ
- #20: reduce Į°ĪË shuffle ĪŽČëĪëĪģĪČĪËĪčĪÃĪÆoņjĪĘĨÕĨĄĨĪĨëĨģĨÔĐ`ĪŽīæÔÚĪ·ĪĘĪŊĪĘĪë
- #27: ĪĘĪÎĪĮžÆËãĪÎūÖËųÐÔĪÏgĪÏĪĒĪóĪÞĪęąĢĪŋĪėĪÆĪĪĪĘĪĪĄĢĨÕĨĄĨĪĨëÜËÍĪÎÎÞņjĪŽīóĪĪĪ