ýĽîýĽäŰĹÉŰę┤ ýôŞŰŹ░ý׳ŰŐö ýőáŕŞ░ÝĽť ŕ░ĽÝÖöăŕÖýŐÁ NAVER 2017
484 likes198,016 views

Ű░ťÝĹť ýśüýâü: http://tv.naver.com/v/2051482 PDFŰą╝ Ű░ŤýĽäýäť Ű│┤ýůöýĽ╝ ŕ╣ĘŰüŚÝĽśŕ▓î Ű│┤ý×ůŰőłŰőĄ. ýÁťŕĚ╝ ŕ░ĽÝÖöăŕÖýŐÁ ÝŐŞŰáîŰôťŰą╝ ŰőĄýä» ŕ░ÇýžÇŰíť ŰéśŰłá ýäĄŰ¬ůÝĽśŕ│á, ŰŹ░ŰŞîýőťýŐĄÝä░ýŽłýŚÉýäť ÝĺÇŕ│á ý׳ŰŐö ýäŞ ŕ░ÇýžÇ ŕ░ĽÝÖöăŕÖýŐÁ ŰČŞýáťŰôĄýŁä ŕ│ÁýťáÝĽęŰőłŰőĄ.































































































































































































More Related Content
What's hot (20)
Viewers also liked (20)
![[NDC2017 : Ű░ĽýĄÇý▓á] Python ßäÇßůŽßäőßůÁßćĚ ßäëßůąßäçßůą ßäőßůíßćźßäéßůžßć╝ßäĺßůíßäëßůÁßćŞßäéßůÁßäüßůí - ßäćßůęßćźßäëßů│ßäÉßůą ßäëßů▓ßäĹßůąßäůßůÁßäÇßů│ ßäÇßůŽßäőßůÁßćĚ ßäëßůąßäçßůą](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=560&fit=bounds)
![[IGC 2016] ŰäĚŕ▓îý×äýŽł ŕ╣ÇŰ│ÁýőŁ - ýĄĹŕÁş ۬ĘŰ░öýŁ╝ ŕ▓îý×äŕ│╝ ý║Éýú╝ýľ╝ ŕ▓îý×ä Űööý×ÉýŁŞ](https://cdn.slidesharecdn.com/ss_thumbnails/2-161009034159-thumbnail.jpg?width=560&fit=bounds)
![[ÝĽ┤ýÖŞýäŞŰ»ŞŰéś]ýäťýÜŞ-ÝéĄýŚÉÝöäýőť ŕÁÉÝćÁýáĽý▒ů Ű░Ć Ű╣ůŰŹ░ýŁ┤Ýä░ýćöŰúĘýůś ýžÇýőŁŕ│Áýťá ýŤîÝüČýâÁ ŕ░ĽýŚ░](https://cdn.slidesharecdn.com/ss_thumbnails/random-170809083329-thumbnail.jpg?width=560&fit=bounds)








![[ŰŹ░ýŁ┤Ýä░ýĽ╝ŰćÇý×É2107] ŕ░ĽŰéĘ ýÂťŕĚ╝પýŚÉ ÝîÉŕÁÉ/ýáĽý×ÉýŚşýŚÉ Űé┤ŰŽ┤ ýéČŰ×î ýśłýŞíÝĽśŕŞ░](https://cdn.slidesharecdn.com/ss_thumbnails/predict-get-off-station-171012210042-thumbnail.jpg?width=560&fit=bounds)






More from Taehoon Kim (7)

![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=560&fit=bounds)





ýĽîýĽäŰĹÉŰę┤ ýôŞŰŹ░ý׳ŰŐö ýőáŕŞ░ÝĽť ŕ░ĽÝÖöăŕÖýŐÁ NAVER 2017
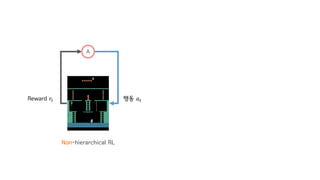
- 7. Environment Agent State ŁĹá" Action ŁĹÄ" = 2
- 8. Environment Agent Action ŁĹÄ" = 2State ŁĹá" Reward ŁĹč" = 1
- 9. Environment Agent Action ŁĹÄ" = 2State ŁĹá" Reward ŁĹč" = 1
- 10. Environment Agent Action ŁĹÄ" = 0State ŁĹá" Reward ŁĹč" = Ôłĺ1
- 11. Environment Agent Action ŁĹÄ" = 0State ŁĹá" Reward ŁĹč" = Ôłĺ1
- 12. ÝľëŰĆÖýŁä ÝĽśŕ│á ýőťÝľëý░ęýśĄŰą╝ ŕ▓¬ýť╝Űę░ ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ
- 13. ýÁťŕĚ╝ ŕ░ĽÝÖö ăŕÖýŐÁ ýŚ░ŕÁČŰôĄ
- 15. 2017.08.09
- 17. 2017.08.11
- 20. 2014 Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533. Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489. Vinyals, Oriol, et al. "StarCraft II: A New Challenge for Reinforcement Learning." 2016 2017
- 21. 2014 2016 ýŁ┤ýáäýŁś ŕ░ĽÝÖöăŕÖýŐÁýŁÇ ýל ýĽîŰáĄýžä Ű░śŰę┤..
- 23. ŕĚŞŰלýäť
- 26. 1.Multi Agent 2.Planning 3.Meta Learning 4.Guided RL 5.ETC Exploration, Continuous action, Imitation learning ÔÇŽ
- 27. 1.ýŚČŰčČ ŰíťŰ┤ç ăŕÖýŐÁÝĽśŕŞ░ 2.ýáäŰ×Á ýäŞýÜ░ŕŞ░ 3.Ű░░ŕ▓Ż ýžÇýőŁ ÝÖťýÜęÝĽśŕŞ░ 4.۬ůŰá╣ýŚÉ Űö░ŰŁ╝ ŰőĄŰą┤ŕ▓î ÝľëŰĆÖÝĽśŕŞ░ 5.ŕĚŞ ýÖŞ ŰőĄýľĹÝĽť ýőťŰĆä, ýŚ░ýćŹýáüýŁŞ ÝľëŰĆÖ, Űö░ŰŁ╝ÝĽśŕŞ░, ÔÇŽ
- 28. WARNING ŕ░ĽÝÖö ăŕÖýŐÁýŁ┤ ý▓śýŁîýŁ┤ýőá ŰÂäŕ╗ś ŰőĄýćî ýľ┤ŰáĄýÜŞ ýłś ý׳ŕŞ░ ŰĽîŰČŞýŚÉ ýáäý▓┤ýáüýŁŞ ÝŁÉŰŽä ÝîîýĽůýŚÉŰžî ýžĹýĄĹÝĽ┤ ýú╝ýäŞýÜö
- 30. 1. ýŚČŰčČ ŰíťŰ┤ç ăŕÖýŐÁÝĽśŕŞ░ Multi Agent RL
- 32. ÝśĹýŚů or ŕ▓ŻýčüýŁ┤ ÝĽäýÜöÝĽť Multi Agent ý×ÉýťĘ ýú╝Ýľë ý×ÉŰĆÖý░Ę, ŰîÇÝÖö AI, ŰîÇŕĚťŰ¬Ę ŕ│Áý׹ ŰíťŰ┤ç ÔÇŽ
- 33. Starcraft Peng, Peng, et al. "Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games." arXiv preprint arXiv:1703.10069 (2017).
- 34. Multi-Agent RL ŰőĄýĄĹ ýŚÉýŁ┤ýáäÝŐŞ ŕ░ĽÝÖö ăŕÖýŐÁ
- 35. Single Agent ăŕÖýŐÁ Ű░ęýőŁýŁä ŕĚŞŰîÇŰíť ýô░ŕŞ░ ýľ┤ŰáÁŰőĄ Deep Q┬şlearning, Policy Gradient ÔÇŽ
- 37. Non stationary environment ŰőĄŰąŞ Agent ŰĽîŰČŞýŚÉ ýâŁŕŞ░ŰŐö ŰÂłÝÖĽýőĄýä▒ ŰĽîŰČŞýŚÉ ăŕÖýŐÁýŁ┤ ýľ┤ŰáÁŕ│á ŕŞ░ýí┤ýŁś ŕ▓ŻÝŚśýŁä Ű░öŰíť ÝÖťýÜęÝĽśŕŞ░ ýľ┤ŰáÁŰőĄ
- 38. B A
- 39. BýŚÉ ŕ░Çŕ╣îýŁ┤ ŕ░ł ŰĽî +1 reward B A
- 40. +1 +1-1 -1 BýŚÉ ŕ░Çŕ╣îýŁ┤ ŕ░ł ŰĽî +1 reward B A
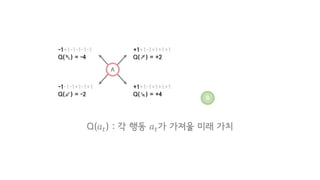
- 41. +1+1-1+1+1+1 Q( ) = +2 Q(ŁĹÄ") : ŕ░ü ÝľëŰĆÖ ŁĹÄ"ŕ░Ç ŕ░ÇýáŞýÜŞ Ű»ŞŰל ŕ░Çý╣ś B A
- 42. +1+1-1+1+1+1 Q( ) = +2 +1+1-1+1+1+1 Q( ) = +4 Q(ŁĹÄ") : ŕ░ü ÝľëŰĆÖ ŁĹÄ"ŕ░Ç ŕ░ÇýáŞýÜŞ Ű»ŞŰל ŕ░Çý╣ś B A
- 43. +1+1-1+1+1+1 Q( ) = +2 +1+1-1+1+1+1 Q( ) = +4 -1-1-1+1-1+1 Q( ) = -2 -1+1-1-1-1-1 Q( ) = -4 Q(ŁĹÄ") : ŕ░ü ÝľëŰĆÖ ŁĹÄ"ŕ░Ç ŕ░ÇýáŞýÜŞ Ű»ŞŰל ŕ░Çý╣ś B A
- 44. +1+1-1+1+1+1 Q( ) = +2 +1+1-1+1+1+1 Q( ) = +4 -1-1-1+1-1+1 Q( ) = -2 -1+1-1-1-1-1 Q( ) = -4 Q(ŁĹÄ") : ŕ░ü ÝľëŰĆÖ ŁĹÄ"ŕ░Ç ŕ░ÇýáŞýÜŞ Ű»ŞŰל ŕ░Çý╣ś B A
- 45. Bŕ░Ç ŕ░Ĺý×ÉŕŞ░ ýŤÇýžüýŁ┤ŕŞ░ ýőťý×ĹÝĽťŰőĄŰę┤? B B A
- 46. Q( ) = ? Q( ) = ?Q( ) = ? Q( ) = ? Aŕ░Ç ýŁ┤ýáäýŚÉ Ű░░ýŤáŰŹś Q(ŁĹÄ")ŰŐö ŰČ┤ýôŞŰ¬Ę B A B ýśłŰą╝ ŰôĄýľ┤ Bŕ░Ç ŕ░Ĺý×ÉŕŞ░ ýłťŕ░ä ýŁ┤ŰĆÖýŁä ÝĽťŰőĄŕ│á ÝľłýŁäŰĽî
- 47. Bŕ░Ç ŰőĄŰąŞ rewardŰą╝ Ű░ŤŰŐö AgentŰŁ╝Űę┤? ăŕÖýŐÁÝĽśŰę┤ýäť ÝľëŰĆÖýŁä Ű░öŕż╝ŰőĄŰę┤ B B Q( ) = ? Q( ) = ?Q( ) = ? Q( ) = ? A
- 48. Q-value ăŕÖýŐÁýŁ┤ ŕÁëý׹Ý׳ ŰÂłýĽłýáĽÝĽ┤ ýžł ŕ▓â B B Q( ) = ? Q( ) = ?Q( ) = ? Q( ) = ? A
- 50. Communication Mordatch, Igor, and Pieter Abbeel. "Emergence of Grounded Compositional Language in Multi-Agent Populations." arXiv preprint arXiv:1703.04908 (2017) https://blog.openai.com/learning-to-communicate/ ŰőĄŰąŞ ۬ĘŰôá AgentýŚÉŕ▓î ŰęöýäŞýžÇ ýáäŰőČ
- 51. Actor-Critic + Centralized Q-value ŰőĄŰąŞ AgentýŁś Űé┤ŰÂÇ ýáĽŰ│┤Űą╝ ŕ│Áýťá Lowe, Ryan, et al. "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments." arXiv preprint arXiv:1706.02275 (2017) https://blog.openai.com/learning-to-cooperate-compete-and-communicate/ Centralized Q-value
- 52. 2. ýáäŰ×Á ýäŞýÜ░ŕŞ░ Hierarchical RL + Model-based RL
- 53. Rewardŕ░Ç ý×Éýú╝ ýâŁŕ▓Ęýäť ăŕÖýŐÁýŁ┤ ýëČýŤÇ
- 54. Rewardŕ░Ç ŰäłŰČ┤ ŰôťŰČ╝ýľ┤ýäť ăŕÖýŐÁýŁ┤ ýľ┤ŰáĄýŤÇ
- 55. Sparse Reward Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016. Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017). 30Ű▓ł ýáĽŰĆäýŁś ýśČŰ░öŰąŞ ÝľëŰĆÖ ÝŤäýŚÉ 0ýŁ┤ ýĽäŰőî RewardýŁä ýľ╗ýŁî Feedback Ű░žýĄäýŁä ÝâÇŕ│á Űé┤ŰáĄŕ░Çýäť ÝĽ┤ŕ│ĘýŁä Ýö╝ÝĽśŕ│á ýéČŰőĄŰŽČŰą╝ ÝâÇýäť ýŚ┤ýçáŰą╝ ýľ╗ýľ┤ýĽ╝ 100ýáÉ ýľ╗ýŁî
- 56. Hierarchical RL ŕ│äýŞÁ ŕ░ĽÝÖö ăŕÖýŐÁ
- 60. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL
- 61. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3
- 62. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL Ű░žýĄä ý×íŕŞ░ ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3
- 63. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL Ű░žýĄä ý×íŕŞ░ ýéČŰőĄŰŽČ Űé┤ŰáĄŕ░ÇŕŞ░ ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3
- 64. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL Ű░žýĄä ý×íŕŞ░ ýéČŰőĄŰŽČ Űé┤ŰáĄŕ░ÇŕŞ░ ýáÉÝöä ÝĽśŕŞ░ ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3
- 65. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3 A A ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" ŁĹÄ*,"ŁĹÄ,," Non-hierarchical RL Hierarchical RL ŁĹÄ-," Ű░žýĄä ý×íŕŞ░ ýéČŰőĄŰŽČ Űé┤ŰáĄŕ░ÇŕŞ░ ýáÉÝöä ÝĽśŕŞ░
- 66. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3 - - ON A A ۬ęÝĹť ╬ę ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Non-hierarchical RL Hierarchical RL ŁĹÄ*,"ŁĹÄ,," ŁĹÄ-,"
- 67. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3 - - ON A A ۬ęÝĹť ╬ę ÝľëŰĆÖ ŁĹÄ-,"ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" ŁĹÄ*,"ŁĹÄ,," Non-hierarchical RL Hierarchical RL
- 68. Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017 ۬ęÝĹť1 ۬ęÝĹť2 ۬ęÝĹť3 - - ON A A ۬ęÝĹť ╬ę ÝľëŰĆÖ ŁĹÄ-,"ÝľëŰĆÖ ŁĹÄ"Reward ŁĹč" Reward ŁĹč" ŁĹÄ*,"ŁĹÄ,," Non-hierarchical RL Hierarchical RL
- 69. Montezuma ýל ÝĺÇýŚłŰőĄ Kulkarni, Tejas D., et al. "Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation." Advances in Neural Information Processing Systems. 2016 Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017) Bacon, Pierre-Luc, Jean Harb, and Doina Precup. "The Option-Critic Architecture." AAAI. 2017
- 70. ăŕś.ýžÂ─.Űžî.
- 71. ÝĽśýžÇŰžî, ýĽöŕŞ░Űíť ÝĺÇ ýłś ý׳ýŁî
- 72. ýĽöŕŞ░Űíť ÝĺÇ ýłś ýŚćŰŐö ŰČŞýáť Weber, Th├ęophane, et al. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017). https://deepmind.com/blog/agents-imagine-and-plan/
- 73. Weber, Th├ęophane, et al. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017). https://deepmind.com/blog/agents-imagine-and-plan/ ýőĄýáťŰíť ýŁ╝ýľ┤Űéá ýŁ╝ýŁä ýőťŰ«ČŰáłýŁ┤ýůśýť╝Űíť (internal simulation) ýâüýâüÝĽ┤ Ű│┤ŕ│á ÝľëŰĆÖ
- 74. Model-free RL + Model-based RL Deep Q-learning Policy Gradient ÔÇŽ
- 75. Model-free RL + Model-based RL Imagination Weber, Th├ęophane, et al. "Imagination-Augmented Agents for Deep Reinforcement Learning." arXiv preprint arXiv:1707.06203 (2017). https://deepmind.com/blog/agents-imagine-and-plan/
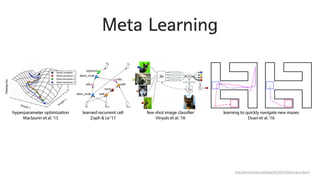
- 76. 3. Ű░░ŕ▓Ż ýžÇýőŁ ÝÖťýÜęÝĽśŕŞ░ Meta Learning
- 77. ýéČŰ×îý▓śŰč╝ ŕŞ░ýí┤ýŁś ŕ▓ŻÝŚśýŁä ÝÖťýÜęÝĽ┤ ýâłŰíťýÜ┤ ÝÖśŕ▓ŻýŚÉýäť ýľ┤Űľ╗ŕ▓î ýל ýáüýŁĹýŁä ÝĽá ýłś ý׳ýŁäŕ╣î? Meta Learning
- 79. Weight UpdateŰą╝ Ű╣áŰą┤ŕ▓î ÝĽśŰáĄŰę┤? http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
- 80. ýÁťýáüýŁś ŰäĄÝŐŞýŤîÝüČŰą╝ ý░żýť╝ŰáĄŰę┤? http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
- 81. ý×ĹýŁÇ ŰŹ░ýŁ┤Ýä░Űžî Ű│┤ŕ│áŰĆä ýל ŰÂäŰąśÝĽśŰáĄŰę┤? http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
- 82. ÝĽťŰ▓łŰĆä ýĽł Ű│Ş ŕ▓îý×äŰĆä ýל Ýü┤ŰŽČýľ┤ ÝĽśŰáĄŰę┤? http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/ Meta Learning + RL
- 84. Meta Learning + RL
- 85. Meta Reinforcement Learning ÝĽťŰ▓łŰĆä ýĽł Ű│Ş ŕ▓îý×äŰĆä ýל Ýü┤ŰŽČýľ┤ ÝĽśŰáĄŰę┤?
- 86. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). https://www.youtube.com/playlist?list=PLp24ODExrsVeA-ZnOQhdhX6X7ed5H_W4q
- 87. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). ÝĽťÝîÉ = ÝĽť Episode
- 88. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). Episodeŕ░Ç ŰüŁŰéśŰĆä ýáĽŰ│┤Űą╝ ŰŽČýůőÝĽśýžÇ ýĽŐŕ│á ŕ│äýćŹ ýéČýÜę
- 89. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). NŰ▓łýŁś EpisodeŰą╝ ÝĽśŰéśýŁś TrialŰíť ýáĽýŁś NŰ▓łýŁś EpisodeŰą╝ ÝćÁÝĽ┤ýäť ýÁťýáüýŁś ÝöîŰáłýŁ┤Űą╝ ý░żŰŐö Ű░ęŰ▓ĽýŁä ăŕÖýŐÁ
- 90. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). ýâłŰíťýÜ┤ ýőťŰĆäýŚÉŰŐö ýâłŰíťýÜ┤ ŕ▓îý×ä(ýŚČŕŞ░ýäťŰŐö ýâłŰíťýÜ┤ ŰžÁ)ýŁä ÝöîŰáłýŁ┤
- 91. Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). ýâłŰíťýÜ┤ ýőťŰĆäýŚÉŰŐö ýâłŰíťýÜ┤ ŕ▓îý×ä(ýŚČŕŞ░ýäťŰŐö ýâłŰíťýÜ┤ ŰžÁ)ýŁä ÝöîŰáłýŁ┤
- 92. ýóÇ ŰŹö ÝśäýőĄýáüýŁŞ ýśłýőť: ŰžłŰŽČýśĄŰą╝ NŰ▓ł ÝöîŰáłýŁ┤ Űé┤ýŚÉ ŰüŁŕ╣îýžÇ Ýü┤ŰŽČýľ┤
- 96. ŰőĄýľĹÝĽť ŰžłŰŽČýśĄ ŕ▓îý×äýŁä ăŕÖýŐÁÝĽśŕ│á ăŕÖýŐÁÝĽśýžÇ ýĽŐýĽśŰŹś ŰžłŰŽČýśĄ ŕ▓îý×äýŁä ÝöîŰáłýŁ┤
- 97. ŰőĄýľĹÝĽť ŰáłýŁ┤ýő▒ ŕ▓îý×äýŁä ăŕÖýŐÁÝĽśŕ│á ăŕÖýŐÁÝĽśýžÇ ýĽŐýĽśŰŹś ŰáłýŁ┤ýő▒ ŕ▓îý×äýŁä ÝöîŰáłýŁ┤ ex. GTA, ýőĄýáť ý×ÉýťĘ ýú╝Ýľë ý×ÉŰĆÖý░Ę
- 99. RL2: Recurrent Network Duan, Yan, et al. "RL $^ 2$: Fast Reinforcement Learning via Slow Reinforcement Learning." arXiv preprint arXiv:1611.02779 (2016). https://www.youtube.com/playlist?list=PLp24ODExrsVeA-ZnOQhdhX6X7ed5H_W4q EpisodeýŁś ReturnýŁ┤ ýĽäŰőî TrialýŁś ReturnýŁä optimize
- 100. Model-Agnostic Meta-Learning Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks." arXiv preprint arXiv:1703.03400 (2017). ýŚČŰčČ TaskŰą╝ ŰĆÖýőťýŚÉ ăŕÖýŐÁÝĽ┤ weightýŁś central pointŰą╝ ý░żýŁî ŕĚŞŰŽČŕ│á 1Ű▓łýŁś gradient updateŰíť ýâł TaskýŚÉ ýáüýŁĹ
- 101. 4. ۬ůŰá╣ýŚÉ Űö░ŰŁ╝ ŰőĄŰą┤ŕ▓î ÝľëŰĆÖÝĽśŕŞ░
- 102. ŰőĘ ÝĽťŕ░ÇýžÇ ۬ęÝĹť
- 103. ŰőĘ ÝĽťŕ░ÇýžÇ ۬ęÝĹť ý×ÉýťĘ ýú╝Ýľë = ŰČ┤ÝĽťŕ░ÇýžÇ ۬ęÝĹť ÝĽÖŕÁÉŕ╣îýžÇ ýú╝Ýľë ýĽ× ý░ĘŰą╝ Űö░ŰŁ╝ýäť ýú╝Ýľë ýú╝ý░Ęý׹ýŚÉ ýú╝ý░Ę ...
- 104. Guided RL ۬ůŰá╣ýŚÉ Űö░ŰŁ╝ ŰőĄŰą┤ŕ▓î ÝľëŰĆÖÝĽśŰĆäŰíŁ AgentŰą╝ ăŕÖýŐÁ
- 105. + Guided RL
- 106. Teaching Machines to Understand Visual Manuals via Attention Supervision for Object Assembly Taehoon Kim1, Youngwoon Lee2, Joseph Lim2 1 2
- 107. ýÖť?
- 108. ýéČŰ×îý▓śŰč╝ ýâłŰíťýÜ┤ ÝÖśŕ▓ŻýŚÉýäť ýל ýáüýŁĹÝĽśŰáĄŰę┤? Generalization in Reinforcement Learning
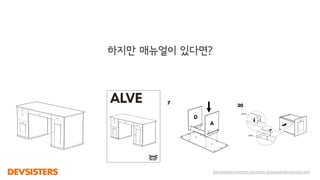
- 109. http://www.ikea.com/ms/en_US/customer_service/assembly_instructions.html ýŁśý×É ýí░ŰŽŻýŁä Ű░░ýÜ┤ ýéČŰ×î
- 110. http://www.ikea.com/ms/en_US/customer_service/assembly_instructions.html ý▒ůýâüýŁä ŰžĄŰë┤ýľ╝ ýŚćýŁ┤ ýí░ŰŽŻÝĽá ýłś ý׳ýŁäŕ╣î?
- 112. ýéČŰ×îŰĆä ýâłŰíťýÜ┤ ŰČŞýáťŰą╝ ÝĺÇŕŞ░ ýťäÝĽ┤ýäťŰŐö ŰžĄŰë┤ýľ╝ýŁä Ű┤ÉýĽ╝ÝĽťŰőĄ
- 113. ŰČ┤ýŚçýŁä?
- 114. ý╣áŕÁÉ ÝŹ╝ýŽÉ ŕ░ÇŕÁČ ýí░ŰŽŻ Hierarchical PlanningýŁ┤ ÝĽäýÜöÝĽť ŰČŞýáť
- 115. State ŁĹá"
- 116. State ŁĹá" Manual ŁĹÜ&▒š│▄┤ă│┘;
- 119. ÔÇŽ
- 120. ÔÇŽ ÔÇŽ
- 121. Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. "Pointer networks." Advances in Neural Information Processing Systems. 2015. ÔÇŽ ÔÇŽ Pointer Network
- 122. Łĺö Łĺę," ŁŁů ŁĹŻ ŁĹÄ"5, ŁĹĺŁĹŤŁĹÉ ÔÇŽ Łĺö*," Łĺö,," ÔÇŽ ÔčĘŁĹöÔčę ÔÇŽ ÔÇŽ ŁĹá<," , ŁĹá<," * ŁĹá<," Łĺ« ŁĹŁ<," , ŁĹŁ<," Łĺź5, ŁĹ┤" Image segmentation + Pointer Network
- 123. ÝĽśýžÇŰžî Pointer Network ăŕÖýŐÁýŁä ýťäÝĽ┤ ýÂöŕ░ÇýáüýŁŞ Supervision ÝĽäýÜö ŰőĘýáÉ Ű¬ç Ű▓łýžŞ segmentŕ░Ç ŰžĄŰë┤ýľ╝ ýí░ŕ░üýŁä ÝĆČÝĽĘÝĽśŰŐöýžÇ ÔÇŽ ÔÇŽ
- 124. Attention Xu, Kelvin, et al. "Show, attend and tell: Neural image caption generation with visual attention." International Conference on Machine Learning. 2015.
- 125. ŰęöŰë┤ýľ╝ýŚÉ ÝĽ┤Űő╣ÝĽśŰŐö ŰÂÇŰÂäýŚÉ ýžĹýĄĹ(┤í│┘│┘▒▓ď│┘ż▒┤ă▓ď)
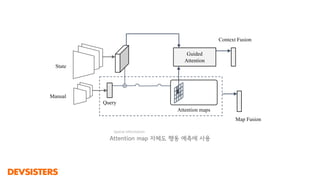
- 126. Query Attention maps Guided Attention ¤Ç V Manual State Context Fusion Map Fusion ÔÇŽ ÔÇŽ ÔÇŽ ÔÇŽ ÔÇŽ Guided Attention + A3C
- 127. ŕĚŞŰŽČŕ│á Ű│Áý×íÝĽť ăŕÖýŐÁ ŕ│╝ýáĽýŁä ŕ▒░ý│Éýäť.. Curriculum Learning Semi-supervised Learning Self-supervision ÔÇŽ
- 128. ŕ▓░ŕ│╝
- 132. ŰőĄŰąŞ Guided RL ýŚ░ŕÁČŰôĄ Text as Manual
- 133. Gated-Attention + A3C Hermann, Karl Moritz, et al. "Grounded language learning in a simulated 3D world." arXiv preprint arXiv:1706.06551 (2017) https://sites.google.com/view/gated-attention/home
- 134. Self-Supervision + A3C Chaplot, Devendra Singh, et al. "Gated-Attention Architectures for Task-Oriented Language Grounding." arXiv preprint arXiv:1706.07230 (2017) https://www.youtube.com/watch?v=wJjdu1bPJ04 ŰČ╝ý▓┤ŰôĄýŁś ŕ┤Çŕ│äŕ╣îýžÇ ýŁ┤ÝĽ┤ÝĽ┤ýĽ╝ ÝĽśŰŐö Agent
- 135. 5. ETC Exploration, Continuous action, Imitation learning
- 136. Exploration ýžÇળŕ╣îýžÇ ýóőŰőĄŕ│á ýâŁŕ░üÝľłŰŹś ÝľëŰĆÖýŁ┤ ýĽäŰőî ۬ĘÝŚś(ŰםۏĄ ÝľëŰĆÖ)ýŁä ÝĽśŰŐö ŕ▓â
- 138. Exploration ŰםۏĄýť╝Űíť Ű¬ĘÝŚś(ÝľëŰĆÖ)ýŁä ÝĽśŰŐö ŕ▓â Exploitation ýžÇળŕ╣îýžÇ Ű░░ýÜ┤ ýÁťýäáýŁś ÝľëŰĆÖýŁä ÝĽśŰŐö ŕ▓â
- 139. Exploration Pathak, Deepak, et al. "Curiosity-driven exploration by self-supervised prediction." arXiv preprint arXiv:1705.05363 (2017) https://pathak22.github.io/noreward-rl/ Curiosity reward + Inverse Dynamics Model
- 140. Curriculum Learning ýëČýÜ┤ ŰČŞýáťŰÂÇÝä░ ýľ┤ŰáĄýÜ┤ ŰČŞýáťŕ╣îýžÇ ý░ĘŕĚ╝ý░ĘŕĚ╝ ŰéťýŁ┤ŰĆäŰą╝ ýśČŰáĄŕ░ÇŰę░ ăŕÖýŐÁ
- 141. ăŕÖýŐÁ ýőťŕ░ä ŰéťýŁ┤ŰĆä ÝĽś ýĄĹ ýâü Non-curriculum learning ÝŐ╣ýἠŰéťýŁ┤ŰĆäýŁś ŰČŞýáť ŰŻĹýŁä ÝÖĽŰąá
- 142. ăŕÖýŐÁ ýőťŕ░ä ŰéťýŁ┤ŰĆä ÝĽś ýĄĹ ýâü ăŕÖýŐÁ ý▓śýŁîŰÂÇÝä░ ŰüŁŕ╣îýžÇ ۬ĘŰôá ŰéťýŁ┤ŰĆäŰą╝ ŰĆÖýŁ╝ÝĽť ÝÖĽŰąáŰíť ŰŻĹŕŞ░ Non-curriculum learning
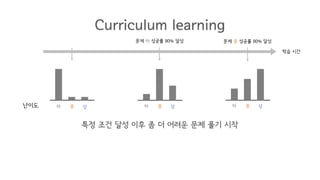
- 143. ăŕÖýŐÁ ýőťŕ░ä ŰéťýŁ┤ŰĆä ÝĽś ýĄĹ ýâü Curriculum learning ý▓śýŁîýŚÉŰŐö ŕ░Çý׹ ýëČýÜ┤ ŰČŞýáťŰą╝ ŰžÄýŁ┤ ăŕÖýŐÁ
- 144. ăŕÖýŐÁ ýőťŕ░ä ŰéťýŁ┤ŰĆä ÝĽś ýĄĹ ýâü ÝĽś ýĄĹ ýâü Curriculum learning ÝŐ╣ýἠýí░ŕ▒┤ ŰőČýä▒ ýŁ┤ÝŤä ýóÇ ŰŹö ýľ┤ŰáĄýÜ┤ ŰČŞýáť ÝĺÇŕŞ░ ýőťý×Ĺ ŰČŞýáť ÝĽś ýä▒ŕ│ÁŰąá 80% ŰőČýä▒
- 145. ăŕÖýŐÁ ýőťŕ░ä ŰéťýŁ┤ŰĆä ÝĽś ýĄĹ ýâü ÝĽś ýĄĹ ýâü ÝĽś ýĄĹ ýâü ŰČŞýáť ÝĽś ýä▒ŕ│ÁŰąá 80% ŰőČýä▒ ŰČŞýáť ýĄĹ ýä▒ŕ│ÁŰąá 80% ŰőČýä▒ Curriculum learning ÝŐ╣ýἠýí░ŕ▒┤ ŰőČýä▒ ýŁ┤ÝŤä ýóÇ ŰŹö ýľ┤ŰáĄýÜ┤ ŰČŞýáť ÝĺÇŕŞ░ ýőťý×Ĺ
- 146. Curriculum Learning + GAN Held, David, et al. "Automatic Goal Generation for Reinforcement Learning Agents." arXiv preprint arXiv:1705.06366 (2017) https://sites.google.com/view/goalgeneration4rl
- 147. Continuous Action ýŚ░ýćŹýáüýŁŞ ÝľëŰĆÖýŁä ŕ░Çýžä AgentýŁś ăŕÖýŐÁ (ex. ŰíťŰ┤ç)
- 148. Discrete Action ŁĹÄ" < Ôłł {0,1} ýťä ýĽäŰל ON -
- 149. Continuous Action Ôłĺ1 ÔëĄ ŁĹÄ" < ÔëĄ 1Discrete Action ŁĹÄ" < Ôłł {0,1} ýľ┤ŕ╣Ę ŰČ┤ŰŽÄ ÝŚłŰŽČ 0.1 -0.2 0.5 ýťä ýĽäŰל ON -
- 150. Continuous Action Schulman, John, et al. "Proximal Policy Optimization Algorithms." arXiv preprint arXiv:1707.06347 (2017) https://blog.openai.com/openai-baselines-ppo/ PPO
- 151. Continuous Action Heess, Nicolas, et al. "Emergence of Locomotion Behaviours in Rich Environments." arXiv preprint arXiv:1707.02286 (2017) https://www.youtube.com/watch?v=hx_bgoTF7bs Distributed PPO
- 152. ýŁ┤ ýÖŞýŚÉŰĆä..
- 154. ŰäĄ.
- 155. ŕ░ĽÝÖö ăŕÖýŐÁ ý║ëÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ÉÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÜî ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ ŕ░ĽÝÖö ăŕÖýŐÁ
- 156. Neural Turing Machine Differentiable Neural Computer Neural Module Network Neural Programmer-Interpreter Programmable Agent ÔÇŽ ŕ░ĽÝÖö ăŕÖýŐÁ ýÖŞýŚÉŰĆä ŕ┤ÇýőČý׳ŰŐö ŰÂäýĽ╝ Graves, Alex, Greg Wayne, and Ivo Danihelka. "Neural turing machines." arXiv preprint arXiv:1410.5401 (2014). Graves, Alex, et al. "Hybrid computing using a neural network with dynamic external memory." Nature 538.7626 (2016): 471-476. Andreas, Jacob, et al. "Neural module networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. Reed, Scott, and Nando De Freitas. "Neural programmer-interpreters." arXiv preprint arXiv:1511.06279 (2015). Denil, Misha, et al. "Programmable agents." arXiv preprint arXiv:1706.06383(2017).
- 157. ŰőĄ ýŁ┤ýĽ╝ŕŞ░ÝĽśŕ│á ýőÂýžÇŰžî ýśĄŰŐśýŁÂ─..
- 159. Berthelot, David, Tom Schumm, and Luke Metz. "Began: Boundary equilibrium generative adversarial networks." arXiv preprint arXiv:1703.10717 (2017). https://github.com/carpedm20/BEGAN-tensorflow
- 160. Kim, Taeksoo, et al. "Learning to discover cross-domain relations with generative adversarial networks." arXiv preprint arXiv:1703.05192 (2017). https://github.com/carpedm20/DiscoGAN-pytorch
- 161. Shrivastava, Ashish, et al. "Learning from simulated and unsupervised images through adversarial training." arXiv preprint arXiv:1612.07828 (2016). https://github.com/carpedm20/simulated-unsupervised-tensorflow
- 162. Generative Model + Audio
- 163. Generative Model + Audio
- 164. ý╣┤ý╣┤ýśĄŰ▒ůÝüČŕ░Ç ŕ░ťýőť 5ýŁ╝ŰžîýŚÉ 100Űžî ŕ│äýóîŰą╝ ŰĆîÝîîÝĽśŰę┤ýäť ŰĆîÝĺŹýŁä ýŁ╝ýť╝ÝéĄŕ│á ý׳ŰőĄ. CVPR2017 Ýśäý׹ ÝĺŹŕ▓Żý×ůŰőłŰőĄ. ŰžÄýŁÇ ý╗┤ÝôĘÝä░Ű╣äýáä ýŚ░ŕÁČý×ÉŰôĄýŁ┤ ŰäĄýŁ┤Ű▓äŰ×ęýŐĄ ŰÂÇýŐĄŰą╝ ý░żýĽśýŐÁŰőłŰőĄ. ýśĄŰŐśýŁś ŰéáýöĘŰŐö ýľ┤ýáťŰ│┤ŰőĄ 3ŰĆä ŰćĺýŐÁŰőłŰőĄ. ý┤Ł 3ŕ░ťýŁś ýŁ╝ýáĽýŁ┤ Űô▒ŰíŁŰÉśýľ┤ ý׳ýŐÁŰőłŰőĄ.
- 165. .voice Voice Synthesis Technologies for Developers
- 166. ŰŹö ý×ÉýäŞÝĽťŕ▒┤...