


![5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō
? ź┴źŃź¾źŁź¾ź░(chunking) [5.5š┬]
? čįšZ▒Ē¼Fż╬ęŌ╬ČĄ─żóżļżżżŽ╬─Ę©Ą─ż╦ż▐ż╚ż▐ż├ż┐▓┐Ęųż“░kęŖż╣żļ蹊┐
? ├¹į~Šõż╬│ķ│÷żõ╚╦├¹│ķ│÷ż╩ż╔ż¼Æżż▓żķżņżļ
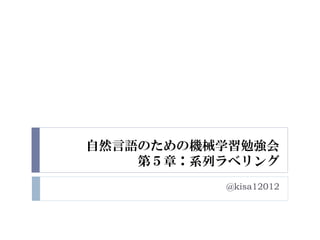
Ī░After stubbing out the cigarette, Lunvalet talked to me.Ī▒
╚╦├¹
Ī░LunvaletĪ▒ż╚żżż”╚╦├¹ż¼┤µį┌ż╣żļż│ż╚ż“ų¬żķż╩ż»żŲżŌĪó╬─├}ż½żķ═Ų£yż╣żļ
ż│ż╚ż¼│÷└┤żļ
? č}╩²šZż½żķż╩żļ▒Ē¼Fż¼╚╦ż“ųĖżĘżŲżżżļż│ż╚żŌżóżļ
Ī░Suddenly, the tall German guy talked to me.Ī▒
O B I I I O O O
╚╦
B(╚╦├¹ķ_╩╝ģgšZ),I(╚╦├¹▓┐),O(żĮż╬╦¹)ż╬żĶż”ż╦ź┐ź░ĖČż▒ż¼żĘż┐żż](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-6-320.jpg)
![5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō
B,I,Oż╬żĶż”ż╦│ķ│÷ż╬ż┐żßż╬ė├żżżķżņżļźķź┘źļż“IOB2ź┐ź░ż╚żżż”
IOB2ź┐ź░ĖČż▒żŌŽĄ┴ąźķź┘źĻź¾ź░ż╬ę╗ĘN
? ŽĄ┴ąźķź┘źĻź¾ź░ż╬å¢Ņ}ĄŃ
? ┐╔─▄ż╩źķź┘źļ┴ąż╬ĮMż▀║Žż’ż╗╩²ż¼┼“┤¾
? [ĮMż▀║Žż’ż╗╩²] ŻĮ [ŲĘį~ĘNŅÉ╩²]ż╬[ę¬╦ž╩²]ü\
? ┐╔─▄ż╩ŲĘį~┴ąż“╚½żŲ┴ąÆżżĘżŲĘųŅÉŲ„ż“ū„│╔ż╣żļż│ż╚żŽ▓╗┐╔─▄
? ŽĄ┴ąźķź┘źĻź¾ź░ż╦żŽĪó╠žäeż╩╩ųĘ©ż¼▒žę¬ż╚ż╩żļ
? ╬─Ģ°żŽ╬─?ģgšZż╬ŽĄ┴ąż╚ęŖżļż│ż╚ż¼│÷└┤żļż┐żßĪóŽĄ┴ąźķź┘źĻź¾ź░żŽčįšZ
äI└Ēż╦ż¬żżżŲĘŪ│Żż╦ėąė├](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-7-320.jpg)
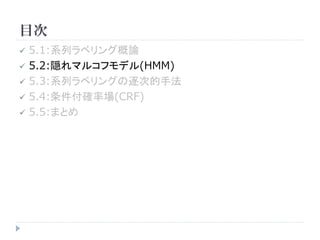

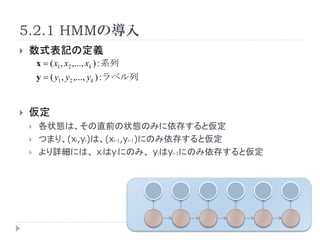

![5.2.2 źčźķźß®`ź┐═ŲČ©
ė¢ŠÜźŪ®`ź┐: D = {( x (1) , y (1) ),..., (x , y
(D) (D)
)} ż╬ūŅė╚═ŲČ©ĮŌż“Ū¾żßżļż│ż╚żŪĪóźčźķ
źß®`ź┐P( x | y ), P( y | y ' ) ż“═ŲČ©ż╣żļ
ż▐ż║ĪóīØ╩²ė╚Č╚ log P( D) ż“Ž┬╩Įż╬żĶż”ż╦▒Ēż╣
log P ( D ) = ĪŲ log P(x (i )
, y (i ) )
( x ( i ) , y ( i ) )Ī╩D
? ?
= ĪŲ ? ĪŲ log P ( x j | y j ) + ĪŲ log P ( y j | y j ?1 ) ?
?
(i ) (i ) (i ) (i )
?
( x ( i ) , y ( i ) )Ī╩D ? j j ?
= ĪŲ n(( x, y ), D) log P( x | y ) + ĪŲ n(( y ' , y ), D) log P( y | y ' )
x, y y, y'
= ĪŲ [źŪ®`ź┐DżŪĪóxż╦źķź┘źļyż¼ĖČėļżĄżņż┐╗ž╩²] log p x| y
x, y
+ ĪŲ [źŪ®`ź┐DżŪĪóźķź┘źļy'ż╬┤╬ż╦źķź┘źļyż¼│÷¼FżĘż┐╗ž╩²] log q y '| y
y ', y](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-12-320.jpg)
![5.2.2 źčźķźß®`ź┐═ŲČ©
ųŲ╝s╠§╝■ż“┐╝æ]ż╣żļż╚ĪóūŅė╚═ŲČ©ĮŌżŽęįŽ┬ż╬å¢Ņ}ż“ĮŌż»ż│ż╚żŪī¦│÷żŪżŁżļ
max ĪŲ n(( x, y ), D) log p x| y + ĪŲ n(( y ' , y ), D) log q y| y '
x, y y, y'
s.t. ĪŲp
x
x| y =1 ĪŲp
y
y| y ' =1
źķź░źķź¾źĖźÕĘ©ż“ė├żżżŲĪóūŅ┤¾╗»ż╣żļźčźķźß®`ź┐ż“Ū¾żßżļż╚ĪóęįŽ┬ż╬╩Įż╦ż╩żļ
(č▌┴Ģå¢Ņ}Ż▒)
n(( x, y ), D)
p x| y =
ĪŲ n(( x, y), D)
x
n(( y ' , y ), D)
q y| y ' =
ĪŲ n(( y' , y), D)
x
ę¬╦žż╚źķź┘źļĪóźķź┘źļż╚źķź┘źļż╬ĮMż▀║Žż’ż╗ż╬│÷¼FŅlČ╚ż“
źčźķźß®`ź┐ż╚żĘżŲżżżļż└ż▒ż╩ż╬żŪĪóĄ▒ż┐żĻŪ░ż╬ĮY╣¹](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-13-320.jpg)
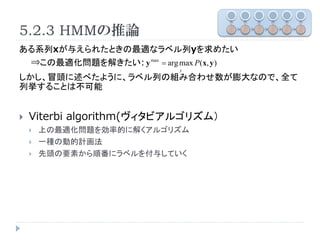
![Viterbi algorithm Pseudocode(Ū░░ļ)
╚ļ┴”:ŽĄ┴ąx
for j=2 to |x|
for all yj
t ( j , y j ) = max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
s ( j , y j ) = arg max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
end for
╚½żŲż╬ę¬╦žż╦īØÅĻż╣żļ╚½żŲż╬źķź┘źļż╦ż─żżżŲĪóż╔ż╬źķź┘źļ
end for ż½żķ▀węŲż╣żļ┤_┬╩ż¼Ė▀żżż½ż“▒╚▌^ż╣żļ
t(j,yj):ę¬╦žjż╦īØÅĻż╣żļźķź┘źļż¼yjż“ż╚żļ╠§╝■ż╬żŌż╚Īó┤_┬╩ż¼ūŅ┤¾ż╚ż╩żļźķ
ź┘źļ┴ąż“ż╚żļ┤_┬╩ĪŻ
s(j,yj):┤_┬╩ż¼ūŅ┤¾ż╚ż╩żļźķź┘źļż“ż╚ż├ż┐ł÷║Žż╬yj-1ż“▒Ż┤µĪŻźóźļź┤źĻź║źÓż╬
ßß░ļżŪ╩╣ė├ĪŻ](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-15-320.jpg)

![5.3 ═©│Żż╬ĘųŅÉŲ„ż╬ų┤╬▀mė├
? 4š┬ż╬ĘųŅÉŲ„ż“ų┤╬Ą─ż╦ė├żżżļż│ż╚żŪĪóŽĄ┴ąźķź┘źĻź¾ź░ż“ąąż”
ĘĮĘ©żŌżóżļ
? Ex. P ( y j | x j ?1 , x j , x j +1 y j ?1 )
ĘųŅÉŲ„żŽż╩ż¾żŪżŌżĶżż(Na?ve Bayes/SVMż╩ż╔Ż®
? ĘųŅÉŲ„ż╬ų┤╬▀mė├ż╬╠žÅš
? ų▒ßßż╬ę¬╦žż“ė├żżżļ╩┬żŌżŪżŁżļ
? Ė„ę¬╦žż╦ż─żżżŲĪóśöĪ®ż╩╦žąįż“ė├żżżļż│ż╚ż¼│÷└┤żļ
? ę╗░ŃĄ─ż╦Īóėŗ╦ŃĢrķgż¼ēł┤¾ż╣żļ
? źķź┘źļŽĄ┴ą╚½╠Õż╬┤_ż½żķżĘżĄżŽ┐╝æ]żĘżŲżżż╩żż](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-18-320.jpg)



![5.4.1 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬ī¦╚ļ
y ? = arg max ĪŲ w ? ”šk (x, yt , yt ?1 )
y t
╔Ž╩Įż╩żķżąĪówż¼Ęųż½ż├żŲżżżņżąViterbi AlgorithmżŪĖ▀╦┘ż╦ĮŌż»ż│ż╚ż¼żŪ
żŁżļ
t ( j , y j ) = max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
s ( j , y j ) = arg max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
t ( j , y j ) = max[w ? ”Ą(x, y j , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
s ( j , y j ) = arg max[w ? ”Ą(x, y j , y j ?1 ) + t ( j ? 1, y j ?1 )]
y j ?1
źŌźŪźļż╬ÆłÅłżŌ╚▌ęūż╦┐╔─▄
”šk (x, y ) = ĪŲ ”šk (x, yt , yt ?1 , yt ? 2 )
t](https://image.slidesharecdn.com/nlpforml5-100807023449-phpapp02/85/NLPforml5-22-320.jpg)





NLPforml5
- 1. ūį╚╗čįė’ż╬ż┐żßż╬╗·ąĄč¦Ž░├ŃŪ┐╗ß Ą┌ŻĄš┬Ż║ŽĄ┴ąźķź┘źĻź¾ź░ @kisa12012
- 2. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 3. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 4. 5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? ŽĄ┴ąźķź┘źĻź¾ź░ ? ŲĘį~ź┐ź░ĖČż▒ ? ź┴źŃź¾źŁź¾ź░Ż©╬─Ģ°─┌ż½żķ╚╦├¹?Ąž├¹ż╬│ķ│÷Ż® ? ŲĘį~ź┐ź░ĖČż▒ Ī░Nurture passes nature.Ī▒ ├¹į~ äėį~ ├¹į~ ? ŽĄ┴ą(sequence) Ī▒Nurture passes nature.Ī▒ żżż»ż─ż½ż╬ę¬╦žż¼▀Bż╩ż├ż┐żŌż╬ ? ŽĄ┴ąźķź┘źĻź¾ź░(sequential labeling) Ī║NurtureĪ¹├¹į~Ī╗ż“ĖČėļ ŽĄ┴ą─┌ż╬żĮżņżŠżņż╦źķź┘źļż“ĖČż▒żļż│ż╚
- 5. 5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō Ī░Nurture passes nature.Ī▒ ż╬Ī▒passĪ▒ż╦ū┼─┐ ├¹į~ äėį~ ├¹į~ ? Ī░passĪ▒żŽĪóĮ±╗žż╬└²żŪżŽäėį~ĪŻżĘż½żĘĪó Ī░nice pass.Ī▒ ż╬żĶż”ż╦Īóų▒Ū░ż╦ ą╬╚▌į~ż¼└┤żļł÷║Žż╦żŽ├¹į~ż╚ż╩żĻżõż╣żżĪŻ ? żóżļę¬╦žż╬źķź┘źļż¼ĪóżĮż╬ų▒Ū░ż╬źķź┘źļż╦ę└┤µż╣żļ Ī¹ę¬╦žż“ŽĄ┴ąż╚żĘżŲęŖżļ╩┬żŪĪóŠ½Č╚Ž“╔Žż“ćĒżļ ? ŽĄ┴ąźķź┘źĻź¾ź░żŪżŽĪóę¬╦žż╬źķź┘źļż¼ŽĄ┴ą─┌ż╬╦¹ż╬źķź┘źļż╦ę└┤µż╣żļ ł÷║Žż“ÆQż” ų▒Ū░ż╬źķź┘źļż¼ą╬╚▌į~żŪżóżņżąĪópassżŽ├¹į~ż╬┤_┬╩ż¼Ė▀żż ų▒Ū░ż╬źķź┘źļż¼├¹į~żŪżóżņżąĪópassżŽäėį~ż╬┤_┬╩ż¼Ė▀żż
- 6. 5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? ź┴źŃź¾źŁź¾ź░(chunking) [5.5š┬] ? čįšZ▒Ē¼Fż╬ęŌ╬ČĄ─żóżļżżżŽ╬─Ę©Ą─ż╦ż▐ż╚ż▐ż├ż┐▓┐Ęųż“░kęŖż╣żļ蹊┐ ? ├¹į~Šõż╬│ķ│÷żõ╚╦├¹│ķ│÷ż╩ż╔ż¼Æżż▓żķżņżļ Ī░After stubbing out the cigarette, Lunvalet talked to me.Ī▒ ╚╦├¹ Ī░LunvaletĪ▒ż╚żżż”╚╦├¹ż¼┤µį┌ż╣żļż│ż╚ż“ų¬żķż╩ż»żŲżŌĪó╬─├}ż½żķ═Ų£yż╣żļ ż│ż╚ż¼│÷└┤żļ ? č}╩²šZż½żķż╩żļ▒Ē¼Fż¼╚╦ż“ųĖżĘżŲżżżļż│ż╚żŌżóżļ Ī░Suddenly, the tall German guy talked to me.Ī▒ O B I I I O O O ╚╦ B(╚╦├¹ķ_╩╝ģgšZ),I(╚╦├¹▓┐),O(żĮż╬╦¹)ż╬żĶż”ż╦ź┐ź░ĖČż▒ż¼żĘż┐żż
- 7. 5.1 ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō B,I,Oż╬żĶż”ż╦│ķ│÷ż╬ż┐żßż╬ė├żżżķżņżļźķź┘źļż“IOB2ź┐ź░ż╚żżż” IOB2ź┐ź░ĖČż▒żŌŽĄ┴ąźķź┘źĻź¾ź░ż╬ę╗ĘN ? ŽĄ┴ąźķź┘źĻź¾ź░ż╬å¢Ņ}ĄŃ ? ┐╔─▄ż╩źķź┘źļ┴ąż╬ĮMż▀║Žż’ż╗╩²ż¼┼“┤¾ ? [ĮMż▀║Žż’ż╗╩²] ŻĮ [ŲĘį~ĘNŅÉ╩²]ż╬[ę¬╦ž╩²]ü\ ? ┐╔─▄ż╩ŲĘį~┴ąż“╚½żŲ┴ąÆżżĘżŲĘųŅÉŲ„ż“ū„│╔ż╣żļż│ż╚żŽ▓╗┐╔─▄ ? ŽĄ┴ąźķź┘źĻź¾ź░ż╦żŽĪó╠žäeż╩╩ųĘ©ż¼▒žę¬ż╚ż╩żļ ? ╬─Ģ°żŽ╬─?ģgšZż╬ŽĄ┴ąż╚ęŖżļż│ż╚ż¼│÷└┤żļż┐żßĪóŽĄ┴ąźķź┘źĻź¾ź░żŽčįšZ äI└Ēż╦ż¬żżżŲĘŪ│Żż╦ėąė├
- 8. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 9. 5.2 ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? ļLżņź▐źļź│źšźŌźŪźļ(Hidden Markov Model) ? ŽĄ┴ąźķź┘źĻź¾ź░ż╦ė├żżżļż│ż╚ż¼│÷└┤żļĘŪ│Żż╦źĘź¾źūźļż╩źŌźŪźļ ? ═©│ŻżŽĪóźķź┘źļż╬ĖČżżżŲżżż╩żżŽĄ┴ąźŪ®`ź┐ż╬ż▀ż¼ėļż©żķżņż┐ż╚żŁż╦źč źķźß®`ź┐ż“═ŲČ©ż╣żļ╩ųĘ©ż╬╩┬ż“ųĖż╣ĪŻżĘż½żĘĪóż│ż│żŪżŽŽĄ┴ąźķź┘źĻź¾ź░ż╬ ż┐żßż╬źķź┘źļĖČżŁė¢ŠÜźŪ®`ź┐ż¼ėļż©żķżņżŲżżżļū┤æBż“ŽļČ©żĘżŲżżżļ ę¬ ę¬ ę¬ ę¬ ę¬ ę¬ ╦ž ╦ž ╦ž ╦ž ╦ž ╦ž źķ źķ źķ źķ źķ źķ ź┘ ź┘ ź┘ ź┘ ź┘ ź┘ źļ źļ źļ źļ źļ źļ
- 10. 5.2.1 HMMż╬ī¦╚ļ ? ╩²╩Į▒Ēėøż╬Č©┴x x = ( x1 , x2 ,..., xk ) : ŽĄ┴ą y = ( y1 , y2 ,..., yk ) :źķź┘źļ┴ą ? üóČ© ? Ė„ū┤æBżŽĪóżĮż╬ų▒Ū░ż╬ū┤æBż╬ż▀ż╦ę└┤µż╣żļż╚üóČ© ? ż─ż▐żĻĪó(xi,yi)żŽĪó(xi-1,yi-1)ż╦ż╬ż▀ę└┤µż╣żļż╚üóČ© ? żĶżĻįö╝Üż╦żŽĪó xiżŽyiż╦ż╬ż▀Īó yiżŽyi-1ż╦ż╬ż▀ę└┤µż╣żļż╚üóČ©
- 11. 5.2.1 HMMż╬ī¦╚ļ xż╚yż╬═¼Ģr┤_┬╩żŽĪóęįŽ┬ż╬╩ĮżŪī¦│÷żŪżŁżļ P (x, y ) = P ( xk , yk | xk ?1 , yk ?1 ) P( xk ?1 , yk ?1 | xk ? 2 , yk ? 2 )...P ( x1 , y1 | x0 , y0 ) = ĪŪ P ( xi , yi | xi ?1 , yi ?1 ) i = ĪŪ P( xi | yi ) P( yi | yi ?1 ) i ║åģgż╬ż┐żßĪóź└ź▀®`ę¬╦ž(x0,y0)ż“ė├ęŌżĘĪóęįŽ┬ż╬╩Įż“ė├żżż┐ P( x1 , y1 ) = P( x1 , y1 | x0 , y0 ) P( y1 ) = P( y1 | y0 )
- 12. 5.2.2 źčźķźß®`ź┐═ŲČ© ė¢ŠÜźŪ®`ź┐: D = {( x (1) , y (1) ),..., (x , y (D) (D) )} ż╬ūŅė╚═ŲČ©ĮŌż“Ū¾żßżļż│ż╚żŪĪóźčźķ źß®`ź┐P( x | y ), P( y | y ' ) ż“═ŲČ©ż╣żļ ż▐ż║ĪóīØ╩²ė╚Č╚ log P( D) ż“Ž┬╩Įż╬żĶż”ż╦▒Ēż╣ log P ( D ) = ĪŲ log P(x (i ) , y (i ) ) ( x ( i ) , y ( i ) )Ī╩D ? ? = ĪŲ ? ĪŲ log P ( x j | y j ) + ĪŲ log P ( y j | y j ?1 ) ? ? (i ) (i ) (i ) (i ) ? ( x ( i ) , y ( i ) )Ī╩D ? j j ? = ĪŲ n(( x, y ), D) log P( x | y ) + ĪŲ n(( y ' , y ), D) log P( y | y ' ) x, y y, y' = ĪŲ [źŪ®`ź┐DżŪĪóxż╦źķź┘źļyż¼ĖČėļżĄżņż┐╗ž╩²] log p x| y x, y + ĪŲ [źŪ®`ź┐DżŪĪóźķź┘źļy'ż╬┤╬ż╦źķź┘źļyż¼│÷¼FżĘż┐╗ž╩²] log q y '| y y ', y
- 13. 5.2.2 źčźķźß®`ź┐═ŲČ© ųŲ╝s╠§╝■ż“┐╝æ]ż╣żļż╚ĪóūŅė╚═ŲČ©ĮŌżŽęįŽ┬ż╬å¢Ņ}ż“ĮŌż»ż│ż╚żŪī¦│÷żŪżŁżļ max ĪŲ n(( x, y ), D) log p x| y + ĪŲ n(( y ' , y ), D) log q y| y ' x, y y, y' s.t. ĪŲp x x| y =1 ĪŲp y y| y ' =1 źķź░źķź¾źĖźÕĘ©ż“ė├żżżŲĪóūŅ┤¾╗»ż╣żļźčźķźß®`ź┐ż“Ū¾żßżļż╚ĪóęįŽ┬ż╬╩Įż╦ż╩żļ (č▌┴Ģå¢Ņ}Ż▒) n(( x, y ), D) p x| y = ĪŲ n(( x, y), D) x n(( y ' , y ), D) q y| y ' = ĪŲ n(( y' , y), D) x ę¬╦žż╚źķź┘źļĪóźķź┘źļż╚źķź┘źļż╬ĮMż▀║Žż’ż╗ż╬│÷¼FŅlČ╚ż“ źčźķźß®`ź┐ż╚żĘżŲżżżļż└ż▒ż╩ż╬żŪĪóĄ▒ż┐żĻŪ░ż╬ĮY╣¹
- 14. 5.2.3 HMMż╬═Ųšō żóżļŽĄ┴ąxż¼ėļż©żķżņż┐ż╚żŁż╬ūŅ▀mż╩źķź┘źļ┴ąyż“Ū¾żßż┐żż ?ż│ż╬ūŅ▀m╗»å¢Ņ}ż“ĮŌżŁż┐żż: y max = arg max P(x, y ) y żĘż½żĘĪó├░Ņ^ż╦╩÷ż┘ż┐żĶż”ż╦Īóźķź┘źļ┴ąż╬ĮMż▀║Žż’ż╗╩²ż¼┼“┤¾ż╩ż╬żŪĪó╚½żŲ ┴ąÆżż╣żļż│ż╚żŽ▓╗┐╔─▄ ? Viterbi algorithm(ź¶źŻź┐źėźóźļź┤źĻź║źÓŻ® ? ╔Žż╬ūŅ▀m╗»å¢Ņ}ż“ä┐┬╩Ą─ż╦ĮŌż»źóźļź┤źĻź║źÓ ? ę╗ĘNż╬äėĄ─ėŗ╗ŁĘ© ? Ž╚Ņ^ż╬ę¬╦žż½żķĒśĘ¼ż╦źķź┘źļż“ĖČėļżĘżŲżżż»
- 15. Viterbi algorithm Pseudocode(Ū░░ļ) ╚ļ┴”:ŽĄ┴ąx for j=2 to |x| for all yj t ( j , y j ) = max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 s ( j , y j ) = arg max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 end for ╚½żŲż╬ę¬╦žż╦īØÅĻż╣żļ╚½żŲż╬źķź┘źļż╦ż─żżżŲĪóż╔ż╬źķź┘źļ end for ż½żķ▀węŲż╣żļ┤_┬╩ż¼Ė▀żżż½ż“▒╚▌^ż╣żļ t(j,yj):ę¬╦žjż╦īØÅĻż╣żļźķź┘źļż¼yjż“ż╚żļ╠§╝■ż╬żŌż╚Īó┤_┬╩ż¼ūŅ┤¾ż╚ż╩żļźķ ź┘źļ┴ąż“ż╚żļ┤_┬╩ĪŻ s(j,yj):┤_┬╩ż¼ūŅ┤¾ż╚ż╩żļźķź┘źļż“ż╚ż├ż┐ł÷║Žż╬yj-1ż“▒Ż┤µĪŻźóźļź┤źĻź║źÓż╬ ßß░ļżŪ╩╣ė├ĪŻ
- 16. Viterbi algorithm Pseudocode(ßß░ļ) Ū░░ļ▓┐ż╬źżźß®`źĖ ūŅ▀mż╩źķź┘źļ┴ąż“╠Įż╣ ßß░ļ▓┐ ╚ļ┴”:t(|x|,y),s y|max = arg max t (| x |, y ) x| y for j=|x|-1 to 1 y max = s ( j + 1, y max ) j j +1 end for ūŅ▀mż╩źķź┘źļ┴ąż“ßßżĒé╚ż╬ę¬╦žż½żķĒśż╦Īó─µŽ“żŁż╦╚ĪżĻ│÷żĘżŲżżżļ
- 17. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 18. 5.3 ═©│Żż╬ĘųŅÉŲ„ż╬ų┤╬▀mė├ ? 4š┬ż╬ĘųŅÉŲ„ż“ų┤╬Ą─ż╦ė├żżżļż│ż╚żŪĪóŽĄ┴ąźķź┘źĻź¾ź░ż“ąąż” ĘĮĘ©żŌżóżļ ? Ex. P ( y j | x j ?1 , x j , x j +1 y j ?1 ) ĘųŅÉŲ„żŽż╩ż¾żŪżŌżĶżż(Na?ve Bayes/SVMż╩ż╔Ż® ? ĘųŅÉŲ„ż╬ų┤╬▀mė├ż╬╠žÅš ? ų▒ßßż╬ę¬╦žż“ė├żżżļ╩┬żŌżŪżŁżļ ? Ė„ę¬╦žż╦ż─żżżŲĪóśöĪ®ż╩╦žąįż“ė├żżżļż│ż╚ż¼│÷└┤żļ ? ę╗░ŃĄ─ż╦Īóėŗ╦ŃĢrķgż¼ēł┤¾ż╣żļ ? źķź┘źļŽĄ┴ą╚½╠Õż╬┤_ż½żķżĘżĄżŽ┐╝æ]żĘżŲżżż╩żż
- 19. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 20. 5.4 ╠§╝■ĖČ┤_┬╩ł÷(CRF) ? ╠§╝■ĖČ┤_┬╩ł÷(Conditional Random Field) ? CRFż╚║¶żążņżļż│ż╚ż¼ČÓżż ? śöĪ®ż╩╦žąįż“ė├żżżļż│ż╚ż¼│÷└┤Īóż▐ż┐źķź┘źļŽĄ┴ą╚½╠Õż╬┤_ż½żķżĘżĄż╦żŌ Į╣ĄŃż“Ą▒żŲż┐č¦┴Ģż“ąąż©żļźŌźŪźļ ? 4.5╣Øż╬īØ╩²ŠĆą╬źŌźŪźļż“ŽĄ┴ąźķź┘źĻź¾ź░å¢Ņ}żž▀mė├żĘż┐żŌż╬ ė¢ŠÜźŪ®`ź┐: D = {( x (1) , y (1) ),..., (x (D) (D) ,y )} ż¼ėļż©żķżņż┐ż╚ż╣żļ ż│ż╬ĢrĪóźķź┘źļ┴ąż╬ŽĄ┴ąż╦īØż╣żļ╠§╝■ĖČżŁ┤_┬╩ż“ęįŽ┬ż╬żĶż”ż╦ż¬ż» 1 P ( y | x) = exp(w ? ”Ą(x, y)) Z x,w w : ╦žąįż╦īØż╣żļųžż▀ź┘ź»ź╚źļ ? ? Z x,w : š²ęÄ╗»éS╩²? Z x, w = ? ĪŲ exp(w ? ”Ą(x, y)) ? ? ? y ?
- 21. 5.4.1 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬ī¦╚ļ ūŅ▀mż╩źķź┘źļ┴ąż“Ū¾żßż┐żżĪŻżĶż├żŲĪóęįŽ┬ż╬ūŅ┤¾╗»å¢Ņ}ż“ĮŌż» 1 y ? = arg max exp(w ? ”Ą(x, y)) y Z x,w = arg max w ? ”Ą(x, y) y ż┐ż└żĘĪóż│ż╬ūŅ┤¾╗»å¢Ņ}ż“ĮŌż»ż╬żŽĘŪ│Żż╦Ģrķgż¼ż½ż½żļż┐żßĪóyżŽļOżĻ║Žż” źķź┘źļyt,yt-1ż╦ż╬ż▀ż╦ę└┤µż╣żļż╚żżż”╠§╝■ż“ż¬ż» ”šk (x, y ) = ĪŲ ”šk (x, yt , yt ?1 ) t w ? ”Ą(x, y) = w ? ĪŲ ”šk (x, yt , yt ?1 ) t = ĪŲ w ? ”šk (x, yt , yt ?1 ) t y ? = arg max ĪŲ w ? ”šk (x, yt , yt ?1 ) y t
- 22. 5.4.1 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬ī¦╚ļ y ? = arg max ĪŲ w ? ”šk (x, yt , yt ?1 ) y t ╔Ž╩Įż╩żķżąĪówż¼Ęųż½ż├żŲżżżņżąViterbi AlgorithmżŪĖ▀╦┘ż╦ĮŌż»ż│ż╚ż¼żŪ żŁżļ t ( j , y j ) = max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 s ( j , y j ) = arg max[log P( x j , y j | x j ?1 , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 t ( j , y j ) = max[w ? ”Ą(x, y j , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 s ( j , y j ) = arg max[w ? ”Ą(x, y j , y j ?1 ) + t ( j ? 1, y j ?1 )] y j ?1 źŌźŪźļż╬ÆłÅłżŌ╚▌ęūż╦┐╔─▄ ”šk (x, y ) = ĪŲ ”šk (x, yt , yt ?1 , yt ? 2 ) t
- 23. 5.4.2 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬č¦┴Ģ Wż╬č¦┴ĢĘĮĘ© ęįŽ┬ż╬─┐Ą─ķv╩²ż“ūŅ┤¾╗»ż╣żļ L(w ) = ĪŲ log P(y | x) = ĪŲ w ? ”Ą(x, y) ? log Z D D x,w īgļHżŽĪóš²ät╗»ĒŚż“╝ėż©ż┐─┐Ą─ ķv╩²ż“ūŅ▀m╗»ż╣żļł÷║Žż¼ČÓżż L(w ) ? C | w | 2 żĘż½żĘĪó╔Ž╩ĮżŽĮŌ╬÷Ą─ż╦ĮŌż»ż│ż╚ż¼▓╗┐╔─▄ ūŅ╝▒╣┤┼õĘ©(1.2.2╣Ø)ż“ė├żżżļŻ©£╩ź╦źÕ®`ź╚ź¾Ę©żõ┤_┬╩Ą─╣┤┼õĘ©ż¼ė├żżżķżņżõż╣żżŻ® w new = w old + ”┼? w L(w old ) ? ? ? w L(w old )= ĪŲ ? ”Ą ( x (i ) , y (i ) ) ? ? ĪŲ P ( y | x )”Ą ( x , y ) ? (i ) (i ) ? D ? y ? ŽĄ┴ąźķź┘źĻź¾ź░żŪżŽyż╬ĮMż▀║Žż’ż╗ż¼┼“┤¾żŪĪó P(y|x)ż¼ėŗ╦Ń▓╗┐╔─▄
- 24. 5.4.2 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬č¦┴Ģ ĪŲ P ( y | x )”Ą ( x , y ) = ĪŲ P ( y | x )ĪŲ ”Ą ( x , y , y ) y (i ) (i ) y (i ) t (i ) t t ?1 = ĪŲ ĪŲ P( y , y t yt , yt ?1 t t ?1 | x (i ) )”Ą (x (i ) , yt , yt ?1 ) ż╚ēõą╬ż╣żļż│ż╚żŪĪóP( yt , yt ?1 | x (i ) ) ż¼ėŗ╦ŃżŪżŁżņżążĶżżą╬ż╚ż╩żļ ? t ( yt , yt ?1 ) = exp( w ? ”Ą (x, yt , yt ?1 ))ż╚ż¬ż▒żąĪó ? t ( yt , yt ?1 ) P ( y | x) = ĪŪ t Z x,w ż╚Ģ°ż▒żļż╬żŪĪó P( yt , yt ?1 | x) = ĪŲ ĪŲ P ( y | x) y 0:t ?2 y t +1:T +1 ĪŲ ĪŲ ĪŪ? ( y , y 1 = t' t' t '?1 ) Z x, w y 0:t ?2 y t +1:T +1 t' ? t ( yt , yt ?1 ) = Z x, w ĪŲ ĪŲ ĪŪ? ( y , y y 0:t ?2 y t +1:T +1 t 'Ī┘ t t' t' t '?1 )
- 25. 5.4.2 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬č¦┴Ģ ĪŲ ĪŲ ĪŪ? ( y , y ) y 0:t ?2 y t +1:T +1 t 'Ī┘ t t' t' t '?1 ? t ?1 ?? T +1 ? ? t ? = ? ? ĪŲĪŪ ? t ' ( yt ' , yt '?1 ) ?? ?? ĪŲĪŪ ? t ' ( yt ' , yt '?1 ) ? ? ”┴ ( yt , t ) = ? ? ĪŲĪŪ ? t ' ( yt ' , yt '?1 ) ? ? ? y 0:t ?2 t '=1 ?? y t +1:T +1 t '=t +1 ? ? y 0:t ?2 t '=1 ? = ”┴ ( yt ?1 , t ? 1) ”┬ ( yt , t ) ? T +1 ? 1 ”┬ ( yt , t ) = ? ? ĪŲĪŪ ? t ' ( yt ' , yt '?1 ) ? ? P( yt , yt ?1 | x) = ? t ( yt , yt ?1 )”┴ ( yt ?1 , t ? 1) ”┬ ( yt , t ) ? y t +1:T +1 t '=t +1 ? Z x,w ╔Ž╩Įż¼Ė▀╦┘ż╦ėŗ╦ŃżŪżŁżņżążĶżż ”┴ ( yt , t ) = ĪŲ? ( y , y t t t ?1 )”┴ ( yt ?1 , t ? 1) ”┴ ”┬ yt ?1 ”┬ ( yt , t ) = ĪŲ? yt +1 t +1 ( yt +1 , yt ) ”┬ ( yt +1 , t + 1) Z x,w = ĪŲ”┴ ( y yT T ,T ) ż“└¹ė├ż╣żņżąĪóDPż“ė├żżżŲĖ▀╦┘ż╦ėŗ╦Ń┐╔─▄ż╦ż╩żļ
- 26. 5.4.2 ╠§╝■ĖČ┤_┬╩ł÷(CRF)ż╬č¦┴Ģ ”┴ ( yt , t ), ”┬ ( yt , t ) ż“└¹ė├żĘż┐ż│ż╬żĶż”ż╩╦ŃĘ©żŽĪóŪ░Ž“żŁ?ßßżĒŽ“żŁźóźļź┤źĻź║źÓ (forward-backward algorithm)ż╬ę╗ĘN ę╗░Ńż╬CRFżŽĪóŽĄ┴ą╔Žż╬ź╬®`ź╔ż└ż▒żŪż╩ż»Īóź░źķźš╔Žż╬ź╬®`ź╔ż╬źķź┘źĻź¾ź░å¢ Ņ}ż╦▀mė├┐╔─▄Ż©Ex.éSżĻ╩▄ż▒ĮŌ╬÷Ż®
- 27. ─┐┤╬ ? 5.1:ŽĄ┴ąźķź┘źĻź¾ź░Ė┼šō ? 5.2:ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? 5.3:ŽĄ┴ąźķź┘źĻź¾ź░ż╬ų┤╬Ą─╩ųĘ© ? 5.4:╠§╝■ĖČ┤_┬╩ł÷(CRF) ? 5.5:ż▐ż╚żß
- 28. 5.5 ż▐ż╚żß ? ŽĄ┴ąźķź┘źĻź¾ź░ ? ļLżņź▐źļź│źšźŌźŪźļ(HMM) ? ĘųŅÉŲ„ż╬ų┤╬▀mė├ ? ╠§╝■ĖČ┤_┬╩ł÷(CRF) ż╬Ż│ĘNż╦ż─żżżŲĪóšh├„ż“żĘż┐ ? ŽĄ┴ąźķź┘źĻź¾ź░╚½╠Õż╚żĘżŲżŽĪóNLP2006ź┴źÕ®`ź╚źĻźóźļżŌ▓╬ššż╣żļż╚żĶ żż http://www.geocities.co.jp/Technopolis/5893/publication/N LP2006slide.pdf ? HMMż╬forward-backward algorithm : Baum- Welch algorithm ? ż│żņżŽĪóEM algorithmż╬ę╗ĘN(3.5╣Ø)
- 29. 5.5 ż▐ż╚żß ? ĘųŅÉŲ„ż╦żĶżļų┤╬▀mė├ż╦żĶżļŽĄ┴ąźķź┘źĻź¾ź░żŪ╠ž╣Pż╣ż┘żŁżŌż╬ ? YamChaż╦żŌė├żżżķżņżŲżżżļSVMż“ė├żżż┐ŽĄ┴ąźķź┘źĻź¾ź░ ? CRFż“ūį╚╗čįšZäI└Ēż╦ÅĻė├żĘż┐żŌż╬ż╚żĘżŲĪóMALLET,CRF++ż╩ż╔ ? ─Šśŗįņż╦īØżĘżŲCRFż“ÆQż”ż╦żŽĪó┤_┬╩ü╗▓źĘ©(belief propagation)ż¼ ▒žę¬ (Bishop▒Š:8.4╣Ø) ? ź┴źŃź¾źŁź¾ź░ż╦żŽIOB2ź┐ź░ęį═Ōż╦żŌĪóśöĪ®ż╩ēõĘNż¼┤µį┌