Object Detection & Instance Segmentation§ő’ďőńĹBĹť | OHS√„ŹäĽŠ#3
Download as PPTX, PDF9 likes58,146 views

√„ŹäĽŠ§«◊ÓĹŁ’i§ů§ņ’ďőń£≤Īĺ§őĹBĹť§Ú––§§§ř§∑§Ņ°£ ?SSD: Single Shot MultiBox Detector ?End-to-End Instance Segmentation and Counting with Recurrent Attention




















![[DL›Ü’iĽŠ]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=560&fit=bounds)


![[DL›Ü’iĽŠ]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=560&fit=bounds)








![[DL›Ü’iĽŠ]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=560&fit=bounds)


![SSII2021 [OS2-02] …ÓĆ”—ßŃē§ň§™§Ī§Ž•«©`•ŅíąŹą§ő‘≠ņŪ§»◊Ó–¬Ą”ŌÚ](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)






![[DL›Ü’iĽŠ]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)
![[DL›Ü’iĽŠ]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=560&fit=bounds)

![[DL›Ü’iĽŠ]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=560&fit=bounds)
More Related Content
What's hot (20)
Similar to Object Detection & Instance Segmentation§ő’ďőńĹBĹť | OHS√„ŹäĽŠ#3 (20)

![[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20180528-180528084124-thumbnail.jpg?width=560&fit=bounds)





![[DL›Ü’iĽŠ]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=560&fit=bounds)
![[DL›Ü’iĽŠ]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=560&fit=bounds)
![[DL›Ü’iĽŠ]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=560&fit=bounds)








Recently uploaded (11)











Object Detection & Instance Segmentation§ő’ďőńĹBĹť | OHS√„ŹäĽŠ#3
- 1. OHS#3 ’ďőńĹBĹť Object Detection & Instance Segmentation įŽĻ»
- 2. Contents ? Object Detection ? •Ņ•Ļ•Į§ň§ń§§§∆ ? R-CNN ? Faster R-CNN ? Region Proposal Network§ő§∑§Į§Ŗ ? SSD: Single Shot Multibox Detector ? Instance Segmentation ? •Ņ•Ļ•Į§ň§ń§§§∆ ? End-to-End Instance Segmentation and Counting with Recurrent Attention 2
- 3. “Ľį„őÔŐŚ’J◊R∑÷“į§«§őDeep Learning ? ĺ≤÷Ļ§ő∑÷Óź•Ņ•Ļ•Į§Ō°ĘCNN§ň§Ť§ŽŐōŹ’ŃŅ≥ť≥Ų§™§Ť§”—ßŃē§ň§Ť§Íįk’Ļ ? §Ť§ÍłŖ∂»§ •Ņ•Ļ•Į§«§Ę§ŽőÔŐŚó ≥Ų°ĘőÔŐŚÓI”Ú≥ť≥Ų§ō§»įk’Ļ Classification Object Detection Semantic Segmentation Instance Segmentation Plants http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/CNN_survey.pdf http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html Plants Plants Plants §Ť§ÍłŖ∂» 3
- 4. Object Detection ĹBĹť§Ļ§Ž’ďőń£ļ SSD: Single Shot MultiBox Detector
- 5. Object Detection ? Ľ≠ŌŮ÷–§ő—} ż§őőÔŐŚ§Ú¬©§ž§ §Į£Į÷ō—}üo§Įó ≥Ų§Ļ§Ž§≥§»§¨ńŅĶń°£ ? őÔŐŚ§őó ≥Ųĺę∂»£®Precision£©§»°Ę¬©§ž§ §Įó ≥Ų§«§≠§∆§§§Ž§ę§ő÷łėň§«§Ę§ŽŖmļŌ¬ £®Recall£©§őťvāS(Precision-recall curve)§ę§ťň„≥Ų§∑§Ņ°ĘAverage Precision (AP) §¨÷ų§ ÷łėň°£ ? ĆgÜĖÓ}§ō§őŹÍ”√§¨∆ŕīż§Ķ§ž°ĘAP§ő§Ř§ę”Ťúyēr§ő”čň„ērťg§‚÷ō“™§«°Ę•Í•Ę•Ž•Ņ•§•ŗ–‘§¨«ů§Š §ť§ž§∆§§§Ž°£ http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ Precision Recall1 1 √ś∑e = AP 5
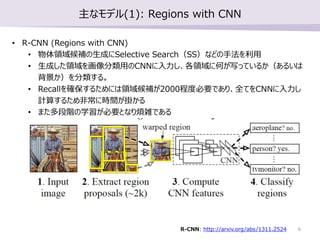
- 6. ÷ų§ •‚•«•Ž(1): Regions with CNN ? R-CNN (Regions with CNN) ? őÔŐŚÓI”ÚļÚ—a§ő…ķ≥…§ňSelective Search£®SS£©§ §…§ő ÷∑®§ÚņŻ”√ ? …ķ≥…§∑§ŅÓI”Ú§ÚĽ≠ŌŮ∑÷Óź”√§őCNN§ň»ŽŃ¶§∑°ĘłųÓI”Ú§ňļő§¨–ī§√§∆§§§Ž§ę£®§Ę§Ž§§§Ō Ī≥ĺį§ę£©§Ú∑÷Óź§Ļ§Ž°£ ? Recall§Úī_Ī£§Ļ§Ž§Ņ§Š§ň§ŌÓI”ÚļÚ—a§¨2000≥Ő∂»Īō“™§«§Ę§Í°Ę»ę§∆§ÚCNN§ň»ŽŃ¶§∑ ”čň„§Ļ§Ž§Ņ§Š∑«≥£§ňērťg§¨íž§ę§Ž ? §ř§Ņ∂ŗ∂őŽA§ő—ßŃē§¨Īō“™§»§ §Íü©Žj§«§Ę§Ž R-CNN: http://arxiv.org/abs/1311.2524 6
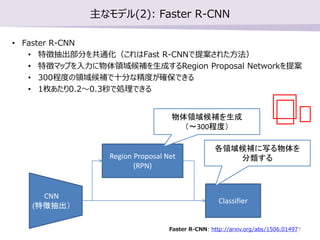
- 7. ÷ų§ •‚•«•Ž(2): Faster R-CNN ? Faster R-CNN ? ŐōŹ’≥ť≥Ų≤Ņ∑÷§ÚĻ≤Õ®ĽĮ£®§≥§ž§ŌFast R-CNN§«ŐŠįł§Ķ§ž§Ņ∑Ĺ∑®£© ? ŐōŹ’•ř•√•◊§Ú»ŽŃ¶§ňőÔŐŚÓI”ÚļÚ—a§Ú…ķ≥…§Ļ§ŽRegion Proposal Network§ÚŐŠįł ? 300≥Ő∂»§őÓI”ÚļÚ—a§« ģ∑÷§ ĺę∂»§¨ī_Ī£§«§≠§Ž ? 1√∂§Ę§Ņ§Í0.2°ę0.3√Ž§«ĄIņŪ§«§≠§Ž Region Proposal Net (RPN) CNN (ŐōŹ’≥ť≥Ų£© Classifier őÔŐŚÓI”ÚļÚ—a§Ú…ķ≥… £®°ę300≥Ő∂»£© łųÓI”ÚļÚ—a§ň–ī§ŽőÔŐŚ§Ú ∑÷Óź§Ļ§Ž Faster R-CNN: http://arxiv.org/abs/1506.014977
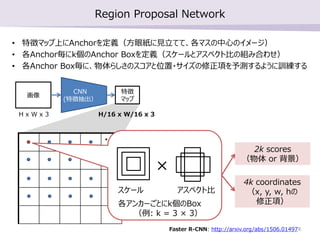
- 8. Region Proposal Network ? ŐōŹ’•ř•√•◊…Ō§ňAnchor§Ú∂®Ńx£®∑Ĺ—Řľą§ň“äŃʧ∆§∆°Ęłų•ř•Ļ§ő÷––ń§ő•§•Š©`•ł£© ? łųAnchoröį§ňkāħőAnchor Box§Ú∂®Ńx£®•Ļ•Ī©`•Ž§»•Ę•Ļ•ŕ•Į•»Ī»§őĹM§ŖļŌ§Ô§Ľ£© ? łųAnchor Boxöį§ň°ĘőÔŐŚ§ť§∑§Ķ§ő•Ļ•≥•Ę§»őĽ÷√?•Ķ•§•ļ§ő–ř’żŪó§Ú”Ťúy§Ļ§Ž§Ť§¶§ň”Ėĺö§Ļ§Ž Faster R-CNN: http://arxiv.org/abs/1506.01497 Ľ≠ŌŮ ŐōŹ’ •ř•√•◊ CNN (ŐōŹ’≥ť≥Ų£© ??? •Ļ•Ī©`•Ž •Ę•Ļ•ŕ•Į•»Ī» °Ń łų•Ę•ů•ę©`§ī§»§ňkāħőBox £®ņż: k = 3 °Ń 3£© 2k scores £®őÔŐŚ or Ī≥ĺį£© 4k coordinates £®x, y, w, h§ő –ř’żŪó£© H x W x 3 H/16 x W/16 x 3 8
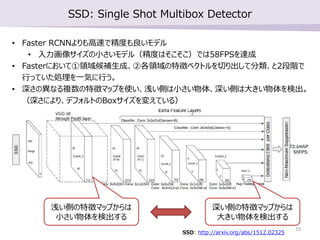
- 9. SSD: Single Shot Multibox Detector Region Proposal Net (RPN) CNN (ŐōŹ’≥ť≥Ų£© Classifier ĘŔ őÔŐŚÓI”ÚļÚ—a§Ú…ķ≥… £®őÔŐŚ§ť§∑§Ķ§ő•Ļ•≥•Ę£© Ęŕ łų•Į•ť•Ļ§ň∑÷Óź CNN (ŐōŹ’≥ť≥Ų£© Region Proposal + Classifier őÔŐŚÓI”ÚļÚ—a§Ú…ķ≥… £®•Į•ť•Ļöį§ő•Ļ•≥•Ę£©SSD Faster R-CNN ? Faster RCNN§Ť§Í§‚łŖňŔ§«ĺę∂»§‚Ńľ§§•‚•«•Ž ? »ŽŃ¶Ľ≠ŌŮ•Ķ•§•ļ§ő–°§Ķ§§•‚•«•Ž£®ĺę∂»§Ō§Ĺ§≥§Ĺ§≥£©§«§Ō58FPS§ÚŖ_≥… ? Faster§ň§™§§§∆ĘŔÓI”ÚļÚ—a…ķ≥…°ĘĘŕłųÓI”Ú§őŐōŹ’•Ŕ•Į•»•Ž§Ú«–§Í≥Ų§∑§∆∑÷Óź°Ę§»2∂őŽA§« ––§√§∆§§§ŅĄIņŪ§Ú“Ľö›§ň––§¶°£ ? …Ó§Ķ§őģź§ §Ž—} ż§őŐōŹ’•ř•√•◊§Ú Ļ§§°Ę«≥§§ā»§Ō–°§Ķ§§őÔŐŚ°Ę…Ó§§ā»§Ōīů§≠§§őÔŐŚ§Úó ≥Ų°£ SSD: http://arxiv.org/abs/1512.02325 9
- 10. SSD: Single Shot Multibox Detector ? Faster RCNN§Ť§Í§‚łŖňŔ§«ĺę∂»§‚Ńľ§§•‚•«•Ž ? »ŽŃ¶Ľ≠ŌŮ•Ķ•§•ļ§ő–°§Ķ§§•‚•«•Ž£®ĺę∂»§Ō§Ĺ§≥§Ĺ§≥£©§«§Ō58FPS§ÚŖ_≥… ? Faster§ň§™§§§∆ĘŔÓI”ÚļÚ—a…ķ≥…°ĘĘŕłųÓI”Ú§őŐōŹ’•Ŕ•Į•»•Ž§Ú«–§Í≥Ų§∑§∆∑÷Óź°Ę§»2∂őŽA§« ––§√§∆§§§ŅĄIņŪ§Ú“Ľö›§ň––§¶°£ ? …Ó§Ķ§őģź§ §Ž—} ż§őŐōŹ’•ř•√•◊§Ú Ļ§§°Ę«≥§§ā»§Ō–°§Ķ§§őÔŐŚ°Ę…Ó§§ā»§Ōīů§≠§§őÔŐŚ§Úó ≥Ų°£ £®…Ó§Ķ§ň§Ť§Í°Ę•«•’•©•Ž•»§őBox•Ķ•§•ļ§ÚČš§®§∆§§§Ž£© «≥§§ā»§őŐōŹ’•ř•√•◊§ę§ť§Ō –°§Ķ§§őÔŐŚ§Úó ≥Ų§Ļ§Ž …Ó§§ā»§őŐōŹ’•ř•√•◊§ę§ť§Ō īů§≠§§őÔŐŚ§Úó ≥Ų§Ļ§Ž SSD: http://arxiv.org/abs/1512.02325 10
- 11. SSD: Single Shot Multibox Detector ? Pascal VOC 2007§őDetection•Ņ•Ļ•Į§őĹYĻŻ ? »ŽŃ¶Ľ≠ŌŮ•Ķ•§•ļ§¨300x300§ő•‚•«•Ž£®SSD300)§«§Ō58FPS§ÚŖ_≥…§∑°Ęmean AP §‚70%§Ú≥¨§®§∆§§§Ž°£ ? »ŽŃ¶Ľ≠ŌŮ•Ķ•§•ļ§¨500x500§ő•‚•«•Ž(SSD500)§«§Ō°ĘFaster R-CNN§Ť§Íĺę∂»§‚łŖ §ĮĄIņŪňŔ∂»§‚ňŔ§§°£ SSD: http://arxiv.org/abs/1512.02325 11
- 12. Instance Segmentation ĹBĹť§Ļ§Ž’ďőń£ļ End-to-End Instance Segmentation and Counting with Recurrent Attention
- 13. Instance Segmentation ? ÓI”Ú∑÷łÓ£®Segmentation£© ? •‘•Į•Ľ•Žöį§ő•ť•Ŕ•Ž§Ú”Ťúy§Ļ§Ž ? –ő◊ī§š√ś∑e§»§§§√§Ņ«ťąů§¨Ķ√§ť§ž§Ž§Ņ§ŠŹÍ”√Ō»§‚∂ŗ§Į°ĘĽÓįk§ň—–ĺŅ§Ķ§ž§∆§§§Ž°£ ? •Ņ•Ļ•Į§ő∑÷Óź ? Semantic Segmentation ? łų•‘•Į•Ľ•Ž§ň•Į•ť•Ļ§ő•ť•Ŕ•Ž§Úł∂”Ž§Ļ§ŽÜĖÓ}°£ ? •‹•»•Ž§¨4Īĺ§Ę§ŽąŲļŌ§«§‚°Ę»ę§∆°ł•‹•»•Ž•Į•ť•Ļ°Ļ§ő•ť•Ŕ•Ž§Ú§ń§Ī§Ž ? Instance Segmentation ? āÄ°©§őőÔŐŚ§ī§»§ňĄe§ő•ť•Ŕ•Ž§Úł∂”Ž§Ļ§ŽÜĖÓ} ? •‹•»•Ž§¨4Īĺ§Ę§ŽąŲļŌ°ĘĄe°©§ő•ť•Ŕ•Ž§Úł∂”Ž§Ļ§Ž (b) Instance ~ (a) Semantic ~Raw Image http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html 13
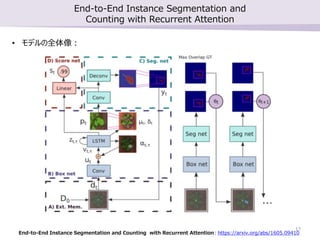
- 16. End-to-End Instance Segmentation and Counting with Recurrent Attention ? Instance Segmentation”√§ő•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į ? •Ļ•∆•√•◊öį§ň£Ī§ń§őőÔŐŚ§ň◊ĘńŅ§∑§∆ÓI”Ú∑÷łÓ§Ļ§Ž ? “Ľ∂»“ä§ŅÓI”Ú§Ō”õĎõ§∑§∆§™§Į £®»ňťg§ő ż§®∑ŧÚ≤őŅľ§ň§∑§∆§§§Ž£© End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 16
- 17. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 ? •‚•«•Ž§ő»ęŐŚŌŮ£ļ 17
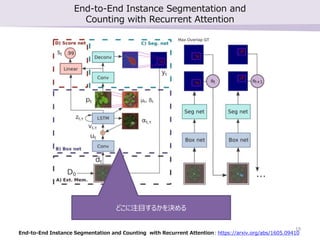
- 18. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 “Ľ∂»“ä§ŅÓI”Ú§Ú”õĎõ§∑§∆§™§Į≤Ņ∆∑ 18
- 19. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 §…§≥§ň◊ĘńŅ§Ļ§Ž§ę§ÚõQ§Š§Ž 19
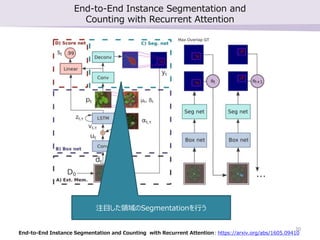
- 20. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 ◊ĘńŅ§∑§ŅÓI”Ú§őSegmentation§Ú––§¶ 20
- 21. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 őÔŐŚ§¨“ä§ń§ę§√§Ņ§ę§…§¶§ę§őŇ–∂®§Ú––§¶ £®•Ļ•≥•Ę§¨0.5“‘Ō¬§ň§ §√§Ņ§ťĹKŃň£© 21
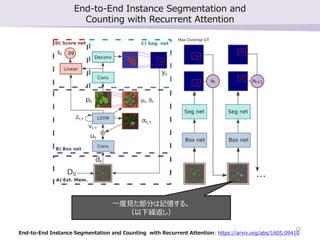
- 22. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 “Ľ∂»“ä§Ņ≤Ņ∑÷§Ō”õĎõ§Ļ§Ž°£ £®“‘Ō¬ņR∑Ķ§∑£© 22
- 23. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 ? ĹYĻŻ£®£Ī£©»~§√§—§őÓI”Ú∑÷łÓ 23
- 24. End-to-End Instance Segmentation and Counting with Recurrent Attention End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410 ? ĹYĻŻ£®2£©‹áĀI§őÓI”Ú∑÷łÓ 24
Editor's Notes
- #11: Ą”Ľ≠; https://drive.google.com/file/d/0BzKzrI_SkD1_R09NcjM1eElLcWc/view?pref=2&pli=1 •≥©`•…; https://github.com/weiliu89/caffe/tree/ssd