Open stackВЮў vmЖ░ювЁљВЮё ьєхьЋю dockerВЮў ьЎхМџЕ
14 likes2,516 views

OpenStack Days Korea 2017 в░юьЉюВъљвБї





































![XECon2015 :: [1-5] Ж╣ђьЏѕв»╝ - Вёюв▓ё Вџ┤ВўЂВъљЖ░ђ Ж╝Г ВЋїВЋёВЋ╝ ьЋа Docker](https://cdn.slidesharecdn.com/ss_thumbnails/xecon2015-1-5docker-160316043822-thumbnail.jpg?width=560&fit=bounds)

![[NDC17] KubernetesвАю Ж░юв░юВёюв▓ё Ж░ёвІеьъѕ В░ЇВќ┤вѓ┤ЖИ░](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=560&fit=bounds)



![[H3 2012] вѓ┤В╗┤ВЌљВёа ВъўвљўвЇўвЇ░? - vagrantвАю Вёюв▓ёВЎђ вЈЎВЮ╝ьЋю Ж░юв░юьЎўЖ▓й ЖЙИв»ИЖИ░](https://cdn.slidesharecdn.com/ss_thumbnails/c6-vagrantshare-121107074434-phpapp01-thumbnail.jpg?width=560&fit=bounds)

![[Nomad connection]docker seminar 15.10.08](https://cdn.slidesharecdn.com/ss_thumbnails/nomadconnectiondockerseminar-15-151012144050-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)





![[ВўцьћѕВєїВіцВ╗еВёцьїЁ]В┐ав▓ёвёцьІ░ВіцвЦ╝ ьЎхМџЕьЋю Ж░юв░юьЎўЖ▓й ЖхгВХЋ](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=560&fit=bounds)



![[ВўцьћѕВєїВіцВ╗еВёцьїЁ]Virtualization kvm-rhev](https://cdn.slidesharecdn.com/ss_thumbnails/virtualization-kvm-rhev-140407012113-phpapp01-thumbnail.jpg?width=560&fit=bounds)

More Related Content
What's hot (20)
Similar to Open stackВЮў vmЖ░ювЁљВЮё ьєхьЋю dockerВЮў ьЎхМџЕ (20)





![[ВўцьћѕВєїВіцВ╗еВёцьїЁ]ьЂ┤вЮ╝Вџ░вЊюВъљвЈЎьЎћ в░Ј Вџ┤ВўЂьџеВюеьЎћв░ЕВЋѕ](https://cdn.slidesharecdn.com/ss_thumbnails/random-140217215646-phpapp01-thumbnail.jpg?width=560&fit=bounds)


![2.[d2 рёІрЁЕрёЉрЁ│рєФрёЅрЁдрёєрЁхрёѓрЁА]рёѓрЁдрёІрЁхрёЄрЁЦрёЈрЁ│рє»рёЁрЁАрёІрЁ«рёЃрЁ│ рёЅрЁхрёЅрЁ│рёљрЁдрєи рёІрЁАрёЈрЁхрёљрЁдрєерёјрЁЦ рёєрЁхрєЙ рёњрЁфрє»рёІрЁГрє╝ рёЄрЁАрє╝рёІрЁАрєФ](https://cdn.slidesharecdn.com/ss_thumbnails/2-140905001236-phpapp02-thumbnail.jpg?width=560&fit=bounds)
![[NDC18] вДївЊцЖ│а вХЊЖ│а вХђВѕўЖ│а - сђѕВЋ╝ВЃЮВЮў вЋЁ: вЊђвъЉЖ│асђЅ Вёюв▓ё Ж┤ђвдг в░░ьЈг ВЮ┤ВЋ╝ЖИ░](https://cdn.slidesharecdn.com/ss_thumbnails/ndc18-180429152609-thumbnail.jpg?width=560&fit=bounds)


![[OpenStack Days Korea 2016] Track3 - VDI on OpenStack with LeoStream Connecti...](https://cdn.slidesharecdn.com/ss_thumbnails/36gotocloud-160226174146-thumbnail.jpg?width=560&fit=bounds)


![[ВўцьћѕьЁїьЂгвёиВёюв░І2022] ЖхГвѓ┤ PaaS(Kubernetes) Best Practice в░Ј DevOps ьЎўЖ▓й ЖхгВХЋ ВѓгвАђ.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/2022paaskubernetesbestpracticedevops-220927105318-84776c9a-thumbnail.jpg?width=560&fit=bounds)
![[IGC 2017] ВЋёвДѕВА┤ ЖхгВі╣вфе - Ж▓їВъё ВЌћВДёВю╝вАю Вёюв▓ё ВаюВъЉ в░Ј Вџ┤ВўЂЖ╣їВДђ](https://cdn.slidesharecdn.com/ss_thumbnails/igc2017-170904090322-thumbnail.jpg?width=560&fit=bounds)

More from Tae Young Lee (20)




















Open stackВЮў vmЖ░ювЁљВЮё ьєхьЋю dockerВЮў ьЎхМџЕ
- 1. Produced by Tae Young Lee
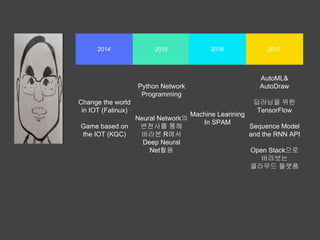
- 2. 2014 2015 20172016 AutoML& AutoDraw вћЦвЪгвІЮВЮё ВюёьЋю TensorFlow Sequence Model and the RNN API Open StackВю╝вАю в░ћвЮ╝в│┤віћ ьЂ┤вЮ╝Вџ░вЊю ьћївъФьЈ╝ Machine Learning In SPAM Python Network Programming Neural NetworkВЮў в│ђВ▓юВѓгвЦ╝ ьєхьЋ┤ в░ћвЮ╝в│И RВЌљВёю Deep Neural NetьЎхМџЕ Change the world in IOT (Falinux) Game based on the IOT (KGC)
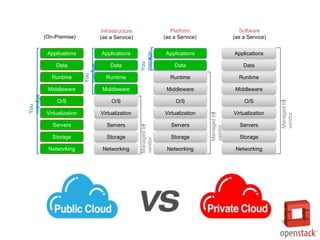
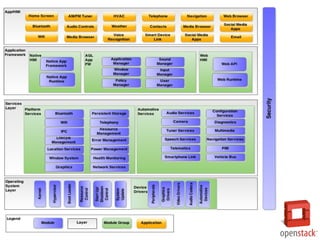
- 5. (On-Premise) Storage Servers Networking O/S Middleware Virtualization Data Applications Runtime Managedby vendor Infrastructure (as a Service) Storage Servers Networking O/S Middleware Virtualization Data Applications Runtime You manage You manage Platform (as a Service) Managedby vendor Storage Servers Networking O/S Middleware Virtualization Applications Runtime Data Managedby vendor Software (as a Service) Storage Servers Networking O/S Middleware Virtualization Applications Runtime Data You manage
- 6. РЌЈ Вёюв▓ёьєхьЋЕ РЌІ вЇ░ВЮ┤ьё░Вё╝ьё░ ВаёваЦ ВЌљвёѕВДђВЎђ Ж│хЖ░ё ВаѕВЋй РЌЈ Вёюв╣ёВіц вХёвдг РЌІ Вёюв╣ёВіц вХёвдгвЦ╝ ВюёьЋю ВЋаьћївдгВ╝ђВЮ┤ВЁўВЮё Ж░ђВЃЂВёюв▓ёвЦ╝ ьєхьЋ┤ вХёвдг Ж░ђвіЦ РЌЈ в╣авЦИ Вёюв▓ё в░░ьЈг РЌІ ВЮ┤в»ИВДђ ВЎђ ВіцвЃЁВЃиВЮё ьєхьЋю ВІюВіцьЁю в░░ьЈг в░Ј в│хВаю Ж░ђвіЦ РЌЈ ВъгьЋ┤в│хЖхг РЌІ ВіцвЃЁВЃиВЮё ьєхьЋю Ж░ђВЃЂВёюв▓ё в│хВЏљ, VM вДѕВЮ┤ЖиИваѕВЁўВю╝вАю вЇ░ВЮ┤ьё░Вё╝ьё░ ВЮ┤вЈЎ Ж░ђвіЦ РЌЈ вЈЎВаЂ вАювЊюв░ИвЪ░ВІ▒ РЌІ ВъЉВЌЁ вХђьЋўВЌљ вћ░вЮ╝ ВъљВЏљ ВѓгВџЕвЪЅ ВА░Ваѕ Ж░ђвіЦ РЌЈ в╣авЦИ Ж░юв░юВЮё ВюёьЋю ьЁїВіцьіИ ьЎўЖ▓йВаюЖ│х РЌІ Ж░ђВЃЂВёюв▓ёвЦ╝ ьєхьЋю в╣авЦИ ьЁїВіцьіИ ьЎўЖ▓й ВаюЖ│хВю╝вАю Ж░юв░ю ВІюЖ░ё вІеВХЋ Ж░ђВЃЂьЎћВЮў ВъЦВаљ
- 7. РЌЈ ВІюВіцьЁю в│┤ВЋѕ Ж│╝ ВІавб░Вё▒ ьќЦВЃЂ РЌІ Ж░ђВЃЂВёюв▓ёВЎђ вг╝вдгВаЂ ьЋўвЊюВЏеВќ┤ ВѓгВЮ┤ ВХћВЃЂьЎћ ваѕВЮ┤Вќ┤вЦ╝ ьєхьЋю в│┤ВЋѕ Ж░ЋьЎћ РЌЈ OS вЈЁвдй , ьЋўвЊюВЏеВќ┤ в▓цвЇћ вЮй-ВЮИ(lock-in) ВХЋВєї РЌІ ьЋўвЊюВЏеВќ┤ ВХћВЃЂьЎћвЦ╝ ьєхьЋ┤ Ж░ђВЃЂ ьЋўвЊюВЏеВќ┤віћ в▓цвЇћ вЮй-ВЮИВЮ┤ ВаюЖ▒░вље Ж░ђВЃЂьЎћВЮў ВъЦВаљ
- 8. РЌЈ вЈЎВЮ╝ьЋю вг╝вдгВаЂ ьўИВіцьіИЖ░ђ ВёювАювІцвЦИ ВъЉВЌЁВЮё Ж░ђвіЦьЋўЖ▓ї ьЋе РЌІ ВъЉВЌЁВЮђ вЈЎВЮ╝ьЋю Вџ┤ВўЂВ▓┤ВаюВЌљВёю вЈЁвдйВаЂВю╝вАю ВъЉвЈЎ РЌЈ В╗еьЁїВЮ┤вёѕ Ж░ђВЃЂьЎћ РЌІ вг╝вдгВаЂ Вёюв▓ёВЌљ вІцВцЉВЮў Ж▓Евдгвљю Вџ┤ВўЂВ▓┤Ваю ВЮИВіцьё┤Віц(В╗еьЁїВЮ┤вёѕ)вЦ╝ ВІцьќЅ РЌЈ В╗еьЁїВЮ┤вёѕ Ж░ђВЃЂьЎћ ВбЁвЦў РЌІ Solaris В╗еьЁїВЮ┤вёѕ, FreeBSD jails, Parallels OpenVZ РЌЈ вІеВЮ╝ ВІюВіцьЁюВЌљВёю ВІцьќЅ РЌІ ьћёвАюВёИВіц Ж▓Евдг ВЎђ ВъљВЏљ Ж┤ђвдгвіћ В╗цвёљВЮ┤ вІ┤вІ╣ РЌІ В╗еьЁїВЮ┤вёѕвіћ ВъљВІаВЮў ьїїВЮ╝ВІюВіцьЁю, ьћёвАюВёИВіц, вЕћвфевдг, вћћв░ћВЮ┤ВіцЖ░ђ ьЋавІ╣вље РЌЈ вЕђьІ░ OS ВІцьќЅ ВаюьЋю РЌІ ВюѕвЈёВџ░, вдгвѕЁВіц, ВюавІЅВіцвЊ▒ вІцВцЉ Вџ┤ВўЂВ▓┤ВаюЖ░ђ ВІцьќЅвљўвіћ Ж░ђВЃЂьЎћЖ░ђ ВЋёвІў РЌІ вІеВЮ╝ OS ВІцьќЅВю╝вАю Вё▒віЦЖ│╝ ьџеВюеВё▒ВЮ┤ вЏ░Вќ┤вѓе Вџ┤ВўЂВ▓┤Ваю Ж░ђВЃЂьЎћ/ьїїьІ░ВЁћвІЮ
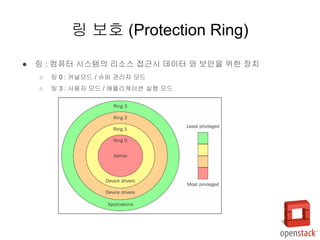
- 9. РЌЈ вДЂ : В╗┤ьЊеьё░ ВІюВіцьЁюВЮў вдгВєїВіц ВаЉЖи╝ВІю вЇ░ВЮ┤ьё░ ВЎђ в│┤ВЋѕВЮё ВюёьЋю ВъЦВ╣ў РЌІ вДЂ 0 : В╗цвёљвфевЊю / ВіѕьЇ╝ Ж┤ђвдгВъљ вфевЊю РЌІ вДЂ 3 : ВѓгВџЕВъљ вфевЊю / ВЋаьћївдгВ╝ђВЮ┤ВЁў ВІцьќЅ вфевЊю вДЂ в│┤ьўИ (Protection Ring)
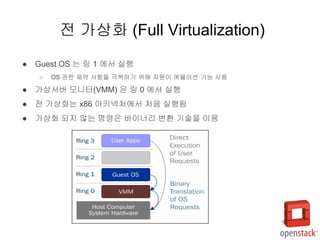
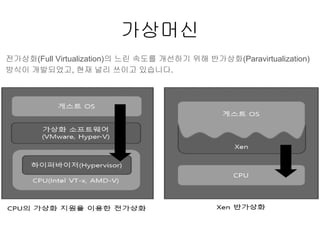
- 10. РЌЈ Guest OS віћ вДЂ 1 ВЌљВёю ВІцьќЅ РЌІ OS ЖХїьЋю ВаюВЋй ВѓгьЋГВЮё Жи╣в│хьЋўЖИ░ ВюёьЋ┤ ВъљВЏљВЮ┤ ВЌљв«гВЮ┤ВЁў ЖИ░віЦ ВѓгВџЕ РЌЈ Ж░ђВЃЂВёюв▓ё вфевІѕьё░(VMM) ВЮђ вДЂ 0 ВЌљВёю ВІцьќЅ РЌЈ Ваё Ж░ђВЃЂьЎћвіћ x86 ВЋёьѓцвёЦВ▓ўВЌљВёю В▓ўВЮї ВІцьќЅвље РЌЈ Ж░ђВЃЂьЎћ вљўВДђ ВЋівіћ вфЁва╣ВЮђ в░ћВЮ┤вёѕвдг в│ђьЎў ЖИ░ВѕаВЮё ВЮ┤ВџЕ Ваё Ж░ђВЃЂьЎћ (Full Virtualization)
- 11. РЌЈ ЖХїьЋюВЮ┤ ьЋёВџћьЋю вфЁва╣ВЮђ VMM ВЌљ ВаёвІгвљўВќ┤ в░ћВЮ┤вёѕвдг в│ђьЎў РЌЈ в░ћВЮ┤вёѕвдг в│ђьЎўв░ЕВІЮВЮђ ьЂ░ Вё▒віЦ ВађьЋўвЦ╝ в░юВЃЮ РЌЈ OS ВЮў В╗цвёљ ВѕўВаЋВЌєВЮ┤ ВѓгВџЕ Ж░ђвіЦьЋе РЌЈ VMM ВЮђ CPU вЦ╝ Ж┤ђвдгьЋўЖ│а ВЌљв«гваѕВЮ┤ВЁў ЖИ░віЦВЮё ВаюЖ│х Ваё Ж░ђВЃЂьЎћ (Full Virtualization)
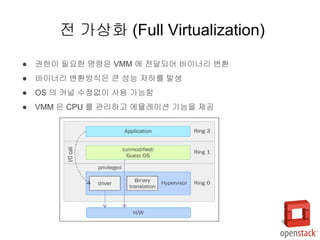
- 12. РЌЈ Guest OS вДЂ 0 ВЌљ ВаЉЖи╝ ьЋўЖИ░ ВюёьЋ┤ Вџ┤ВўЂВ▓┤ВаюЖ░ђ ВѕўВаЋвљўВќ┤ВЋ╝ ьЋе РЌЈ Guest OSвіћ ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ/VMM ВѓгВЮ┤ВЌљ ьЋўВЮ┤ьЇ╝Вйю(Hypercall) ьўИВХю ВІцьќЅ РЌЈ ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађвіћ APIвЦ╝ ВаюЖ│х РЌЈ ЖХїьЋюВЮ┤ ьЋёВџћьЋю вфЁва╣ВЮђ API вЦ╝ ьєхьЋ┤ ВІцьќЅ вљўВќ┤ вДЂ 0 ВЌљВёю ВІцьќЅвље в░ў Ж░ђВЃЂьЎћ (Para Virtualization)
- 13. РЌЈ Guest OSвіћ ВъљВІаВЮў VM ВЮ┤ Ж░ђВЃЂьЎћ вљўВЌѕВЮїВЮё ВЮИВДђьЋўЖ│а ВъѕВЮї РЌЈ ЖХїьЋюВЮ┤ ьЋёВџћьЋю вфЁва╣ВЮђ VMM ВЌљ ВаёвІгвљўЖИ░ ВюёьЋ┤ ьЋўВЮ┤ьЇ╝Вйю ьўИВХю РЌЈ Guest OS В╗цвёљВЮђ ьЋўВЮ┤ьЇ╝ВйюВЮё ьєхьЋ┤ VMM Ж│╝ ВДЂВаЉ ьєхВІа Ж░ђвіЦ РЌЈ в░ћВЮ┤вёѕвдг в│ђьЎўВЮ┤ ьЋёВџћьЋю ВаёЖ░ђВЃЂьЎћВЎђ в╣ёЖхљьЋ┤ ьЂ░ Вё▒віЦ ьќЦВЃЂ РЌЈ в░ўЖ░ђВЃЂьЎћ ВЮИВДђ Ж░ђвіЦьЋю ьі╣ВѕўьЋю Guest OS В╗цвёљВЮ┤ ьЋёВџћ в░ў Ж░ђВЃЂьЎћ (Para Virtualization)
- 15. РЌЈ Intel Ж│╝ AMD віћ Ж░ђВЃЂьЎћЖ░ђ x86 ВЋёьѓцьЁЇВ▓ўВЮў ВцЉВџћ Ж│╝ВаювАю ВЮИВІЮ РЌЈ ьћёвАюВёИВіц ьЎЋВъЦВЮё ьєхьЋю вЈЁвдйВаЂВЮИ Ж░ђВЃЂьЎћ ВДђВЏљ ЖИ░віЦ Ж░юв░ю РЌІ Intel : Intel VT-x РЌІ AMD : AMD-V РЌІ Itanium : VT-i РЌЈ IA-32 вфЁва╣Вќ┤вЦ╝ ьЎЋВъЦ РЌІ Intel : VT(Virtualization Techonology) РЌІ AMD : SVM(Secure Virutal Machine) РЌЈ ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађВЎђ VMM ВЮ┤ Guest OSвЦ╝ Ring 0 ВЌљВёю ВІцьќЅ Ж░ђвіЦьЋўвЈёвАЮ ВДђВЏљ РЌЈ VM ВЮё вДЂ 0 ВЌљВёю ВІцьќЅ Ж░ђвіЦ ьЋа Вѕў ВъѕвЈёвАЮ, ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ ВЎђ VMM ВЮё вДЂ - 1 ВЌљВёю ВІцьќЅьЋе РЌЈ ЖИ░ВА┤ ВаёЖ░ђВЃЂьЎћ ЖИ░Вѕав│┤вІц Вё▒віЦВЮ┤ ьќЦВЃЂвље ьЋўвЊюВЏеВќ┤ Ж░ђВЃЂьЎћ ВДђВЏљЖИ░віЦ
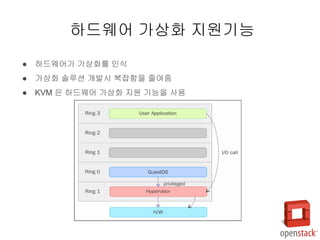
- 16. РЌЈ ьЋўвЊюВЏеВќ┤Ж░ђ Ж░ђВЃЂьЎћвЦ╝ ВЮИВІЮ РЌЈ Ж░ђВЃЂьЎћ ВєћвБеВЁў Ж░юв░юВІю в│хВъАьЋеВЮё ВцёВЌгВцї РЌЈ KVM ВЮђ ьЋўвЊюВЏеВќ┤ Ж░ђВЃЂьЎћ ВДђВЏљ ЖИ░віЦВЮё ВѓгВџЕ ьЋўвЊюВЏеВќ┤ Ж░ђВЃЂьЎћ ВДђВЏљЖИ░віЦ
- 17. РЌЈ ьЋўВЮ┤ьЇ╝ в░ћВЮ┤Вађ/Ж░ђВЃЂВёюв▓ё вфевІѕьё░(VMM) РЌІ VM , Guest OS вЦ╝ Ж┤ђвдгьЋўвіћ ВєїьћёьіИ ВЏеВќ┤ РЌЈ Ж░ђВЃЂьЎћ ВъЉВЌЁ Ж┤ђвдг РЌІ Ж░ђВЃЂ ьЋўвЊюВЏеВќ┤ ВаюЖ│х РЌІ VM ВЃЮвфЁВБ╝ЖИ░, ВІцВІюЖ░ё вдгВєїВіц ьЋавІ╣, Ж░ђВЃЂвеИВІа ВаЋВ▒ЁЖ┤ђвдг РЌЈ Ж░ђВЃЂВёюв▓ё вфевІѕьё░ (VMM) РЌІ Guest OS ВЮў ВъљВЏљ ьЋавІ╣ ВџћВ▓ГВЮё вІ┤вІ╣ РЌІ ьћёвАюВёИВіц, вЕћвфевдгвЊ▒ ВІюВіцьЁю ьЋўвЊюВЏеВќ┤ ьЎўЖ▓й ВёцВаЋВЌљ ВЮўьЋ┤ ВъљВЏљ ьЋавІ╣вље ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ/Ж░ђВЃЂВёюв▓ё вфевІѕьё░(VMM)
- 18. РЌЈ ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађвіћ ВА┤Въг ВюёВ╣ўВЌљ вћ░вЮ╝ ЖиИ вХёвЦўЖ░ђ вІгвЮ╝ВДёвІц. РЌІ Type1 : ьЋўвЊюВЏеВќ┤ ВюёВЌљВёю ВДЂВаЉ ВІцьќЅ РЌІ Type2 : Вџ┤ВўЂВ▓┤ВаюЖ░ђ ВъѕЖ│а, ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађЖ░ђ вХёвдгвљю ВИхВЌљ ВІцьќЅ РЌЈ Type1 ьЋўВЮ┤ьЇ╝ в░ћВЮ┤Вађ РЌІ ВІюВіцьЁю ьЋўвЊюВЏеВќ┤ВЎђ ВДЂВаЉ ВЃЂьўИВъЉВџЕ РЌІ Вџ┤ВўЂВ▓┤ВаюЖ░ђ ьЋёВџћьЋўВДђ ВЋіВЮї РЌІ в▓аВќ┤вЕћьЃѕ, Въёв▓авћћвЊю, вёцВЮ┤ьІ░вИї ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађвЮ╝Ж│а ьЋе РЌЈ Type2 ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ РЌІ Вџ┤ВўЂВ▓┤Ваю ВюёВЌљ ВА┤Въг РЌІ вІцВќЉьЋю в│ђЖ▓йВЮ┤ Ж░ђвіЦьЋўвІц РЌІ Hosted ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ Type1 , Type2 ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ
- 19. Type1 , Type2 ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ РЌЈ ВёцВ╣ўВЎђ ВёцВаЋВЮ┤ ВЅйвІц РЌЈ ВѓгВЮ┤ВдѕЖ░ђ ВъЉЖ│а ВъљВЏљВѓгВџЕ ВхюВаЂьЎћ РЌЈ вХђьЋўЖ░ђ ВъЉЖ│а ВёцВ╣ў ВЋаьћївдгВ╝ђВЮ┤ВЁўВЮ┤ ВъЉвІц РЌЈ в│ёвЈёВЮў ьћёвАюЖиИвъе в░Ј вЊювЮ╝ВЮ┤в▓ё ВёцВ╣ўЖ░ђ вХѕЖ░ђвіЦ Type1 Type2 РЌЈ ьўИВіцьіИ Вџ┤ВўЂВ▓┤ВаюВЌљ ВбЁВєЇВаЂВЮ┤вІц. РЌЈ Ж┤Љв▓ћВюёьЋю ьЋўвЊюВЏеВќ┤ ВДђВЏљВЮ┤ Ж░ђвіЦьЋўвІц
- 20. ВўцьћѕВєїВіц Ж░ђВЃЂьЎћ ьћёвАюВаЮьіИ Project Virtualization Type Project URL KVM (Kernel-based Virtual Machine) Full virtualization http://www.linux-kvm.org/ VirtualBox Full virtualization https://www.virtualbox.org/ Xen Full and paravirtualization http://www.xenproject.org/ Lguest Paravirtualization http://lguest.ozlabs.org/ UML (User Mode Linux) http://user-mode-linux. sourceforge.net/ Linux-VServer http://www.linux-vserver.org/ Welcome_to_Linux-VServer.org
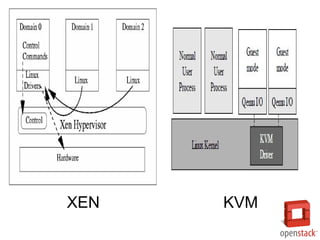
- 21. XEN KVM
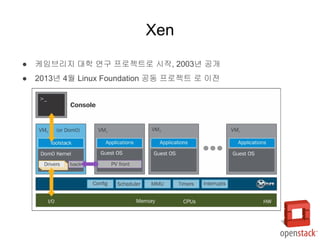
- 22. РЌЈ В╝ђВъёвИївдгВДђ вїђьЋЎ ВЌ░Жхг ьћёвАюВаЮьіИвАю ВІюВъЉ, 2003вЁё Ж│хЖ░ю РЌЈ 2013вЁё 4ВЏћ Linux Foundation Ж│хвЈЎ ьћёвАюВаЮьіИ вАю ВЮ┤Ваё Xen
- 23. РЌЈ в░ўЖ░ђВЃЂьЎћ, ВаёЖ░ђВЃЂьЎћ, ьЋўвЊюВЏеВќ┤ВДђВЏљ вфевЊю ВѓгВџЕ Ж░ђвіЦ РЌЈ Guest VM ВЮё вЈёвЕћВЮИ ВЮ┤вЮ╝Ж│а вХђвЦИвІц. РЌЈ Xen ВЌљвіћ вЉљ ВбЁвЦўВЮў вЈёвЕћВЮИВЮ┤ ВА┤Въг РЌІ Dom 0 : ьі╣ЖХїВЮ┤ Въѕвіћ вЈёвЕћВЮИ, ЖИ░віЦВЮ┤ ьЎЋВъЦвљю ьі╣Вѕў Guest VM РЌІ Dom U : ЖХїьЋюВЮ┤ ВЌєвіћ вЈёвЕћВЮИ, ВЮ╝в░ў Guest VM РЌЈ Dom 0 РЌІ VMВЮё вДївЊцЖ│а, ВѓГВаюьЋўЖ│а, Ж┤ђвдг в░Ј ВёцВаЋЖ░ђвіЦ РЌІ ВЮ╝в░ў Guest ВІюВіцьЁюВЮ┤ Ж░ђВЃЂьЎћ вЊювЮ╝ВЮ┤в▓ёвЦ╝ ьєхьЋ┤ ьЋўвЊюВЏеВќ┤ВЌљ ВДЂВаЉ ВаЉЖи╝ Ж░ђвіЦьЋўвЈёвАЮ ВДђВЏљ РЌІ API ВЮИьё░ьјўВЮ┤ВіцвЦ╝ ьєхьЋю ВІюВіцьЁю Ж┤ђвдгЖИ░віЦ ВаюЖ│х РЌІ ВІюВіцьЁюВЌљВёю В▓Фв▓ѕВДИвАю ВІюВъЉвљўвіћ вЈёвЕћВЮИ РЌІ Xen ьћёвАюВаЮьіИ ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађвЦ╝ ВюёьЋю ьЋёВѕў вЈёвЕћВЮИ Xen
- 24. РЌЈ KVM (Kernel-based Virtual Machine) РЌЈ ьЋўвЊюВЏеВќ┤ Ж░ђВЃЂьЎћ ВДђВЏљЖИ░віЦ (VT-x, AMD-V) вЦ╝ ьЎхМџЕьЋю ВхюВІа ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ РЌЈ KVMВЮђ KVM В╗цвёљвфевЊѕ ВёцВ╣ўвАю ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађвАю в│ђьЎўЖ░ђвіЦ РЌІ вдгвѕЁВіц ьЉюВцђ В╗цвёљВЌљ KVM В╗цвёљ вфевЊѕВЮё ВХћЖ░ђ РЌІ ьЉюВцђ В╗цвёљВЮў вЕћвфевдг ВДђВЏљ, ВіцВ╝ђВцёвЪг вЊ▒ВЮё ВѓгВџЕЖ░ђвіЦьЋю ВъЦВаљВЮ┤ ВъѕВЮї РЌІ вдгвѕЁВіц В╗┤ьЈгвёїьіИ ВхюВаЂьЎћвіћ ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађВЎђ вдгвѕЁВіц Guest OS вЉўвІц ВЮ┤ВаљВЮё Ж░ќВЮї РЌЈ I/O ВЌљв«гваѕВЮ┤ВЁўВЮё ВюёьЋ┤ QEMU вЦ╝ ВѓгВџЕ РЌІ QEMUвіћ ьЋўвЊюВЏеВќ┤ ВЌљв«гваѕВЮ┤ВЁўВЮё ВДђВЏљьЋўвіћ ВѓгВџЕВъљ ВўЂВЌГ ьћёвАюЖиИвъе РЌІ ьћёвАюВёИВіц, вћћВіцьЂг, вёцьіИВЏїьЂг, VGA, PCI, USB, Serial/Parallel ьЈгьіИ ВЌљв«гваѕВЮ┤ВЁў KVM
- 25. вдгвѕЁВіцвіћ ьЂ┤вЮ╝Вџ░вЊю ЖИ░в░ўВЮў ВєћвБеВЁў Ж░юв░юВЮё ВюёьЋ┤ В▓Фв▓ѕВДИвАю ВёаьЃЮвљўВќ┤ ВЎћвІц РЌЈ ВЋёвДѕВА┤ EC2 ьЂ┤вЮ╝Вџ░вЊювіћ Xen Ж░ђВЃЂьЎћвЦ╝ ВѓгВџЕ РЌЈ вћћВДђьЃѕВўцВЁў KVM ВѓгВџЕ вдгвѕЁВіц Ж░ђВЃЂьЎћвЦ╝ ВѓгВџЕьЋю ВўцьћѕВєїВіц IaaS ьЂ┤вЮ╝Вџ░вЊю ВєїьћёьіИВЏеВќ┤ РЌЈ ВўцьћѕВіцьЃЮ РЌІ Openstack Foundation ВЌљ ВЮўьЋ┤ Ж┤ђвдгвљўвіћ ВўцьћѕВєїВіц IaaS ьЂ┤вЮ╝Вџ░вЊю ВєћвБеВЁў РЌІ вфЄЖ░юВЮў ВўцьћѕВєїВіц ьћёвАюВаЮьіИ В╗┤ьЈгвёїьіИвАю ЖхгВё▒ РЌІ KVM ВЮё ЖИ░в│И ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађвАю ВѓгВџЕ РЌЈ ьЂ┤вЮ╝Вџ░вЊюВіцьЃЮ РЌІ Apache Software Foundation ВЌљ ВЮўьЋ┤ Ж┤ђвдгвљўвіћ IaaS ьЂ┤вЮ╝Вџ░вЊю ВєћвБеВЁў РЌІ ВЋёвДѕВА┤ EC2/S3 API ВЎђ ьўИьЎўВё▒ РЌІ Xen ВЮё ЖИ░в│И ьЋўВЮ┤ьЇ╝в░ћВЮ┤ВађвАю ВѓгВџЕ РЌЈ ВюаВ╣╝вдйьѕгВіц РЌІ AWS ВЎђ ьўИьЎўВё▒ВЮё Ж░ђВДё ьћёвЮ╝ВЮ┤в╣Ќ ьЂ┤вЮ╝Вџ░вЊю ВєїьћёьіИВЏеВќ┤ РЌІ Xen, KVM вфевЉљ ВДђВЏљ ьЂ┤вЮ╝Вџ░вЊюВЌљВёю вдгвѕЁВіц Ж░ђВЃЂьЎћЖ░ђ ВаюЖ│хьЋўвіћЖ▓Ѓ
- 26. OpenStack VM
- 28. ВўцьћѕВіцьЃЮВЮў ЖИ░в│И ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ KVM(Kernel Based Virtual Machine) TYPE1(native or bare-metal)ВЌљ ьЋ┤вІ╣ьЋўвіћ ьЋўВЮ┤ьЇ╝в░ћВЮ┤Вађ вЕћвфевдг Ж┤ђвдгВъљвіћ ьїїВЮ╝ ВІюВіцьЁю вЊ▒Ж│╝ Ж░ЎВЮђ В╗цвёљВЮў ВёювИї вфевЊѕвАю ВиеЖИЅвљўвЕ░, KVMВЮё ВѓгВџЕьЋўЖИ░ ВюёьЋ┤Вёювіћ CPUВЌљВёю HVM(Hardware Virtual Machine) ЖИ░віЦВЮё ВаюЖ│хьЋ┤ВЋ╝ ьЋЕвІѕвІц. HVMВЮё ВаюЖ│хьЋўвіћ CPUвАювіћ x86 ВЋёьѓцьЁЇВ▓ўВЮў Intel VT-xВЎђ AMDВЮў AMD-vЖ░ђ ВъѕВіхвІѕвІц.
- 30. Ж░ђВЃЂвеИВІа ВаёЖ░ђВЃЂьЎћ(Full Virtualization)ВЮў віљвд░ ВєЇвЈёвЦ╝ Ж░юВёаьЋўЖИ░ ВюёьЋ┤ в░ўЖ░ђВЃЂьЎћ(Paravirtualization) в░ЕВІЮВЮ┤ Ж░юв░ювљўВЌѕЖ│а, ьўёВъг вёљвдг ВЊ░ВЮ┤Ж│а ВъѕВіхвІѕвІц.
- 31. Ж░ђВЃЂвеИВІаВЮў ьЋюЖ│ё Ж░ђВЃЂ веИВІа ВъљВ▓┤віћ ВЎёВаёьЋю В╗┤ьЊеьё░вЮ╝ ьЋГВЃЂ Ж▓їВіцьіИ OSвЦ╝ ВёцВ╣ўьЋ┤ВЋ╝ ьЋЕвІѕвІц. ЖиИвъўВёю ВЮ┤в»ИВДђ ВЋѕВЌљ OSЖ░ђ ьЈгьЋевљўЖИ░ вЋївгИВЌљ ВЮ┤в»ИВДђ ВџЕвЪЅВЮ┤ В╗цВДЉвІѕвІц. вёцьіИВЏїьЂгВЎђ ВЮИьё░вёи ВєЇвЈёЖ░ђ в╣евЮ╝ВАївІц ьЋўвЇћвЮ╝вЈё Ж░ђВЃЂьЎћ ВЮ┤в»ИВДђвЦ╝ ВБ╝Ж│ав░Џвіћ Ж▓ЃВЮђ Жйц вХђвІ┤ВіцвЪйВіхвІѕвІц. ьі╣ьъѕ Вўцьћѕ ВєїВіц Ж░ђВЃЂьЎћ ВєїьћёьіИВЏеВќ┤віћ OSвЦ╝ Ж░ђВЃЂьЎћьЋўвіћ Ж▓ЃВЌљвДї В┤ѕВаљВЮ┤ вДъВХ░ВаИ ВъѕВіхвІѕвІц. ЖиИвъўВёю ВЮ┤в»ИВДђвЦ╝ ВЃЮВё▒ьЋўЖ│а ВІцьќЅьЋўвіћ ЖИ░віЦвДї ВъѕВЮё в┐љ в░░ьЈгВЎђ Ж┤ђвдг ЖИ░віЦВЮ┤ вХђВА▒
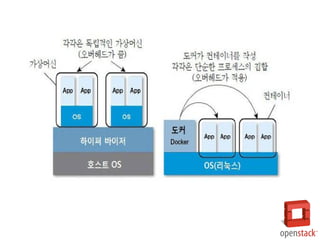
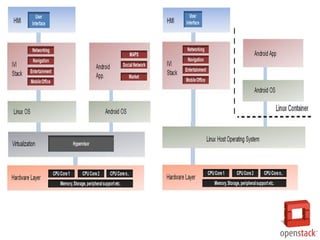
- 32. Dockerвъђ? Dockerвіћ в░ўЖ░ђВЃЂьЎћв│┤вІц ВбђвЇћ Ж▓йвЪЅьЎћвљю в░ЕВІЮВъЁвІѕвІц. ЖиИвд╝ 1-6ВЎђ Ж░ЎВЮ┤ Ж▓їВіцьіИ OSвЦ╝ ВёцВ╣ўьЋўВДђ ВЋіВіхвІѕвІц. Docker ВЮ┤в»ИВДђВЌљ Вёюв▓ё Вџ┤ВўЂВЮё ВюёьЋю ьћёвАюЖиИвъеЖ│╝ вЮ╝ВЮ┤вИївЪгвдгвДї Ж▓ЕвдгьЋ┤Вёю ВёцВ╣ўьЋа Вѕў ВъѕЖ│а, OS ВъљВЏљ(ВІюВіцьЁю Вйю)ВЮђ ьўИВіцьіИВЎђ Ж│хВюаьЋЕвІѕвІц. ВЮ┤ваЄЖ▓ї вљўвЕ┤Вёю ВЮ┤в»ИВДђ ВџЕвЪЅВЮ┤ ьЂгЖ▓ї ВцёВќ┤вЊцВЌѕВіхвІѕвІц. Dockerвіћ ьЋўвЊюВЏеВќ┤вЦ╝ Ж░ђВЃЂьЎћьЋўвіћ Ж│ёВИхВЮ┤ ВЌєЖИ░ вЋївгИВЌљ вЕћвфевдг ВаЉЖи╝, ьїїВЮ╝ВІюВіцьЁю, вёцьіИВЏїьЂг ВєЇвЈёЖ░ђ Ж░ђВЃЂ веИВІаВЌљ в╣ёьЋ┤ ВЏћвЊ▒ьъѕ в╣авдЁвІѕвІц.
- 33. Dockerвіћ Ж░ђВЃЂ веИВІаЖ│╝віћ вІгвдг ВЮ┤в»ИВДђ ВЃЮВё▒Ж│╝ в░░ьЈгВЌљ ьі╣ьЎћвљю ЖИ░віЦВЮё ВаюЖ│хьЋЕвІѕвІц. GitВЌљВёю ВєїВіцвЦ╝ Ж┤ђвдгьЋўвіћ Ж▓ЃВ▓ўвЪ╝ ВЮ┤в»ИВДђ в▓ёВаё Ж┤ђвдг ЖИ░віЦВЮё ВаюЖ│хьЋЕвІѕвІц. вўљьЋю, ВцЉВЋЎ Ж┤ђвдгвЦ╝ ВюёьЋ┤ ВађВъЦВєїВЌљ ВЮ┤в»ИВДђвЦ╝ ВўгвдгЖ│а, в░ЏВЮё ВѕўВъѕВіхвІѕвІц(Push/Pull). ЖиИвдгЖ│а GitHubВ▓ўвЪ╝ Docker ВЮ┤в»ИВДђвЦ╝ Ж│хВюаьЋа Вѕў Въѕвіћ Docker HubвЈё ВаюЖ│х ьЋЕвІѕвІц(GitHubВ▓ўвЪ╝ ВюавБї Ж░юВЮИ ВађВъЦВєївЈё ВаюЖ│хьЋЕвІѕвІц). вІцВќЉьЋю APIвЦ╝ ВаюЖ│хьЋўЖИ░ вЋївгИВЌљ ВЏљьЋўвіћ вДїьЂ╝ ВъљвЈЎьЎћвЦ╝ ьЋа Вѕў ВъѕВќ┤ Ж░юв░юЖ│╝ Вёюв▓ё Вџ┤ВўЂВЌљ вДцВџ░ ВюаВџЕьЋЕвІѕвІц. DockerВЮў ВъЦВаљ
- 39. ВЌћв╣ёвћћВЋёВЮў В░евЪЅВџЕ ВіѕьЇ╝В╗┤ьЊеьё░ РђўвЊювЮ╝ВЮ┤вИї PX2РђЎвіћ ВъљВюеВБ╝ьќЅВ░еВџЕВю╝вАю Ж░юв░юьЋю РђўьїїВ╗ц(Parker)РђЎ ьћёвАюВёИВёюВЎђ РђўьїїВіцВ╣╝РђЎ ВЋёьѓцьЁЇВ▓ў ЖИ░в░ў GPUЖ░ђ Ж░ЂЖ░Ђ 2Ж░юВћЕ вЊцВќ┤Ж░ё вІеВЮ╝ SoC(ВІюВіцьЁю Вўе В╣Е)вЦ╝ ьЃЉВъгьЋ┤ ВЋй 8TFlopsВЮў ВЌ░Вѓ░віЦваЦВЮё Ж░ќВиёвІц. ВЮ┤вЦ╝ ьєхьЋ┤ Рќ▓В░евЪЅ ВюёВ╣ў ьїїВЋЁ Рќ▓ВЋѕВаёьЋю Вџ┤ьќЅЖХцвЈё ВИАВаЋ Рќ▓360вЈё ВБ╝в│ђ ВЃЂьЎЕ ВЮИВІЮ вЊ▒ВЮё ВѕўьќЅьЋўвЕ┤Вёю В┤ѕвІ╣ ВЋй 24ВА░ ьџїВЮў вћЦвЪгвІЮ ВъЉВЌЁ ВєЇвЈёвЦ╝ ЖхгьўёьЋювІц. ВЌгЖИ░ВЌљ ВБ╝в│ђ ьЎўЖ▓йВЮё в│┤вІц ьЈГвёЊЖ▓ї ВЮ┤ьЋ┤ьЋўЖИ░ ВюёьЋ┤ 12Ж░юВЮў в╣ёвћћВўцВ╣┤вЕћвЮ╝вЦ╝ в╣ёвА»ьЋ┤ ваѕВЮ┤вЇћ, В┤ѕВЮїьїї Вё╝Вёю вЊ▒ вІцВќЉьЋю Ж▓йвАюВЌљВёю ВѕўВДЉвљўвіћ ВаЋв│┤вЊцВЮё Ж▓░ьЋЕьЋўвіћ РђўВё╝Вёю ВюхьЋЕРђЎ ЖИ░ВѕавЈё ьЎхМџЕьЋювІц. ВхюВІа ьЁїВігвЮ╝ вфевЇИS(Tesla Model S)Ж░ђ ВаёВІювљљВіхвІѕвІц. ВЮ┤ вфевЇИВЮђ DRIVE PX 2Ж░ђ ВъЦВ░Е вљю ВхюВ┤ѕВЮў ВІювдгВдѕ В░евЪЅВю╝вАю, DRIVE PX 2віћ ьќЦьЏё ВєїьћёьіИВЏеВќ┤ ВЌЁвЇ░ВЮ┤ьіИвЦ╝ ьєхьЋ┤ ВЎёВаёьЋю ВъљВюеВё▒ВЮё ВаюЖ│хьЋа ВўцьєаьїїВЮ╝вЪ┐(AutoPilot) ВІюВіцьЁюВЮў ЖИ░в░ўВЮё ВаюЖ│х Automation Car
- 40. Automation Car
- 45. 1> Mastering KVM Virtualization 2> https://github.com/tylee33/brat-docker 3> https://github.com/TensorMSA/tensormsa_syntax_docker В░ИЖ│авгИьЌї