















翱辫迟颈尘颈锄别谤入门&最新动向
- 2. Optimizerとは ? Optimization(最適化)する者 ? 機械学習の?脈では、損失関数の値をできるだけ?さくするパラメータの 値を?つけることを最適化(Optimization) といい、その?法を指して Optimizerと呼ぶ。 ? 関数の最?化と?うと、ラグランジュの未定乗数法、ニュートン法、共役 勾配法など?々あるが、機械学習タスクに使われているOptimizerは主に 計算量的な観点から1階微分の勾配降下法がベースとなる。
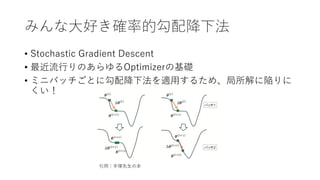
- 3. みんな?好き確率的勾配降下法 ? Stochastic Gradient Descent ? 最近流?りのあらゆるOptimizerの基礎 ? ミニバッチごとに勾配降下法を適?するため、局所解に陥りに くい! 引?:?塚先?の本
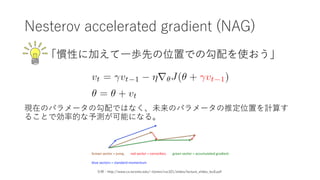
- 6. Nesterov accelerated gradient (NAG) 「慣性に加えて?歩先の位置での勾配を使おう」 現在のパラメータの勾配ではなく、未来のパラメータの推定位置を計算す ることで効率的な予測が可能になる。 引?:http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
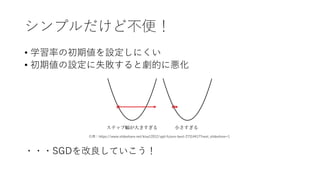
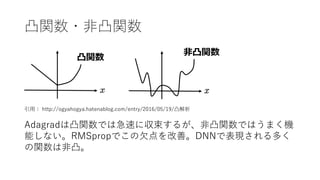
- 8. Adagrad(Adaptive Gradient) <?点> ? エポックを重ねるごとに過去の学習率が累積していき、やがて0に漸近してしまう ? 学習の初期に勾配の?きな場所を通ると、それ以降その軸?向の勾配は?さいまま になってしまう
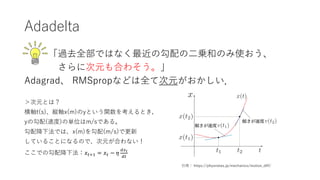
- 11. Adadelta 「過去全部ではなく最近の勾配の?乗和のみ使おう、 さらに次元も合わそう。」 Adagrad、 RMSpropなどは全て次元がおかしい. >次元とは? 横軸t(s)、縦軸x(m)のyという関数を考えるとき, yの勾配(速度)の単位はm/sである。 勾配降下法では、x(m)を勾配(m/s)で更新 していることになるので、次元が合わない! ここでの勾配降下法:?"#$ = ?" ? ? ()* (" 引?: https://physnotes.jp/mechanics/motion_diff/
- 14. 結局どれが良いの?? ? 今のところ、?間が経験的に「このタスクにはこのOptimizer を使う」のような決め?をしている ? ??データが疎な場合、適応学習率法のどれかを使うと良い ? Adamが最強というわけではない むしろタスクによってはSGDの?がより良い性能を?せることもある…! 最近の流れの1つ:Adamを改良しよう!
- 15. Weight decay ? DNNにおいて、多層になるほどモデルの表現?は増すが、その 分オーバーフィッティングの危険性も?まる ? そこでパラメータの?由度を制限するWeight decayが?いられ る ? 重みの?由度を制限するという意味で、これはL2正則化と同じ 効果を得ると理解できる
- 16. Adam with Weight decay 新しい更新式 ?さなデータセットやCIFAR-10のデータセットではAdam with Weight decayの?が通常のAdamよりもパフォーマンスが向上.
- 17. Fixing the exponential moving average ? 指数移動平均(EMA)とは、指数関数的に減衰する重み付き平 均のことで、Adamのような適応学習率法の基本的な考え? ? Adamで最適解を狙う場合、?部のミニバッチでは有益な勾配 が得られるが、そのようなミニバッチは稀にしか現れない →そこでパラメータ更新時に?乗勾配に関してはEMAではなく、過去の ?乗勾配の最?値を?いるAMSgradという?法が提案された。
- 18. Learning rate annealing schedule ? 学習率アニーリング ? annealing:焼きなまし ? ?旦?きくなりすぎた学習率をもう?度?さくするイメージ ? つまり、勾配降下法における損失関数の下がり?を調整してい る 興味深い?例:Adam+以下の学習率アニーリングによって機械翻訳タスクに成功
- 19. Warm Restarts ? cosineなどを?いた周期的な学習率アニーリング ? 通常の学習率アニーリングよりも2~4倍のエポックが必要とな るが、同等以上のパフォーマンスを達成する。 Restart後の?い学習率によって、前に収束 した最?値から損失関数の異なる領域へと 抜け出せるようになる。 引?:http://ruder.io/deep-learning-optimization-2017/index.html#fnref:22
- 20. 課題と今後の?針 ? 今のところタスクによって最適なOptimizerは異なる ? ?間が経験的にこれ!ってやつを使っている ? Adamのような複雑な最適化よりも、シンプルで軽いSGDが使われることも少なくない ? 最適化理論(局所解の性質、最適化の簡単さ etc...) ? 損失関数の形?体が分かれば、勾配が消失するor爆発するタイミングが分かって、?幅 な改善につながるのでは ? また、損失関数の構造が分かればどのタスクにどのOptimizerが効くかが分かる? ? 近似理論(表現?解析、層とノードの関係 etc...) ? 2階微分まで盛り込んでいるニュートン法(計算量がとてつもなく?きいが収束が早い) と1階微分の通常の勾配降下法を交互に組み合わせる?法は??そう ? Adadeltaで議論されている次元おかしい問題の突き詰め
- 21. 参考?献 ? Sebastian Ruder. “An overview of gradient descent optimization algorithms”. http://ruder.io/optimizing-gradient-descent/. ? Sebastian Ruder. “Optimization for Deep Learning Highlights in 2017”. http://ruder.io/deep-learning-optimization- 2017/index.html. ? Ian Goodfellow and Yoshua Bengio and Aaron Courville. “Deep Learning”. http://www.deeplearningbook.org. ? Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems. ? Loshchilov, I., & Hutter, F. (2017). SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of ICLR 2017. ? Loshchilov, I., & Hutter, F. (2017). Fixing Weight Decay Regularization in Adam. arXiv Preprint arXi1711.05101. Retrieved from http://arxiv.org/abs/1711.05101 ? Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method. Retrieved from http://arxiv.org/abs/1212.5701 ? Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1?13. ? Masaaki Imaizumi. “深層学習による?滑らかな関数の推定”. 狠狠撸Share. /masaakiimaizumi1/ss-87969960. ? nishio.”勾配降下法の最適化アルゴリズム”. 狠狠撸Share. /nishio/ss-66840545