




















































More Related Content
Similar to pelatihan eviews dan ragam analisis data (20)
Recently uploaded (20)


















pelatihan eviews dan ragam analisis data
- 1. ANALISIS STATISTIK PENDEKATAN E V I E W S I K A S W A S T I P U T R I , S E , M . A k
- 2. OVERVIEW 1.Pengenalan statistika dasar 2.Skala pengukuran 3.Pengenalan Program Eviews 4.Praktik Tabulasi Data Eviews 5.Uji Asumsi Klasik Padaa Eviews 6.Penanganan Data Tidak Normal 7.Uji Regresi Linier sederhana 8.Uji Regresi Linier Berganda Konsep dasar Analisis Regresi Data Panel 9. 10.Tahapan Regresi data Panel Metode Estimasi Model Regresi Data Panel Pada Eviews 11. Pemilihan Model Regresi Data Panel Pada Eviews 12. Analisis Regresi Data Panel pada Eviews 13.
- 3. Statistika adalah suatu kumpulan angka yang tersusun lebih dari satu angka Statistika adalahh kumpulanmetode yag digunakan untuk merencsnakan eskperimen, mengambil data, dan kmudian menyusun , meringkas, menyajikan, menganalisis, meginterpretasikan dan mengambil simpulan yang didsarkan padda data tersebut.
- 4. NOMINAL Sifatnya hanya untuk membedakan antar kelompok. Artinya data hanya dibedakan berdasarkan kategori. Jika suatu pengukuran data hanya menghasilkan satu dan hanya satu-satunya kategori, maka data tersebut adalah data nominal, contoh : Pagawai negeri, pegawai swasta. data ordinal, adalah data dengan urutan lebih tinggi dan urutan lebih rendah, contoh : panjang, kurang panjang, pendek Ciri data ordinal yaitu posisi data tidak setara. Skala yang sering dipakai dalam penyusunan kuisioner adalah skala ordinal atau sering disebut skala likert. Data interval selain urutannya bisa bertingkat, urutan tersebut bisa juga dikuantitatifkan. Data berskala interval yang diperoleh dengan cara pengukuran, dimana jarak dua titik pada skala sudah diketahui. Hal ini berbeda dengan skala ordinal, dimana jarak antara dua titik tidak diperhatikan (seperti berapa jarak antara puas dengan tidak puas, yang sebenarnya menyangkut perasaan seseorang saja), contoh : nilai ujian, temperatur suatu ruangan. SKALA PENGUKURAN Data rasio adalah data yang bersifat angka dalam arti yang sesungguhnya dan bisa dioperasikan secara matematika (+, -, :, x) . Data yang berskala rasio adalah data yang diperoleh dengan cara pengukuran, dimana jarak dua titik pada skala sudah diketahui, dan mempunyai titik nol yang absolut. Hal ini berbeda dengan skala interval, dimana tidak ada titik nol mutlak, seperti titik derajat celcius tentu berbeda dengan titik derajat farehit. ORDINAL INTERVAL RASIO
- 5. Dalam analisis regresi terdapat beberapa asumsi yang harus dipenuhi sehingga persamaan regresi yang dihasilkan akan valid jika digunakan untuk memprediksi suatu masalah. Model regresi dapat disebut sebagai model yang baik jika model tersebut memenuhi kriteria BLUE (Best Linear Unbiased Estimator).
- 6. Uji Normalitas Uji normalitas data merupakan uji distribusi data yang akan di analisis. Apabila data tidak berdistribusi normal maka tidak dapat menggunakan analisis parametrik, melainkan menggunakan analisis non parametrik Uji normalitas bertujuan untuk menguji apakah dalam model regresi, variabel pengganggu atau residual memiliki distribusi normal. Ada 4 perlakuan: 1.Menambah jumlah data Menghilangkan data penyebab tidak normal (dengan cara membuang outlier) 2. Dilakukan transformasi data, misal mengubah data ke bentuk logaritma atau natural atau bentuk lainnya, lalu diuji ulang (Imam Ghozali) 3. Terima apa adanya. Pilih alat analisis yang tepat, misalnya gunakan uji nonparametrik 4. Uji Asumsi Klasik Penanganan Data Tidak Normal Pilih quick -> estimate equation Langkah-Langkah Masukan label variable dengan format ŌĆ£variable dependen c variable independŌĆØ Klik view, Residual Diagnostic, lalu pilih histogram UNTUK MENENTUKAN APAKAH DATA TERSEBUT LULUS UJI NORMALITAS ATAU TIDAK DENGAN MELIHAT NILAI PROBABILITY. APABILA NILAI PROBABILITY > 0.05 MAKA DAPAT DIPASTIKAN BAHWA DATA TERSEBUT LULUS UJI NORMALITAS ATAU DENGAN KATA LAIN TELAH TERDISTRIBUSI DENGAN NORMAL
- 7. Uji Heteroskedastisitas Uji heteroskedastisitas bertujuan untuk menguji apakah dalam model regresi linear terjadi ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain. Model regresi yang baik adalah yang homoskedastisitas atau tidak terjadi heteroskedastisitas. Jika menggunakan Eviews, Metode white dapat menjadi alternatif untuk mendekteksi heteroskedastisitas. Jika adavariabel yang mengalami heterokedastisitas, dapat dilakukan transformasi data, seperti mengubah data menjadi bentuk logaritma, natural (Ln) atau yang lainnya (Imam Gozali dan Singgih santoso) SKALA PENGUKURAN Penanganan Masalah Uji Heterokesdatisitas Klik View, Residual Diagnostics, Heterokesdatisitas Test Langkah-Langkah Ada beberapa pilihan yang bisa diplih. Dalam tutorial kali ini pilih uji white untuk mendapatkan hasil heterokesdatisitas test. Setelah itu akan muncul output dari Heterokesdatisitas test. terdapat heterokesdatisitas. DARI HASIL HETEROKESDATISITAS TEST DENGAN MENGGUNAKAN METODE WHITE MAKA DIDAPATKAN PROB. CHI-SQUARE (S) ADALAH 0.33997>0.05. MAKA DAPAT DISIMPULKAN BAHWA TIDAK
- 8. Uji multikolinearitas bertujuan untuk menguji apakah model regresi ditemukan adanya korelasi antar variabel bebas (independent variable). Uji multikolinieritas berarti terjadi korelasi yang kuat (hampirsempurna) antarvariabel bebas. Tepatnya multikolinieritas berkenaan dengan terdapatnya lebih dari satu hubungan linier pasti, dan istilah kolinieritas berkenaan dengan terdapatnya satu hubungan linier. Metode untuk mendeteksi multikolinearitas antara lain variance influence factor dan korelasi berpasangan. Metode korelasi berpasangan untuk Mendeteksi multikolinearitas akan lebih Bermanfaat karena dengan menggunakan metode tersebut peneliti dapat mengetahui secara rinci variabel bebas apa saja yang memiliki korelasi yang kuat. SKALA PENGUKURAN Uji Multikoinieritas Cara mendeteksi ada atau tidaknya multikolinearitas: Multikolinearitas dapat juga dilihat dari nilai tolerance dan lawannya variace inflation factor (VIF). Nilai cutoff yg umumnya dipakai untuk menunjukkan adanya multikolinearitas adalah nilai tolerance Ōēż 0.10 atau sama dengan Ōēź 10. Dengan cara regresi parsial (bandingkan r square model utama dengan r square regresi variabel indepandent terhadap variabel independent lainnya, jika r square utama > r square baru, berarti tidak terdapat multikolonieritas) Langkah-Langkah Klik Quick, Group Statistics, Correlation Masukan Semua Variabel bebas DARI HASIL UJI MULTIKOLINIERITAS DIDAPATKAN HASILNYA ADALAH <0.7 MAKA DAPAT DISIMPULKAN BAHWA TIDAK TERJADI MASALAH MULTIKOLINEARITAS PADA VARIABEL PENELITIAN TERSEBUT.
- 9. SKALA PENGUKURAN Uji Autokorelasi Cara mengatasi masalah autokorelasi : Transformasi data Menambahvariabelpengganggu pada fungsi regresi yang menjelaskanasosiasi pada respon dariperiode 1 ke periode selanjutnya. Uji autokorelasi bertujuan untuk melihat apakah dalam model regresi linear ada korelasi antara kesalahan pengganggu pada periode t dengan kesalahan pengganggu pada periode t-1 (sebelumnya). Autokorelasi dilakukan untuk data time series, sedangkan untuk data cross section autokorelasi tidak perlu dilakukan (Rambat Lupiyoadi dan Ridho Bramulya Ikhsan), namun menurut imam ghozali model regresi yang baik adalah regresi yang bebas dari autokorelasi. Metode lagrange multiplier dapat menjadi alternatif untuk mendeteksi autokorelasi jika menggunakan eviews. Klik View, Residual Diagnostics, Serial Correlation Test Setelah itu akan muncul output dari Uji autokeralasi. Langkah-Langkah DARI HASIL AUTOKORELASI TEST DIDAPATKAN PROB. CHI-SQUARE (2) > 0.05 MAKA DAPAT DISIMPULKAN BAHWA TIDAK TERDAPAT MASALAH AUTOKORELASI.
- 10. Apa Itu Eviews? Item menu utama (main menu item) yang berisikan semua perintah program olah data EViews, yaitu FILE, EDIT, OBJECT, VIEW, PROCS, OPTIONS, WINDOWS dan HELP.
- 12. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis vulputate nulla at ante rhoncus, vel efficitur felis condimentum. Proin odio odio. Dalam regresi linear sederhana uji asumsi klasik harus terpenuhi kecuali uji multikolonieritas (tidak perlu dilakukan) Regresi sederhana = variabel independennya hanya 1 sedangkan regresi berganda jika variabel independent > 1 Uji F dilakukan untuk menguji kelayakan model, uji ini harus terpenuhi. Uji ini lebih tepat diterapkan pada regresi berganda Jika Uji F tidak terpenuhi artinya model yang kita buat salah (jadi dalam kerangka pemikiran tidak diperlukan dibuat uji simultan dan tidak perlu dibuat hipotesisnya, karena uji F harus terpenuhi).
- 13. ŌĆóMenilai Goodness of Fit Model Regresi Koefisien Determinasi Uji Signifikansi Simultan ( Uji Statistik F) Uji Signifikansi Parameter Individual (Uji Statistik t) REGRESI LINIER BERGANDA
- 14. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis vulputate nulla at ante rhoncus, vel efficitur felis condimentum. Proin odio odio. Dapat diukur dengan oleh R Square atau Adjusted R Square R Square digunakan jika variabel X nya 1 atau paling banyak 2 variabel Jika variabel X lebih dari 2, maka digunakan Adjusted R Square
- 15. U ji Parsial ( uji t ) Uji t dilakukan untuk melihat pengaruh suatu variabel independent terhadap Variable dependen. Dengan menggunakan hipotesis : Ho : tidak berpengaruh Ha : berpengaruh Jika nilai t hitung < t table, artinya Ho diterima Jika nilai t hitung > t table, artinya Ho ditolak Pilih quick -> estimate equation Masukan label variable dengan format ŌĆ£variable dependen c variable independŌĆØ sesuai dengan judul penelitian. Langkah-Langkah
- 16. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis vulputate nulla at ante rhoncus, vel efficitur felis condimentum. Proin odio odio. U ji Simul tan ( U J I F) Uji simultan dilakukan untuk melihat pengaruh variabel independent secara bersama-sama terhadap variabel independent. Apabila nilai f hitung lebih besar daripada f tabel maka dapat disimpulkan bahwa secara bersama-sama variabel independen berpengaruh terhadap variabel dependen. sebagai contoh : Nilai df1 = k-1 = 2-1 = 1 df2 = n-k = 32-2= 30 Berdasarkan Tabel F dengan nilai df 1 = 1 df 2 = 30 maka nilai F table adalah 4.17. Dari hasil regresi di atas dapat dilihat bahwa nilai f hitung (74.79874) > f table 4.17 dehingga dapat disimpulkan bahwa variabel independent secara bersama- masa berpengaruh terhadap variable independent.
- 17. ANALISIS STATISTIK PENDEKATAN E V I E W S
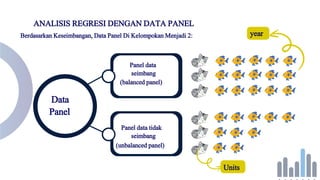
- 18. ANALISIS REGRESI DENGAN DATA PANEL Konsep Dasar Data Panel Time Series Cross Section Data runtut waktu (time series). Dapat dikumpulkan dari waktu ke waktu pada satu obyek. Data silang waktu (cross section). Data dikumpulkan dari beberapa obyek padasatu waktu. Data yang dikumpulkan dari beberapa obyek dengan beberapa waktu. Disebut juga pool data.
- 19. Data Panel Panel data seimbang (balanced panel) Panel data tidak seimbang (unbalanced panel) ANALISIS REGRESI DENGAN DATA PANEL Berdasarkan Keseimbangan, Data Panel Di Kelompokan Menjadi 2: year Units
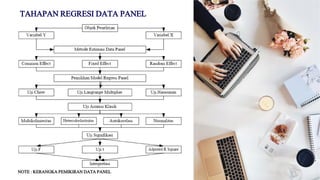
- 20. NOTE : KERANGKA PEMIKIRAN DATA PANEL TAHAPAN REGRESI DATA PANEL
- 21. TAHAPAN REGRESI DATA PANEL Teknik analisis regresi data panel memiliki serangkaian tahapan berupa: Pemilihan model regresi pengujian asumsi klasik uji kelayakan model interpretasi model
- 22. Pemilihan model regresi TAHAPAN REGRESI DATA PANEL
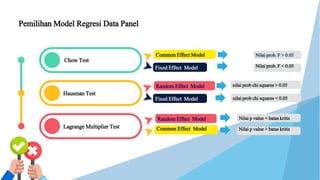
- 23. Metode Estimasi Model Regresi Data Panel Common Effect Model Fixed Effect Model Random Effect Model
- 24. Fixed Effect Model Fixed Effect Model Pemilihan Model Regresi Data Panel Chow Test Hausman Test Lagrange Multiplier Test Common Effect Model Random Effect Model Random Effect Model Common Effect Model Nilai prob. F > 0.05 Nilai prob. F < 0.05 nilai prob chi squares < 0.05 nilai prob chi squares > 0.05 Nilai p value < batas kritis Nilai p value > batas kritis
- 25. Klik View, Residual Diagnostics, Heterokesdatisitas Test Ada beberapa pilihan yang bisa diplih. Dalam tutorial kali ini pilih uji white untuk mendapatkan hasil heterokesdatisitas test. Setelah itu akan muncul output dari Heterokesdatisitas test. terdapat heterokesdatisitas. Pilih quick -> estimate equation Masukan label variable dengan format ŌĆ£variable dependen c variable independŌĆØ sesuai dengan judul penelitian Klik view, Residual Diagnostic, lalu pilih histogram Uji Normalitas Uji Heterokesdatisitas Klik View, Residual Diagnostics, Serial Correlation Test Setelah itu akan muncul output dari Uji autokeralasi. Uji autokorelasi Klik View, Coeficient Diagnostics, Variance Inflation Factors Setelah itu akan muncul output dari Uji autokeralasi. Uji Multikolinieritas Jika nilai VIF < 10 atau nilai Tolerance > 0,01, maka dinyatakan tidak terjadi multikolinearitas prob chi squares > 0.05 maka tidak ada autokorelasi probabilitas jarque-bera > 0.05 maka lulus uji normalitas prob chi squares > 0.05 maka tidak ada heteroskedastisitas.
- 26. Uji Parsial (Uji T) Uji partial (Uji T) Uji t dilakukan untuk melihat pengaruh suatu variabel independent terhadap variable dependen. Dengan menggunakan hipotesis : Ho : tidak berpengaruh Ha : berpengaruh Jika nilai t hitung < t table, artinya Ho diterima Jika nilai t hitung > t table, artinya Ho ditolak
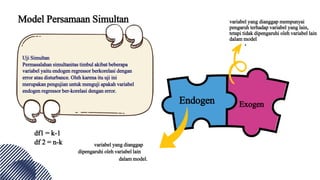
- 27. Model Persamaan Simultan Uji Simultan Permasalahan simultanitas timbul akibat beberapa variabel yaitu endogen regressor berkorelasi dengan error atau disturbance. Oleh karena itu uji ini merupakan pengujian untuk menguji apakah variabel endogen regressor ber-korelasi dengan error. Endogen Exogen variabel yang dianggap dipengaruhi oleh variabel lain dalam model. variabel yang dianggap mempunyai pengaruh terhadap variabel yang lain, tetapi tidak dipengaruhi oleh variabel lain dalam model df1 = k-1 df 2 = n-k