






























Pythonで入門するApache Spark at PyCon2016
- 1. Copyright ? BrainPad Inc. All Rights Reserved. Pythonで入門するApache Spark 2016年9月22日@PyConJP 2016
- 2. Copyright ? BrainPad Inc. All Rights Reserved. ? 名前 – Tatsuya Atsumi – Twitter: https://twitter.com/__Attsun__ ? 仕事 – BrainPad – 自社製品(DMP)の開発 ? 好きなもの – Python ? 6年くらい – Spark ? 1年半くらい ? その他 – 今年刊行された「詳解Apache Spark」のレビュアーを担当させていただきました。と ても良い本です! 2 自己紹介
- 3. Copyright ? BrainPad Inc. All Rights Reserved. ? 対象者 – Sparkについて興味があるが、詳しいことはまだよく知らない方。 – Pythonで基本的なプログラミングができる方。 ? 狙い – Sparkについての基礎的な特徴を理解していただく。 – Pythonを使ったSparkの使用方法について理解していただく。 – Sparkのライブラリについて、特にSparkSQLとMLlibについての理解をしていただく。 3 本プレゼンでの対象者と狙い
- 4. Copyright ? BrainPad Inc. All Rights Reserved. 1. Apache Sparkの概要と歴史 2. 弊社内でのSpark使用事例について 3. Apache Sparkの基礎(コアAPI) 4. Spark SQL 5. MLlib 6. まとめ ? Appendix(実行モデルとスケジューリング) 4 アジェンダ
- 5. Copyright ? BrainPad Inc. All Rights Reserved. 1. Apache Sparkの概要と歴史 5
- 6. Copyright ? BrainPad Inc. All Rights Reserved. 公式ドキュメントによると、 Apache Spark is a fast and general-purpose cluster computing system. つまり、「高速」と「多目的」を特徴とした分散処理システム。 ? 複数台のサーバを使って、大量のデータを高速に処理できる。 ? タスクのスケジューリングや障害発生時の復旧のような分散処理にまつわる面倒 な点はSparkがカバーしてくれる。 ? MapReduceで行われていたようなログ集計から、レコメンドシステム、リアル タイム処理まで幅広い用途で使われている。 6 Sparkとは
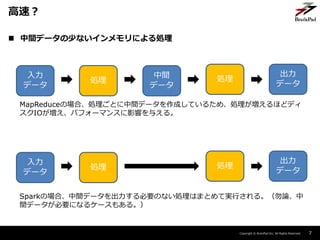
- 7. Copyright ? BrainPad Inc. All Rights Reserved. ? 中間データの少ないインメモリによる処理 7 高速? 入力 データ 処理 中間 データ 処理 出力 データ MapReduceの場合、処理ごとに中間データを作成しているため、処理が増えるほどディ スクIOが増え、パフォーマンスに影響を与える。 入力 データ 処理 処理 出力 データ Sparkの場合、中間データを出力する必要のない処理はまとめて実行される。(勿論、中 間データが必要になるケースもある。)
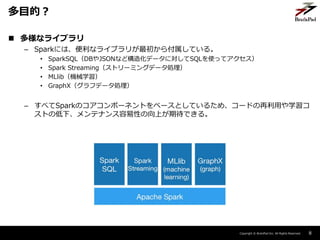
- 8. Copyright ? BrainPad Inc. All Rights Reserved. ? 多様なライブラリ – Sparkには、便利なライブラリが最初から付属している。 ? SparkSQL(DBやJSONなど構造化データに対してSQLを使ってアクセス) ? Spark Streaming(ストリーミングデータ処理) ? MLlib(機械学習) ? GraphX(グラフデータ処理) – すべてSparkのコアコンポーネントをベースとしているため、コードの再利用や学習コ ストの低下、メンテナンス容易性の向上が期待できる。 8 多目的?
- 9. Copyright ? BrainPad Inc. All Rights Reserved. ? 多様なAPI – 以下4つのプログラミング言語をサポートしている。 ? Python ? Scala ? Java ? R – Pythonは、以下バージョンをサポートしている。 ? 2.6以上 ? 3.4以上 ? PyPy2.3以上 – 今日はPython2.7をベースとした使い方について話します。 9 多目的?
- 10. Copyright ? BrainPad Inc. All Rights Reserved. ? 何であるか? – 大規模データの分散処理フレームワーク ? 従来のMapReduceの代替みたいなイメージ ? 何でないか? – 分散ファイルシステム(HDFS) ? HDFSやS3を代替するものではない。 – リソーススケジューラ(YARN, Mesos) ? Sparkがこれらのリソーススケジューラ上で起動する。 – 小規模なデータを処理するツール ? シンプルにPython書いたほうが速いし楽。 ? 増え続ける大規模データを一定の速度で処理したい、スケーラビリティを確保したい、という ケースでなければはまらないと思われる。 10 Sparkは何であるか?何でないか?
- 11. Copyright ? BrainPad Inc. All Rights Reserved. ? わかりやすいインターフェース – APIはmap, filterなど動作が把握できるものが多い。SQLも使える。 ? 高速 – 大規模データを高速に処理できる。(従来のMapReduceに比べてという話) ? 様々なユースケースに対応できる多様なライブラリ – 機械学習、ストリーミングのようなモダンなユースケースに対応できるのは嬉しい。 ? 従来のHadoopスタックが利用可能 – YARNやHDFSといった、従来のHadoopスタックを使用できるため、クラスタを新た に作り直す必要はない。 ? 情報量の多さとコミュニティの安心感 – 類似の様々なフレームワークが存在するが、情報量ではSparkに分がありそう。 – バージョンアップを行う際にも後方互換生を気にしてくれるなど、開発も硬い。 11 なぜSparkを使うか?
- 12. Copyright ? BrainPad Inc. All Rights Reserved. ? 略歴 – 2009年からUC Berkleyで開発が始められる。 – 2010年にオープンソース化。 – 2013年にApache Software Foundationに寄贈される。 – 2014年にApache Top-Level Projectに昇格 – 2014年にバージョン1.0.0がリリース – 2016年にバージョン2.0.0がリリース 現在(2016/8/15時点)での最新バージョンは2.0.0。 今日の解説は2.0.0を前提としています。 12 Sparkの歴史
- 13. Copyright ? BrainPad Inc. All Rights Reserved. 2. 弊社でのSpark使用事例について 13
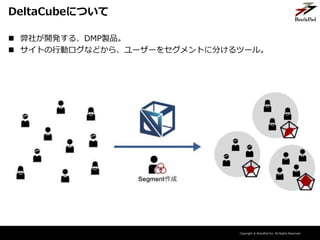
- 14. Copyright ? BrainPad Inc. All Rights Reserved. DeltaCubeについて ? 弊社が開発する、DMP製品。 ? サイトの行動ログなどから、ユーザーをセグメントに分けるツール。
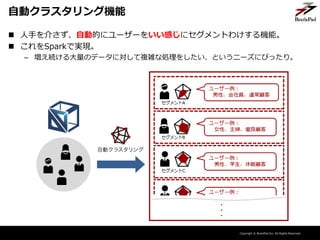
- 15. Copyright ? BrainPad Inc. All Rights Reserved. 自動クラスタリング機能 ? 人手を介さず、自動的にユーザーをいい感じにセグメントわけする機能。 ? これをSparkで実現。 – 増え続ける大量のデータに対して複雑な処理をしたい、というニーズにぴったり。
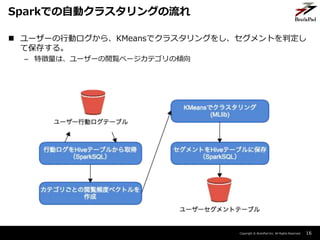
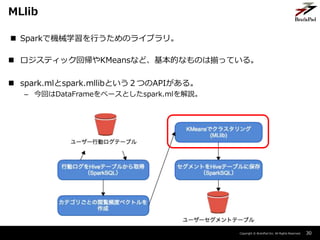
- 16. Copyright ? BrainPad Inc. All Rights Reserved. 16 Sparkでの自動クラスタリングの流れ ? ユーザーの行動ログから、KMeansでクラスタリングをし、セグメントを判定し て保存する。 – 特徴量は、ユーザーの閲覧ページカテゴリの傾向
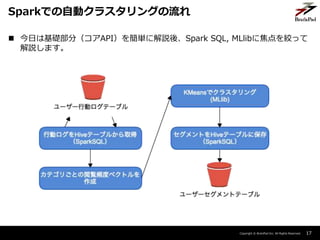
- 17. Copyright ? BrainPad Inc. All Rights Reserved. 17 Sparkでの自動クラスタリングの流れ ? 今日は基礎部分(コアAPI)を簡単に解説後、Spark SQL, MLlibに焦点を絞って 解説します。
- 18. Copyright ? BrainPad Inc. All Rights Reserved. 3. Apache Sparkの基礎(コアAPI) 18
- 19. Copyright ? BrainPad Inc. All Rights Reserved. 19 (jupyter)Sparkをはじめてみよう Sparkはインタプリターがあるので、お試しで起動するのもすごく簡単です。 デフォルトのPythonインタープリタのほか、iPythonやjupyter notebook上でも気 軽に起動できます。 今回はjupyter notebook上で起動してみます。
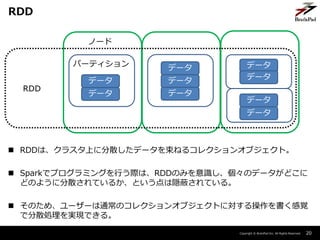
- 20. Copyright ? BrainPad Inc. All Rights Reserved. ? RDDは、クラスタ上に分散したデータを束ねるコレクションオブジェクト。 ? Sparkでプログラミングを行う際は、RDDのみを意識し、個々のデータがどこに どのように分散されているか、という点は隠蔽されている。 ? そのため、ユーザーは通常のコレクションオブジェクトに対する操作を書く感覚 で分散処理を実現できる。 20 RDD データ データ データ データ データ データ データ データ データ パーティション ノード RDD
- 21. Copyright ? BrainPad Inc. All Rights Reserved. ? RDDはTransformationと呼ばれる処理ごとに、新たなRDDオブジェクトが作 成される。 – map – filter ? 実際の処理は、Actionと呼ばれる処理が実行されるまで遅延される。 – count – take – saveAsTextFile 21 遅延実行 RDD RDD RDD transformationにより生成 transformationにより生成 参照を保持参照を保持
- 22. Copyright ? BrainPad Inc. All Rights Reserved. 22 (jupyter)RDDの処理イメージ
- 23. Copyright ? BrainPad Inc. All Rights Reserved. 4. Spark SQL 23
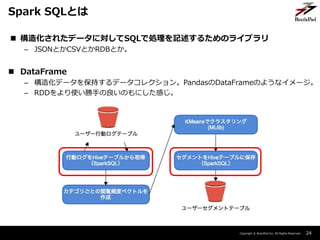
- 24. Copyright ? BrainPad Inc. All Rights Reserved. ? 構造化されたデータに対してSQLで処理を記述するためのライブラリ – JSONとかCSVとかRDBとか。 ? DataFrame – 構造化データを保持するデータコレクション。PandasのDataFrameのようなイメージ。 – RDDをより使い勝手の良いのもにした感じ。 24 Spark SQLとは
- 25. Copyright ? BrainPad Inc. All Rights Reserved. 25 (jupyter) SparkSQLを動かしてみよう
- 26. Copyright ? BrainPad Inc. All Rights Reserved. ? select, filter, join, limit, orderByのような基本的な操作 ? UDF(ユーザー定義関数) – もちろん、関数はPythonで記述可能。 – https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.S QLContext.registerFunction ? window関数 ? abs, ceilのような関数 関数やメソッドはそれ以外にも数多くあります。APIドキュメントを参照。 26 DataFrameのメソッド
- 27. Copyright ? BrainPad Inc. All Rights Reserved. ? JSON ? CSV ? Parquet ? HiveTable ? その他 – JDBC – ORC – 外部ライブラリを使うことで、avroなどのフォーマットも扱えるようになります。 ? csvはもともと外部ライブラリだったものが本体に取り込まれました。 27 様々なデータソース
- 28. Copyright ? BrainPad Inc. All Rights Reserved. ? SQLで処理を記述する場合、Spark固有のAPIを使う必要がない。 ? DataFrameを使う場合でも、より少ないコードで可読性の高いコードが書ける。 – RDDと比べて。 ? オプティマイザにより処理が最適化される – Databricksのベンチマークを参照 ? https://databricks.com/blog/2015/04/24/recent-performance-improvements-in- apache-spark-sql-python-dataframes-and-more.html – RDDによる処理は、ScalaがPythonの倍以上高速 – DataFrameによる処理では言語間の差がないほか、RDDよりも高速 – RDDに比べて細かいチューニングが不要になる。 28 (jupyter)Spark SQLのメリット
- 29. Copyright ? BrainPad Inc. All Rights Reserved. 5. MLlib 29
- 30. Copyright ? BrainPad Inc. All Rights Reserved. ? Sparkで機械学習を行うためのライブラリ。 ? ロジスティック回帰やKMeansなど、基本的なものは揃っている。 ? spark.mlとspark.mllibという2つのAPIがある。 – 今回はDataFrameをベースとしたspark.mlを解説。 30 MLlib
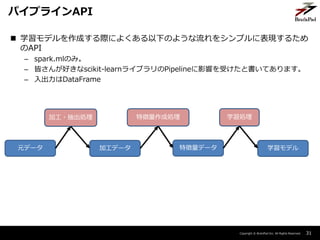
- 31. Copyright ? BrainPad Inc. All Rights Reserved. ? 学習モデルを作成する際によくある以下のような流れをシンプルに表現するため のAPI – spark.mlのみ。 – 皆さんが好きなscikit-learnライブラリのPipelineに影響を受けたと書いてあります。 – 入出力はDataFrame 31 パイプラインAPI 元データ 加工データ 特徴量データ 学習モデル 加工?抽出処理 特徴量作成処理 学習処理
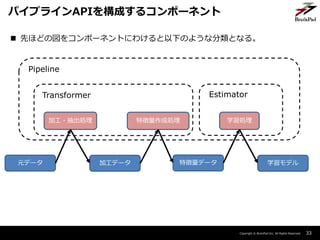
- 32. Copyright ? BrainPad Inc. All Rights Reserved. ? Transformer – 入力データ(DataFrame)から異なる出力データ(DataFrame)を生成するコンポー ネント。 – 文章から単語を生成するTokenizerなど。 ? 「This is a pen」-> 「”This”, “is”, “a”, “pen”」 ? Estimator – DataFrameからTransformerを生成するコンポーネント。 – LogisticRegressionやKMeansなどの学習アルゴリズム。 ? Pipeline – TransformerやEstimatorを組み合わせて予測モデルを構築する。 32 パイプラインAPIを構成するコンポーネント
- 33. Copyright ? BrainPad Inc. All Rights Reserved. 33 パイプラインAPIを構成するコンポーネント 元データ 加工データ 特徴量データ 学習モデル 加工?抽出処理 特徴量作成処理 学習処理 Pipeline Transformer Estimator ? 先ほどの図をコンポーネントにわけると以下のような分類となる。
- 34. Copyright ? BrainPad Inc. All Rights Reserved. ? スパムメッセージの判定を行う。 – データセット ? UCI(カリフォルニア大学アーバイン校)にあるやつ ? https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection ? Sparkが生まれたのはバークレー校 – 特徴量 ? 単語の出現頻度 – モデル ? ロジスティック回帰 – 扱うライブラリ ? SparkML ? DataFrame 34 (jupyter)SparkML(&DataFrame)の使用例
- 35. Copyright ? BrainPad Inc. All Rights Reserved. 6. まとめ 35
- 36. Copyright ? BrainPad Inc. All Rights Reserved. ? Sparkは、インメモリ処理による高速性と、多目的なライブラリを持つ分散処理 フレームワーク。 ? Spark SQLとMLlibを組み合わせることで、弊社のケースのような大規模データ に対する複雑な処理も簡単に。 ? データ量の少ないタスクにとっては速度的にも運用負荷の面でもいいことがない と思われるので、やみくもな導入は避けたい。 36 まとめ
- 37. Copyright ? BrainPad Inc. All Rights Reserved. ? 自分で動かしてみて、Sparkを体感してみましょう。 ? 本を買ってみましょう。 ? GraphXやSpark Streamingなど、今回触れなかったライブラリについて調べて みましょう。 ? DriverやExecutorといった実行モデルについて調べてみましょう。 ? Shuffle処理について調べてみましょう。 – パフォーマンス改善の勘所の一つ 37 さらに知りたい方へ
- 38. Copyright ? BrainPad Inc. All Rights Reserved. ブレインパッドでは、「データ分析」と「エンジニアリング」の融合により新しい 価値を提供したいエンジニア?データサイエンティストを募集しています! ご興味ある方は是非お気軽に話しかけてください! 38 WE ARE HIRING !!
- 39. Copyright ? BrainPad Inc. All Rights Reserved. ご静聴ありがとうございました。 39
- 40. Copyright ? BrainPad Inc. All Rights Reserved. 株式会社ブレインパッド 〒108-0071 東京都港区白金台3-2-10 白金台ビル3F TEL:03-6721-7001 FAX:03-6721-7010 info@brainpad.co.jp Copyright ? BrainPad Inc. All Rights Reserved. www.brainpad.co.jp
- 41. Copyright ? BrainPad Inc. All Rights Reserved. Appendix: 実行モデルとスケジューリング 41
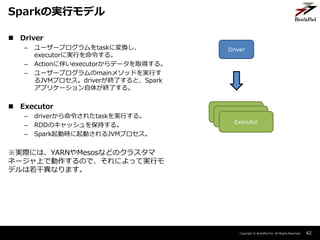
- 42. Copyright ? BrainPad Inc. All Rights Reserved. 42 Sparkの実行モデル Driver Executor ? Driver – ユーザープログラムをtaskに変換し、 executorに実行を命令する。 – Actionに伴いexecutorからデータを取得する。 – ユーザープログラムのmainメソッドを実行す るJVMプロセス。driverが終了すると、Spark アプリケーション自体が終了する。 ? Executor – driverから命令されたtaskを実行する。 – RDDのキャッシュを保持する。 – Spark起動時に起動されるJVMプロセス。 ※実際には、YARNやMesosなどのクラスタマ ネージャ上で動作するので、それによって実行モ デルは若干異なります。 Executor Executor
- 43. Copyright ? BrainPad Inc. All Rights Reserved. 1. ユーザープログラムが、transformationを組み合わせてRDDの参照グラフを作 成する。 2. ユーザープログラムが、actionを実行する。 3. Driverが、RDDの依存グラフから実行プランを作成する。 – 実行プランは複数のステージからなる。 – Stage ? 複数のTaskの集合。 ? Shuffle(後述)が必要となるポイントでStageを分ける。 ? 同じパーティションに対する処理が連続している場合、マージすることで最適化する。 – Task ? executorの実行する処理の最小単位。1パーティションごとに作成される。 4. Executorに各Stageの処理を命令する。 43 Driverによる実行計画作成
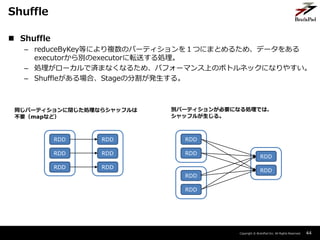
- 44. Copyright ? BrainPad Inc. All Rights Reserved. ? Shuffle – reduceByKey等により複数のパーティションを1つにまとめるため、データをある executorから別のexecutorに転送する処理。 – 処理がローカルで済まなくなるため、パフォーマンス上のボトルネックになりやすい。 – Shuffleがある場合、Stageの分割が発生する。 44 Shuffle RDD RDD RDD RDD RDD RDD RDD RDD RDD RDD RDD RDD 同じパーティションに閉じた処理ならシャッフルは 不要(mapなど) 別パーティションが必要になる処理では、 シャッフルが生じる。
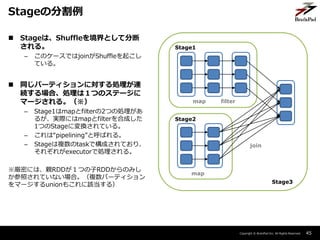
- 45. Copyright ? BrainPad Inc. All Rights Reserved. ? Stageは、Shuffleを境界として分断 される。 – このケースではjoinがShuffleを起こし ている。 ? 同じパーティションに対する処理が連 続する場合、処理は1つのステージに マージされる。(※) – Stage1はmapとfilterの2つの処理があ るが、実際にはmapとfilterを合成した 1つのStageに変換されている。 – これは“pipelining”と呼ばれる。 – Stageは複数のtaskで構成されており、 それぞれがexecutorで処理される。 ※厳密には、親RDDが1つの子RDDからのみし か参照されていない場合。(複数パーティション をマージするunionもこれに該当する) 45 Stageの分割例 map filter map join Stage1 Stage2 Stage3
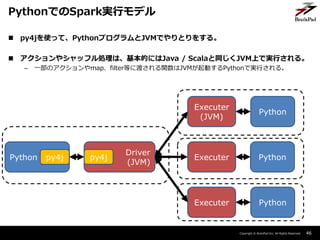
- 46. Copyright ? BrainPad Inc. All Rights Reserved. ? py4jを使って、PythonプログラムとJVMでやりとりをする。 ? アクションやシャッフル処理は、基本的にはJava / Scalaと同じくJVM上で実行される。 – 一部のアクションやmap、filter等に渡される関数はJVMが起動するPythonで実行される。 46 PythonでのSpark実行モデル Python py4j Driver (JVM) py4j Executer Executer Executer (JVM) Python Python Python