
















































More Related Content
What's hot (20)
Similar to Apache Spark の紹介(前半:Sparkのキホン) (20)


















More from NTT DATA OSS Professional Services (20)




















Apache Spark の紹介(前半:Sparkのキホン)
- 1. Apache Sparkのご紹介 ~Sparkのキホン NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 土橋 昌 2014年5月29日 第16回 Hadoopソースコードリーディング 発表資料
- 2. 2Copyright ? 2013 NTT DATA Corporation ? 氏名:土橋 昌 ? 略歴: ? まだ世にHadoopクラスタが少なかったころから、数十台~数千台のHadoopクラスタのため に奔走。結局Hadoop以外のOSSとも格闘する日々。ActiveDirectory、LDAP、Ganglia、 Nagios、Zabbix、Puppet、???。OSSじゃなのも混ざってますが、OSS屋さん。 ? 最近はHadoopしながら、Stormやったり、Sparkやったり、HBase触れたり、Cassandraを覗 いたり。「ゲテモノ」にぶつかって 心砕ける 心踊るのが仕事。 ? どんな人?: ? 基本はインフラエンジニア。下手の横好きでコード書くのも好き。 ? コンサル(ご相談)から開発、運用もやります。 ? 実は人前は苦手。こっそり生きています。 ? 他には?: ? 分散システムやっている関係で構成管理には昔から悩まされてきました。数年Puppet使っ ていますが、ここ1年くらいはAnsible使ってます。個人的な検証は Vagrant + VirtualBox + Ansible ? 写真撮ったり出掛けたりするのが好き。 自己紹介
- 3. 3Copyright ? 2013 NTT DATA Corporation ? 日頃Hadoopに触れる生活で見出したSparkの背景 ?一面的な説明ですが、なるべく分かりやすく書いたつもり??? ? Spark Summit 2013の振り返り ? Sparkのキホン ?Sparkの鍵 => RDDってなに? ?スケジューラ外観からその動き ? Sparkの細かな話 ?きっと@taroleoさんが話してくれる アジェンダ
- 4. Copyright ? 2013 NTT DATA Corporation 4 Sparkの簡単なご説明
- 5. 5Copyright ? 2013 NTT DATA Corporation ?この資料で紹介する内容は、基本的に机上調査+ ソースコード調査をもとにしています ?動作確認しながら???の内容はここには含まれていま せん。 ?あと、Scalaはコワクナイ まず初めにお伝えする大切なこと
- 6. 6Copyright ? 2013 NTT DATA Corporation ? 大規模データの分散処理をオンメモリで実現する ?データ処理してHDDに都度書き出す方式よりも高速 ?JavaやScalaのコレクション操作のような使い方で 分散処理を実現できる ? 大規模データの分散処理ではHadoopが有名だが、 Hadoopとは異なるアイデア?方法でデータ処理を実現する ?UCBerkeleyのResilient distributed datasets(RDD)の 論文がおおもと Sparkとはオンメモリデータ処理の分散処理基盤 Hadoopとよく比較されるが、 アーキテクチャが全く異なる 最新バージョン「Spark 0.9.1」 (2014/4/9 リリース) メモリ上に分散した 変換処理に適したデータセット
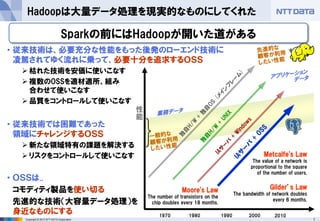
- 7. 7Copyright ? 2013 NTT DATA Corporation Hadoopは大量データ処理を現実的なものにしてくれた ? 従来技術は、必要充分な性能をもった後発のローエンド技術に 凌駕されてゆく流れに乗って、必要十分を追求するOSS ? 枯れた技術を安価に使いこなす ? 複数のOSSを適材適所、組み 合わせて使いこなす ? 品質をコントロールして使いこなす ? 従来技術では困難であった 領域にチャレンジするOSS ? 新たな領域特有の課題を解決する ? リスクをコントロールして使いこなす ? OSSは.. コモディティ製品を使い切る 先進的な技術(大容量データ処理)を 身近なものにする 性 能 1970 1980 1990 2000 Moore's Law The number of transistors on the chip doubles every 18 months. Gilder’s Law The bandwidth of network doubles every 6 months. Metcalfe's Law The value of a network is proportional to the square of the number of users. 2010 Sparkの前にはHadoopが開いた道がある
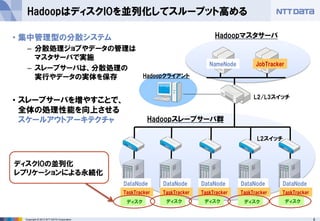
- 8. 8Copyright ? 2013 NTT DATA Corporation HadoopはディスクIOを並列化してスループット高める ? 集中管理型の分散システム – 分散処理ジョブやデータの管理は マスタサーバで実施 – スレーブサーバは、分散処理の 実行やデータの実体を保存 ? スレーブサーバを増やすことで、 全体の処理性能を向上させる スケールアウトアーキテクチャ Hadoopマスタサーバ Hadoopクライアント L2/L3スイッチ NameNode JobTracker L2スイッチ Hadoopスレーブサーバ群 DataNode TaskTracker DataNode TaskTracker DataNode TaskTracker DataNode TaskTracker DataNode TaskTracker ディスク ディスク ディスク ディスク ディスク ディスクIOの並列化 レプリケーションによる永続化
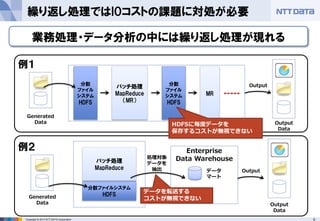
- 9. 9Copyright ? 2013 NTT DATA Corporation 繰り返し処理ではIOコストの課題に対処が必要 Generated Data 分散 ファイル システム HDFS バッチ処理 MapReduce (MR) MR Enterprise Data Warehouse Generated Data 処理対象 データを 抽出 Output Output Data データ マート 分散ファイルシステム HDFS バッチ処理 MapReduce 分散 ファイル システム HDFS HDFSに毎度データを 保存するコストが無視できない データを転送する コストが無視できない Output Output Data 例1 例2 業務処理?データ分析の中には繰り返し処理が現れる
- 10. 10Copyright ? 2013 NTT DATA Corporation ?Hadoopはパワフルだけど… ?もう少し繰り返し計算を効率よくできないか? - 途中結果を何回も再利用しながら計算している - 業務処理が煩雑でジョブが200段くらいになっている ?インタラクティブなドリルダウン分析につかえないか? - 既存HiveやPigでも何とかならないでもないが、もう少し 速さと使い勝手の良いREPLが欲しい - (あとSQL以外の選択肢が欲しい。行指向じゃないこと もしたい) Hadoopはパワフルだけど…という思い
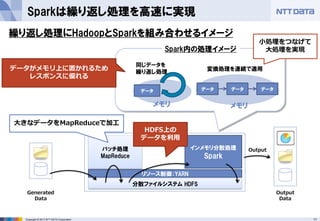
- 11. 11Copyright ? 2013 NTT DATA Corporation Sparkは繰り返し処理を高速に実現 Generated Data Output Output Data 分散ファイルシステム HDFS バッチ処理 MapReduce インメモリ分散処理 Spark リソース制御:YARN 繰り返し処理にHadoopとSparkを組み合わせるイメージ 大きなデータをMapReduceで加工 データがメモリ上に置かれるため レスポンスに優れる Spark内の処理イメージ データ 同じデータを 繰り返し処理 データ データ データ 変換処理を連続で適用 HDFS上の データを利用 小処理をつなげて 大処理を実現 メモリ メモリ
- 12. 12Copyright ? 2013 NTT DATA Corporation ? JavaやScalaのコレクション操作のようなメソッドやフレームワークを利用できるため、 JavaやScalaに慣れた技術者にとって、複雑な処理を実装しやすい ? Hadoopを置き換えるものではなく、SparkはHadoopの仕組みも利用する ? 利用例 ? ログ分析: POSデータ解析、トラヒック解析、M2M、行動履歴、ライフログ長期保存 など ? レコメンド: クリック?ストリーム分析、関係グラフ解析、広告分析 など ? 検索: 非構造データの検索、データ抽出 ? データマイニング: 取引情報の分析?監査、不整データの抽出など ? 機械学習: 大量データのパターン分析、分類など Sparkは大量データを次々に変換する処理が得意 得意 苦手 ? Hadoopで加工した後のドリルダウン分析 ? TB級までのデータを扱うシステム ? サンプリングが有効でないロングテールの データ分析 ? 数秒~数分級のHadoopよりも短い レスポンスが必要な処理 ? クラスタ全体のメモリに乗り切らない 巨大なデータ処理(TB級以上) ? 大きなデータセットを少しずつ更新する処理 ? 秒以下の特に短いレスポンスが必要な処理
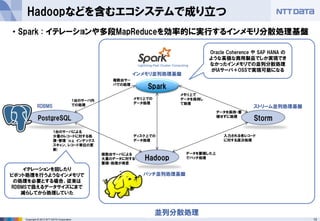
- 13. 13Copyright ? 2013 NTT DATA Corporation Hadoopなどを含むエコシステムで成り立つ ? Spark : イテレーションや多段MapReduceを効率的に実行するインメモリ分散処理基盤 バッチ処理では間に合わないような 速報値を必要とするケースで、かつ1 台のサーバでは処理できない量の データに対応する必要があるケース でStormを採用する Storm ストリーム並列処理基盤 Hadoop バッチ並列処理基盤 Spark インメモリ並列処理基盤 イテレーションを回したり ピボット処理を行うようなインメモリで の処理を必要とする場合、従来は RDBMSで扱えるデータサイズにまで 減らしてから処理していた PostgreSQL RDBMS Oracle Coherence や SAP HANA の ような高価な商用製品でしか実現でき なかったインメモリでの並列分散処理 がIAサーバ+OSSで実現可能になる 1台のサーバによる 少量のレコードに対する処 理?管理 (e.g. インデックス スキャン、レコード単位の更 新) 複数台サーバによる 大量のデータに対する 蓄積?処理が得意 ディスク上での データ処理 メモリ上での データ処理 データを蓄積した上 でバッチ処理 入力される各レコード に対する逐次処理 1台のサーバ内 での処理 複数台サー バでの処理 メモリ上で データを保持し て処理 データを保持?蓄 積せずに処理 並列分散処理
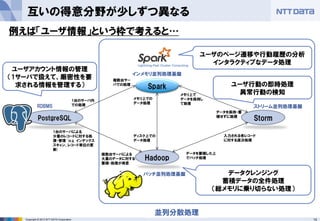
- 14. 14Copyright ? 2013 NTT DATA Corporation 互いの得意分野が少しずつ異なる バッチ処理では間に合わないような 速報値を必要とするケースで、かつ1 台のサーバでは処理できない量の データに対応する必要があるケース でStormを採用する Storm ストリーム並列処理基盤 Hadoop バッチ並列処理基盤 Spark インメモリ並列処理基盤 PostgreSQL RDBMS 1台のサーバによる 少量のレコードに対する処 理?管理 (e.g. インデックス スキャン、レコード単位の更 新) 複数台サーバによる 大量のデータに対する 蓄積?処理が得意 ディスク上での データ処理 メモリ上での データ処理 データを蓄積した上 でバッチ処理 入力される各レコード に対する逐次処理 1台のサーバ内 での処理 複数台サー バでの処理 メモリ上で データを保持し て処理 データを保持?蓄 積せずに処理 並列分散処理 ユーザアカウント情報の管理 (1サーバで扱えて、厳密性を要 求される情報を管理する) ユーザ行動の即時処理 異常行動の検知 ユーザのページ遷移や行動履歴の分析 インタラクティブなデータ処理 例えば「ユーザ情報」という枠で考えると… データクレンジング 蓄積データの全件処理 (総メモリに乗り切らない処理)
- 15. 15Copyright ? 2013 NTT DATA Corporation (参考)Sparkの開発背景や体制 Apache Spark ホームページと Spark Summit のスポンサー ここ1年の Sparkの contributorが 1年前に17人だったの が今年9月に67人に 2009年: - UC Berkley AMPLab にて 研究プロジェクトがスタート 2012年: - AMP Camp 1 2013年: - 急速に動きが活発化 - 6/19 Apache Incubation Project - 8月 AMP Camp 2 - 10/27 AMPLab から Databrics 社設立 - 12/2 Spark Summit 開催 開発背景
- 16. Copyright ? 2013 NTT DATA Corporation 16 Spark Summit 2013の様子とホットトピック
- 17. 17Copyright ? 2013 NTT DATA Corporation ? 日時:2013年12月2日~3日 ? 場所:The Hotel Nikko @ San Francisco ? 参加者: 450名以上 (半数はチュートリアルに参加) ? 1日目午前 : keynote 1日目午後 : 2トラックで合計24セッション ? 2日目 : チュートリアル イベント概要 スポンサー
- 18. 18Copyright ? 2013 NTT DATA Corporation ? Keynote : Databricks 社 CEO からのメッセージ ? 「いろいろ道具立てが溢れているが、Spark の上で全部やれるようになるこ とを目指しています」 ? 「Hadoop とは共存します」 ? Cloudera との提携を前面に押し出していた ? アカデミック+エンタープライズの両方の雰囲気をもつ会場 会場は満員御礼、チュートリアルも人気 Keynoteの様子 チュートリアルの様子 (こちらも満員)
- 19. 19Copyright ? 2013 NTT DATA Corporation ? Hadoopコミュニティとの連携が強まり、Sparkコミュニティも急速に成長中 ? Yahoo!の事例が目立った ? 最も先行して導入している様子が伺われた ? ただし、SparkはもともとUCBerkeleyが推し進めていたので、Hadoop YARN連携以外の 細かな既存事例が他にもある様子 ? Sparkの特徴や利用イメージに関する発表が多かった ? アプリの見た目は、Java8 Streamなどに似ている…? ? Shark(SQL on Spark)、Spark Streaming、MLbaseなどのエコシステムも形成されている ? 後発だけあって、黎明期のHadoopよりもドキュメントやUIが充実している印象 Yahoo事例とSparkの特徴紹介が多かった セッション全体のポイント
- 20. 20Copyright ? 2013 NTT DATA Corporation サミットの盛況ぶりを裏付けるコミュニティの成長 出典: The State of Spark(Matei Zaharia) 最近話題に上ることが多い Stormなどと比較してもSparkも 負けていない 開発母体であるオープンソースコミュニティが成長してくると、 機能拡充や不具合への対応が充実してくる傾向がある
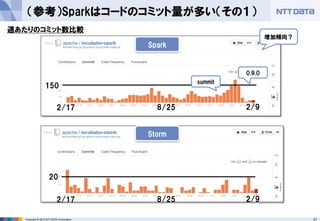
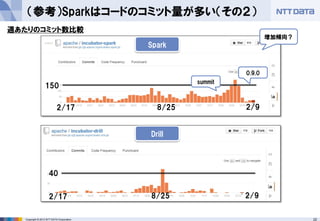
- 21. 21Copyright ? 2013 NTT DATA Corporation (参考)Sparkはコードのコミット量が多い(その1) 150 20 2/17 8/25 2/9 2/17 8/25 2/9 summit 0.9.0 週あたりのコミット数比較 Spark Storm 増加傾向?
- 22. 22Copyright ? 2013 NTT DATA Corporation (参考)Sparkはコードのコミット量が多い(その2) 150 40 2/17 8/25 2/9 2/17 8/25 2/9 summit 0.9.0 週あたりのコミット数比較 Spark Drill 増加傾向?
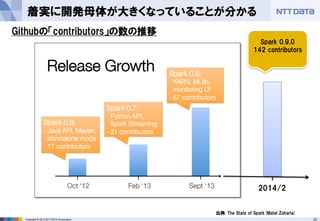
- 23. 23Copyright ? 2013 NTT DATA Corporation 着実に開発母体が大きくなっていることが分かる 出典: The State of Spark(Matei Zaharia) Spark 0.9.0 142 contributors 2014/2 Githubの「contributors」の数の推移
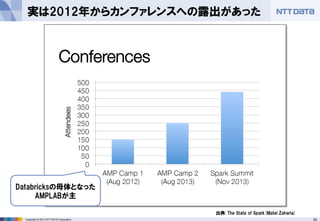
- 24. 24Copyright ? 2013 NTT DATA Corporation 実は2012年からカンファレンスへの露出があった 出典: The State of Spark(Matei Zaharia) Databricksの母体となった AMPLABが主
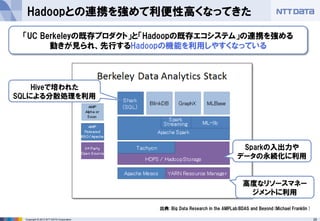
- 25. 25Copyright ? 2013 NTT DATA Corporation Hadoopとの連携を強めて利便性高くなってきた 出典: Big Data Research in the AMPLab:BDAS and Beyond(Michael Franklin ) 「UC Berkeleyの既存プロダクト」と「Hadoopの既存エコシステム」の連携を強める 動きが見られ、先行するHadoopの機能を利用しやすくなっている Sparkの入出力や データの永続化に利用 高度なリソースマネー ジメントに利用 Hiveで培われた SQLによる分散処理を利用
- 26. 26Copyright ? 2013 NTT DATA Corporation Yahoo台湾でパーソナライズに利用されている 一部の処理をHadoopから Sparkに置き換えている 出典: Hadoop and Saprk Join Forces at Yahoo(Andy Feng) 台湾のショッピングサイトで 利用されている 企業ユースも少しずつ増えている様子である (数人程度 x 数か月で移行したとのこと)
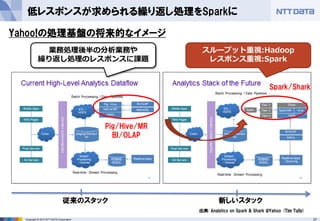
- 27. 27Copyright ? 2013 NTT DATA Corporation 低レスポンスが求められる繰り返し処理をSparkに 出典: Analytics on Spark & Shark @Yahoo (Tim Tully) 新しいスタック従来のスタック 業務処理後半の分析業務や 繰り返し処理のレスポンスに課題 スループット重視:Hadoop レスポンス重視:Spark Yahoo!の処理基盤の将来的なイメージ Pig/Hive/MR BI/OLAP Spark/Shark
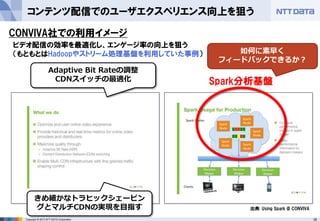
- 28. 28Copyright ? 2013 NTT DATA Corporation コンテンツ配信でのユーザエクスペリエンス向上を狙う CONVIVA社での利用イメージ 出典: Using Spark @ CONVIVA Adaptive Bit Rateの調整 CDNスイッチの最適化 きめ細かなトラヒックシェーピン グとマルチCDNの実現を目指す 如何に素早く フィードバックできるか? Spark分析基盤 ビデオ配信の効率を最適化し、エンゲージ率の向上を狙う (もともとはHadoopやストリーム処理基盤を利用していた事例)
- 29. 29Copyright ? 2013 NTT DATA Corporation Conviva社「デメリットを補って余りあるメリット」 ?分析の高速化、ビットレート向上に確かに貢献 ?プログラミングモデルが適していた&コミュニティが活発 ?Conviva社では様々な機械学習をプロトタイプ ?バッチ処理とストリーム処理で同じフレームワークを利用できた ?スケールさせやすかった 良かった点 苦労した点 ?故障対処と運用 ?Sparkの基盤に関する独自の知識(特にデータモデル)が必要 ?デバッグに際して知識が必要 ?チューニングに際して知識が必要 数か月間のプロダクション環境実績から得られた感想
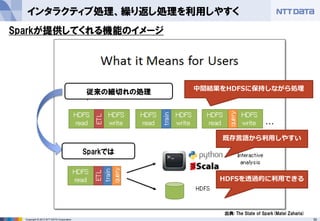
- 30. 30Copyright ? 2013 NTT DATA Corporation インタラクティブ処理、繰り返し処理を利用しやすく 出典: The State of Spark(Matei Zaharia) 中間結果をHDFSに保持しながら処理 従来の細切れの処理 Sparkでは 既存言語から利用しやすい HDFSを透過的に利用できる Sparkが提供してくれる機能のイメージ
- 31. Copyright ? 2013 NTT DATA Corporation 31 適用範囲の広がるSparkエコシステム
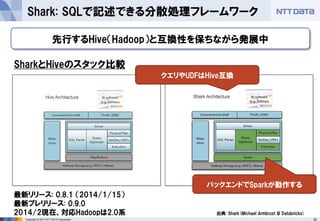
- 32. 32Copyright ? 2013 NTT DATA Corporation Shark: SQLで記述できる分散処理フレームワーク バックエンドでSparkが動作する 先行するHive(Hadoop)と互換性を保ちながら発展中 SharkとHiveのスタック比較 出典: Shark(Michael Armbrust @ Databricks) クエリやUDFはHive互換 最新リリース: 0.8.1 (2014/1/15) 最新プレリリース: 0.9.0 2014/2現在、対応Hadoopは2.0系
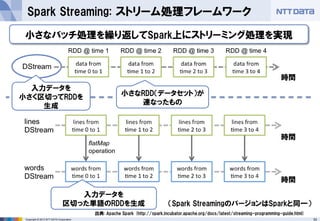
- 33. 33Copyright ? 2013 NTT DATA Corporation Spark Streaming: ストリーム処理フレームワーク 出典: Apache Spark (http://spark.incubator.apache.org/docs/latest/streaming-programming-guide.html) 入力データを 小さく区切ってRDDを 生成 小さなRDD(データセット)が 連なったもの 入力データを 区切った単語のRDDを生成 小さなバッチ処理を繰り返してSpark上にストリーミング処理を実現 時間 時間 時間 (Spark StreamingのバージョンはSparkと同一)
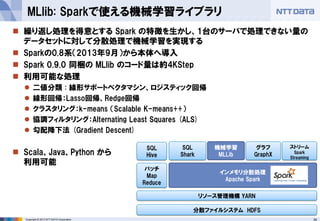
- 34. 34Copyright ? 2013 NTT DATA Corporation ? 繰り返し処理を得意とする Spark の特徴を生かし、1台のサーバで処理できない量の データセットに対して分散処理で機械学習を実現する ? Sparkの0.8系(2013年9月)から本体へ導入 ? Spark 0.9.0 同梱の MLlib のコード量は約4KStep ? 利用可能な処理 ? 二値分類 : 線形サポートベクタマシン、ロジスティック回帰 ? 線形回帰:Lasso回帰、Redge回帰 ? クラスタリング:k-means (Scalable K-means++) ? 協調フィルタリング:Alternating Least Squares (ALS) ? 勾配降下法 (Gradient Descent) ? Scala、Java、Python から 利用可能 MLlib: Sparkで使える機械学習ライブラリ 分散ファイルシステム HDFS バッチ Map Reduce SQL Hive リソース管理機構 YARN インメモリ分散処理 Apache Spark SQL Shark 機械学習 MLLib グラフ GraphX ストリーム Spark Streaming
- 35. Copyright ? 2013 NTT DATA Corporation 35 (参考)Sparkの技術トピック
- 36. 36Copyright ? 2013 NTT DATA Corporation Python、Scala、Javaに対応 出典: Using Apache Spark(Pat McDonough@Databricks) 「関数」を書きやすいScalaかPythonがおすすめ
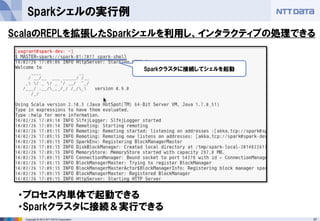
- 37. 37Copyright ? 2013 NTT DATA Corporation Sparkシェルの実行例 ScalaのREPLを拡張したSparkシェルを利用し、インタラクティブの処理できる ?プロセス内単体で起動できる ?Sparkクラスタに接続&実行できる Sparkクラスタに接続してシェルを起動
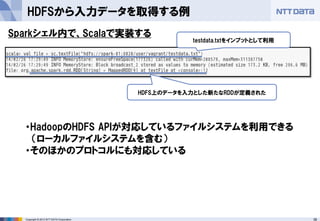
- 38. 38Copyright ? 2013 NTT DATA Corporation HDFSから入力データを取得する例 Sparkシェル内で、Scalaで実装する testdata.txtをインプットとして利用 HDFS上のデータを入力とした新たなRDDが定義された ?HadoopのHDFS APIが対応しているファイルシステムを利用できる (ローカルファイルシステムを含む) ?そのほかのプロトコルにも対応している
- 39. 39Copyright ? 2013 NTT DATA Corporation データを単語に分割してカウントし、出力する例 入力データを単語に分割して 単語ごとに総数を算出する (いわゆるワードカウント) HDFS上に出力 出力結果の例 あたかもJavaやScalaの コレクション操作をするように見えて、 裏では分散処理を実行している
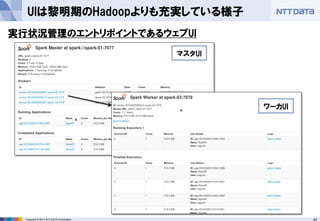
- 40. 40Copyright ? 2013 NTT DATA Corporation UIは黎明期のHadoopよりも充実している様子 実行状況管理のエントリポイントであるウェブUI マスタUI ワーカUI
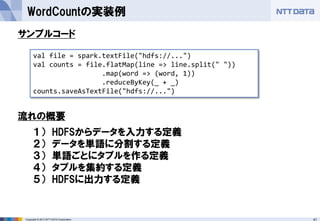
- 41. 41Copyright ? 2013 NTT DATA Corporation WordCountの実装例 val file = spark.textFile("hdfs://...") val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...") 1) HDFSからデータを入力する定義 2) データを単語に分割する定義 3) 単語ごとにタプルを作る定義 4) タプルを集約する定義 5) HDFSに出力する定義 サンプルコード 流れの概要