


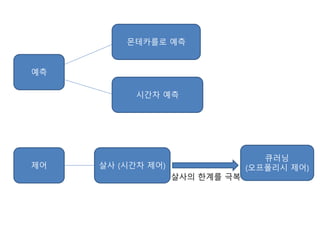












![[нҢҢмқҙмҚ¬кіј мјҖлқјмҠӨлЎң л°°мҡ°лҠ” к°•нҷ”н•ҷмҠө] p.128 к·ёлҰј 4.14
к°•нҷ”н•ҷмҠө м•Ңкі лҰ¬мҰҳ нқҗлҰ„мқ„ мӮҙнҺҙліҙл©ҙ
м •мұ… мқҙн„°л Ҳмқҙм…ҳкіј к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳ
мқҖ мӮҙмӮ¬лЎң л°ңм „н•ңлӢӨ.
мӮҙмӮ¬л¶Җн„° к°•нҷ”н•ҷмҠөмқҙлқјкі л¶ҖлҘёлӢӨ.](https://image.slidesharecdn.com/rlfromscratch-part3-180701081720/85/Rl-from-scratch-part3-20-320.jpg)





![мӢңк°„м°Ё м ңм–ҙм—җм„ң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳл Өл©ҙ мғҳн”Ңмқҙ мһҲм–ҙм•ј н•ңлӢӨ.
мӢңк°„м°Ё м ңм–ҙм—җм„ңлҠ” [ ]мқ„ мғҳн”ҢлЎң мӮ¬мҡ©н•ңлӢӨ.
м—җмқҙм „нҠёлҠ” мғҳн”Ңмқё мғҒнғң S_tм—җм„ң нғҗмҡ• м •мұ…м—җ л”°лқј н–үлҸҷ A_tлҘј м„ нғқн•ҳкі
к·ё н–үлҸҷмқ„ нҷҳкІҪм—җм„ң н•ң нғҖмһ„мҠӨн…қмқ„ 진н–үн•ңлӢӨ.
к·ёлҹ¬л©ҙ нҷҳкІҪмқҖ м—җмқҙм „нҠём—җкІҢ ліҙмғҒ R_(t+1)мқ„ мЈјкі
лӢӨмқҢ мғҒнғң S_(t+1)лҘј м•Ңл ӨмӨҖлӢӨ.
м—¬кё°м„ң н•ң лІҲ лҚ” м—җмқҙм „нҠёлҠ” нғҗмҡ• м •мұ…м—җ л”°лқј н–үлҸҷ A_(t+1)мқ„ м„ нғқн•ҳкі
н•ҳлӮҳмқҳ мғҳн”Ңмқҙ мғқм„ұлҗҳл©ҙ к·ё мғҳн”ҢлЎң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ңлӢӨ.
мқҙкІғмқҙ мӢңк°„м°Ё м ңм–ҙмқҳ кіјм •мқҙлӢӨ.
[ ]мқ„ н•ҳлӮҳмқҳ мғҳн”ҢлЎң мӮ¬мҡ©н•ҳкё° л•Ңл¬ём—җ
мӢңк°„м°Ё м ңм–ҙлҘј лӢӨлҘё л§җлЎң мӮҙмӮ¬(SARSA)лқјкі л¶ҖлҘёлӢӨ.
мӮҙмӮ¬лҠ” нҳ„мһ¬ к°Җм§Җкі мһҲлҠ” нҒҗн•ЁмҲҳлҘј нҶ лҢҖлЎң мғҳн”Ңмқ„ нғҗмҡ• м •мұ…мңјлЎң лӘЁмңјкі
к·ё мғҳн”ҢлЎң л°©л¬ён•ң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳлҠ” кіјм •мқ„ л°ҳліөн•ҳлҠ” кІғмқҙлӢӨ.](https://image.slidesharecdn.com/rlfromscratch-part3-180701081720/85/Rl-from-scratch-part3-26-320.jpg)

![[нҢҢмқҙмҚ¬кіј мјҖлқјмҠӨлЎң л°°мҡ°лҠ” к°•нҷ”н•ҷмҠө] p.132 к·ёлҰј 4.21
1-Оөмқё нҷ•лҘ лЎңлҠ” нҳ„мһ¬ мғҒнғңм—җм„ң к°ҖмһҘ нҒ° нҒҗн•ЁмҲҳмқҳ к°’мқ„ к°Җм§ҖлҠ”
н–үлҸҷмқ„ м„ нғқн•ңлӢӨ.
мҰү, нғҗмҡ• м •мұ…мқ„ л”°лҘҙлҠ” кІғмқҙлӢӨ.
н•ҳм§Җл§Ң нҳ„мһ¬ к°Җм§Җкі мһҲлҠ” нҒҗн•ЁмҲҳлҠ” мҲҳл ҙн•ҳкё° м „к№Ңм§ҖлҠ” нҺён–ҘлҸј мһҲлҠ”,
м •нҷ•н•ҳм§Җ м•ҠмқҖ к°’мқҙлӢӨ.
л”°лқјм„ң м—җмқҙм „нҠёлҠ” м •нҷ•н•ҳм§Җ м•ҠмқҖ нҒҗн•ЁмҲҳлҘј нҶ лҢҖлЎң
нғҗмҡ•м ҒмңјлЎң н–үлҸҷн•ҳкё° ліҙлӢӨлҠ”
мқјм •н•ң Оөмқё нҷ•лҘ лЎң м—үлҡұн•ң н–үлҸҷмқ„ н•ңлӢӨ.](https://image.slidesharecdn.com/rlfromscratch-part3-180701081720/85/Rl-from-scratch-part3-28-320.jpg)

![мқҙмІҳлҹј мӮҙмӮ¬лҠ” GPIмқҳ м •мұ… нҸүк°ҖлҘј нҒҗн•ЁмҲҳлҘј мқҙмҡ©н•ң мӢңк°„м°Ё мҳҲмёЎмңјлЎң,
нғҗмҡ• м •мұ… л°ңм „мқ„ Оө-нғҗмҡ• м •мұ…мңјлЎң ліҖнҷ”мӢңнӮЁ к°•нҷ”н•ҷмҠө м•Ңкі лҰ¬мҰҳмқҙлӢӨ.
лҳҗн•ң м •мұ… мқҙн„°л Ҳмқҙм…ҳкіјлҠ” лӢ¬лҰ¬ лі„лҸ„мқҳ м •мұ… м—Ҷмқҙ
Оө-нғҗмҡ• м •мұ…мқ„ мӮ¬мҡ©н•ҳлҠ” кІғмқҖ к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳм—җм„ң к·ё к°ңл…җмқ„ к°Җм ёмҳЁ кІғмқҙлӢӨ.
мӮҙмӮ¬лҠ” к°„лӢЁнһҲ л‘җ лӢЁкі„лЎң мғқк°Ғн•ҳл©ҙ лҗңлӢӨ.
1. Оө-нғҗмҡ• м •мұ…мқ„ нҶөн•ҙ мғҳн”Ң [ ]мқ„ нҡҚл“қ
2. нҡҚл“қн•ң мғҳн”ҢлЎң лӢӨмқҢ мӢқмқ„ нҶөн•ҙ нҒҗн•ЁмҲҳ Q(S_t,A_t)лҘј м—…лҚ°мқҙнҠё
нҒҗн•ЁмҲҳлҠ” м—җмқҙм „нҠёк°Җ к°Җ진 м •ліҙлЎңм„ң
нҒҗн•ЁмҲҳмқҳ м—…лҚ°мқҙнҠёлҠ” м—җмқҙм „нҠё мһҗмӢ мқ„ м—…лҚ°мқҙнҠён•ҳлҠ” кІғкіј к°ҷлӢӨ.](https://image.slidesharecdn.com/rlfromscratch-part3-180701081720/85/Rl-from-scratch-part3-30-320.jpg)







Rl from scratch part3
- 2. 1. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎ 2. мӢңк°„м°Ё мҳҲмёЎ 3. мӮҙмӮ¬ 4. нҒҗлҹ¬лӢқ
- 3. к°•нҷ”н•ҷмҠөмқҖ нҷҳкІҪмқҳ лӘЁлҚёмқ„ лӘ°лқјлҸ„ нҷҳкІҪкіјмқҳ мғҒнҳёмһ‘мҡ©мқ„ нҶөн•ҙ мөңм Ғ м •мұ…мқ„ н•ҷмҠөн•ңлӢӨ. м—җмқҙм „нҠёлҠ” нҷҳкІҪкіјмқҳ мғҒнҳёмһ‘мҡ©мқ„ нҶөн•ҙ мЈјм–ҙ진 м •мұ…м—җ лҢҖн•ң к°Җм№ҳн•ЁмҲҳлҘј н•ҷмҠөн• мҲҳ мһҲлҠ”лҚ°, мқҙлҘј мҳҲмёЎмқҙлқјкі н•ңлӢӨ. лҳҗн•ң к°Җм№ҳн•ЁмҲҳлҘј нҶ лҢҖлЎң м •мұ…мқ„ лҒҠмһ„м—Ҷмқҙ л°ңм „мӢңмјң лӮҳк°Җм„ң мөңм Ғ м •мұ…мқ„ н•ҷмҠөн•ҳлҠ” кІғмқҙ м ңм–ҙмқҙлӢӨ.
- 4. мҳҲмёЎ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎ мӢңк°„м°Ё мҳҲмёЎ м ңм–ҙ мӮҙмӮ¬ (мӢңк°„м°Ё м ңм–ҙ) мӮҙмӮ¬мқҳ н•ңкі„лҘј к·№ліө нҒҗлҹ¬лӢқ (мҳӨн”„нҸҙлҰ¬мӢң м ңм–ҙ)
- 5. к°•нҷ”н•ҷмҠөмқҖ нҷҳкІҪмқҳ лӘЁлҚё м—Ҷмқҙ нҷҳкІҪмқҙлқјлҠ” мӢңмҠӨн…ңмқҳ мһ…л Ҙкіј м¶ңл Ҙ мӮ¬мқҙмқҳ кҙҖкі„лҘј н•ҷмҠөн•ңлӢӨ. мқҙл•Ң мһ…л ҘмқҖ м—җмқҙм „нҠёмқҳ мғҒнғңмҷҖ н–үлҸҷмқҙкі м¶ңл ҘмқҖ ліҙмғҒмқҙлӢӨ. к°•нҷ”н•ҷмҠөмқҖ 1. мқјлӢЁ н•ҙліҙкі 2. мһҗмӢ мқ„ нҸүк°Җн•ҳл©° 3. нҸүк°Җн•ң лҢҖлЎң мһҗмӢ мқ„ м—…лҚ°мқҙнҠён•ҳл©° 4. мқҙ кіјм •мқ„ л°ҳліөн•ңлӢӨ. к°•нҷ”н•ҷмҠөм—җм„ңлҠ” кі„мӮ°мқ„ нҶөн•ҙм„ң к°Җм№ҳн•ЁмҲҳлҘј м•Ңм•„лӮҙлҠ” кІғмқҙ м•„лӢҲлқј м—җмқҙм „нҠёк°Җ кІӘмқҖ кІҪн—ҳмңјлЎңл¶Җн„° к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠё н•ңлӢӨ.
- 6. м •мұ… мқҙн„°л Ҳмқҙм…ҳм—җм„ң м •мұ… нҸүк°ҖлҠ” нҳ„мһ¬ м •мұ…мқ„ л”°лһҗмқ„ л•Ң м°ё к°Җм№ҳн•ЁмҲҳлҘј кө¬н•ҳлҠ” кіјм •мқҙлӢӨ. к°•нҷ”н•ҷмҠөм—җм„ңлҠ” мқҙ кіјм •мқ„ "мҳҲмёЎ"мқҙлқјкі н•ңлӢӨ. лҳҗн•ң лӢӨмқҙлӮҙлҜ№ н”„лЎңк·ёлһҳл°Қм—җм„ңлҠ” м •мұ… нҸүк°ҖмҷҖ м •мұ… л°ңм „мқ„ н•©м№ң кІғмқ„ м •мұ… мқҙн„°л Ҳмқҙм…ҳмқҙлқјкі л¶Ҳл Җм§Җл§Ң к°•нҷ”н•ҷмҠөм—җм„ңлҠ” мҳҲмёЎкіј н•Ёк»ҳ м •мұ…мқ„ л°ңм „мӢңнӮӨлҠ” кІғмқ„ "м ңм–ҙ"лқјкі л¶ҖлҘёлӢӨ.
- 7. лӘ¬н…Ңм№ҙлҘјлЎң к·јмӮ¬ лӘ¬н…Ңм№ҙлҘјлЎңлқјлҠ” л§җмқҖ "л¬ҙмһ‘мң„лЎң л¬ҙм—Үмқёк°ҖлҘј н•ҙліёлӢӨ"лҠ” мқҳлҜёмқҙлӢӨ. к·јмӮ¬лқјлҠ” кІғмқҖ мӣҗлһҳмқҳ к°’мқҖ лӘЁлҘҙм§Җл§Ң "мғҳн”Ң"мқ„ нҶөн•ҙ "мӣҗлһҳмқҳ к°’м—җ лҢҖн•ҙ мқҙлҹҙ кІғмқҙлӢӨ"лқјкі м¶”м •н•ҳлҠ” кІғмқҙлӢӨ. лӘ¬н…Ңм№ҙлҘјлЎң к·јмӮ¬мқҳ нҠ№м„ұ мӨ‘ н•ҳлӮҳлҠ” л¬ҙн•ңнһҲ л°ҳліөн–Ҳмқ„ л•Ң мӣҗлһҳмқҳ к°’кіј лҸҷмқјн•ҙ진лӢӨлҠ” кІғмқҙлӢӨ. (мў…мқҙмқҳ л©ҙм Ғмқ„ м•ҲлӢӨкі н–Ҳмқ„л•Ң к·ё мў…мқҙм—җ к·ёл Ө진 мӣҗмқҳ л„“мқҙлҘј м¶”м •н•ҳлҠ” л¬ём ңлҘј мғқк°Ғн•ҙліҙмһҗ. мў…мқҙм—җ м җмқ„ л¬ҙмһ‘мң„лЎң л¬ҙмҲҳнһҲ л§Һмқҙ м°ҚлҠ”лӢӨ. м „мІҙ м°ҚмқҖ м җл“Ө мӨ‘м—җм„ң мӣҗ м•Ҳм—җ л“Өм–ҙк°Җ мһҲлҠ” м җмқҳ 비мңЁмқ„ кө¬н•ҳл©ҙ мқҙлҜё м•Ңкі мһҲлҠ” мў…мқҙмқҳ л©ҙм Ғмқ„ нҶөн•ҙ мӣҗмқҳ л„“мқҙ к°’мқ„ м¶”м •н• мҲҳ мһҲлӢӨ. мҰү м°ҚмқҖ м җмқҳ 비мңЁлЎң мӣҗмқҳ л„“мқҙлҘј к·јмӮ¬н•ҳлҠ” кІғмқҙлӢӨ. мӣҗмқҳ л„“мқҙлҘј кө¬н•ҳлҠ” л°©м •мӢқмқ„ лӘ°лқјлҸ„ мқҙ л°©мӢқмқ„ нҶөн•ҙ мӣҗмқҳ л„“мқҙлҘј кө¬н• мҲҳ мһҲлӢӨлҠ” м җмқҙ мһҘм җмқҙлӢӨ.)
- 8. мғҳн”Ңл§Ғкіј лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎ м •мұ… мқҙн„°л Ҳмқҙм…ҳмқҳ м •мұ… нҸүк°Җ кіјм •м—җм„ң лӘ¬н…Ңм№ҙлҘјлЎң к·јмӮ¬лҘј мқҙмҡ©н•ҙ к°Җм№ҳн•ЁмҲҳлҘј м¶”м •н•ҙліҙмһҗ мӣҗмқҳ л„“мқҙлҘј м¶”м •н• л•ҢлҠ” м җмқҙ н•ҳлӮҳмқҳ мғҳн”Ңмқҙл©° м җмқ„ м°ҚлҠ” кІғмқҙ "мғҳн”Ңл§Ғ"мқҙлӢӨ. к°Җм№ҳн•ЁмҲҳлҘј м¶”м •н• л•ҢлҠ” м—җмқҙм „нҠёк°Җ н•ң лІҲ нҷҳкІҪм—җм„ң м—җн”јмҶҢл“ңлҘј 진н–үн•ҳлҠ” кІғмқҙ мғҳн”Ңл§ҒмқҙлӢӨ. мқҙ мғҳн”Ңл§Ғмқ„ нҶөн•ҙ м–»мқҖ мғҳн”Ңмқҳ нҸүк· мңјлЎң м°ё к°Җм№ҳн•ЁмҲҳмқҳ к°’мқ„ м¶”м •н•ңлӢӨ. мқҙл•Ң лӘ¬н…Ңм№ҙлҘјлЎң к·јмӮ¬лҘј мӮ¬мҡ©н•ҳлҠ” кІғмқ„ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎмқҙлқјкі н•ңлӢӨ.
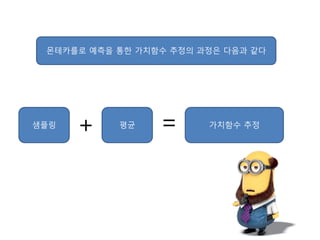
- 9. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎмқ„ нҶөн•ң к°Җм№ҳн•ЁмҲҳ м¶”м •мқҳ кіјм •мқҖ лӢӨмқҢкіј к°ҷлӢӨ мғҳн”Ңл§Ғ к°Җм№ҳн•ЁмҲҳ м¶”м •нҸүк· + =
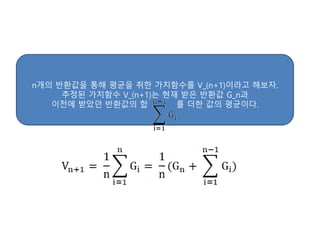
- 10. лІЁл§Ң кё°лҢҖ л°©м •мӢқмқ„ кі„мӮ°н•ҳл Өл©ҙ мЎ°кұҙмқҙ н•„мҡ”н–Ҳм—ҲлӢӨ. л°”лЎң нҷҳкІҪмқҳ лӘЁлҚёмқё ліҙмғҒкіј мғҒнғң ліҖнҷҳ нҷ•лҘ мқ„ м•Ңм•„м•ј н•ҳлҠ” кІғмқҙлӢӨ. мқҙкІғмқҖ л§Ҳм№ҳ мӣҗмқҳ л„“мқҙлҘј кө¬н• л•Ң мӣҗмқҳ л„“мқҙмқҳ л°©м •мӢқмқ„ м•Ңм•„м•ј н•ҳлҠ” кІғкіј л§Ҳм°¬к°Җм§ҖмқҙлӢӨ. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎм—җм„ңлҠ” нҷҳкІҪмқҳ лӘЁлҚёмқ„ лӘ°лқјлҸ„ м—¬лҹ¬ м—җн”јмҶҢл“ңлҘј нҶөн•ҙ кө¬н•ң л°ҳнҷҳк°’мқҳ нҸүк· мқ„ нҶөн•ҙ к°Җм№ҳн•ЁмҲҳлҘј м¶”м •н•ңлӢӨ. мң„ мҲҳмӢқмқҖ м—¬лҹ¬ лІҲмқҳ м—җн”јмҶҢл“ңм—җм„ң sлқјлҠ” мғҒнғңлҘј л°©л¬ён•ҙм„ң м–»мқҖ л°ҳнҷҳк°’л“Өмқҳ нҸүк· мқ„ нҶөн•ҙ м°ё к°Җм№ҳн•ЁмҲҳлҘј м¶”м •н•ҳлҠ” мӢқмқҙлӢӨ. N(s)лҠ” мӢұнғң sлҘј м—¬лҹ¬ лІҲмқҳ м—җн”јмҶҢл“ң лҸҷм•Ҳ л°©л¬ён•ң нҡҹмҲҳмқҙлӢӨ. G_i (s)лҠ” к·ё мғҒнғңлҘј л°©л¬ён•ң iлІҲм§ё м—җн”јмҶҢл“ңм—җм„ң sмқҳ л°ҳнҷҳк°’мқҙлӢӨ. sлҘј л°©л¬ён–ҲлҚҳ м—җн”јмҶҢл“ңм—җ лҢҖн•ҙ л§Ҳм№Ё мғҒнғңк№Ңм§Җмқҳ л°ҳнҷҳк°’мқ„ нҸүк· лӮҙлҠ” кІғмқҙлӢӨ.
- 11. нҳ„мһ¬ м •мұ…м—җ л”°лқј л¬ҙмҲҳнһҲ л§ҺмқҖ м—җн”јмҶҢл“ңлҘј 진н–үн•ҙ ліҙл©ҙ нҳ„мһ¬ м •мұ…мқ„ л”°лһҗмқ„ л•Ң м§ҖлӮ мҲҳ мһҲлҠ” лӘЁл“ мғҒнғңм—җ лҢҖн•ҙ 충분н•ң л°ҳнҷҳк°’л“Өмқ„ лӘЁмқ„ мҲҳ мһҲлӢӨ. л”°лқјм„ң к°Ғ мғҒнғңм—җ лҢҖн•ҙм„ң лӘЁмқё л°ҳнҷҳк°’л“Өмқҳ нҸүк· мқ„ лӮҙл©ҙ мғҒлӢ№нһҲ м •нҷ•н•ң к°Җм№ҳн•ЁмҲҳмқҳ к°’мқ„ м–»мқ„ мҲҳ мһҲлӢӨ.
- 12. nк°ңмқҳ л°ҳнҷҳк°’мқ„ нҶөн•ҙ нҸүк· мқ„ м·Ён•ң к°Җм№ҳн•ЁмҲҳлҘј V_(n+1)мқҙлқјкі н•ҙліҙмһҗ. м¶”м •лҗң к°Җм№ҳн•ЁмҲҳ V_(n+1)лҠ” нҳ„мһ¬ л°ӣмқҖ л°ҳнҷҳк°’ G_nкіј мқҙм „м—җ л°ӣм•ҳлҚҳ л°ҳнҷҳк°’мқҳ н•© лҘј лҚ”н•ң к°’мқҳ нҸүк· мқҙлӢӨ.
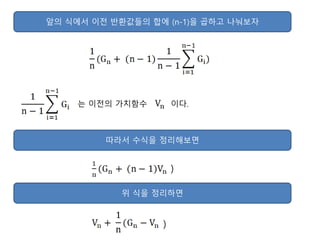
- 13. м•һмқҳ мӢқм—җм„ң мқҙм „ л°ҳнҷҳк°’л“Өмқҳ н•©м—җ (n-1)мқ„ кіұн•ҳкі лӮҳлҲ ліҙмһҗ лҠ” мқҙм „мқҳ к°Җм№ҳн•ЁмҲҳ мқҙлӢӨ. л”°лқјм„ң мҲҳмӢқмқ„ м •лҰ¬н•ҙліҙл©ҙ ) мң„ мӢқмқ„ м •лҰ¬н•ҳл©ҙ )
- 14. м–ҙл–Ө мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳлҠ” мғҳн”Ңл§Ғмқ„ нҶөн•ҙ м—җмқҙм „нҠёк°Җ к·ё мғҒнғңлҘј л°©л¬ён• л•Ңл§ҲлӢӨ м—…лҚ°мқҙнҠён•ҳкІҢ лҗңлӢӨ. мӣҗлһҳ к°Җм§Җкі мһҲлҚҳ к°Җм№ҳн•ЁмҲҳ к°’ V(s)м—җ 1/n(G(s)-V(s))лҘј лҚ”н•ЁмңјлЎңмҚЁ м—…лҚ°мқҙнҠё н•ҳлҠ” кІғмқҙлӢӨ. лӢӨмқҢмқҖ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎм—җм„ң к°Җм№ҳн•ЁмҲҳмқҳ м—…лҚ°мқҙнҠё мӢқмқҙлӢӨ. G(s)-V(s)лҘј мҳӨм°Ёлқјкі н•ҳл©°, 1/nмқҖ мҠӨн…қмӮ¬мқҙмҰҲлЎңм„ң м—…лҚ°мқҙнҠён• л•Ң мҳӨм°Ёмқҳ м–јл§ҲлҘј к°Җм§Җкі м—…лҚ°мқҙнҠён• м§Җ м •н•ҳлҠ” кІғмқҙлӢӨ. мқҙл•Ң мҠӨн…қмӮ¬мқҙмҰҲк°Җ 1мқҙлқјл©ҙ G(s)к°Җ кё°мЎҙмқҳ V(s)лҘј лҢҖмІҙн•ҳкІҢ лҗңлӢӨ. мқјл°ҳм ҒмңјлЎң мҠӨн…қмӮ¬мқҙмҰҲлҠ” ОұлЎң н‘ңнҳ„н•ңлӢӨ. мқҙ к°’мқҙ л„Ҳл¬ҙ нҒ¬л©ҙ мҲҳл ҙн•ҳм§Җ лӘ»н•ҳкі л„Ҳл¬ҙ мһ‘мңјл©ҙ мҲҳл ҙмқҳ мҶҚлҸ„к°Җ лҠҗлҰ¬лӢӨ. лӘЁл“ к°•нҷ”н•ҷмҠө л°©лІ•м—җм„ң к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳлҠ” кІғмқҖ лӘЁл‘җ мң„ мӢқмқҳ ліҖнҳ•мқј лҝҗмқҙлҜҖлЎң мқҙ мӢқмқ„ м •нҷ•нһҲ мқҙн•ҙн•ҙм•ј н•ңлӢӨ.
- 15. к°Җм№ҳн•ЁмҲҳ мһ…мһҘм—җм„ң м—…лҚ°мқҙнҠёлҘј нҶөн•ҙ лҸ„лӢ¬н•ҳл ӨлҠ” лӘ©н‘ңлҠ” л°ҳнҷҳк°’мқҙлӢӨ. к°Җм№ҳн•ЁмҲҳлҠ” мқҙ лӘ©н‘ңлЎң к°җмңјлЎңмҚЁ мһҗмӢ мқ„ м—…лҚ°мқҙнҠён•ҳлҠ”лҚ° н•ң лІҲм—җ лӘ©н‘ңм җмңјлЎң к°ҖлҠ” кІғмқҙ м•„лӢҲкі мҠӨн…қмӮ¬мқҙмҰҲлҘј кіұн•ң л§ҢнҒјл§Ң к°ҖлҠ” кІғмқҙлӢӨ. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎм—җм„ң м—җмқҙм „нҠёлҠ” мқҙ м—…лҚ°мқҙнҠё мӢқмқ„ нҶөн•ҙ м—җн”јмҶҢл“ң лҸҷм•Ҳ кІҪн—ҳн–ҲлҚҳ лӘЁл“ мғҒнғңм—җ лҢҖн•ҙ к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ңлӢӨ. м–ҙл– н•ң мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳк°Җ м—…лҚ°мқҙнҠёлҗ мҲҳлЎқ к°Җм№ҳн•ЁмҲҳлҠ” нҳ„мһ¬ м •мұ…м—җ лҢҖн•ң м°ё к°Җм№ҳн•ЁмҲҳм—җ мҲҳл ҙн•ҙк°„лӢӨ. м—җмқҙм „нҠёлҠ” л§Ҳм№Ё мғҒнғңм—җ к°Ҳ л•Ңк№Ңм§Җ м•„л¬ҙкІғлҸ„ н•ҳм§Җ м•ҠлҠ”лӢӨ. л§Ҳм№Ё мғҒнғңм—җ лҸ„м°©н•ҳл©ҙ м—җмқҙм „нҠёлҠ” м§ҖлӮҳмҳЁ лӘЁл“ мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ңлӢӨ. м—җн”јмҶҢл“ң лҸҷм•Ҳ л°©л¬ён–ҲлҚҳ лӘЁл“ мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳл©ҙ м—җмқҙм „нҠёлҠ” лӢӨмӢң мӢңмһ‘ мғҒнғңм—җм„ңл¶Җн„° мғҲлЎңмҡҙ м—җн”јмҶҢл“ңлҘј 진н–үн•ңлӢӨ. мқҙлҹ¬н•ң кіјм •мқ„ кі„мҶҚ л°ҳліөн•ҳлҠ” кІғмқҙ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎмқҙлӢӨ.
- 16. к°•нҷ”н•ҷмҠөм—җм„ң к°ҖмһҘ мӨ‘мҡ”н•ң м•„мқҙл””м–ҙ мӨ‘ н•ҳлӮҳк°Җ л°”лЎң мӢңк°„м°ЁмқҙлӢӨ. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎмқҳ лӢЁм җмқҖ мӢӨмӢңк°„мқҙ м•„лӢҲлқјлҠ” м җмқҙлӢӨ. к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳкё° мң„н•ҙм„ңлҠ” м—җн”јмҶҢл“ңк°Җ лҒқлӮ л•Ңк№Ңм§Җ кё°лӢӨл Өм•ј н•ңлӢӨ. лҳҗн•ң м—җн”јмҶҢл“ңмқҳ лҒқмқҙ м—Ҷкұ°лӮҳ м—җн”јмҶҢл“ңмқҳ кёёмқҙк°Җ кёҙ кІҪмҡ°м—җлҠ” лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎмқҖ м Ғн•©н•ҳм§Җ м•ҠлӢӨ. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎм—җм„ңмҷҖ к°ҷмқҙ м—җн”јмҶҢл“ңл§ҲлӢӨк°Җ м•„лӢҲлқј нғҖмһ„мҠӨн…қл§ҲлӢӨ к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳлҠ” л°©лІ•мқҙ мӢңк°„м°Ё мҳҲмёЎмқҙлӢӨ.
- 17. лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎм—җм„ңлҠ” лӢӨмқҢкіј к°ҷмқҖ к°Җм№ҳн•ЁмҲҳмқҳ м •мқҳлҘј мқҙмҡ©н•ҳлҠ”лҚ° кё°лҢ“к°’мқ„ кі„мӮ°н•ҳм§Җ м•Ҡкі мғҳн”Ңл§Ғмқ„ нҶөн•ҙ мҳҲмёЎн–Ҳм—ҲлӢӨ. мӢңк°„м°Ё мҳҲмёЎм—җм„ңлҠ” лӢӨмқҢкіј к°ҷмқҖ к°Җм№ҳн•ЁмҲҳмқҳ м •мқҳлҘј мқҙмҡ©н•ңлӢӨ кё°лҢ“к°’мқ„ кі„мӮ°н•ҳм§Җ м•Ҡкі к°’мқ„ мғҳн”Ңл§Ғн•ҙм„ң к·ё к°’мңјлЎң нҳ„мһ¬мқҳ к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ңлӢӨ. к°Җм№ҳн•ЁмҲҳмқҳ м—…лҚ°мқҙнҠёлҠ” мӢӨмӢңк°„мңјлЎң мқҙлӨ„м§Җл©°, лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎкіјлҠ” лӢ¬лҰ¬ н•ң лІҲм—җ н•ҳлӮҳмқҳ к°Җм№ҳн•ЁмҲҳл§Ң м—…лҚ°мқҙнҠён•ңлӢӨ.
- 18. лӢӨмқҢ мӢқмқҖ мӢңк°„м°Ё мҳҲмёЎм—җм„ң к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳлҠ” мӢқмқҙлӢӨ. ) : м—…лҚ°мқҙнҠёмқҳ нҒ¬кё° : м—…лҚ°мқҙнҠёмқҳ лӘ©н‘ң : мӢңк°„м°Ё м—җлҹ¬
- 19. мӢңк°„м°Ё мҳҲмёЎм—җм„ң м—…лҚ°мқҙнҠёмқҳ лӘ©н‘ңлҠ” мӢӨм ңмқҳ к°’мқҖ м•„лӢҲлӢӨ. V(S_(t+1))мқҖ нҳ„мһ¬ м—җмқҙм „нҠёк°Җ к°Җм§Җкі мһҲлҠ” к°’мқҙлӢӨ. м—җмқҙм „нҠёлҠ” мқҙ к°’мқ„ S_(t+1)мқҳ к°Җм№ҳ н•ЁмҲҳмқј кІғмқҙлқјкі мҳҲмёЎн•ҳкі мһҲлӢӨ. лӢӨлҘё мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳ мҳҲмёЎк°’мқ„ нҶөн•ҙ м§ҖкёҲ мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳлҘј мҳҲмёЎн•ҳлҠ” мқҙлҹ¬н•ң л°©мӢқмқ„ л¶ҖнҠёмҠӨнҠёлһ©(Bootstrap)мқҙлқјкі н•ңлӢӨ. мҰү, м—…лҚ°мқҙнҠё лӘ©н‘ңлҸ„ м •нҷ•н•ҳм§Җ м•ҠмқҖ мғҒнҷ©м—җм„ң к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠё н•ҳлҠ” кІғмқҙлӢӨ. м–ҙл–Ө мғҒнғңм—җм„ң н–үлҸҷмқ„ н•ҳл©ҙ ліҙмғҒмқ„ л°ӣкі лӢӨмқҢ мғҒнғңлҘј м•ҢкІҢ лҗҳкі лӢӨмқҢ мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳмҷҖ л°ӣмқҖ ліҙмғҒмқ„ лҚ”н•ҙ к·ё к°’мқ„ м—…лҚ°мқҙнҠёмқҳ лӘ©н‘ңлЎң мӮјлҠ”лӢӨлҠ” кІғмқҙлӢӨ. лӢӨмқҢ мғҒнғңм—җм„ң лҳҗ лӢӨмӢң н–үлҸҷмқ„ м„ нғқн•ҳкі мқҙ кіјм •мқҙ л°ҳліөлҗңлӢӨ. мӢңк°„м°Ё мҳҲмёЎмқҖ м—җн”јмҶҢл“ңк°Җ лҒқлӮ л•Ңк№Ңм§Җ кё°лӢӨлҰҙ н•„мҡ” м—Ҷмқҙ л°”лЎң к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠё н• мҲҳ мһҲлӢӨ. мӢңк°„м°Ё мҳҲмёЎмқҖ 충분нһҲ л§ҺмқҖ мғҳн”Ңл§Ғмқ„ нҶөн•ҙ м—…лҚ°мқҙнҠён•ҳл©ҙ м°ё к°Җм№ҳн•ЁмҲҳм—җ мҲҳл ҙн•ҳл©° л§ҺмқҖ кІҪмҡ°м—җ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎліҙлӢӨ лҚ” нҡЁмңЁм ҒмңјлЎң л№ лҘё мӢңк°„ м•Ҳм—җ м°ё к°Җм№ҳн•ЁмҲҳм—җ к·јм ‘н•ңлӢӨ.
- 20. [нҢҢмқҙмҚ¬кіј мјҖлқјмҠӨлЎң л°°мҡ°лҠ” к°•нҷ”н•ҷмҠө] p.128 к·ёлҰј 4.14 к°•нҷ”н•ҷмҠө м•Ңкі лҰ¬мҰҳ нқҗлҰ„мқ„ мӮҙнҺҙліҙл©ҙ м •мұ… мқҙн„°л Ҳмқҙм…ҳкіј к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳ мқҖ мӮҙмӮ¬лЎң л°ңм „н•ңлӢӨ. мӮҙмӮ¬л¶Җн„° к°•нҷ”н•ҷмҠөмқҙлқјкі л¶ҖлҘёлӢӨ.
- 21. м •мұ… мқҙн„°л Ҳмқҙм…ҳмқҖ "м •мұ… нҸүк°Җ"мҷҖ "м •мұ… л°ңм „"мқ„ лІҲк°Ҳм•„ к°Җл©° мӢӨн–үн•ҳлҠ” кіјм •мқҙлӢӨ. нҳ„мһ¬мқҳ м •мұ…м—җ лҢҖн•ҙ м •мұ… нҸүк°ҖлҘј нҶөн•ҙ к°Җм№ҳн•ЁмҲҳлҘј кө¬н•ҳкі , к·ё к°Җм№ҳн•ЁмҲҳлҘј нҶөн•ҙ м •мұ…мқ„ л°ңм „н•ҳлҠ” кІғмқҳ л°ҳліөмқҙлӢӨ. лІЁл§Ң кё°лҢҖ л°©м •мӢқмқ„ мқҙмҡ©н•ҙ нҳ„мһ¬мқҳ м •мұ…м—җ лҢҖн•ң м°ё к°Җм№ҳн•ЁмҲҳлҘј кө¬н•ҳлҠ” кІғмқҙ м •мұ… нҸүк°Җмқҙл©°, кө¬н•ң к°Җм№ҳн•ЁмҲҳм—җ л”°лқј м •мұ…мқ„ м—…лҚ°мқҙнҠён•ҳлҠ” кІғмқҙ м •мұ… л°ңм „мқҙлӢӨ.
- 22. м •мұ… нҸүк°Җ кіјм •м—җм„ң м°ё к°Җм№ҳн•ЁмҲҳм—җ мҲҳл ҙн• л•Ңк№Ңм§Җ кі„мӮ°н•ҳм§Җ м•Ҡм•„лҸ„ м •мұ… нҸүк°ҖмҷҖ м •мұ… л°ңм „мқ„ н•ң лІҲм”© лІҲк°Ҳм•„ к°Җл©ҙм„ң мӢӨн–үн•ҳл©ҙ м°ё к°Җм№ҳн•ЁмҲҳм—җ мҲҳл ҙн• л•Ңк№Ңм§Җ кі„мӮ°н–Ҳмқ„ л•ҢмҷҖ л§Ҳм°¬к°Җм§ҖлЎң мөңм Ғ к°Җм№ҳн•ЁмҲҳм—җ к°Җм№ҳн•ЁмҲҳк°Җ мҲҳл ҙн•ңлӢӨ. мқҙлҹ¬н•ң м •мұ… мқҙн„°л Ҳмқҙм…ҳмқ„ GPI(Generalized Policy Iteration)лқјкі н•ңлӢӨ. GPIлҠ” лӢЁ н•ң лІҲл§Ң м •мұ…мқ„ нҸүк°Җн•ҙм„ң к°Җм№ҳн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳкі л°”лЎң м •мұ…мқ„ л°ңм „н•ҳлҠ” кіјм •мқ„ л°ҳліөн•ңлӢӨ. GPIмқҳ м •мұ… нҸүк°Җ кіјм •мқ„ мҲҳн–үн•ҳлҠ” кІғмқҙ лӘ¬н…Ңм№ҙлҘјлЎң мҳҲмёЎ, мӢңк°„м°Ё мҳҲмёЎмқҙлӢӨ. мӢңк°„м°Ё мҳҲмёЎм—җ лҢҖн•ҙм„ңл§Ң мӮҙнҺҙліҙмһҗ GPIмқҳ нғҗмҡ• м •мұ… л°ңм „мқҖ мЈјм–ҙ진 к°Җм№ҳн•ЁмҲҳм—җ лҢҖн•ҙ мғҲлЎңмҡҙ м •мұ…мқ„ м–»лҠ” кіјм •мқҙлӢӨ. мӢңк°„м°Ё л°©лІ•м—җм„ңлҠ” нғҖмһ„мҠӨн…қл§ҲлӢӨ к°Җм№ҳн•ЁмҲҳлҘј нҳ„мһ¬ мғҒнғңм—җ лҢҖн•ҙм„ңл§Ң м—…лҚ°мқҙнҠён•ңлӢӨ. л”°лқјм„ң GPIм—җм„ңмІҳлҹј лӘЁл“ мғҒнғңмқҳ м •мұ…мқ„ л°ңм „мӢңнӮ¬ мҲҳ м—ҶлӢӨ. н•ҳм§Җл§Ң мӢңк°„м°Ё л°©лІ•м—җм„ң мқҙлҘј к°ҖлҠҘмјҖ н• мҲҳ мһҲлҠ”лҚ°, л°”лЎң к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳмқҳ л°©лІ•мқ„ мӮ¬мҡ©н•ҳлҠ” кІғмқҙлӢӨ. к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳм—җм„ңлҠ” м •мұ… мқҙн„°л Ҳмқҙм…ҳм—җм„ңмҷҖ лӢ¬лҰ¬ лі„лҸ„мқҳ м •мұ… м—Ҷмқҙ к°Җм№ҳн•ЁмҲҳм—җ лҢҖн•ҙ нғҗмҡ•м ҒмңјлЎң мӣҖм§Ғмқј лҝҗмқҙм—ҲлӢӨ. мӢңк°„м°Ё л°©лІ•м—җм„ңлҸ„ л§Ҳм°¬к°Җм§ҖмқёлҚ° лі„лҸ„мқҳ м •мұ…мқ„ л‘җм§Җ м•Ҡкі м—җмқҙм „нҠёлҠ” нҳ„мһ¬ мғҒнғңм—җм„ң к°ҖмһҘ нҒ° к°Җм№ҳлҘј м§ҖлӢҲлҠ” н–үлҸҷмқ„ м„ нғқн•ҳлҠ” нғҗмҡ• м •мұ…мқ„ мӮ¬мҡ©н•ҳл©ҙ лҗңлӢӨ. мӢңк°„м°Ё мҳҲмёЎкіј нғҗмҡ• м •мұ…мқҙ н•©міҗ진 кІғмқ„ мӢңк°„м°Ё м ңм–ҙлқјкі н•ңлӢӨ.
- 23. GPIм—җм„ң м •мұ… л°ңм „мқҳ мӢқмқҖ лӢӨмқҢкіј к°ҷлӢӨ. нҳ„мһ¬ мғҒнғңмқҳ м •мұ…мқ„ л°ңм „мӢңнӮӨл Өл©ҙ кІ°көӯ мқҳ мөңлҢ“ к°’мқ„ м•Ңм•„м•ј н•ҳлҠ”лҚ° к·ёлҹ¬л Өл©ҙ нҷҳкІҪмқҳ лӘЁлҚёмқё лҘј м•Ңм•„м•ј н•ңлӢӨ.
- 24. нғҗмҡ• м •мұ…м—җм„ң лӢӨмқҢ мғҒнғңмқҳ к°Җм№ҳн•ЁмҲҳлҘј ліҙкі нҢҗлӢЁн•ҳлҠ” кІғмқҙ м•„лӢҲкі нҳ„мһ¬ мғҒнғңмқҳ нҒҗн•ЁмҲҳлҘј ліҙкі нҢҗлӢЁн•ңлӢӨл©ҙ нҷҳкІҪмқҳ лӘЁлҚёмқ„ лӘ°лқјлҸ„ лҗңлӢӨ. нҒҗн•ЁмҲҳлҘј мӮ¬мҡ©н•ң нғҗмҡ• м •мұ…мқҳ мӢқмқҖ лӢӨмқҢкіј к°ҷлӢӨ.
- 25. мӢңк°„м°Ё м ңм–ҙм—җм„ңлҠ” мң„ мҲҳмӢқмңјлЎң н‘ңнҳ„лҗҳлҠ” нғҗмҡ• м •мұ…мқ„ нҶөн•ҙ н–үлҸҷмқ„ м„ нғқн•ңлӢӨ. нҒҗн•ЁмҲҳм—җ л”°лқј н–үлҸҷмқ„ м„ нғқн•ҳл Өл©ҙ м—җмқҙм „нҠёлҠ” к°Җм№ҳн•ЁмҲҳк°Җ м•„лӢҢ нҒҗн•ЁмҲҳмқҳ м •ліҙлҘј м•Ңм•„м•ј н•ңлӢӨ. л”°лқјм„ң мӢңк°„м°Ё м ңм–ҙм—җм„ң м—…лҚ°мқҙнҠён•ҳлҠ” лҢҖмғҒмқҙ к°Җм№ҳн•ЁмҲҳк°Җ м•„лӢҢ нҒҗн•ЁмҲҳк°Җ лҸјм•ј н•ңлӢӨ. мӢңк°„м°Ё м ңм–ҙмқҳ мӢқмқҖ лӢӨмқҢкіј к°ҷлӢӨ. мң„ мҲҳмӢқм—җм„ң лӢӨмқҢ мғҒнғңмқҳ нҒҗн•ЁмҲҳмқё лҘј м•Ңкё° мң„н•ҙм„ңлҠ” лӢӨмқҢ мғҒнғң S_(t+1)м—җм„ң лӢӨмқҢ н–үлҸҷ к№Ңм§Җ A_(t+1)м„ нғқн•ҙм•ј н•ңлӢӨ.
- 26. мӢңк°„м°Ё м ңм–ҙм—җм„ң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳл Өл©ҙ мғҳн”Ңмқҙ мһҲм–ҙм•ј н•ңлӢӨ. мӢңк°„м°Ё м ңм–ҙм—җм„ңлҠ” [ ]мқ„ мғҳн”ҢлЎң мӮ¬мҡ©н•ңлӢӨ. м—җмқҙм „нҠёлҠ” мғҳн”Ңмқё мғҒнғң S_tм—җм„ң нғҗмҡ• м •мұ…м—җ л”°лқј н–үлҸҷ A_tлҘј м„ нғқн•ҳкі к·ё н–үлҸҷмқ„ нҷҳкІҪм—җм„ң н•ң нғҖмһ„мҠӨн…қмқ„ 진н–үн•ңлӢӨ. к·ёлҹ¬л©ҙ нҷҳкІҪмқҖ м—җмқҙм „нҠём—җкІҢ ліҙмғҒ R_(t+1)мқ„ мЈјкі лӢӨмқҢ мғҒнғң S_(t+1)лҘј м•Ңл ӨмӨҖлӢӨ. м—¬кё°м„ң н•ң лІҲ лҚ” м—җмқҙм „нҠёлҠ” нғҗмҡ• м •мұ…м—җ л”°лқј н–үлҸҷ A_(t+1)мқ„ м„ нғқн•ҳкі н•ҳлӮҳмқҳ мғҳн”Ңмқҙ мғқм„ұлҗҳл©ҙ к·ё мғҳн”ҢлЎң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ңлӢӨ. мқҙкІғмқҙ мӢңк°„м°Ё м ңм–ҙмқҳ кіјм •мқҙлӢӨ. [ ]мқ„ н•ҳлӮҳмқҳ мғҳн”ҢлЎң мӮ¬мҡ©н•ҳкё° л•Ңл¬ём—җ мӢңк°„м°Ё м ңм–ҙлҘј лӢӨлҘё л§җлЎң мӮҙмӮ¬(SARSA)лқјкі л¶ҖлҘёлӢӨ. мӮҙмӮ¬лҠ” нҳ„мһ¬ к°Җм§Җкі мһҲлҠ” нҒҗн•ЁмҲҳлҘј нҶ лҢҖлЎң мғҳн”Ңмқ„ нғҗмҡ• м •мұ…мңјлЎң лӘЁмңјкі к·ё мғҳн”ҢлЎң л°©л¬ён•ң нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳлҠ” кіјм •мқ„ л°ҳліөн•ҳлҠ” кІғмқҙлӢӨ.
- 27. н•ҳм§Җл§Ң мқҙлҜё 충분нһҲ л§ҺмқҖ кІҪн—ҳмқ„ н•ң м—җмқҙм „нҠёмқҳ кІҪмҡ°м—җлҠ” нғҗмҡ• м •мұ…мқҙ мўӢмқҖ м„ нғқмқҙкІ м§Җл§Ң мҙҲкё°мқҳ м—җмқҙм „нҠём—җкІҢ нғҗмҡ• м •мұ…мқҖ мһҳлӘ»лҗң н•ҷмҠөмңјлЎң к°ҖкІҢ н• к°ҖлҠҘм„ұмқҙ нҒ¬лӢӨ. мҰү, 충분н•ң кІҪн—ҳмқ„ нҶөн•ҙ м—җмқҙм „нҠёк°Җ ліҙмң н•ҳкі мһҲлҠ” нҒҗн•ЁмҲҳл“Өмқҙ мөңм Ғм—җ к°Җк№ҢмӣҢм§ҖкІҢ н•ҳлҠ” кІғмқҙ н•„мҡ”н•ҳлӢӨ. мқҙ л¬ём ңлҠ” к°•нҷ”н•ҷмҠөмқҳ мӨ‘мҡ”н•ң л¬ём ңлЎңм„ң нғҗн—ҳ(Exploration)мқҳ л¬ём ңмқҙлӢӨ. л”°лқјм„ң нғҗмҡ• м •мұ…мқ„ лҢҖмІҙн• мҲҳ мһҲлҠ” мғҲлЎңмҡҙ м •мұ…мқҙ н•„мҡ”н•ҳлӢӨ. м—җмқҙм „нҠёлЎң н•ҳм—¬кёҲ лҚ” нғҗн—ҳн•ҳкІҢ н• л°©лІ•мқҙ н•„мҡ”н•ң кІғмқҙлӢӨ. к·ё лҢҖм•Ҳмқҙ Оө-нғҗмҡ• м •мұ…мқҙлӢӨ. Оөл§ҢнҒјмқҳ нҷ•лҘ лЎң нғҗмҡ•м Ғмқҙм§Җ м•ҠмқҖ н–үлҸҷмқ„ м„ нғқн•ҳкІҢ н•ҳлҠ” кІғмқҙлӢӨ.
- 28. [нҢҢмқҙмҚ¬кіј мјҖлқјмҠӨлЎң л°°мҡ°лҠ” к°•нҷ”н•ҷмҠө] p.132 к·ёлҰј 4.21 1-Оөмқё нҷ•лҘ лЎңлҠ” нҳ„мһ¬ мғҒнғңм—җм„ң к°ҖмһҘ нҒ° нҒҗн•ЁмҲҳмқҳ к°’мқ„ к°Җм§ҖлҠ” н–үлҸҷмқ„ м„ нғқн•ңлӢӨ. мҰү, нғҗмҡ• м •мұ…мқ„ л”°лҘҙлҠ” кІғмқҙлӢӨ. н•ҳм§Җл§Ң нҳ„мһ¬ к°Җм§Җкі мһҲлҠ” нҒҗн•ЁмҲҳлҠ” мҲҳл ҙн•ҳкё° м „к№Ңм§ҖлҠ” нҺён–ҘлҸј мһҲлҠ”, м •нҷ•н•ҳм§Җ м•ҠмқҖ к°’мқҙлӢӨ. л”°лқјм„ң м—җмқҙм „нҠёлҠ” м •нҷ•н•ҳм§Җ м•ҠмқҖ нҒҗн•ЁмҲҳлҘј нҶ лҢҖлЎң нғҗмҡ•м ҒмңјлЎң н–үлҸҷн•ҳкё° ліҙлӢӨлҠ” мқјм •н•ң Оөмқё нҷ•лҘ лЎң м—үлҡұн•ң н–үлҸҷмқ„ н•ңлӢӨ.
- 29. Оө-нғҗмҡ• м •мұ…мқҖ нғҗмҡ• м •мұ„мқҳ лҢҖм•ҲмңјлЎңм„ң м—җмқҙм „нҠёк°Җ м§ҖмҶҚм ҒмңјлЎң нғҗн—ҳн•ҳкІҢ н•ңлӢӨ. л¬јлЎ Оө-нғҗмҡ• м •мұ…мқҖ мөңм Ғ нҒҗн•ЁмҲҳлҘј м°ҫм•ҳлӢӨ н•ҳлҚ”лқјлҸ„ Оөмқҳ нҷ•лҘ лЎң кі„мҶҚ нғҗн—ҳн•ңлӢӨлҠ” н•ңкі„к°Җ мһҲлӢӨ. л”°лқјм„ң н•ҷмҠөмқ„ 진н–үн•Ём—җ л”°лқј Оөмқҳ к°’мқ„ к°җмҶҢмӢңнӮӨлҠ” л°©лІ•лҸ„ мһҲлӢӨ. лҚ” л§ҺмқҖ н•ҷмҠө л°©лІ•мқҙ мһҲлҠ”лҚ° к·ёкұҙ лӮҳмӨ‘м—җ лӢӨлЈ° кІғмқҙлӢӨ.
- 30. мқҙмІҳлҹј мӮҙмӮ¬лҠ” GPIмқҳ м •мұ… нҸүк°ҖлҘј нҒҗн•ЁмҲҳлҘј мқҙмҡ©н•ң мӢңк°„м°Ё мҳҲмёЎмңјлЎң, нғҗмҡ• м •мұ… л°ңм „мқ„ Оө-нғҗмҡ• м •мұ…мңјлЎң ліҖнҷ”мӢңнӮЁ к°•нҷ”н•ҷмҠө м•Ңкі лҰ¬мҰҳмқҙлӢӨ. лҳҗн•ң м •мұ… мқҙн„°л Ҳмқҙм…ҳкіјлҠ” лӢ¬лҰ¬ лі„лҸ„мқҳ м •мұ… м—Ҷмқҙ Оө-нғҗмҡ• м •мұ…мқ„ мӮ¬мҡ©н•ҳлҠ” кІғмқҖ к°Җм№ҳ мқҙн„°л Ҳмқҙм…ҳм—җм„ң к·ё к°ңл…җмқ„ к°Җм ёмҳЁ кІғмқҙлӢӨ. мӮҙмӮ¬лҠ” к°„лӢЁнһҲ л‘җ лӢЁкі„лЎң мғқк°Ғн•ҳл©ҙ лҗңлӢӨ. 1. Оө-нғҗмҡ• м •мұ…мқ„ нҶөн•ҙ мғҳн”Ң [ ]мқ„ нҡҚл“қ 2. нҡҚл“қн•ң мғҳн”ҢлЎң лӢӨмқҢ мӢқмқ„ нҶөн•ҙ нҒҗн•ЁмҲҳ Q(S_t,A_t)лҘј м—…лҚ°мқҙнҠё нҒҗн•ЁмҲҳлҠ” м—җмқҙм „нҠёк°Җ к°Җ진 м •ліҙлЎңм„ң нҒҗн•ЁмҲҳмқҳ м—…лҚ°мқҙнҠёлҠ” м—җмқҙм „нҠё мһҗмӢ мқ„ м—…лҚ°мқҙнҠён•ҳлҠ” кІғкіј к°ҷлӢӨ.
- 31. мӮҙмӮ¬лҠ” мҳЁнҸҙлҰ¬мӢң(On-Policy) мӢңк°„м°Ё м ңм–ҙ, мҰү мһҗмӢ мқҙ н–үлҸҷн•ҳлҠ” лҢҖлЎң н•ҷмҠөн•ҳлҠ” мӢңк°„м°Ё м ңм–ҙмқҙлӢӨ. нғҗн—ҳмқ„ мң„н•ҙ м„ нғқн•ң Оө-нғҗмҡ• м •мұ…мқ„ мӢңн–үн•ҳлҠ” кіјм •м—җм„ң лһңлҚӨн•ң м•Ўм…ҳмқ„ м·Ён•ң кІғмқҳ кІ°кіјлЎң м—җмқҙм „нҠёк°Җ мөңм Ғмқҳ м •мұ…мқҙ м•„лӢҲлқј мһҳлӘ»лҗң м •мұ…мқ„ н•ҷмҠөн•ҳкІҢ лҗҳлҠ” кІҪмҡ°к°Җ л°ңмғқн• мҲҳ мһҲлӢӨ. н•ҳм§Җл§Ң к°•нҷ”н•ҷмҠөм—җм„ң нғҗн—ҳмқҖ м ҲлҢҖм ҒмңјлЎң н•„мҡ”н•ң мҡ”мҶҢмқҙкё°лҸ„ н•ҳлӢӨ. 충분н•ң нғҗн—ҳмқ„ н•ҳм§Җ м•Ҡмңјл©ҙ мөңм Ғ м •мұ…мқ„ н•ҷмҠөн•ҳм§Җ лӘ»н•ҳкё° л•Ңл¬ёмқҙлӢӨ. мқҙлҹ¬н•ң л”ңл Ҳл§ҲлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ мӮ¬мҡ©н•ҳлҠ” кІғмқҙ л°”лЎң мҳӨн”„нҸҙлҰ¬мӢң(Off-Policy) мӢңк°„м°Ё м ңм–ҙмқҙлӢӨ. лӢӨлҘё л§җлЎңлҠ” нҒҗлҹ¬лӢқмқҙлқјкі н•ңлӢӨ.
- 32. мҳӨн”„нҸҙлҰ¬мӢңмқҳ л§җк·ёлҢҖлЎң нҳ„мһ¬ н–үлҸҷн•ҳлҠ” м •мұ…кіјлҠ” лҸ…лҰҪм ҒмңјлЎң н•ҷмҠөн•ңлӢӨлҠ” кІғмқҙ нҒҗлҹ¬лӢқмқҳ м•„мқҙл””м–ҙмқҙлӢӨ. мҰү н–үлҸҷн•ҳлҠ” м •мұ…кіј н•ҷмҠөн•ҳлҠ” м •мұ…мқ„ л”°лЎң 분лҰ¬н•ңлӢӨ. м—җмқҙм „нҠёлҠ” н–үлҸҷн•ҳлҠ” м •мұ…мңјлЎң м§ҖмҶҚм Ғмқё нғҗн—ҳмқ„ н•ҳл©ҙм„ң л”°лЎң лӘ©н‘ң м •мұ…мқ„ 둬м„ң н•ҷмҠөмқҖ лӘ©н‘ң м •мұ…м—җ л”°лқјм„ң н•ңлӢӨ. л°ҳл©ҙ мӮҙмӮ¬м—җм„ңлҠ” л”°лЎң м •мұ…мқҙ мЎҙмһ¬н•ҳм§Җ м•Ҡмңјл©° лӢЁм§Җ нҳ„мһ¬ нҒҗн•ЁмҲҳм—җ л”°лқј н–үлҸҷмқ„ м„ нғқн–Ҳмқ„ лҝҗмқҙм—ҲлӢӨ. мӮҙмӮ¬м—җм„ң м—җмқҙм „нҠёлҠ” нҳ„мһ¬ мғҒнғң sм—җм„ң н–үлҸҷ aлҘј Оө-нғҗмҡ• м •мұ…м—җ л”°лқј м„ нғқн•ңлӢӨ. к·ёлҰ¬кі м—җмқҙм „нҠёлҠ” нҷҳкІҪмңјлЎңл¶Җн„° ліҙмғҒ rмқ„ л°ӣкі лӢӨмқҢ мғҒнғң s МҒ мқ„ л°ӣлҠ”лӢӨ. к·ёлҰ¬кі лӢӨмқҢ мғҒнғңмқё s МҒ м—җм„ң лҳҗлӢӨмӢң Оө-нғҗмҡ• м •мұ…м—җ л”°лқј лӢӨмқҢ н–үлҸҷмқ„ м„ нғқн•ң нӣ„м—җ к·ёкІғмқ„ н•ҷмҠөм—җ мғҳн”ҢлЎң мӮ¬мҡ©н•ңлӢӨ. н•ҳм§Җл§Ң нҒҗлҹ¬лӢқм—җм„ңлҠ” м—җмқҙм „нҠёк°Җ лӢӨмқҢ мғҒнғң s МҒ лҘј м•ҢкІҢ лҗҳл©ҙ s МҒ м—җм„ң к°ҖмһҘ нҒ° нҒҗн•ЁмҲҳлҘј нҳ„мһ¬ мғҒнғң sм—җм„ңмқҳ нҒҗн•ЁмҲҳмқҳ м—…лҚ°мқҙнҠём—җ мӮ¬мҡ©н•ңлӢӨ. м—җмқҙм „нҠёлҠ” мӢӨм ңлЎң s МҒ м—җм„ң м–ҙл–Ө н–үлҸҷмқ„ н–ҲлҠ”м§ҖмҷҖ мғҒкҙҖм—Ҷмқҙ нҳ„мһ¬ мғҒнғң sмқҳ нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён• л•ҢлҠ” s МҒ мқҳ мөңлҢҖ нҒҗн•ЁмҲҳлҘј мқҙмҡ©н•ңлӢӨ. л”°лқјм„ң нҳ„мһ¬ мғҒнғңмқҳ нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳкё° мң„н•ҙ н•„мҡ”н•ң мғҳн”ҢмқҖ <s,a,r,s МҒ>мқҙлӢӨ.
- 33. нҒҗлҹ¬лӢқмқҳ м—…лҚ°мқҙнҠё мҲҳмӢқмқҖ лӢӨмқҢкіј к°ҷлӢӨ. лӢӨмқҢ мӢқмқҙ лҚ” мқөмҲҷн•ң мӮ¬лһҢмқҙ мһҲмқ„ мҲҳлҸ„ мһҲлӢӨ.
- 34. мӮҙмӮ¬мҷҖ нҒҗлҹ¬лӢқмқҳ м—…лҚ°мқҙнҠё мӢқкіј лІЁл§Ң кё°лҢҖ л°©м •мӢқ, лІЁл§Ң мөңм Ғ л°©м •мӢқмқ„ лӢӨмӢң мӮҙнҺҙліҙмһҗ лІЁл§Ң кё°лҢҖ л°©м •мӢқ мӮҙмӮ¬ лІЁл§Ң мөңм Ғ л°©м •мӢқ нҒҗлҹ¬лӢқ мқҙлҘј нҶөн•ҙ м•Ң мҲҳ мһҲлҠ” м җмқҖ мӮҙмӮ¬м—җм„ңлҠ” нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳкё° мң„н•ҙ лІЁл§Ң кё°лҢҖ л°©м •мӢқмқ„ мӮ¬мҡ©н•ҳкі , нҒҗлҹ¬лӢқм—җм„ңлҠ” нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён•ҳкё° мң„н•ҙ лІЁл§Ң мөңм Ғ л°©м •мӢқмқ„ мӮ¬мҡ©н•ңлӢӨлҠ” кІғмқҙлӢӨ.
- 35. нҒҗлҹ¬лӢқмқ„ нҶөн•ҙ н•ҷмҠөн•ҳл©ҙ лӢӨмқҢ мғҒнғң s МҒ м—җм„ң мӢӨм ң м„ нғқн•ң н–үлҸҷмқҙ м•Ҳ мўӢмқҖ н–үлҸҷмқҙлқјлҸ„ к·ё м •ліҙк°Җ нҳ„мһ¬ мғҒнғң sмқҳ нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён• л•Ң нҸ¬н•Ёлҗҳм§Җ м•ҠлҠ”лӢӨ. мҷңлғҗн•ҳл©ҙ нҒҗлҹ¬лӢқм—җм„ң н•ҷмҠөм—җ мӮ¬мҡ©н–ҲлҚҳ лӢӨмқҢ мғҒнғңм—җм„ңмқҳ н–үлҸҷкіј мӢӨм ңлЎң лӢӨмқҢ мғҒнғңлЎң к°Җм„ң н•ң н–үлҸҷмқҙ лӢӨлҘҙкё° л•Ңл¬ёмқҙлӢӨ. мқҙмІҳлҹј мӢӨм ң нҷҳкІҪм—җм„ң н–үлҸҷмқ„ н•ҳлҠ” м •мұ…кіј нҒҗн•ЁмҲҳлҘј м—…лҚ°мқҙнҠён• л•Ң мӮ¬мҡ©н•ҳлҠ” м •мұ…мқҙ лӢӨлҘҙкё° л•Ңл¬ём—җ нҒҗлҹ¬лӢқмқ„ мҳӨн”„нҸҙлҰ¬мӢңлқјкі н•ңлӢӨ. нҒҗлҹ¬лӢқмқҖ мӮҙмӮ¬м—җм„ң л”ңл Ҳл§ҲмҳҖлҚҳ "нғҗн—ҳ vs мөңм Ғ м •мұ… н•ҷмҠө"мқҳ л¬ём ңлҘј м •мұ…мқҖ 분лҰ¬мӢңнӮӨкі н–үлҸҷ м„ нғқмқҖ Оө-нғҗмҡ• м •мұ…мңјлЎң, м—…лҚ°мқҙнҠёлҠ” лІЁл§Ң мөңм Ғ л°©м •мӢқмқ„ мқҙмҡ©н•ЁмңјлЎңмҚЁ н•ҙкІ°н–ҲлӢӨ.