Skip gram shirakawa_20141121
14 likes7,406 views

Skip-gramźŌźŪźļż╦ż─żżżŲĪóÜs╩ĘĄ─▒│Š░ÆiżŁż╦ż¬ż¬ż▐ż½ż╦šh├„żĘżŲżżż▐ż╣ĪŻūŅĮ³░kęŖżĄżņż┐PMIąą┴ąż╬ĘųĮŌż╚ż╬ķvéSąįż╚ĪóżĮż╬ėQĄŃż╦ż┐ż├ż┐ż╚żŁż╬Linear Regularityż╬ĮŌßŗż╦ż─żżżŲżŌżšżņż▐żĘż┐ĪŻ








![Copyright@2014 NTT DATA Mathematical Systems Inc.
9
Skip-gram źŌźŪźļŻ©+ Noise SamplingŻ®
?T. Mikolov+, Ī░Distributed Representations of Words and Phrases and their CompositionalityĪ▒, NIPS2013
?Skip-gram źŌźŪźļżŽĪóģgšZż╦═¼żĖ┤╬į¬ż╬ź┘ź»ź┐ż“ĖŅżĻĄ▒żŲż▐ż╣Ż©šZ ? ż╦ ĖŅżĻĄ▒żŲżķżņż┐ź┘ź»ź┐ż¼ ?? Ż®ĪŻ
?ź│®`źčź╣żŪ╣▓Ųż╣żļģgšZź┌źóŻ©?,?Ī½??Ż®żŽĪóź┘ź»ź┐ż╬─┌Ęeż¼┤¾żŁż» ż╩żļżĶż”ż╦żĘż▐ż╣ĪŻ
?ź│®`źčź╣ż╬?▒Čż╬éĆ╩²ż╬ģgšZź┌źóŻ©?,?Ī½??Ż®ż“äe═Šū„│╔żĘż▐ż╣ż¼Īó żĮżņżķż╬ģgšZź┌źóż╬ź┘ź»ź┐ż╬─┌ĘeżŽąĪżĄż»ż╩żļżĶż”ż╦żĘż▐ż╣ĪŻ
Skip-gram (+NS) maximize ? ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?), ????? ??,?;?=?????? ??????? = 11+exp (??????)](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/85/Skip-gram-shirakawa_20141121-9-320.jpg)
![Copyright@2014 NTT DATA Mathematical Systems Inc.
15
Skip-gram = PMIąą┴ąż╬ąą┴ąĘųĮŌ
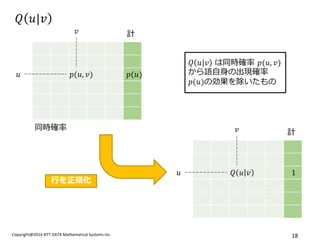
?ūŅĮ³Īó?=1,??(?,?)=?????? Ż©źµź╦ź░źķźÓĘų▓╝ż╬ĘeŻ®ż╚ż╚ż├ż┐ Skip-gram źŌźŪźļżŽ PMI ąą┴ąż╬ąą┴ąĘųĮŌż╦ŽÓĄ▒ż╣żļż│ż╚ż¼╩ŠżĄżņż▐żĘż┐ĪŻ
?O. Levy+, Ī░Neural Word Embedding as Implecit Matrix FactorizationĪ▒, NIPS2014
Skip-gram (+NS) maximize ? ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?), ????? ??,?;?=?????? ??????? = 11+exp (??????)
?
?
Pointwise Mutual Information
????,?=log ???,? ?????(?)
PMIąą┴ą](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/85/Skip-gram-shirakawa_20141121-15-320.jpg)
![Copyright@2014 NTT DATA Mathematical Systems Inc.
16
į^├„
Ž┬ėøż╬į^├„żŽĪó▒Š┘|Ą─ż╦żŽ┤╬ż╬šō╬─ż╦żĶżļżŌż╬żŪż╣ĪŻ I. J. Goodfellow+, Ī░Generative Adversarial NetworksĪ▒, NIPS2014
Ż©į^├„Ż® ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?) = ???,?log??,?;?+????,?log1???,?;? ?(?,?) żŪż╣ż¼Īó?log?+?log1??żŽ?=?/(?+?)żŪ╬©ę╗ż╬ūŅ┤¾éÄż“ż╚żļż╬żŪĪó ?(?) ż“ūŅ┤¾╗»ż╣żļż╚ĪóŽ┬ėøżžģ¦╩°żĘż▐ż╣ĪŻ ??,?;?= ???,? ???,?+???(?,?) =??log ???,? ????,? ??,?;?=??????ż╚▒╚ż┘żļż╚ ?????=log ???,? ????,?
ż“Ą├ż▐ż╣ĪŻżĶż├żŲĪó?=1,??=?????? ż╬ł÷║Žż╦żŽĪóPMIąą┴ąż╬ĘųĮŌ ż╦ż╩żĻż▐ż╣ĪŻ](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/85/Skip-gram-shirakawa_20141121-16-320.jpg)











![[DL▌åši╗ß]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=560&fit=bounds)


![[DL▌åši╗ß]Deep Learning Ą┌2š┬ ŠĆą╬┤·╩²](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)







![SSII2021 [OS2-02] ╔Ņīėč¦┴Ģż╦ż¬ż▒żļźŪ®`ź┐ÆłÅłż╬įŁ└Ēż╚ūŅą┬äėŽ“](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)









More Related Content
What's hot (20)
Similar to Skip gram shirakawa_20141121 (20)


















Skip gram shirakawa_20141121
- 1. Copyright@2014 NTT DATA Mathematical Systems Inc. Skip-gram ż╦ż─żżżŲ 1 2014/11/21 ░ū┤© ▀_ę▓ sirakawa@msi.co.jp
- 2. Copyright@2014 NTT DATA Mathematical Systems Inc. 2 king ©C man + woman = ?
- 3. Copyright@2014 NTT DATA Mathematical Systems Inc. 3 king ©C man + woman = queen ĪŁżŪż╣żĶż═Ż┐
- 4. Copyright@2014 NTT DATA Mathematical Systems Inc. 4 walked ©C walk + run = ?
- 5. Copyright@2014 NTT DATA Mathematical Systems Inc. 5 walked ©C walk + run = ran ĪŁżŪż╣żĶż═Ż┐
- 6. Copyright@2014 NTT DATA Mathematical Systems Inc. 6 france ©C paris + japan = ?
- 7. Copyright@2014 NTT DATA Mathematical Systems Inc. 7 france ©C paris + japan = tokyo ĪŁżŪż╣żĶż═Ż┐
- 8. Copyright@2014 NTT DATA Mathematical Systems Inc. 8 ╚╦ķgżŽźóź╩źĒźĖ®`ķvéSż“▀mŪąż╦ż╚żķż©żļ ż│ż╚ż¼żŪżŁż▐ż╣ĪŻ Skip-gramż╦┤·▒ĒżĄżņżļčįšZźŌźŪźļż╬▀M╗» ż╦żĶżĻĪóż│ż╬żĶż”ż╩źóź╩źĒźĖ®`ķvéSż“żó żļ│╠Č╚ÖCąĄĄ─ż╦ėŗ╦ŃżŪżŁżļżĶż”ż╦ż╩żĻż▐ żĘż┐ĪŻ
- 9. Copyright@2014 NTT DATA Mathematical Systems Inc. 9 Skip-gram źŌźŪźļŻ©+ Noise SamplingŻ® ?T. Mikolov+, Ī░Distributed Representations of Words and Phrases and their CompositionalityĪ▒, NIPS2013 ?Skip-gram źŌźŪźļżŽĪóģgšZż╦═¼żĖ┤╬į¬ż╬ź┘ź»ź┐ż“ĖŅżĻĄ▒żŲż▐ż╣Ż©šZ ? ż╦ ĖŅżĻĄ▒żŲżķżņż┐ź┘ź»ź┐ż¼ ?? Ż®ĪŻ ?ź│®`źčź╣żŪ╣▓Ųż╣żļģgšZź┌źóŻ©?,?Ī½??Ż®żŽĪóź┘ź»ź┐ż╬─┌Ęeż¼┤¾żŁż» ż╩żļżĶż”ż╦żĘż▐ż╣ĪŻ ?ź│®`źčź╣ż╬?▒Čż╬éĆ╩²ż╬ģgšZź┌źóŻ©?,?Ī½??Ż®ż“äe═Šū„│╔żĘż▐ż╣ż¼Īó żĮżņżķż╬ģgšZź┌źóż╬ź┘ź»ź┐ż╬─┌ĘeżŽąĪżĄż»ż╩żļżĶż”ż╦żĘż▐ż╣ĪŻ Skip-gram (+NS) maximize ? ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?), ????? ??,?;?=?????? ??????? = 11+exp (??????)
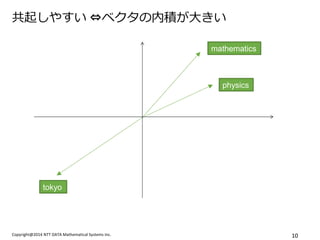
- 10. Copyright@2014 NTT DATA Mathematical Systems Inc. 10 ╣▓ŲżĘżõż╣żż ?ź┘ź»ź┐ż╬─┌Ęeż¼┤¾żŁżż mathematics physics tokyo
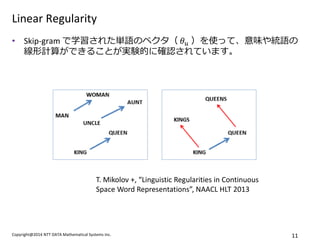
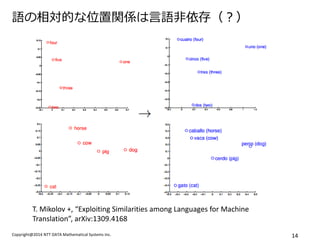
- 11. Copyright@2014 NTT DATA Mathematical Systems Inc. 11 Linear Regularity ?Skip-gram żŪč¦┴ĢżĄżņż┐ģgšZż╬ź┘ź»ź┐Ż© ?? Ż®ż“╩╣ż├żŲĪóęŌ╬ČżõĮyšZż╬ ŠĆą╬ėŗ╦Ńż¼żŪżŁżļż│ż╚ż¼īg“YĄ─ż╦┤_šJżĄżņżŲżżż▐ż╣ĪŻ T. Mikolov +, Ī░Linguistic Regularities in Continuous Space Word RepresentationsĪ▒, NAACL HLT 2013
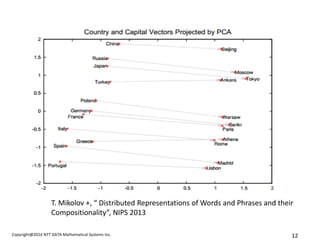
- 12. Copyright@2014 NTT DATA Mathematical Systems Inc. 12 T. Mikolov +, Ī░ Distributed Representations of Words and Phrases and their CompositionalityĪ▒, NIPS 2013
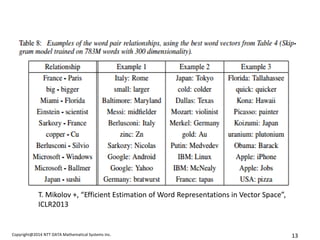
- 13. Copyright@2014 NTT DATA Mathematical Systems Inc. 13 T. Mikolov +, Ī░Efficient Estimation of Word Representations in Vector SpaceĪ▒, ICLR2013
- 14. Copyright@2014 NTT DATA Mathematical Systems Inc. 14 šZż╬ŽÓīØĄ─ż╩╬╗ų├ķvéSżŽčįšZĘŪę└┤µŻ©Ż┐Ż® T. Mikolov +, Ī░Exploiting Similarities among Languages for Machine TranslationĪ▒, arXiv:1309.4168
- 15. Copyright@2014 NTT DATA Mathematical Systems Inc. 15 Skip-gram = PMIąą┴ąż╬ąą┴ąĘųĮŌ ?ūŅĮ³Īó?=1,??(?,?)=?????? Ż©źµź╦ź░źķźÓĘų▓╝ż╬ĘeŻ®ż╚ż╚ż├ż┐ Skip-gram źŌźŪźļżŽ PMI ąą┴ąż╬ąą┴ąĘųĮŌż╦ŽÓĄ▒ż╣żļż│ż╚ż¼╩ŠżĄżņż▐żĘż┐ĪŻ ?O. Levy+, Ī░Neural Word Embedding as Implecit Matrix FactorizationĪ▒, NIPS2014 Skip-gram (+NS) maximize ? ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?), ????? ??,?;?=?????? ??????? = 11+exp (??????) ? ? Pointwise Mutual Information ????,?=log ???,? ?????(?) PMIąą┴ą
- 16. Copyright@2014 NTT DATA Mathematical Systems Inc. 16 į^├„ Ž┬ėøż╬į^├„żŽĪó▒Š┘|Ą─ż╦żŽ┤╬ż╬šō╬─ż╦żĶżļżŌż╬żŪż╣ĪŻ I. J. Goodfellow+, Ī░Generative Adversarial NetworksĪ▒, NIPS2014 Ż©į^├„Ż® ?(?)=??,?Ī½??[log?(?,?;?)]+???,?Ī½??log(1??(?,?;?) = ???,?log??,?;?+????,?log1???,?;? ?(?,?) żŪż╣ż¼Īó?log?+?log1??żŽ?=?/(?+?)żŪ╬©ę╗ż╬ūŅ┤¾éÄż“ż╚żļż╬żŪĪó ?(?) ż“ūŅ┤¾╗»ż╣żļż╚ĪóŽ┬ėøżžģ¦╩°żĘż▐ż╣ĪŻ ??,?;?= ???,? ???,?+???(?,?) =??log ???,? ????,? ??,?;?=??????ż╚▒╚ż┘żļż╚ ?????=log ???,? ????,? ż“Ą├ż▐ż╣ĪŻżĶż├żŲĪó?=1,??=?????? ż╬ł÷║Žż╦żŽĪóPMIąą┴ąż╬ĘųĮŌ ż╦ż╩żĻż▐ż╣ĪŻ
- 17. Copyright@2014 NTT DATA Mathematical Systems Inc. 17 Linear Regularity į┘┐╝ ?PMIąą┴ąż╬ĘųĮŌżŪżóżļż│ż╚ż“ŽļČ©ż╣żļż╚Īó ż╬żĶż”ż╩ķvéSżŽĪó╚╬ęŌż╬šZ ? ż╦ż┐żżżĘżŲĪó ż╚żżż”ķvéSż“ėļż©żļż│ż╚ż¼ż’ż½żĻż▐ż╣ĪŻīgļHĪó ????????=??????????? ?? ???????????????+?????=0 ?????,?????????,????????,?????+????,?????=0 ż│ż│żŪūŅßßż╬╩Įż╬ū¾▐xż“ėŗ╦Ńż╣żļż╚ log ?????? ????? ©M ??????? ??????? =0 ż╩ż╬żŪĪó╔ŽėøķvéSż“Ą├ż▐ż╣ĪŻ ????????=??????????? Ż©?????ż“????ż╩ż╔ż╚┬įėøŻ® ?????? ????? = ??????? ??????? ????? ???= ??? ??
- 18. Copyright@2014 NTT DATA Mathematical Systems Inc. 18 ??|? ? ? ?(?,?) ?(?) ėŗ ? ? ??? 1 ėŗ ąąż“š²ęÄ╗» ═¼Ģr┤_┬╩ ??|? żŽ═¼Ģr┤_┬╩ ?(?,?) ż½żķšZūį╔Ēż╬│÷¼F┤_┬╩ ?(?)ż╬ä┐╣¹ż“│²żżż┐żŌż╬
- 19. Copyright@2014 NTT DATA Mathematical Systems Inc. 19 Linear Regularity ????????=???????????? ?????? ????? = ??????? ??????? 1 1 1 1 ? ? ? ? ? ż│ż│ż╬▒╚ż¼│Żż╦Ą╚żĘżż ????Ī├ ???=?????Ī├ ????? king, man, queen, woman ╣╠ėąż╬│÷ ¼F┤_┬╩ż“¤oęĢż╣żļż╚Īóż╔ż¾ż╩šZż╦īØ żĘżŲżŌĪóżĮż╬šZż╬ų▄▐xż╦ĪĖ man ż╦▒╚ ż┘żŲ king ż¼ż╔żņż»żķżż│÷żõż╣żżż½Ī╣ żŽĪóĪĖwoman ż╦▒╚ż┘żŲ queen ż¼ż╔ żņż»żķżż│÷żõż╣żżż½Ī╣ż╚Ą╚żĘżżĪŻ
- 20. Copyright@2014 NTT DATA Mathematical Systems Inc. 20 ─µŽ“żŁżŽ│╔żĻ┴óż─ż½ ?ū¾é╚ż╬Ą╚╩Įż¼│╔żĻ┴óż├żŲżżżņżąĪóż╣ż┘żŲż╬šZ ? ż╦ż┐żżżĘżŲ ????,??????,??????,?+????,?=0 ż¼│╔żĻ┴óż─ż╬żŪĪó ? ?? ?? ??+?=0 ??? ??? ? ż╚ż╩żĻż▐ż╣ĪŻż│ż╬ż│ż╚ż½żķĪó ? ╚½╠Õż¼Åłżļ┐šķgż¼žNż½ż╩ł÷║ŽŻ©įöżĘż» żŽĪóż│ż╬┐šķgż╬┤╬į¬ż¼Ęų╔ó▒Ē¼Fż╬┤╬į¬ż╚ę╗ų┬ż╣żļł÷║ŽŻ®Īó ? ?? =??? ż╚ż╩żļż│ż╚żŌī¦ż½żņż▐ż╣ĪŻ QAvQav= ??? ??? ?? ?? =??? ?