




![R§«§‰§√§∆§fl§Î£∫
•™•È•Ø•Î–‘±£‘^∏∂§≠Lasso§Ú 𧶧≥§»§«∏ƒ…∆
? ¡PÑtÌó§Úπ§∑Ú§π§Î§≥§»§«°¢Lasso§À•™•È•Ø•Î–‘§Ú≥÷§ø§ª§Î
? ΩÒªÿ§œmsgps•—•√•±©`•∏§Œadaptive Lasso§Ú π§¶
? flxíkª˘ú §œBIC§Ú π§¶
fit.alasso <- msgps(X= X, y=c(y), penalty="alasso",gamma=1, lambda=0)
coeff.alasso <- coef(fit.alasso) %>>% data.frame %>>% select(BIC) %>>% unlist
sse.alasso <- (this_data$beta - coeff.alasso[-1])^2 %>>% sum
’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ(30ªÿ∆Ωæ˘)
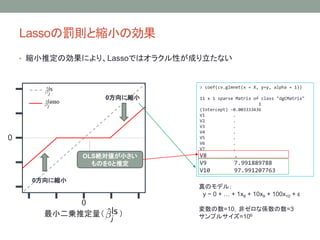
? •™•Í•∏• •Î§»±»§Ÿ§∆¡º§§æ´∂»
’ʧŒ•‚•«•Î£∫
y ~ 0 + °≠ + 10x8 + 10x9 + 10x10 + ¶≈
? ≠˝§Œ ˝=10
? ∑«•º•Ì§ ÇS ˝§Œ ˝=3
? •µ•Û•◊•Î•µ•§•∫§Ú–Ï°©§À¥Û§≠§Ø§π§Î
Õ∆∂®æ´∂»=’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ](https://image.slidesharecdn.com/oraclepropertyandhdmpkgrigorouslasso-160619012516/85/Oracle-property-and_hdm_pkg_rigorouslasso-11-320.jpg)




Oracle property and_hdm_pkg_rigorouslasso
- 1. §Ë§§•‚•«•Î§Úflx§”§ø§§ °∞The Oracle Properties of Feature Selection using Lassos°± £±£Æ°∏¡PÑt∏∂§≠ªÿ颧»•«©`•øΩ‚Œˆ≠hæ≥R°π§Œ“ª≤ø§ÚR§«•»•Ï©`•π§∑§fi§π (ªƒƒæ –¢÷Œ£¨•™•⁄•Ï©`•∑•Á•Û•∫?•Í•µ©`•¡2013 ƒÍ 5 ‘¬∫≈£¨261-266) £≤£Æ{hdm} package§ÚΩBΩȧ∑§fi§π (DJ Stekhoven, P B®πhlmann (2011), Bioinformatics 28 (1), 112-118) µ⁄£µ£¥ªÿR√„è䪷£¿ñ|æ©£®#TokyoR£© Lasso§À§™§±§Î≠˝flxík§»•™•È•Ø•Î–‘ Æ∑÷§ •µ•Û•◊•Î•µ•§•∫§ •«©`•ø§Àåù§π§Î ÷∑®§Œ±»›^ ≥¨∏fl¥Œ‘™£®p>>n£©§ •«©`•ø§Àåù§π§Î ÷∑®§Œ±»›^
- 2. ≠˝flxík(•‚•«•Îflxík) §…§¶§∑§∆§fi§π§´? •™•⁄•Ï©`•∑•Á•Û•∫?•Í•µ©`•¡2013 ƒÍ 5 ‘¬∫≈£¨261-266
- 3. Lasso ? æÄ–Œ÷ÿªÿ颕‚•«•Î§«°¢◊Ó–°∂˛Å\∑®§«ÇS ˝§ÚÕ∆∂®§Ú§π§ÎÎH§À°¢ Õ∆∂®¡ø(¶¬)§ŒΩ~åùÇé§Ú¥Û§≠§Ø§∑§ø§Ø§ §§ ? Œ¥∂®Å\ ˝∑®§«ï¯§Ø§»£∫ |¶¬|§Œ¥Û§≠§µ§Àåù§π§Î¡PÑtÌó◊Ó–°∂˛Å\∑® ¶À§œ¡PÑt§Œ¥Û§≠§µ§Ú ’{’˚§π§Î•—•È•·©`•ø ¶¬§ŒΩ~åùÇé§Ú¥Û§≠§µ§Ú ∂® ˝ £Ù “‘œ¬§À“÷§®§ø§§ ◊Ó–°∂˛Å\∑®
- 4. Lasso§»â‰ ˝flxík Lasso§À§Ë§√§∆°∏§Ë§§•‚•«•Î°π§ÚÕ∆∂®§∑§ø§§ ? æflõƒ§ ÷æA§≠§»§∑§∆§œ°¢¡PÑt§Œè䧵£®¶À£©§ÚõQ§·§ø§§ ? ¶À °˙ 0 (no penalty) §«§œ°¢¡PÑt§Œ§ §§÷ÿªÿé¢ ? ¶À °˙ °fi §«§œ°¢∂® ˝Ì󧿧±§Œ•‚•«•Î Õ∆∂®§µ§Ï§ø•‚•«•Î§Œ °∏¡º§µ°π§»§œ? §ø§»§®§–°¢Cross Validation §« ¶À§ÚõQ§·§Îàˆ∫œ°£ •‚•«•Î§Œ¡º§µ§œ Cross Validation Error§Œ–°§µ§µ £ø
- 5. Lasso§Œâ‰ ˝flxík§»•™•È•Ø•Î–‘£®Oracle Property£© ’ʧŒ•‚•«•Î§Ú§ §Î§Ÿ§Øæ´∂»¡º§Ø‘Ÿ¨F§∑§ø§§ ? flxík§µ§Ï§Î≠˝§Œ“ª÷¬–‘£®selection consistency£© ? ÷ÿ“™§ ≠˝§Ú»°§Í§≥§‹§µ§∫flxík§∑°¢•Œ•§•∫§»§ §Î≠˝§œ§π§Ÿ§∆≥˝Õ‚§π§Î ? •µ•Û•◊•Î•µ•§•∫n §¨¥Û§≠§Ø§ §Î§»§≠£¨0 §«§ §§ÇS ˝£®¶¬j = 0£©§Ú≥÷§ƒ’h√˜â‰ ˝§¨’˝§∑§Øflxík§µ§Ï§Î¥_¬ §¨1 §ÀÖß ¯§π§Î ? Õ∆∂®¡ø§Œ“ª÷¬–‘£®estimation consistency£© ? ∑«•º•Ì§ ÇS ˝§ŒÕ∆∂®¡ø§œ°¢’ÊÇé§ÀÖß ¯§π§Î ? 0 §«§ §§ÇS ˝§Ú≥÷§ƒ’h√˜â‰ ˝§Àåù§π§ÎÕ∆∂®¡ø§¨°¢ùuΩ¸≤ª∆´£¨ùuΩ¸’˝“é–‘§Ú≥÷§ƒ J. Fan and R. Li, Variable selection via nonconcave penalized likelihood and its oracle properties. Jour-nal of the American Statistical Association, 96 , 1348®C1360, 2001.
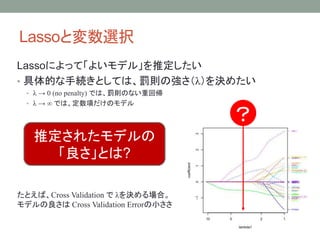
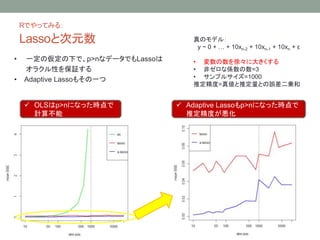
- 6. R§«§‰§√§∆§fl§Î: Lasso§œ•™•È•Ø•Î–‘§Ú≥÷§ø§ §§£®£±£© > summary(lm(y~X) ) Call: lm(formula = y ~ X) Residuals: Min 1Q Median 3Q Max -4.3396 -0.6766 0.0031 0.6782 4.1351 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.025e-03 3.172e-03 0.323 0.7467 X1 2.481e-03 3.169e-03 0.783 0.4336 X2 2.480e-03 3.169e-03 0.782 0.4340 X3 -3.055e-03 3.168e-03 -0.964 0.3349 X4 2.829e-04 3.174e-03 0.089 0.9290 X5 -2.657e-03 3.162e-03 -0.840 0.4007 X6 -1.525e-03 3.155e-03 -0.483 0.6288 X7 5.367e-03 3.168e-03 1.694 0.0902 . X8 1.006e+00 3.176e-03 316.898 <2e-16 *** X9 1.000e+01 3.168e-03 3156.907 <2e-16 *** X10 1.000e+02 3.179e-03 31454.897 <2e-16 *** --- Signif. codes: 0 °Æ***°Ø 0.001 °Æ**°Ø 0.01 °Æ*°Ø 0.05 °Æ.°Ø 0.1 °Æ °Ø 1 Residual standard error: 1.003 on 99989 degrees of freedom Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999 F-statistic: 9.993e+07 on 10 and 99989 DF, p-value: < 2.2e-16 > coef(cv.glmnet(x = X, y=y, alpha = 1)) 11 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) -0.003333436 V1 . V2 . V3 . V4 . V5 . V6 . V7 . V8 . V9 7.991889788 V10 97.991207763 Õ¨§∏•«©`•ø§Àåù§∑§∆£∫ ? 8∑¨ƒø§Œâ‰ ˝§¨œ˚§®§∆§§§Î ? Õ∆∂®Ç駂ƒøúp§Í§∑§∆§§§Î? ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 1x8 + 10x9 + 100x10 + ¶≈ ≠˝§Œ ˝=10£¨∑«•º•Ì§ ÇS ˝§Œ ˝=3 •µ•Û•◊•Î•µ•§•∫=106 ÷ÿªÿé¢ Lasso
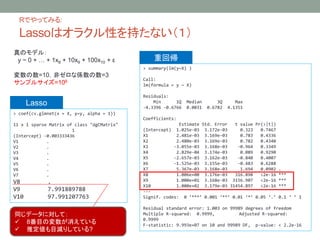
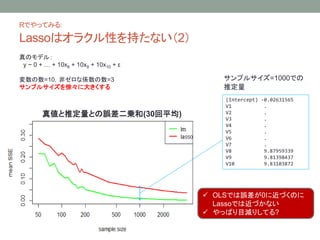
- 7. R§«§‰§√§∆§fl§Î: Lasso§œ•™•È•Ø•Î–‘§Ú≥÷§ø§ §§£®2£© (Intercept) -0.02631565 V1 . V2 . V3 . V4 . V5 . V6 . V7 . V8 9.87959339 V9 9.81398437 V10 9.83103872 •µ•Û•◊•Î•µ•§•∫=1000§«§Œ Õ∆∂®¡ø ’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ(30ªÿ∆Ωæ˘) ? OLS§«§œ’`≤Ó§¨0§ÀΩ¸§≈§Ø§Œ§À Lasso§«§œΩ¸§≈§´§ §§ ? §‰§√§—§Íƒøúp§Í§∑§∆§Î? ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 10x8 + 10x9 + 10x10 + ¶≈ ≠˝§Œ ˝=10£¨∑«•º•Ì§ ÇS ˝§Œ ˝=3 •µ•Û•◊•Î•µ•§•∫§Ú–Ï°©§À¥Û§≠§Ø§π§Î
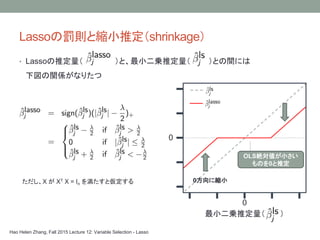
- 8. Lasso§Œ¡PÑt§»øs–°Õ∆∂®£®shrinkage£© §ø§¿§∑°¢X §¨ XT X = In §Úú∫§ø§π§»Å¢∂®§π§Î 0 0 0∑ΩœÚ§Àøs–° OLSΩ~åùÇ駨–°§µ§§ §‚§Œ§Ú0§»Õ∆∂® ◊Ó–°∂˛Å\Õ∆∂®¡ø£® £© Hao Helen Zhang, Fall 2015 Lecture 12: Variable Selection - Lasso ? Lasso§ŒÕ∆∂®¡ø£® £©§»°¢◊Ó–°∂˛Å\Õ∆∂®¡ø£® £©§»§ŒÈg§À§œ œ¬á̧ŒÈvÇS§¨§ §Í§ø§ƒ
- 9. Lasso§Œ¡PÑt§»øs–°§ŒÑøπ˚ ? øs–°Õ∆∂®§ŒÑøπ˚§À§Ë§Í°¢Lasso§«§œ•™•È•Ø•Î–‘§¨≥…§Í¡¢§ø§ §§ 0 0 0∑ΩœÚ§Àøs–° 0∑ΩœÚ§Àøs–° OLSΩ~åùÇ駨–°§µ§§ §‚§Œ§Ú0§»Õ∆∂® ◊Ó–°∂˛Å\Õ∆∂®¡ø£® £© > coef(cv.glmnet(x = X, y=y, alpha = 1)) 11 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) -0.003333436 V1 . V2 . V3 . V4 . V5 . V6 . V7 . V8 . V9 7.991889788 V10 97.991207763 ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 1x8 + 10x9 + 100x10 + ¶≈ ≠˝§Œ ˝=10£¨∑«•º•Ì§ ÇS ˝§Œ ˝=3 •µ•Û•◊•Î•µ•§•∫=106
- 10. •™•È•Ø•Î–‘±£‘^∏∂§≠Lasso H. Zou: The adaptive lasso and its oracle properties, Journal of the American Statistical Association, 101, 1418®C1429, 2006. Hao Helen Zhang, Fall 2015, Lecture 13: Variable Selection - Beyond LASSO •«©`•ø“¿¥Êµƒ§À◊Óflm§ ÷ÿ§fl§¨flx§–§Ï§Î Adaptive Lasso§Œ§€§´§À§‚…´°©§»Ã·∞∏§µ§Ï§∆§§§Î§¨∏Óê€ Adaptive Lasso ? Õ∆∂®§Œ∆´§Í§Úúp…Ÿ§µ§ª§Î÷ÿ§fl§≈§± ? 0 §ÀΩ¸§§Õ∆∂®¡ø§Àåù§∑§∆§œ¥Û§≠§ ÷ÿ§fl§Úflm”√§∑§∆ 0 §À§π§Î ? Ω~åùÇ駌¥Û§≠§ Õ∆∂®¡ø§Àåù§∑§∆§œ£¨–°§µ§ ÷ÿ§fl§Úflm”√§π§Î§≥§»§«øs–°§ŒÑøπ˚§Úúp§È§π ? 2∂ŒÎA§ŒÕ∆∂® ÷Ìò ? ¶¬ §Œ≥ı∆⁄Õ∆∂®¡ø §Ú«Û§·§Î ? £±§Ú¿˚”√§∑§ø÷ÿ§fl§Ú¿˚”√§π§Î?£± ¡PÑt∏∂§≠ªÿ颧ږ–§¶
- 11. R§«§‰§√§∆§fl§Î£∫ •™•È•Ø•Î–‘±£‘^∏∂§≠Lasso§Ú 𧶧≥§»§«∏ƒ…∆ ? ¡PÑtÌó§Úπ§∑Ú§π§Î§≥§»§«°¢Lasso§À•™•È•Ø•Î–‘§Ú≥÷§ø§ª§Î ? ΩÒªÿ§œmsgps•—•√•±©`•∏§Œadaptive Lasso§Ú 𧶠? flxíkª˘ú §œBIC§Ú 𧶠fit.alasso <- msgps(X= X, y=c(y), penalty="alasso",gamma=1, lambda=0) coeff.alasso <- coef(fit.alasso) %>>% data.frame %>>% select(BIC) %>>% unlist sse.alasso <- (this_data$beta - coeff.alasso[-1])^2 %>>% sum ’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ(30ªÿ∆Ωæ˘) ? •™•Í•∏• •Î§»±»§Ÿ§∆¡º§§æ´∂» ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 10x8 + 10x9 + 10x10 + ¶≈ ? ≠˝§Œ ˝=10 ? ∑«•º•Ì§ ÇS ˝§Œ ˝=3 ? •µ•Û•◊•Î•µ•§•∫§Ú–Ï°©§À¥Û§≠§Ø§π§Î Õ∆∂®æ´∂»=’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ
- 12. Lasso§»¥Œ‘™ ˝ ? èæ¿¥§Œªÿé¢∑÷Œˆ§Œ ˝—ßµƒÕ◊µ±–‘§œ°¢p<nÃıº˛œ¬§«±£‘^§µ§Ï§∆§§§ø ? ∏fl¥Œ‘™•«©`•ø(p>n)§Œàˆ∫œ°¢§Ω§Ï§¨∆∆æ`§π§Î°£§§§Ô§Ê§Î°∏¥Œ‘™§ŒÖ‚§§°π ? Lasso§«§œ•π•—©`•π–‘§ÚÅ¢∂®§π§Î ? °∏∫Ú—a≠˝§Œ§ §´§«’ʧÀÑøπ˚§Ú≥÷§ƒâ‰ ˝§Œ ˝(d)§œ∑«≥£§À…Ÿ ˝§«§¢§Î°π§»§§§¶Å¢∂® ? p>n>>d ? “ª∂®§ŒÅ¢∂®§Œœ¬§«°¢p>n§ •«©`•ø§«§‚•™•È•Ø•Î–‘§Ú±£‘^§π§Î ? Adaptive Lasso§‚§Ω§Œ“ª§ƒ ? Huang, J. et al.: Adaptive lasso for sparse high dimensional regression, Stat. Sin., 18: 1603-1618, 2007. •≤•Œ•‡•Ô•§•…ÈvflBΩ‚Œˆ§ŒΩy”ã—ßµƒÜñÓ}µ„§»§Ω§ŒΩ‚õQ ÷≤ƒæÉû∑Ú, ÃÔåm‘™, “Ω—ß§Œ§¢§Ê§fl µ⁄230éÜ12∫≈(2009ƒÍ9‘¬19»’∫≈) (1079-1080)
- 13. R§«§‰§√§∆§fl§Î£∫ Lasso§»¥Œ‘™ ˝ ? “ª∂®§ŒÅ¢∂®§Œœ¬§«°¢p>n§ •«©`•ø§«§‚Lasso§œ •™•È•Ø•Î–‘§Ú±£‘^§π§Î ? Adaptive Lasso§‚§Ω§Œ“ª§ƒ ? OLS§œp>n§À§ §√§øïrµ„§« ”ãÀ„≤ªƒ‹ ? Adaptive Lasso§‚p>n§À§ §√§øïrµ„§« Õ∆∂®æ´∂»§¨êôªØ ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 10xn-2 + 10xn-1 + 10xn + ¶≈ ? ≠˝§Œ ˝§Ú–Ï°©§À¥Û§≠§Ø§π§Î ? ∑«•º•Ì§ ÇS ˝§Œ ˝=3 ? •µ•Û•◊•Î•µ•§•∫=1000 Õ∆∂®æ´∂»=’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ
- 14. Lasso§»¥Œ‘™ ˝ ? ∏fl¥Œ‘™•«©`•ø(p>>n)§Œàˆ∫œ 1. ∫Œ§È§´§Œ ÷Ìò§«§§§√§ø§Û¥Œ‘™àRøs§Ú––§¶ 2. àRøs§∑§ø•«©`•ø§«°¢§¢§È§ø§·§∆ÇS ˝§Ú∏flæ´∂»§ÀÕ∆∂®§π§Î ? ÷∑®§Œ¿˝ ? p>>n§«§‚°¢“ª∂®§ŒÅ¢∂®§Œœ¬§«flxík§Œ“ª÷¬–‘§¨±£‘^§µ§Ï§∆§§§Î ? Adaptive Lasso ? Huang, J. et al.: Adaptive lasso for sparse high dimensional regression, Stat. Sin., 18: 1603-1618, 2007. ? L2 boosting ? Buhlmann, P.: Boosting for high-dimensional linear models. Ann. Statist., 34:559-583, 2006. ? ≠˝§Œ•È•Û•≠•Û•∞§Àª˘§≈§Ø•π•Ø•Í©`•À•Û•∞ ? SURE independence screening (SIS) ? Fan, J. and Lv, J.: Sure independence screening for ultrahigh dimensional feature space (with discussion). J. R. Statist. Soc B, 70: 849-911, 2008. ? Lasso§«ÓBèà§Î ? ’`§√§∆∑«•º•Ì§»§∑§øÇS ˝§œ§π§Ÿ§∆•º•Ì§ÀΩ¸§§Ç駫Öߧfi§Î–‘Ÿ|§Ú 𧶠? Meinshausen, N. and Yu, B.: Lasso-type recovery of sparse representations of high-dimensional data. To appear in Ann. Statist. •≤•Œ•‡•Ô•§•…ÈvflBΩ‚Œˆ§ŒΩy”ã—ßµƒÜñÓ}µ„§»§Ω§ŒΩ‚õQ ÷≤ƒæÉû∑Ú, ÃÔåm‘™, “Ω—ß§Œ§¢§Ê§fl µ⁄230éÜ12∫≈(2009ƒÍ9‘¬19»’∫≈) (1079-1080)
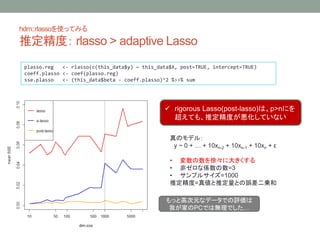
- 15. °∞rigorous°± lasso in hdm package rlasso§ŒÃÿ…´ ? Post-Lasso§À§Ë§Î°¢â‰ ˝ ¬«∞§Œ•π•Ø•Í©`•À•Û•∞ ? Lasso§«ÇS ˝§ŒÕ∆∂®¡ø§¨0§À§µ§Ï§ø≠˝§Ú≥˝»•§∑§∆§´§È°¢◊Ó–°∂˛Å\∑®§Ú§™§≥§ §¶ ? ¡PÑtèä∂»(¶À)§Ú¿Ì’쵃±≥æ∞§Œ§‚§»§«”Χ®§Î ? ’`≤Ó§Œµ»∑÷…¢–‘§ŒÅ¢∂®§Œ”–üo °¡ data-driven or Not §«°¢∫œ”㣥•—•ø©`•Û§Œ¡PÑtÌó§Ú÷∞∏ ? Õ∆∂®§∑§øÇS ˝§Œ–≈Óm«¯Èg§Ú÷π©§π§Î ? Shooting Lasso Algorithm§À§Ë§Î∏flÀŸªØ V Chernozhukov, C Hansen, M Spindler (2016+). hdm: High-Dimensional Metrics R Journal, forthcoming https://cran.rstudio.com/web/packages/hdm/ ∏fl¥Œ‘™•«©`•ø(p>>n)§Œàˆ∫œ 1. ∫Œ§È§´§Œ ÷Ìò§«§§§√§ø§Û¥Œ‘™àRøs§Ú––§¶ 2. àRøs§∑§ø•«©`•ø§Œ§‚§»§«°¢§¢§È§ø§·§∆ÇS ˝§Ú∏flæ´∂»§ÀÕ∆∂®§π§Î
- 16. hdm::rlasso§Ú π§√§∆§fl§Î rlasso( formula, data, post = TRUE, # TRUE§«Post-Lasso°£ FALSE§«∂¿◊‘§Œ¡PÑt§¿§±rigorous§ Lasso intercept = TRUE, # TRUE§««–∆¨Ìó(¶¬0£©§Œ¡PÑt∏∂§≠Õ∆∂®§Ú§∑§ §§ penalty = list(homoscedastic = FALSE, # FALSE§«’`≤Ó§Œµ»∑÷…¢–‘§ÚÅ¢∂®§∑§ §§ X.dependent.lambda = FALSE, # TRUE§«•«©`•ø“¿¥Êµƒ§ ¶À§Œflxík§Ú§π§Î lambda.start = NULL, c = 1.1, gamma = 0.1/log(n)), control = list(numIter =15, tol = 10^-5, threshold = NULL), ...)
- 17. hdm::rlasso§Ú π§√§∆§fl§Î Õ∆∂®æ´∂»£∫ rlasso > adaptive Lasso plasso.reg <- rlasso(c(this_data$y) ~ this_data$X, post=TRUE, intercept=TRUE) coeff.plasso <- coef(plasso.reg) sse.plasso <- (this_data$beta - coeff.plasso)^2 %>>% sum ? rigorous Lasso(post-lasso)§œ°¢p>n§À§Ú ≥¨§®§∆§‚°¢Õ∆∂®æ´∂»§¨êôªØ§∑§∆§§§ §§ §‚§√§»∏fl¥Œ‘™§ •«©`•ø§«§Œ‘uÅ˝§œ Œ“§¨º“§ŒPC§«§œüo¿Ì§«§∑§ø°≠ ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 10xn-2 + 10xn-1 + 10xn + ¶≈ ? ≠˝§Œ ˝§Ú–Ï°©§À¥Û§≠§Ø§π§Î ? ∑«•º•Ì§ ÇS ˝§Œ ˝=3 ? •µ•Û•◊•Î•µ•§•∫=1000 Õ∆∂®æ´∂»=’ÊÇ駻Õ∆∂®¡ø§»§Œ’`≤Ó∂˛Å\∫Õ
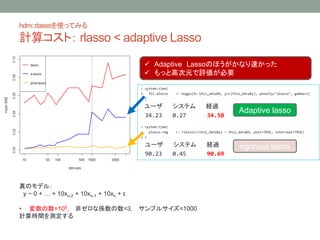
- 18. hdm::rlasso§Ú π§√§∆§fl§Î ”ãÀ„•≥•π•»£∫ rlasso < adaptive Lasso > system.time( + fit.alasso <- msgps(X= this_data$X, y=c(this_data$y), penalty="alasso", gamma=1) + ) •Ê©`•∂ •∑•π•∆•‡ ΩUfl^ 34.23 0.27 34.50 > system.time( + plasso.reg <- rlasso(c(this_data$y) ~ this_data$X, post=TRUE, intercept=TRUE) + ) •Ê©`•∂ •∑•π•∆•‡ ΩUfl^ 90.23 0.45 90.69 Adaptive lasso rigorous lasso ? Adaptive Lasso§Œ§€§¶§¨§´§ §ÍÀŸ§´§√§ø ? §‚§√§»∏fl¥Œ‘™§«‘uÅ˝§¨±ÿ“™ ’ʧŒ•‚•«•Î£∫ y ~ 0 + °≠ + 10xn-2 + 10xn-1 + 10xn + ¶≈ ? ≠˝§Œ ˝=105£¨ ∑«•º•Ì§ ÇS ˝§Œ ˝=3£¨ •µ•Û•◊•Î•µ•§•∫=1000 ”ãÀ„ïrÈg§Úúy∂®§π§Î
- 19. §fi§»§· •™•⁄•Ï©`•∑•Á•Û•∫?•Í•µ©`•¡2013 ƒÍ 5 ‘¬∫≈£¨261-266 °∞rigorous°± lasso V Chernozhukov, C Hansen, M Spindler (2016+). hdm: High-Dimensional Metrics R Journal, forthcoming https://cran.rstudio.com/web/packages/hdm/