

![深層学習の広がり 2
[Glow: Generative Flow with Invertible 1x1 Convolutions. Kingma
and Dhariwal, 2018]
AlphaGo/Zero 画像の生成
画像の変換
画像認識
自動翻訳
[Zhu, Park, Isola, and Efros: Unpaired image-to-image translation using
cycle-consistent adversarial networks. ICCV2017.]
様々なタスクで高い精度
[Silver et al. (Google Deep Mind): Mastering the game of Go with
deep neural networks and tree search, Nature, 529, 484—489, 2016]
[Wu et al.: Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv:1609.08144]
[He, Gkioxari, Dollár, Girshick: Mask R-CNN, ICCV2017]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-2-320.jpg)
![諸分野への波及 3
[Litjens, et al. (2017)]
医療分野における「深層学習」
を用いた論文数
医療
- 人を超える精度
(FROC73.3% -> 87.3%)
- 悪性腫瘍の場所も特定
[Detecting Cancer Metastases on
Gigapixel Pathology Images: Liu et
al., arXiv:1703.02442, 2017]
[Niepert, Ahmed&Kutzkov: Learning Convolutional Neural Networks
for Graphs, 2016]
[Gilmer et al.: Neural Message Passing for Quantum Chemistry, 2017]
[Faber et al.:Machine learning prediction errors better than DFT
accuracy, 2017.]
量子化学計算,分子の物性予測
[Google AI Blog, “Deep Learning for Robots: Learning from Large-
Scale Interaction,” 2016/5/8]
ロボット](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-3-320.jpg)
![ImageNet 4
ImageNet: 1,000カテゴリ,約120万枚の訓練画像データ
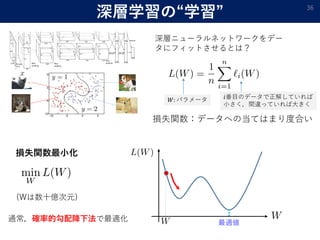
ILSVRC (ImageNet Large Scale Visual Recognition Competition)
[J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei.
ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-4-320.jpg)

![表現能力「万能近似能力」
理論的にはデータが無限にあり,素子数が無限
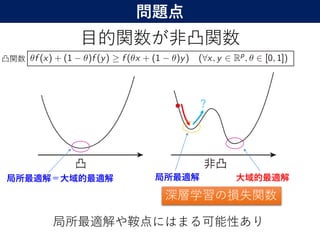
にあるニューラルネットワークを用いればどん
な問題でも学習できる.
12
深層ニューラルネットワークのモデルは連続関数?L1可積分関数?
L2可積分関数の空間で稠密
真の関数有限和近似(2層NN)
ニューラルネットワークはどんな関数も
任意の精度で近似できる.
「関数近似理論」
[Sonoda & Murata, 2015]
[Hecht-Nielsen,1987][Cybenko,1989]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-12-320.jpg)
![Fourier変換との関係
? Fourier変換
18
? Ridgelet変換
ウェーブレット変換 + ラドン変換
cos,sinの代わりに,各素子の出力の
足し合わせで関数を表現
CTスキャン
Ridgelet変換による復元定理
[Wikipedia,フーリエ変換]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-18-320.jpg)
![これまででわかったこと
? [理論] 万能近似能力という意味では2層で十分.
? [実際] 実際は多層を使うことが多い.
→ この差はどう埋める?
20
カーネル法
従来法
多層ニューラルネット
深層学習
→ 推定/近似の「精度」を比べてみる.](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-20-320.jpg)
![なぜ深層学習が良いのか?
? いろいろな理論がある.
21
深
層
カ
ー
ネ
ル
縮小ランク回帰
特徴空間の次元
が低い状況は深
層学習が得意
区分滑らかな関数
不連続な関数の
推定は深層学習
が得意
Besov空間
滑らかさが非一
様な関数の推定
は深層学習が得
意
低次元データ
データが低次元
部分空間上に分
布していたら深
層学習が有利
[Suzuki, 2019]
[Schmidt-Hieber, 2019] [Nakada&Imaizumi,
2019][Chen et al., 2019][Suzuki&Nitanda, 2019][Imaizumi&Fukumizu, 2019]
推
定
精
度](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-21-320.jpg)
![深層学習の適応能力 22
[Suzuki, ICLR2019]
深層学習はBesov空間(????,??
??
)の元を推定するのにミニマックス最適レートを達成する.
(複雑な関数形状に適応的にフィットすることができる)
深層学習には「高い適応力がある」ことを解明
明らかに犬 明らかに猫犬と猫の中間
少し絵が変わっても
「犬」のまま
少し絵が変わっても
「猫」のまま
少し絵が変わると
犬/猫のどちらかに偏る
猫の度合い
滑らかでない
急激に変化滑らか
滑らか
どこが重要でどこが重要でないかを見分けて,重要な部分を重点的に学習
→ 多層だから可能](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-22-320.jpg)
![「浅い」学習との比較 23
?
(??: sample size,??: uniformity of smoothness,??: smoothness)
(カーネルリッジ回帰,KNN法,シーブ法など)
深層でない学習方法
最適ではない
深層学習
最適
? 深層学習は“必要最低限”の情報のみを抽出して学習
→学習効率が良い
? 浅い学習は“無駄な”情報も捉えて学習
→学習効率が悪い (無駄な情報に左右されてしまう)
理論上これ以上改善できない精度を達成できている.
推定誤差(平均二乗誤差 E ??? ? ??? 2
)がサンプルサイズが増えるにつれどれだけ速く減少するか
[Suzuki, ICLR2019]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-23-320.jpg)
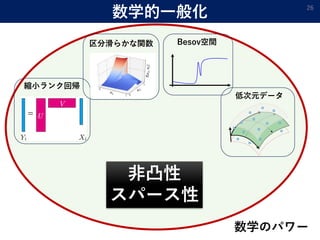
![数学的に一般化 25
[Satoshi Hayakawa and Taiji Suzuki: On the minimax optimality and superiority of deep neural network
learning over sparse parameter spaces. arXiv:1905.09195.]
「滑らかさの非一様性」「不連続性」「データの低次元性」
凸結合を取って崩れる性質をもった関数の学習は深層学習が強い
→ 様々な性質を“凸性”で統一的に説明
例:ジャンプが3か所の区分定数関数
+ =
0.5x 0.5x
ジャンプ3か所 ジャンプ3か所 ジャンプ6か所
→ さらには「スパース推定」という観点からも説明できる.
深層:1/??, カーネル: 1/ ??](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-25-320.jpg)

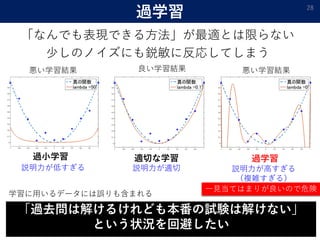
![従来の学習理論 29
過学習適切な学習過小学習
[Neyshabur et al., ICLR2019]
ネットワークのサイズを大きくしても過学習しない
実際は...
データサイズ:130万
モデルパラメータサイズ:10億
[Xu et al., 2018]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-29-320.jpg)
![深層ニューラルネットの冗長性 30
? 深層学習は重要な情報に絞って特徴抽出
→ 構造的に冗長性が現れる.
重視 簡単簡単
パラメータ数 ? データサイズ
数十億 数百万 数十万
? 実質的自由度
[仮説] 見かけの大きさ (パラメータ数) よりも
実質的な大きさ (自由度) はかなり小さいはず.
“実質的自由度”を調べる研究:
? 圧縮型バウンド
? ノルム型バウンド
…](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-30-320.jpg)
![圧縮型バウンド 31
「圧縮」できるネットワークは
過学習しない
[Taiji Suzuki: Fast generalization error bound of deep learning from a kernel perspective.
AISTATS2018]
[Jingling Li, Yanchao Sun, Ziyin Liu, Taiji Suzuki and Furong Huang: Understanding of Generalization
in Deep Learning via Tensor Methods. AISTATS2020]
[Taiji Suzuki, Hiroshi Abe, Tomoaki Nishimura: Compression based bound for non-compressed
network: unified generalization error analysis of large compressible deep neural network, ICLR2020]
圧縮
?中間層の分散共分散行列の固有値分布で圧縮率を評価.
?「テンソル分解」の援用によりCNNの詳細な評価も実現.
元サイズ 圧縮可能
サイズ
大 小
実質的自由度
元のサイズ
[実験的観察] 実際に学習した
ネットワークは圧縮しやすい.](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-31-320.jpg)
![ニューラルネットワークの圧縮 33
VGG-16ネットワークの圧縮
提案手法:
従来手法より良い精度 94%の圧縮
(精度変わらず)
ResNet-50ネットワークの圧縮
約半分に圧縮しても精度落ちず
圧縮 ? メモリ消費量を減少
? 予測にかかる計算量を減少
→ 小型デバイスでの作動に有利
(自動運転など)
[Suzuki, Abe, Murata, Horiuchi, Ito, Wachi, Hirai, Yukishima, Nishimura:
Spectral-Pruning: Compressing deep neural network via spectral analysis, 2018]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-33-320.jpg)


![オーバーパラメトライゼーション
? 横幅が広いと局所最適解が大域的最適解になる.
38
? オーバーパラメトライゼーション
? Neural Tangent Kernel
? Mean-field analysis (平均場解析)
…
狭い横幅
広い横幅
自由度が上がるため,初期値が最適解
(完全フィット)の近くに位置する.
0
0
[Nitanda &Suzuki, arXiv:1905.09870]
[Nitanda &Suzuki, arXiv:1712.05438.][Ba,Erdogdu,Suzuki, Wu, Zhang, ICLR2020]](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-38-320.jpg)
![平均場解析
? ニューラルネットワークの最適化をパラメータ
の分布最適化としてみなす.
39
(??, ??)に関する確率密度??による平均とみなせる:
??の最適化 ? ??の最適化
連続方程式,Wasserstein勾配流
?? → ∞
連続方程式
[Atsushi Nitanda and Taiji Suzuki: Stochastic Particle Gradient Descent for Infinite Ensembles. arXiv:1712.05438.]
(流体力学,確率論)](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-39-320.jpg)
![粒子勾配降下法 40
? 各ニューロンのパラメータを一つの粒子とみなす.
? 粒子全体の分布が最適化される.
1つの粒子
M個の粒子が移動
?? → ∞の極限で,最適解への収束が示せる.
[Nitanda&Suzuki, 2017][Chizat&Bach, 2018][Mei, Montanari&Nguyen, 2018]
データへの当てはまりを
良くする方向に変化
(各粒子の移動方向)
(分布の形)](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-40-320.jpg)
![まとめ
? 深層学習はなぜうまくいくのか?[世界的課題]
? 数学による深層学習の原理究明
? 「表現能力」,「汎化能力」,「最適化」
41
今後のAIの潮流:論理推論 (脱帰納) ?
数学パワーでAIを“謎の技術”から“制御可能な技術”へ
カーネル法
スパース推定
テンソル分解
特徴抽出
深層学習の統計的学習理論
Besov空間
連続方程式 Wasserstein幾何
確率集中不等式数学
確率過程](https://image.slidesharecdn.com/mathpower2020public-200202071858/85/-41-320.jpg)

数学で解き明かす深层学习の原理
- 2. 深層学習の広がり 2 [Glow: Generative Flow with Invertible 1x1 Convolutions. Kingma and Dhariwal, 2018] AlphaGo/Zero 画像の生成 画像の変換 画像認識 自動翻訳 [Zhu, Park, Isola, and Efros: Unpaired image-to-image translation using cycle-consistent adversarial networks. ICCV2017.] 様々なタスクで高い精度 [Silver et al. (Google Deep Mind): Mastering the game of Go with deep neural networks and tree search, Nature, 529, 484—489, 2016] [Wu et al.: Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv:1609.08144] [He, Gkioxari, Dollár, Girshick: Mask R-CNN, ICCV2017]
- 3. 諸分野への波及 3 [Litjens, et al. (2017)] 医療分野における「深層学習」 を用いた論文数 医療 - 人を超える精度 (FROC73.3% -> 87.3%) - 悪性腫瘍の場所も特定 [Detecting Cancer Metastases on Gigapixel Pathology Images: Liu et al., arXiv:1703.02442, 2017] [Niepert, Ahmed&Kutzkov: Learning Convolutional Neural Networks for Graphs, 2016] [Gilmer et al.: Neural Message Passing for Quantum Chemistry, 2017] [Faber et al.:Machine learning prediction errors better than DFT accuracy, 2017.] 量子化学計算,分子の物性予測 [Google AI Blog, “Deep Learning for Robots: Learning from Large- Scale Interaction,” 2016/5/8] ロボット
- 4. ImageNet 4 ImageNet: 1,000カテゴリ,約120万枚の訓練画像データ ILSVRC (ImageNet Large Scale Visual Recognition Competition) [J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.]
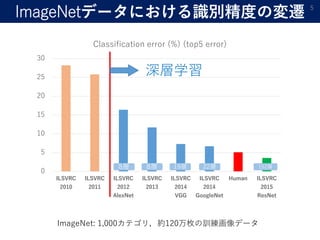
- 5. ImageNetデータにおける識別精度の変遷 5 0 5 10 15 20 25 30 ILSVRC 2010 ILSVRC 2011 ILSVRC 2012 AlexNet ILSVRC 2013 ILSVRC 2014 VGG ILSVRC 2014 GoogleNet Human ILSVRC 2015 ResNet Classification error (%) (top5 error) 深層学習 ImageNet: 1,000カテゴリ,約120万枚の訓練画像データ 8層 8層 19層 22層 152層
- 6. 解決すべき問題点 なぜ深層学習はうまくいくのか? ? 「○○法が良い」という様々な仮説の氾濫. ? 世界的課題 6 “錬金術”という批判 学会の問題意識 民間の問題意識 Ali Rahimi’s talk at NIPS2017 (test of time award). “Random features for large-scale kernel methods.” ? 中で何が行われているか分か らないものは用いたくない. ? 企業の説明責任.深層学習の ホワイトボックス化. ? 原理解明 ? どうすれば“良い”学習が実現できるか?→新手法の開発 数学の必要性
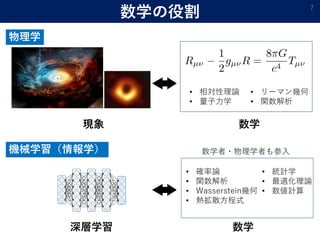
- 7. 数学の役割 7 物理学 数学現象 ? 相対性理論 ? 量子力学 ? リーマン幾何 ? 関数解析 機械学習(情報学) 深層学習 数学 ? 確率論 ? 関数解析 ? Wasserstein幾何 ? 熱拡散方程式 ? 統計学 ? 最適化理論 ? 数値計算 数学者?物理学者も参入
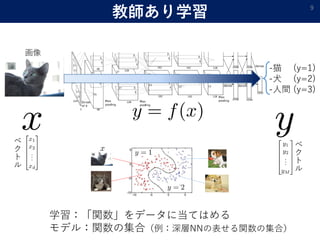
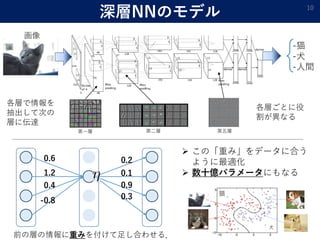
- 9. 教師あり学習 9 -猫 (y=1) -犬 (y=2) -人間 (y=3) 画像 学習:「関数」をデータに当てはめる モデル:関数の集合(例:深層NNの表せる関数の集合) ベ ク ト ル ベ ク ト ル
- 10. 深層NNのモデル 10 -猫 -犬 -人間 画像 各層で情報を 抽出して次の 層に伝達 第一層 第二層 第五層 0.6 1.2 0.4 -0.8 0.2 0.1 0.9 0.3 前の層の情報に重みを付けて足し合わせる. 各層ごとに役 割が異なる ? この「重み」をデータに合う ように最適化 ? 数十億パラメータにもなる 猫 犬
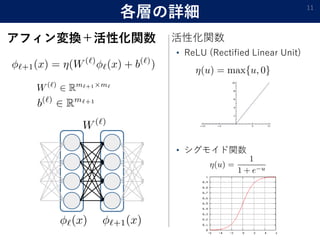
- 11. 各層の詳細 アフィン変換+活性化関数 11 ? ReLU (Rectified Linear Unit) ? シグモイド関数 活性化関数
- 12. 表現能力「万能近似能力」 理論的にはデータが無限にあり,素子数が無限 にあるニューラルネットワークを用いればどん な問題でも学習できる. 12 深層ニューラルネットワークのモデルは連続関数?L1可積分関数? L2可積分関数の空間で稠密 真の関数有限和近似(2層NN) ニューラルネットワークはどんな関数も 任意の精度で近似できる. 「関数近似理論」 [Sonoda & Murata, 2015] [Hecht-Nielsen,1987][Cybenko,1989]
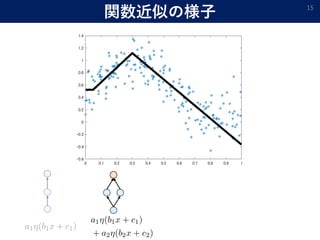
- 13. 関数近似の様子 13
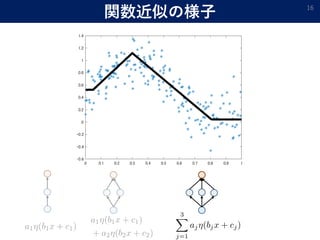
- 15. 関数近似の様子 15
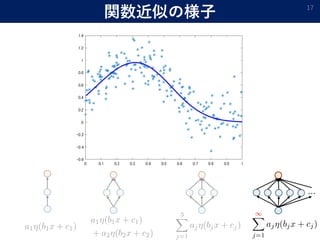
- 16. 関数近似の様子 16
- 17. 関数近似の様子 17 …
- 18. Fourier変換との関係 ? Fourier変換 18 ? Ridgelet変換 ウェーブレット変換 + ラドン変換 cos,sinの代わりに,各素子の出力の 足し合わせで関数を表現 CTスキャン Ridgelet変換による復元定理 [Wikipedia,フーリエ変換]
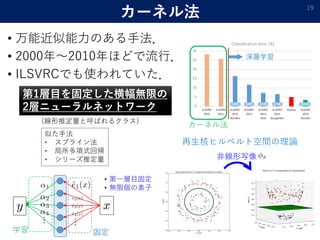
- 19. カーネル法 ? 万能近似能力のある手法. ? 2000年~2010年ほどで流行. ? ILSVRCでも使われていた. 19 非線形写像 カーネル法 再生核ヒルベルト空間の理論 似た手法 ? スプライン法 ? 局所多項式回帰 ? シリーズ推定量 xy … … ? 第一層目固定 ? 無限個の素子 第1層目を固定した横幅無限の 2層ニューラルネットワーク (線形推定量と呼ばれるクラス) 固定学習
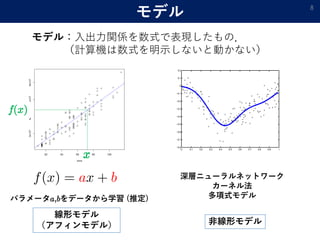
- 20. これまででわかったこと ? [理論] 万能近似能力という意味では2層で十分. ? [実際] 実際は多層を使うことが多い. → この差はどう埋める? 20 カーネル法 従来法 多層ニューラルネット 深層学習 → 推定/近似の「精度」を比べてみる.
- 21. なぜ深層学習が良いのか? ? いろいろな理論がある. 21 深 層 カ ー ネ ル 縮小ランク回帰 特徴空間の次元 が低い状況は深 層学習が得意 区分滑らかな関数 不連続な関数の 推定は深層学習 が得意 Besov空間 滑らかさが非一 様な関数の推定 は深層学習が得 意 低次元データ データが低次元 部分空間上に分 布していたら深 層学習が有利 [Suzuki, 2019] [Schmidt-Hieber, 2019] [Nakada&Imaizumi, 2019][Chen et al., 2019][Suzuki&Nitanda, 2019][Imaizumi&Fukumizu, 2019] 推 定 精 度
- 22. 深層学習の適応能力 22 [Suzuki, ICLR2019] 深層学習はBesov空間(????,?? ?? )の元を推定するのにミニマックス最適レートを達成する. (複雑な関数形状に適応的にフィットすることができる) 深層学習には「高い適応力がある」ことを解明 明らかに犬 明らかに猫犬と猫の中間 少し絵が変わっても 「犬」のまま 少し絵が変わっても 「猫」のまま 少し絵が変わると 犬/猫のどちらかに偏る 猫の度合い 滑らかでない 急激に変化滑らか 滑らか どこが重要でどこが重要でないかを見分けて,重要な部分を重点的に学習 → 多層だから可能
- 23. 「浅い」学習との比較 23 ? (??: sample size,??: uniformity of smoothness,??: smoothness) (カーネルリッジ回帰,KNN法,シーブ法など) 深層でない学習方法 最適ではない 深層学習 最適 ? 深層学習は“必要最低限”の情報のみを抽出して学習 →学習効率が良い ? 浅い学習は“無駄な”情報も捉えて学習 →学習効率が悪い (無駄な情報に左右されてしまう) 理論上これ以上改善できない精度を達成できている. 推定誤差(平均二乗誤差 E ??? ? ??? 2 )がサンプルサイズが増えるにつれどれだけ速く減少するか [Suzuki, ICLR2019]
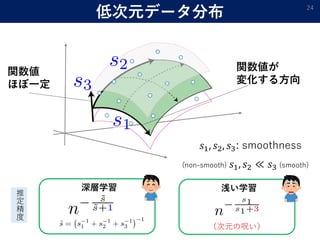
- 24. 低次元データ分布 24 関数値 ほぼ一定 関数値が 変化する方向 ??1, ??2, ??3: smoothness (non-smooth) ??1, ??2 ? ??3 (smooth) 推 定 精 度 深層学習 浅い学習 (次元の呪い)
- 25. 数学的に一般化 25 [Satoshi Hayakawa and Taiji Suzuki: On the minimax optimality and superiority of deep neural network learning over sparse parameter spaces. arXiv:1905.09195.] 「滑らかさの非一様性」「不連続性」「データの低次元性」 凸結合を取って崩れる性質をもった関数の学習は深層学習が強い → 様々な性質を“凸性”で統一的に説明 例:ジャンプが3か所の区分定数関数 + = 0.5x 0.5x ジャンプ3か所 ジャンプ3か所 ジャンプ6か所 → さらには「スパース推定」という観点からも説明できる. 深層:1/??, カーネル: 1/ ??
- 27. 深層学習の汎化誤差 27
- 29. 従来の学習理論 29 過学習適切な学習過小学習 [Neyshabur et al., ICLR2019] ネットワークのサイズを大きくしても過学習しない 実際は... データサイズ:130万 モデルパラメータサイズ:10億 [Xu et al., 2018]
- 30. 深層ニューラルネットの冗長性 30 ? 深層学習は重要な情報に絞って特徴抽出 → 構造的に冗長性が現れる. 重視 簡単簡単 パラメータ数 ? データサイズ 数十億 数百万 数十万 ? 実質的自由度 [仮説] 見かけの大きさ (パラメータ数) よりも 実質的な大きさ (自由度) はかなり小さいはず. “実質的自由度”を調べる研究: ? 圧縮型バウンド ? ノルム型バウンド …
- 31. 圧縮型バウンド 31 「圧縮」できるネットワークは 過学習しない [Taiji Suzuki: Fast generalization error bound of deep learning from a kernel perspective. AISTATS2018] [Jingling Li, Yanchao Sun, Ziyin Liu, Taiji Suzuki and Furong Huang: Understanding of Generalization in Deep Learning via Tensor Methods. AISTATS2020] [Taiji Suzuki, Hiroshi Abe, Tomoaki Nishimura: Compression based bound for non-compressed network: unified generalization error analysis of large compressible deep neural network, ICLR2020] 圧縮 ?中間層の分散共分散行列の固有値分布で圧縮率を評価. ?「テンソル分解」の援用によりCNNの詳細な評価も実現. 元サイズ 圧縮可能 サイズ 大 小 実質的自由度 元のサイズ [実験的観察] 実際に学習した ネットワークは圧縮しやすい.
- 33. ニューラルネットワークの圧縮 33 VGG-16ネットワークの圧縮 提案手法: 従来手法より良い精度 94%の圧縮 (精度変わらず) ResNet-50ネットワークの圧縮 約半分に圧縮しても精度落ちず 圧縮 ? メモリ消費量を減少 ? 予測にかかる計算量を減少 → 小型デバイスでの作動に有利 (自動運転など) [Suzuki, Abe, Murata, Horiuchi, Ito, Wachi, Hirai, Yukishima, Nishimura: Spectral-Pruning: Compressing deep neural network via spectral analysis, 2018]
- 34. 転移学習のネットワーク構造決定 ? ある閾値以上の固有値をカウント (e.g., 10?3 ). → 縮小したネットワークのサイズとして使う. ? その後,スクラッチから学習 (??) もしくはImageNet事前学習モデルをファイン チューニングする (?). 34 Network size determination alg.
- 35. 深層学習の最適化計算 35
- 38. オーバーパラメトライゼーション ? 横幅が広いと局所最適解が大域的最適解になる. 38 ? オーバーパラメトライゼーション ? Neural Tangent Kernel ? Mean-field analysis (平均場解析) … 狭い横幅 広い横幅 自由度が上がるため,初期値が最適解 (完全フィット)の近くに位置する. 0 0 [Nitanda &Suzuki, arXiv:1905.09870] [Nitanda &Suzuki, arXiv:1712.05438.][Ba,Erdogdu,Suzuki, Wu, Zhang, ICLR2020]
- 39. 平均場解析 ? ニューラルネットワークの最適化をパラメータ の分布最適化としてみなす. 39 (??, ??)に関する確率密度??による平均とみなせる: ??の最適化 ? ??の最適化 連続方程式,Wasserstein勾配流 ?? → ∞ 連続方程式 [Atsushi Nitanda and Taiji Suzuki: Stochastic Particle Gradient Descent for Infinite Ensembles. arXiv:1712.05438.] (流体力学,確率論)
- 40. 粒子勾配降下法 40 ? 各ニューロンのパラメータを一つの粒子とみなす. ? 粒子全体の分布が最適化される. 1つの粒子 M個の粒子が移動 ?? → ∞の極限で,最適解への収束が示せる. [Nitanda&Suzuki, 2017][Chizat&Bach, 2018][Mei, Montanari&Nguyen, 2018] データへの当てはまりを 良くする方向に変化 (各粒子の移動方向) (分布の形)
- 41. まとめ ? 深層学習はなぜうまくいくのか?[世界的課題] ? 数学による深層学習の原理究明 ? 「表現能力」,「汎化能力」,「最適化」 41 今後のAIの潮流:論理推論 (脱帰納) ? 数学パワーでAIを“謎の技術”から“制御可能な技術”へ カーネル法 スパース推定 テンソル分解 特徴抽出 深層学習の統計的学習理論 Besov空間 連続方程式 Wasserstein幾何 確率集中不等式数学 確率過程
- 42. より高度な“知能”とは? 42 Neuroscience-Inspired Artificial Intelligence D. Hassabis, D. Kumaran, C. Summerfield, and M. Botvinick