![Mr. Kailash Shaw [ HOD ( CSE DEPT.) ]
Mrinal Kumar - 1301292599
Pranav Kumar - 1301292603
1](https://image.slidesharecdn.com/sycamorequantumcomputer-240422140551-fc6fdaaf/85/Sycamore-Quantum-Computer-2019-developed-pptx-1-320.jpg)



















![Broken into pieces
[ MAP ]
Computation
Computation
Computation
Computation
Computation
Computation
Shuffle and Sort](https://image.slidesharecdn.com/sycamorequantumcomputer-240422140551-fc6fdaaf/85/Sycamore-Quantum-Computer-2019-developed-pptx-22-320.jpg)






































More Related Content
Similar to Sycamore Quantum Computer 2019 developed.pptx (20)
Recently uploaded (20)


















Sycamore Quantum Computer 2019 developed.pptx
- 1. Mr. Kailash Shaw [ HOD ( CSE DEPT.) ] Mrinal Kumar - 1301292599 Pranav Kumar - 1301292603 1
- 2. ’üČ Introduction ’üČ Why Cloud Computing ’üČ Benefits of Cloud Computing ’üČ Characteristics ’üČ Advantagesof Cloud Computing ’üČ Disadvantages of Cloud Computing ’üČ How Cloud Computing Works ’üČ Challenges of Cloud Computing ’üČ Layers of Cloud Computing ’üČ Components of Cloud Computing ’üČ Big Data ’üČ 3 Vs of Big Data ’üČ Importance of Big Data ’üČ What Comes Under Big Data ’üČ Hadoop ’üČ Hadoop Architecture ’üČ Hadoop With Big Data ’üČ Map Reduce ’üČ Why Data Analytics ’üČ Types of Analysis ’üČ Types of Data Analytics ’üČ Big Data Analytics ’üČ Conclusion ’üČ References ’üČ Thanking You 2
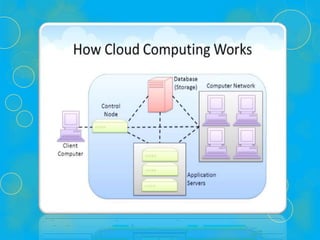
- 3. What is Cloud? A cloud is a combination of networks, hardware, services, storage, and interfaces that helps in delivering computing as a service. What is Cloud Computing ? Cloud computing is an internet based computer technology. It is the next stage technology that uses the clouds to provide the services whenever and wherever the user need it. It provides a method to access several servers world wide. 3
- 4. Why Cloud Computing? Without Cloud Computing With Cloud Computing 4
- 5. Benefits of Cloud Computing ’üČ ’āś ’üČ Cloud computing enables companies and applications, which are system infrastructure dependent, to be infrastructure-less. By using the Cloud infrastructure on ŌĆ£pay as used and on demandŌĆØ, all of us can save in capital and operational investment! Clients can:- ’ā╝ Put their data on the platform instead of on their own desktop PCs and/or on their own servers. ’ā╝ They can put their applications on the cloud and use the servers within the cloud to do processing and data manipulations etc. 5
- 6. Agile Highly Reliable Independent of Device and Location Low Cost Pay-Per-Use Easy to Maintain Highly Scalable Multi-Shared 6
- 7. Advantages of Cloud Computing ’üČ Lower cost computer users ’üČ Lower IT infrastructure ’üČ Fewer Maintenance cost ’üČ Lower Software Cost ’üČ Instant Software updates ’üČ Increased Computing Powers ’üČ Unlimited storage capacity 7
- 8. Disadvantages of Cloud Computing ’üČ Requires a constant Internet connection ’üČ Stored data might not be secured ’üČ Limited control and flexibility ’üČ More risk on information leakage ’üČ Users cannot be aware of the network ’üČ Dependencies on service suppliers for implementing data management 8
- 10. ’āś Use of cloud computing means dependence on others and that could possibly limit flexibility and innovation ’āś Security could prove to be a big issue: ’ü▒ It is still unclear how safe out-sourced data is and when using these services ’ü▒ Ownership of data is not always clear. ’āś Data Centre can become environmental hazards: Green Cloud ’āś Cloud Interoperability is still an issue.
- 11. Layers of Cloud Computing ’āś Infrastructure as a service (IaaS):-It provides cloud infrastructure in terms of hardware as like memory, processor, speed etc. ’āś Platform as a service (PaaS):It provides cloud application platform for the developer. ’āś Software as a service (SaaS)::It provides the cloud applications to users directly without installing anything on the system. These applications remains on cloud.
- 12. Components Of Cloud Computing
- 13. Big Data Big Data refers to a collection of data sets so large and complex. It is impossible to process them with the usual databases and tools because of its size and associated numbers. Big data is hard to capture, store, search, share, analyze and visualize.
- 14. 3 Vs of Big Data ’üČ The ŌĆ£BIGŌĆØ in big data isnŌĆÖt just about volume ’ü▒ Volume ’ü▒ Variety ’ü▒ Velocity
- 15. Importance of Big Data The importance of big data does not revolve around how much data you have , but what you do with it. You can take data from any source and analyze it to find answer that enables, ’üČ Cost reductions. ’üČ Time reductions. ’üČ New product development and optimized offerings . ’üČ Smart decision making.
- 16. ’āś Black Box Data ’āś Social Media Data ’āś Stock Exchange Data ’āś Power Grid Data ’āś Transport Data ’āś Search Engine Data ’āś Structured data ’āś Semi Structured data ’āś Unstructured data
- 17. What is Hadoop ? ’üČ Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs. ’āś The software framework that supports HDFS, MapReduce and other related entities is called the project Hadoop or simply Hadoop. ’ā╝ This is open source and distributed by Apache.
- 18. Hadoop Ecosystem Apache Oozie (Workflow) HDFS (Hadoop Distributed File System) Map Reduce Framework Flume Sqoop Unstructured or Semi-Structured data Structured data P Pi ig gL L a a tit n in D D a at ta a A An n aa ly ly sis sis M M a a h h o u o t u t M M a a c ch hi in ne eL L e e aa rn rin ni g ng H Base Hive DW System
- 19. With Big Data Hadoop is the core platform for structuring Big Data, and solves the problem of formatting it for subsequent analytics purposes. Hadoop uses a distributed computing architecture consisting of multiple servers using commodity hardware, making it relatively
- 20. ’üČCost Effective System ’üČLarge Cluster of Notes ’üČParallel Processing ’üČDistributive Data ’üČAutomatic failover management ’üČData Locality optimization ’üČHeterogeneous Cluster ’üČScalability
- 21. Map Reduce MapReduce is a programming model that Google has used successfully in processing its ŌĆ£big-dataŌĆØ sets (~ 20000 peta bytes per day) ’ā╝ A map function extracts some intelligence from raw data. ’ā╝ A reduce function aggregates according to some guides the data output by the map. ’ā╝ Users specify the computation in terms of a map and a reduce function, ’ā╝ Underlying runtime system automatically parallelizes the computation across large-scale clusters of machines, and ’ā╝ Underlying system also handles machine failures, efficient communications, and performance issues.
- 22. Broken into pieces [ MAP ] Computation Computation Computation Computation Computation Computation Shuffle and Sort
- 23. Why Data Analysis? It is important to remember that the primary value from big data does not come from the data in its raw form but from the processing and analysisofitandtheinsights,products and services that emerge from analysis.
- 24. For unstructured data to be useful it must be analysed to extract and expose the information it contains Different types of analysis are possible, such as:- ’üČ Entity analysis ŌĆō people, organisations, objects and events, and the relationships between them ’üČ Topic analysis ŌĆō topics or themes, and their relative importance ’üČ Sentiment analysis ŌĆō subjective view of a person to a particular topic ’üČ Feature analysis ŌĆō Inherent characteristics that are significant for a particular analytical perspective (e.g. land coverage in satellite imagery) Types Of Analysis
- 25. Types Of Data Analytics Analytic Excellence leads to better decisions:- ’üČ Descriptive Analytics : What is happening? ’üČ Diagnostic Analytics : Why did it happen? ’üČ Predictive Analytics : What is likely going to happen? ’üČ Prescriptive Analytics : What should we do about it?
- 26. Analytics ’āś Focus On :- ’ā╝ Predictive Analysis ’ā╝ Data Science ’üČ Data Sets:- ’ā╝ Large Scale Data Sets ’ā╝ More type of Data ’ā╝ Raw Data ’ā╝ Complex Data Models ’ü▒ Supports:- ’ā╝ Correlations ŌĆō new insight more accurate answer
- 27. ’üČ Two IT initiatives are currently top of mind for organizations across the globe i.e. ’āś Big Data Analytics ’āś Cloud Computing ’üČ As a delivery model for IT services , cloud computing has the potential to enhance business agility and productivity while enabling greater efficiencies and reducing costs. ’üČ In the current scenario , Big Data is a big challenge for the organizations . To store and process such large volume of data , variety of data and velocity of data Hadoop came into existence. ’ü▒ Our presentation is all about Cloud Computing , Big Data & Big Data Analytics.