TIBCO Spotfire Desktop „Į„å©`„Č„ź„¢„ė6.5
0 likes22,580 views

TIBCO””Spotfire Desktop„Š©`„ø„ē„ó¤ĪČÕ±¾ÕZ„Į„å©`„Č„ź„¢„ė¤Ē¤¹”£ „Ē©`„æ¤ņČ”¤źŽz¤ß”¢ŗ g¤Ė„°„é„Õ×÷³É¤Ž¤Ē¤Ē¤¤ė¤č¤¦¤Ė¤Ź¤ź¤Ž¤·¤ē¤¦”£









![ÓĖć¤Ē„«„é„ą¤ņ×·¼Ó
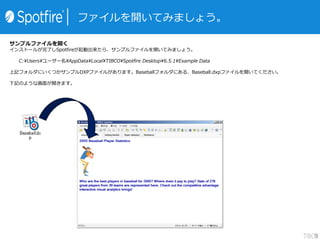
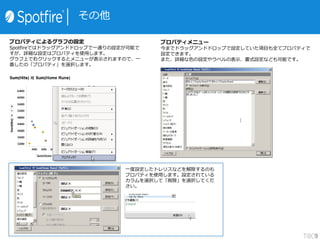
£±£®ÓĖć„«„é„ą¤Ī×·¼Ó
Č”¤źŽz¤ó¤Ą„Ē©`„æ¤ņŌŖ¤ĖÓĖć„«„é„ą¤ņ×÷³É¤¹¤ėŹĀ¤¬¤Ē¤¤Ž¤¹”£
”ø·Čė”¹”ś”øÓĖć„«„é„ą”¹¤ņßxk¤·¤ĘĻĀ¤µ¤¤”£
£²£®ÓĖćŹ½¤ĪČėĮ¦
„Ū©`„ą„é„óŅ»±¾¤¢¤æ¤ź¤Ī½oĮĻ¤ņĖć³ö¤·¤Ę¤ß¤Ž¤·¤ē¤¦”£
”øŹ½”¹¤Ė”±[Home Runs] / [Salary] ”°¤ČČėĮ¦¤·¤Ę¤Æ¤Ą¤µ¤¤”£
„«„é„ąĆū¤Ļ”ø„Ū©`„ą„é„óµ±¤æ¤ź¤Ī„³„¹„Č”¹¤Ė¤·”¢”øOK”¹¤ņ
Ńŗ¤·¤Ę¤Æ¤Ą¤µ¤¤”£
£³£®„«„é„ą¤ņ“_ÕJ
×÷³É¤µ¤ģ¤æÓĖć„«„é„ą¤ĻĶس£¤Ī„«„é„ą¤ČĶ¬¤ø¤č¤¦¤ĖŹ¹ÓƤĒ¤
¤Ž¤¹”£„Õ„£„ė„æ©`¤ņŹ¹ÓƤ·¤Ę½g¤źŽz¤ó¤Ą¤ź”¢„°„é„Õ¤ĪŻS¤ĖŌO
¶Ø¤¹¤ėŹĀ¤āæÉÄܤĒ¤¹”£
ÓĖć„«„é„ą¤Ē¤Ļ”©¤ŹévŹż¤ņŹ¹ÓƤ¹¤ėŹĀ¤¬³öĄ“¤Ž¤¹”£
Ź½¤ĪČėĮ¦»Ćę¤Ēßxk¤¹¤ė¤Č„µ„ó„ׄė¤ņŅ¤ė¤³¤Č¤¬³öĄ“¤Ž¤¹”£
¤É¤Ī¤č¤¦¤ŹévŹż¤¬¤¢¤ė¤Ī¤«¤Ļ„Ų„ė„פņ¤“ÓE¤Æ¤Ą¤µ¤¤”£](https://image.slidesharecdn.com/tibcospotfire-150226220159-conversion-gate02/85/TIBCO-Spotfire-Desktop-6-5-13-320.jpg)
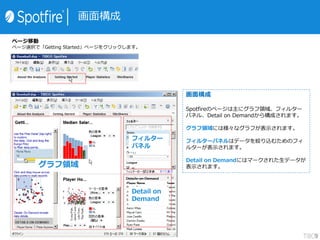
![„°„é„Õ¤ĪŻS¤ĖÓĖćŹ½¤ņŌO¶Ø¤¹¤ė
£±£®„«„¹„æ„ąŃŻĖćŹ½
Ē°„Ś©`„ø¤ĒÓĖ椷¤æ„«„é„ą¤ņ×·¼Ó¤·¤Ž¤·¤æ”£
Spotfire¤Ē¤ĻČ«¤Ę¤ĪŻS¤Ē”¢¤½¤Ī„°„é„Õ¤Ą¤±¤ĖÓŠæ¤Ź
”ø„«„¹„æ„ąŃŻĖćŹ½”¹¤ņŌO¶Ø¤¹¤ėŹĀ¤ā¤Ē¤¤Ž¤¹”£
ŻS¤ĪÉĻ¤ĒÓŅ„Æ„ź„Ć„Æ¤·”ø„«„¹„æ„ąŃŻĖćŹ½”¹¤ņßxk¤·¤Ž¤¹”£
£²£®Ź½¤ĪČėĮ¦
ÓĖć„«„é„ą¤ČĶ¬¤øŹ½ČėĮ¦»Ć꤬±ķŹ¾¤µ¤ģ¤Ž¤¹”£
¤³¤Į¤é¤ĒŹ½¤ņŌO¶Ø¤Ē¤¤Ž¤¹”£
”ö°ō„°„é„Õ¤ĪYŻS¤ĖŌO¶Ø¤·¤æĄż
Avg([At Bats] - ([Hits] + [Doubles] + [Triples] + [Home
Runs]))
¤ņŌO¶Ø¤·”¢“ņĻÆŹż-“ņŹż¤ņĖć³ö
”öÉ«¤Ī»łŹ¤ĖŌO¶Ø¤·¤æĄż
<If([Team]="Arizona","yes","no")>
¤ņŌO¶Ø¤·”¢„¢„ź„¾„Ź„Į©`„ą¤ņÄæĮ¢¤æ¤»¤ė”£
„«„¹„æ„ąŃŻĖćŹ½¤ņŹ¹ÓƤ¹¤ėŹĀ¤Ē”©¤ŹĆ軤¬æÉÄܤĖ¤Ź¤ź¤Ž¤¹”£
”ö„ׄķ„Ń„Ę„£¤«¤é„é„Ł„ė¤ĖŌO¶Ø¤·¤æĄż
"ĆūĒ°¤Ļ" & [Player Name] & "?n½oĮĻ¤Ļ"
& (if([Salary]>1000000,"øߤ¤","ĘÕĶØ"))](https://image.slidesharecdn.com/tibcospotfire-150226220159-conversion-gate02/85/TIBCO-Spotfire-Desktop-6-5-14-320.jpg)
































More Related Content
What's hot (20)
More from TAKESHI KIURA (8)






TIBCO Spotfire Desktop „Į„å©`„Č„ź„¢„ė6.5
- 3. »Ćę³É „Ś©`„øŅĘÓ „Ś©`„øßxk¤Ē”øGetting Started”¹„Ś©`„ø¤ņ„Æ„ź„Ć„Æ¤·¤Ž¤¹”£ „°„é„ÕīIÓņ „Õ„£„ė„æ©` „Ń„Ķ„ė Detail on Demand »Ćę³É Spotfire¤Ī„Ś©`„ø¤ĻÖ÷¤Ė„°„é„ÕīIÓņ”¢„Õ„£„ė„æ©` „Ń„Ķ„ė”¢Detail on Demand¤«¤é³É¤µ¤ģ¤Ž¤¹”£ „°„é„ÕīIÓņ¤Ė¤Ļ”©¤Ź„°„é„Õ¤¬±ķŹ¾¤µ¤ģ¤Ž¤¹”£ „Õ„£„ė„æ©`„Ń„Ķ„ė¤Ļ„Ē©`„æ¤ņ½g¤źŽz¤ą¤æ¤į¤Ī„Õ„£ „ė„æ©`¤¬±ķŹ¾¤µ¤ģ¤Ž¤¹”£ Detail on Demand¤Ė¤Ļ„Ž©`„Ƥµ¤ģ¤æÉś„Ē©`„椬 ±ķŹ¾¤µ¤ģ¤Ž¤¹”£
- 4. „Õ„£„ė„æ©`¤ČDetail On Demand „Õ„£„ė„æ©`„Ń„Ķ„ė »ĆęÓŅÉĻ¤Ė±ķŹ¾¤µ¤ģ¤Ę¤¤¤ė„Õ„£„ė„æ©`„Ń„Ķ„ė¤ĪCÄܤņŹ¹ÓƤ¹¤ė¤Č”¢ „Ē©`„æ¤Ė„Õ„£„ė„æ©`¤ņ¤«¤±¤ė¤³¤Č¤Ē¤¤Ž¤¹”£ Ō¤·¤Ė”¢Team¤Ī„Õ„£„ė„æ©`¤ņ„¹„鄤„ɤ·”¢”øArizona”¹¤ņßx¤ó¤Ē ¤ß¤Ę¤Æ¤Ą¤µ¤¤”£ ½ń¤Ž¤ĒČ«¤Ę¤Ī„Į©`„ą¤¬±ķŹ¾¤µ¤ģ¤Ę¤¤¤æ„°„é„Õ¤¬Arizona„Į©`„ą¤Ą¤± ¤Ī„°„é„Õ¤Ėä¤ļ¤ź¤Ž¤¹”£ „Õ„£„ė„æ©`„Ń„Ķ„ė¤Ļ„Ē©`„æ¤ņČ”¤źŽz¤ßr¤Ė”¢Č«¤Ę¤Ī„«„é„ą¤Ė¤· ¤Ę×ŌӵĤĖ×÷³É¤µ¤ģ¤Ž¤¹”£ Detail on Demand »ĆęÓŅĻĀ¤Ė±ķŹ¾¤µ¤ģ¤Ę¤¤¤ėDetail on Demand¤Ļ„Ž©`„ƤĒßxk¤µ¤ģ ¤æ¹ ģ¤ĪŌŖ„Ē©`„æ¤ņ±ķŹ¾¤·¤Ž¤¹”£ „Ž©`„ƤĪ·½·Ø¤Ļ„°„é„ÕÉĻ¤Ē×ó„Æ„ź„Ć„Æ¤·¤Ź¤¬¤é„É„é„Ć„°¤·¤Ž¤¹”£ Ctrl¤ņŃŗ¤·¤Ź¤¬¤éßxk¤¹¤ė¤Č×·¼Óßxk¤āæÉÄܤĒ¤¹”£ ×ó„Æ„ź„Ć„Æ£¦„É„é„Ć„°¤Ē¹ ģßxk¤¹¤ė¤Č”¢ßxk¹ ģ¤Ė¤¢¤ė„Ē©`„椬±ķŹ¾¤µ¤ģ¤ė”£ ”ł„Õ„£„ė„æ©`ŠĪŹ½¤Ļäøü¤¹¤ėŹĀ¤¬æÉÄܤĒ¤¹”£ „Õ„£„ė„æ©`ÉĻ¤ĒÓŅ„Æ„ź„Ć„Æ”ś”ø„Õ„£„ė„æ©`¤Ī·Nī”¹¤«¤éŗƤ¤ŹŠĪ Ź½¤ņßxk¤Ē¤¤Ž¤¹”£ Detail-on-Demand„Ń„Ķ„ė¤Ļ „É„é„Ć„°„¢„ó„É„É„ķ„ƄפĒĻĀ¤ŲÅäÖƤ¹¤ėŹĀ¤āæÉÄܤĒ¤¹”£
- 5. ŠĀŅ„Ē©`„æ¤ĪČ”¤źŽz¤ß ŠĀŅ„Õ„”„¤„ė¤ĪČ”¤źŽz¤ß·½ Spotfire¤ņŠĀ¤æ¤ĖĘšÓ¤·¤Ę¤Æ¤Ą¤µ¤¤”£ ĻȤŪ¤É¤ČĶ¬¤ø„Õ„©„ė„Ą¤Ė¤¢¤ėBaseball.txt„Õ„”„¤„ė¤ņČ”¤źŽz¤ó¤Ē¤Æ ¤Ą¤µ¤¤”£ Č”¤źŽz¤ß·½·Ø¤ĻĻĀÓ¤Ī·½·Ø¤¬¤¢¤ź¤Ž¤¹”£ ? „Ø„Æ„¹„ׄķ©`„é©`¤«¤éSpotfire¤Ė„É„é„Ć„°„¢„ó„É„É„ķ„Ć„× ? ”ø„Õ„”„¤„ė”¹”ś”øé_¤Æ”¹ ? ĘšÓ»Ćę¤Ī”ø„Õ„”„¤„ė¤ņé_¤Æ”¹¤ņßxk Č”¤źŽz¤ßæÉÄܤŹ„Ē©`„æ Spotfire¤Ļ”©¤ŹŠĪŹ½¤Ī„Õ„”„¤„ė¤ņČ”¤źŽz¤ßæÉÄܤĒ¤¹”£ CSV¤äExcel„Õ„”„¤„ė¤Ź¤É¤ĪŅ»°ćµÄ¤Ź¤ā¤Ī¤«¤é”¢„Ē©`„æ„Ł©`„¹¤«¤é „Ē©`„æ¤ņÕi¤ßŽz¤ą¤³¤Č¤¬¤Ē¤¤Ž¤¹”£ „¤„ó„Ż©`„ȤĪŌO¶Ø¤Ē ”øOK”¹¤ņŃŗ¤·¤Ž¤¹”£
- 6. °ō„°„é„Õ¤ņ×÷¤Ć¤Ę¤ß¤č¤¦£” £±£®„Ś©`„ø¤Ī×÷³É »ĆęÉĻ¤Ī”ø„Ś©`„ø”¹¤ĒÓŅ„Æ„ź„Ć„Æ¤·¤Ę”øŠĀ Ņ„Ś©`„ø”¹¤ņßxk¤·”¢ŠĀŅ„Ś©`„ø¤ņ×÷³É¤· ¤Ž¤¹”£ £²£®„°„é„Õ¤Ī×÷³É °ō„°„é„Õ¤ņ×÷³É¤·¤Ž¤¹”£ »ĆęÉĻ²æ¤Ė¤¢¤ė„¢„¤„³„ó¤«¤é ¤ņ„Æ„ź„Ć„Æ¤·¤Ž¤¹”£ £³£®„°„é„Õ¤Ī“_ÕJ °ō„°„é„Õ¤¬×÷³É¤µ¤ģ¤Ž¤¹”£ ×ī³õ¤ĪדB¤Ē¤Ļ”¢Positione¤Ī„«„¦„ó„Č¼ÆÓ ¤Ė¤Ź¤Ć¤Ę¤¤¤Ž¤¹”£ 4£®ŻS¤Īäøü£Ø„Į©`„ąe½oĮĻ¤Ī¼ÆÓ£© ”ø„ķ©`¤ĪŹż”¹¤Ī ¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤ČŻS¤Ī Ņ»ÓE¤¬±ķŹ¾¤µ¤ģ¤Ž¤¹”£ Salary¤ņßxk¤·¤Ę¤Æ¤Ą¤µ¤¤”£ XŻS¤āĶ¬¤ø¤č¤¦¤Ė”øTeam”¹¤Ėäøü¤·¤Ę¤Æ¤Ą ¤µ¤¤”£ £µ£®É«¤Īäøü ”øÉ«¤Ī»łŹ”¹¤ņ”øPosition”¹¤ĖŌO¶Ø¤·¤Ž¤¹”£ Ķ¬¤ĖÉ«¤Ī»łŹ¤ņ”øPlayer Name”¹¤Ėäøü¤¹ ¤ė¤Č”¢¤É¤ĪßxŹÖ¤¬Ņ»·¬øߤ¤½oĮĻ¤ņ¤ā¤é¤Ć¤Ę¤¤ ¤ė¤Ī¤«“_ÕJ¤Ē¤¤Ž¤¹”£ ¤Ž¤æ”¢YŻS¤ņ”øHits”¹¤ä”øHome Runs”¹¤Ėä øü¤¹¤ė¤³¤Č¤Ē”¢³Éæ¤ņ“_ÕJ¤¹¤ėŹĀ¤¬¤Ē¤¤Ž¤¹”£
- 8. „Æ„ķ„¹„Ę©`„Ö„ė¤ņ×÷¤Ć¤Ę¤ß¤č¤¦£” £±£®„Ś©`„ø¤Ī×÷³É ŠĀŅ„Ś©`„ø¤ņ×÷³É¤·¤Ž¤¹”£ £²£®„°„é„Õ¤Ī×÷³É „Æ„ķ„¹„Ę©`„Ö„ė×÷³É¤·¤Ž¤¹”£ »ĆęÉĻ²æ¤Ė¤¢¤ė„¢„¤„³„ó¤«¤é ¤ņ„Æ„ź„Ć„Æ¤·¤Ž¤¹”£ £³£®„°„é„Õ¤Ī“_ÕJ „Æ„ķ„¹„Ę©`„Ö„ė¤¬×÷³É¤µ¤ģ¤Ž¤¹”£ ¬FŌŚ¤Ī±ķÓ¤Ą¤Č”¢æk”øPosition”¹ŗį”ø£ų”¹¤Ī Batting Average¤Ī¼ÆÓ¤Ē¤¹”£ 4£®ækŻS¤Īäøü ŗįŻS¤Īäøü ækŻS¤Ī”øPosition”¹¤ņ”øTeam”¹¤Ėäøü¤·¤Ž ¤¹”£ŻS¤ņßxk¤·¤ær¤ĖŹĖ÷·¤Ėteam¤ČČėĮ¦ ¤¹¤ėŹĀ¤ĒŻS¤ņŹĖ÷¤¹¤ėŹĀ¤ā¤Ē¤¤Ž¤¹”£ ækŻS¤āĶ¬¤ø¤č¤¦¤Ė”øPosition”¹¤Ėäøü¤·¤Ž ¤¹”£ækŻS¤Ļ„°„é„ÕÉĻ·½¤ĪŌO¶ØķÄæ¤Ė¤Ź¤ź¤Ž ¤¹¤Ī¤Ē×¢Ņā¤·¤Ę¤Æ¤Ą¤µ¤¤”£ £µ£®¼ÆÓķÄæäøü „°„é„ÕĻĀ¤Ī”øSum(Batting Average)”¹ ¤ņßxk¤·”øSalary”¹¤Ėäøü¤·¤Ž¤¹”£ ¤³¤ģ¤Ē„Į©`„ą?„Ż„ø„·„ē„óe½oĮĻ¤Ī¼ÆÓ ¤¬³öĄ“¤Ž¤·¤æ”£ ŻS¤Ī×·¼Ó ½oĮĻ¤Ī¼ÆÓ¤¬³öĄ“¤Ž¤·¤æ¤¬”¢„Ū©`„ą„é„󏿤āĶ¬r ¤Ė±ķŹ¾¤·¤æ¤¤öŗĻ”¢Salary¤Īŗį¤Ė¤¢¤ė ¤ņßxk ¤·”¢”øHome Runs”¹¤ņ×·¼Ó¤¹¤ėŹĀ¤¬¤Ē¤¤Ž¤¹”£ ŗįŻS¤ĪŌO¶Ø ækŻS¤ĪŌO¶Ø
- 9. É¢²¼ķ¤ņ×÷¤Ć¤Ę¤ß¤č¤¦£” £±£®„Ś©`„ø¤Ī×÷³É ŠĀŅ„Ś©`„ø¤ņ×÷³É¤·¤Ž¤¹”£ £²£®„°„é„Õ¤Ī×÷³É É¢²¼ķ¤ņ×÷³É¤·¤Ž¤¹”£ »ĆęÉĻ²æ¤Ė¤¢¤ė„¢„¤„³„ó¤«¤é ¤ņ„Æ„ź„Ć„Æ¤·¤Ž¤¹”£ £³£®„°„é„Õ¤Ī“_ÕJ É¢²¼ķ¤¬×÷³É¤µ¤ģ¤Ž¤¹”£ ×÷³Ér¤Ļæk”øOn Base Percentage”¹ ŗį”øBatting Average”¹¤Ī¼ÆÓ¤Ė¤Ź¤Ć¤Ę¤¤¤Ž¤¹”£ 4£®ækŻS¤Īäøü ŗįŻS¤Īäøü ækŻS¤ņ”øHits”¹ŗįŻS¤ņ”øHome Runs”¹¤Ėä øü¤·ĻąévŠŌ¤ņŅ¤Ę¤ß¤Ž¤¹”£ ¤³¤ĪדB¤Ē¤ĻßxŹÖŅ»ČĖ¤¬„ׄķ„Ć„ČŅ»µć¤Ė ¤Ź¤Ć¤Ę¤¤¤Ž¤¹¤Ī¤Ē”¢“Ī¤ĪŹÖķ¤ĒPositione ¤Ī¼ÆÓ„°„é„Õ¤Ė¤·¤Ž¤¹”£ £µ£®¼ÆÓ gĪ»äøü „°„é„Õ×ó¤Ī”ø„Ž©`„«©`¤Ī»łŹ”¹¤¬£Ø„ķ©`·¬ ŗÅ£©¤Ė¤Ź¤Ć¤Ę¤¤¤Ž¤¹”£¤³¤Į¤é¤ņßxk¤·”¢Ņ»·¬ ĻĀ¤Ī”øĻ÷³ż”¹¤ņßxk¤·¤Ž¤¹”£ „Ž©`„«©`¤Ī»łŹ¤ņĻ÷³ż¤¹¤ė¤Č”¢É«¤Ī»łŹ¤Ē „µ„Ž„ź©`¤µ¤ģ¤æ„°„é„Õ¤Ė¤Ź¤ź¤Ž¤¹”£ ækŻS”¢ŗįŻS¤¬Sum¤ĒÓĖ椵¤ģ¤Ž¤¹”£ 8¤Ä¤ĪPositione¤Ė„ׄķ„ƄȤ¬“ņ¤æ¤ģ¤Ž¤¹”£ „Į©`„ąe¤Ė¼ÆÓ¤·¤æ¤¤öŗĻ¤Ļ”¢É«¤Ī»łŹ¤ņ ”øTeam”¹¤Ėäøü¤·¤Ę¤Æ¤Ą¤µ¤¤”£
- 12. ½yÓ¤Ē„Ē©`„æ¤ĪĻąév¤ņ¤ß¤ė”£ £±£®Data Relationships Spotfire¤Ė¤Ļ”©¤Ź½yÓCÄܤ¬¤¢¤ź¤Ž¤¹”£ ½ń»Ų¤Ļ„Ē©`„æ¤ĪĻąévŠŌ¤ņ±ķŹ¾¤¹¤ė”øData Relationships”¹ ¤ņ¤“½B½é¤·¤Ž¤¹”£ ”ø„Ä©`„ė”¹”ś”øData Relationships”¹¤ņßxk £²£®„«„é„ą¤ĪŌO¶Ø ½oĮĻ¤ĖŅ»·¬évS¤·¤Ę¤¤¤ė„Ń„é„į©`„æ¤ņÕ{¤Ł¤æ¤¤¤ČĖ¼¤¤¤Ž¤¹”£ ±ČŻ^·½·Ø¤Ė”ø¾ŠĪ»Ų¢”¹ ßxk¤·¤æY„«„é„ą¤Ė”øSalary”¹¤ņßxk¤· ßxk¤·¤æX„«„é„ą¤ĖČ«¤Ę¤Ī„«„é„ą¤ņßxk¤·¤Ę”øOK”¹¤ņŃŗ¤· ¤ĘĻĀ¤µ¤¤”£ £³£®½Y¹ū±ķŹ¾ ½yӵĤĖĻąévŠŌ¤¬øߤ¤ķŠņ¤Ė½Y¹ū¤¬±ķŹ¾¤µ¤ģ¤Ž¤¹”£ ±ķ¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤³¤Č¤Ē”¢É¢²¼ķ¤¬ĒŠ¤źĢę¤ļ¤ė¤Ī¤Ē”¢±¾µ± ¤Ė½Y¹ū¤¬Õż¤·¤¤¤Ī¤«gėH¤ĖŅ¤Ę“_ÕJ¤·¤Ę¤Æ¤Ą¤µ¤¤”£ É¢²¼ķ¤ĻĶس£¤ĪĪļ¤ČĶ¬¤ø¤č¤¦¤ĖÉ«¤ä„Č„ģ„ź„¹¤ĪŌO¶Ø¤ņ¤¹¤ė ŹĀ¤ā¤Ē¤¤Ž¤¹”£ ½ń»Ų¤Ļŗ g¤ŹĄż¤ņ½B½é¤·¤Ž¤·¤æ¤¬”¢Spotfire¤Ė¤ĻĖū¤Ė¤ā É«”©¤Ź½yÓCÄܤ¬¤¢¤ź¤Ž¤¹”£ ¤Ž¤æ”¢RŃŌÕZ„Ø„ó„ø„ó¤āÄŚŹi¤·¤Ę¤¤¤Ž¤¹¤Ī¤Ēø߶ȤŹ½yÓ CÄܤņg×°¤¹¤ėŹĀ¤āæÉÄܤĒ¤¹”£
- 13. ÓĖć¤Ē„«„é„ą¤ņ×·¼Ó £±£®ÓĖć„«„é„ą¤Ī×·¼Ó Č”¤źŽz¤ó¤Ą„Ē©`„æ¤ņŌŖ¤ĖÓĖć„«„é„ą¤ņ×÷³É¤¹¤ėŹĀ¤¬¤Ē¤¤Ž¤¹”£ ”ø·Čė”¹”ś”øÓĖć„«„é„ą”¹¤ņßxk¤·¤ĘĻĀ¤µ¤¤”£ £²£®ÓĖćŹ½¤ĪČėĮ¦ „Ū©`„ą„é„óŅ»±¾¤¢¤æ¤ź¤Ī½oĮĻ¤ņĖć³ö¤·¤Ę¤ß¤Ž¤·¤ē¤¦”£ ”øŹ½”¹¤Ė”±[Home Runs] / [Salary] ”°¤ČČėĮ¦¤·¤Ę¤Æ¤Ą¤µ¤¤”£ „«„é„ąĆū¤Ļ”ø„Ū©`„ą„é„óµ±¤æ¤ź¤Ī„³„¹„Č”¹¤Ė¤·”¢”øOK”¹¤ņ Ńŗ¤·¤Ę¤Æ¤Ą¤µ¤¤”£ £³£®„«„é„ą¤ņ“_ÕJ ×÷³É¤µ¤ģ¤æÓĖć„«„é„ą¤ĻĶس£¤Ī„«„é„ą¤ČĶ¬¤ø¤č¤¦¤ĖŹ¹ÓƤĒ¤ ¤Ž¤¹”£„Õ„£„ė„æ©`¤ņŹ¹ÓƤ·¤Ę½g¤źŽz¤ó¤Ą¤ź”¢„°„é„Õ¤ĪŻS¤ĖŌO ¶Ø¤¹¤ėŹĀ¤āæÉÄܤĒ¤¹”£ ÓĖć„«„é„ą¤Ē¤Ļ”©¤ŹévŹż¤ņŹ¹ÓƤ¹¤ėŹĀ¤¬³öĄ“¤Ž¤¹”£ Ź½¤ĪČėĮ¦»Ćę¤Ēßxk¤¹¤ė¤Č„µ„ó„ׄė¤ņŅ¤ė¤³¤Č¤¬³öĄ“¤Ž¤¹”£ ¤É¤Ī¤č¤¦¤ŹévŹż¤¬¤¢¤ė¤Ī¤«¤Ļ„Ų„ė„פņ¤“ÓE¤Æ¤Ą¤µ¤¤”£
- 14. „°„é„Õ¤ĪŻS¤ĖÓĖćŹ½¤ņŌO¶Ø¤¹¤ė £±£®„«„¹„æ„ąŃŻĖćŹ½ Ē°„Ś©`„ø¤ĒÓĖ椷¤æ„«„é„ą¤ņ×·¼Ó¤·¤Ž¤·¤æ”£ Spotfire¤Ē¤ĻČ«¤Ę¤ĪŻS¤Ē”¢¤½¤Ī„°„é„Õ¤Ą¤±¤ĖÓŠæ¤Ź ”ø„«„¹„æ„ąŃŻĖćŹ½”¹¤ņŌO¶Ø¤¹¤ėŹĀ¤ā¤Ē¤¤Ž¤¹”£ ŻS¤ĪÉĻ¤ĒÓŅ„Æ„ź„Ć„Æ¤·”ø„«„¹„æ„ąŃŻĖćŹ½”¹¤ņßxk¤·¤Ž¤¹”£ £²£®Ź½¤ĪČėĮ¦ ÓĖć„«„é„ą¤ČĶ¬¤øŹ½ČėĮ¦»Ć꤬±ķŹ¾¤µ¤ģ¤Ž¤¹”£ ¤³¤Į¤é¤ĒŹ½¤ņŌO¶Ø¤Ē¤¤Ž¤¹”£ ”ö°ō„°„é„Õ¤ĪYŻS¤ĖŌO¶Ø¤·¤æĄż Avg([At Bats] - ([Hits] + [Doubles] + [Triples] + [Home Runs])) ¤ņŌO¶Ø¤·”¢“ņĻÆŹż-“ņŹż¤ņĖć³ö ”öÉ«¤Ī»łŹ¤ĖŌO¶Ø¤·¤æĄż <If([Team]="Arizona","yes","no")> ¤ņŌO¶Ø¤·”¢„¢„ź„¾„Ź„Į©`„ą¤ņÄæĮ¢¤æ¤»¤ė”£ „«„¹„æ„ąŃŻĖćŹ½¤ņŹ¹ÓƤ¹¤ėŹĀ¤Ē”©¤ŹĆ軤¬æÉÄܤĖ¤Ź¤ź¤Ž¤¹”£ ”ö„ׄķ„Ń„Ę„£¤«¤é„é„Ł„ė¤ĖŌO¶Ø¤·¤æĄż "ĆūĒ°¤Ļ" & [Player Name] & "?n½oĮĻ¤Ļ" & (if([Salary]>1000000,"øߤ¤","ĘÕĶØ"))
- 17. ¤½¤ĪĖū „Ń„ļ©`„Ż„¤„ó„ȤĒ¤Ī„ģ„Ż©`„Č×÷³É ×÷³É¤·¤æ„Ś©`„ø¤Ļ„Ń„ļ©`„Ż„¤„ó„ȤĖ„Ø„Æ„¹„Ż©`„Ȥ¹¤ėŹĀ¤¬ ¤Ē¤¤Ž¤¹”£”ø„Õ„”„¤„ė”¹”ś”ø„Ø„Æ„¹„Ż©`„Č”¹”ś ”øMicrosoft@ Power Point¤Ų”¹¤ņßxk¤·¤ĘĻĀ¤µ¤¤”£ ³öĮ¦¤Ļ„Ś©`„øÖø¶Ø¤«”¢Č«¤Ę¤Ī„Ś©`„ø¤ņŅ»¶Č¤Ė³öĮ¦¤¹¤ėŹĀ¤ā æÉÄܤĒ¤¹”£ „Ę„„¹„Č„Ø„ź„¢¤Ė×¢į¤ņÓŻd „°„é„Õ¤Ą¤±¤Ē·Ö¤«¤ź¤Å¤é¤¤öŗĻ¤Ļ„Ę„„¹„Č„Ø„ź„¢¤Ė„³„į„ó „Ȥņų¤Žz¤ą¤³¤Č¤¬³öĄ“¤Ž¤¹”£ „°„é„Õ„¢„¤„³„ó¤«¤é ¤ņ„Æ„ź„Ć„Æ¤·¤Ę¤Æ¤Ą¤µ¤¤”£ „Ę„„¹„Č„Ø„ź„¢¤Ė¤Ļ„³„į„ó„ȤĄ¤±¤Ē¤Ź¤Æ»Ļń¤ä„Õ„£„ė„æ©` ¤ņ×·¼Ó¤¹¤ėŹĀ¤ā¤Ē¤¤Ž¤¹”£
- 18. ¤½¤ĪĖū évŹż½B½é „«„¹„æ„ąŃŻĖćŹ½¤ä”¢ÓĖć„«„é„ą¤ĒÉ«”©¤ŹévŹż¤ņŹ¹ÓƤĒ¤¤Ž¤¹”£¤½¤ĪÖŠ¤Ē¤āŹ¹ÓĆīl¶Č¤¬øߤ¤évŹż¤ņ½B½é¤·¤Ž¤¹”£ „Ę„„¹„ČévŹż £¦ ĪÄ×ÖĮŠ¤ņßB½Y¤·¤Ž¤¹”£ Left ĪÄ×ÖĮŠ¤ņ×󤫤锚ĪÄ×ÖĒŠ¤źČ”¤ź¤Ž¤¹”£ Right ĪÄ×ÖĮŠ¤ņÓŅ¤«¤é”šĪÄ×ÖĒŠ¤źČ”¤ź¤Ž¤¹”£ Mid ĪÄ×ÖĮŠ¤ņ”ĮĪÄ×ÖÄ椫¤é”šĪÄ×ÖĒŠ¤źČ”¤ź¤Ž¤¹”£ Find ĪÄ×ÖĮŠÖŠ¤«¤éĪÄ×Ö¤ņŹĖ÷¤·”¢¤½¤ĪĪ»ÖƤņ·µ¤·¤Ž¤¹”£ Ö÷¤Ėmid¤äright,leftévŹż¤Č¹²¤ĖŹ¹ÓƤ·¤Ž¤¹”£ Len ĪÄ×ÖĮŠ¤ĪéL¤µ¤ņ·µ¤·¤Ž¤¹”£¤³¤Į¤é¤āfind¤ämid¤Č Ź¹ÓƤ¹¤ėŹĀ¤¬¶ą¤¤¤Ē¤¹”£ RxReplace ĪÄ×ÖĮŠ¤ņÕżŅ±ķ¬F¤ĒIĄķ¤·¤Ž¤¹”£ Substitute ĪÄ×ÖĮŠ¤Ī gÕZ¤ņÖĆQ¤·¤Ž¤¹”£ Trim ĪÄ×ÖĮŠ¤ĪĻČī^?Ä©Ī²¤ĪæհפņĻ÷³ż¤·¤Ž¤¹”£ UniqueConcatinate ĪÄ×ÖĮŠ¤Ī¹ĢÓŠ¤ņßB½Y¤·¤Ž¤¹”£ „é„Ł„ė¤ĖŹ¹ÓƤ¹¤ėŹĀ¤¬¶ą¤¤¤Ē¤¹”£ ŹżŃ§évŹż Ceiling ŅżŹż¤ņ×ī¤ā½ü¤¤×ŌČ»Źż¤ĖĒŠ¤źÉĻ¤²¤Ž¤¹ Floor ŅżŹż¤ņ×ī¤ā½ü¤¤×ŌČ»Źż¤ĖĒŠ¤źĻĀ¤²¤Ž¤¹”£ Mod ³żĖ椷¤æÓą¤ź¤ņÓĖ椷¤Ž¤¹”£ Product ŅżŹż¤Ī·e¤ņÓĖ椷¤Ž¤¹”£ ½yÓévŹż Avg Ę½¾ł¤ņÓĖ椷¤Ž¤¹”£ Count ŅżŹż¤Ī„«„鄹ȤĪæÕ¤Ē¤Ź¤¤¤ĪŹż¤ņÓĖ椷¤Ž¤¹ Max ×ī“ó¤ņÓĖ椷¤Ž¤¹”£ Median ŅżŹż¤ĪÖŠŃė¤ņÓĖ椷¤Ž¤¹”£ Min ×īŠ”¤ņÓĖ椷¤Ž¤¹”£ StdDev ĖŹĘ«²ī¤ņÓĖ椷¤Ž¤¹”£ UniqueCount „«„鄹ȤĪæÕ¤Ē¤Ź¤¤¹ĢÓŠ¤ĪŹż¤ņÓĖ椷¤Ž¤¹”£ ÕĄķévŹż Case Ń}Źż¤ĪĢõ¼ž·ÖįŖ¤¬¤Ē¤¤Ž¤¹”£ If Ģõ¼ž·ÖįŖ¤¬³öĄ“¤Ž¤¹”£ ČÕø¶évŹż DataAdd égøō¤ņČÕø¶”¢ræĢ¤Ž¤æ¤ĻČÕø¶ræĢ¤Ė×·¼Ó¤·¤Ž¤¹ DataDiff ČÕø¶ræĢ„«„é„ą¤Īég¤Ī²ī®¤ņÓĖ椷¤Ž¤¹”£ DataTimeNow ¬FŌŚræĢ¤ņ·µ¤·¤Ž¤¹”£ DataPart ČÕø¶”¢ræĢ¤Ž¤æ¤ĻČÕø¶ræĢ¤ĪÖø¶Ø²æ·Ö¤ņ·µ¤·¤Ž¤¹”£ RankévŹż Rank,DenseRank ¹²¤Ė„é„ó„„ó„°ķĪ»¤ņ·µ¤¹évŹż¤Ē¤¹”£ ķĪ»ø¶¤±¤ä„½©`„ČķŠņ¤ĖŹ¹ÓƤ¹¤ėŹĀ¤¬¶ą¤¤¤Ē¤¹”£