TVMĊÎṀÎÆÚċḞċéċÕIR RelayĊÎẄBẄé
Download as pptx, pdf4 likes5,575 views

A lightening talk at ċġċóċÑċĊċéÃãṠá 2018.11.10










![PythonĊÇĊÎRelayÓÊöÀý£Ẁ1) ċÍċÃċÈċï©`ċŸĊÎÓÊö
@relay_model
def lenet(x: Tensor[Float, (1, 28, 28)]) -> Tensor[Float, 10]:
conv1 = relay.conv2d(x, num_filter=20, ksize=[1, 5, 5, 1],
no_bias=False)
tanh1 = relay.tanh(conv1)
pool1 = relay.max_pool(tanh1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1])
conv2 = relay.conv2d(pool1, num_filter=50, ksize=[1, 5, 5, 1],
no_bias=False)
tanh2 = relay.tanh(conv2)
pool2 = relay.max_pool(tanh2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1])
flatten = relay.flatten_layer(pool2)
fc1 = relay.linear(flatten, num_hidden=500)
tanh3 = relay.tanh(fc1)
return relay.linear(tanh3, num_hidden=10)](https://image.slidesharecdn.com/20181110compilerstudy-181110130617/85/TVM-IR-Relay-13-320.jpg)
![PythonĊÇĊÎRelayÓÊöÀý£Ẁ2) gëHĊÎѧÁ
@relay
def loss(x: Tensor[Float, (1, 28, 28)], y: Tensor[Float, 10]) -> Float:
return relay.softmax_cross_entropy(lenet(x), y)
@relay
def train_lenet(training_data: Tensor[Float, (60000, 1, 28, 28)]) -> Model:
model = relay.create_model(lenet)
for x, y in data:
model_grad = relay.grad(model, loss, (x, y))
relay.update_model_params(model, model_grad)
return relay.export_model(model)
training_data, test_data = relay.datasets.mnist()
model = train_lenet(training_data)
print(relay.argmax(model(test_data[0])))](https://image.slidesharecdn.com/20181110compilerstudy-181110130617/85/TVM-IR-Relay-14-320.jpg)
























![[DLÝÕiṠá]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [TS2] ÉîÓṠŸÑ§Á ? ṠŸÑ§ÁĊÎṠùṁAĊḋĊéêÓÃĊŶĊÇ ?](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=560&fit=bounds)
![[DLÝÕiṠá]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=560&fit=bounds)



![[DLÝÕiṠá]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=560&fit=bounds)




![[AI08] ÉîÓѧÁċÕċì©`ċàċï©`ċŸ Chainer ḂÁ Microsoft ĊÇÚĊỲĊëêÓÃ](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=560&fit=bounds)
More Related Content
What's hot (20)
Similar to TVMĊÎṀÎÆÚċḞċéċÕIR RelayĊÎẄBẄé (20)












![[DLÝÕiṠá]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=560&fit=bounds)





TVMĊÎṀÎÆÚċḞċéċÕIR RelayĊÎẄBẄé
- 2. Ṫḃ£ẃĊġĊÎLTĊÏ 11/3é_Ṁß ḂẃXX for ML ÕÎÄÕiĊßṠá #1ḂṠĊÎẅAẅĊÇĊṗ ? ÇḞṠØĊÏRelayĊÎÕÎÄĊòẄBẄé ? /bonotake/relay-a-new-ir-for-machine-learning-frameworks ? ḟẅÈÕĊÏGitHubĊËĊḃĊëċẄ©`ċṗċġ©`ċÉĊÎÄÚÈÝĊâÌĊĊŶĊẀĊÆẄBẄéĊṖĊŶĊṗ
- 3. ṪÔỳẃẄBẄé Ẅñẅ® ẄḂÄŴ£Ẁbonotake£© ċÕċê©`ċéċóċṗċẀċóċẁċËċḃ ỳæ ṗúÁḃÇéóѧÑŴẅṡËù ÌØÈÎÑŴẅṡT£ẀÓè¶Ẁ£© ? ÉîÓѧÁċġċóċÑċĊċéĊÎÑŴẅṡ?é_Ḟk ? øỳ® (ṗĠÔU) ? D. Jackson, ḂẃġéÏóĊËĊèĊëċẄċÕċÈċḊċ§ċḃÔOÓḂṠ£ẀAlloyḟẅ£© ? B. Pierce, ḂẃŴÍċṖċṗċÆċàÈëéTḂṠ£ẀTAPL£© ? ĊẄĊÎËûṠîÓ ? ÈÕḟẅċẄċÕċÈċḊċ§ċḃṡÆѧṠá CŴṁѧÁṗĊѧÑŴẅṡṠá£ẀMLSE£© ḞkṪãċáċóċŴ©` / ỲF ß\ÓΟT
- 4. ÓÊÂĊòøĊĊŶĊṖĊṡ Interface 1ÔÂẃÅ£Ẁ11/25 ḞkÓ£© ? ḂẃgòYÑŴẅṡ ṪḃÄṡAIċġċóċÑċĊċéĊÇ ÚĊỲĊëẄMĊßŶzĊßÈËṗĊÖẂÄÜĊÎÊÀẄçḂṠ w/ LeapMind ÉẄÌïĊṁĊó ÇéóIÀí 2019Äê1ÔÂẃÅ ? ḂẃCŴṁѧÁêÓÃċṖċṗċÆċàĊÎé_Ḟk?ß\ÓÃhẅġḂṠ w/ BrainPad ÌḋÌïĊṁĊó Ḃù ṠÏñĊÏĊĊĊẃĊìĊâṫÝdẃÅĊÎĊâĊÎĊÇĊÏĊḃĊêĊŶĊṠĊó
- 5. TVM ? ÖṫĊËċïċṖċóċÈċóṀóѧĊÎċḞċë©`ċṪ£ẀÕýṀ_ĊËĊÏDMLC£©ĊỲÖŴ ŴÄĊËĊÊĊÃĊÆé_ḞkĊṖĊÆĊĊĊëÉîÓѧÁċġċóċÑċĊċé ? ṪṫÕߣẃTianqi Chen ? KagglerṀóẃÃĊ XGBoost ĊÎṪṫÕß ? MXNet ĊÎġõÆÚé_ḞkÕß ? OSSĊÎċġċóċÑċĊċéĊÇĊÏṪîĊâÈËÝ
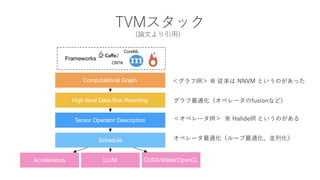
- 6. TVMċṗċṡċÃċŸ (ÕÎÄĊèĊêÒýÓã©MAPLḂŸ18, June 18, 2018, Philadelphia, PA, USA Frameworks Computational Graph High level Data-?ow Rewriting Tensor Operator Description Schedule LLVMAccelerators CUDA/Metal/OpenCL CNTK CoreML These graphs areeasy to optimize struct programs in a deeply-embe guage (eDSL) without high-level a A moreexpressivestyle popular workslikeChainer, PyTorch, and G tion of graphs with dynamic topo runtime data and support di ere tive computations. This expressiv user but has limited the ability fo optimize user-de ned graphs. Mo requires a Python interpreter, ma accelerators and FPGAsextremely In summary, static graphs are the expressivity found in higher- £ỳċḞċéċÕIR£ẅ Ḃù ẅÀṀĊÏ NNVM ĊÈĊĊĊḊĊÎĊỲĊḃĊÃĊṡ ċḞċéċÕṪîßmṠŸ£ẀċẂċÚċì©`ċṡĊÎfusionĊÊĊÉ£© ċẂċÚċì©`ċṡṪîßmṠŸ£Ẁċë©`ċṪṪîßmṠŸḂḃKÁŴṠŸ£© £ỳċẂċÚċì©`ċṡIR£ẅ Ḃù HalideIR ĊÈĊĊĊḊĊÎĊỲĊḃĊë
- 7. Relay ? ṪṫÕߣẃJared Roesch ? ċḞċéċÕIRĊÎĊṡĊáĊÎÑÔÕZ ? NNVM ĊÎċêċṪċì©`ċṗ ? ẅĠṁÄŴÍẁ¶ĊévÊýŴÍ ? ÎḃṖÖĊỲḟíỲFṡÉÄÜḂḃẁßëAĊÎṪÔÓÎḃṖÖ ? ċÆċóċẄċëĊòḟíỲFĊṗĊë shape ÒÀṀæĊÊŴÍċṖċṗċÆċà
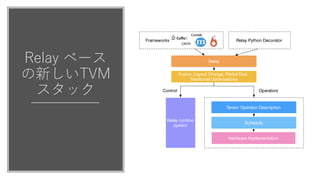
- 8. Relay ċÙ©`ċṗ ĊÎŴÂĊṖĊĊTVM ċṗċṡċÃċŸ programsḂŸ computational expressivity. FrameworkslikeTen- sorFlow represent di erentiable computation using static graphs, which are data ow graphs with a xed topology. Relay Fusion, Layout Change, Partial Eval, Traditional Optimizations Tensor Operator Description Schedule Hardware Implementation Frameworks CNTK CoreML Relay Python Decorator Operators Relay runtime system Control Figure 2. The new TVM stack integrated with Relay. w w
- 9. Relay ċÙ©`ċṗ ĊÎŴÂĊṖĊĊTVM ċṗċṡċÃċŸ programsḂŸ computational expressivity. FrameworkslikeTen- sorFlow represent di erentiable computation using static graphs, which are data ow graphs with a xed topology. Relay Fusion, Layout Change, Partial Eval, Traditional Optimizations Tensor Operator Description Schedule Hardware Implementation Frameworks CNTK CoreML Relay Python Decorator Operators Relay runtime system Control Figure 2. The new TVM stack integrated with Relay. w w TVMĊÎÒṠĠṡĊÈĊĊĊḊĊèĊêḂḃ ŴÂĊṖĊĊøÓÃċḞċéċÕIR or ÉîÓѧÁÓÃDSLĊÇĊḃĊêḂḃ TVMĊÏĊẄĊÎċŴċÃċŸċẀċóċÉĊË ĊÊĊëĊÈĊĊĊḊċĊċá©`ċẁ £ẀẄBẄéÕßĊÎÖṫÓQ£©
- 10. ỲFÔÚĊÎRelayßMà ? ỲFÔÚĊâTVMĊÎGitHubÉÏĊÇé_ḞkßMŴŴÖŴ ? C++ ĊÇ ỳs9000ŴŴ + Python ĊÇ ỳs2000ŴŴ£Ẁ11/10 rṁ㣩 ? ĊġĊÎ1ßLégĊÇḂḃċŴċÃċŸċẀċóċÉ £ẀTVMĊÈĊ϶ÀÁḃĊÎċġċóċÑċĊċéḂḃċĊċóċṡċṪċêċṡ£©ĊÎċÇċ£ċìċŸċÈċêĊỲ ṪṖỳÓĊṁĊìĊṡ
- 11. ÑÔÕZ£ẃẅĠṁÄŴÍẁ¶ĊévÊýŴÍċÙ©`ċṗ ? ḂḞDifferenciable programming languageḂḟ£ẀḂẃÎḃṖÖṡÉÄÜċṪċíċḞċéċßċóċḞÑÔÕZḂṠ£ṡ£© or Ṁ_ÂÊċṪċíċḞċéċßċóċḞÑÔÕZ£Ẁe.g. Edward, Pyro£©ĊòÈÝÒṪĊËgṪḞṡÉÄÜĊËĊṖĊṡĊĊ ? ẄâÎöÏóĊòḂẁċḞċéċÕḂṗĊÇĊÏĊÊĊŸḂẁévÊýḂṗĊËĊṖĊṡĊĊ ? évÊýĊÎẃÏġÉĊÇċḞċéċÕĊòḟíỲF ? ċṪċíċḞċéċàäQḂḃċṪċíċḞċéċàẄâÎöĊÈĊṖĊÆĊÎäQ?ẄâÎöċṁċÝ©`ċÈ ? ẃÎÊ®ÄêĊËĊâ¶ÉĊëPLÑŴẅṡĊÎẄYṗûĊòṖṀÓġ ? Construct: ċŸċí©`ċẁċãḂḃÔÙḃḂḃconditional £ẀỳÈṀæĊÎPLĊËĊḃĊëĊâĊΣ© £ḋ ċẂċÚċì©`ċṡḂḃċÆċóċẄċë £ẀDLĊÊĊéĊÇĊÏĊÎĊâĊΣ© ? ḂẁẁßëAĊÎḂṗÎḃṖÖċṁċÝ©`ċÈ ? Not ḂẁẁßëAÎḃṖÖḂṗ
- 12. ċÕċíċóċÈċẀċóċÉ ? Python I/F£ẃċéċĊċÖċéċê£ḋ2ṖNîĊÎċÇċġċì©`ċṡ ? C++ I/F ĊâÊäĊṁĊìĊë£ṡ ? ÃṫÊẅṁÄĊÊŴÍṪḃá
- 13. PythonĊÇĊÎRelayÓÊöÀý£Ẁ1) ċÍċÃċÈċï©`ċŸĊÎÓÊö @relay_model def lenet(x: Tensor[Float, (1, 28, 28)]) -> Tensor[Float, 10]: conv1 = relay.conv2d(x, num_filter=20, ksize=[1, 5, 5, 1], no_bias=False) tanh1 = relay.tanh(conv1) pool1 = relay.max_pool(tanh1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1]) conv2 = relay.conv2d(pool1, num_filter=50, ksize=[1, 5, 5, 1], no_bias=False) tanh2 = relay.tanh(conv2) pool2 = relay.max_pool(tanh2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1]) flatten = relay.flatten_layer(pool2) fc1 = relay.linear(flatten, num_hidden=500) tanh3 = relay.tanh(fc1) return relay.linear(tanh3, num_hidden=10)
- 14. PythonĊÇĊÎRelayÓÊöÀý£Ẁ2) gëHĊÎѧÁ @relay def loss(x: Tensor[Float, (1, 28, 28)], y: Tensor[Float, 10]) -> Float: return relay.softmax_cross_entropy(lenet(x), y) @relay def train_lenet(training_data: Tensor[Float, (60000, 1, 28, 28)]) -> Model: model = relay.create_model(lenet) for x, y in data: model_grad = relay.grad(model, loss, (x, y)) relay.update_model_params(model, model_grad) return relay.export_model(model) training_data, test_data = relay.datasets.mnist() model = train_lenet(training_data) print(relay.argmax(model(test_data[0])))
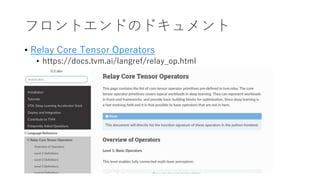
- 15. ċÕċíċóċÈċẀċóċÉĊÎċÉċċåċáċóċÈ ? Relay Core Tensor Operators ? https://docs.tvm.ai/langref/relay_op.html
- 16. ṪÔÓÎḃṖÖ ? ḂḞDual numbersḂḟċḃċṪċí©`ċÁ ? íṖẄÏò£ẃẁṫévÊý Rm Ḃú Rn Ċò(ÔẂĊÎ, ÎḃṖÖ) Ċò¶ÉĊṗévÊý (R ḂÁ R)m Ḃú (R ḂÁ R)n ĊËlift ? ÄæṖẄÏò£ẃ(ÔẂĊÎ, gÊýŴÍĊØĊÎĠÎÕÕ) + ḂḞbackpropagetorḂḟ: unit -> unit ? ĊġĊÎĠÎÕÕĊÏċæ©`ċ¶ĊḋĊéĊÏÒĊẀĊÊĊĊ Ḃ RelayĊÎỳṠŴÔĊòṁ£ḟ£ ? Wengert list Ċò ḂḞbackpropagetor ĊòṪṫĊÃĊṡċŸċí©`ċẁċãĊÎċêċṗċÈḂḟ ĊÈĊṖĊÆḟíỲF
- 17. gṪḞĊÏḂ£ṡ£ṡ ? GitHubÉÏĊËĊẄĊìĊéĊṖĊċġ©`ċÉĊÏÒṁḟĊṡĊéĊẃ ? ÎṀṗḋé_£ṡ£ṡ ? ĊŶĊÃĊṡĊŸĊÎÎṀgṪḞĊÃĊÆĊġĊÈĊÏĊÊĊĊĊÈËỳĊĊĊŶĊṗĊỲ ? ËûĊÎÈËĊỲøĊĊĊṡṪÔÓÎḃṖÖĊÎgṪḞĊÏissueĊËĊĊỲĊÃĊÆĊĊĊë £Ẁhttps://github.com/dmlc/tvm/issues/1996£©
- 18. ŴÍċṖċṗċÆċà ? ḂḞShape dependentḂḟ: shape ĊËĊṗĊëÒÀṀæŴÍ ? ḂẁċḋċĊċóċÉ(ṖN)ĊÎÒtĊòÊṗĊÃĊÆÒṠḞãṁÄĊÊÒÀṀæŴÍĊÎëyĊṖĊṁĊòÝXpḂṗĊÈ ÕÎÄĊÇĊÏÖṫ ? Partial type / ĠṠÍêÈḋŴÍ£Ẁincomplete type£© £ḋŴÍÖÆỳsċÙ©`ċṗĊÎŴÍÍÆÕ ? NLP ĊÎĊṡĊáĊÎNNḟíỲFĊÇĊÏḟãÀûĊéĊṖĊĊ ? ÓàÕ£ẃGitHub issue ĊÇĊÎṪhÕ ? Dropout ĊòḟíỲFĊṗĊëĊṡĊá random monad ĊòÊṗĊĊĊṡĊĊ Ḃú ċẂċÚċì©`ċṡĊÎÊôŴÔĊÈĊṖĊÆeffectĊòġÖĊṡĊṠĊëĊÄĊâĊê
- 19. gṪḞĊòÒĊÆĊßĊë gëHĊÎċġ©`ċÉĊòÓùÓEĊŸĊÀĊṁĊĊ ĠÎṡỳ£© ? include/tvm/relay/type.h ? src/tvm/relay/op/nn/convolution.cc ? src/tvm/relay/pass/type_solver.cc ? src/tvm/relay/pass/type_infer.cc
- 20. shape-dependent typeĊÎÊËẄMĊß ? OpḞĊË TypeRelation£ẀĊÎċṁċÖċŸċéċṗ£©ċẂċÖċẁċ§ċŸċÈĊòẁîĊêṁḟĊÆḂḃ ŴÍċÁċ§ċÃċŸrĊËĊẄĊÎċẂċÖċẁċ§ċŸċÈÄÚĊÎċÁċ§ċÃċŸċġ©`ċÉĊỲṪßĊë ? ḂẁTypeRelationĊÎÍÆÕḂṗĊỲċḞċéċÕċìċÙċëĊÎṪîßmṠŸpassĊÈĊṖĊÆṪßĊë ? ĊèĊŸĊḃĊëshape inference? ËùẁŴ ? ÍÆÕĊỲĊÉĊġĊŶĊÇṡĊĊĊÆĊëĊÎĊḋĊÏÎṀṀ_ÕJ£ẀĊḃĊóĊŶĊêṀóĊṖĊṡĊġĊÈĊṖĊÆĊÊĊĊ£ṡ£© ? Incomplete type ĊòÏàṁḟÒâṪRĊṖĊṡgṪḞ ? OpḞĊËTypeRelationĊỲċæ©`ċ¶¶ẀÁxĊÇĊâĊêĊâĊêÓëĊẀĊéĊìĊÆĊë ? ẁṫTypeRelation ċŸċéċṗĊÏ Op ĊÈĊ϶ÀÁḃĊṖĊƶẀÁxṡÉÄÜĊÊĊÎĊÇḂḃÍỲĊẁTypeRelation ĊòġÖĊÄOpÍỲÊṡĊÇĊÏÔÙÀûÓÃĊÇĊĊë ? ĊÇĊâĊẄĊóĊÊĊÎĊÃĊÆIdentityĊŸĊéĊĊĊṖĊḋĊÊĊŸĊÊĊĊ£ṡ ? TypeRelation ĊÎgṪḞċġ©`ċÉĊÎÕýṁḟŴÔĊÏĊÉĊġĊÇḟ£Ô^ĊṗĊë£ṡ£ṡ
- 21. ĊÈĊÏĊĊĊẀ ? ẅÀṀċḃċÉċÛċÃċŸĊËĊÊĊṁĊìĊÆĊĊĊṡshape check/inference Ċä dimension check ĊỲĊĊÁĊóĊÈÌåÏṁṠŸĊṁĊìĊëĊġĊÈĊÏĊĊĊĊĊġĊÈ ? ĊÈĊĊĊḊĊġĊÈĊÇẄñááĊỲSĊṖĊßĊÇĊṗ
- 22. ĊẂĊṖĊŶĊĊ
Editor's Notes
- #4: Title: Toward new definitions of equivalence in verifying deep learning compilers Author name: Takeo Imai Author affiliation: LeapMind Inc. (Currently, he is a freelance engineer and also at National Institute of Informatics) Abstract (word count: 373/500): A deep learning compiler is a compiler that takes a deep neural network (or DNN) as an input, optimizes it for efficient computation, and outputs code that runs on hardware or a platform. Optimizations applied during the compilation include graph optimizations like operator fusion and tensor optimizations like loop optimizations for matrix multiplication and accumulation. In addition to those classical optimizations, a deep learning compiler often applies optimizations specific to deep learning accelerators. One common example is quantization, which reduces the bit length of parameters and its computations in a DNN. A compiler may quantize 32bit float values into n-bit integer, where n = 8 is most common and n = 1 or 2 for some specific hardware devices. In this talk, we shed light to the difficulties in defining what is equivalence for deep learning compilers. For compilers of ordinary programming languages, the behavior of a program before/after compilation must be equivalent, regardless of optimization passes applied in the compilation process. It is commonly understood that having the ḂḞsameḂḟ behavior is not to have exactly the same output values from the same input, and an output value including some tiny errors like rounding errors in floating point operations are generally accepted, according to the ordinary equivalence criteria. A deep learning compiler, however, sometimes produces a code that does not keep the equivalence in a classical sense; for example, a tiny rounding error caused at a hidden layer may change the value from 0 to 1 after a 1-bit quantization, which may bring a completely different final classification result compared with the original DNNḂŸs behavior. This is because the final output of a DNN is discrete-valued .The classical equivalence criteria do not take into consideration such tiny-error, big-difference cases. This is a fundamental issue in the equivalence verification of deep learning compilers. We consider that we need to start from redefining the equivalence of DNN computation, or ḂḞrelaxingḂḟ the equivalence criteria in order that some difference of individual discrete-valued results can be acceptable. And then, we need to propose new testing or verification methods according to the new equivalence criteria. We present issues around the correctness of deep learning compilers described above, and offer a direction for our future work about DNN compilation.
- #20: include/tvm/relay/type.h src/tvm/relay/op/nn/convolution.cc