















































![[DLÝÕiŧá]Grandmaster level in StarCraft II using multi-agent reinforcement lear...](https://cdn.slidesharecdn.com/ss_thumbnails/alphastarfinal-191227002114-thumbnail.jpg?width=560&fit=bounds)







More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to Gpu vs fpga (20)




















Recently uploaded (8)








Gpu vs fpga
- 2. ĪŽĪÃĪŦĪęĨÝĨĪĨóĨČ ? Ë―ĪÏĄļ―MĪßÞzĪߥđGPUĪōÔOÓĪ·ĪÆĪĪĪÞĪđ ĻC CUDAĪČĪŦévSĪĘĪĪĪĮĪđ ĻC OpenCLČŦČŧĘĒĪęÉÏĪŽĪÃĪÆĪĘĪĪĪĮĪđ ? FPGAĪÏĪĒĪÞĪęīĨĪÃĪÆĪÞĪŧĪó ĻC ÖļĘūģöĪđČĪĮĪđ ĻC FPGAĪČļņęLĪ·ĪÆĪĪĪŋĪÎĪÏĢąĢ°ÄęŌÔÉÏĮ°ĪĮĪđ ? Altera FLEX10KĪČĪŦĄ
- 3. DMP Ĩ°ĨéĨÕĨĢĨÃĨŊĨđIPĨ―ĨęĨåĐ`Ĩ·ĨįĨó ? ―MÞzĪßCÆũÏōĪąļßÐÔÄÜ?ĩÍÏûŲMëÁĶĨ°ĨéĨÕĨĢĨÃĨŊĨđIP ĨģĨĒ ? ļßÐÔÄÜĢēD/3DĨ°ĨéĨÕĨĢĨÃĨŊĨđIP ? ĩÍëÁĶĨâĨÐĨĪĨëĪŦĪéļßÐÔÄÜĨĒĨßĨåĐ`ĨšĨáĨóĨČĪÞĪĮĨĩĨÝĐ`ĨČ ? ĨÓĨëĨĮĨĢĨóĨ°?ĨÖĨíĨÃĨŊÔėĪËĪčĪëĨđĨąĐ`ĨéĨÖĨëĪĘĨĒĐ`ĨĨÆĨŊĨÁĨã OpenVG 1.1ę PICA200Lite (OpenGLES 1.1 ) ĨŲĨŊĨŋĐ`Ĩ°ĨéĨÕĨĢĨÃĨŊĨđIPĨģĨĒ ĨÕĨĐĨČĨęĨĒĨęĨđĨÆĨĢĨÃĨŊ 3DĨ°ĨéĨÕĨĢĨÃĨŊĨđIPĨģĨĒ ËĘ3DĨ°ĨéĨÕĨĢĨÃĨŊĨđIPĨģĨĒ ĢĻOpenGL ES 1.1 ŧĨQ + ķĀŨÔ ĢĐ SMAPH-S (OpenGLES 2.0 ) PICA200 SMAPH-F
- 4. GPUĪÎģõi ? ēÄÁÏ ĻC íĩãĨĮĐ`Ĩŋ ĻC IndexĨĮĐ`Ĩŋ ĻC ĨÆĨŊĨđĨÁĨã ĻC Ĩ·Ĩ§Đ`ĨĀ ? ĨŅĨéĨáĨŋĢŊĨÆĐ`ĨÖĨëĩČĪōĨėĨļĨđĨŋĪØ void main() { #if defined MASK vec4 mask = texture2D( texture_unit2, out_texcoord0); #else const vec4 mask = vec4( 1.0, 1.0, 1.0, 1.0); #endif #if defined ALPHA_TEST if( mask.x < 0.6) discard; #endif vec3 color = texture2D( texture_unit0, out_texcoord0).xyz; color = planar_reflection2( color);
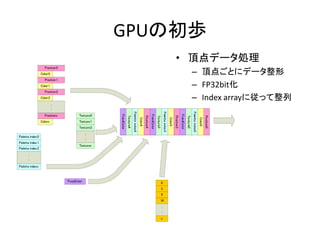
- 5. GPUĪÎģõi ? íĩãĨĮĐ`ĨŋIĀí Position0 ĻC íĩãĪīĪČĪËĨĮĐ`ĨŋÕûÐÎ ĻC FP32bitŧŊ ĻC Index arrayĪËūĪÃĪÆÕûÁÐ Color 0 Position1 Color 1 Position2 Color 2 : : Color0 : : Palette indexx 0 3 4 16 : : x Index array Position0 Palette index0 Texture0 FixedColor Color3 ČŦĪÆfloat24/vec4 Texturex FixedColor Position3 Palette index3 Texture3 Position4 Palette index2 FixedColor : : Palette index0 Palette index1 Color4 Texture2 Texture4 Texture1 Palette index4 Colorx Texture0 FixedColor Positionx VPĪØ
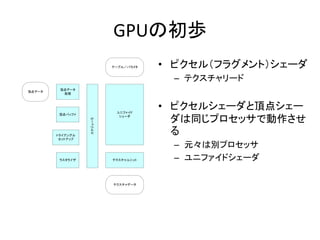
- 6. GPUĪÎģõi ? íĩãĨ·Ĩ§Đ`ĨĀĨŨĨíĨŧĨÃĨĩ ĻC íĩãĨÆĨŊĨđĨÁĨãĨęĐ`ĨÉ ĻC M-VäQ ? íĩãĨÐĨÃĨÕĨĄ ĻC íĩãĨ·Ĩ§Đ`ĨĀIĀíááĪÎĨĮĐ`ĨŋĪōĨđĨČĨĒ ĨÆĨŊĨđĨÁĨã ĨæĨËĨÃĨČ íĩãĨĮĐ`Ĩŋ íĩãĨĮĐ`Ĩŋ IĀí íĩãĨŨĨíĨŧĨĩ íĩãĨÐĨÃĨÕĨĄ
- 7. GPUĪÎģõi ? ĨČĨéĨĪĨĒĨóĨ°ĨëĨŧĨÃĨČĨĒĨÃĨŨ ĻC íĩãĪōĨŨĨęĨßĨÆĨĢĨÖŧŊ ĻC ĨŊĨęĨÃĨÔĨóĨ° ĻC ĨŦĨęĨóĨ° ? ĨéĨđĨŋĨéĨĪĨš ĨÆĨŊĨđĨÁĨã ĻC ŅÝËãÆũĪÎK ? ĨŨĨíĨŧĨÃĨĩĪĮĪäĪëĪČĪŦĢũ ĨÆĨŊĨđĨÁĨã ĨæĨËĨÃĨČ íĩãĨĮĐ`Ĩŋ íĩãĨĮĐ`Ĩŋ IĀí íĩãĨŨĨíĨŧĨĩ íĩãĨÐĨÃĨÕĨĄ ĨČĨéĨĪĨĒĨóĨ°Ĩë ĨŧĨÃĨČĨĒĨÃĨŨ ĨéĨđĨŋĨéĨĪĨķ
- 8. GPUĪÎģõi ĨÆĐ`ĨÖĨë ĨŅĨéĨáĨŋ ? ĨÔĨŊĨŧĨëĢĻĨÕĨéĨ°ĨáĨóĨČĢĐĨ·Ĩ§Đ`ĨĀ ĻC ĨÆĨŊĨđĨÁĨãĨęĐ`ĨÉ íĩãĨĮĐ`Ĩŋ IĀí íĩãĨÐĨÃĨÕĨĄ ĨČĨéĨĪĨĒĨóĨ°Ĩë ĨŧĨÃĨČĨĒĨÃĨŨ ĨéĨđĨŋĨéĨĪĨķ ĨđĨąĨļĨåĐ`Ĩé íĩãĨĮĐ`Ĩŋ ĨæĨËĨÕĨĄĨĪĨÉ Ĩ·Ĩ§Đ`ĨĀ ĨÆĨŊĨđĨÁĨãĨæĨËĨÃĨČ ĨÆĨŊĨđĨÁĨãĨĮĐ`Ĩŋ ? ĨÔĨŊĨŧĨëĨ·Ĩ§Đ`ĨĀĪČíĩãĨ·Ĩ§Đ` ĨĀĪÏÍŽĪļĨŨĨíĨŧĨÃĨĩĪĮÓŨũĪĩĪŧ Īë ĻC ÔŠĄĐĪÏeĨŨĨíĨŧĨÃĨĩ ĻC ĨæĨËĨÕĨĄĨĪĨÉĨ·Ĩ§Đ`ĨĀ
- 9. GPUĪÎģõi ? ROPĢĻRendering Output Pipeline / Rasterize OPerationĢĐ ĻC ĻC ĻC ĻC ĻC ĻC Ĩ·Ĩ§Đ`ĨĀĪŦĪé1pixelĪÎĨŦĨéĐ`ĪōĘÜĪąČĄĪÃĪÆ ZĨÐĨÃĨÕĨĄĪōÕiĪóĪĮĪ―ĪÎĨÔĨŊĨŧĨëĪōÃčŧĪđĪŲĪĪŦÅÐķĻĪ·ĪÆ Ī―ĪÎpixelĪŽŌŧ·ŽĘÖĮ°ĪĘĪéZĨÐĨÃĨÕĨĄĪōļüÐÂĪ·ĪÆ ĢĻĨÕĨėĐ`ĨāĨÐĨÃĨÕĨĄĪŦĪéžČĪËøĪŦĪėĪÆĪĪĪëĨŦĨéĐ`ĪōÕiĪóĪĮĢĐ ĢĻĨ·Ĩ§Đ`ĨĀĪŦĪéĪÎĨĒĨëĨÕĨĄĪËūĪÃĪÆĨÖĨėĨóĨÉĪ·ĪÆĢĐ ĨÕĨėĐ`ĨāĨÐĨÃĨÕĨĄĪËøĪÞzĪā íĩãĨĮĐ`Ĩŋ ĨÆĐ`ĨÖĨëĢŊĨŅĨéĨáĨŋ íĩãĨĮĐ`Ĩŋ IĀí ZĨÐĨÃĨÕĨĄ ĨČĨéĨĪĨĒĨóĨ°Ĩë ĨŧĨÃĨČĨĒĨÃĨŨ ĨđĨąĨļĨåĐ`Ĩé ĨæĨËĨÕĨĄĨĪĨÉĨ·Ĩ§Đ`ĨĀĪČ ĨÆĨŊĨđĨÁĨãĨæĨËĨÃĨČĪĀĪąĪōĘđĪĶĪÎĪŽ GPGPU íĩãĨÐĨÃĨÕĨĄ ĨæĨËĨÕĨĄĨĪĨÉ Ĩ·Ĩ§Đ`ĨĀ ROP ĨÕĨėĐ`ĨāĨÐĨÃĨÕĨĄ ĨéĨđĨŋĨéĨĪĨķ ĨÆĨŊĨđĨÁĨãĨæĨËĨÃĨČ ĨÆĨŊĨđĨÁĨãĨĮĐ`Ĩŋ
- 11. GPUĪÎĖØÕ ? ĨđĨëĐ`ĨŨĨÃĨČĨģĨóĨÔĨåĐ`ĨÆĨĢĨóĨ° ĻC Ĩ°ĨéĨÕĨĢĨÃĨŊĨđĪÏmsĪÎĘĀ―į ĻC CPUĪÏĨėĨĪĨÆĨóĨ·ĨģĨóĨÔĨåĐ`ĨÆĨĢĨóĨ°Ģŋ ĻC FPGAĪÏĪÉĪÁĪéĪËĪâÕņĪėĪë ? ŨîķĖĪÎĨėĨĪĨÆĨóĨ·ĪōĩÃĪëĪĘĪéFPGA ? ļĄÓÐĄĘýĩãŅÝËãÖØŌ ĻC RĩđĩÄĪĘFLOPS ? ĪâĪÏĪäTFLOPSĪË ? ĪŋĪĀĪ·ëÁĶĘģĪĪ ĻC ÕûĘýoŌĪČŅÔĪÃĪÆĪâÁžĪĪĪ°ĪéĪĪ ? Ũî―üĪÏĪ―ĪĶĪĮĪâĪĘĪĪĪąĪÉ ĻC GPUĪĮÕûĘýŅÝËãĪōĪđĪëĪÎĪÏĪâĪÃĪŋĪĪĪĘĪĪĪŦĪâ ? ëÁĶŋÂĘŨîĪŦĪâ ? ÕûĘýĪĘĪéFPGAīóŧîÜSĪÎŋÉÄÜÐÔ
- 12. GPUÐÔÄÜĪōÉÏĪēĪëĪŋĪáĪË ? ŋÉÄÜĪĘĪéđĖķĻĨŅĨĪĨŨĨéĨĪĨóĪĮ ĻC ĪäĪëĪģĪČĪŽQĪÞĪÃĪÆĪĪĪėĪÐĨŨĨíĨŧĨÃĨĩĪčĪęļßŋÂĘ ? ģöĀīĪëĪĀĪągÉ―ŅÝËãÆũĪōÔĪáĪë ĻC ŨîĩÍÏÞĪÎūŦķČĪĮ ? ļũŅÝËãÆũĪÎĘđÓÃÂĘĪōģöĀīĪëĪĀĪąļßĪŊ ĻC gÉ―ČëĪėĪÆĪâÓĪĪĪÆĪĘĪĪĪóĪļĪãŌâÎķĪŽoĪĪ ? ÓŨũÖÜēĻĘýĪōļßĪŊ ĻC ĨŅĨĪĨŨĨéĨĪĨóŅÝËãÆũ ? ļĄÓÐĄĘýĩãŅÝËãĪĀĪČąØí ĻC ĪÁĪįĪÃĪČđÅĪĪGPUĪĀĪČ4stage ĻC Ũî―üĪÎĪÏķā·Ö8stageĪČĪŦ ? ÕûĘý?đĖķĻÉŲĘýĪĮĪâ32bitĪĘĪéąØŌŠ ? ķÎĘýÉîĪŊĪđĪėĪÐļßÖÜēĻĘýęŋÉÄÜ ĻC ŋÂĘÁžĪŊÓĪŦĪđĪÎĪÏëyĪ·ĪŊĪĘĪë
- 13. ĨŅĨĪĨŨĨéĨĪĨóŅÝËãÆũ ? GPUĪÏĪĘĪžĨŅĨĪĨŨĨéĨĪĨóŅÝËãÆũĪōĘđĪĪĪģĪĘĪŧĪë ĪÎĪŦ ĻC ļũĨŅĨĪĨŨĨéĨĪĨóĪËeĄĐĪÎĨđĨėĨÃĨÉĪŽŨßĪÃĪÆĪĪĪë ? GPUĪŽÐÔÄÜģöĪŧĪëÃØÃÜĪÏĪģĪė ĻC ĪģĪÎĪčĪĶĪËÓĪąĪĘĪĪĨĒĨŨĨęĨąĐ`Ĩ·ĨįĨóĪĮĪÏÐÔÄÜĪŽģöĪĘ ĪĪ ? FPGAĪĮĪâÐÔÄÜĪōģöĪđĪËĪÏĄĒÍŽĪļĪčĪĶĪËĨŅĨĪĨŨĨéĨĪ ĨóŅÝËãÆũĪËĨĮĐ`ĨŋĪōÔĪáĪĘĪĪĪČĪĪĪąĪĘĪĪ ĻC ĨėĨĪĨÆĨóĨ·ĪËĖØŧŊĪđĪëĪĘĪéĪ―ĪÎÏÞĪęĪĮĪÏĪĘĪĪĢŋ
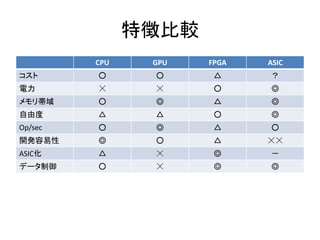
- 14. GPUĪÎĪÛĪĶĪŽÓÐĀûĪĘöšÏ ? ? ? ? īóÁŋĪÎļĄÓÐĄĘýĩãŅÝËã ëÁĶÝĪËĪ·ĪĘĪĪ ĨĮĐ`ĨŋKÁÐÐÔ ĨėĨĪĨÆĨóĨ·ÝĪËĪ·ĪĘĪĪ
- 15. FPGAĪÎĪÛĪĶĪŽÓÐĀûĪĘöšÏ ? Float/intūŦķČĪŽēŧŌŠ ĻC ÐĄĪĩĪĪŅÝËãÆũĘđĪĻĪë ? ? ? ? ? ÏûŲMëÁĶÖØŌŠ ĨėĨĪĨÆĨóĨ·ÖØŌŠ ĨŅĨĪĨŨĨéĨĪĨóĪōÉîĪŊģöĀīĪë ÉŲĪĘĪĪĨęĨ―Đ`ĨđĪĮŨãĪęĪëĨĒĨŨĨęĨąĐ`Ĩ·ĨįĨó ŋāšĪō ĪïĪĘĪĪ ĻC HWÎÝĪĮĪâFPGAĨÄĐ`ĨëĪËĪÏĨÏĨÞĪëĪģĪČķāĪĪĪĮĪđ ? FPGAĨĒĐ`ĨĨÆĨŊĨÁĨãĪËšÏĪĶŧØ·ĪŽŨũĪėĪë ? ĖØĘâĪĘĨáĨâĨęĨĒĐ`ĨĨÆĨŊĨÁĨãĪŽąØŌŠ ĻC īóĪĪĘĄÓōĪÏąØĪšĪ·ĪâąØŌŠĪĘĪĪ ? ĄÓōĪĀĪąĪĮŲØĪ·ĪŋĪéGPUĪŽÉÏĪËĪĘĪë
- 17. ĘÂĀýĪ―ĪÎĢą - GPU ? FPGAĪËGPUĪōČëĪėĪÆĪßĪëĄĢ ĻC ĘđĪÃĪŋĪâĪÎ ? TEDÉįŅuFPGAĨÜĐ`ĨÉ ĻC Xilinx Virtex7ĘđÓÃ(XC7V2000T) ? ĨÏĨĪĨĻĨóĨÉĪâĪĪĪĪĪČĪģĪí ĻC ĪŠķΞsxxxÍōŌĢĻĩąrĢĐ ĻC ČëĪėĪŋĪâĪÎ ? DMP OpenGLES3.0ĘGPU ĻC SMAPH-S ĻC 4 shaders ? 4SIMD x 4
- 18. đóąĘģŌīĄĨÜĐ`ĨÉĀý
- 19. đóąĘģŌīĄĨÜĐ`ĨÉĀý
- 20. đóąĘģŌīĄĨÜĐ`ĨÉĀý
- 21. ĘÂĀýĪ―ĪÎĢą - GPU ? ―Yđû ĻC Slice LUT:70% ĻC Slice reg: 15% ĻC BRAM:20% ĻC ĪŋĪŦĪŽĢīĪÄĪÎSIMDĨŨĨíĨŧĨÃĨĩĪĮļîĪČĪĪĪÃĪŅĪĪĪČĪĪĪĶĪģĪČ ? GPUĪÏÅäūĪŽķāĪĪĪÎĪĮĄĒĪĒĪÞĪęÔĪÞĪéĪĘĪĪ ? ŽFrĩãĪĮĪÏFPGAĪĮļĄÓÐĄĘýĩãŅÝËãĪōQĪĶĪÎĪÏĨáĨęĨÃĨČÉŲĪĘĪĪĢŋ ĻC ĪģĪėĪĮĪâĪŦĪĘĪęĪÞĪ·ĪËĪĘĪÃĪŋ ? Virtex6ĪČĪŦĪŌĪÉĪŦĪÃĪŋ ? ĨÏĨšĨėĘĀīúĪËŨĒŌâĪ·ĪÞĪ·ĪįĪĶ
- 22. ĘÂĀýĪ―ĪÎĢē ĻC ŅÝËãÆũĨĒĨėĨĪ ? ÄŋĩÄ ĻC FPGAĪËĪÉĪėĪ°ĪéĪĪļĄÓÐĄĘýĩãŅÝËãÆũĪŽÔĪÞĪëĪŦī_ ĪŦĪáĪÆĪßĪë ? ļņ°ēFPGAĪĮĪÉĪėĪ°ĪéĪĪĪÎFLOPSĪÞĪĮÐÐĪąĪëĪŦ ĻC ļĄÓÐĄĘýĩãŅÝËãĨĒĨŊĨŧĨéĨėĐ`ĨŋĪČĪ·ĪÆĘđĪĶĨĪĨáĐ`Ĩļ ? hūģ ĻC Xilinx Zynq-7000 ? XC7Z020CLG484 ? f:50MHz ĻC ËŲĪĪļĄÓÐĄĘýĩãŅÝËãCĪŽÓÃŌâĪĮĪĪÞĪŧĪóĪĮ ĻC îBĪėĪÐ200MHzĪ°ĪéĪĪĪÞĪĮĪÏÐÐĪąĪëĪŦĪČ
- 23. ĨÖĨíĨÃĨŊí ? ÓŨũĨÕĨíĐ`ĪÏŌÔÏÂĪÎÍĻĪę AXI Interconnect master ĻC DMAC ĻC ĻC FP Unit Array IBUF1 SW OBUF0 SW IBUF0 ĻC OBUF1 ? IBUFĪØĪÎøĪÞzĪßž°ĪÓ OBUFĪŦĪéĪÎÕiĪßģöĪ·ĪÏĄĒĨĀ ĨÖĨëĨÐĨÃĨÕĨĄĪËĪčĪęÓËãÖÐ ĪËĪâÐÐĪĶĄĢ ? FP Unit ArrayĪÎŌÄĢĪōĪÉĪģ ĪÞĪĮĪäĪŧĪëĪŦ Configuration Register AXI Interconnect slave ARMĪŦĪéĨâĐ`ĨÉĩČĪōĨėĨļĨđ ĨŋÔOķĻ DMACĪĮARMČĨáĨâĨęĪŦĪé IBUF0ÓÖĪÏ1ĪØÓËãĨĮĐ`Ĩŋ ÜËÍ ÆðÓĄĢÓËã―YđûĪōOBUF0 ÓÖĪÏ1ĪËøĪÞzĪß DMACĪĮOBUFĪŦĪéARMČ ĪØøĪøĪ·
- 24. ĨÖĨíĨÃĨŊí MAD MAD INP MAD MAD UNIT ? ŧųąūĨæĨËĨÃĨČ ĻC Fp32 multiply and add x 4 ĻC Fp32 x 8 variable input ĻC Fp32 x 4 constant input ĻC 4stage pipeline
- 25. ĨÖĨíĨÃĨŊí 1set IBUF0 UNIT FIFO UNIT SFU UNIT FIFO UNIT SFU UNIT FIFO FIFO FIFO OBUF0 FIFO Constant register ? UNITĢēĪÄĪČSFUĢąĪÄĪōĨŧĨÃĨČĪËĘýÖéĪÄĪĘĪŪ ĻC SFU ? RCP/RSQ/SIN/COS/EXP/LOG ? Fp32bit x 1 ? ĪĒĪŊĪÞĪĮÔuýĪÎĪŋĪáĪÎŧØ· ĻC ķāÉŲĪĘĪęĪČĪâĘđĪĪÎïĪËĪ·ĪčĪĶĪČĪđĪëĪĘĪéĄĒUNITĪÎČëÁĶž°ĪÓĨÐĨÃĨÕĨĄĪōĪäĪĩĪĘ ĪĪĪČĪĪĪąĪĘĪĪĪŽĄ ? ÅäūĘđĪĪß^ĪŪĪëĪČFPGAĪËĪÏČëĪéĪĘĪĪ ? ĨÛĨóĨČĪÏUNITÄÚēŋĪËąČÝ^ÆũĩČČëĪėĪÆĄĒš gĪĘ·ÖáŠĪŽģöĀīĪëĪčĪĶĪËĪ·ĪŋĪĪ
- 27. ĘÂĀýĪ―ĪÎĢē ĻC ŅÝËãÆũĨĒĨėĨĪ ? ―Yđû ĻC Slice LUT: 94.91% ĻC Slice Reg: 35.57% ĻC ČëĪÃĪŋĪâĪÎ ? IBUF0 UNIT FIFO UNIT SFU UNIT ĪģĪėĪĀĪąĄú ĻC 33 FP units FIFO ? 1.65GFLOPS ? 200MHzĪĘĪé6.6GFLOPS FIFO ĻC ĪâĪÁĪíĪógëHĪģĪóĪĘĪËģöĪÞĪŧĪóĪŽ Constant register ĻC ĢąĨéĨóĨŊÉÏĪÎFPGAĪÎöšÏ ? ? ? XC7Z030CLG484 93FP units 29.65GFLOPS ĻC 200MHzĪĘĪé118.6GFLOPS ĻC ArtixĨŊĨéĨđĪĀĪČÖÆÓųÏĩĪĮĪŦĪĘĪęĨęĨ―Đ`ĨđĘģĪÃĪÆĪ·ĪÞĪĪĄĒÓËãĪËĨęĨ―Đ`ĨđĪŽŧØĪéĪĘĪĪĢŋ ? Z030ĪÏKintexĨŊĨéĨđĪĀĪ―ĪĶĪĮ OBUF0
- 28. ĪÞĪČĪá ? °ēýĪĘFPGAĪĮĪÏĪäĪėĪëĪģĪČĪŽÉŲĪĘĪĪ ĻC ĖØĪËŅÝËãÏĩ ĻC ŅÝËãÏĩĪĘĪéGPUĨŠĨđĨđĨá ? ASICŧŊĪōŌūÝĪĻĪŋĨŨĨíĨČĨŋĨĪĨŨŨũģÉÓÃĪËũČÁĶ