°Ā¾±°ł±š»å°Õ¾±²µ±š°ł¤ņĻź¤·¤ÆÕhĆ÷
Download as PPTX, PDF1 like9,816 views

²Ń“Ē²Ō²µ“Ē¶Łµž¤Ī„¹„Č„ģ©`„ø„Ø„ó„ø„ó¤Ē¤¢¤ė°Ā¾±°ł±š»å°Õ¾±²µ±š°ł¤Ė¤Ä¤¤¤ĘĻź¤·¤ÆÕhĆ÷¤·¤Ž¤¹

![Copyright ?2017 CREATIONLINE, INC. All Rights Reserved
×Ō¼ŗ½B½é
2
{"ID" £ŗ"fetaro"
"ĆūĒ°"£ŗ"¶É²æ ŲĢ«ĄÉ"
"ŃŠ¾æ"£ŗ"|¾©¹¤I“óѧ¤Ē„Ē©`„æ„Ł©`„¹¤ČĒéóŹĖ÷¤ĪŃŠ¾æ
(@ČÕ±¾„Ē©`„æ„Ł©`„¹Ń§»į)"
"ŹĖŹĀ"£ŗ{Ē°Ā:["Ō^ČÆ»įÉē¤Ī„Ŗ„ó„鄤„ó„Č„ģ©`„É„·„¹„Ę„ą¤ĪWeb»ł±P",
"„Ŗ©`„ׄ󄽩`„¹¤Ź¤éŗĪ¤Ē¤ā”£Ö÷¤ĖMongoDB,NoSQL"],
¬FĀ:["“óŹÖWebĘóI¤Īŗį¶Ļ·ÖĪö»ł±P,Exadata,Hortonworks,EMR"]
ø±I:["MongoDB„³„󄵄ė„æ„ó„Č" ]}
"„Ø„Ē„£„æ"£ŗ"emacsÅÉ",
"ȤĪ¶"£ŗ ["×ŌÕ¬„µ©`„Š","ĀéČø"]
}](https://image.slidesharecdn.com/wiredtiger-170919000215/85/WiredTiger-2-320.jpg)


















![[GKE & Spanner Ćć»į] Cloud Spanner ¤Ī¼¼ŠgøÅŅŖ](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=560&fit=bounds)


















More Related Content
What's hot (20)
Similar to °Ā¾±°ł±š»å°Õ¾±²µ±š°ł¤ņĻź¤·¤ÆÕhĆ÷ (20)













![[db tech showcase Tokyo 2016] B31: Spark Summit 2016£ĄSF¤Ė²Ī¼Ó¤·¤Ę¤¤æ¤Ī¤Ē×īŠĀŹĀĄż¤Ź¤É¤ņ½B½é¤·¤Ä¤Ä„Ē...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=560&fit=bounds)




More from Tetsutaro Watanabe (20)




















°Ā¾±°ł±š»å°Õ¾±²µ±š°ł¤ņĻź¤·¤ÆÕhĆ÷
- 1. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved °Ā¾±°ł±š»å°Õ¾±²µ±š°ł¤ņĻź¤·¤ÆÕhĆ÷ 2017/09/13 MongoDBĆć»į in 2017 „³„󄵄ė„æ„ó„Č ¶É²æ ŲĢ«ĄÉ 1
- 2. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved ×Ō¼ŗ½B½é 2 {"ID" £ŗ"fetaro" "ĆūĒ°"£ŗ"¶É²æ ŲĢ«ĄÉ" "ŃŠ¾æ"£ŗ"|¾©¹¤I“óѧ¤Ē„Ē©`„æ„Ł©`„¹¤ČĒéóŹĖ÷¤ĪŃŠ¾æ (@ČÕ±¾„Ē©`„æ„Ł©`„¹Ń§»į)" "ŹĖŹĀ"£ŗ{Ē°Ā:["Ō^ČÆ»įÉē¤Ī„Ŗ„ó„鄤„ó„Č„ģ©`„É„·„¹„Ę„ą¤ĪWeb»ł±P", "„Ŗ©`„ׄ󄽩`„¹¤Ź¤éŗĪ¤Ē¤ā”£Ö÷¤ĖMongoDB,NoSQL"], ¬FĀ:["“óŹÖWebĘóI¤Īŗį¶Ļ·ÖĪö»ł±P,Exadata,Hortonworks,EMR"] ø±I:["MongoDB„³„󄵄ė„æ„ó„Č" ]} "„Ø„Ē„£„æ"£ŗ"emacsÅÉ", "ȤĪ¶"£ŗ ["×ŌÕ¬„µ©`„Š","ĀéČø"] }
- 3. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved ? ”øWiredTiger”¹¤ņ¤·¤Ć¤Ę¤¤¤Ž¤¹¤«£æ 3
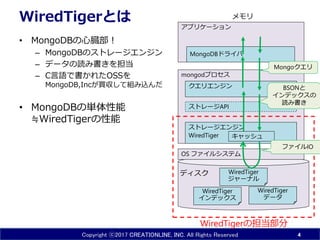
- 4. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved OS „Õ„”„¤„ė„·„¹„Ę„ą WiredTiger¤Č¤Ļ ? MongoDB¤ĪŠÄÄ ²æ£” ØC MongoDB¤Ī„¹„Č„ģ©`„ø„Ø„ó„ø„ó ØC „Ē©`„æ¤ĪÕi¤ßų¤¤ņµ£µ± ØC CŃŌÕZ¤Ēų¤«¤ģ¤æOSS¤ņ MongoDB,Inc¤¬ŁI §¤·¤Ę½M¤ßŽz¤ó¤Ą ? MongoDB¤Ī gĢåŠŌÄÜ ØPWiredTiger¤ĪŠŌÄÜ 4 „¢„ׄź„±©`„·„ē„ó MongoDB„Ʉ鄤„Š mongod„ׄķ„»„¹ WiredTiger „ø„ć©`„Ź„ė WiredTiger „Ē©`„æ WiredTiger „¤„ó„Ē„Ć„Æ„¹ „¹„Č„ģ©`„ø„Ø„ó„ø„ó WiredTiger „¹„Č„ģ©`„øAPI „Æ„Ø„ź„Ø„ó„ø„ó WiredTiger¤Īµ£µ±²æ·Ö „Ē„£„¹„Æ „į„ā„ź Mongo„Æ„Ø„ź BSON¤Č „¤„ó„Ē„Ć„Æ„¹¤Ī Õi¤ßų¤ „„ć„Ć„·„å „Õ„”„¤„ėIO
- 5. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved WiredTiger¤ĪµĒöĒ°¤ĻMMAPv1 ? MongoDB 2.6¤Ž¤Ē¤Ļ„¹„Č„ģ©`„ø„Ø„ó„ø„ó¤ĻMMAPv1¤Ą¤Ć¤æ ØC MMAPv1¤ĻŹÖi¤¤Ī„¹„Č„ģ©`„ø ? MonvoDB 3.0¤«¤é¤ĻWiredTiger¤ņ§Čė ØC ¤Ū¤ÜČ«¤Ę¤ĪČĆę¤ĒWiredTiger¤¬¤ģ¤Ę¤¤¤ė(Õi¤ßŽz¤ßŠŌÄÜŅŌĶā) 5 WiredTiger MMAPv1 MongoDB 2.6 ©` ?„Ē„Õ„©„ė„Č MongoDB 3.0 („Ŗ„ׄ·„ē„ó) ?„Ē„Õ„©„ė„Č MongoDB 3.2 ?„Ē„Õ„©„ė„Č („Ŗ„ׄ·„ē„ó) MongoDB 3.4 ?„Ē„Õ„©„ė„Č („Ŗ„ׄ·„ē„ó)
- 6. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved WiredTiger ¤Č MMAPv1 ¤Īß`¤¤ 6 WiredTiger MMAPv1 øÅŅŖ ĢŲÕ „Ē©`„æÓĄ¾A»Æ¤ĖĢŲ»Æ OSĢį¹©CÄܤĒ„·„ó„ׄė¤Ėg ×° „¢©`„„Ę„Æ„Į„ć MVCC (øüŠĀ¤ĻČ«¤Ę×·Ó) „Ē©`„æ„Õ„”„¤„ė¤½¤Ī¤ā¤Ī¤ņ øüŠĀ ŠŌÄÜ ų¤Žz¤ßŠŌÄÜ ? „É„„å„į„ó„Č gĪ»„ķ„Ć„Æ¤Ēøß ĖŁ ? „³„ģ„Æ„·„ē„ó gĪ»„ķ„Ć„Æ¤Ē µĶĖŁ(”ł) Õi¤ßŽz¤ßŠŌÄÜ ?×·ÓŠĶ¤Ź¤Ī¤Ē¤ä¤äŃ}ėj ”ņ„·„ó„ׄė¤Ź¤Ī¤ĒĖŁ¤¤ „į„ā„źÖĘĻŽ ?æÉÄÜ ?²»æÉÄÜ £ØOS¤¬øī¤źµ±¤Ę¤ė¤Ą¤±Ź¹¤¦) „Õ„”„¤„ė „·„¹„Ę„ą „Ē©`„æRæs ?æÉÄÜ ?²»æÉÄÜ „¤„ó„Ē„Ć„Æ„¹Ræs ?æÉÄÜ ?²»æÉÄÜ „Ē©`„æ„Õ„”„¤„ė¤Ī„Õ„é„° „į„ó„Ę©`„·„ē„ó ?×īŠ”ĻŽ ”÷„É„„å„į„ó„ȤĪ·Ź“ó»Æ¤Ė ¤č¤ź°kÉś „Ē©`„æ¤Č„¤„ó„Ē„Ć„Æ„¹¤Ī ·Öėx ?æÉÄÜ ?²»æÉÄÜ ÄĶÕĻŗ¦ŠŌ „ø„ć©`„Ź„ėo¤·¤Ē„Æ„é„Ć „·„夷¤æ¤Č¤ ?×·ÓŠĶ¤Ź¤Ī¤Ē²¤ģ¤Ź¤¤ ?„É„„å„į„ó„Ȥ¬²¤ģ¤ė £Ø„ź„Ś„¢¤¬±ŲŅŖ£© (”ł)2.6ŅŌĒ°¤Ļ„Ē©`„æ„Ł©`„¹ gĪ»„ķ„Ć„Æ
- 7. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved ¤³¤ģ¤«¤é ? ¤³¤ģ¤«¤éWiredTiger¤ĪÓ×÷¤ĪŌ¼¤ņÕhĆ÷¤·¤Ž¤¹¤¬”¢ ¤¤¤¤Ź¤źWiredTiger¤ĪÕhĆ÷¤Ļėy¤·¤¤¤Ī¤Ē”¢ ¤Ž¤ŗ¤Ļ„·„ó„ׄė¤ŹMMAP v1 ¤«¤é 7
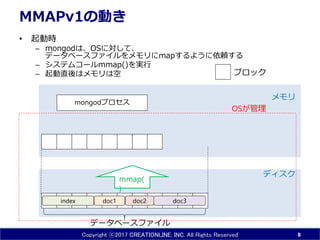
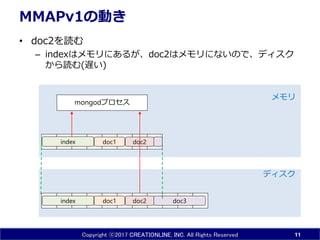
- 8. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? ĘšÓr ØC mongod¤Ļ”¢OS¤Ė¤·¤Ę”¢ „Ē©`„æ„Ł©`„¹„Õ„”„¤„ė¤ņ„į„ā„ź¤Ėmap¤¹¤ė¤č¤¦¤ĖŅĄīm¤¹¤ė ØC „·„¹„Ę„ą„³©`„ėmmap()¤ņgŠŠ ØC ĘšÓÖ±įį¤Ļ„į„ā„ź¤ĻæÕ 8 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„ź mongod„ׄķ„»„¹ OS¤¬¹ÜĄķ „Ö„ķ„Ć„Æ „Ē©`„æ„Ł©`„¹„Õ„”„¤„ė mmap( )
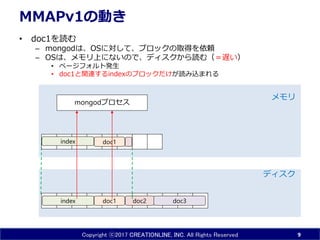
- 9. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc1¤ņÕi¤ą ØC mongod¤Ļ”¢OS¤Ė¤·¤Ę”¢„Ö„ķ„Ć„Æ¤ĪČ”µĆ¤ņŅĄīm ØC OS¤Ļ”¢„į„ā„źÉĻ¤Ė¤Ź¤¤¤Ī¤Ē”¢„Ē„£„¹„Ƥ«¤éÕi¤ą£Ø£½ßW¤¤£© ? „Ś©`„ø„Õ„©„ė„Č°kÉś ? doc1¤ČévßB¤¹¤ėindex¤Ī„Ö„ķ„Ć„Æ¤Ą¤±¤¬Õi¤ßŽz¤Ž¤ģ¤ė 9 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„ź doc1 mongod„ׄķ„»„¹ index
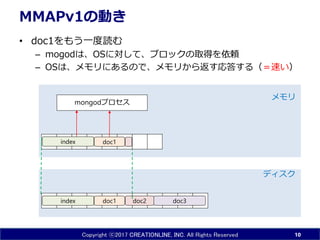
- 10. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc1¤ņ¤ā¤¦Ņ»¶ČÕi¤ą ØC mogod¤Ļ”¢OS¤Ė¤·¤Ę”¢„Ö„ķ„Ć„Æ¤ĪČ”µĆ¤ņŅĄīm ØC OS¤Ļ”¢„į„ā„ź¤Ė¤¢¤ė¤Ī¤Ē”¢„į„ā„ź¤«¤é·µ¤¹ź“š¤¹¤ė£Ø£½ĖŁ¤¤£© 10 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„ź doc1 mongod„ׄķ„»„¹ index
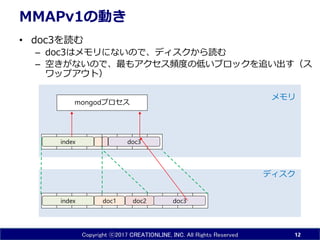
- 11. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc2¤ņÕi¤ą ØC index¤Ļ„į„ā„ź¤Ė¤¢¤ė¤¬”¢doc2¤Ļ„į„ā„ź¤Ė¤Ź¤¤¤Ī¤Ē”¢„Ē„£„¹„Æ ¤«¤éÕi¤ą(ßW¤¤) 11 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„ź doc1 mongod„ׄķ„»„¹ doc2index
- 12. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc3¤ņÕi¤ą ØC doc3¤Ļ„į„ā„ź¤Ė¤Ź¤¤¤Ī¤Ē”¢„Ē„£„¹„Ƥ«¤éÕi¤ą ØC æÕ¤¤¬¤Ź¤¤¤Ī¤Ē”¢×ī¤ā„¢„Æ„»„¹īl¶Č¤ĪµĶ¤¤„Ö„ķ„Ć„Æ¤ņ×·¤¤³ö¤¹£Ø„¹ „ļ„Ƅׄ¢„¦„Č£© 12 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„ź mongod„ׄķ„»„¹ index doc3
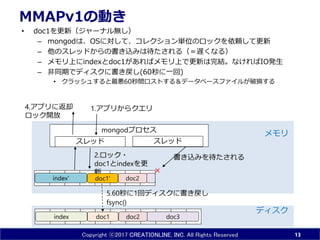
- 13. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc1¤ņøüŠĀ£Ø„ø„ć©`„Ź„ėo¤·£© ØC mongod¤Ļ”¢OS¤Ė¤·¤Ę”¢„³„ģ„Æ„·„ē„ó gĪ»¤Ī„ķ„Ć„Æ¤ņŅĄīm¤·¤ĘøüŠĀ ØC Ėū¤Ī„¹„ģ„Ƅɤ«¤é¤Īų¤Žz¤ß¤Ļ“ż¤æ¤µ¤ģ¤ė£Ø£½ßW¤Æ¤Ź¤ė£© ØC „į„ā„źÉĻ¤Ėindex¤Čdoc1¤¬¤¢¤ģ¤Š„į„ā„źÉĻ¤ĒøüŠĀ¤ĻĶź½Y”£¤Ź¤±¤ģ¤ŠIO°kÉś ØC ·ĒĶ¬ĘŚ¤Ē„Ē„£„¹„ƤĖų¤ų¤·(60Ćė¤ĖŅ»»Ų) ? „Æ„é„Ć„·„夹¤ė¤Č×ī60Ćėég„ķ„¹„Ȥ¹¤ė£¦„Ē©`„æ„Ł©`„¹„Õ„”„¤„ė¤¬ĘĘp¤¹¤ė 13 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„źmongod„ׄķ„»„¹ doc2index' „¹„ģ„Ć„É „¹„ģ„Ć„É ų¤Žz¤ß¤ņ“ż¤æ¤µ¤ģ¤ė2.„ķ„Ć„Æ? doc1¤Čindex¤ņøü ŠĀ ”Į 1.„¢„ׄź¤«¤é„Æ„Ø„ź4.„¢„ׄź¤Ė·µČ“ „ķ„Ć„Æé_·Å 5.60Ćė¤Ė1»Ų„Ē„£„¹„ƤĖų¤ų¤· fsync() doc1'
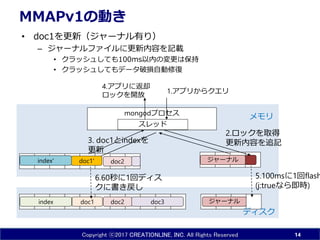
- 14. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved MMAPv1¤ĪÓ¤ ? doc1¤ņøüŠĀ£Ø„ø„ć©`„Ź„ėÓŠ¤ź£© ØC „ø„ć©`„Ź„ė„Õ„”„¤„ė¤ĖøüŠĀÄŚČŻ¤ņÓŻd ? „Æ„é„Ć„·„夷¤Ę¤ā100msŅŌÄŚ¤Īäøü¤Ļ±£³Ö ? „Æ„é„Ć„·„夷¤Ę¤ā„Ē©`„æĘĘp×ŌÓŠŽĶ 14 doc1 doc3index doc2 „Ē„£„¹„Æ „į„ā„źmongod„ׄķ„»„¹ doc2 „¹„ģ„Ć„É 2.„ķ„Ć„Æ¤ņČ”µĆ øüŠĀÄŚČŻ¤ņ×·Ó „ø„ć©`„Ź„ė „ø„ć©`„Ź„ė 5.100ms¤Ė1»Ųflash (j:true¤Ź¤é¼“r) 4.„¢„ׄź¤Ė·µČ“ „ķ„Ć„Æ¤ņé_·Å 1.„¢„ׄź¤«¤é„Æ„Ø„ź 3. doc1¤Čindex¤ņ øüŠĀ 6.60Ćė¤Ė1»Ų„Ē„£„¹ „ƤĖų¤ų¤· doc1'index'
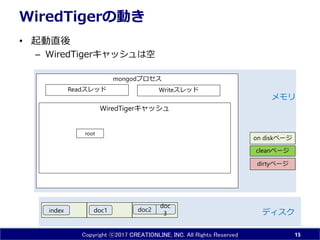
- 15. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? ĘšÓÖ±įį ØC WiredTiger„„ć„Ć„·„å¤ĻæÕ 15 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø root
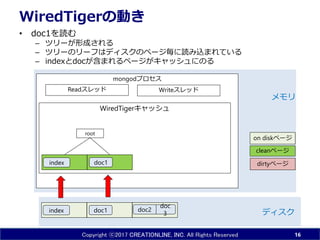
- 16. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? doc1¤ņÕi¤ą ØC „Ä„ź©`¤¬ŠĪ³É¤µ¤ģ¤ė ØC „Ä„ź©`¤Ī„ź©`„Õ¤Ļ„Ē„£„¹„ƤĪ„Ś©`„ø°¤ĖÕi¤ßŽz¤Ž¤ģ¤Ę¤¤¤ė ØC index¤Čdoc¤¬ŗ¬¤Ž¤ģ¤ė„Ś©`„ø¤¬„„ć„Ć„·„å¤Ė¤Ī¤ė 16 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø
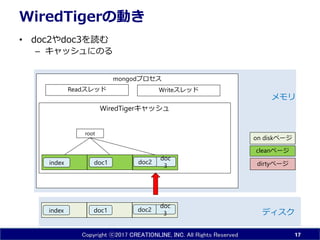
- 17. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? doc2¤ädoc3¤ņÕi¤ą ØC „„ć„Ć„·„å¤Ė¤Ī¤ė 17 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root doc 3 doc2 dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø
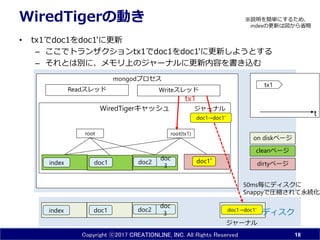
- 18. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? tx1¤Ēdoc1¤ņdoc1'¤ĖøüŠĀ ØC ¤³¤³¤Ē„Č„é„󄶄Ƅ·„ē„ótx1¤Ēdoc1¤ņdoc1'¤ĖøüŠĀ¤·¤č¤¦¤Č¤¹¤ė ØC ¤½¤ģ¤Č¤Ļe¤Ė”¢„į„ā„źÉĻ¤Ī„ø„ć©`„Ź„ė¤ĖøüŠĀÄŚČŻ¤ņų¤Žz¤ą 18 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root doc 3 doc2 doc1”Æ root(tx1) dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø tx1 tx1 tdoc1”śdoc1' „ø„ć©`„Ź„ė „ø„ć©`„Ź„ė doc1”śdoc1' ”łÕhĆ÷¤ņŗ g¤Ė¤¹¤ė¤æ¤į”¢ index¤ĪøüŠĀ¤Ļķ¤«¤éŹ”ĀŌ 50ms°¤Ė„Ē„£„¹„ƤĖ Snappy¤ĒRæs¤µ¤ģ¤ĘÓĄ¾A»Æ¤µ
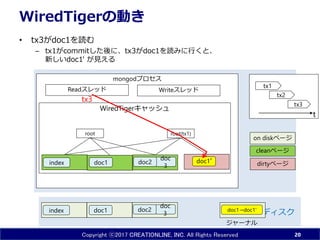
- 19. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? tx2¤Ēdoc1¤ņÕi¤ą ØC tx1¤¬½K¤ļ¤ėĒ°¤Ė”¢doc1¤ĪÕi¤ßŽz¤ß„Č„é„󄶄Ƅ·„ē„ótx2¤¬Ó¤³ö¤¹¤Č”¢ tx2¤Ė¤Ļ¹Å¤¤„É„„å„į„ó„Ȥ¬Ņ¤Ø¤ė 19 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root doc 3 doc2 doc1”Æ root(tx1) dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø tx1 tx2 tx2 tx1 tdoc1”śdoc1' doc1”śdoc1' „ø„ć©`„Ź„ė
- 20. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? tx3¤¬doc1¤ņÕi¤ą ØC tx1¤¬commit¤·¤æįį¤Ė”¢tx3¤¬doc1¤ņÕi¤ß¤ĖŠŠ¤Æ¤Č”¢ ŠĀ¤·¤¤doc1' ¤¬Ņ¤Ø¤ė 20 doc1 doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root doc 3 doc2 doc1”Æ root(tx1) dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø tx3 tx2 tx1 tx3 t doc1”śdoc1' „ø„ć©`„Ź„ė
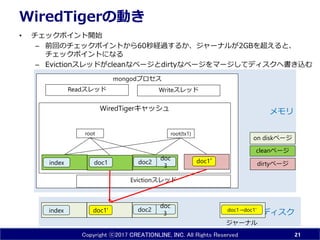
- 21. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? „Į„§„Ć„Æ„Ż„¤„ó„Čé_Ź¼ ØC Ē°»Ų¤Ī„Į„§„Ć„Æ„Ż„¤„ó„Ȥ«¤é60Ćė½Uß^¤¹¤ė¤«”¢„ø„ć©`„Ź„ė¤¬2GB¤ņ³¬¤Ø¤ė¤Č”¢ „Į„§„Ć„Æ„Ż„¤„ó„ȤĖ¤Ź¤ė ØC Eviction„¹„ģ„Ƅɤ¬clean¤Ź„Ś©`„ø¤Čdirty¤Ź„Ś©`„ø¤ņ„Ž©`„ø¤·¤Ę„Ē„£„¹„ƤŲų¤Žz¤ą 21 doc1' doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É doc1index root doc 3 doc2 Eviction„¹„ģ„Ć„É doc1”Æ root(tx1) dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø doc1”śdoc1' „ø„ć©`„Ź„ė
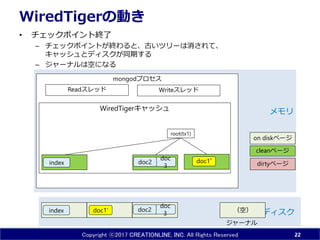
- 22. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved mongod„ׄķ„»„¹ WiredTiger„„ć„Ć„·„å WiredTiger¤ĪÓ¤ ? „Į„§„Ć„Æ„Ż„¤„ó„Č½KĮĖ ØC „Į„§„Ć„Æ„Ż„¤„ó„Ȥ¬½K¤ļ¤ė¤Č”¢¹Å¤¤„Ä„ź©`¤ĻĻū¤µ¤ģ¤Ę”¢ „„ć„Ć„·„å¤Č„Ē„£„¹„Ƥ¬Ķ¬ĘŚ¤¹¤ė ØC „ø„ć©`„Ź„ė¤ĻæÕ¤Ė¤Ź¤ė 22 doc1' doc 3index „Ē„£„¹„Æ „į„ā„ź doc2 Read„¹„ģ„Ć„É Write„¹„ģ„Ć„É index doc 3 doc2 doc1”Æ root(tx1) dirty„Ś©`„ø clean„Ś©`„ø on disk„Ś©`„ø „ø„ć©`„Ź„ė £ØæÕ£©
- 23. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved ¤Ž¤Č¤į ? WiredTiger¤ĻMongoDB¤ĪŠÄÄ ²æ ? ¹Å¤¤ŹÖi¤¤ĪMMAPv1¤«¤é“󷳤ĖßM»Æ ? „ķ„Ć„Æ¤ņ°kÉś¤µ¤»¤Ź¤¤MVCC¤ņńÓĆ 23
- 24. Copyright ?2017 CREATIONLINE, INC. All Rights Reserved ²Ī漤Ė¤·¤æŁYĮĻ ? ¤Į¤ē¤Ć¤Č¹Å¤¤¹«Ź½ÕhĆ÷ŁYĮĻ”£¤Ą¤¤¤æ¤¤Ķ¬¤ø„¹„鄤„É ØC http://www.slideshare.net/mongodb/mongo-db- wiredtigerwebinar?ref=https%3A%2F%2Fwww.mongodb.co m%2Fpresentations%2Fwebinar-a-technical-introduction-to- wiredtiger ØC http://www.slideshare.net/NorbertoLeite/mongodb- wiredtiger-internals ØC https://scs.hosted.panopto.com/Panopto/Pages/Viewer.aspx ?id=9a55027f-2b6c-48f4-86f6-73cc167619d0 ? ŠĀ¤·¤¤¹«Ź½„»„ß„Ź”£WiredTiger¤ĒŹ¹¤Ć¤Ę¤¤¤ė”©¤Ź¹¤·ņ¤ņŌ¼¤Ė ÕhĆ÷¤·¤Ę¤¤¤ė”£ ØC https://www.mongodb.com/presentations/mongodb-europe- 2017-building-wiredtiger ? „Ö„ķ„°”£WiredTiger¤Īstat¤ĪŅ·½¤ä”¢„Ń„Õ„©©`„Ž„󄹄Į„å©`„Ė„ó„° ¤Ė¤Ä¤¤¤Ę½āÕh¤·¤Ę¤¤¤ė ØC http://www.developer.com/db/tips-for-mongodb-wiredtiger- performance-tuning.html 24