ZTG 2013 Agnieszka Ławrynowicz
Download as pptx, pdf0 likes477 views

Prezentacja ze Zjazdu Tw├│rc├│w Gier 2013.





















![Otwarte powi─ģzane dane w ŌĆ×pigu┼éceŌĆØ
ŌĆó Projekt spo┼éeczno┼øciowy ze wsparciem W3C
ŌĆó Publikowanie zbior├│w danych jako otwarte i powi─ģzane ze
sob─ģ dane grafowe (sieci semantyczne)
ŌĆó G┼é├│wna idea: wzi─ģ─ć istniej─ģce (otwarte) zbiory danych i
uczyni─ć je dost─Öpnymi w sieci WWW w formacie RDF (sieci
semantyczne)
ŌĆó Raz opublikowane w RDF, po┼é─ģczy─ć je linkami z innymi
zbiorami danych
ŌĆó Przyk┼éadowy link RDF: http://dbpedia.org/resource/Berlin
[Identyfikator Berlina w DBPedia] owl:sameAs
http://sws.geonames.org/2950159 [Identyfikator Berlina w Geonames].](https://image.slidesharecdn.com/ztg2013lawrynowicz-140527053233-phpapp01/85/ZTG-2013-Agnieszka-Lawrynowicz-26-320.jpg)





ZTG 2013 Agnieszka Ławrynowicz
- 1. Wiedza w grach, gry z celem tworzenia wiedzy dr inż. Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej ZTG 2013
- 2. Kim jestem? ŌĆó Adiunkt w Instytucie Informatyki Politechniki Pozna┼äskiej ŌĆó Zainteresowania: sztuczna inteligencja, g┼é├│wnie reprezentacja i in┼╝ynieria wiedzy (ontologie), odkrywanie wiedzy i technologie semantyczne (Semantic Web) http://www.cs.put.poznan.pl/alawrynowicz/
- 3. LeoLOD ŌĆó LeoLOD - Learning and Evolving Ontologies from Linked Open Data (2013-2015) ŌĆó Projekt realizowany w ramach programu POMOST Fundacji na Rzecz Nauki Polskiej ŌĆó Tworzenie wiedzy: metody automatyczne (uczenie maszynowe) ŌĆó Walidacja wynik├│w: crowd-sourcing (mikro-zadania) ŌĆó Strona projektu: http://www.cs.put.poznan.pl/alawrynowicz/leolod/
- 5. Jeopardy! ŌĆó Jeopardy! to ameryka┼äski quiz show (odpowiednik polskiego Va Banque!) ŌĆó 1964 ŌĆō do dzisiaj ŌĆó format odpowied┼║-i-pytanie ŌĆó Przyk┼éad: ŌĆō Kategoria: Nauka og├│lnie ŌĆō Wskaz├│wka: W zderzeniu z elektronami, fosfor wydziela energi─Ö elektromagnetyczn─ģ w tej formie ŌĆō Odpowied┼║: Czym jest ┼øwiat┼éo? dla ludzi, wyzwaniem jest znajomo┼ø─ć odpowiedzi dla maszyn, wyzwaniem jest zrozumienie pytania
- 6. IBM Watson ŌĆó Watson ŌĆō system komputerowy stworzony przez IBM do odpowiadania na pytania zadawane w j─Özyku naturalnym ŌĆó Watson wyst─ģpi┼é w Jeopardy! w trzydniowej rozgrywce (2011) ŌĆ”
- 7. IBM Watson ŌĆ” ŌĆó przeciwnikami IBM Watsona byli: ŌĆō Brad Rutter ŌĆō do tej pory wygra┼é najwi─Öcej pieni─Ödzy, ŌĆō Ken Jennings ŌĆō by┼é najd┼éu┼╝ej niepokonanym mistrzem ŌĆó IBM Watson zaj─ģ┼é pierwsze miejsce
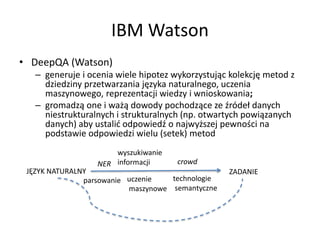
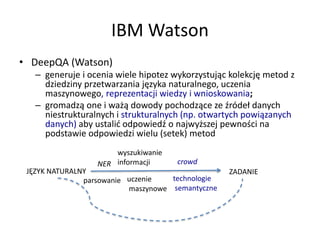
- 8. IBM Watson ŌĆó DeepQA (Watson) ŌĆō generuje i ocenia wiele hipotez wykorzystuj─ģc kolekcj─Ö metod z dziedziny przetwarzania j─Özyka naturalnego, uczenia maszynowego, reprezentacji wiedzy i wnioskowania; ŌĆō gromadz─ģ one i wa┼╝─ģ dowody pochodz─ģce ze ┼║r├│de┼é danych niestrukturalnych i strukturalnych (np. otwartych powi─ģzanych danych) aby ustali─ć odpowied┼║ o najwy┼╝szej pewno┼øci na podstawie odpowiedzi wielu (setek) metod J─śZYK NATURALNY ZADANIE parsowanie NER wyszukiwanie informacji technologie semantyczne uczenie maszynowe crowd
- 9. IBM Watson ŌĆó DeepQA (Watson) ŌĆō generuje i ocenia wiele hipotez wykorzystuj─ģc kolekcj─Ö metod z dziedziny przetwarzania j─Özyka naturalnego, uczenia maszynowego, reprezentacji wiedzy i wnioskowania; ŌĆō gromadz─ģ one i wa┼╝─ģ dowody pochodz─ģce ze ┼║r├│de┼é danych niestrukturalnych i strukturalnych (np. otwartych powi─ģzanych danych) aby ustali─ć odpowied┼║ o najwy┼╝szej pewno┼øci na podstawie odpowiedzi wielu (setek) metod J─śZYK NATURALNY ZADANIE parsowanie NER wyszukiwanie informacji technologie semantyczne uczenie maszynowe crowd
- 10. GRY Z CELEM TWORZENIA WIEDZY
- 11. Tworzenie wiedzy ŌĆó wykwalifikowany zesp├│┼é ludzi ŌĆó metody (p├│┼é)-automatyczne ŌĆó spo┼éeczno┼øciowe (crowd-sourcing)
- 12. Tworzenie wiedzy ŌĆó wykwalifikowany zesp├│┼é ludzi ŌĆó metody (p├│┼é)-automatyczne ŌĆó spo┼éeczno┼øciowe (crowd-sourcing): ŌĆō Gry z celem tworzenia wiedzy
- 13. Motywacje w tworzeniu tre┼øci przez spo┼éeczno┼ø─ć ŌĆó Obop├│lna korzy┼ø─ć (tagowanie) ŌĆó Reputacja, s┼éawa (Wikipedia) ŌĆó Rywalizacja ŌĆó Przystosowanie si─Ö do grupy ŌĆó Altruizm ŌĆó Poczucie w┼éasnej warto┼øci i nauka ŌĆó Zabawa i osobista przyjemno┼ø─ć ŌĆó Domniemana obietnica przysz┼éych nagr├│d ŌĆó Nagrody (Amazon Mechanical Turk)
- 14. Gry z celem ŌĆó Games with a purpose (GWAP): ŌĆó Technika oparta na obliczeniach wykonywanych przez ludzi (human-based computation) ŌĆó Proces obliczeniowy wykonywany jest poprzez zlecanie niekt├│rych czynno┼øci ludziom do wykonania w zabawny, zajmuj─ģcy spos├│b ŌĆó GWAP wykorzystuje r├│┼╝nice w umiej─Ötno┼øciach i kosztach pracy ludzi i metod informatycznych w celu osi─ģgni─Öcia symbiotycznej interakcji cz┼éowiek-komputer
- 15. Gry z celem ŌĆó Luis Von Ahn (2006) ŌĆó G┼é├│wna motywacja: nie le┼╝y w rozwi─ģzaniu instancji problemu obliczeniowego, jest to ludzkie pragnienie zabawy ŌĆó W GWAP ludzie wykonuj─ģ po┼╝yteczne obliczenia jako efekt uboczny przyjemnej rozrywki ŌĆó Miar─ģ u┼╝yteczno┼øci GWAP jest kombinacja wygenerowanych wynik├│w i przyjemno┼øci rozgrywki
- 17. Gry z celem tworzenia tre┼øci, wiedzy ŌĆó Adnotacja tekstu/audio/obraz├│w/video ŌĆó Konstrukcja ontologii ŌĆó Mapowanie ontologii ŌĆó Tworzenie link├│w mi─Ödzy zasobami ŌĆó ŌĆ×Wy┼øcigi WikiŌĆØ
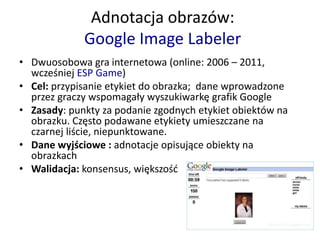
- 18. Adnotacja obraz├│w: Google Image Labeler ŌĆó Dwuosobowa gra internetowa (online: 2006 ŌĆō 2011, wcze┼øniej ESP Game) ŌĆó Cel: przypisanie etykiet do obrazka; dane wprowadzone przez graczy wspomaga┼éy wyszukiwark─Ö grafik Google ŌĆó Zasady: punkty za podanie zgodnych etykiet obiekt├│w na obrazku. Cz─Östo podawane etykiety umieszczane na czarnej li┼øcie, niepunktowane. ŌĆó Dane wyj┼øciowe : adnotacje opisuj─ģce obiekty na obrazkach ŌĆó Walidacja: konsensus, wi─Ökszo┼ø─ć
- 20. ŌĆó Wieloosobowa gra ŌĆó Cel: adnotacja audio ŌĆó Zasady: kilka mini-gier dotycz─ģcych cz─Ö┼øci utworu muzycznego; wszyscy gracze s┼éuchaj─ģ tego samego fragmentu audio i odpowiadaj─ģ na pytania. Punkty przyznawane za podobie┼ästwo odpowiedzi do tych udzielonych przez innych graczy. ŌĆó Dane wyj┼øciowe: adnotacja plik├│w audio ŌĆó Walidacja: konsensus, wi─Ökszo┼ø─ć Adnotacja audio: HerdIt
- 21. Ontologia w ŌĆ×pigu┼éceŌĆØ ŌĆó ŌĆ£An ontology is a ŌĆó formal specification ’üØ maszynowa interpretacja ŌĆó of a shared ’üØ grupa os├│b, konsensus ŌĆó conceptualization ’üØ abstrakcyjny model zjawisk, poj─Öcia ŌĆó of a domain of interestŌĆ£ ’üØ wiedza dziedzinowa ŌĆó (Gruber 93) ontologia = formalna specyfikacja poj─Ö─ć z danej dziedziny
- 22. Konstrukcja ontologii: OntoPronto (Ontogame) ŌĆó Dwuosobowa gra quizowa ŌĆó Cel: budowa ontologii dziedzinowej b─Öd─ģcej rozszerzeniem ontologii Proton ŌĆó Zasady: Gracze czytaj─ģ streszczenie losowo wybranego artyku┼éu z Wikipedii i odpowiadaj─ģ na zapytania o relacji tego artyku┼éu w stosunku do ontologii Proton. ŌĆó Dane wyj┼øciowe: Ontologia dziedzinowa ufundowana na ontologii Proton ŌĆó Walidacja: konsensus, wi─Ökszo┼ø─ć
- 24. Mapowanie ontologii: SpotTheLink ŌĆó Dwuosobowa gra quizowa ŌĆó Cel: uzgadnianie ontologii, np. Dbpedia i Proton ŌĆó Zasady: Graczom prezentowane jest poj─Öcie z jednej ontologii. Pierwszy krok: zgadzaj─ģ si─Ö co do odpowiadaj─ģcego mu poj─Öcia w drugiej ontologii. Krok drugi: zgadzaj─ģ si─Ö co do relacji wi─ģ┼╝─ģcej te dwa poj─Öcia. ŌĆó Dane wyj┼øciowe: Odwzorowanie (w j─Özyku SKOS)pomi─Ödzy poj─Öciami w ontologiach ŌĆó Walidacja: konsensus, wi─Ökszo┼ø─ć
- 25. SpotTheLink
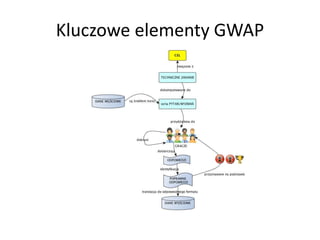
- 26. Otwarte powi─ģzane dane w ŌĆ×pigu┼éceŌĆØ ŌĆó Projekt spo┼éeczno┼øciowy ze wsparciem W3C ŌĆó Publikowanie zbior├│w danych jako otwarte i powi─ģzane ze sob─ģ dane grafowe (sieci semantyczne) ŌĆó G┼é├│wna idea: wzi─ģ─ć istniej─ģce (otwarte) zbiory danych i uczyni─ć je dost─Öpnymi w sieci WWW w formacie RDF (sieci semantyczne) ŌĆó Raz opublikowane w RDF, po┼é─ģczy─ć je linkami z innymi zbiorami danych ŌĆó Przyk┼éadowy link RDF: http://dbpedia.org/resource/Berlin [Identyfikator Berlina w DBPedia] owl:sameAs http://sws.geonames.org/2950159 [Identyfikator Berlina w Geonames].
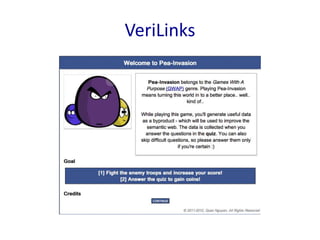
- 27. Tworzenie link├│w mi─Ödzy zasobami: VeriLinks ŌĆó Cel: walidacja link├│w w arbitralnym zbiorze danych ŌĆó Zasady: Zgoda graczy co do poprawno┼øci linku jest nagradzana monetami, kt├│re s─ģ nast─Öpnie wykorzystywane do zwalczania naje┼║d┼║c├│w w grze polegaj─ģcej na obronie wie┼╝y. ŌĆó Dane wyj┼øciowe: zwalidowane linki
- 28. VeriLinks
- 29. ŌĆ×Wy┼øcigi WikiŌĆØ: Wikispeedia ŌĆó Pod─ģ┼╝anie za linkami w Wikipedii ŌĆó Cel: obliczanie semantycznej odleg┼éo┼øci pomi─Ödzy dwoma artyku┼éami Wikipedii. ŌĆó Zasady: Gracze musz─ģ znale┼║─ć jak najkr├│tsz─ģ ┼øcie┼╝k─Ö mi─Ödzy dwoma has┼éami. ŌĆó Dane wyj┼øciowe: semantyczna odleg┼éo┼ø─ć pomi─Ödzy dwoma artyku┼éami Walidacja: Wi─Ökszo┼ø─ć
- 30. Wikispeedia Spr├│buj: Game -> Astronomy, Game->Potato
- 31. Dalsze uwagi ŌĆó Nie ka┼╝de zadanie da si─Ö ┼éatwo przerobi─ć na GWAP (wym├│g dekompozycji na mikro- zadania) ŌĆó Tworzenie niekt├│rych ontologii wymaga bardzo specjalistycznej wiedzy ŌĆó To co powstaje w wyniku GWAP jest raczej ŌĆ×p┼éytkimŌĆØ modelem ŌĆó GWAP wymaga strategii zapobiegania oszustwom
- 32. Wi─Öcej informacji ŌĆó LeoLOD: http://www.cs.put.poznan.pl/alawrynowicz/leolod ŌĆó IBM Watson (The DeepQA Project): http://researcher.ibm.com/researcher/view_project.php?id=2099 ŌĆó GWAP: 1. Luis von Ahn (2006). "Games With A Purpose" (PDF). IEEE Computer Magazine: 96ŌĆō98. 2. Luis von Ahn, Laura Dabbish (2008). "Designing Games With A Purpose" (PDF). Communications of the ACM 51 (08/08). ŌĆó Semantic Games: 1. Elena Simperl, Roberta Cuel, Martin Stein, Incentive-Centric Semantic Web Application Engineering, Morgan & Claypool Publishers (2013) 2. http://semanticgames.org/
Editor's Notes
- #3: Mo┼╝e mo┼╝na od razu cos powiedziec o moim projekcie i ze tworzenie wiedzy jest jego tematem? Mo┼╝e mo┼╝na po prostu zrobic slajd z tego kim jestem i czym si─Ö zajmuje i drugi o kontekscie projektu i dlaczego mnie ten wlasnie temat/te tematy interesuje/interesuja?
- #7: Mo┼╝na usunac np. ostatnia informacje i po tym puscic film z tego jak to bylo
- #9: Tutaj mo┼╝e przed tym film a ten slajd jako podsumowanie
- #10: Tutaj mo┼╝e przed tym film a ten slajd jako podsumowanie
- #12: Tutaj mo┼╝e by─ć krotka reklama, np., w pierwszym przypadku np., za pomoca narzedzia protege, w drugim chcemy napisac wtyczke do tego narzedzia i zrobic to pol-automatycznie, a dzisiaj chce mowic o trzecim temacie
- #14: In the last few years researchers from different scientific disciplines investigated the grounds of the success of community-driven content creation. Although these studies reveal that the inner motivations that drive people to participate are heterogeneous and strongly context-specific, several main categories can be identified: Reciprocity and expectancy Reciprocity means that contributors receive an immediate or long- term benefit in return for spending their time and resources on performing a certain task. An example of this is tagging, where the user organizes her knowledge assets, such as bookmarks or pictures, and while doing so, reuses tag classifications of other users. Reputation Reputation is an important factor within (virtual) communities: it can drive users to invest time and effort to improve the opinion of their peers about them. It has shown that this is an important motivation for, for instance, Wikipedia users [75]. Competition Competition is a relevant incentive in the context of games (rankings), but it can also be a strong driver in community portals where the user with the, for example, most contributions, or highest status is awarded. Conformitytoagroup Throughimitationandempathypeopletendtoconformtothesocialgroup they belong to, therefore making available information about members behaviors is a way to spur people to act according to this information. Staying with the example of Wikipedia as a strong community, studies have shown that the feeling of belonging to a group makes users be more active and supportive. They feel needed and thus obliged to contribute to the joint goals of their community [75]. Altruism People contribute to a joint endeavor because they believe it is for a good cause, without expecting anything in return. Self-esteem and learning People contribute to a certain endeavor in order for them to grow as individuals, either in terms of their own self-perception or to increase their knowledge and skills. Fun and personal enjoyment People get engaged in entertaining activities. The most popular ap- proach in this context hides a complex task behind casual games [114, 132]. Implicit promise of future monetary rewards People typically act in order to increase their own human capital and to position themselves to gain future rewards (money or better roles). Rewards Peoplereceiveadirectcompensationwhichcanobviouslyplayalargeroleinexplainingthe rationale for contributing effort toward a goal. Examples of this are crowdsourcing platforms, such as AmazonŌĆÖs Mechanical Turk2 or InnoCentive.3
- #15: I tutaj o tym, ze wg tego pana najwazniejsza motywacja jest nie altruism i pieniadze ale wlasnie to radosc z grania
- #17: described as a series of interconnected questions (or challenges), which the players will need to answer during the game. The questions depend on the input, which is taken from the knowledge corpus the game processes and may be closed or open scale. The problem solved through the game needs to be highly decomposable into tasks which can be approached in a decentralized fashion by answering different questions. The questions themselves can have a varying level of difficulty, but in general it is assumed that an average player will be able to answer them in a matter of a couple of minutes. The input used to generate the questions needs to be verbalized and translated into simple, unambiguous questions. When the input is generated automatically, for instance because it contains results computed by algorithms that need to be validated by the players, it is essential that the quality of these results is not too lowŌĆöotherwise the game experience will be less entertaining, as many of the questions will probably not make any sense at all. One important aspect to be considered is how to assign questions to players. The basic approach is to do this randomly, though optimizations are possible when information about the performance of players in previous game rounds is available In addition, in a multi-player game, the game developer might want to customize the ways players are matched to play against each other. The output of a game with a purpose is an aggregated, manually cleansed form of the playersŌĆÖ answers. In a first step, the game developer needs to be able to match the contributions of the players; this is a not an issue for those challenges in which the set of allowed solutions are known, but it is less trivial in open-scale questions, where one has to deal not only with different spelling and spelling errors, but also synonyms and the like. As a second step, the game developer needs ways to be able to identify correct answers with as little effort as possible, ideally automatically. Once accurate answers are identified, the game developer needs to translate them into a semantic format, using existing ontologies and Semantic Web representation languages. The most basic game elements are points and leader boards.
- #18: Tutaj wymienione te kategorie od eleny lub z insemtives itp..