
















![ä·Ö„Ł„¤„ŗ·Ø¤Č„Ƅ鄹·Öī
?? ä·Ö„Ł„¤„ŗ·Ø¤Ī½M¤ß
?
ØC? x¤Ė¤Ä¤¤¤Ę¤ĪÖÜŽxÓȶȤ¬
?
XZ P (x, , ?)
log P (x) = d?q( , ?) log + KL(q||P ( , ?|x))
q( , ?)
XZ P (x, , ?)
d?q( , ?) log ? F [q]
q( , ?)
?
?
?
?¤Čų¤±”¢µČŗŤ¬ q( , ?) = P ( , ?|x) ¤Ī¤Č¤¤Ė³É¤źĮ¢¤Ä
?
?
?
?
?¤³¤Č¤ņĄūÓƤ¹¤ė
?
?
ØC?
?F
?[q]
?¤ņ×ī“ó»Æ¤¹¤ėq¤ņä·ÖµÄ¤ĖĒó¤į”¢¤½¤ģ¤ņŹĀįį·Ö²¼¤Č
?
?
?
?
?
?
Ņ¤Ź¤¹¤³¤Č¤¬¤Ē¤¤ė£ØF[q]¤ņä·Ö×ŌÓÉ„Ø„Ķ„ė„®©`¤Čŗō¤Ö£©
?
?? ¤½¤Ī¤Ž¤Ž¤Ē¤Ļq¤ņĒó¤į¤ė¤³¤Č¤¬¤Ē¤¤Ź¤¤](https://image.slidesharecdn.com/quantumannealing-121022082430-phpapp02/85/1-18-320.jpg)


































More Related Content
What's hot (20)
Viewers also liked (8)






Similar to Įæ×Ó„¢„Ė©`„ź„ó„°½āÕh 1 (20)




















More from Kohta Ishikawa (11)
![[Paper reading] Hamiltonian Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/hamiltoniannn-200131102421-thumbnail.jpg?width=560&fit=bounds)










Įæ×Ó„¢„Ė©`„ź„ó„°½āÕh 1
- 1. Įæ×Ó„¢„Ė©`„ź„ó„°½āÕh ?1 2012/10 ? @_kohta ?
- 2. „¢„¦„Ȅ鄤„ó ?? Įæ×ÓĮ¦Ń§ČėéT ? ØC? דB”¢¼»×“B”¢»ģŗĻדB ? ?? ¹ÅµäĮ¦Ń§¤ĪŹĄ½ē¤ČĮæ×ÓĮ¦Ń§¤ĪŹĄ½ē ? ?? Įæ×ÓĮ¦Ń§¤ĪŹĄ½ē ? ØC? ¼»×“B¤Č»ģŗĻדB ? ?? »śŠµŃ§Ļ°¤Ų¤ĪźÓĆ ? ØC? „Ƅ鄹·Öīī} ? ?? Įæ×Ó„¢„Ė©`„ź„ó„°¤Ė¤č¤ė×īßm»Æ ? ?? to ?be ?con1nued ?
- 3. Įæ×ÓĮ¦Ń§ČėéT background ?image ?: ?h9p://personal.ashland.edu/rmichael/courses/phys403/phys403.html
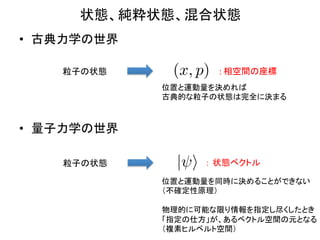
- 4. דB”¢¼»×“B”¢»ģŗĻדB ?? ¹ÅµäĮ¦Ń§¤ĪŹĄ½ē ? Į£×Ó¤ĪדB (x, p) : ?ĻąæÕég¤Ī׳Ė ? Ī»ÖƤČß\ÓĮæ¤ņQ¤į¤ģ¤Š ? ¹ÅµäµÄ¤ŹĮ£×Ó¤ĪדB¤ĻĶźČ«¤ĖQ¤Ž¤ė ?? Įæ×ÓĮ¦Ń§¤ĪŹĄ½ē Į£×Ó¤ĪדB | i £ŗ דB„Ł„Æ„Č„ė ? Ī»ÖƤČß\ÓĮæ¤ņĶ¬r¤ĖQ¤į¤ė¤³¤Č¤¬¤Ē¤¤Ź¤¤ ? £Ø²»“_¶ØŠŌŌĄķ£© ? ? ĪļĄķµÄ¤ĖæÉÄܤŹĻŽ¤źĒéó¤ņÖø¶Ø¤·¾”¤Æ¤·¤æ¤Č¤ ? ”øÖø¶Ø¤ĪŹĖ·½”¹¤¬”¢¤¢¤ė„Ł„Æ„Č„ėæÕég¤ĪŌŖ¤Č¤Ź¤ė ? £ØŃ}ĖŲ„Ņ„ė„Ł„ė„ČæÕég£© ?
- 5. דB”¢¼»×“B”¢»ģŗĻדB ?? ¼»×“B ? ØC? Ē°Źö¤Ī”øĪļĄķµÄ¤ĖæÉÄܤŹĻŽ¤źĒéó¤ņÖø¶Ø¤·¾”¤Æ¤·¤æדB”¹ ¤ņ¼»×“B¤Čŗō¤Ö ? ØC? ĘÕĶؤĪĮæ×ÓĮ¦Ń§¤ĒQ¤¦Ļó¤Ē”¢„·„å„ģ„Ē„£„󄬩`·½³ĢŹ½ ? H| i = E| i ”” ¤Ė¾¤¦ ? ? Ļµ¤ĪHamiltonian „Ø„Ķ„ė„®©`¹ĢÓŠ ØC? Hamiltonian¤ĻדB„Ł„Æ„Č„ė¤Ė¤¹¤ė£Ø„Ø„ė„ß©`„Č£©ŃŻĖć×Ó ¤Ē”¢£ØÓŠĻŽ“ĪŌŖ¤ĪöŗĻ£©ŠŠĮŠ¤Ēų¤Æ¤³¤Č¤ā¤Ē¤¤ė ? ?? ŅŖ¤¹¤ė¤ĖŠŠĮŠH¤Ī¹ĢÓŠī} ?
- 6. דB”¢¼»×“B”¢»ģŗĻדB ?? ¼»×“B ? ØC? ¾ßĢåµÄ¤ĖÓĖć¤¹¤ė¤Č¤¤Ļ”¢ŗĪ¤é¤«¤Ī»łµ×¤Ē”ø±ķŹ¾”¹¤¹¤ė±Ų ŅŖ¤¬¤¢¤ė ? ?? „Ł„Æ„Č„ė¤Ī³É·Ö¤ņÓĖć¤¹¤ė¤³¤Č¤Ėź¤¹¤ė ? h | : ?„Ö„é?„Ł„Æ„Č„ė””£Ø„±„ƄȤĖ×÷ÓƤ·¤Ę„¹„«„é©`Ń}ĖŲŹż¤ņ·µ¤¹£© | i : ?„±„Ć„Č?„Ł„Æ„Č„ė h | i : ?2¤Ä¤Ī„±„Ć„Č | i ¤Č””””””””¤ĪÄŚ·e | i ?? £ØĄż¤Ø¤Š£©”ø׳Ė”¹±ķŹ¾”””ś ? ?„·„å„ģ„Ē„£„󄬩`·½³ĢŹ½¤Ī×󤫤é hx| ¤ņ ×÷ÓĆ ? hx|H| i = Hx hx| i = Ehx| i ׳Ė±ķŹ¾¤ĪHamiltonian ? ׳Ė±ķŹ¾¤ĪדB„Ł„Æ„Č„ė ? (Ī¢·ÖŃŻĖć×Ó) (²ØÓévŹż)
- 7. דB”¢¼»×“B”¢»ģŗĻדB ?? ¼»×“B¤Č“_ĀŹ ? ØC? £ØĄż¤Ø¤Š£©×łĖ±ķŹ¾¤Ī²ØÓévŹż hx| i ? (x) ¤¬ ? ”” ¤ļ¤«¤ė¤Č”¢ ”øĮ£×Ó¤¬Ī»ÖĆx~x+dx¤Ė¤¢¤ė“_ĀŹ”¹¤Ļ ? ? P (x) = | (x)|2 dx ? ? ? ? ? ?¤Č¤Ź¤ė£Ø„Ü„ė„ót£ÆĮæ×ÓĮ¦Ń§¤Ī“_ĀŹ½āį£© ? ? ØC? דB¤¬”øĪ»ÖĆŃŻĖć×Ó”¹¤Ī¹ĢӊדB¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤Č¤¤Ļ”¢“_ ĀŹĆܶȤĻ¦ÄévŹż¤Č¤Ź¤ė ? ?? æÉQ¤ŹŃŻĖć×Ó¤Ī½M¤ĻĶ¬r½Ē»ÆæÉÄܤĒ”¢¤½¤ģ¤é¤Ī¤ņĶ¬r¤ĖÕż “_¤ĖQ¶Ø¤¹¤ė¤³¤Č¤¬¤Ē¤¤ė ? ?? x¤Čp¤Ļ·ĒæÉQ¤Ź¤Ī¤ĒĶ¬r¤ĖQ¶Ø¤Ē¤¤Ź¤¤ ? ØC? ”ø·ĒæÉQ¤Ī¶ČŗĻ¤¤”¹¤¬²»“_¶ØŠŌ¤Ī“󤤵¤ņQ¤į¤ė
- 8. דB”¢¼»×“B”¢»ģŗĻדB ?? »ģŗĻדB ? ØC? ¼»×“B¤Ļ”¢¾ßĢåµÄ¤Ź±ķŹ¾¤ĒŅ¤ė¤Č ? X X | i= |xihx| i = (x)|xi x x ? ? ? ? ?¤Ź¤É¤Č¤Ź¤ź”¢¹ĢӊדB¤ĪÖŲ¤ĶŗĻ¤ļ¤»£Ø”©¤ŹĪ»ÖƤĖ¤¤¤ė ? ? ? ? ? ?דB¤¬Ķ¬r¤Ė»ģŌŚ¤·¤Ę¤¤¤ė£©¤Č¤Ź¤Ć¤Ę¤¤¤ė”£ ? ? ØC? Ņ»·½”¢Ń}Źż¤Ī¼»×“B¤Ī”ø¹ÅµäµÄ¤ŹÖŲ¤ĶŗĻ¤ļ¤»”¹¤ņæ¼¤Ø ¤æ¤¤öŗĻ¤ā¤¢¤ė ? ?? ½yÓĮ¦Ń§¤Ē¤Ļ”¢¶ąŹż¤ĪĮ£×Ó¤Ī¤¢¤źµĆ¤ėÅäĪ»¤Ė¤Ä¤¤¤Ę¤Ī“_ĀŹµÄ¤Ź Ę½¾ł¤ņ漤ؤė ? ?? ¤½¤ģ¤¾¤ģ¤ĪÅäĪ»¤ĻĪļĄķµÄ¤ĖøÉh¤¹¤ėŌU¤Ē¤Ļ¤Ź¤¤¤Ī¤Ē”¢¹ÅµäµÄ¤Ź ÖŲ¤ĶŗĻ¤ļ¤»¤Č¤Ź¤ė ? ?? ¤½¤Ī¤č¤¦¤Ź×“B¤ņ»ģŗĻדB¤Čŗō¤Ö
- 9. דB”¢¼»×“B”¢»ģŗĻדB ?? »ģŗĻדB ? ØC? ¶ØĮx¤«¤é”¢¼»×“B | 1 i, ”¤ ”¤ ”¤ , | k i ¤ņ“_ĀŹµÄÖŲ¤ß ? p1 , ”¤ ”¤ ”¤ , pk ? ? ? ?””””””””””””””””””¤Ē»ģŗĻ¤·¤æ»ģŗĻדB¤Ė¤·¤Ę”¢ĪļĄķĮæA¤Ī ? ? ? ? ?“_ĀŹ·Ö²¼¤Ļ ? X ? P (a) = pi |ha| i i|2 ? i ”” ¤Č¤Ź¤ė”£ ? ĪļĄķĮæA¤¬¹ĢÓŠa¤ņ¤Č¤ėדB¤Ī„Ö„é„Ł„Æ„Č„ė
- 10. דB”¢¼»×“B”¢»ģŗĻדB ?? »ģŗĻדB ? ØC? ¤½¤Ī¤č¤¦¤Ź»ģŗĻדB¤ņ±ķ¤¹¤æ¤į¤Ė”¢ŅŌĻĀ¤ĪĆܶČŃŻĖć×Ó¤ņ 漤ؤė¤Č±ćĄū ? X X ?= ? pi | i ih i | ?= ? |xihx|?|x0 ihx0 | ? i x,x0 ĆܶČŃŻĖć×Ó¤ĪŠŠĮŠ±ķŹ¾£ØĆܶȊŠĮŠ£© ØC? ĆܶČŃŻĖć×Ó¤¬Óė¤Ø¤é¤ģ¤ė¤Č”¢ĪļĄķĮæA¤Ī“_ĀŹ·Ö²¼¤Ļ ? P (a) = ha|?|ai ? ? ? ? ?¤Čų¤±”¢ĘŚ“ż¤Ļ ? X X X ? aP (a) = aha|?|ai = ? ha|?A|ai ? Tr(?A) ? ? ? a a a ? ? ? ?¤Čų¤±¤ė ?
- 11. »śŠµŃ§Ļ°¤Ų¤ĪźÓĆ
- 12. Įæ×Ó„¢„Ė©`„ź„ó„° ?? »ģŗĻדB¤ĪĮæ×ÓĮ¦Ń§¤Ī“_ĀŹÕµÄ¤Ź½M¤ß¤ņźÓĆ ? ØC? £Ø¼»×“B¤ĪĄķÕ¤Ē¶ØŹ½»Æ¤¹¤ėĮ÷x¤ā¤¢¤ė¤é¤·¤¤£© ? ?? „Ƅ鄹·Öīī} ? ØC? N¤Ī„Ē©`„æ¤ņK¤Ī„Ƅ鄹¤Ė·Öī¤¹¤ė ? ?? kNN·Ø¤ņŹ¼¤į¤Č¤·¤ĘÉ«”©¤ä¤ź·½¤¬¤¢¤ė ? ØC? ä·Ö„Ł„¤„ŗ¤Ė¤č¤ė·½·Ø¤ĖĮæ×Óæ¹ū¤ņ§Čė¤¹¤ė ? ?? Issei ?Sato, ?et ?al. ?”°Quantum ?Annealing ?for ?Varia1onal ?Bayes ? Inference”± ? ? ØC? „Ƅ鄹„æ„ź„ó„° ? ?? Kenichi ?Kurihara, ?et ?al. ?”°Quantum ?Annealing ?for ?Clustering”± ?
- 13. „Ƅ鄹·Öīī}¤ČĆܶȊŠĮŠ ?? „Ƅ鄹·Öīī} ? ØC? „Ē©`„æ x = x1 , ”¤ ”¤ ”¤ , xN ¤ņK¤Ī„Ƅ鄹¤Ė·Öī¤¹¤ė ī} ? ?? gŅ»„Ē©`„æ xk ¤Ī„Ƅ鄹øī¤źµ±¤Ę¤ņŅŌĻĀ¤Ī¤č¤¦¤Ėų¤Æ ? ?k = (0, ”¤ ”¤ ”¤ , 0, 1, 0, ”¤ ”¤ ”¤ , 0)T K“ĪŌŖ 0 1 ?? N¤Ī„Ē©`„æČ«¤Ę¤Ė¤¹¤ė¤¢¤ėøī¤źµ±¤Ę¤Ļ ? a11 B ”¤”¤”¤ a1l B B . .. . C A?B =@ .. . . A . N = ?k=1 ?k ak1 B ”¤”¤”¤ akl B „Æ„ķ„Ķ„Ć„«©`·e ? ? ? ?¤Č¤Ź¤ė”£ ? T T ØC? K=N=2¤Ī¤Č¤”¢ ?1 = (1, 0) ?2 = (0, 1) ¤Ź¤é ? ?1 ? ?2 = (0, 1, 0, 0)T
- 14. „Ƅ鄹·Öīī}¤ČĆܶȊŠĮŠ ?? Ąż¤Ø¤ŠK=N=2¤ĪöŗĻ ? ØC? 4Ķؤź¤ĪדB¤ņ¤Č¤ė“_ĀŹ¤¬ p1 , p2 , p3 , p4 ¤Ī¤Č¤”¢“Ī¤Ī ¤č¤¦¤ŹĆܶȊŠĮŠ¤ņ漤ؤė ? X diag(p1 , p2 , p3 , p4 ) = pi (i) (i)T i (i) 2 {(1, 0, 0, 0)T , (0, 1, 0, 0)T , (0, 0, 1, 0)T , (0, 0, 0, 1)T } ØC? Įæ×ÓĮ¦Ń§¤Č¤Ī„¢„Ź„ķ„ø©`¤ņ漤ؤė¤Č ? (i) דB„Ł„Æ„Č„ė£Ø„±„Ć„Č£©£ŗ Hamiltonian£ŗ diag( log p1 , ”¤ ”¤ ”¤ , log p4 )
- 15. „Ƅ鄹·Öī¤ĪĮæ×ÓĮ¦Ń§µÄ¶ØŹ½»Æ ?? ŅŌĻĀ¤Ī¤č¤¦¤ŹHamiltonian¤ņ漤ؤė ? (1) (N K ) Hc = diag( log p(x, ), ”¤ ”¤ ”¤ , log p(x, )) Hc log p(x) = log Tr{e } ØC? Hamiltonian¤ĖĮæ×Óæ¹ū¤ņČė¤ģ¤ė ? N X Hq = xi , ? i 1 EK ? j=1 x ? ?N l=i+1 EK i=1 įį¤Īāľ-?©\Tro9erÕ¹é_¤Ē ? x = (EK 1K ) ¤¦¤Ž¤ÆÓĖć¤Ē¤¤ėŠĪ¤Ė¤Ź¤ė H = Hc + Hq „¤„į©`„ø 0 (1) 1 log p(x, ) 0 B log p(x, (2) ) 0 C H=B @ (3) C A 0 log p(x, ) (4) 0 log p(x, )
- 16. ĆܶȊŠĮŠ¤Č¹ÅµäµÄ“_ĀŹ ?? Hamiltonian¤¬½Ē¤Ź¤é”¢ī}¤Ļ£ØĶس£¤Ī£©¹ÅµäµÄ¤Ź“_ĀŹ „ā„Ē„ė¤ČĶźČ«¤ĖŅ»ÖĀ¤¹¤ė ? ØC? ĆܶȊŠĮŠ¤ņÓƤ¤¤ė¤³¤Č¤Ē”¢Hamiltonian¤Ī·Ē½Ēķ¤ĖĮæ×ÓÕµÄ æ¹ū¤ņČė¤ģ¤ė¤³¤Č¤¬¤Ē¤¤ė¤č¤¦¤Ė¤Ź¤ė ? ØC? Įæ×Ó„¢„Ė©`„ź„ó„°¤Ē¤Ļ”¢·Ē½Ēķ¤ņŹ¹¤Ć¤Ę¾ÖĖł×īßm½ā¤«¤éi ¤±³ö¤¹¤³¤Č¤ņ漤ؤė ? ?? Ņ»°ćµÄ¤ŹI·½¹{ ? ØC? „Ē©`„æ¤ČדB¤Ė¤Ä¤¤¤Ę”¢½ĒŅŖĖŲ¤¬¹ÅµäµÄ“_ĀŹ¤Č¤Ź¤ė Hamiltonian¤ņŌOÓ¤¹¤ė ? ØC? ßmµ±¤ŹĮæ×Óæ¹ū¤ņČė¤ģ¤æĻą»„×÷ÓĆHamiltonian¤ņ×·¼Ó¤·”¢ā ľ-?©\Tro9erÕ¹é_¤ņÓƤ¤¤Ę½Ē¤Ź£Ø„µ„ó„ׄź„ó„°æÉÄܤŹ£©“_ĀŹ„ā„Ē „ė¤Ī·e¤Č¤·¤Ę½üĖʤ¹¤ė ? ØC? Įæ×Óæ¹ū¤ņŠģ”©¤ĖČõ¤į¤ė„¢„Ė©`„ź„ó„°¤ņŠŠ¤¤¤Ź¤¬¤é„µ„ó„ׄź„ó „°¤·”¢×īßm½ā¤ņĒó¤į¤ė ?
- 17. ä·Ö„Ł„¤„ŗ·Ø¤Č„Ƅ鄹·Öī ?? ä·Ö„Ł„¤„ŗ·Ø¤Ī½M¤ß ? ØC? ėL¤ģ䏿¦Ņ”¢„Ń„é„į©`„æ¦Č¤¬¤¢¤ėÓQy䏿x¤Ī“_ĀŹ·Ö²¼ ? ? P (x, , ?) ? ØC? ÓQyx¤Ė¤¹¤ė¦Ņ¤ĪŹĀįį·Ö²¼ ? P ( , ?|x) ? ? ? ? ? ? ? ? ?¤ņĒó¤į¤æ¤¤¤¬”¢ ĆܤĖÓĖć¤¹¤ė¤Ī¤Ļėy¤·¤¤ ? ? ?? „Ƅ鄹·Öīī} ? ØC? ÓQy䏿x£Ø„Ē©`„棩¤Č”¢ėL¤ģ䏿¦Ņ£Ø„Ē©`„æ¤Ī„Ƅ鄹·Öī£© ¤Ė¤·¤Ę”¢„Ē©`„æx¤Ė¤¹¤ė¦Ņ¤ĪŹĀįį·Ö²¼¤ņĒó¤į¤ėī}
- 18. ä·Ö„Ł„¤„ŗ·Ø¤Č„Ƅ鄹·Öī ?? ä·Ö„Ł„¤„ŗ·Ø¤Ī½M¤ß ? ØC? x¤Ė¤Ä¤¤¤Ę¤ĪÖÜŽxÓȶȤ¬ ? XZ P (x, , ?) log P (x) = d?q( , ?) log + KL(q||P ( , ?|x)) q( , ?) XZ P (x, , ?) d?q( , ?) log ? F [q] q( , ?) ? ? ? ?¤Čų¤±”¢µČŗŤ¬ q( , ?) = P ( , ?|x) ¤Ī¤Č¤¤Ė³É¤źĮ¢¤Ä ? ? ? ? ?¤³¤Č¤ņĄūÓƤ¹¤ė ? ? ØC? ?F ?[q] ?¤ņ×ī“ó»Æ¤¹¤ėq¤ņä·ÖµÄ¤ĖĒó¤į”¢¤½¤ģ¤ņŹĀįį·Ö²¼¤Č ? ? ? ? ? ? Ņ¤Ź¤¹¤³¤Č¤¬¤Ē¤¤ė£ØF[q]¤ņä·Ö×ŌÓÉ„Ø„Ķ„ė„®©`¤Čŗō¤Ö£© ? ?? ¤½¤Ī¤Ž¤Ž¤Ē¤Ļq¤ņĒó¤į¤ė¤³¤Č¤¬¤Ē¤¤Ź¤¤
- 19. ä·Ö„Ł„¤„ŗŅŌĶā¤Ī·½·Ø ?? MCMC¤Ź¤É¤ņÓƤ¤¤Ę”¢¤Ź¤ó¤Č¤«””””””””””””””¤«¤é„µ„ó P ( , ?|x) „ׄź„ó„°¤¹¤ė·½·Ø¤ā¤¢¤ė ? ØC? „Ƅ鄹„é„Ł„ėæÕégČ«Ģ夫¤éŅ»¶Č¤Ė„µ„ó„ׄź„ó„°¤¹¤ė¤Ī¤Ļ ėy¤·¤¤ ? ØC? 1䏿¤ņ²Š¤·¤ĘĖū¤ņ¹Ģ¶Ø¤·¤Ę„µ„ó„ׄź„ó„°¤¹¤ėß^³Ģ¤ņĄR¤ź ·µ¤¹”¢„®„Ö„¹„µ„ó„ׄé©`¤Ī·½·Ø¤ņŹ¹¤Ø¤ėŠĪ¤Ė¤·¤æ¤¤
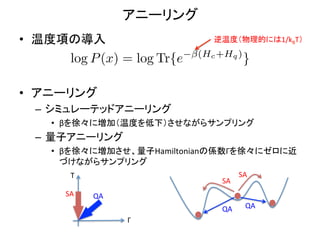
- 20. Įæ×ÓµÄHamiltonian¤ĪČ”¤źQ¤¤ ?? Įæ×Óæ¹ū¤ņČė¤ģ¤æHamiltonian¤Ļ¤Ž¤Č¤ā¤ĖÓĖć¤¹¤ė ¤³¤Č¤¬¤Ē¤¤Ź¤¤ ? (Hc +Hq ) log P (x) = log Tr{e } ØC? ·Ē½Ē¤ŹŠŠĮŠ¤Īexp?? ? ?? āľ-?©\Tro9erÕ¹é_ ? ! ? ”ō! m ? ”ō X Y Al 1 exp Al = exp +O m m l l ?? Hamiltonian¤Ī·Ē½Ē²æ·Ö¤ņÓĖćæÉÄܤŹŠĪ¤Ė½üĖʤ·”¢MCMC„µ„ó „ׄź„ó„°¤Ź¤É¤ņŠŠ¤¦ ? ?? m¤¬Ņ»¤Ä¤Ī¶ĄĮ¢¤Ź½ĒHamiltonian¤Ėź¤¹¤ėŠĪ¤Č¤Ź¤ź”¢g×°µÄ ¤Ė¤Ļm¤Ī„·„ß„å„ģ©`„Ę„Ć„É„¢„Ė©`„ź„ó„°¤ņ×ߤ餻¤ė¤³¤Č¤Ė¤Ź¤ė ?
- 21. „¢„Ė©`„ź„ó„° ?? ĪĀ¶Čķ¤Ī§Čė ? ÄęĪĀ¶Č£ØĪļĄķµÄ¤Ė¤Ļ1/kBT£© ? (Hc +Hq ) log P (x) = log Tr{e } ?? „¢„Ė©`„ź„ó„° ? ØC? „·„ß„å„ģ©`„Ę„Ć„É„¢„Ė©`„ź„ó„° ? ?? ¦Ā¤ņŠģ”©¤Ė¼Ó£ØĪĀ¶Č¤ņµĶĻĀ£©¤µ¤»¤Ź¤¬¤é„µ„ó„ׄź„ó„° ? ØC? Įæ×Ó„¢„Ė©`„ź„ó„° ? ?? ¦Ā¤ņŠģ”©¤Ė¼Ó¤µ¤»”¢Įæ×ÓHamiltonian¤ĪSŹż¦£¤ņŠģ”©¤Ė„¼„ķ¤Ė½ü ¤Å¤±¤Ź¤¬¤é„µ„ó„ׄź„ó„° T SA SA SA QA QA QA ¦£
- 22. gņY½Y¹ū£ØĪÄĻפ褟£© ?? ä·Ö„Ł„¤„ŗ¤Ī·½·Ø ? ØC? ŹżÓȶȤĒŅ¤Ę”¢SA¤Ė±Č¤Ł·ÖīŠŌÄܤ¬10%³Ģ¶ČøÄÉʤ· ¤æ¤é¤·¤¤ ? ØC? SA¤Ė±Č¤Ł”¢¾ÖĖł½ā¤Ėź¤ź¤Ė¤Æ¤Æ¤Ź¤ėŠŌŁ|¤¬¤¢¤ė¤é¤·¤¤