






















![48
ź▐źļź┴GPUč¦┴Ģż╬źčźšź®®`ź▐ź¾ź╣
NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7 8
Speed-upto1GPU
Number of GPUs
AlexNet VGG-D ResNet
[Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12
0
0.5
1
1.5
2
2.5
1 2 4 8
Relativetimeto1GPU
Number of GPUs
Time per one batch (VGG-D)
Update
Allreduce
Backward
Forward
DGX-1Ī»s NVLink is not well utilized.
ChainerĪ»s all-reduce implementation
is na?ve Ī░gather and broadcatĪ▒.](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-43-320.jpg)
![49
ź▐źļź┴GPUč¦┴Ģż╬źčźšź®®`ź▐ź¾ź╣(NCCL╩╣ė├ż╩żĘ) )
NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch
0
2
4
6
8
0 2 4 6 8
Number of GPUs
Scalability
ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers)
0
2
4
6
8
0 2 4 6 8
0
2
4
6
8
0 2 4 6 8
Gather & Bcast
[Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-44-320.jpg)


![53
NCCLż╬īgū░
? 1 CPU and 4 GPUs (PCIe)
Ring Algorithm
Most collectives amenable to bandwidth-optimal
implementation on rings, and many topologyies can be
interpreted as one or more rings [P. Patarasuk and X. Yuan]](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-48-320.jpg)
![54
NCCLż╬īgū░
? 2 CPUs and 8 GPUs (QPI and PCIe)
Ring Algorithm
Most collectives amenable to bandwidth-optimal
implementation on rings, and many topologyies can be
interpreted as one or more rings [P. Patarasuk and X. Yuan]](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-49-320.jpg)
![56
Multi-GPU performance w/o NCCL
NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch
0
2
4
6
8
0 2 4 6 8
Number of GPUs
Scalability
ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers)
0
2
4
6
8
0 2 4 6 8
0
2
4
6
8
0 2 4 6 8
Gather & Bcast
[Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-51-320.jpg)
![57
Multi-GPU performance with NCCL
NVIDIA DGX-1, Chainer 1.17.0 with NCCL patch
0
2
4
6
8
0 2 4 6 8
Number of GPUs
Scalability
ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers)
0
2
4
6
8
0 2 4 6 8
0
2
4
6
8
0 2 4 6 8
NCCL (4-ring)NCCL (1-ring)Gather & Bcast
[Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12](https://image.slidesharecdn.com/20170421tensorflowusergroup-170425052716/85/20170421-tensor-flowusergroup-52-320.jpg)


20170421 tensor flowusergroup
- 1. ź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ń źŪźŻ®`źūźķ®`ź╦ź¾ź░ źĮźĻźÕ®`źĘźńź¾źó®`źŁźŲź»ź╚╝µCUDAź©ź¾źĖź╦źó ┤Õ╔Žšµ─╬ TensorFlow User Group źŽ®`ź╔▓┐ #2 TensorFlow+GPUźŪźŻ®`źūźķ®`ź╦ź¾ź░
- 2. 2 ūį╝║ĮBĮķ ┤Õ╔Žšµ─╬(żÓżķż½ż▀ż▐ż╩) / mmurakami@nvidia.com ? CUDAź©ź¾źĖź╦źóŻ½źŪźŻ®`źūźķ®`ź╦ź¾ź░SA ? źŪźŻ®`źūźķ®`ź╦ź¾ź░?CUDA╝╝ągźĄź▌®`ź╚ż╚ż½ĪóżżżĒżżżĒ ł╬ė±▒hżĄżżż┐ż▐╩ą įńĘR╠’┤¾č¦Į╠ė²č¦▓┐└Ēč¦┐Ų╩²č¦?źĘź╣źŲźÓėŗ╗ŁčąŠ┐╦∙?źĄźÓź╣ź¾╚š▒ŠčąŠ┐╦∙?ź©ź╠źėźŪźŻźó ╗ŁŽ±äI└Ē(ų„ż╦Š▓ų╣╗Ł)ĪóźĮźšź╚ż╬ūŅ▀m╗»ż╚ż½Īó źūźĻź»źķż╚ż½Ę┼╦═ÖCŲ„ż╚ż½źŲźņźėż╚ż½ 2010─ĻĒĢż╦│§żßżŲCUDAż╦żšżņżļ(CUDA1.XXż╚ż½ż╬Ģr┤·) NVIDIAGPUComputing NVIDIAJapan @NVIDIAJapan
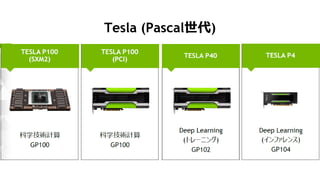
- 6. 7 2012 20142008 2010 2016 2018 48 36 12 0 24 60 72 Tesla Fermi Kepler Maxwell Pascal ╗ņ║ŽŠ½Č╚č▌╦Ń ▒ČŠ½Č╚č▌╦Ń 3D źßźŌźĻ NVLink Volta GPU źĒ®`ź╔ź▐ź├źū SGEMM/W
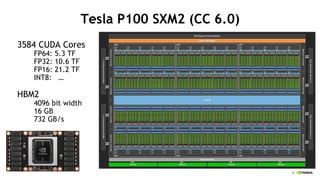
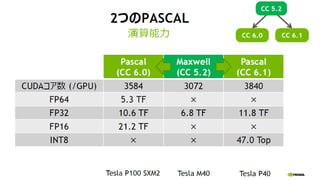
- 7. 8 Tesla P100 SXM2 (CC 6.0) 3584 CUDA Cores FP64: 5.3 TF FP32: 10.6 TF FP16: 21.2 TF INT8: ĪŁ HBM2 4096 bit width 16 GB 732 GB/s
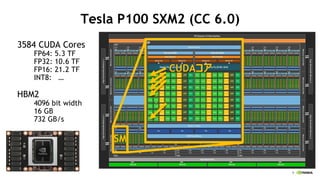
- 8. 9 Tesla P100 SXM2 (CC 6.0) 3584 CUDA Cores FP64: 5.3 TF FP32: 10.6 TF FP16: 21.2 TF INT8: ĪŁ HBM2 4096 bit width 16 GB 732 GB/s SM CUDAź│źó Ż« Ż« Ż«
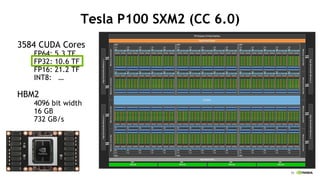
- 9. 10 Tesla P100 SXM2 (CC 6.0) 3584 CUDA Cores FP64: 5.3 TF FP32: 10.6 TF FP16: 21.2 TF INT8: ĪŁ HBM2 4096 bit width 16 GB 732 GB/s
- 10. 11 GPUźó®`źŁźŲź»ź┴źŃĖ┼ę¬ PCI I/F ź█ź╣ź╚ĮėŠAźżź¾ź┐źšź¦®`ź╣ Giga Thread Engine SMż╦äI└Ēż“ĖŅżĻš±żļź╣ź▒źĖźÕ®`źķ DRAM (384-bit, GDDR5) ╚½SMĪóPCI I/Fż½żķźóź»ź╗ź╣┐╔─▄ż╩ źßźŌźĻ (źŪźąźżź╣źßźŌźĻ, źšźņ®`źÓźąź├ źšźĪ) L2 cache (1.5MB) ╚½SMż½żķźóź»ź╗ź╣┐╔─▄ż╩R/WźŁźŃź├ źĘźÕ SM (Streaming Multiprocessor) ĪĖüK┴ąĪ╣źūźĒź╗ź├źĄ Pascal GP100
- 11. 12 SM (streaming multiprocessor) ? CUDA core ? GPUź╣źņź├ź╔żŽż│ż╬╔ŽżŪäėū„ ? Pascal: 64éĆ ? Other units ? DP, LD/ST, SFU ? Register File (65,536 x 32bit) ? Shared Memory/L1 Cache (64KB) ? Read-Only Cache(48KB)
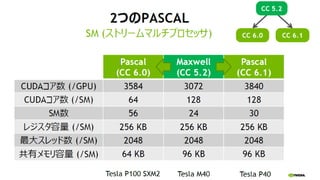
- 12. 13 Register File Scheduler Dispatch Scheduler Dispatch Load/Store Units x 16 Special Func Units x 4 Interconnect Network 64K Configurable Cache/Shared Mem Uniform Cache Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Instruction Cache Compute Capability (CC) Kepler CC 3.5 192 cores / SMX Maxwell CC 5.0 128 cores / SMM Fermi CC 2.0 32 cores / SM Pascal CC 6.0 64 cores / SMM https://developer.nvidia.com/cuda-gpus
- 16. 17 Image Recognition (Microsoft) šJūRŠ½Č╚Ž“╔Žż╬ż┐żß źŌźŪźļżŽżĶżĻźŪźŻ®`źūż╦ĪóźŪ®`ź┐żŽżĶżĻ┤¾żŁż» ÅŖ┴”ż╩ėŗ╦Ńźčź’®`ż¼▒žę¬ż╦ 2012 AlexNet 8 Layers 1.4 GFLOP ~16% Error 152 Layers 22.6 GFLOP ~3.5% Error 2015 ResNet 16X Model 2014 Deep Speech 1 80 GFLOP 7,000 hrs of Data ~8% Error 465 GFLOP 12,000 hrs of Data ~5% Error 2015 Deep Speech 2 10X Training Ops Speech Recognition (Baidu)
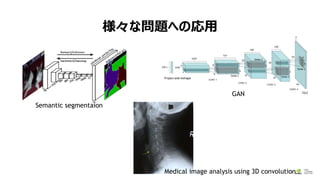
- 17. śöĪ®ż╩å¢Ņ}żžż╬ÅĻė├ 18 Semantic segmentaion GAN Medical image analysis using 3D convolution
- 18. GPUż¼źŪźŻ®`źūźķ®`ź╦ź¾ź░ż╦Ž“żżżŲżżżļ└Ēė╔ 1. Ü°ė├źóź»ź╗źķźņ®`ź┐żŪżóżļĪŻżĘż½żŌėŗ╦Ńż¼Ė▀╦┘ ? śöĪ®ż╩źóźūźĻź▒®`źĘźńź¾ż“ū▀żķż╗żļ╩┬ż¼┐╔─▄ĪŻżĘż½żŌĖ▀╦┘ż╦ėŗ╦Ńż╣żļ╩┬ż¼│÷└┤żļĪŻ 2. ķ_░kĢrķgż¼Č╠żżĪŻūŅ▀m╗»ż¼║åģgĪŻ ? CUDA C/C++ż╚żżż”C/C++ż╬ÆłÅłčįšZżŪėø╩÷┐╔─▄ĪŻč¦┴Ģź│ź╣ź╚żŌĄ═ż»Īó║åģgż╦źóźūźĻź▒®`źĘźńź¾ķ_ ░kż¼│÷└┤żļĪŻ ? ķ_░kź─®`źļż¼│õīgżĘżŲż¬żĻĪóźūźĒźšźĪźżźķżõźŪźąź├ź¼ż“╩╣ż©żąĪóźąź░ą▐š²żõūŅ▀m╗»ż¼╚▌ęū 3. źŽ®`ź╔ź”ź¦źóż¼źŪźŻ®`źūźķ®`ź╦ź¾ź░Ž“ż▒ż╦▀M╗» ? NVLINKż╚żżż”Ė▀╦┘ż╩źŪ®`ź┐▄×╦═źżź¾ź┐®`ź│ź═ź»ź╚ż“źĄź▌®`ź╚(ź▐źļź┴GPUżŪż╬č¦┴Ģż¼żĶżĻĖ▀╦┘ż╦) ? GPU┤Ņ▌dźßźŌźĻ┴┐ż╬ēł╝ė(żĶżĻč}ļjż╩ź═ź├ź╚ź’®`ź»ż“┤¾żŁż╩źąź├ź┴źĄźżź║żŪėŗ╦Ń┐╔─▄ż╦) ? żĮż╬╦¹żżżĒżżżĒ 19
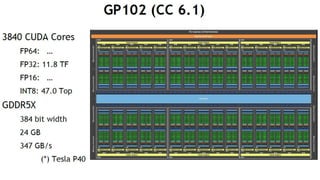
- 19. 20 K80 M40 M4 P100 (SXM2) P100 (PCIE) P40 P4 GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104 CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560 PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5 PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA PEAK TIOPs NA NA NA NA NA 47 22 Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5 Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3 NVLINK + PCIe Gen3 PCIe Gen3 PCIe Gen3 PCIe Gen3 ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5 Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W TeslačuŲĘę╗ėE ż┐ż»żĄż¾żóżļż¼Īóż╔żņż“╩╣ż©żążĶżżż╬ż½?
- 23. 24 K80 M40 M4 P100 (SXM2) P100 (PCIE) P40 P4 GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104 CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560 PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5 PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA PEAK TIOPs NA NA NA NA NA 47 22 Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5 Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3 NVLINK + PCIe Gen3 PCIe Gen3 PCIe Gen3 PCIe Gen3 ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5 Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W TeslačuŲĘę╗ėE ═Ųšō ═Ųšōč¦┴Ģ č¦┴Ģ
- 24. 25 K80 M40 M4 P100 (SXM2) P100 (PCIE) P40 P4 GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104 CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560 PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5 PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA PEAK TIOPs NA NA NA NA NA 47 22 Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5 Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3 NVLINK + PCIe Gen3 PCIe Gen3 PCIe Gen3 PCIe Gen3 ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5 Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W TeslačuŲĘę╗ėE
- 25. 26 2ż─ż╬PASCAL
- 26. 27
- 27. 28
- 28. 29
- 29. 30
- 30. 31
- 31. 32
- 32. 33
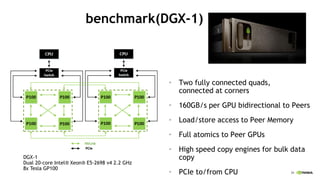
- 35. 39 benchmark(DGX-1) ? Two fully connected quads, connected at corners ? 160GB/s per GPU bidirectional to Peers ? Load/store access to Peer Memory ? Full atomics to Peer GPUs ? High speed copy engines for bulk data copy ? PCIe to/from CPU DGX-1 Dual 20-core Intel? Xeon? E5-2698 v4 2.2 GHz 8x Tesla GP100
- 36. 40 TensorFlow Deep Learning Training An open-source software library for numerical computation using data flow graphs. VERSION 1.0 ACCELERATED FEATURES Full framework accelerated SCALABILITY Multi-GPU and multi-node More Information https://www.tensorflow.org/ TensorFlow Deep Learning Framework Training on 8x P100 GPU Server vs 8 x K80 GPU Server - 1.0 2.0 3.0 4.0 5.0 Speedupvs.Serverwith8xK80 AlexNet GoogleNet ResNet-50 ResNet-152 VGG16 2.5x Avg. Speedup 3x Avg. Speedup GPU Servers: Single Xeon E5-2690 v4@2.6GHz with GPUs configs as shown Ubuntu 14.04.5, CUDA 8.0.42, cuDNN 6.0.5; NCCL 1.6.1, data set: ImageNet; batch sizes: AlexNet (128), GoogleNet (256), ResNet-50 (64), ResNet-152 (32), VGG-16 (32) Server with 8x P100 16GB NVLink Server with 8x P100 PCIe 16GB
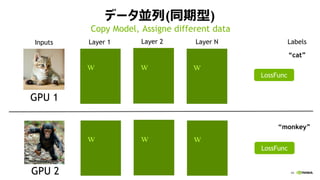
- 39. 44 źŪ®`ź┐üK┴ą(═¼Ų┌ą═) w w w Layer 1 Layer 2Inputs Layer N LossFunc LossFunc GPU 1 GPU 2 Ī░catĪ▒ Labels Ī░monkeyĪ▒ w w w Copy Model, Assigne different data
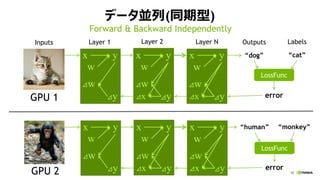
- 40. 45 źŪ®`ź┐üK┴ą(═¼Ų┌ą═) w x y w x y w x y Layer 1 Ī░dogĪ▒ Layer 2Inputs OutputsLayer N LossFunc Ī░humanĪ▒ LossFunc GPU 1 GPU 2 Ī░catĪ▒ Labels Ī░monkeyĪ▒ error©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw w x y w x y w x y ©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw error Forward & Backward Independently
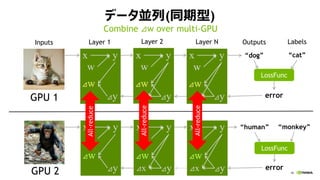
- 41. 46 źŪ®`ź┐üK┴ą(═¼Ų┌ą═) w x y w x y w x y Layer 1 Ī░dogĪ▒ Layer 2Inputs OutputsLayer N LossFunc Ī░humanĪ▒ LossFunc GPU 1 GPU 2 Ī░catĪ▒ Labels Ī░monkeyĪ▒ error©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw w x y w x y w x y ©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw error Combine ©Sw over multi-GPU ©Sw©Sw©Sw ©Sw©Sw©Sw All-reduce All-reduce All-reduce
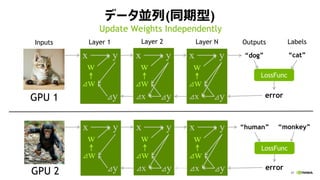
- 42. 47 źŪ®`ź┐üK┴ą(═¼Ų┌ą═) w x y w x y w x y Layer 1 Ī░dogĪ▒ Layer 2Inputs OutputsLayer N LossFunc Ī░humanĪ▒ LossFunc GPU 1 GPU 2 Ī░catĪ▒ Labels Ī░monkeyĪ▒ error©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw w x y w x y w x y ©Sy©Sx©Sy©Sx©Sy ©Sw©Sw©Sw error Update Weights Independently w w w w w w
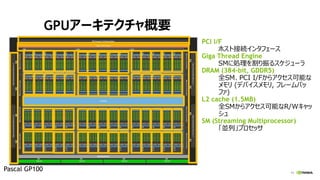
- 43. 48 ź▐źļź┴GPUč¦┴Ģż╬źčźšź®®`ź▐ź¾ź╣ NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 Speed-upto1GPU Number of GPUs AlexNet VGG-D ResNet [Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12 0 0.5 1 1.5 2 2.5 1 2 4 8 Relativetimeto1GPU Number of GPUs Time per one batch (VGG-D) Update Allreduce Backward Forward DGX-1Ī»s NVLink is not well utilized. ChainerĪ»s all-reduce implementation is na?ve Ī░gather and broadcatĪ▒.
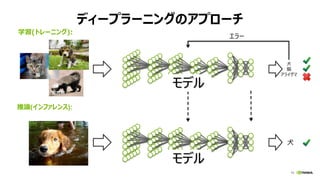
- 44. 49 ź▐źļź┴GPUč¦┴Ģż╬źčźšź®®`ź▐ź¾ź╣(NCCL╩╣ė├ż╩żĘ) ) NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch 0 2 4 6 8 0 2 4 6 8 Number of GPUs Scalability ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers) 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 Gather & Bcast [Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12
- 45. 50 NCCL
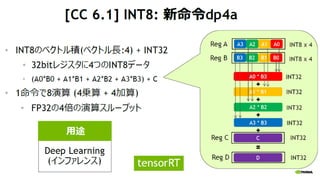
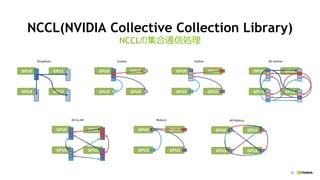
- 46. 51 NCCL(NVIDIA Collective Collection Library) ź▐źļź┴GPU╝»║Ž═©ą┼źķźżźųźķźĻ ? ūŅą┬źĻźĻ®`ź╣żŽv1.2.3 ? https://github.com/NVIDIA/nccl all-gather, reduce, broadcast ż╩ż╔ś╦£╩Ą─ż╩╝»║Ž═©ą┼ż╬äI└Ēż“źąź¾ź╔Ę∙ż¼│÷żļżĶż”ż╦ūŅ▀m╗» źĘź¾ź░źļźūźĒź╗ź╣ż¬żĶżėź▐źļź┴źūźĒź╗ź╣żŪ╩╣ė├ż╣żļ╩┬ż¼┐╔─▄ źŪźŻ®`źūźķ®`ź╦ź¾ź░ SDK
- 47. 52 NCCL(NVIDIA Collective Collection Library) NCCLż╬╝»║Ž═©ą┼äI└Ē
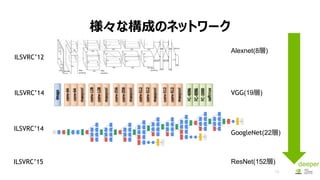
- 48. 53 NCCLż╬īgū░ ? 1 CPU and 4 GPUs (PCIe) Ring Algorithm Most collectives amenable to bandwidth-optimal implementation on rings, and many topologyies can be interpreted as one or more rings [P. Patarasuk and X. Yuan]
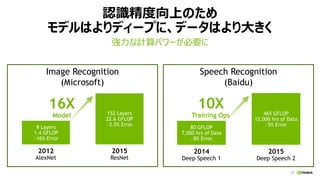
- 49. 54 NCCLż╬īgū░ ? 2 CPUs and 8 GPUs (QPI and PCIe) Ring Algorithm Most collectives amenable to bandwidth-optimal implementation on rings, and many topologyies can be interpreted as one or more rings [P. Patarasuk and X. Yuan]
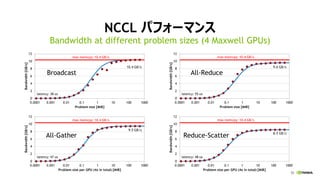
- 50. 55 NCCL źčźšź®®`ź▐ź¾ź╣ Bandwidth at different problem sizes (4 Maxwell GPUs) All-Gather All-Reduce Reduce-Scatter Broadcast
- 51. 56 Multi-GPU performance w/o NCCL NVIDIA DGX-1, Chainer 1.17.0 with multi-process patch 0 2 4 6 8 0 2 4 6 8 Number of GPUs Scalability ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers) 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 Gather & Bcast [Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12
- 52. 57 Multi-GPU performance with NCCL NVIDIA DGX-1, Chainer 1.17.0 with NCCL patch 0 2 4 6 8 0 2 4 6 8 Number of GPUs Scalability ResNet (152 layers)VGG-D (16 layers)AlexNet (7 layers) 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 NCCL (4-ring)NCCL (1-ring)Gather & Bcast [Batch size per GPU] AlexNet:768, VGG-D:32, ResNet:12
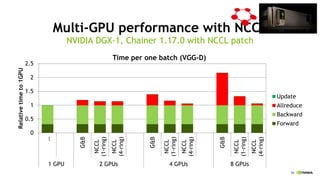
- 53. 58 Multi-GPU performance with NCCL NVIDIA DGX-1, Chainer 1.17.0 with NCCL patch 0 0.5 1 1.5 2 2.5 ĪŁ G&B NCCL (1-ring) NCCL (4-ring) G&B NCCL (1-ring) NCCL (4-ring) G&B NCCL (1-ring) NCCL (4-ring) 1 GPU 2 GPUs 4 GPUs 8 GPUs Relativetimeto1GPU Time per one batch (VGG-D) Update Allreduce Backward Forward
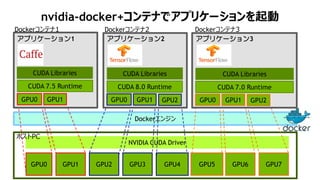
- 55. 60 nvidia-docker+ź│ź¾źŲź╩żŪźóźūźĻź▒®`źĘźńź¾ż“Ųäė GPU2 GPU3 GPU4 GPU6 GPU7 NVIDIA CUDA Driver Dockerź©ź¾źĖź¾ GPU5GPU0 GPU1 ź█ź╣ź╚PC GPU0 GPU1 CUDA Libraries Dockerź│ź¾źŲź╩1 CUDA 7.5 Runtime źóźūźĻź▒®`źĘźńź¾1 GPU0 GPU1 GPU2 CUDA Libraries Dockerź│ź¾źŲź╩2 CUDA 8.0 Runtime źóźūźĻź▒®`źĘźńź¾2 GPU0 GPU1 GPU2 CUDA Libraries Dockerź│ź¾źŲź╩3 CUDA 7.0 Runtime źóźūźĻź▒®`źĘźńź¾3
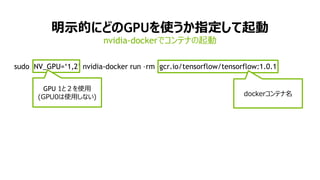
- 56. 61 ├„╩ŠĄ─ż╦ż╔ż╬GPUż“╩╣ż”ż½ųĖČ©żĘżŲŲäė sudo NV_GPU=Ī«1,2Ī» nvidia-docker run ©Crm gcr.io/tensorflow/tensorflow:1.0.1 nvidia-dockerżŪź│ź¾źŲź╩ż╬Ųäė GPU 1ż╚Ż▓ż“╩╣ė├ (GPU0żŽ╩╣ė├żĘż╩żż) dockerź│ź¾źŲź╩├¹
- 57. THANK YOU!