Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņŹ¹¤¤¤³¤Ź¤¹
15 likes18,718 views

2018Äź12ŌĀ15ČÕ¤Ī Chainer Meetup #08 ¤Ē„Ø„Ģ„Ó„Ē„£„¢¤Ī³É¤¬°k±ķ¤·¤æŁYĮĻ¤Ē¤¹”£ https://chainer.connpass.com/event/106292/












![26
NHWC FORMAT
? NCHW ¤Ą¤Č”¢Convolution Ē°įį
¤Ē”¢ŗĻÓ 3 »Ų¤Ī Tensor
Transpose ¤¬±ŲŅŖ
? NHWC ¤Ź¤é”¢Transpose ²»ŅŖ
”ś GPU „«©`„Ķ„ėŹżĻ÷p
? Chainer ¤Ļ NCHW only
? NHWC ÓƤĪ
Convolution/Bnorm „ā„ø„å©`„ė
¤ņŌ×÷
cuDNN Convolution for TensorCore: NHWC format ¤Ēøߤ¤ŠŌÄܤņ°k]
NCHW NHWC
Ō×÷](https://image.slidesharecdn.com/20181215chainermeetup-181217054721/85/Chainer-Tensor-fp16-26-320.jpg)






![[Track2-2] ×īŠĀ¤ĪNVIDIA Ampere„¢©`„„Ę„Æ„Į„ć¤Ė¤č¤ėNVIDIA A100 Tensor„³„¢GPU¤ĪĢŲéL¤Č¤½¤ĪŠŌÄܤņŅż¤³ö¤¹·½·Ø](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=560&fit=bounds)










![[DLŻÕi»į]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=560&fit=bounds)
![[DLŻÕi»į]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=560&fit=bounds)













More Related Content
What's hot (20)
Similar to Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņŹ¹¤¤¤³¤Ź¤¹ (20)


















More from NVIDIA Japan (20)




















Recently uploaded (11)











Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņŹ¹¤¤¤³¤Ź¤¹
- 1. Akira Naruse, Senior Developer Technology Engineer, 2018/12/15 Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņ Ź¹¤¤¤³¤Ź¤¹
- 3. 3 ×ī³õ¤Ė¤Ŗ¤³¤Č¤ļ¤ź” „愤„Č„ė: ? Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņŹ¹¤¤¤³¤Ź¤¹ ÖŠÉķ: ? ¤¢¤ź¤Č¤¢¤é¤ę¤ėŹÖ¶Ī¤ņŹ¹¤¤”¢Chainer ¤Ē Tensor „³„¢ (fp16) ¤ņ ¤É¤³¤Ž¤ĒŹ¹¤¤¤¤ģ¤ė¤«¤ņ”¢gņY¤·¤æ
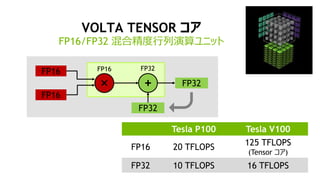
- 4. 4 VOLTA TENSOR „³„¢ FP16/FP32 »ģŗĻ¾«¶ČŠŠĮŠŃŻĖć„ę„Ė„Ć„Č Tesla P100 Tesla V100 FP16 20 TFLOPS 125 TFLOPS (Tensor „³„¢) FP32 10 TFLOPS 16 TFLOPS FP16 FP16 ”Į + FP32 FP32 FP16 FP32
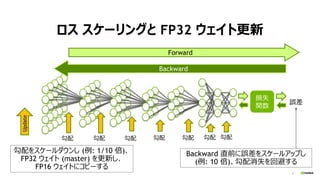
- 5. 5 FP16 ¤ĒѧĮ¤·¤Ę”¢¾«¶Č¤Ļ“óÕÉ·ņ? ? 2 ¤Ä¤Ī„Ę„Æ„Ė„Ć„Æ ? „ķ„¹ „¹„±©`„ź„ó„° ? „ķ„¹¤ņ„¹„±©`„ė„¢„Ƅפ·”¢¹“ÅäĻūŹ§¤ņ¾ŗĶ ? „¦„§„¤„ČøüŠĀÖ±Ē°¤Ė”¢¹“Åä¤ņ„¹„±©`„ė„Ą„¦„ó ? FP32 „¦„§„¤„ČøüŠĀ (FP16 ¤Č FP32 ¤ĪćÓĆ) ? Forward/Backward ¤Ļ FP16 ¤ĒÓĖć ? Update ¤Ē FP32 ¤ņŹ¹ÓĆ Mixed Precision Training https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/ ¹“Åä¤Ī·Ö²¼ (*) FP16 ¤Ė¤¹¤ė¤Č”¢¶ą¤Æ¤Ī¹“Å䤬„¼„ķ¤Ė¤Ź¤Ć¤Ę¤·¤Ž¤¦
- 6. 6 „ķ„¹ „¹„±©`„ź„ó„°¤Č FP32 „¦„§„¤„ČøüŠĀ ¹“Å乓Å乓Å乓Å乓Å乓Å乓Åä pŹ§ évŹż Õ`²ī Backward Forward Update ¹“Åä¤ņ„¹„±©`„ė„Ą„¦„ó¤· (Ąż: 1/10 ±¶)”¢ FP32 „¦„§„¤„Č (master) ¤ņøüŠĀ¤·”¢ FP16 „¦„§„¤„ȤĖ„³„Ō©`¤¹¤ė Backward Ö±Ē°¤ĖÕ`²ī¤ņ„¹„±©`„ė„¢„Ƅפ· (Ąż: 10 ±¶)”¢¹“ÅäĻūŹ§¤ņ»Ų±Ü¤¹¤ė
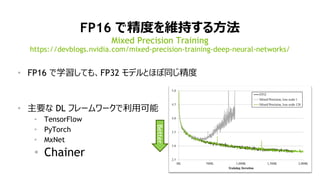
- 7. 7 FP16 ¤Ē¾«¶Č¤ņ¾S³Ö¤¹¤ė·½·Ø ? FP16 ¤ĒѧĮ¤·¤Ę¤ā”¢FP32 „ā„Ē„ė¤Č¤Ū¤ÜĶ¬¤ø¾«¶Č ? Ö÷ŅŖ¤Ź DL „Õ„ģ©`„ą„ļ©`„ƤĒĄūÓĆæÉÄÜ ? TensorFlow ? PyTorch ? MxNet ? Chainer Mixed Precision Training https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/ Better
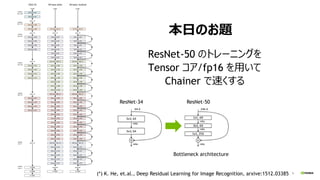
- 8. 8 ±¾ČÕ¤Ī¤Ŗī} ResNet-50 ¤Ī„Č„ģ©`„Ė„ó„°¤ņ Tensor „³„¢/fp16 ¤ņÓƤ¤¤Ę Chainer ¤ĒĖŁ¤Æ¤¹¤ė (*) K. He, et.al., Deep Residual Learning for Image Recognition, arxive:1512.03385 Bottleneck architecture ResNet-34 ResNet-50
- 9. 9 „Ę„¹„Čh¾³ Machine: DGX Station GPU: Tesla V100-16GB CUDA: 9.2 cuDNN: 7.4.1 Chainer: v6.0.0b1+ CuPy: v6.0.0b1+
- 10. 10 ×¢ŅāŹĀķ: ¤½¤Ī1 cuDNN ¤Ī„ļ©`„Æ„¹„Ś©`„¹„µ„¤„ŗ¤ņ“ó¤¤į¤ĖŌO¶Ø¤¹¤ė chainer.cuda.set_max_workspace_size(512*1024*1024) # 512MiB cuDNN ¤Ī Auto Tuning ¤ņŹ¹¤¦ config.autotune = True (*) ¤½¤¦¤·¤Ź¤¤¤Č”¢ßmĒŠ¤Ź„¢„ė„“„ź„ŗ„ą¤¬ßxk¤µ¤ģ¤Ź¤¤”¢¤³¤Č¤¬¶ą¤¤ cuDNN ¤ĪøßĖŁ Batch Normalization g×°¤ņŹ¹¤¦ config.cudnn_fast_batch_normalization = True (*) fp32 ¤Ē¤āӊ攢„Ŗ©`„Š©`„Õ„ķ©`¤ĪæÉÄÜŠŌÓŠ¤ė¤Ī¤Ē×¢Ņā cuDNN tips
- 11. 11 ×¢ŅāŹĀķ: ¤½¤Ī2 „ā„Ē„ėÓŹö¤ņ fp16 Ļņ¤±¤ĖŠŽÕż ? ČėĮ¦: fp16 ¤Ė cast ? Initializer”¢Batch normalization: dtype ¤Ė fp16 Öø¶Ø ±¾µ±¤Ļ”¢fp16 „ā©`„ɤņ„»„ƄȤ¹¤ė¤Ą¤±¤Ē OK ¤Ź¤ó¤Ą¤±¤É.. CHAINER_DTYPE=float16 Chainer tips def forward(self, x, t): - h = self.bn1(self.conv1(x)) + h = self.bn1(self.conv1(F.cast(x, np.float16))) h = F.max_pooling_2d(F.relu(h), 3, stride=2) self.conv1 = L.Convolution2D(3, 64, 7, 2, 3, - initialW=initializers.HeNormal()) - self.bn1 = L.BatchNormalization(64) + initialW=initializers.HeNormal(dtype=np.float16)) + self.bn1 = L.BatchNormalization(64, dtype=np.float16)
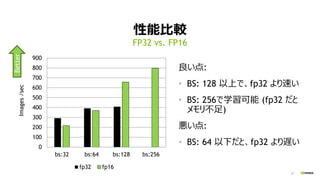
- 12. 12 ŠŌÄܱȯ^ Į¼¤¤µć: ? BS: 128 ŅŌÉĻ¤Ē”¢fp32 ¤č¤źĖŁ¤¤ ? BS: 256¤ĒѧĮæÉÄÜ (fp32 ¤Ą¤Č „į„ā„ź²»×ć) ¤¤µć: ? BS: 64 ŅŌĻĀ¤Ą¤Č”¢fp32 ¤č¤źßW¤¤ FP32 vs. FP16 0 100 200 300 400 500 600 700 800 900 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 Better
- 13. 13 TRAINING ITERATION CPU ¤ĪŹĖŹĀ ? IO: ČėĮ¦»Ļń¤ĪĒ°IĄķ (Decode, Augmentation) ? Forward/Backward/Update: ÓĖć„°„é„Õ¹ÜĄķ, „į„ā„ź¹ÜĄķ, GPU „«©`„Ķ„ėĶ¶Čė IO Forward Backward Update GPU ¤ĪŹĖŹĀ ? Forward/Backward/Update: CPU ¤«¤éĶ¶Čė¤µ¤ģ¤æ„«©`„Ķ„ė¤ņgŠŠ
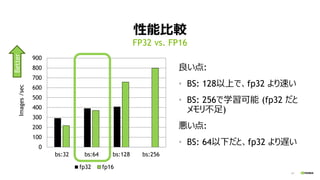
- 14. 14 ŠŌÄܱȯ^ Į¼¤¤µć: ? BS: 128ŅŌÉĻ¤Ē”¢fp32 ¤č¤źĖŁ¤¤ ? BS: 256¤ĒѧĮæÉÄÜ (fp32 ¤Ą¤Č „į„ā„ź²»×ć) ¤¤µć: ? BS: 64ŅŌĻĀ¤Ą¤Č”¢fp32 ¤č¤źßW¤¤ FP32 vs. FP16 0 100 200 300 400 500 600 700 800 900 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 Better
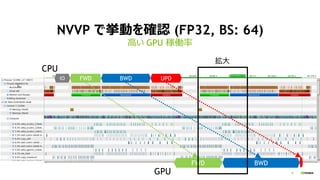
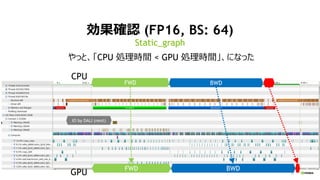
- 15. 15 NVVP ¤Ē¤Ó¤ņ“_ÕJ (FP32, BS: 64) øߤ¤ GPU ¼ŚPĀŹ FWD BWD UPDIO CPU FWD BWD GPU “ó
- 16. 16 NVVP ¤Ē¤Ó¤ņ“_ÕJ (FP32, BS: 64) “óķ øߤ¤ GPU ¼ŚPĀŹ FWD BWD
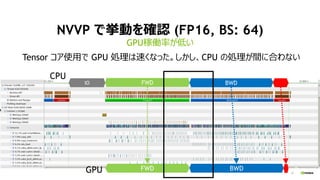
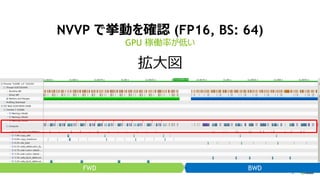
- 17. 17 NVVP ¤Ē¤Ó¤ņ“_ÕJ (FP16, BS: 64) GPU¼ŚPĀŹ¤¬µĶ¤¤ FWD BWDIO CPU FWD BWDGPU Tensor „³„¢Ź¹ÓƤĒ GPU IĄķ¤ĻĖŁ¤Æ¤Ź¤Ć¤æ”£¤·¤«¤·”¢CPU ¤ĪIĄķ¤¬ég¤ĖŗĻ¤ļ¤Ź¤¤
- 18. 18 NVVP ¤Ē¤Ó¤ņ“_ÕJ (FP16, BS: 64) “óķ GPU ¼ŚPĀŹ¤¬µĶ¤¤ FWD BWD
- 19. 19 ²ß: CPU ¤ĪŲŗɤņp¤é¤¹ IO IĄķ¤ņøßĖŁ»Æ”¢e„¹„ģ„ƄɤĒgŠŠ ? NVIDIA DALI GPU ²Ł×÷»ŲŹż”¢GPU „«©`„Ķ„ėŹż¤ņĻ÷p ? Batched weight update”¢ Fused Bnorm/ReLu”¢ NHWC format ÓĖć„°„é„Õ¹ÜĄķŲŗɤņĻ÷p ? Chainer static_graph
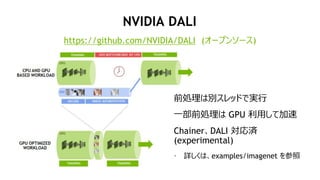
- 20. 20 NVIDIA DALI https://github.com/NVIDIA/DALI („Ŗ©`„ׄ󄽩`„¹) Ē°IĄķ¤Ļe„¹„ģ„ƄɤĒgŠŠ Ņ»²æĒ°IĄķ¤Ļ GPU ĄūÓƤ·¤Ę¼ÓĖŁ Chainer”¢DALI źg (experimental) ? Ō¤·¤Æ¤Ļ”¢examples/imagenet ¤ņ²ĪÕÕ
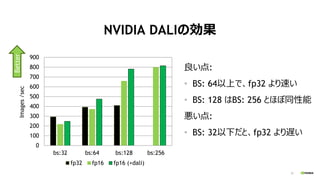
- 21. 21 NVIDIA DALI¤Īæ¹ū Į¼¤¤µć: ? BS: 64ŅŌÉĻ¤Ē”¢fp32 ¤č¤źĖŁ¤¤ ? BS: 128 ¤ĻBS: 256 ¤Č¤Ū¤ÜĶ¬ŠŌÄÜ ¤¤µć: ? BS: 32ŅŌĻĀ¤Ą¤Č”¢fp32 ¤č¤źßW¤¤ 0 100 200 300 400 500 600 700 800 900 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 fp16 (+dali) Better
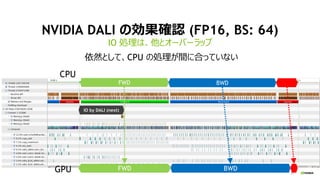
- 22. 22 NVIDIA DALI ¤Īæ¹ū“_ÕJ (FP16, BS: 64) IO IĄķ¤Ļ”¢Ėū¤Č„Ŗ©`„Š©`„é„Ć„× FWD BWD FWD BWD IO by DALI (next) CPU GPU ŅĄČ»¤Č¤·¤Ę”¢CPU ¤ĪIĄķ¤¬ég¤ĖŗĻ¤Ć¤Ę¤¤¤Ź¤¤
- 23. 23 ²ß: CPU ¤ĪŲŗɤņp¤é¤¹ IO IĄķ¤ņøßĖŁ»Æ”¢e„¹„ģ„ƄɤĒgŠŠ ? NVIDIA DALI GPU ²Ł×÷»ŲŹż”¢GPU „«©`„Ķ„ėŹż¤ņĻ÷p ? Batched weight update”¢ Fused Bnorm/ReLu”¢ NHWC format ÓĖć„°„é„Õ¹ÜĄķŲŗɤņĻ÷p ? Chainer static_graph
- 24. 24 BATCHED WEIGHT UPDATE Chainer optimizer ¤Ļ”¢„ģ„¤„ä©`°(¤č¤źÕż“_¤Ė¤Ļ„Ń„é„į©`„æ°)¤Ė”¢ÖŲ¤ß¤ņøüŠĀ ? ¶ąŹż¤Ī GPU „«©`„Ķ„ėĘšÓ ”ś CPU ŲŗÉ“ó Single GPU „«©`„Ķ„ė¤Ē”¢Č«¤Ę¤ĪÖŲ¤ß¤ņøüŠĀ (batched_update) Chainer #5841 PRÖŠ update update CPU GPU
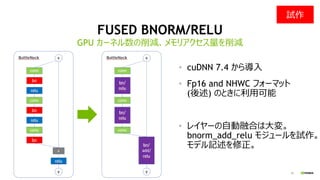
- 25. 25 FUSED BNORM/RELU ? cuDNN 7.4 ¤«¤é§Čė ? Fp16 and NHWC „Õ„©©`„Ž„Ć„Č (įįŹö) ¤Ī¤Č¤¤ĖĄūÓĆæÉÄÜ ? „ģ„¤„ä©`¤Ī×ŌÓČŚŗĻ¤Ļ“ó䔣 bnorm_add_relu „ā„ø„å©`„ė¤ņŌ×÷”£ „ā„Ē„ėÓŹö¤ņŠŽÕż”£ GPU „«©`„Ķ„ėŹż¤ĪĻ÷p”¢„į„ā„ź„¢„Æ„»„¹Įæ¤ņĻ÷p Ō×÷
- 26. 26 NHWC FORMAT ? NCHW ¤Ą¤Č”¢Convolution Ē°įį ¤Ē”¢ŗĻÓ 3 »Ų¤Ī Tensor Transpose ¤¬±ŲŅŖ ? NHWC ¤Ź¤é”¢Transpose ²»ŅŖ ”ś GPU „«©`„Ķ„ėŹżĻ÷p ? Chainer ¤Ļ NCHW only ? NHWC ÓƤĪ Convolution/Bnorm „ā„ø„å©`„ė ¤ņŌ×÷ cuDNN Convolution for TensorCore: NHWC format ¤Ēøߤ¤ŠŌÄܤņ°k] NCHW NHWC Ō×÷
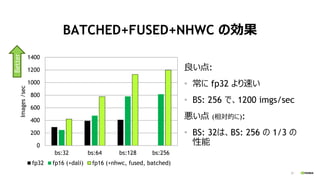
- 27. 27 BATCHED+FUSED+NHWC ¤Īæ¹ū Į¼¤¤µć: ? ³£¤Ė fp32 ¤č¤źĖŁ¤¤ ? BS: 256 ¤Ē”¢1200 imgs/sec ¤¤µć (ĻąµÄ¤Ė): ? BS: 32¤Ļ”¢BS: 256 ¤Ī 1/3 ¤Ī ŠŌÄÜ0 200 400 600 800 1000 1200 1400 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 (+dali) fp16 (+nhwc, fused, batched) Better
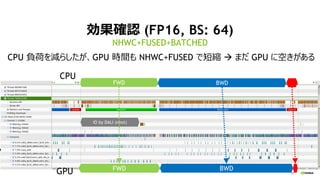
- 28. 28 æ¹ū“_ÕJ (FP16, BS: 64) NHWC+FUSED+BATCHED FWD BWD FWD BWD IO by DALI (next) CPU GPU CPU Ųŗɤņp¤é¤·¤æ¤¬”¢GPU rég¤ā NHWC+FUSED ¤Ē¶Ģæs ”ś ¤Ž¤Ą GPU ¤ĖæÕ¤¤¬¤¢¤ė
- 29. 29 ²ß: CPU ¤ĪŲŗɤņp¤é¤¹ IO IĄķ¤ņøßĖŁ»Æ”¢e„¹„ģ„ƄɤĒgŠŠ ? NVIDIA DALI GPU ²Ł×÷»ŲŹż”¢GPU „«©`„Ķ„ėŹż¤ņĻ÷p ? Batched weight update”¢ Fused Bnorm/ReLu”¢ NHWC format ÓĖć„°„é„Õ¹ÜĄķŲŗɤņĻ÷p ? Chainer static_graph
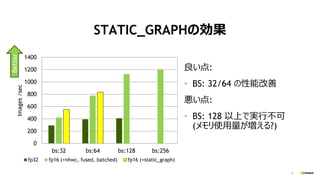
- 31. 31 STATIC_GRAPH¤Īæ¹ū Į¼¤¤µć: ? BS: 32/64 ¤ĪŠŌÄÜøÄÉĘ ¤¤µć: ? BS: 128 ŅŌÉĻ¤ĒgŠŠ²»æÉ („į„ā„źŹ¹ÓĆĮ椬¤Ø¤ė?) 0 200 400 600 800 1000 1200 1400 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 (+nhwc, fused, batched) fp16 (+static_graph) Better
- 32. 32 æ¹ū“_ÕJ (FP16, BS: 64) Static_graph FWD BWD FWD BWD IO by DALI (next) CPU GPU ¤ä¤Ć¤Č”¢”øCPU IĄķrég < GPU IĄķrég”¹”¢¤Ė¤Ź¤Ć¤æ
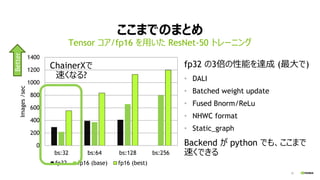
- 33. 33 ¤³¤³¤Ž¤Ē¤Ī¤Ž¤Č¤į fp32 ¤Ī3±¶¤ĪŠŌÄܤņß_³É (×ī“ó¤Ē) ? DALI ? Batched weight update ? Fused Bnorm/ReLu ? NHWC format ? Static_graph Backend ¤¬ python ¤Ē¤ā”¢¤³¤³¤Ž¤Ē ĖŁ¤Æ¤Ē¤¤ė Tensor „³„¢/fp16 ¤ņÓƤ¤¤æ ResNet-50 „Č„ģ©`„Ė„ó„° 0 200 400 600 800 1000 1200 1400 bs:32 bs:64 bs:128 bs:256 Images/sec fp32 fp16 (base) fp16 (best) Better ChainerX¤Ē ĖŁ¤Æ¤Ź¤ė?
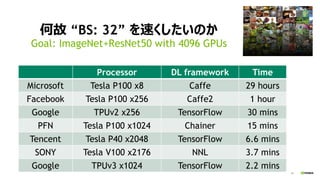
- 34. 34 ŗĪ¹Ź ”°BS: 32”± ¤ņĖŁ¤Æ¤·¤æ¤¤¤Ī¤« Goal: ImageNet+ResNet50 with 4096 GPUs Processor DL framework Time Microsoft Tesla P100 x8 Caffe 29 hours Facebook Tesla P100 x256 Caffe2 1 hour Google TPUv2 x256 TensorFlow 30 mins PFN Tesla P100 x1024 Chainer 15 mins Tencent Tesla P40 x2048 TensorFlow 6.6 mins SONY Tesla V100 x2176 NNL 3.7 mins Google TPUv3 x1024 TensorFlow 2.2 mins
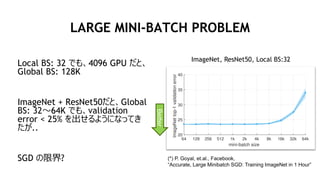
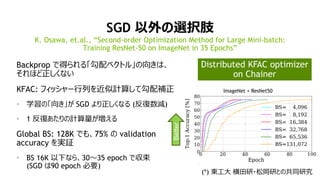
- 35. 35 LARGE MINI-BATCH PROBLEM Local BS: 32 ¤Ē¤ā”¢4096 GPU ¤Ą¤Č”¢ Global BS: 128K ImageNet + ResNet50¤Ą¤Č”¢Global BS: 32”«64K ¤Ē¤ā”¢validation error < 25% ¤ņ³ö¤»¤ė¤č¤¦¤Ė¤Ź¤Ć¤Ę¤ ¤æ¤¬.. SGD ¤ĪĻŽ½ē? ImageNet, ResNet50, Local BS:32 (*) P. Goyal, et.al., Facebook, ”°Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”± Better
- 36. 36 SGD ŅŌĶā¤ĪßxkÖ« Backprop ¤ĒµĆ¤é¤ģ¤ė”ø¹“Åä„Ł„Æ„Č„ė”¹¤ĪĻņ¤¤Ļ”¢ ¤½¤ģ¤Ū¤ÉÕż¤·¤Æ¤Ź¤¤ KFAC: „Õ„£„Ć„·„ć©`ŠŠĮŠ¤ņ½üĖĘÓĖ椷¤Ę¹“ÅäŃaÕż ? ѧĮ¤Ī”øĻņ¤”¹¤¬ SGD ¤č¤źÕż¤·¤Æ¤Ź¤ė (·“ĶŹżp) ? 1 ·“Ķ¤¢¤æ¤ź¤ĪÓĖćĮ椬¤Ø¤ė Global BS: 128K ¤Ē¤ā”¢75% ¤Ī validation accuracy ¤ņgŌ^ ? BS 16K ŅŌĻĀ¤Ź¤é”¢30”«35 epoch ¤Ē §Źų (SGD ¤Ļ90 epoch ±ŲŅŖ) K. Osawa, et.al., ”°Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs”± (*) |¹¤“ó ŗįĢļŃŠ?Ėɳъ¤Č¤Ī¹²Ķ¬ŃŠ¾æ ImageNet + ResNet50 Better Distributed KFAC optimizer on Chainer