More Related Content
What's hot (20)
1070: CUDA źūźĒź░źķź▀ź¾ź░╚ļķT1070: CUDA źūźĒź░źķź▀ź¾ź░╚ļķTNVIDIA Japan?
2015─Ļ9į┬18╚šķ_┤▀ĪĪGTC Japan 2015 ųvč▌┘Y┴Ž
┴Ōč¾ź©źņź»ź╚źĒųĻ╩Į╗ß╔ńĪĪCUDAź©ź¾źĖź╦źóĪĪ╩»Š«ū┴╚╦
ż│ż╬ź┴źÕ®`ź╚źĻźóźļżŪżŽĪóż│żņż½żķCUDAźūźĒź░źķź▀ź¾ź░ż“╩╝żßżļĮįśöż╦żÓż▒żŲĪóGPUż╬źŽ®`ź╔ź”ź¦źó źó®`źŁźŲź»ź┴źŃż╚Īóż│żņż╦īØÅĻż╣żļCUDAźūźĒź░źķź▀ź¾ź░źŌźŪźļż╦ż─żżżŲĖ┼šhżĘż▐ż╣ĪŻż▐ż┐Īó║åģgż╩╗ŁŽ±äI└Ēż╬źĄź¾źūźļż“└²ż╦ĪóWindowsŁhŠ│ż╦ż¬ż▒żļCUDA C/C++ż“ė├żżż┐źóźūźĻź▒®`źĘźńź¾ż╬ķ_░kĘĮĘ©ż╦ż─żżżŲĪóźŪźąź├ź░?źūźĒźšźĪźżźļż╬╩╦ĘĮżŌ║¼żßżŲšh├„żĘż▐ż╣ĪŻGPUź│ź¾źįźÕ®`źŲźŻź¾ź░ż╦┼d╬Čż¼żóżĻĪó╩╝żßżŲż▀ż┐żżż╚żżż”ĘĮż╬ż┤▓╬╝ėż“ż¬┤²ż┴żĘżŲżżż▐ż╣ĪŻ (JP) GPGPUż¼PostgreSQLż“╝ė╦┘ż╣żļ(JP) GPGPUż¼PostgreSQLż“╝ė╦┘ż╣żļKohei KaiGai?
http://www.insight-tec.com/dbts-tokyo-2014.html
--------
CPU/GPUż╚żżż”╠žąįż╬«Éż╩żļźūźĒź╗ź├źĄż╬Ą├ęŌĘųę░ż“ĮMż▀║Žż’ż╗żŲ┘Mė├?ļŖ┴”īØąį─▄ż╬Ž“╔Žż“Ščż”źžźŲźĒźĖź╦źóź╣ėŗ╦Ń╝╝ągżŽĪóĮ³─Ļż╬░ļī¦╠Õ╝╝ągż╬ź╚źņź¾ź╔ż╬ę╗ż─żŪż╣ĪŻ
▒Šź╗ź├źĘźńź¾żŪżŽĪóSQLź’®`ź»źĒ®`ź╔ż╬ż”ż┴CPUžō║╔ż╬Ė▀żżźĒźĖź├ź»ż“GPUż╦ź¬źšźĒ®`ź╔ż╣żļ╩┬żŪ░▓ü²ż╦Ś╩╦„äI└Ēż╬Ė▀╦┘╗»ż“īg¼Fż╣żļPostgreSQLė├ż╬ÆłÅłźŌźĖźÕ®`źļ PG-Strom ż╚ĪóGPGPUż“żŽżĖżßż╚ż╣żļų▄▐x╝╝ągż╦ż─żżżŲż┤ĮBĮķżĘż▐ż╣ĪŻ An Intelligent Storage?An Intelligent Storage?Kohei KaiGai?
SSD-to-GPU Direct DMAż“ė├żżżŲĪóŻ©ęŖż½ż▒╔ŽĪóŻ®GPUż¼I/Oż“Ė▀╦┘╗»ż╣żļż╚żżż”ż¬įÆżŪż╣ĪŻ
ź¬ź▐ź▒żŪĪóNVMe-SSDż“ūŅ┤¾Ž▐╗Ņė├żĘżŲWALĢ°żŁ▐zż▀ż“Ė▀╦┘╗»ż╣żļįÆżŌĪŻ Similar to 20170726 py data.tokyo (20)
NVIDIA GPU ╝╝ągūŅą┬Ūķł¾NVIDIA GPU ╝╝ągūŅą┬Ūķł¾IDC Frontier?
2017─Ļ6į┬13╚šż╦ķ_┤▀żĘż┐ĪĖAIŻ©╚╦╣żų¬─▄Ż®?Deep Learningż╬ūŅŪ░ŠĆĪ╣ż╦żŲĄŪē»żĄżņż┐Īóź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ń ū¶Ī®─Šśöż╬░k▒Ē┘Y┴ŽżŪż╣ 1010: ź©ź╠źėźŪźŻźó GPU ż¼╝ė╦┘ż╣żļźŪźŻ®`źūźķ®`ź╦ź¾ź░1010: ź©ź╠źėźŪźŻźó GPU ż¼╝ė╦┘ż╣żļźŪźŻ®`źūźķ®`ź╦ź¾ź░NVIDIA Japan?
2015─Ļ9į┬18╚šķ_┤▀ĪĪGTC Japan 2015 ųvč▌┘Y┴Ž
ź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ń
ź©ź¾ź┐®`źūźķźżź║źūźĒź└ź»ź╚╩┬śI▓┐ĪĪ╩┬śI▓┐ķLĪĪ╔╝▒Š ▓®╩Ę
ź©ź╠źėźŪźŻźóżŽźŪźŻ®`źūźķ®`ź╦ź¾ź░ż╬ż┐żßż╦ģgż╦GPUż“╠ß╣®żĘżŲżżżļż└ż▒żŪżŽżóżĻż▐ż╗ż¾ĪŻGPUż╬źčź’®`ż“ūŅ┤¾Ž▐ę²żŁ│÷ż╣ż┐żßż╬CUDAżŽżŌż┴żĒż¾ĪóGPUż╦ūŅ▀m╗»żĄżņż┐╩²éÄėŗ╦ŃźķźżźųźķźĻcuBLASżõźŪźŻ®`źūźķ®`ź╦ź¾ź░ė├ż╦ūŅ▀m╗»żĄżņż┐źķźżźųźķźĻcuDNNż╬╠ß╣®Ī󿥿ķż╦Caffeż╩ż╔ų°├¹ż╩źŪźŻ®`źūźķ®`ź╦ź¾ź░źšźņ®`źÓź’®`ź»ż“║åģgż╦╩╣ż”ż┐żßż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░GPUź╚źņ®`ź╦ź¾ź░źĘź╣źŲźÓDIGITSżŌķ_░kżĘżŲżżż▐ż╣ĪŻż│ż╬ź╗ź├źĘźńź¾żŪżŽż│żņżķź©ź╠źėźŪźŻźóż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░żžż╬╚ĪĮMż▀ż╚źŪźŻ®`źūźķ®`ź╦ź¾ź░ż╦ūŅ▀mż╩GPUčuŲĘż“ż┤ĮBĮķżĘż▐ż╣ĪŻ GTC 2018 ż╬╗∙š{ųvč▌ż½żķGTC 2018 ż╬╗∙š{ųvč▌ż½żķNVIDIA Japan?
ż│ż╬ź╣źķźżź╔żŽĪó2018 ─Ļ 4 į┬ 24 ╚š (╗) ż╦ź┘źļźĄ®`źļĖ▀╠’±Rł÷ż╦żŲķ_┤▀ż╬ NVIDIA Deep Learning Seminar 2018 ż╦ż¬ż▒żļĪóź©ź╠źėźŪźŻźó╚š▒Š┤·▒Ē╝µ├ū╣·▒Š╔ńĖ▒╔ńķL ┤¾Ųķšµąóż╦żĶżļĪĖGTC 2018 ż╬╗∙š{ųvč▌ż½żķĪ╣ż╬┘Y┴ŽżŪż╣ĪŻ GTC 2020 ░k▒Ē─┌╚▌ż▐ż╚żßGTC 2020 ░k▒Ē─┌╚▌ż▐ż╚żßNVIDIA Japan?
2020─Ļ5į┬22╚šŻ©ĮŻ®ķ_┤▀
Enterprise webinar vol.1
ĄŪē»Ż║
ź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ń
ź│ź¾ź╣®`ź▐®` ź▐®`ź▒źŲźŻź¾ź░▓┐
źŲź»ź╦ź½źļź▐®`ź▒źŲźŻź¾ź░ź▐ź═®`źĖźŃ®`
Ø╔Š«└Ē╝o NVIDIA Deep Learning SDK ż“└¹ė├żĘż┐╗ŁŽ±šJūRNVIDIA Deep Learning SDK ż“└¹ė├żĘż┐╗ŁŽ±šJūRNVIDIA Japan?
NVIDIA Deep Learning Institute
2016─Ļ4į┬27╚šż╬NVIDIA Deep Learning Day 2016 Springż╬┘Y┴ŽżŪż╣ĪŻ
ź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ńĪĪźūźķź├ź╚źšź®®`źÓźėźĖź═ź╣▒Š▓┐
źĘź╦źó CUDA ź©ź¾źĖź╦źóĪĪ╔Łę░ ╔„ę▓
[Ė┼ę¬]
źŪźŻ®`źūźķ®`ź╦ź¾ź░ SDK ż╬ź│ź¾ź▌®`ź═ź¾ź╚ż╬ę█ĖŅż“šh├„żĘĪóźŪźŻ®`źūźķ®`ź╦ź¾ź░ SDK ż“└¹ė├żĘż┐ Inference źóźūźĻź▒®`źĘźńź¾ż“╗ŁŽ±šJūRż╬└²ż“ė├żżżŲż┤ĮBĮķżĘż▐ż╣ĪŻ
Ī∙ 2016/5/2ż╦Īóźżź┘ź¾ź╚Ą▒╚šż╦╩╣ė├żĘż┐┘Y┴Žż╦Ė³ą┬żĘż▐żĘż┐ĪŻ NVIDIA ūŅĮ³ż╬äėŽ“NVIDIA ūŅĮ³ż╬äėŽ“NVIDIA Japan?
▒Šźūźņź╝ź¾źŲ®`źĘźńź¾żŽ 2017 ─Ļ 9 į┬ 18 ╚šż╦ķ_┤▀żĄżņż┐ĪóŽ─ż╬ź╚ź├źūź½ź¾źšźĪźņź¾ź╣šō╬─šiż▀╗ß (CVPR/ICML/KDD etc.) ż╦żŲĪóNVIDIA ż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░źĮźĻźÕ®`źĘźńź¾źó®`źŁźŲź»ź╚╔ĮŲķ║═▓®ż¼ż¬įÆżĘż┐żŌż╬żŪż╣ĪŻ ż╩ż╝│ę▒╩▒½żŽźŪźŻ®`źūźķ®`ź╦ź¾ź░ż╦Ž“żżżŲżżżļż½ż╩ż╝│ę▒╩▒½żŽźŪźŻ®`źūźķ®`ź╦ź¾ź░ż╦Ž“żżżŲżżżļż½NVIDIA Japan?
2015─Ļ8į┬19╚šĪĪźŪźŻ®`źūźķ®`ź╦ź¾ź░ź╗ź▀ź╩®`2015
├¹╣┼╬▌źļ®`ź╗ź¾ź╚ź┐ź’®`
ź©ź╠źėźŪźŻźó║Ž═¼╗ß╔ńĪĪźĘź╦źóźŪź┘źĒź├źč®`źŲź»ź╬źĒźĖ®` ź©ź¾źĖź╦źóĪĪ│╔×üš├
[Ė┼ę¬]
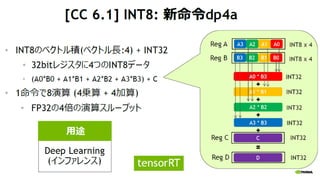
▒Šųvč▌żŪżŽĪóźŌźļźšź®ż¼╚ĪżĻĮMżÓDeep LearningŻ©ęįŽ┬ĪóDLŻ®źėźĖź═ź╣ż╦ż─żżżŲż╬Ė┼ꬿ╚Īóīgė├╗»ż╦ Ž“ż▒żŲźŪźŻ®`źūźķ®`ź╦ź¾ź░żŪżŽGPU└¹ė├ż¼źŪźšźĪź»ź╚ż╦ż╩ż├żŲżżż▐ż╣ż¼ĪóGPUż“╩╣ż”ż╚ż╩ż╝źŪźŻ®`źūźķ®`ź╦ź¾ź░ż╬č¦┴Ģźšź¦®`ź║ż“╝ė╦┘żŪżŁżļż╬ż½ĪóżĮż╬╝╝ągĄ─ż╩▒│Š░?└Ēė╔ż“šh├„ż╣żļż╚ż╚żŌż╦Īóź©ź╠źėźŪźŻźóż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░ķv▀BźĮźšź╚ź”ź¦źóż╬ūŅą┬Ūķł¾ż“ĮBĮķų┬żĘż▐ż╣ĪŻ GTC 2019 NVIDIA NEWSGTC 2019 NVIDIA NEWSKuninobu SaSaki?
2019─Ļ3į┬ż╦├ū╣·ź½źĻźšź®źļź╦źóų▌źĄź¾ź╬ź╝żŪķ_┤▀żĄżņż┐╩└ĮńūŅ┤¾ż╬GPU╝╝ągźżź┘ź¾ź╚ĪĖGTC 2019Ī╣╗∙š{ųvč▌ż╬░k▒Ē─┌╚▌ż“ż▐ż╚żßż▐żĘż┐ĪŻ More from ManaMurakami1 (8)
20170726 py data.tokyo
- 2. 2
ūį╝║ĮBĮķ
┤Õ╔Žšµ─╬(żÓżķż½ż▀ż▐ż╩) / mmurakami@nvidia.com
? CUDAź©ź¾źĖź╦źóŻ½źŪźŻ®`źūźķ®`ź╦ź¾ź░SA
? źŪźŻ®`źūźķ®`ź╦ź¾ź░?CUDA╝╝ągźĄź▌®`ź╚ż╚ż½ĪóżżżĒżżżĒ
ł╬ė±▒hżĄżżż┐ż▐╩ą
įńĘR╠’┤¾č¦Į╠ė²č¦▓┐└Ēč¦┐Ų╩²č¦?źĘź╣źŲźÓėŗ╗ŁčąŠ┐╦∙?źĄźÓź╣ź¾╚š▒ŠčąŠ┐╦∙?ź©ź╠źėźŪźŻźó
╗ŁŽ±äI└Ē(ų„ż╦Š▓ų╣╗Ł)ĪóźĮźšź╚ż╬ūŅ▀m╗»ż╚ż½Īó
źūźĻź»źķż╚ż½Ę┼╦═ÖCŲ„ż╚ż½źŲźņźėż╚ż½
2010─ĻĒĢż╦│§żßżŲCUDAż╦żšżņżļ(CUDA1.XXż╚ż½ż╬Ģr┤·)
NVIDIAGPUComputing
NVIDIAJapan
@NVIDIAJapan
- 5. 6
ź©ź╠źėźŪźŻźó
AI ź│ź¾źįźÕ®`źŲźŻź¾ź░ź½ź¾źčź╦®`
> 1993 ─ĻäōśI
> äōśIš▀╝░żė CEO źĖź¦ź¾ź╣ź¾ źšźĪź¾
> ÅŠśIåT 11,000 ╚╦
> 2017 ╗ßėŗ─ĻČ╚ēė╔ŽĖ▀ 69ā|ź╔źļ (╝s 7700 ā|āę)
> Ģrü²ŠtŅ~ 808ā|ź╔źļ (╝s 9šūāę)
Ī░WorldĪ»s Best Performing CEOsĪ▒ Ī¬ Harvard Business
Review
Ī░WorldĪ»s Most Admired CompaniesĪ▒ Ī¬ Fortune
Ī░AmericaĪ»s Greenest CompaniesĪ▒ Ī¬ Newsweek
Ī░50 Smartest CompaniesĪ▒ Ī¬ MIT Tech Review
Ī░Top 50 Best Places to WorkĪ▒ Ī¬ Glassdoor
- 7. 8
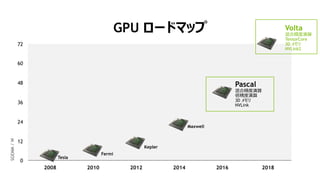
2012 20142008 2010 2016 2018
48
36
12
0
24
60
72
Tesla
Fermi
Kepler
Maxwell
Pascal
╗ņ║ŽŠ½Č╚č▌╦Ń
▒ČŠ½Č╚č▌╦Ń
3D źßźŌźĻ
NVLink
GPU źĒ®`ź╔ź▐ź├źū
SGEMM/W
Volta
╗ņ║ŽŠ½Č╚č▌╦Ń
TensorCore
3D źßźŌźĻ
NVLink2
- 8. 9
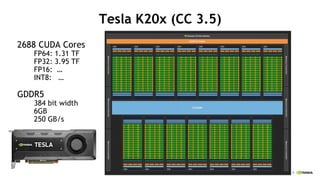
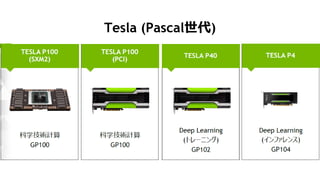
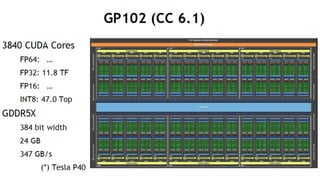
Tesla K20x (CC 3.5)
2688 CUDA Cores
FP64: 1.31 TF
FP32: 3.95 TF
FP16: ĪŁ
INT8: ĪŁ
GDDR5
384 bit width
6GB
250 GB/s
- 9. 10
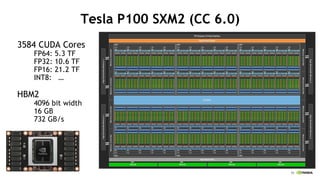
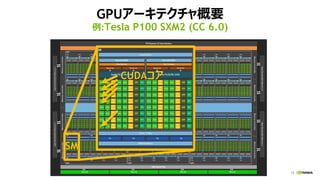
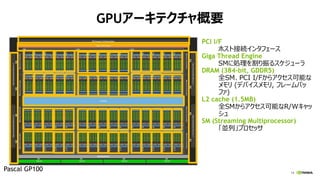
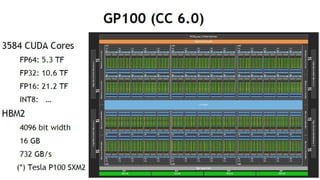
Tesla P100 SXM2 (CC 6.0)
3584 CUDA Cores
FP64: 5.3 TF
FP32: 10.6 TF
FP16: 21.2 TF
INT8: ĪŁ
HBM2
4096 bit width
16 GB
732 GB/s
- 10. 11
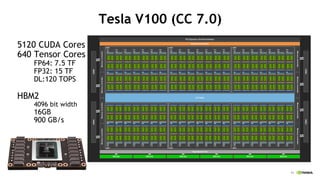
Tesla V100 (CC 7.0)
5120 CUDA Cores
640 Tensor Cores
FP64: 7.5 TF
FP32: 15 TF
DL:120 TOPS
HBM2
4096 bit width
16GB
900 GB/s
- 11. 12
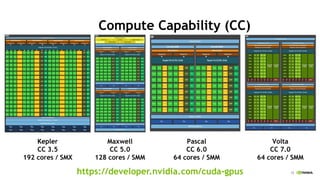
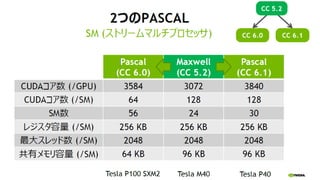
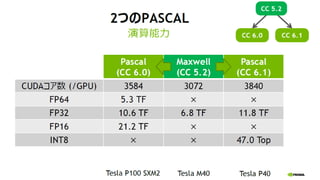
Compute Capability (CC)
Kepler
CC 3.5
192 cores / SMX
Maxwell
CC 5.0
128 cores / SMM
Pascal
CC 6.0
64 cores / SMM
https://developer.nvidia.com/cuda-gpus
Volta
CC 7.0
64 cores / SMM
- 14. 15
SM (streaming multiprocessor)
? CUDA core
? GPUź╣źņź├ź╔żŽż│ż╬╔ŽżŪäėū„
? Pascal: 64éĆ
? Other units
? DP, LD/ST, SFU
? Register File (65,536 x 32bit)
? Shared Memory/L1 Cache
(64KB)
? Read-Only Cache(48KB)
- 21. 22
K80 M40 M4
P100
(SXM2)
P100
(PCIE)
P40 P4
GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104
CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560
PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA
PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5
PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA
PEAK TIOPs NA NA NA NA NA 47 22
Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5
Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s
Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3
NVLINK +
PCIe Gen3
PCIe Gen3 PCIe Gen3 PCIe Gen3
ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5
Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP
Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W
TeslačuŲĘę╗ėE
ż┐ż»żĄż¾żóżļż¼Īóż╔żņż“╩╣ż©żążĶżżż╬ż½?
- 25. 26
K80 M40 M4
P100
(SXM2)
P100
(PCIE)
P40 P4
GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104
CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560
PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA
PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5
PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA
PEAK TIOPs NA NA NA NA NA 47 22
Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5
Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s
Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3
NVLINK +
PCIe Gen3
PCIe Gen3 PCIe Gen3 PCIe Gen3
ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5
Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP
Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W
TeslačuŲĘę╗ėE
═Ųšō ═Ųšōč¦┴Ģ č¦┴Ģ
- 26. 27
K80 M40 M4
P100
(SXM2)
P100
(PCIE)
P40 P4
GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104
CUDA core 4992(2496*2) 3072 1024 3584 3584 3840 2560
PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA
PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5
PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA
PEAK TIOPs NA NA NA NA NA 47 22
Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5
Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s
Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3
NVLINK +
PCIe Gen3
PCIe Gen3 PCIe Gen3 PCIe Gen3
ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5
Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP
Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W
TeslačuŲĘę╗ėE
- 41. 47
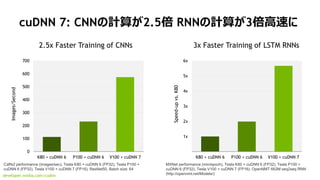
developer.nvidia.com/cudnn
cuDNN 7: CNNż╬ėŗ╦Ńż¼2.5▒Č RNNż╬ėŗ╦Ńż¼3▒ČĖ▀╦┘ż╦
0
100
200
300
400
500
600
700
K80 + cuDNN 6 P100 + cuDNN 6 V100 + cuDNN 7
Images/Second
Caffe2 performance (images/sec), Tesla K80 + cuDNN 6 (FP32), Tesla P100 +
cuDNN 6 (FP32), Tesla V100 + cuDNN 7 (FP16). ResNet50, Batch size: 64
0x
1x
2x
3x
4x
5x
6x
K80 + cuDNN 6 P100 + cuDNN 6 V100 + cuDNN 7
Speed-upvs.K80
MXNet performance (min/epoch), Tesla K80 + cuDNN 6 (FP32), Tesla P100 +
cuDNN 6 (FP32), Tesla V100 + cuDNN 7 (FP16). OpenNMT 662M seq2seq RNN
(http://opennmt.net/Models/)
2.5x Faster Training of CNNs 3x Faster Training of LSTM RNNs
- 43. 49
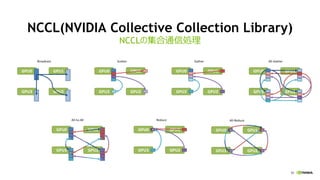
NCCL(NVIDIA Collective Collection Library)
ź▐źļź┴GPUż¬żĶżėź▐źļź┴ź╬®`ź╔ż╬×ķż╬╝»║Ž═©ą┼źķźżźųźķźĻ
all-gather, reduce, broadcast ż╩ż╔ś╦£╩Ą─ż╩╝»║Ž═©
ą┼ż╬äI└Ēż“źąź¾ź╔Ę∙ż¼│÷żļżĶż”ż╦ūŅ▀m╗»
źĘź¾ź░źļźūźĒź╗ź╣ż¬żĶżėź▐źļź┴źūźĒź╗ź╣żŪ╩╣ė├ż╣żļ╩┬ż¼┐╔─▄
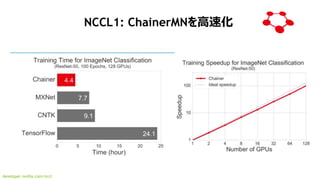
NCCL1:ź▐źļź┴GPUīØÅĻ(ź¬®`źūź¾źĮ®`ź╣źūźĒźĖź¦ź»ź╚)
? https://github.com/NVIDIA/nccl
NCCL2:ź▐źļź┴ź╬®`ź╔īØÅĻ(coming soon)
https://developer.nvidia.com/nccl
źŪźŻ®`źūźķ®`ź╦ź¾ź░ SDK
ź▐źļź┴ź╬®`ź╔:
źżź¾źšźŻź╦źąź¾ź╔
IP Sockets
ź▐źļź┴GPU:
NVLink
PCIe
GPUź╚ź▌źĒźĖż╬
ūįäėŚ╩│÷
- 46. 52
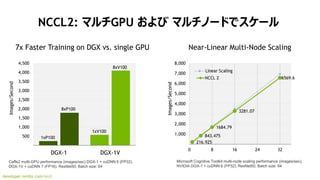
NCCL2: ź▐źļź┴GPU ż¬żĶżė ź▐źļź┴ź╬®`ź╔żŪź╣ź▒®`źļ
developer.nvidia.com/nccl
216.925
843.475
1684.79
3281.07
6569.6
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
0 8 16 24 32
NCCL 2
Images/Second
Near-Linear Multi-Node Scaling
Microsoft Cognitive Toolkit multi-node scaling performance (images/sec),
NVIDIA DGX-1 + cuDNN 6 (FP32), ResNet50, Batch size: 64
Images/Second
7x Faster Training on DGX vs. single GPU
Caffe2 multi-GPU performance (images/sec) DGX-1 + cuDNN 6 (FP32),
DGX-1V + cuDNN 7 (FP16). ResNet50, Batch size: 64
0
500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
4,500
DGX-1 DGX-1V
1xP100
1xV100
8xP100
8xV100
- 52. 58
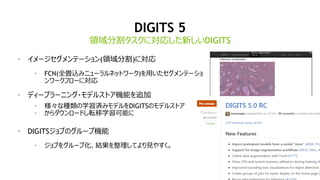
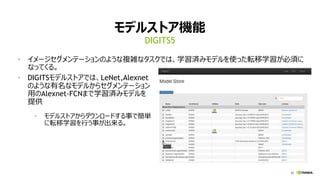
DIGITS 5
? źżźß®`źĖź╗ź░źßź¾źŲ®`źĘźńź¾(ŅIė“ĘųĖŅ)ż╦īØÅĻ
? FCN(╚½«Æ▐zż▀ź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»)ż“ė├żżż┐ź╗ź░źßź¾źŲ®`źĘźń
ź¾ź’®`ź»źšźĒ®`ż╦īØÅĻ
? źŪźŻ®`źūźķ®`ź╦ź¾ź░?źŌźŪźļź╣ź╚źóÖC─▄ż“ūĘ╝ė
? śöĪ®ż╩ĘNŅÉż╬č¦┴Ģ£gż▀źŌźŪźļż“DIGITSż╬źŌźŪźļź╣ź╚źó
? ż½żķź└ź”ź¾źĒ®`ź╔żĘ▄×ęŲč¦┴Ģ┐╔─▄ż╦
? DIGITSźĖźńźųż╬ź░źļ®`źūÖC─▄
? źĖźńźųż“ź░źļ®`źū╗»ĪóĮY╣¹ż“š¹└ĒżĘżŲżĶżĻęŖżõż╣ż»ĪŻ
ŅIė“ĘųĖŅź┐ź╣ź»ż╦īØÅĻżĘż┐ą┬żĘżżDIGITS
- 55. 63
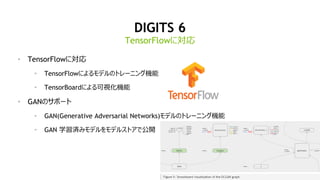
DIGITS 6
? TensorFlowż╦īØÅĻ
? TensorFlowż╦żĶżļźŌźŪźļż╬ź╚źņ®`ź╦ź¾ź░ÖC─▄
? TensorBoardż╦żĶżļ┐╔ęĢ╗»ÖC─▄
? GANż╬źĄź▌®`ź╚
? GAN(Generative Adversarial Networks)źŌźŪźļż╬ź╚źņ®`ź╦ź¾ź░ÖC─▄
? GAN č¦┴Ģ£gż▀źŌźŪźļż“źŌźŪźļź╣ź╚źóżŪ╣½ķ_
TensorFlowż╦īØÅĻ
- 61. 69
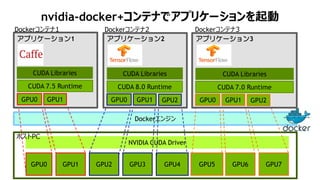
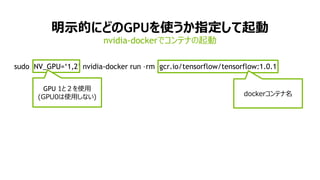
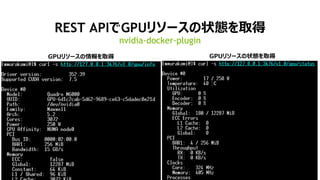
nvidia-docker+ź│ź¾źŲź╩żŪźóźūźĻź▒®`źĘźńź¾ż“Ųäė
GPU2 GPU3 GPU4 GPU6 GPU7
NVIDIA CUDA Driver
Dockerź©ź¾źĖź¾
GPU5GPU0 GPU1
ź█ź╣ź╚PC
GPU0 GPU1
CUDA Libraries
Dockerź│ź¾źŲź╩1
CUDA 7.5 Runtime
źóźūźĻź▒®`źĘźńź¾1
GPU0 GPU1 GPU2
CUDA Libraries
Dockerź│ź¾źŲź╩2
CUDA 8.0 Runtime
źóźūźĻź▒®`źĘźńź¾2
GPU0 GPU1 GPU2
CUDA Libraries
Dockerź│ź¾źŲź╩3
CUDA 7.0 Runtime
źóźūźĻź▒®`źĘźńź¾3



















![39
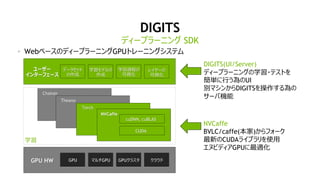
źŪźŻ®`źūźķ®`ź╦ź¾ź░źšźņ®`źÓź’®`ź»
ź│ź¾źįźÕ®`ź┐źėźĖźńź¾ ź▄źżź╣&ź¬®`źŪźŻź¬ ūį╚╗čįšZäI└Ē
╬’╠ÕŚ╩│÷ ę¶╔∙šJūR čįšZĘŁįU ═Ų╦]ź©ź¾źĖź¾ ĖąŪķĘų╬÷
Mocha.jl
╗ŁŽ±ĘųŅÉ
źŪźŻ®`źūźķ®`ź╦ź¾ź░ SDK
źŪźŻ®`źūźķ®`ź╦ź¾ź░ż“╝ė╦┘ż╣żļźŪźŻ®`źūźķ®`ź╦ź¾ź░źķźżźųźķźĻ
źŪźŻ®`źūźķ®`ź╦ź¾ź░
cuDNN
CUDA ╩²č¦źķźżźųźķźĻ
cuBLAS cuSPARSE
ź▐źļź┴GPUķg═©ą┼
NCCLcuFFT
źėźŪź¬ĮŌ╬÷ źżź¾źšźĪźņź¾ź╣](https://image.slidesharecdn.com/20170726pydata-170727155452/85/20170726-py-data-tokyo-37-320.jpg)


![46
NVIDIA cuDNN
GPU╔ŽżŪźŪźŻ®`źūź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╬ėŗ╦Ńż“
Ė▀╦┘ż╦ąąż”×ķż╬źūźĻź▀źŲźŻźų╚║
źŪźŻ®`źūź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╬č¦┴Ģż╬Ė▀żżźč
źšź®®`ź▐ź¾ź╣ż“░kō]
CaffeĪó CNTKĪó TensorflowĪó TheanoĪó
TorchĪóChainerż╩ż╔źŪźŻ®`źūźķ®`ź╦ź¾ź░źšźņ®`
źÓź’®`ź»ż“Ė▀╦┘╗»
źą®`źĖźńź¾źóź├źūÜ░ż╦źčźšź®®`ź▐ź¾ź╣ż¼Ž“╔Ž
Ī░NVIDIAżŽcuDNNż╬źĻźĻ®`ź╣ż╬Č╚ż╦żĶżĻČÓż»ż╬▓┘ū„
ż¼żŪżŁżļżĶż”ż╩ÖC─▄ÆłÅłż“ż¬ż│ż╩ż├żŲż¬żĻĪó═¼Ģr
ż╦ėŗ╦Ń╦┘Č╚żŌŽ“╔ŽżĄż╗żŲżżżļĪ▒
Ī¬UC źą®`ź»źņ®`Īó Caffe źĻ®`ź╔źŪź┘źĒź├źč®`Īó Evan Shelhamer
developer.nvidia.com/cudnn
0
2,000
4,000
6,000
8,000
10,000
12,000
8x K80 8x Maxwell DGX-1 DGX-1V](https://image.slidesharecdn.com/20170726pydata-170727155452/85/20170726-py-data-tokyo-40-320.jpg)